[五年CSP三年模拟]洛谷2020初赛模拟赛分析
#1.0 单项选择题
#1.1 第1题
题面
1.十进制数 \(114\) 的相反数的 \(8\) 位二进制补码是:
A.10001110\(\qquad\)B.10001101
C.01110010\(\qquad\)D.01110011
分析与解答
\(114\) 的相反数为 \(-114\),
\(-114\) 的二进制原码为 \(11110010\)
所以它的补码为原码按位取反加一
即为 \(10001110\),选 A.
#1.2 第2题
题面
2.以下哪个网站不是 Online Judge (在线程序判题系统)? Online Judge可以查看算法题目,提交自己编写的程序,然后可以获得评测机反馈的结果。
A.Luogu\(\qquad\)B.Gitee\(\qquad\)C.Leetcode\(\qquad\)D.Codeforces
分析与解答
不多BB,自己点进去看[\doge]
#1.3 第3题
题面
小A用字母 \(A\) 表示 \(1\),用 \(B\) 表示 \(2\),以此类推,用 \(Z\) 表示 \(26\)。对于 \(27\) 以上的数字,可以用两位或者更长的字符串对应,例如 \(AA\) 表示 \(27\),\(AB\) 表示 \(28\),\(AZ\) 对应 \(52\),\(AAA\) 对应 \(703\)……那么 \(BYT\) 字符串对应的数字是什么?
A.2018\(\qquad\)B.2020\(\qquad\)C.2022\(\qquad\)D.2024
分析与解答
我们发现,我们可以把它看成一种特殊的27进制数,这种数没有 '0' 这个数字,打个比方,就像十进制数 '9' 之后直接是 '11','99' 之后直接是 '111',即第二位向第三位进一时需要的数不用加上第一位的 26 ,那么我们可以发现,每 \(27\) 向第二位进一,但上一位需保留 \(1\)(所以第二位每一个一只包含26),每 \(26^2\) 向第三位进一
通过推算可以得到下表
| Str | Num | Str* |
|---|---|---|
| A | 1 | \(1\) |
| Z | 26 | \(Z\) |
| AA | 27 | \(Z + 1\) |
| AZ | 52 | \(Z + Z\) |
| BA | 53 | \(Z + Z + 1\) |
| ZZ | 702 | \(26^2 + Z\) |
| AAA | 703 | \(ZZ + 1\) |
| AZZ | 1378 | \(ZZ + 26^2\) |
| BZZ | 2054 | \(ZZ + 2 \times 26^2\) |
| BYZ | 2038 | \(ZZ + 2 \times 26^2 - Z\) |
| BYT | 2022 | \(ZZ + 2 \times 26^2 - Z - 16\) |
| 故选 B. |
#1.4 第4题
题面

