【推荐算法】单目标精排模型——Deep Crossing
这篇文章的模型是在广告推荐的背景下实现的。
- 预测任务:预测用户在给定查询中点击广告的可能性
一、研究动机
此前的特征交互是基于人工操作的,面对现如今大规模的特征很难再去人工生成大规模的交互特征。因此,这篇文章提出了Deep Crossing model,是将稠密和稀疏数据作为输入,自动交互特征的模型。
[!note]
作者提出了交叉特征的优越性,在kaggle比赛中最好的模型通常是融合了3-5个特征。
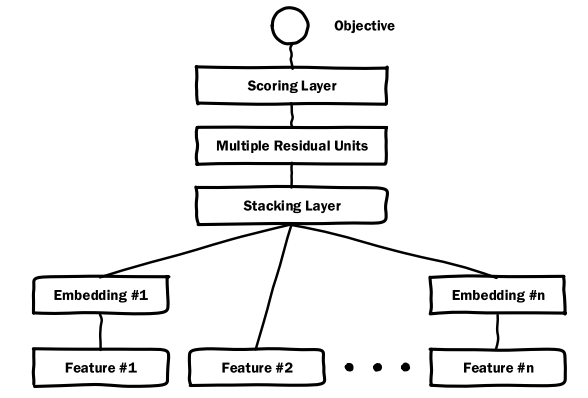
二、模型
- 模型架构主要包括了:
Embedding,Stackding,Residual Unit,Scoring Layer
- 损失函数:交叉熵损失
\[y=-\frac{1}{N}\sum_{i=1}^N (y_i\log(p_i)+(1-y_i)\log(1-p_i))
\]
- Embedding
目的是将高维稀疏特征降维。与
Word2Vec不同,Deep Crossing中的Embedding是模型的整体优化动态调整输入向量表达的权重。而当特征维度低于256时,则采取直接扩展的策略,直接输入到Stacking层,其中,max(0,f(x))表示ReLU激活函数
\[X_j^O=max(0,W_jX_j^O+b_j)
\]
- Stacking
直接对输入向量进行堆叠
三、Pytorch实现
- Redisual Unit
class ResidualBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(ResidualBlock, self).__init__()
self.fc1 = nn.Linear(input_dim, output_dim)
self.fc2 = nn.Linear(output_dim, output_dim)
self.layer_norm = nn.LayerNorm(output_dim)
def forward(self, x):
residual = x
x = F.relu(self.fc1(x))
x = self.fc2(x)
# 形状不同则表示是第一层,需要先映射到相同维度
if x.shape[1] == residual.shape[1]:
x = self.layer_norm(x + residual)
x = F.relu(x)
return x
- Embedding & Stacking
def __init__(self, sparse_feature_sizes, dense_feature_dim, embedding_dim=16):
# 处理高维特征的Embedding层
self.embedding_layers = nn.ModuleList([
nn.Embedding(size, embedding_dim) for size in sparse_feature_sizes
])
self.dense_input_dim = dense_feature_dim
# 所有输入特征维度
self.input_dim = len(sparse_feature_sizes) * embedding_dim + self.dense_input_dim
def forward(self, sparse_inputs, dense_inputs):
# Embedding层
embeddings = [layer(sparse_inputs[:, i]) for i, layer in enumerate(self.embedding_layers)]
# Stacking层
sparse_embedded = torch.cat(embeddings, dim=-1)
combined_inputs = torch.cat([sparse_embedded, dense_inputs], dim=-1)
- 完整代码
class DeepCrossing(nn.Module):
def __init__(self, sparse_feature_sizes, dense_feature_dim, embedding_dim=16, hidden_units=[256, 256, 256]):
super(DeepCrossing, self).__init__()
# 处理高维特征的Embedding层
self.embedding_layers = nn.ModuleList([
nn.Embedding(size, embedding_dim) for size in sparse_feature_sizes
])
self.dense_input_dim = dense_feature_dim
# 所有输入特征维度
self.input_dim = len(sparse_feature_sizes) * embedding_dim + self.dense_input_dim
# Residual blocks
self.residual_blocks = nn.Sequential(
*[ResidualBlock(self.input_dim if i == 0 else hidden_units[i - 1], hidden_units[i]) for i in
range(len(hidden_units))]
)
self.output_layer = nn.Linear(hidden_units[-1], 1)
def forward(self, sparse_inputs, dense_inputs):
# Embedding层
embeddings = [layer(sparse_inputs[:, i]) for i, layer in enumerate(self.embedding_layers)]
# Stacking层
sparse_embedded = torch.cat(embeddings, dim=-1)
combined_inputs = torch.cat([sparse_embedded, dense_inputs], dim=-1)
# 将特征输入到ResNet中
x = self.residual_blocks(combined_inputs)
logits = self.output_layer(x)
# 原文最后是通过sigmoid激活函数进行输出
output = torch.sigmoid(logits)
return output
class ResidualBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(ResidualBlock, self).__init__()
self.fc1 = nn.Linear(input_dim, output_dim)
self.fc2 = nn.Linear(output_dim, output_dim)
self.layer_norm = nn.LayerNorm(output_dim)
def forward(self, x):
residual = x
x = F.relu(self.fc1(x))
x = self.fc2(x)
if x.shape[1] == residual.shape[1]:
x = self.layer_norm(x + residual)
x = F.relu(x)
return x

 浙公网安备 33010602011771号
浙公网安备 33010602011771号