研零学习笔记
前言
博客的目录很有用,可以快速检索想要看的学习笔记,也可以直接把目录当缩写字典用。
希望论文部分能做成可以直接扔到组会周报上用的东西。
一、关键概念与缩写
1. IoU(Intersection over Union)
交并比,它衡量两个边框(或区域)重叠得有多好——也就是预测框与真实框的重合程度,是许多目标检测模型的核心指标之一。
IoU = 交集面积 ÷ 并集面积
具体到算法实现计算:
设预测框为\((x_1^{(p)},y_1^{(p)},x_2^{(p)},y_2^{(p)})\),真实框为\((x_1^{(g)},y_1^{(g)},x_2^{(g)},y_2^{(g)})\)。
则交集坐标:
交集和并集面积:
交并比IoU即为:
有些模型会使用IoU的改进版本,例如GIoU解决了当两个框不相交时IoU = 0,梯度无法提供有用方向的问题。GIoU在IoU基础上增加了“惩罚框未重叠的距离”,公式为:
其中\(C\)是包含预测框和真值框的最小外接矩形。
2. GT(Ground Truth)
3. O2O(One to One)& O2M(One to Many)
4. AP(Average Precision)
在目标检测任务中常用的评价指标是,用于衡量模型在不同阈值下的检测性能。AP 指标通常结合 精度(Precision) 和 召回率(Recall) 来计算:
表示模型预测为正的样本中,有多少是真正的正样本。
表示所有真实正样本中,有多少被模型正确预测。
AP 是 Precision-Recall 曲线下的面积(AUC),反映模型在不同置信度阈值下的整体性能:
其中 \(P(r)\) 表示在召回率 \(r\) 时的精度。AP 衡量模型在不同置信度阈值下精度和召回率的整体表现,值越大表示模型性能越好。
AP包含一些变体:
-
\(AP_{50}\) 与 \(AP_{75}\) 引入了IoU阈值:
- \(AP_{50}\):IoU ≥ 0.5 时算作 True Positive(TP),表示在较宽松匹配条件下的平均精度。
- \(AP_{75}\):IoU ≥ 0.75 时算作 TP,表示在严格匹配条件下的平均精度。
-
\(AP_{S}, AP_{M}, AP_{L}\)
这些指标用于衡量模型在不同目标尺寸上的性能:- \(AP_{S}\)(Small):小目标的 AP,COCO 定义面积 < \(32^2\) 像素
- \(AP_{M}\)(Medium):中等目标的 AP,面积在 \(32^2 \le \text{area} < 96^2\)
- \(AP_{L}\)(Large):大目标的 AP,面积 ≥ \(96^2\)
这种划分可以分析模型在不同尺度目标上的检测能力,通常小目标最难检测。
-
在 COCO 评测中,常用 mAP 指标,即 AP@[0.5:0.95],在 IoU 从 0.5 到 0.95(步长 0.05)之间取平均,全面衡量模型性能。
5. MOT(Multiple Object Tracking)
多目标追踪,工作的核心概念,做一篇详细的笔记。
MOT的核心目标是在视频里持续识别并跟踪多个目标,让每个目标在时间上“保持身份 ID 不变”。一般来说,MOT 要解决两个关键问题:
-
检测:每一帧找到所有目标(行人、车辆等)。
-
关联(Association):将当前帧的目标与上一帧同一目标的轨迹匹配,让 ID 保持一致。
因此,MOT的主流范式也是先检测,再关联(即Tracking-By-Detection(TbD)这一传统方法)。当然也存在不区分这两步直接进行端到端的Transformer MOT,目前我的工作还是考虑TbD。
上面的检测与关联两步具体而言可以包括这些工作:
-
目标检测(Detector):给视频每帧图像使用Yolo、DETR系列、RF-DETR等输出检测框;
-
运动建模(Motion Model):预测目标下一帧位置,让关联更稳,如卡尔曼滤波方法;
-
特征提取(Appearance Embedding):使用ReID或CNN Backbone方法为检测框提取一个特征向量;
-
数据关联(Data Association):一般使用匈牙利算法计算帧间框特征的最小代价匹配来进行目标关联,一般关联依据包括IOU(框的重叠度)、卡尔曼滤波预测距离、外观 embedding 相似度(余弦距离)等;
-
维护轨迹(Track Management)。
目前常用的密集场景下的MOT数据集为MOT17/20。数据集包含若干视频图像帧序列以及三个检测器(DPM、FRCNN、SDP)的检测结果,训练集有GroundTruth。
以MOT17为例,其目录结构如下:
MOT17/
├── train/
│ ├── MOT17-02-DPM/
│ │ ├── img1/ # 所有视频帧
│ │ ├── det/ # 检测器提供的 detections
│ │ ├── gt/ # ground truth
│ │ └── seqinfo.ini # 视频信息(帧率、分辨率、帧数)
│ ├── MOT17-04-FRCNN/
│ └── ...
└── test/
├── MOT17-01/
├── ...
