TensorFlow 导学
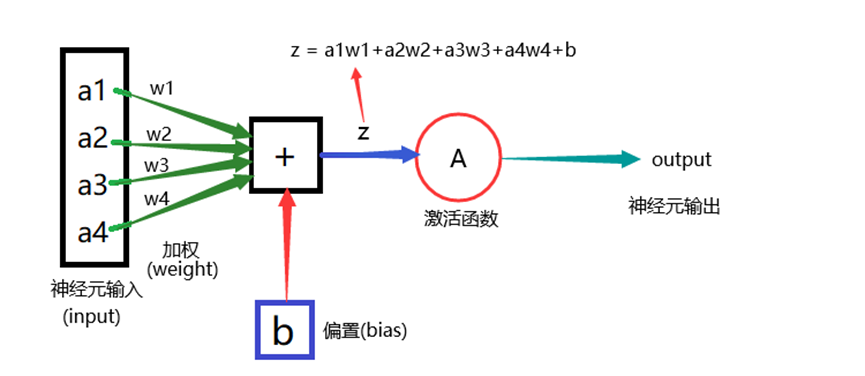
神经元结构
神经网络是由多个神经元的堆叠组成 神经元(Neuron)
代码实现


#np.dot()函数解释说明 weight = [1,2,3] #定义两个列表 inputs = [2,3,5] #weight和inputs列表对应进行相乘相加 z = np.dot(weight,inputs) #输出结果 print(z) #结果23
# 安装numpy:pip3 install numpy # 神经元由以下部分组成: # 1.多输入数据(inputs)—— # 2.加权即权重(weight)—— # 3.偏置即增加权重(bias)—— # 4.前三个通过乘加计算得权值(z) # 5 激活函数选择Relu函数 #神经元的Python代码 import numpy as np #导入numpy进行数值运算 class Neuron: ''' 在初始化接收传入的weight和bias,赋予定义类变量weight(权重)和bias(偏置) relu(z)方法:在传入z,计算0到z最大值进行返回 feedforward:计算权值,将权值z传入relu(z)函数,结果返回 ''' def __init__(self,weight,bias): self.weight = weight #定义权重变量weight self.bias = bias #定义偏置变量bias def relu(self,z): #定义函数relu return max(0,z) #取最大值返回 def feedforward(self,inputs): #dot()多个数据相乘相加,再加上偏置数 z = np.dot(self.weight,inputs) + self.bias #传入relu函数并返回值 return self.relu(z) #定义四个输入的权重和数据以及偏置值 weight = [1,2,3,4] inputs = [10,8,9,4] bias = 10 #神经元实例化 newNeuron = Neuron(weight,bias) #传入参数 #使用feedforward方法 value = newNeuron.feedforward(inputs) #传入参数 #输出结果 print(value) #输出为79
Tensorflow 2的运行模式
TensorF low 2代码的执行机制默认采用Eager Execution (动态图执行机制)
TensorFlow 1. x版本代码的执行主要是基于传统的Graph Execution ( 静态图执行)机制,存在着一-定弊端,如入门i门槛高、调试困难、灵活性差、无法使用Python 原生控制语句等
静态图执行模式对于即时执行模式效率会更高,所以通常当模型开发调试完成,部署采用图执行模式会有更高运行效率。在TensorFlow 2里也支持已函数方式调用计算图。
# ●TensorFlowTM 是一个开放源代码软件库,用于进行高性能数值计算 # ●借助其灵活的架构,用户可以轻松地将计算工作部署到多种平台(CPU、GPU、TPU)和设备(桌面设备、服务器集群、移动设备、边缘设备等) # ●TensorFlow最初是由Google Brain 团队(隶属于Google的AI部门) 中的研究人 员和工程师开发的,可为机器学习和深度学习提供强力支持
安装使用与验证
pip3 install tensorflow==2.0.0 #安装命令
import tensorflow as tf print('tensorflow的版本是:',tf.__version__) #tensorflow的版本是: 2.0.0
M54

 浙公网安备 33010602011771号
浙公网安备 33010602011771号