
SpringBoot配置Druid监控
首先我们的项目是基于Druid连接池
Druid 具有以下特点:
- 亚秒级 OLAP 查询,包括多维过滤、Ad-hoc 的属性分组、快速聚合数据等等。
- 实时的数据消费,真正做到数据摄入实时、查询结果实时。
- 高效的多租户能力,最高可以做到几千用户同时在线查询。
- 扩展性强,支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发。
- 极高的高可用保障,支持滚动升级。
1.在application.yml文件中添加连接池的配置信息
# spring 配置
spring:
application:
name: imodule-nexus-service
# DataSource Config 数据源配置
datasource:
# 数据连接池类型
type: com.alibaba.druid.pool.DruidDataSource
# driver-class-name: com.mysql.jdbc.Driver
# mysql-connector-java 8.0+ 使用这个新的接口
driver-class-name: com.mysql.cj.jdbc.Driver
url: ${db.nexus.url}
username: ${db.nexus.username}
password: ${db.nexus.password}
# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
initial-size: 10
# 最大连接池连接数量,最大活跃连接数
max-active: 150
# 最小连接池连接数量,最小空闲数量
min-idle: 10
# 配置获取连接等待超时的时间
max-wait: 5000
# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。
pool-prepared-statements: false
# 指定每个连接上PSCache的大小
# max-pool-prepared-statement-per-connection-size: 20
# 和上面的等价
# max-open-prepared-statements:
# 指定检测连接sql,如果是null,会影响testWhileIdle、testOnBorrow、testOnReturn失效,如果底层代码use-ping-method是true,默认使用ping
validation-query: SELECT 1
validation-query-timeout: 500
# 申请连接时会使用validationQuery检测连接是否有效,true会降低性能,如果是true,并且检测到连接已关闭,会获取其它的可用的连接
test-on-borrow: false
# 归还连接时会使用validationQuery检测连接是否有效,true会降低性能,如果是true,并且检测到连接已关闭,会获取其它的可用的连接,放回数据库线程池
test-on-return: false
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果此连接空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
# 1)配合testWhileIdle=true时使用,如果当前jdbc使用间隔大于timeBetweenEvictionRunsMillis配置的空闲连接过期时间,执行validationQuery检测连接是否有效。
# 数据库会主动超时并断开连接,因此建议timeBetweenEvictionRunsMillis小于数据库的连接主动断开时间(如mysql的wait_timeout和interactive_timeout)
# 2)配置间隔多久才进行一次检测,Destroy线程检测需要关闭的空闲连接的时间,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 30000
# max-evictable-idle-time-millis:
# 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall
# 配置多个英文逗号分隔
filters: stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;记录慢SQL
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
2.新增配置类 DruidConfig.java
这里需要注意 @ConfigurationProperties(prefix = "spring.datasource") 指定的是Druid连接池配置信息application.yml 层级关系一定要对应好,后面会指出和这里相关的问题
package com.imodule.demo.service.configuration;
import javax.sql.DataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
/**
* 线程池监控信息查看配置
*/
@Configuration
public class DruidConfig {
@Bean
public ServletRegistrationBean druidServlet() { // 主要实现WEB监控的配置处理
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(
new StatViewServlet(), "/druid/*"); // 现在要进行druid监控的配置处理操作
servletRegistrationBean.addInitParameter("allow", "127.0.0.1,10.1.1.1"); // 白名单
// servletRegistrationBean.addInitParameter("deny", "192.168.1.200"); // 黑名单
servletRegistrationBean.addInitParameter("loginUsername", "admin"); // 用户名
servletRegistrationBean.addInitParameter("loginPassword", "admin"); // 密码
servletRegistrationBean.addInitParameter("resetEnable", "false"); // 是否可以重置数据源
return servletRegistrationBean ;
}
@Bean
public FilterRegistrationBean filterRegistrationBean() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean() ;
filterRegistrationBean.setFilter(new WebStatFilter());
filterRegistrationBean.addUrlPatterns("/*"); // 所有请求进行监控处理
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.css,/druid/*");
return filterRegistrationBean ;
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
}
3.项目中用到了Druid的话 肯定会先在pom里面引入相关依赖的,目前我们这个项目中引用的druid 1.1.15
pom.xml (下面两个选一个就可以了,我试过两种方案)
1. 使用组件common-dao层的依赖,统一引用的是 druid 1.1.15 (这个各公司的定义不同,意思就是说我们公司自定义的common包中包含了 druid 依赖,指定了版本号为1.1.15 ,所以我只需要直接引用common包就好了)
2.在引用公司的common包的时候排除druid依赖,然后再自己引入 druid-spring-boot-starter 包
保持一致,我使用的是方案一,整体统一哈哈哈哈(如果你们在使用的时候没有其他包引用了druid ,自己手动将以下其中依赖信息添加到pom.xml即可,具体版本信息可能还需要对应一下哦)
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.9</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.15</version> </dependency>
4.启动SpringBoot项目,执行main方法,启动成功后访问druid
druid监控访问地址: http://ip:port/context-path/druid/index.html
eg:http://127.0.0.1:8080/demo/druid/login.html (这里的IP需要是上面配置文件中白名单指定的哦,多个可以使用逗号分割)
进入如下登录页面,用户名及密码就是在DruidConfig.java中配置的信息(本例中是:admin/admin)