其检测结果和GT的格式如下(每个框一行):
frame, id, x, y, w, h, score, class, visibility
含义如下:
- frame:属于第几帧
- id:目标ID(检测器提供的det中固定为-1,因为还未做关联)
- x, y, w, h:框位置,以左上角坐标+宽高表示,数值为像素而非比例
- score:检测置信度,GT中固定为1
- class:类别,固定为1,因为只是行人数据集
- visibility:可见度,在det中为固定值,GT中为0-1的浮点数,表示被遮挡程度
二、论文
1. DETR(DEtection TRansformer)
论文:End-to-End Object Detection with Transformers。
学习笔记搬了一些这篇博客的。
DETR 通过引入 Transformer ,将目标检测任务视为集合预测问题,首次实现了端到端的目标检测(整个检测流程从输入图像到最终预测框的生成,完全由一个可微的神经网络自动完成,不需要任何手工启发式步骤),无需NMS后处理和anchor设计(相较于 YOLO ),显著简化了模型训练和部署流程。论文的核心贡献包括设计了基于二分图匹配的目标函数,确保输出的独特性,并通过 Transformer 的 encoder-decoder 架构实现了高效的目标检测。
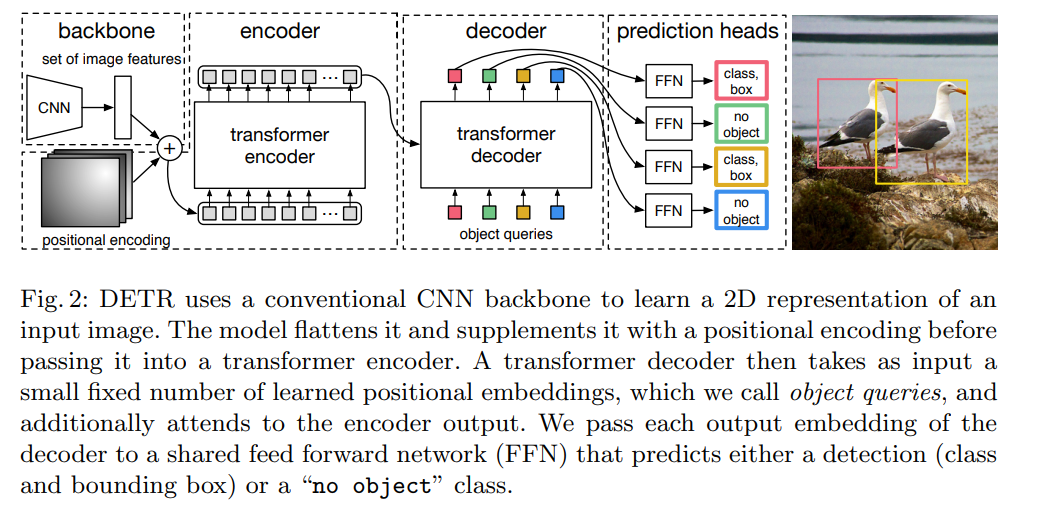
如上图所示, DETR 框架的大致流程为:
- CNN 提取特征(其中 Backbone 可采用 ResNet50 或 ResNet101 ,相应的模型分别称为 DETR 和 DETR-R101 ;
- 特征拉直,送到 encoder-decoder 中,encoder 进一步学习全局信息,为接下来的 decoder 最后出预测框做铺垫;
- decoder 生成框的输出,当你有了图像特征之后,还会有一个 object query (限定了共有多少输出框,本方法中输出框限定为 \(N\) 个, \(N\) 需要远大于目标数量,文中取 \(N=100\) ),通过 query 和特征在 decoder 里进行自注意力操作,得到输出的框;
- loss 计算,通过二分图匹配,计算 100个 预测的框和 2 个 GT 框的 matching loss ,决定100个预测框哪两个是独一无二对应到红黄色的 GT 框,匹配的框去算目标检测的 loss 。