分析与解答
图片大小计算公式:
这张图片的大小为:
故选 B.
#1.5 第5题
题面

分析与解答
最快的排序为 桶排序,时间复杂度为 \(O(n)\),故选 A.
#1.6 第6题
题面

分析与解答
树是一个简单无环连通图,故①④错
选 C.
#1.7 第7题
题面

分析与解答
每次分成两堆,每张卷子至少查看两次,故为 \(42 \times 2=84\) 次
故选 A.
#1.8 第8题
题面

分析与解答
- 前序遍历(VLR)是二叉树遍历的一种,也叫做先根遍历、先序遍历、前序周游,可记做根左右。前序遍历首先访问根结点然后遍历左子树,最后遍历右子树。
- 中序遍历(LDR)是二叉树遍历的一种,也叫做中根遍历、中序周游。在二叉树中,中序遍历首先遍历左子树,然后访问根结点,最后遍历右子树。
由以上的定义我们可以很轻松的画出这棵树:
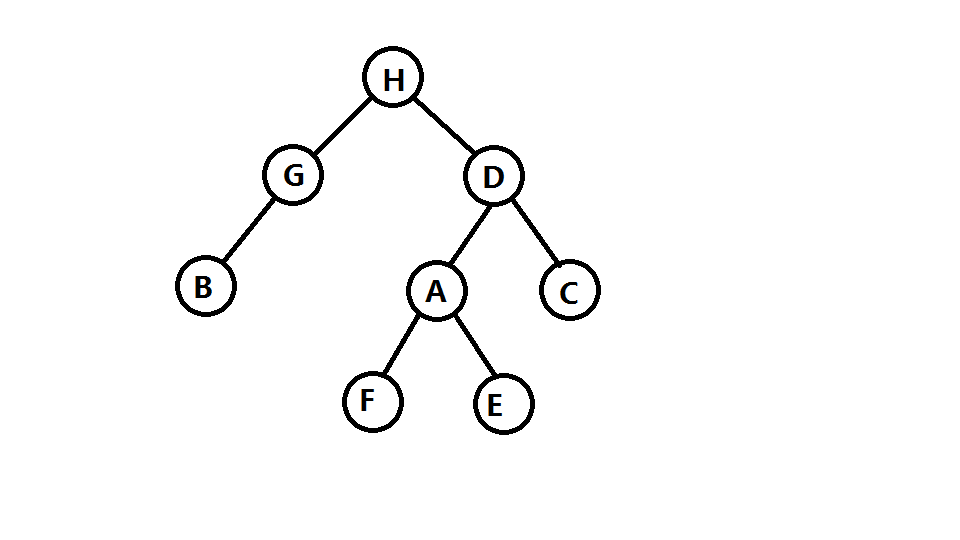
我们又知道,二叉树中,结点 \(i\) 的左儿子编号为 \(2 \times i\),右儿子编号为 \(2 \times i+1\),
故可得下图
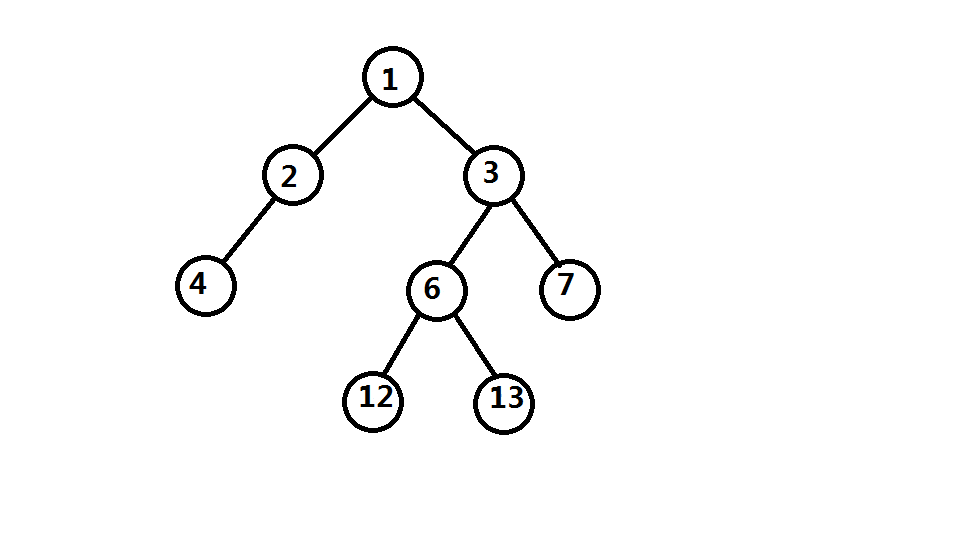
所以数组最大下标为 \(13\)
故选 B.
#1.9 第9题
题面

分析与解答
优先级: \(! > \&\& > ||\)
A选项:\(a\&\&b=0\),\(b\&\&c=0\),所以 \(0||0=0\)
B选项:\(a+b>c=0\),\(b=0\),所以 \(0||0=0\)
C选项:\(!c=0\),\(!a||b=0\),所以 \(0||0=0\)
D选项:\(a+b+c=2\),C艹C++中bool运算非0即
故选 D.
#1.10 第10题
题面

