读懂操作系统之快表(TLB)原理(七)
前言
前不久、我们详细分析了TLB基本原理,本节我们通过一个简单的示例再次叙述TLB的算法和原理,希望借此示例能加深我们对TLB(又称之为快表,深入理解计算机系统(第三版)又称之为翻译后备缓冲区)的理解。
使用分页作为支持虚拟内存的核心机制可能会导致高性能开销,通过将地址空间划分成固定大小的小单元(即页面),分页需要映射大量信息,由于该映射信息通常存储在物理内存中,因此在逻辑上分页需要针对程序生成的每个虚拟地址进行额外的内存查找,在每条指令获取或显式加载或存储之前进入内存获取翻译信息的速度会非常慢。因此,我们的问题演变为:如何对逻辑地址进行高速翻译?我们如何加快地址转换的速度从而避免在分页时需要额外的内存引用?硬件支持是必要的吗?哪些操作需要操作系统参与?
TLB(快表,翻译后备缓冲区)原理和练习
当我们想加快查找速度时,通常需要借助于操作系统通常来完成,那就是来自操作系统的老朋友:硬件。为了加快地址翻译速度,我们将添加一个称为翻译后备缓冲区(TLB),TLB是芯片的内存管理单元(MMU)的一部分,因此,TLB是虚拟地址到物理地址翻译的硬件缓存。在每次引用虚拟内存时,硬件首先检查TLB,以查看是否已保留了所需的翻译(PTE),否则,硬件将检查TLB。如此这样将执行快速翻译而不必每次都去查阅页表(包含所有翻译),因每次进行内存引用必将对对性能的巨大影响,所以从另外一个角度讲,实际上TLB使虚拟内存成为可能。逻辑地址并计算出VPN、如何查找TLB、TLB缺失后如何处理等等通过图解方式来进行详细叙述,这里我们通过伪代码方式来进一步讲解TLB整个大概原理过程若有错误之处,还请批评指正,存有疑惑之处,还请先看操作系统专辑中对此更容易理解的叙述
1 VPN = (VirtualAddress & VPN_MASK) >> SHIFT; 2 (Success, TlbEntry) = TLB_Lookup(VPN); 3 if (Success == true) 4 { 5 if (CanAccess(TlbEntry.ProtectBits) == true) 6 { 7 Offset = VirtualAddress & OFFSET_MASK; 8 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset; 9 Register = AccessMemory(PhysAddr); 10 } 11 else 12 { 13 RaiseException(PROTECTION_FAULT); 14 } 15 } 16 else 17 { 18 PTEAddr = PTBR + (VPN * sizeof(PTE)); 19 PTE = AccessMemory(PTEAddr); 20 if (PTE.Valid == False) 21 RaiseException(SEGMENTATION_FAULT); 22 else if (CanAccess(PTE.ProtectBits) == false) 23 RaiseException(PROTECTION_FAULT); 24 else 25 TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits); 26 RetryInstruction(); 27 }
从逻辑地址提取出VPN(第1行),调用TLB_Lookup方法查找TLB中是否存持有VPN的翻译(第2行),获取到TLB是否命中的标识(Success)和TLB条目。若TLB命中(第3行),获取TLB条目中的保护位并调用CanAccess方法判断是否可访问(第5行),若可访问,从逻辑地址中提取出偏移量(第7行)。