上述的是 DETR 训练的步骤,而在 DETR 的推理过程中,步骤1、2、3一致,步骤4不需要,直接在最后的输出上用一个阈值卡一个输出的置信度,置信度比较大保留。
DETR 的主要特色在于步骤4,它将目标检测视为一个 “集合预测” 问题,通过二分图匹配得到一个可训练的 Loss 。具体而言:
-
令 \(\hat{y}=\{\hat{y}_i\}_{i=1}^N\) 为模型输出的 \(N\) 个预测(每个预测均包含类别概率分布与归一化边框,即 \(\hat{y}_i=(\hat{p}_i,\hat{b}_i)\) ,其中 \(\hat{b}_i\in[0,1]^4\) );
-
令 \(y=\{y_j\}\) 为该图的GT集合,为了方便O2O匹配,将GT集用特殊类(∅)填充至长度 \(N\) ,预测匹配到特殊类即表示该预测被废弃不用,不出现在最终预测输出内;
-
构建代价矩阵,对每一对 \((y_i,\hat{y}_j)\) 计算配对代价 \(\mathcal{L}_{\text{match}}(y_i,\hat{y}_j)\);
-
现在我们的目标是寻找一个配对方案使得总体配对代价最小,即
\[\hat{\sigma} = \arg\min_{\sigma\in S_N} \sum_{i=1}^{N} \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)}) \]显然这是一个一对一指派问题,可以用匈牙利算法求解,时间复杂度\(O(n^3)\)(匈牙利求解指派问题可以看这篇博客)。
上面的式子中
\[\mathcal{L}_{\text{match}}(y_i,\hat{y}_j) = -\mathbf{1}_{\{c_i\neq \varnothing\}}\,\hat{p}_j(c_i) + \mathbf{1}_{\{c_i\neq \varnothing\}}\,\mathcal{L}_{\text{box}}(b_i,\hat{b}_j) \\ \mathcal{L}_{\text{box}}(b,\hat{b}) =\lambda_{\text{iou}}\cdot L_{\text{GIoU}}(b,\hat{b})+ \lambda_{L1}\cdot \|b-\hat b\|_1 \]即一个匹配造成的代价包括分类代价和框代价\(\mathcal{L}_{\text{box}}(b,\hat{b})\)(显然这和一个预测的组成是对应的),其中框代价又使用了 GIoU 和 L1 的线性组合。
-
得到最优匹配 \(\hat\sigma\) 后,我们就可以计算用于反向传播的损失了(论文称为 Hungarian loss):