分析与解答
链表的查询是由前向后逐个查找,那么查询次数最少的情况就是每次要查找的数都是链表的头结点,每次只访问一个结点,共有 \(k\) 次请求,故为 \(k\) 次
故选 B.
#1.11 第11题
题面

分析与解答
- 枚举大法
这显然是道排列组合,不过数据较小,可以枚举(枚举大法好)
要注意每个班有人数限制
| i | C | B | A |
|---|---|---|---|
| 1 | 0 | 0 | 5 |
| 2 | 0 | 2 | 4 |
| 3 | 0 | 3 | 3 |
| 4 | 0 | 4 | 2 |
| 5 | 1 | 0 | 5 |
| 6 | 1 | 1 | 4 |
| 7 | 1 | 2 | 3 |
| 8 | 1 | 3 | 2 |
| 9 | 1 | 4 | 1 |
| 10 | 2 | 0 | 4 |
| 11 | 2 | 1 | 3 |
| 12 | 2 | 2 | 2 |
| 13 | 2 | 3 | 1 |
| 14 | 2 | 4 | 0 |
| 15 | 3 | 0 | 3 |
| 16 | 3 | 3 | 0 |
| 17 | 3 | 1 | 2 |
| 18 | 3 | 2 | 1 |
| 共 \(18\) 种 |
- 排列组合
我们可以将这个问题看成 “有 \(6\) 个相同的小球,放进 \(3\) 个不相同的的盒子中,每个盒子有限制,可以为空”,
我们先来求 “有 \(6\) 个相同的小球,放进 \(3\) 个不相同的的盒子中,可以为空” 的所有情况,即
其中 “有一个盒子中有 \(6\) 个小球,其余盒子为空” 的 \(3\) 种情况都无法满足条件
“有一个盒子中有 \(5\) 个小球,其余两个盒子中,有一个盒子里有 \(1\) 个球”的情况下,这 \(5\) 个球在B盒或C盒的 \(2 \times 2=4\) 种情况无法满足条件
对于每个盒子,盒子里有 \(5\) 个球时,都有 \(2\) 种情况,为
1 5 0,0 5 1和0 1 5,1 0 5
“有一个盒子中有 \(4\) 个小球,其余 \(2\) 个球分散在剩下两个盒子里” 的情况下,这 \(4\) 个球在C盒的 \(C^1_3=3\) 种情况无法满足条件
就是将剩下两个相同球放入两个不同盒子里,盒子可以为空的情况数,
4 0 2,4 2 0,4 1 1
那么共有 \(28 - 3 - 4 - 3 = 18\) 种情况
故选 B.
#1.12 第12题
题面

分析与解答
各排序时间复杂度(平均):
- 插入排序 \(O(n^2)\)
- 希尔排序 \(O(n^{1.3})\)
- 选择排序 \(O(n^2)\)
- 堆排序 \(O(n\log{n})\)
- 冒泡排序 \(O(n^2)\)
- 快速排序 \(O(n\log{n})\)
- 归并排序 \(O(n\log{n})\)
- 基数排序 \(O(d(r+n))\)(\(d\) 表示长度,\(r\) 表示关键字基数,\(n\) 表示关键字个数)
故选 B.
#1.13 第13题
题面

分析与解答
\(x \in [a,b)\) 表示 \(a \leqslant x < b\)
rand()%M表示生成一个在区间 \([0,M)\) 内的随机数
所以rand()%M+a可生成一个在区间 \([a,M+a)\) 内的随机数
那么生成一个在区间 \([a,b)\) 内的随机数就等价于生成一个在区间 \([a,b-a+a)\) 内的随机数
即为rand()%(b-a)+a
故选 A.
#1.14 第14题
题面

分析与解答
我们首先看森林和完全图的定义:
森林(forest)是 \(m\)(\(m \geqslant 0\))棵互不相交的树的集合。
完全图是一个简单的无向图,其中每对不同的顶点之间都恰连有一条边相连。
所以,只有一棵树也可以称作森林
那这道题就变成了 “一个7个顶点的完全图需要至少删掉多少条边才能变成一棵树?”
一个有7个顶点的完全图共有 \(\dfrac{7 \times (7-1)}{2}=21\)条边
一棵有7个结点的树共有 \(6\) 条边
所以最少删去 \(21-6=15\) 条边
故选 C.
#1.15 第15题
题面