通过TLB条目中的物理页帧号即PFN、页偏移量以及基于页起始位置偏移计算出物理地址(第8行),传递物理地址并调用访问主存方法AccessMemory,使得寄存器指向主存地址空间(第9行)若TLB缺失(第16行),通过VPN和页表基寄存器计算PTE地址(第18行),传递PTE地址调用访问主存方法AccessMemory,这里是访问主存页表从而获取PTE,很显然,访问主存页表将导致额外的内存引用,操作成本很高(第19行),若PTE有效位为无效(第20行),则引发错误(第21行),同理若不可访问则引发保护位错误,这个时候将交由操作系统来进行缺页处理进行页面置换。否则调用TLB_Insert方法,将VPN和PTE中的PFN和保护位插入到TLB条目(第25行),一旦更新了TLB条目,那么硬件将重试缺页指令,如此将加速翻译,快速处理内存引用(第26行)
为了更清楚说明TLB的作用,我们通过一个简单的示例来跟踪虚拟地址翻译,最后看看TLB如何改善其性能。在此示例中,假设内存中有10个4字节整数的数组,从虚拟地址100开始。进一步假设我们有一个小的8位虚拟地址空间,具有16字节页面;因此,虚拟地址分为4位VPN(有16个虚拟页面)和4位偏移(即每页面有16个字节)。如下求数组元素之和
int sum = 0; var array = new[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; for (int i = 0; i < 10; i++) { sum += array[i]; }
上述数组中的10个元素在页表中的存放大概如下图所示,第1个元素位于(VPN = 6,偏移量 = 4),所以在第6页只能容纳3个4个字节整数元素,紧接着其他元素则分别放在第7和第8页。
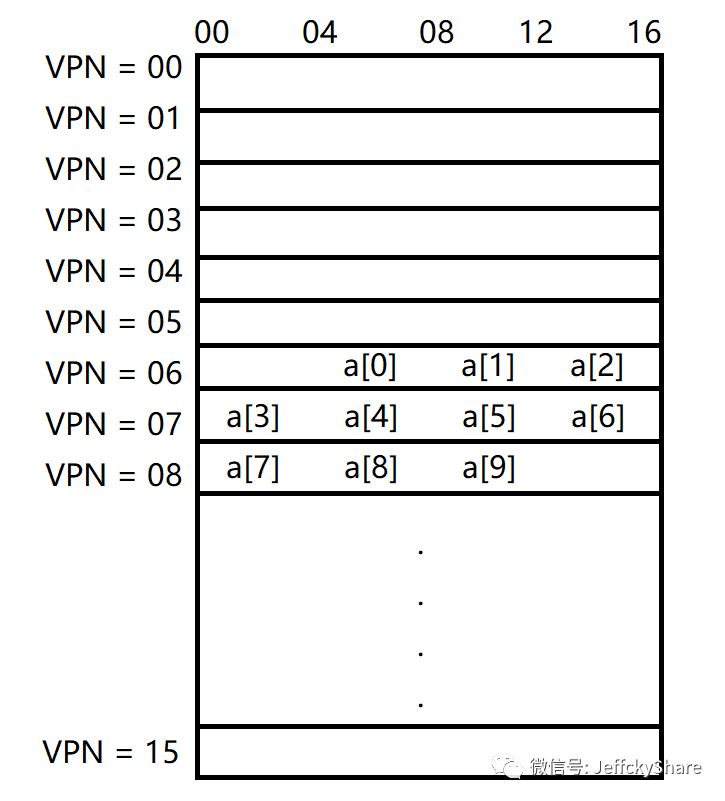
为了简单起见,我们假设循环生成的唯一内存访问就是对数组的访问,忽略变量i和sum以及指令本身。当访问第一个数组元素(a[0])时,CPU将加载100的虚拟地址,硬件从地址中提取VPN(VPN = 06),并使用该地址检查TLB的有效转换,假设这是程序第一次访问数组,则结果将是引起TLB缺失。下一步开始访问元素a[1],好消息是:TLB命中,因为数组的第二个元素紧挨着第一个元素,所以它位于同一页上,因为在访问数组的第1个元素时已经访问了此页面,所以翻译已经加载到了TLB中。当访问元素a[3]时,此时又会引起页缺失,但接下来的a[4]..a[6]都将命中,因为它们和a[3]都在内存中同一页上。我们总结一下对数组的10次访问期间的TLB活动:未命中,命中,命中,未命中,命中,命中,命中,未命中,命中,命中。因此,我们的TLB命中率(即命中数除以访问总数)为70%
虽然这不是太高(实际上,我们希望命中率接近100%),但它不是零,这可能令人惊讶。即使这是程序第1次访问该数组时,由于空间局部性,TLB还是会提高性能。数组的元素紧密地包装在页面中(即它们在空间上彼此靠近),因此只有第1次访问页面上的元素才会产生TLB未命中。其实这也我们联想到了为何要进行缓存预热,因为第1次访问会导致缓存强制缺失。如果页面大小只是原来的2倍(32字节,而非16字节),则数组访问将遭受更少的丢失。由于典型的页面大小是4KB,因此这些类型的密集,基于数组的访问可凸显出出色的TLB性能,每页访问仅遇到一次未命中。
关于TLB性能的最后一点:如果程序在此循环完成后不久再次访问了数组,则假设我们有足够大的TLB来缓存所需的翻译,那么我们可能会看到更好的结果:命中,命中,命中,命中,命中,命中,命中,命中,命中,命中。在这种情况下,由于时间局部性即时间上的快速重新引用,TLB命中率会很高,像任何高速缓存一样,TLB依赖于时间和空间局部性而获得成功,程序具备这两个属性,往往大多时候,此二者不可同时兼得。
总结
相信之前和通过本节专述TLB原理,同时结合一个简单的示例详细的讲解,能够让大家更加明白TLB的实际作用,下一节我们进入关于操作系统内存管理最后一小节内容作为总结,然后我们开始进入程序执行、线程、进程等内容,感谢您的阅读,我们下节见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号