\[\mathcal{L}_{\text{Hungarian}}(y,\hat{y}) = \sum_{i=1}^N \Big[ -\log \hat{p}_{\hat\sigma(i)}(c_i)+ \mathbf{1}_{\{c_i\neq\varnothing\}}\,\mathcal{L}_{\text{box}}(b_i,\hat{b}_{\hat\sigma(i)}) \Big] \]

论文训练得到的模型在COCO数据集上效果较好,但是在小目标检测上仍面临挑战。
2. DEIM(DETR with Improved Matching for Fast Convergence)
论文:DEIM: DETR with Improved Matching for Fast Convergence。
DETR 存在两个主要问题:
- O2O 匹配机制为每个目标仅分配一个正样本,极大地限制了正样本数量;
- DETR 采用少量(\(N=100\))随机初始化的查询。这些查询与目标缺乏空间对齐,导致训练中出现大量低质量匹配,即匹配框与目标的交并比 IoU 较低但置信度分数较高的情况。
这两个问题导致 DETR 仍存在监督稀疏、收敛速度缓慢的缺陷。
DEIM 提出了一套训练框架,通过尝试解决上述两个问题显著加快了 DETR 系列在实时检测任务上的收敛速度并提升最终精度。
-
针对问题一,DEIM 提出了 Dense O2O 策略,该策略保留了 O2O 的一对一匹配结构,但通过一些简单的手段增加了每张图像的目标数,实现了更密集的监督。例如如下图所示, DEIM 方法将原始图像复制为四个象限,并将它们组合成一张合成图像,同时保持原始图像尺寸。这将目标数从1增加到4,实现了与O2M相当的监督水平,同时保持了匹配结构不变,且无需增加复杂性和计算开销。
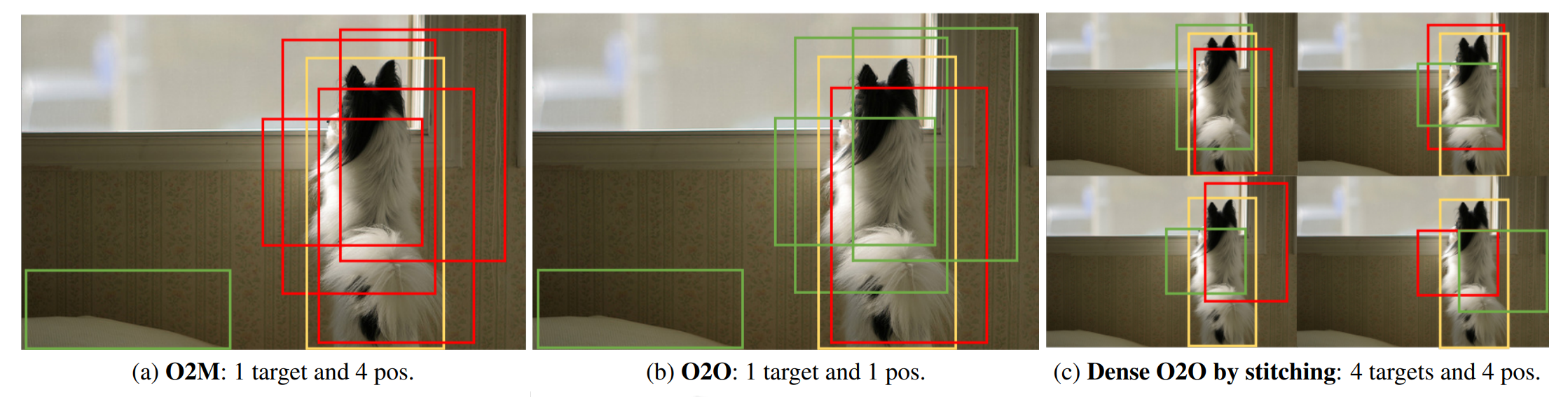
具体到实验中,DEIM 采用了两种数据增强手段,分别是如上图所示的图像拼接方法(Mosaic)和把两张图以某比例叠加的方法(Mixup),两种方法均有效增加了正样本数量。
-
针对问题二,DEIM 提出了一种新的损失:匹配感知损失(Matchability-Aware Loss, MAL)。
DETR 使用的损失计算方法是面向 IoU 的 VariFocal Loss (VFL),在 DETR 中,它可表示为:
\[\text{VFL}(p, q, y) = \begin{cases} - q ( q \log(p) + (1 - q) \log(1 - p) ), & q > 0 \\ - \alpha p^\gamma \log(1 - p), & q = 0 \end{cases} \]其中, \(q\) 表示预测边界框与其目标框之间的 IoU 。对于前景样本(\(q>0\)),目标标签设为 \(q\) ;对于背景样本(\(q=0\)),目标标签为0。
然而, VFL 在优化低质量匹配时存在两个关键局限性:
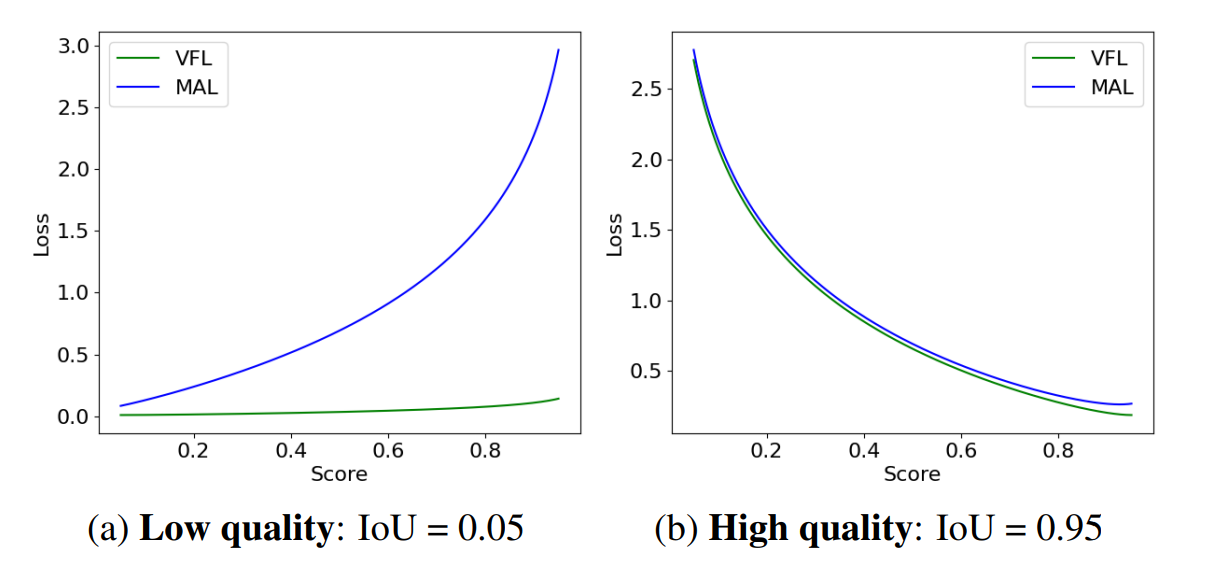
- 低质量匹配: VFL 主要关注高质量匹配(高 IoU )。对于低质量匹配(低 IoU ),损失仍然较小,模型无法优化低质量边界框的预测(如下图所示);
- 负样本: VFL 将无重叠的匹配视为负样本,这减少了正样本数量,限制了有效训练。

为解决这些问题,DEIM 提出了 MAL ,这种损失将匹配质量直接纳入损失函数,使其对低质量匹配更敏感。 MAL 的公式为:
\[\text{MAL}(p, q, y) = \begin{cases} -q^\gamma \log(p) - (1 - q^\gamma)\log(1 - p), & y = 1 \\ -p^\gamma \log(1 - p), & y = 0 \end{cases} \]与 VFL 相比, MAL 将 IoU 权重项从 \(q\) 调整到 \(q^\gamma\),这样在低 IoU 的样本上 MAL 相比 VFL 会给出更大的梯度,加快训练效率;而在高 IoU 区域,MAL 与 VFL 表现相似,不影响高质量匹配的性能。
3. RF-DETR(NEURAL ARCHITECTURE SEARCH FOR
REAL-TIME DETECTION TRANSFORMERS)
论文:RF-DETR: Neural Architecture Search for Real-Time Detection Transformers
近年来最先进的视觉语言模型(如 GroundingDINO )在在COCO等标准数据集上取得了惊人的零样本检测效果,但是遇到其预训练中通常不包含的类别、任务和成像模态时,仍然难以实现良好的泛化能力。将 VLM 在目标数据集上进行微调可以显著提升域内性能,但会牺牲运行效率(因为引入了重量级文本编码器)以及开放词汇泛化能力。为了解决这一问题,论文提出了 RF-DETR。
它在总体设计思路上有如下改进:
-
利用互联网规模预训练模型(DINOv2)作为 backbone 保证模型的泛化能力;