分析与解答
第37届全国青少年信息学奥林匹克竞赛(CCF NOI2020)于2020年8月16-21日在长沙市一中雨花新华都学校举行
故选 D.
#2.0 阅读程序
#2.1 第1题
#include<iostream>
using namespace std;
#define MAXN 20
int gu[MAXN][MAXN];
int luo(int n, int m) {
if(n <= 1 || m < 2)
return 1;
if(gu[n][m] != -1)
return gu[n][m];
int ans = 0;
for(int i = 0;i < m;i += 2)
ans += luo(n - 1,i);
gu[n][m] = ans;
return ans;
}
int main(){
int n, m;
cin >> n >> m;
for(int i = 0; i < MAXN; i++)
for(int j = 0; j < MAXN; j++)
gu[i][j] = -1;
cout << luo(n, m);
return 0;
}
1.luo函数中,\(m\) 的值不可能是奇数 ( )
在主程序main()中,传入luo(n,m),这里 \(m\) 的值由键盘输入,可以为奇数,故为错
2.若将第11行的 “<” 改为 “<=”,程序的输出结果可能会改变 ( )
改后可能会多循环一次,结果可能会改变,故为对
3.若将第8.9.13行删除,程序的运行的结果不变 ( )
观察程序可以发现,二维数组gu[i][j]是用作记忆化搜索
而第8.9.13行则是进行记忆化搜索的实现,记忆化搜索仅会减少程序运行的时间,但不会改变结果,故为对
4.在添加合适的头文件后,将第19到21行替换为memset(gu,255,sizeof(gu));可以起到相同的作用 ( )
第19到21行是给二维数组gu[i][j]赋初值 \(-1\)
memset() 是给每一个byte赋值,int是 \(4 byte = 32bit\),\(255\) 的二进制是 11111111,赋值给int后,int中储存的数为 11111111 11111111 11111111 11111111 ,
但是由于 int 是有符号的,以补码形式储存,第一位为符号位,自然变成了 \(-1\),故为对
同样的,当运行 memset(gu,-1,sizeof(gu)) 时,直接将 \(-1\) 以补码形式(111111111)赋给 int ,
int中储存的数为 11111111 11111111 11111111 11111111 ,结果也是 \(-1\)
5.若输入数据为 4 8,则输出为( )
A.7\(\qquad\)B.8\(\qquad\)C.15\(\qquad\)D.16
没什么好说的,要有一颗勇于模拟的心ヽ( ̄▽ ̄)و选B.
6.最坏情况下,此程序的时间复杂度是( )
A.\(O(m^2n)\qquad\)B.\(O(nm!)\qquad\)C.\(O(n^2)\qquad\)D.\(O(n^2m)\)
不会,过/kk 选 A.
#2.2 第2题


1.错误
调整之后,f[i][k]和f[k][j] 可能并没有计算或得到的不是最优解,不能保证是全局最优解,而原程序则能保证为最优解
2.错误
m与输入有关,想想为什么会有快读这个东西
3.正确
注意数据范围,当整个图为一条链或数据足够大时,答案会超出 \(10^7\)
4.正确
两者顺序更换对答案并无影响
5.A
我们首先需要知道这个程序是在求什么,
第14到19行,求的是原图的全源最短路
第21到40行,则是将原图中任意两点并为一点(程序第 26 行的F[i][j] = F[j][i] = 0就是将两点间的距离改为 \(0\)),再求出此时任意两点间最短路长度之和,取最小值,数据并不大,可以手动模拟
我们先根据给出的数据画出这个图:
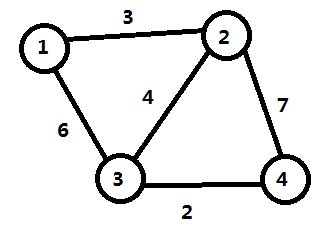
然后列出此时任意两点间最短路长度,如下表:
| i | j | f |
|---|---|---|
| 1 | 2 | 3 |
| 1 | 3 | 6 |
| 1 | 4 | 8 |
| 2 | 3 | 4 |
| 2 | 4 | 6 |
| 3 | 4 | 2 |
再根据上面的分析,依次并点,可得到:

| i | j | f |
|---|---|---|
| 1 | 2 | 0 |
| 1 | 3 | 6 |
| 1 | 4 | 7 |
| 2 | 3 | 6 |
| 2 | 4 | 5 |
| 3 | 4 | 2 |
| tot = 26 | ||
.png) |
||
| i | j | f |
| :--: | :--: | :--: |
| 1 | 2 | 3 |
| 1 | 3 | 0 |
| 1 | 4 | 2 |
| 2 | 3 | 3 |
| 2 | 4 | 5 |
| 3 | 4 | 2 |
| tot = 15 | ||
.png) |
||
| i | j | f |
| :--: | :--: | :--: |
| 1 | 2 | 3 |
| 1 | 3 | 2 |
| 1 | 4 | 0 |
| 2 | 3 | 4 |
| 2 | 4 | 3 |
| 3 | 4 | 2 |
| tot = 14 | ||
.png) |
||
| i | j | f |
| :--: | :--: | :--: |
| 1 | 2 | 3 |
| 1 | 3 | 3 |
| 1 | 4 | 5 |
| 2 | 3 | 0 |
| 2 | 4 | 2 |
| 3 | 4 | 2 |
| tot = 15 | ||
.png) |
||
| i | j | f |
| :--: | :--: | :--: |
| 1 | 2 | 3 |
| 1 | 3 | 5 |
| 1 | 4 | 3 |
| 2 | 3 | 2 |
| 2 | 4 | 0 |
| 3 | 4 | 2 |
| tot = 15 | ||
.png) |
||
| i | j | f |
| :--: | :--: | :--: |
| 1 | 2 | 3 |
| 1 | 3 | 6 |
| 1 | 4 | 6 |
| 2 | 3 | 6 |
| 2 | 4 | 6 |
| 3 | 4 | 0 |
tot = 27
答案显然是 \(14\)
6.A
这奇妙的时间复杂度,肯定就是Floyd(。-`ω´-)
#2.3 第3题
#include <bits/stdc++.h>
using namespace std;
#define MOD 19260817
#define MAXN 1005
long long A[MAXN][MAXN] = {0},sum[MAXN][MAXN] = {0};
int n,m,q;
int main(){
A[1][1] = A[1][0] = 1;
for (int i = 2;i <= 1000;i ++){
A[i][0] = 1;
for (int j = 1;j <= i;j ++)
A[i][j] = (A[i - 1][j] + A[i - 1][j - 1]) % MOD;
}
for (int i = 1;i <= 1000;i ++)
for (int j = 1;j <= 1000;j ++)
sum[i][j] = (sum[i - 1][j] + sum[i][j - 1]
- sum[i - 1][j - 1] + A[i][j] + MOD) % MOD;
int q;
cin >> q;
while (q --){
int n,m;
cin >> n >> m;
cout << sum[n][m] << endl;
}
return 0;
}
1.当i<=j时,A[i][j]的值是0 ( )
当i==j时,值为1,故为错
2.当i>j时,A[i][j]的值相当于从个 \(i\) 不同元素中取出 \(j\) 个元素的排列数 ( )
这里实际是 \(C^j_i\),其递推式与代码中的递推式符合。故为错
拓展-组合数递推公式
简单证明:从 \(n\) 个不同的数中取 \(m\) 个数,第 \(n\) 个数如果取有 \(C^{m-1}_{n-1}\) 种情况,如果不取有 \(C^{m}_{n-1}\) 种情况
3.sum[i][j]的值 \((1 <j<i \leqslant 1000)\) 不小于 sum[i-1][j-1]的值 ( )
注意这里有模数为 \(19260817\) (话说这个模数...好评[\doge])
