读懂操作系统之虚拟内存TLB与缓存(cache)关系篇(四)
前言
前面我们讲到通过TLB缓存页表加快地址翻译,通过上一节缓存原理的讲解为本节做铺垫引入TLB和缓存的关系,同时我们来完整梳理下从CPU产生虚拟地址最终映射为物理地址获取数据的整个过程是怎样的,若有错误之处,还请批评指正。
TLB和缓存串行访问(Serial TLB & Cache Access)
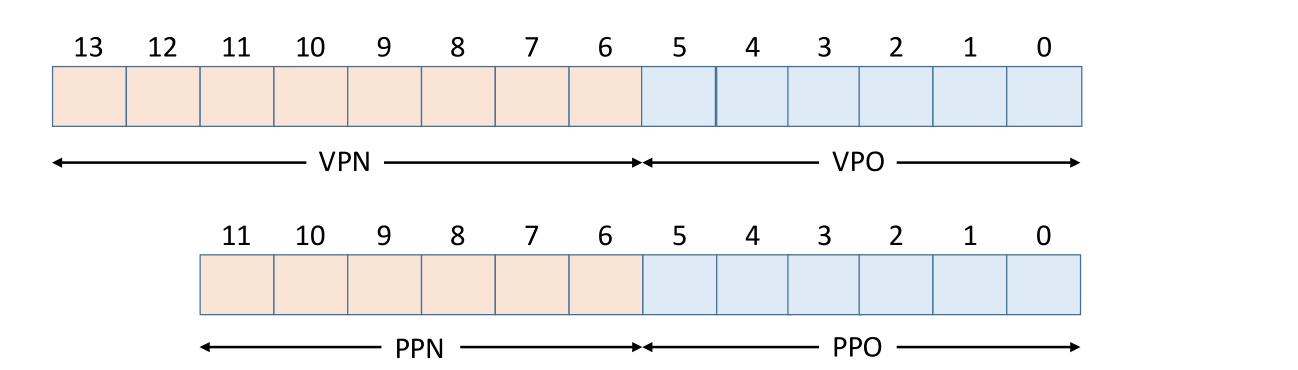
这里会跳过前面对虚拟页号、虚拟页偏移量、TLB索引和标记等的详细分析和计算,不清楚的童鞋请先查看前面文章再来看本文。假设我们有14位的虚拟地址、12位的物理地址,每页大小为64字节,如下:

同时假设已完全清楚虚拟地址和物理地址划分,接下来则是针对虚拟地址和物理地址进行位划分,如下:
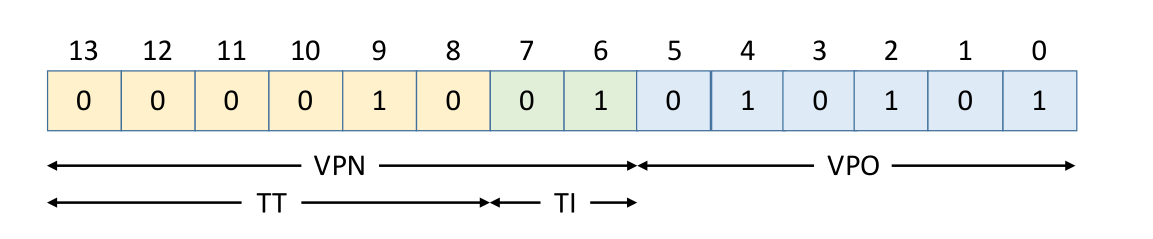
同时我们假设TLB是通过组相联来进行映射,TLB中有16个条目,4路相联,所以TLB索引(TI)和TLB标记(TT)在虚拟地址中虚拟页号进行位划分如下:

我们假设缓存采取直接映射的机制,缓存大小为64字节,每块大小为4个字节,说明缓存有16块即4位,位偏移为2位,所以缓存索引(CI)和缓存标记(CT)在物理地址中进行位划分如下:

现假设读取虚拟地址(0x0255),那么将其划分为VPN(0x09),VPO(0x15),然后将VPN划分为TT(0x02)和TI(1)如下:
接下来通过TT(0x02)和TI(1)去查找TLB,如下:
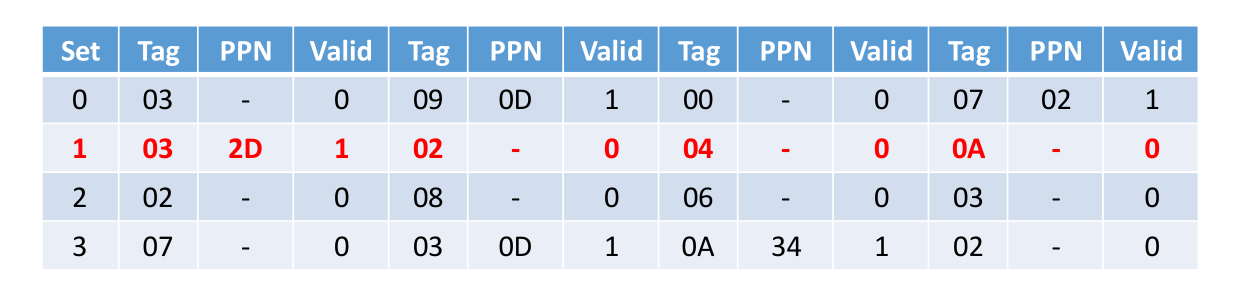
此时我们会发现TLB缺失,紧接着通过VPN(0x0916 = 2110)去页表中查找得到PPN(0x1716 = 2310),如下:

因其PPO = VPO(0x15),所以计算出物理地址为(23 * 64+21 = 149310 = 0x5D516)

然后根据上述物理地址划分为CT(0x17)、CI(5)、CO(1),如下:

最后通过上述CT(0x17)和CI(5)去查找缓存,此时缓存命中,然后将数据发送到CPU,如下:
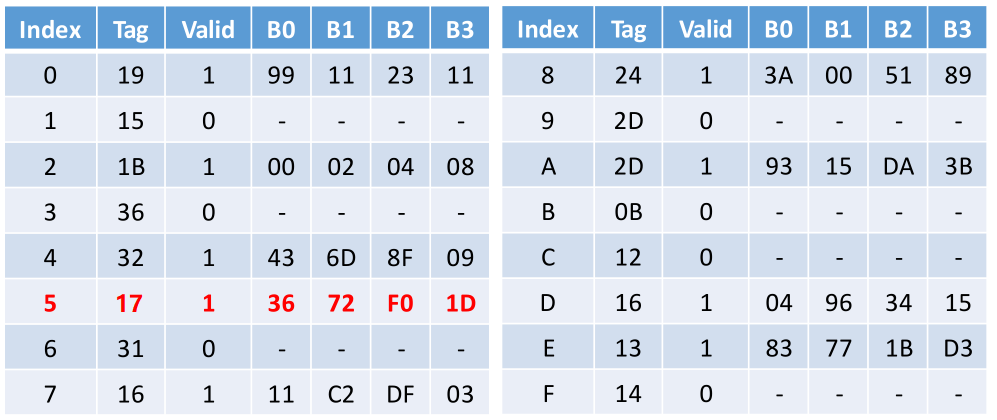
从CPU到获取数据整个的过程是这样的:【1】CPU产生虚拟地址【2】TLB翻译成物理地址【3】TLB命中,将物理地址发送到缓存【4】缓存命中返回数据。其中每一个过程涉及到的细节,比如TLB缺失、页缺失等等前面已有详细讲解,殊途同归,大致过程则是如下图解

通过如上可看出此时TLB与Cache是串行访问的关系,这是最简单同时也是比较慢的方式,因为不得不等待TLB翻译完成后才去检查缓存中是否有数据,如此一来将对CPU处理速度产生重大影响,涉及到大量内存访问时间。
TLB和缓存并行访问(Parallel TLB & Cache Access)
当前处理器最普遍的设计是采取TLB和Cache并行的方式,有些也称之为重叠访问(Overlapping TLB & Cache Access),从而提高访问速度,那么并行访问到底是如何做的呢?有没有什么使用限制呢?这里我们以Intel Skylake(英特尔第六代微处理器架构)为例来说明,其虚拟地址和物理地址结构大致如下:

看到上述结构我们可以发现物理地址中的PPN和缓存标记(CT)位数相等以及其他,英特尔这样设计就是为了让TLB和Cache可以并行访问。TLB和Cache并行访问原理:虚拟地址(VA)中的高阶位即(VPN)用来查找TLB,而低阶位(VPO)用来查找缓存。通过TLB将VPN映射到PPN,此时PPN作为缓存标记(CT),而将VPO中的低阶位作为缓存偏移量(CO),高阶位作为缓存索引(CI)。有了缓存标记和缓存索引我们就可以查询到数据,比如CPU产生虚拟地址(0x7916 = 00011110012),此时通过并行访问则为如下图解
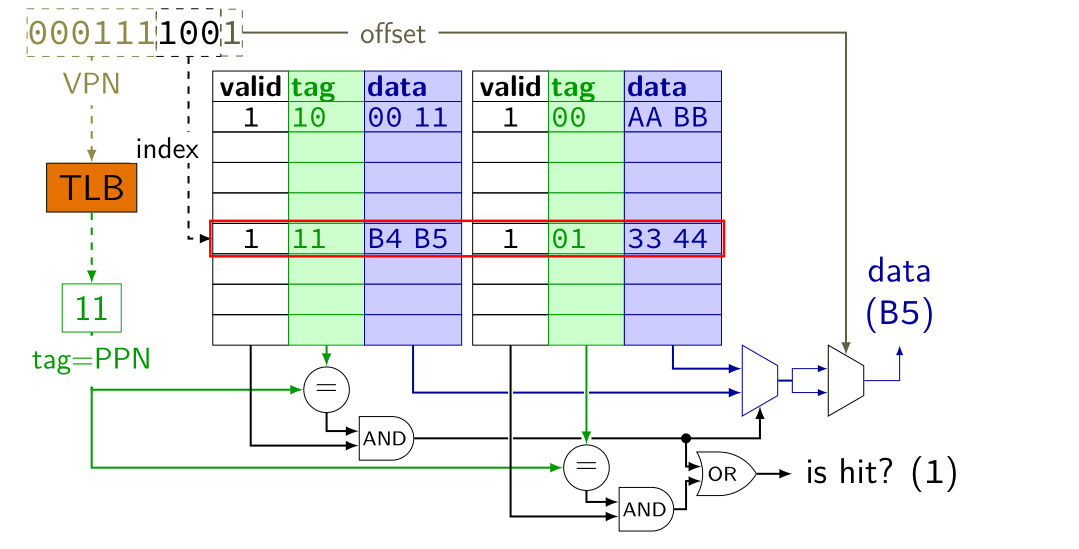
我们结合上述图解继续进行分析将并行访问分为三种情况,比如上缓存中的tag = 11,同时我们产生的PPN = tag = 11,说明缓存标记等于物理页号,同时缓存命中,最终返回数据B5给CPU(其一)。假设产生的缓存标记不是11,那么说明缓存标记不等于页号或者缓存缺失,但此时TLB命中,那么将通过TLB中的物理页号直接访问主存(其二)。否则做标准的虚拟地址翻译(其三)。为便于大家理解,我们通过伪代码形式来说明:
if (cache hit && cache tag = PPN) //返回数据到CPU else if (cache miss || cache tag != PPN && TLB hit) //通过TLB中的PPN访问主存 else //标准地址翻译
两种缓存架构(Cache & TLB Access)
缓存索引(Cache index)用于查找数据在缓存中的索引位置,而缓存标记(Cache tag)则是验证缓存中有哪些数据。从上述对并行访问原理讲解我们知道将虚拟地址中的虚拟偏移量可作为物理缓存索引,这里我们称之为虚拟索引,同时我们将VPN转换为PPN,这种模式称之为虚拟索引、物理标记缓存架构(Virtual-indexed Physically-tagged Caches),其实我们也可以将虚拟地址中的偏移量作为缓存标记,也就是说虚拟地址中的偏移量(VPO)既作为缓存索引也作为缓存标记,这种缓存架构成为虚拟索引、虚拟标记缓存架构(Virtual-indexed Virtually-tagged Caches),也叫虚拟地址缓存(Virtual Address Caches),接下来我们来分析这两种缓存架构。
虚拟索引、虚拟标记缓存(Virtual-indexed Virtually-tagged Caches)