-
设计了一个轻量级实时实例分割头使其能够支持分割任务(称为 RF-DETR-Seg)
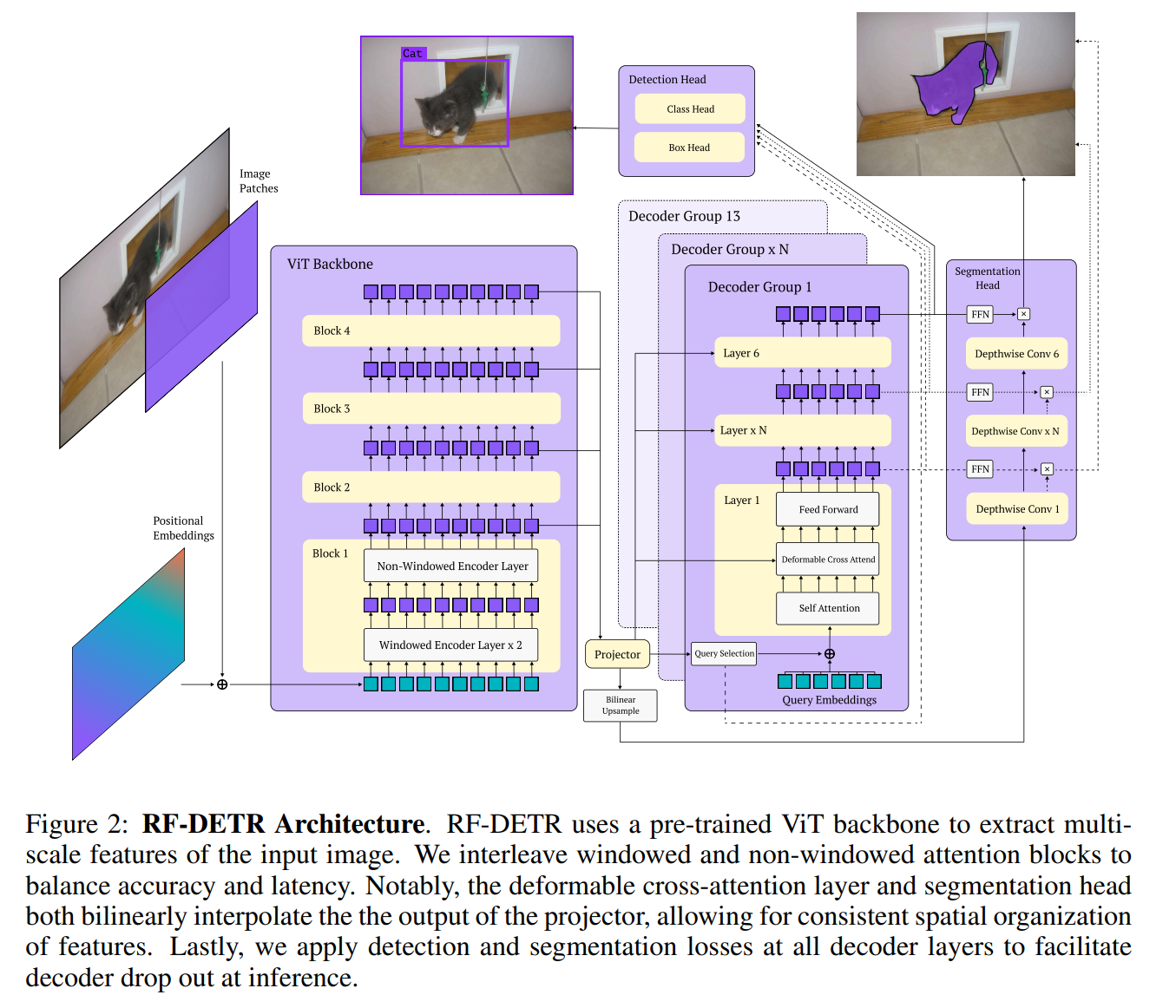
-
核心:设计了一种可调模型架构(端到端神经架构搜索,End-to-End Neural Architecture Search),可调组件包括:
-
patch size:更小的Patch能捕捉更精细的特征,提升精度,但计算量更大。
-
decoder 层数:解码器层数越多,通常性能越好,但延迟也越高。RF-DETR通过对所有 decoder 层的输出均施加回归损失,可以在推理时“丢弃”任意数量的解码器层,从而灵活控制速度。
-
query token 数量:Query的数量决定了模型一次最多能检测出多少个物体。在推理时可以根据置信度丢弃多余的Query,减少计算。
-
图像分辨率:高分辨率图像有助于检测小目标,但更耗时。
-
window attention 中的窗口数:窗口注意力将自注意力计算限制在局部区域,调整窗口数量可以平衡全局信息交互和计算效率。
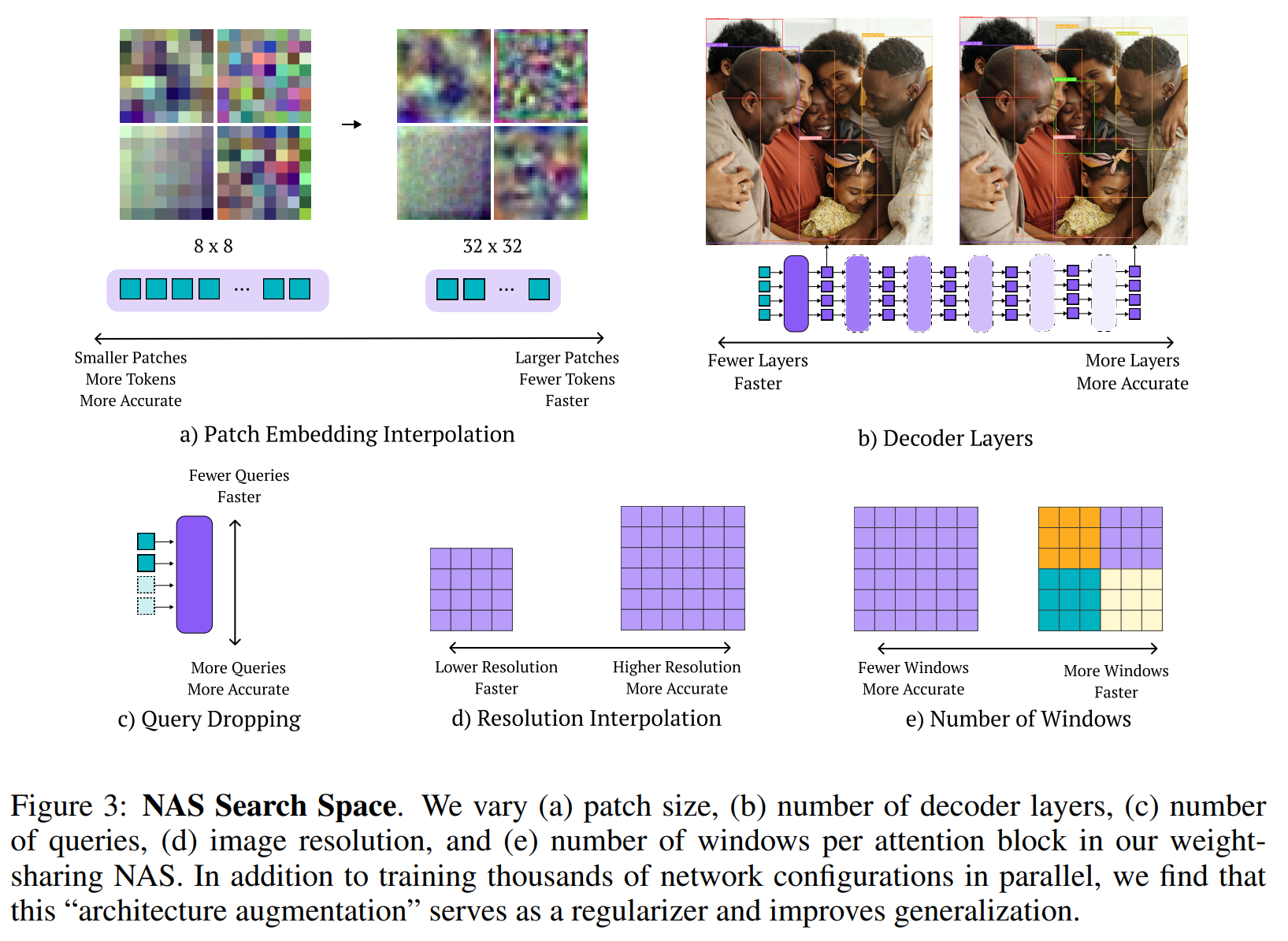
-
在每次训练迭代中,NAS方法会随机均匀采样一个模型配置,并基于该配置进行一次梯度更新。这允许模型类似于 dropout 中的“并行训练多个子网络”,从而高效训练由于5个组件的不同衍生出的数千个子网络。最终测试发现即使只是引入权重共享NAS的训练机制,而不改变最终模型的固定架构,其性能相比于直接训练该固定架构也有所提升。这说明“架构增强”本身就是一种有效的正则化方法。
在推理阶段可以用户配置更合适的五种组件参数来选择最终模型(一般考虑其在具体任务上的准确率-延迟曲线)。
最终该模型在COCO和更具挑战性的、包含100个不同真实世界场景的Roboflow100-VL数据集上都有比较出色的表现。
4. SAM 3: Segment Anything With Concepts
SAM系列提出了可提示分割(promptable segmentation)任务,通过交互式提示来在图像和视频中分割物体,其中提示可以是视觉输入(如点、框、掩码标记某个特定目标)或文本描述目标的输入。然而,SAM1和SAM2聚焦于视觉提示,并且每次提示只能分割单个物体实例。因此,论文提出了SAM3,在SAM2的“可提示视觉分割”(Promptable Visual Segmentation,PVS)上进一步提出了 “可提示概念分割” 任务(Promptable Concept Segmentation,PCS),并将其定义为“给定文本和/或图像示例作为输入,预测所有与该概念匹配的物体的实例掩码和语义掩码,并在视频中保持对象身份一致性”。由于SAM3专注于识别基础视觉概念,因此文本被限制为简单名词短语(noun phrases,NP),例如“红苹果”“条纹猫”。

