吴恩达深度学习笔记(七) —— Batch Normalization
主要内容:
一.Batch Norm简介
二.归一化网络的激活函数
三.Batch Norm拟合进神经网络
四.测试时的Batch Norm
一.Batch Norm简介
1.在机器学习中,我们一般会对输入数据进行归一化处理,使得各个特征的数值规模处于同一个量级,有助于加速梯度下降的收敛过程。
2.在深层神经网络中,容易出现梯度小时或者梯度爆炸的情况,导致训练速度慢。那么,除了对输入数据X进行归一化之外,我们是否还可以对隐藏层的输出值进行归一化,从而加速梯度下降的收敛速度呢?答案是可以的。
3.Batch Norm,即基于mini-batch gradient descent的归一化,将其应用于深层神经网络。
二..归一化网络的激活函数
1.一般地,我们并非对a[0](a[0]即输入值X)、a[1]、a[2]……等进行归一化,而是对z[1]、z[2]……等进行归一化(没有z[0])。
2.对于第l层的某个batch数据,计算出z[l]的均值和方差,然后对其进行归一化,使其均值为0,方差为1:
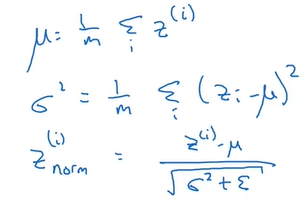 (注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
(注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
3.但是,我们不总希望隐藏单元总是含有均值为0,方差为1,也许隐藏单元有了不同的分布会有意义。(这里没能想明白,大概的意思是:如果总是“均值为0,方差为1”,那么深层神经网络的表示能力就减弱。)所以就再对其进行缩放和平移:

其中,β、γ是需要学习的参数。所以总的来说,需要学习四类参数:w、b、β、γ。
三.Batch Norm拟合进神经网络
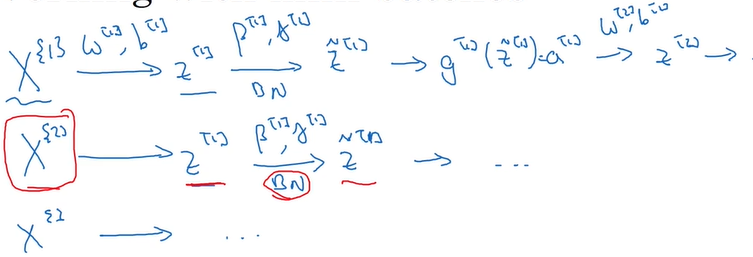
1.在一次梯度下降中(用的batch可能不同),z[1]、z[2]……的均值和方差可能一直在变化,所以对于第l层,需要重新计算z[l]的均值和方差,然后再对其归一化
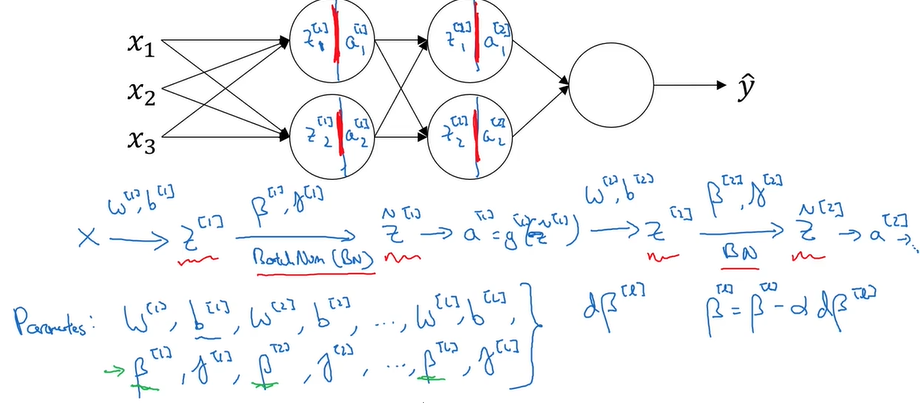
2.当进行了一次梯度下降之后,就利用下一个batch继续梯度下降(大括号标示batch):
四.测试时的Batch Norm
由于每一层中z的均值和方差在每一次梯度下降时都是变化的(与平常的机器学习的不同,机器学习中只需对输入数据X进行归一化,X的均值和方差是恒定的),所以在测试时,用哪个均值和方差进行归一化就成了一个问题。
解决方法是:在训练的过程中,利用指数加权平均去追踪和计算,最终得到用于测试数据的均值和方差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号