登录成功后,即可看到如下信息
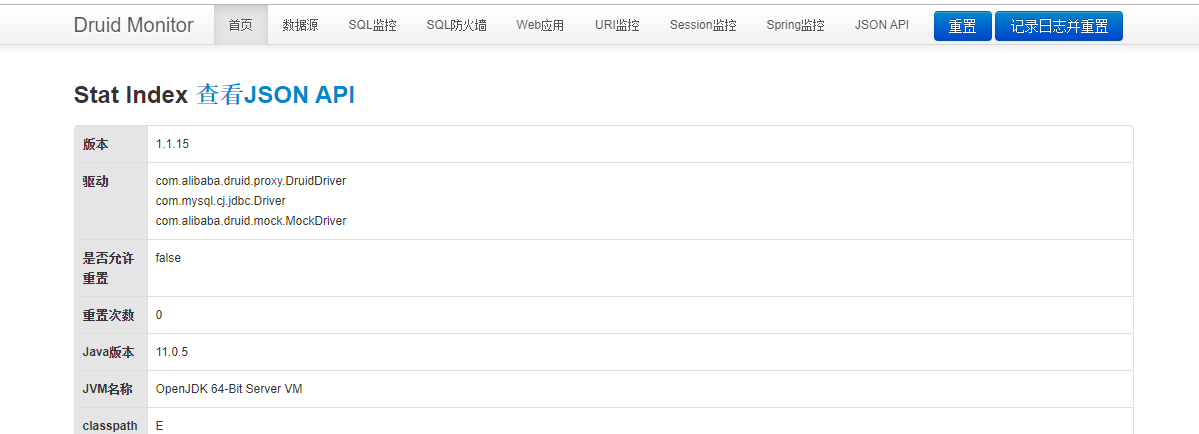
5.配置Druid监控过程中出现过两个问题
问题1:
Failed to bind properties under 'spring.datasource' to javax.sql.DataSource:
Property: spring.datasource.filters
Value: stat,wall,log4j
Origin: class path resource [application.yml]:53:14
Reason: org.apache.log4j.Logger
原因: spring.datasource下面的filters对日志的配置有问题,因为我项目中的日志为 slf4j,而连接池中配置的是log4j,所以出错了

