首先看HashMap存储结构
transient Node<K,V>[] table; static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } /* …… */ }
我对存储结构的理解
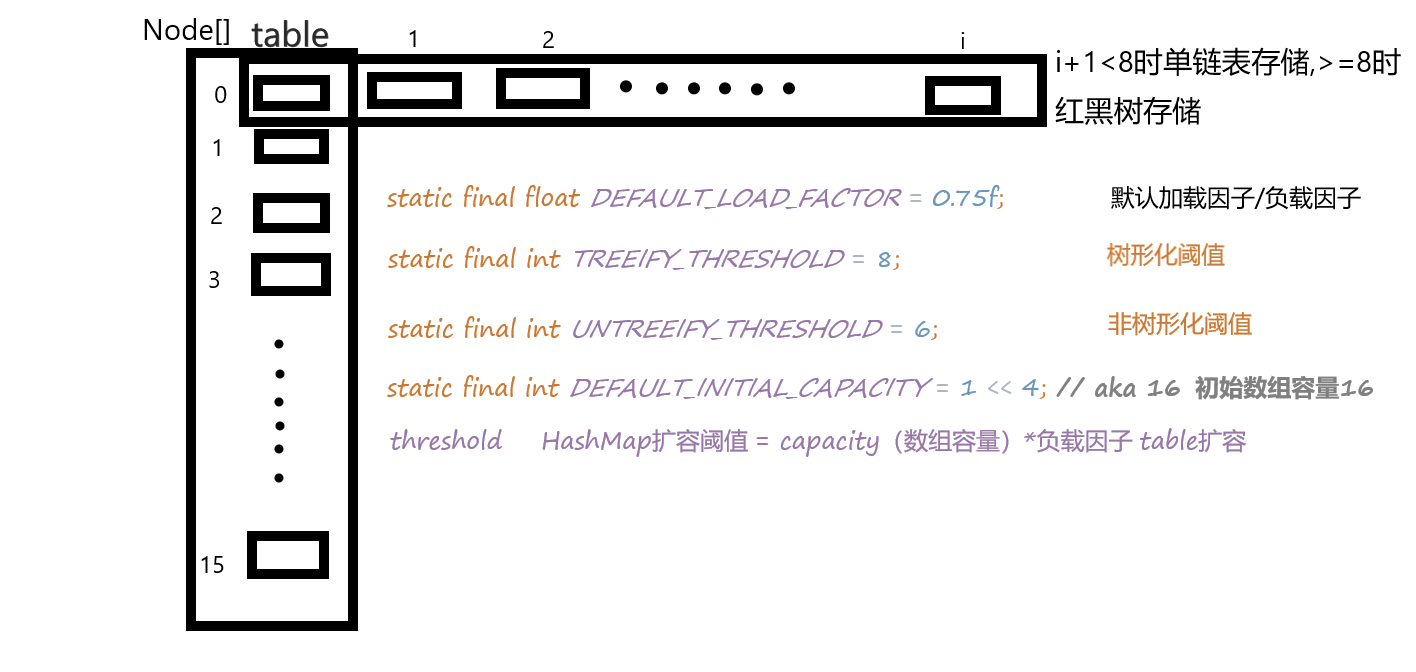
初始化一个长度为16的Node数组,数组中每一个元素是一个Node构成的单链表,好像是大家说的桶?当桶中Node结点长度(链表长度)大于等于TREEIFY_THRESHOLD (8)时 单链表改为 树(红黑树?现在还一点不了解,知道个名字) 存储 ,当桶中Node结点长度(链表长度)小于等于UNTREEIFY_THRESHOLD (6)时,树形结构转换为单链表存储
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
putVal 参数 分别为 key的哈希值,key值,value值,onlyIfAbsent true表示只有在该key对应原来的value为null的时候才插入,也就是说如果value之前存在了,就不会被新put的元素覆盖,false相反,evict //evict if false, the table is in creation mode. 这个是源码中的注释,true的话就不是creation mode?看园里大佬zju_jzb的博说
用于LinkedHashMap中的尾部操作,这里没有实际意义 传送门 https://www.cnblogs.com/jzb-blog/p/6637823.html
new HashMap<>()进行put时
先对table=null 和 table.length = 0 的情况进行处理 执行resize方法默认构造一个长为16的Node数组
再根据hash值 (table.length - 1) & hash 计算出put 的桶的下标
若该元素为空 newNode(hash, key, value, null); 创建一个单链表的“头”结点
若该元素不为空
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;
如果第一个元素key与put的key相同时,将第一个元素引用赋值给要put的新结点e
else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
如果第一个元素 是 TreeNode类型时,说明已转换为树形结构存储,插入到树中
else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } }
如果第一个元素与要put元素不同,而且此时也仍是单链表结构存储的话,遍历链表。找到后又分三种情况
第一种情况时,插入后链表长度达到8,需要转化为树形结构。
第二种情况时,插入后链表长度小于8,仍然是链表存储。
第三种情况时,链表中遍历到相同key值的结点,获得该结点的引用
if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } }
对已存在key的value进行覆盖 返回put之前key所对应的值
++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null;
modCount是对HashMap结构改变次数的记录(插入删除)
若put一个元素后 需要对Node[] table进行扩容 就扩容
putVal 方法走到这里时已经说明 HashMap中不存在和要put的Key相同的Key 返回null
afterNodeInsertion方法还不了解
看了一天了 感觉对HashMap的大致结构有一定的了解了 但是还有很多疑问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号