4.若将第12行改为 A[i][j] = (A[i - 1][j] + A[i - 1][j - 1] + MOD) % MOD;,程序的运行的结果不变 ( )
没有溢出问题的话,这样写是对的。这个写法也常用来对负数取模。
5.A[i][j] \((1 \leqslant j,i \leqslant 10)\) ,的所有元素中,最大值是( )
A.126\(\qquad\)B.276\(\qquad\)C.252\(\qquad\)D.210
由组合数通项公式
可以看出,我们要找最大,要使 \(n\) 尽可能大, \(m! \cdot (n-m)!\) 尽可能小,\(10\) 以内组合数最大为 \(C^5_{10} = 252\),故选C
6.若输入的数为 1/5 3(其中 “/” 为换行符),则输出为( )
A.10\(\qquad\)B.35\(\qquad\)C.50\(\qquad\)D.24
观察程序,加以简单计算,很容易发现 sum 就是杨辉三角的前缀和。
自己计算前缀和可得选C
#3.0 补全程序
#3.1 第1题
(封禁xxs)现有n个xxs(编号为1到n),每个xxs都有一个关注者,第i个xxs的关注者是ai。
现在管理员要将其中的一些xxs的账号封禁,但需要注意的是如果封禁了第i个人,
那么为了不打草惊蛇,就不能封禁他的关注者ai。现在想知道最多可以封禁多少个xxs。
输入第一行是一个不超过300000的整数n,第二行是n个1到n的整数表示ai。
输出一行,一个整数表示答案。
#include <cstdio>
using namespace std;
#define MAXN 300005
int n, ans = 0, a[MAXN], in[MAXN] = {0};
bool vis[MAXN] = {0};
void dfs(int cur, int w) {
if(vis[cur])
return;
vis[cur] = true;
if(w == 1) ans++;
①
if(②)
dfs(a[cur], ③);
}
int main() {
scanf("%d", &n);
for(int i = 1; i <= n; i++) {
scanf("%d", &a[i]);
in[a[i]]++;
}
for(int i = 1; i <= n; i++)
if(!in[i]) ④;
for(int i = 1; i <= n; i++)
if(⑤) dfs(i, 0);
printf("%d\n", ans);
return 0;
}
1.①处应填( )
A.a[cur]=cur;
B.in[a[cur]]=0;
C.in[a[cur]]--;
D.in[cur]--;
该点已经遍历过了,无论是否删除,都不会再次遍历,所以我们可以视为把它去掉,那么我们就要将这个结点(cur)的关注者(a[cur])关注的人数(in[a[cur]])减一
故选 C.
2.②处应填( )
A.in[a[cur]]!=0||w==1
B.in[a[cur]]==0||w==0
C.in[a[cur]]!=0||w==0
D.in[a[cur]]==0||w==1
当这个结点(cur)的关注者(a[cur])关注的人数已经清零(注意这里的清零可能是被去掉但没被删除),那么可以传入看看a[cur]是否可以删除;
若这个结点已经被删除(\(w=1\)),那么这个结点的关注者一定不能被删除,便可以传入进行标记并去掉。
故选 D.
3.③处应填( )
A.0
B.1
C.w
D.1-w
这里要与上一题结合起来,有以下两种情况:
- 这个结点已经被删除(\(w=1\)),那么这个结点的关注者一定不能被删除,所以我们要使传入的 \(w\) 为 0
- 这个结点的关注者关注的人数已经清零,那么有以下两种情况:
- 清零的所有操作中存在删除操作,即存在 \(w=1\) 的情况,那么显然在删除时便会符合第一种情况,需传入 \(w=0\);
- 清零的所有操作都是去掉而不是删除,即每一次 \(w\) 都为 \(0\),那么显然这个新结点可以被删除,需传入 \(w=1\);
综上,我们可以看出,每次传入时 \(w\) 的值要取反,那么符合的代码为1-w
故选 D.
4.④处应填( )
A.dfs(i,1)
B.dfs(i,0)
C.dfs(a[i],1)
D.dfs(a[i],0)