处理方案: 将 application.yml 里面的 spring.datasource.filter 的 log4j 更改为 slf4j

问题2:启动没报错,也能正常访问Druid,但是Druid监控里面sql信息没有显示出来,数据源配置显示正常,连接池配置信息显示不正常,如下图所示
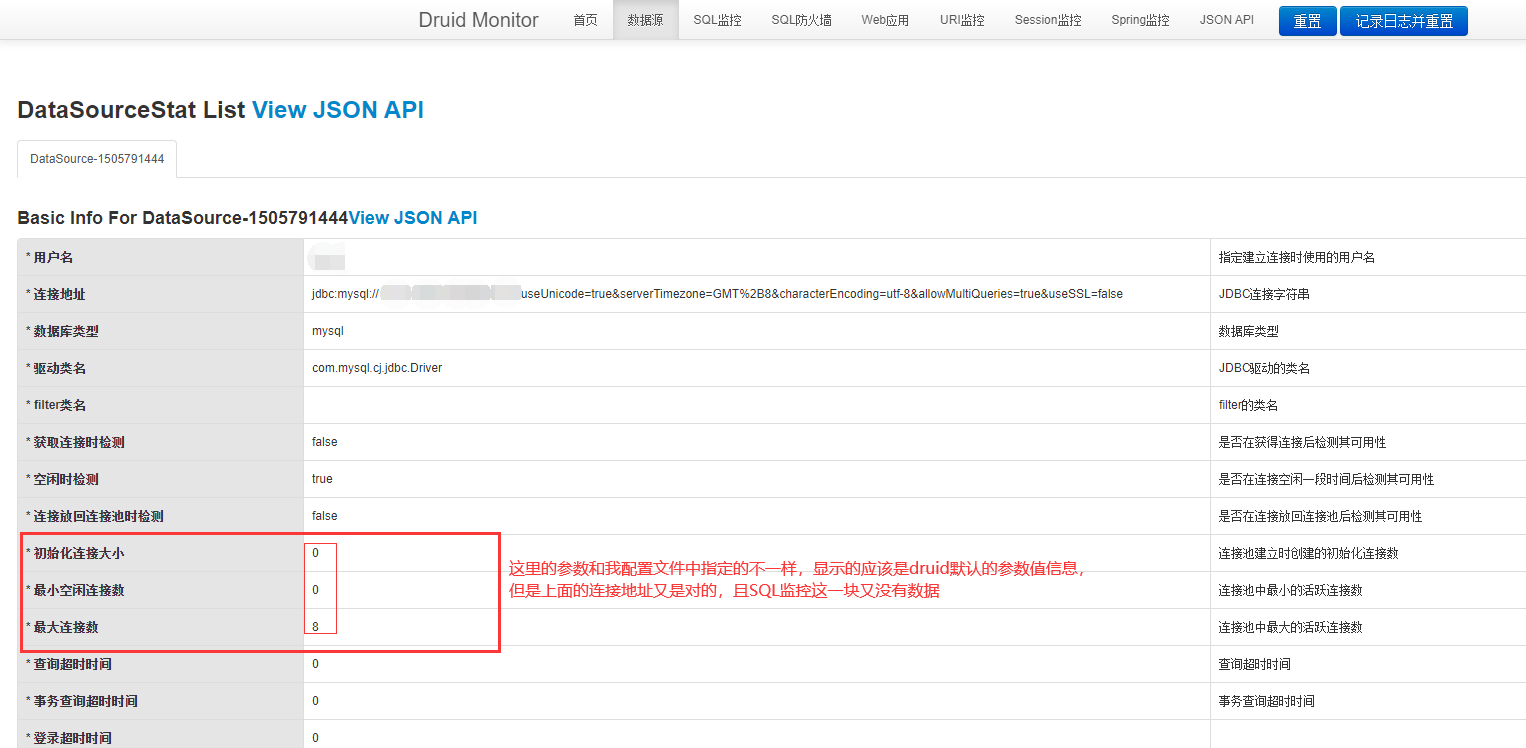
SQL监控:(执行查询数据库的脚本也没有任何信息显示)

