当当网爬虫
当当网爬虫
利用python的requests 库和lxml库,来爬取当当网的图书信息,包括图书名称,图书购买页面url和图书价格,本次以爬取python书籍为例
1、确定url地址
进入当当网,搜索python书籍,得到如下
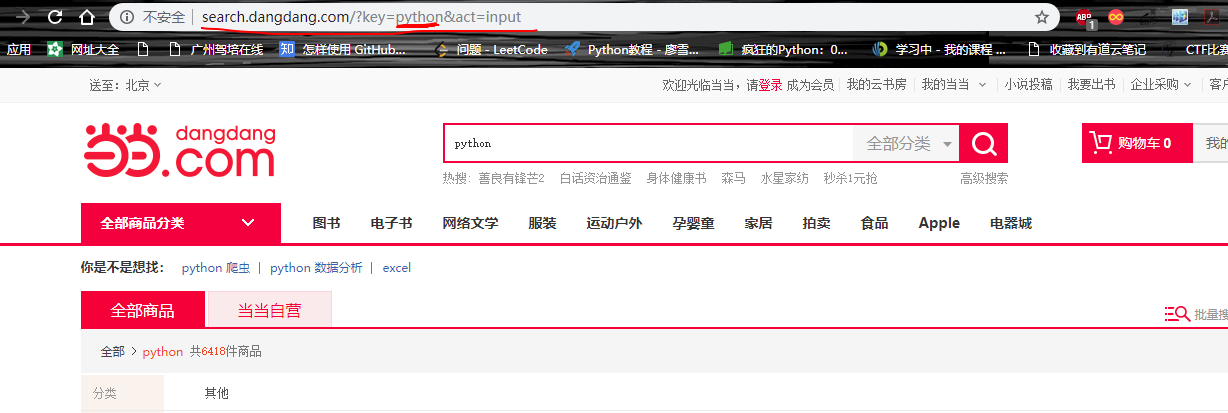
所以可以知道,当你搜索书籍时,书籍的名字会放在key的后面

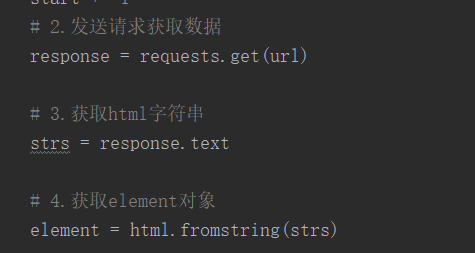
2、获取地址后,就发送请求获取数据,再返回element对象
3、在Chrome上进行元素检查
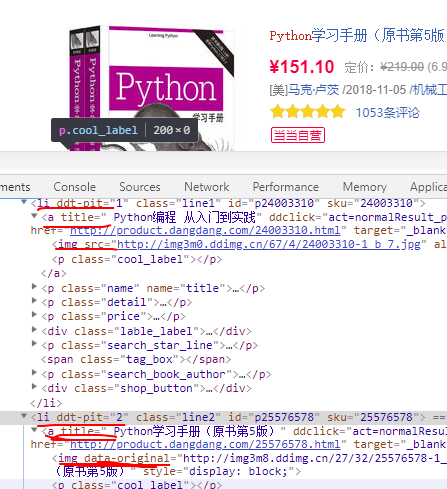
发现每本书都在一个li下,每本书的节点是一个 a 标签,a 标签具有 title,href,price三个属性,这三者分别对应书名、书的链接页面和书的价格,得到了解析规则,就可以写代码了,注意,因为发现有些书是电子书,电子书的class="ebook_buy",而还有一些书籍是根本没有价格的,所以要进行判断,否则会报错
### 4、爬取下一页的内容
对下一页的按钮进行元素检查
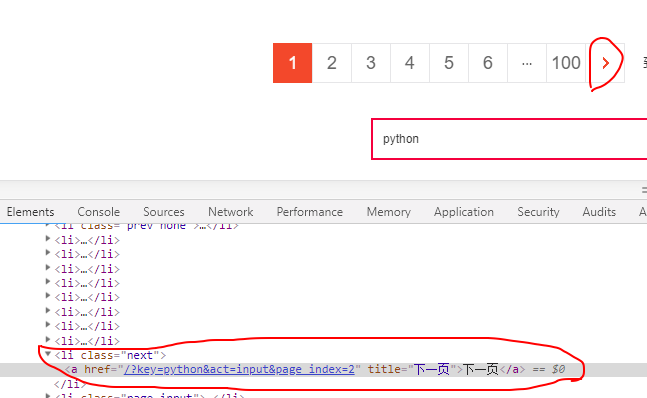
从上面的图片中,我们发现 URL 地址的差异就在于 page_index 的值,所以 URL 地址最终为 http://search.dangdang.com/?key=python&act=input&&page_index=。而 page_index 的值,我们可以通过循环依次在地址后面添加,然后进行拼接

5、保存爬下来的信息
将爬下来的东西进行放在book.txt文件下

结果:

完整代码
import requests
from lxml import html
name = input('请输入要搜索的图书信息:')
# 1.准备url
url = 'http://search.dangdang.com/?key={}&act=input'.format(name)
start = 1
while True:
print('正爬取第' + str(start) + '页信息')
start += 1
# 2.发送请求获取数据
response = requests.get(url)
# 3.获取html字符串
strs = response.text
# 4.获取element对象
element = html.fromstring(strs)
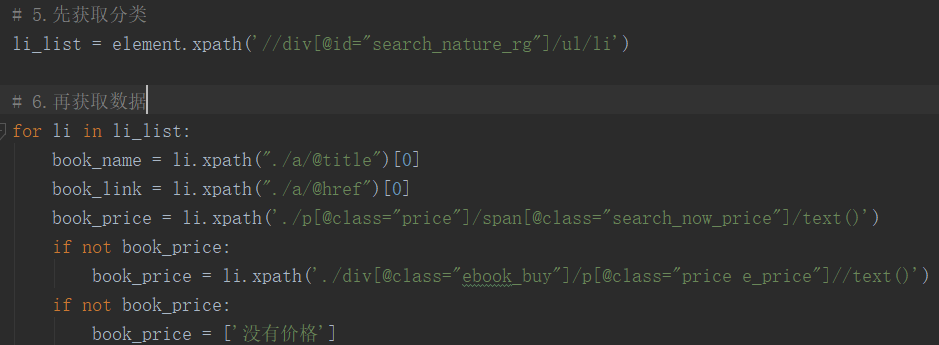
# 5.先获取分类
li_list = element.xpath('//div[@id="search_nature_rg"]/ul/li')
# 6.再获取数据
for li in li_list:
book_name = li.xpath("./a/@title")[0]
book_link = li.xpath("./a/@href")[0]
book_price = li.xpath('./p[@class="price"]/span[@class="search_now_price"]/text()')
if not book_price:
book_price = li.xpath('./div[@class="ebook_buy"]/p[@class="price e_price"]//text()')
if not book_price:
book_price = ['没有价格']
with open('book.txt', 'a', encoding='utf8') as f:
f.write(book_name.strip() + "\n" + book_link + "\n" + book_price[0] + "\n\n")
try:
# 爬取下一页
a_url = element.xpath('//li[@class="next"]/a/@href')[0]
url = 'http://search.dangdang.com' + a_url
except:
print('完成,共爬取了' + str(start - 1) + '页,请在book.txt中查看')
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号