观察此循环中if语句的条件,当这个结点不是任何其他结点的关注者(这个结点关注的人数为0),那么我们可以直接将它删掉,故应传入 \(w=1\)
故选 A.
5.⑤处应填( )
A.!in[i]
B.in[i]
C.!vis[i]
D.vis[i]
这里就是把没有遍历到的点遍历完
#3.2 第2题
(烧作业)某课作业布置了N(3≤N≤100000)个题目,第i题对应的得分是ai。
作业的总得分的计算方式为去掉作业中得分最小的一个题,剩下其它所有题目得分的平均值。
但很不幸小A遇到了一场火灾,前K(1≤K≤N-2)个题目被烧了,无法记录得分。
小A想知道,K是多少时,可以得到最高的作业得分?
作业被烧了前K页,这时的得分是从第K+1页到最后一页中,去除最小得分后取平均值。
输入第一行是整数N,第二行是n个不超过10000的非负整数表示ai。
输出一行,若干个整数表示答案。如果有多个K,请依次升序输出。
#include <cstdio>
#include <cmath>
#define min(a,b) (a<b?a:b)
#define MAXN 100002
using namespace std;
int n, k[MAXN], cnt = 0;
int s[MAXN], minScore, sum;
double maxAverage = 0, nowAverage;
int main() {
scanf("%d", &n);
for(int i = 1; i <= n; i++)
scanf("%d", &s[i]);
minScore = s[n];
①;
for(int i = n - 1; i >= 2; i--) {
minScore = min(minScore, s[i]);
②;
nowAverage = ③;
if(nowAverage > maxAverage) {
④
maxAverage = nowAverage;
} else if(fabs(nowAverage - maxAverage) < 1e-6)
⑤;
}
for(int i = cnt; i >= 1; i--)
printf("%d\n", k[i]);
return 0;
}
1.①处应填( )
A.sum=n
B.sum=s[1]
C.sum=s[n]
D.sum=0
观察程序,显然是从最后一页开始,进行累加,所以初始值为sum=s[n]
故选 C.
2.②处应填( )
A.sum=maxAverage*(n-i)
B.sum+=s[i]
C.sum+=s[n-i]
D.sum=s[i]+minScore
这里是进行累加,显然是将 s[i] 的值加入 sum
故选 B.
3.③处应填( )
A.(double)(sum+minScore)/(n-i)
B.sum*1.0/(n-i)
C.(int)(sum-minScore)/(n-i)
D.(double)(sum-minScore)/(n-i)
读题,要求是去掉最小值,再取平均值,nowAverag的类型是double
故选 D.
4.④处应填( )
A.k[++cnt]=i;
B.k[cnt++]=i-1
C.cnt=1;k[cnt]=i-1;
D.cnt=0;k[cnt]=i;
当当前平均值大于以往最大平均值,我们要更新最大值,而 cnt 是计数,可能有多个相似的结果,所以我们要先将 cnt 置为 \(1\),再进行更新
故选 C.
5.⑤处应填( )
A.k[cnt++]=i;
B.k[++cnt]=i-1;
C.k[cnt++]=n-i;
D.k[cnt]=i;
当有近似值时增加可能的 \(k\) 值,但显然 cnt 在第一次将 \(k\) 存入时,并没有自增加,所以这里要先自加一
故选 B.
#4.0 补充说明
第11题排列组合不懂的朋友可以看一下下面这篇博客:
最后祝各位 \(CSP2020 \quad rp++\) !
更新日志及说明
更新
- 初次完成编辑 - \(2020.10.9\)
- 增添了 #2.2 阅读程序第2题第5小题 的模拟过程
添加了 #2.3 阅读程序第3题 - \(2020.10.10\)- 添加了 #3.0 补全程序 - \(2020.10.11\)
本文若有更改或补充会持续更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号