这个问题纠结了我一上午了,查了无数遍,有人说是包的版本不对,也有人说是日志配置有问题... 都尝试了,不行
后来我眼睛一精,发现原来是我的配置文件 application.yml里面的内容定义有问题
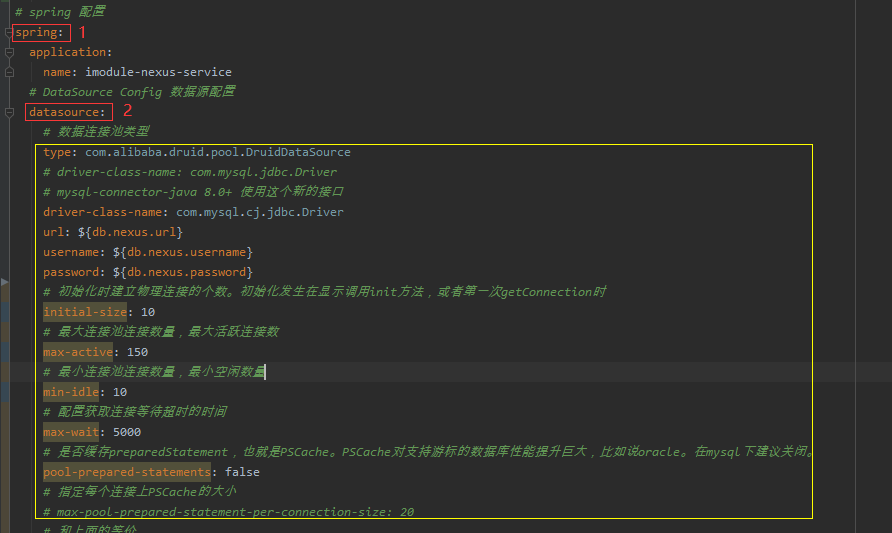
原版配置文件在指定数据源配置信息: spring.datasource.DBINFO spring.datasource.druid.DRUIDINFO
配置文件如下:

这个配置层级关系不对呀,在DruidConfig.java类中,我们指定的配置信息读取路径是 spring.datasource ,关于连接池信息又多了一层 druid(spring.datasource.druid),所以连接池相关配置信息没有被读取到,只读取到了数据源信息,这就出现了上方问题2的错误现象了

处理方案: 将druid这一层移除,调整后的配置文件如下
6.调整之后再次启动项目,访问druid监控,发现一切都正常了

7.最后提供一下完整的关于druid监控的application.yml
# spring 配置
spring:
application:
name: demo-service
# DataSource Config 数据源配置
datasource:
# 数据连接池类型
type: com.alibaba.druid.pool.DruidDataSource
# driver-class-name: com.mysql.jdbc.Driver
# mysql-connector-java 8.0+ 使用这个新的接口
driver-class-name: com.mysql.cj.jdbc.Driver
url: ${db.nexus.url}
username: ${db.nexus.username}
password: ${db.nexus.password}
# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
initial-size: 10
# 最大连接池连接数量,最大活跃连接数
max-active: 150
# 最小连接池连接数量,最小空闲数量
min-idle: 10
# 配置获取连接等待超时的时间
max-wait: 5000
# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。
pool-prepared-statements: false
# 指定每个连接上PSCache的大小
# max-pool-prepared-statement-per-connection-size: 20
# 和上面的等价
# max-open-prepared-statements:
# 指定检测连接sql,如果是null,会影响testWhileIdle、testOnBorrow、testOnReturn失效,如果底层代码use-ping-method是true,默认使用ping
validation-query: SELECT 1
validation-query-timeout: 500
# 申请连接时会使用validationQuery检测连接是否有效,true会降低性能,如果是true,并且检测到连接已关闭,会获取其它的可用的连接
test-on-borrow: false
# 归还连接时会使用validationQuery检测连接是否有效,true会降低性能,如果是true,并且检测到连接已关闭,会获取其它的可用的连接,放回数据库线程池
test-on-return: false
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果此连接空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
# 1)配合testWhileIdle=true时使用,如果当前jdbc使用间隔大于timeBetweenEvictionRunsMillis配置的空闲连接过期时间,执行validationQuery检测连接是否有效。
# 数据库会主动超时并断开连接,因此建议timeBetweenEvictionRunsMillis小于数据库的连接主动断开时间(如mysql的wait_timeout和interactive_timeout)
# 2)配置间隔多久才进行一次检测,Destroy线程检测需要关闭的空闲连接的时间,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 30000
# max-evictable-idle-time-millis:
# 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall
# 配置多个英文逗号分隔
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;记录慢SQL
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号