论文笔记(7)-"Local Newton: Reducing Communication Bottleneck for Distributed Learning"
Main idea
Authors demonstrated a second-order optimization method and incorporated the curvature information to reduce the communication cost.
Algorithm
They have proposed two algorithm: in the first algorithm, there is only once gradient direction computation, i.e., \(L=1\)
\(L\geq 1\) in the second algorithm, called adaptive Local Newton:

Assumption and convergence analysis
In their work, only the weighted function \(f\) is required to be \(M\) smooth and \(\kappa\) strongly convex and the norm of the local gradient \(\Vert \nabla f_i(x)\Vert\) is upper bounded.
Actually, they work on the homogeneous setting: local data sets comes from the same distribution and \(X_i\) is the submatrix of \(X\). Based on it, they manifested local function \(f_i\) is also \(M(1-\epsilon)\) smooth and \(\kappa(1+\epsilon)\) strongly convex (\(\textbf{Lemma 4.1}\)) with probability at least \(1-\delta\).
As they said the sketch of the proof is following:
- Reduce \(f(\bar{w}_{t+1})-f(\bar{w}_t)\) to \(\frac 1 K\sum_i f_i(w_{t+1}^i)-f_i(w_t^i)\)
- Bound \(f_i(w_{t+1}^i)-f_i(w_t^i)\leq -\varphi \Vert g_t^i\Vert^2\)(\(\textbf{Lemma A.2}\))
- local gradient \(g_t^i\) is closed to\(g_t\) by perturbed iterate analysis

conclusion
-
The underlying homogeneous assumption is impractical in federated learning.
-
For DL, solving the hessian matrix is difficult and approximation is more applicable.
-
At last, I want to briefly introduce the Giant: At first, the server will broadcast the weighted gradient \(g\) to users to compute local Hessian matrix.
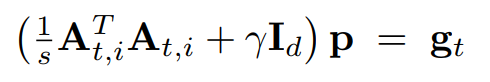

 浙公网安备 33010602011771号
浙公网安备 33010602011771号