SAM3的架构大体基于SAM和DETR系列。如图展示了它的结构:
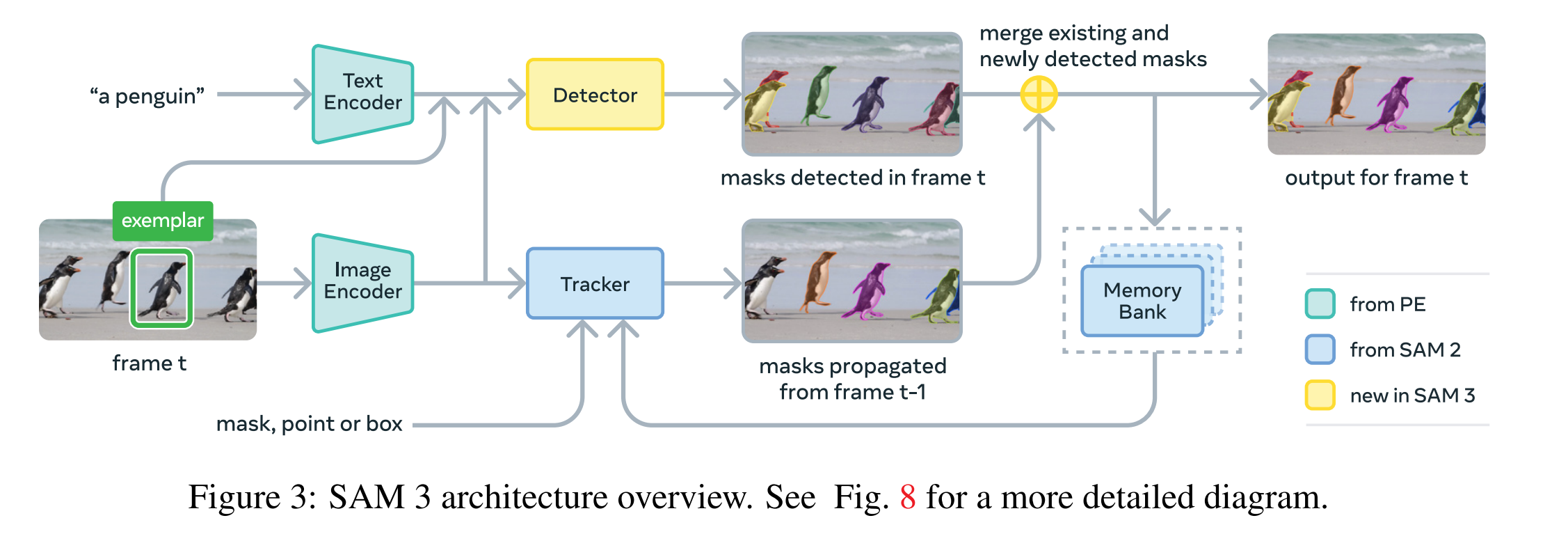
它包含一对编码器-解码器 Transformer —— 用于图像级功能的detector和视频跟踪器tracker。检测器和跟踪器从一个对齐的感知编码器(Perception Encoder, PE)backbone接收视觉-语言输入。
其中检测器部分使用融合 Transformer 对图像特征和提示 token 进行 cross-attention,实现基于提示的目标检测与分割。引入 presence token 解耦识别与定位(也就是先判断某概念在图像中是否存在再进行后续工作),大幅提升匹配精度。图像示例作为额外的 prompt,可用于交互式增删目标。
跟踪器部分采用 SAM 2 风格的 masklet 传播,通过 memory bank 存储目标的外观特征,并在每帧预测新的 masklet 位置。论文中用公式表示为:
基于上面所述的结构,其训练过程为:
-
PE(Perception Encoder)预训练
-
检测器预训练
-
检测器微调(fine-tuning)
-
冻结 backbone 后训练跟踪器
论文表示SAM 3 在可提示分割(PCS)任务上取得了显著的 SOTA 表现:在LVIS数据集上的零样本 mask AP 提升至 47.0(相比此前最佳的 38.5),在论文提出的 SA-Co 新基准上整体达到至少 2 倍的领先优势,并在视频分割任务(PVS)上也明显优于 SAM 2。SAM 3 推理效率也很高:在H200 GPU上对单图(含 100+ 检测对象)推理仅需30 ms,视频中延迟随对象数线性增加,约5个对象时可接近实时运行。
5. Human Semantic Parsing for Person Re-identification(SPReID)
1. 论文内容
这个论文提出了 SPReID(Semantic Parsing ReID),核心思想是:不再用人工划分的 bounding box 局部,而是用语义分割得到的“人体部件掩码”来引导特征学习。
关键点包括:
- Backbone 使用 标准 Inception-V3
- 引入 Human Semantic Parsing Network(HSP) 作为辅助分支
- 利用语义分割结果对特征图进行 部件级加权聚合(part-aware pooling)
于是形成了如下图所示的网络结构:
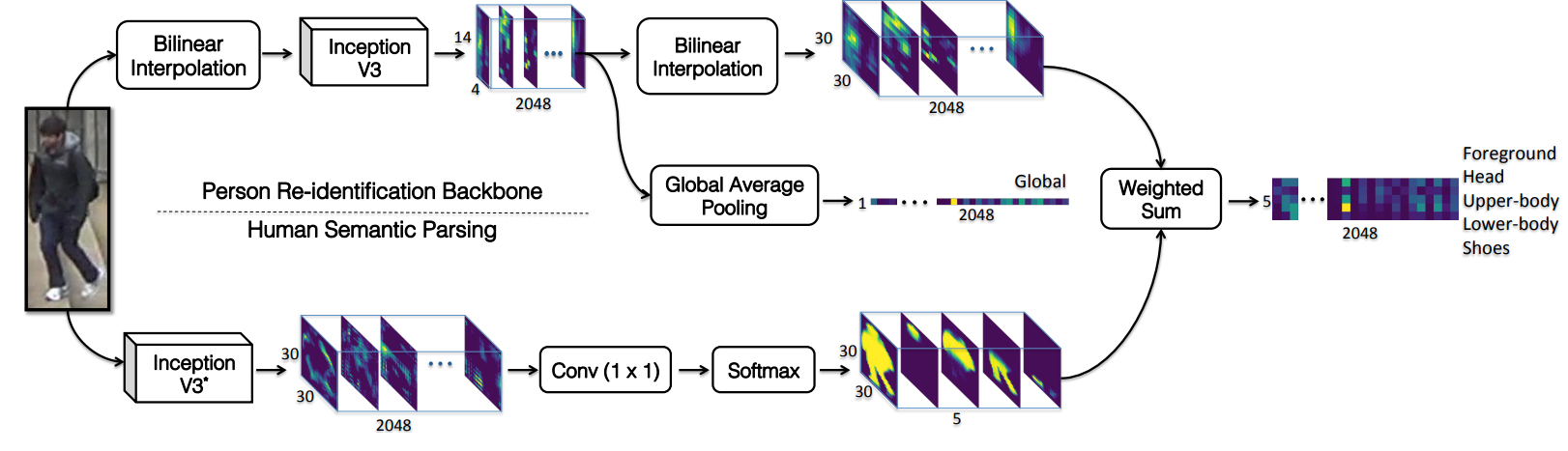
它形成了两条分支,上面一路是直接调用标准 Inception-V3 的特征提取网络,下面一路是使用它们项目改造的变种 Inception-V3 做的语义分割,在像素级上预测 foreground、head、upper-body、lower-body 和 shoes 五类语义概率图。随后,这些概率图被用作权重,对 ReID 主干输出的特征图进行 按语义区域的加权求和(weighted sum),从而得到对应于不同人体部件的特征向量。最后,论文对部分身体部件特征进行融合,并与全局特征拼接,形成最终的行人特征。
论文声称该方法缓解了 MOT 任务中的遮挡、背景干扰和姿态变化导致的 ReID 问题。经试验,该方法在 Market-1501、CUHK03、DukeMTMC-reID 上都取得了显著提升,达到了当年的 SOTA 水平。
2. 与毕设关联和启发
该论文在主要的思想上和我的毕设内容是比较相似的,但是该方法仍存在一些问题:
- 在人员拥挤的场景下容易出现遮挡检测主体目标的是其他行人的情况(比如上面有张图),此时检测框中会出现两个都具有完整语义特征的人,SPReID 会把两个人的像素一起当作同一语义区域,从而导致后续的部件级 pooling 会把两个身份的特征混在一起;
- SPReID 将人体划分为固定的五类语义区域,这种划分方式是在特定人工标注的语义分割数据集上训练得到的。一旦希望引入更精细或不同语义层级的部件(例如更细粒度的服饰区域等),就需要重新构建和标注对应的人体语义分割数据集,并重新训练分割模型,成本较高且扩展性受限。
而这两个问题都可以通过 SAM3 的带语义提示分割、SAM3 比较强大的 zero-shot 能力以及动态的部件选择机制解决。同时该论文的按部件对特征进行加权以及特征 flatten 之后组合形成一个最终特征的处理方式也能对我的毕业论文后面的部件级 embedding 提供方法上的指导。可以说这篇论文既给我的毕设提供了更充分的动机,同时提供了方法上的启发,可以作为一篇比较核心的参考文献。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号