此种缓存架构让缓存保存虚拟地址,但是现代处理器极少使用这种缓存设计,虽然很块,但是处理起来很复杂, 比如进行上下文切换时需要刷新缓存(当然可以在地址空间添加ASID),但是即使这样,由于页面可以共享而造成处理页面别名问题,用于直接映射缓存的解决方案,共享页面的VA必须在缓存索引位中一致,确保访问同一PA的所有VA将在直接映射的缓存(早期SPARC)中发生冲突,所以大多处理器采用第二种(VA-PA)缓存架构。
虚拟索引、物理标记缓存(Virtual-indexed Physically-tagged Caches)

并行TLB & Cache访问采取的就是此种架构,此种架构要求缓存索引完全包含在虚拟地址中的虚拟偏移量中。缓存标记和PPN相等(当然第一种)当查询缓存时也执行TLB访问,它是当前处理器最常见的设计,我们知道缓存使用的是物理地址,而CPU产生的是虚拟地址,这也就意味着没有TLB就无法完成缓存查找。前面我们了解到缓存数据存储结构存在直接映射、组相联、全相联三种结构,在此种缓存架构中有使用限制,我们首先来看看直接映射。
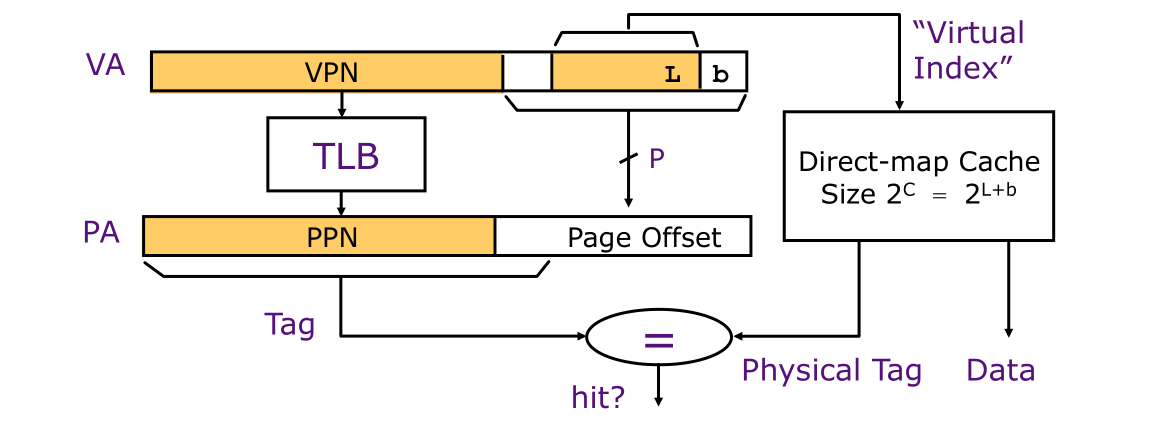
并行访问的本质在于缓存查询数据无需等待TLB完成,二者可同时开始,所以当两者访问完成后需要进行比较,如果(cache size <= page size)即(C = L + b) <= P才有效,因为对于缓存的所有输入都无需进行任何翻译。

通过组相联增加了缓存的关联性从而减少索引到缓存所需地址的位数,在访问完成后进行比较,如果(cache size) / (associativity) ≤ page size即(C <= P + A)才有效。对于缓存和TLB都采用的组相联从而减少缺失率,所以对于并行访问中的缓存组相联映射必须满足(cache size) / (associativity) ≤ page size。那么问题来了,如果一个缓存大小为64KB,采用2路相联,页大小>=4k,那么可以进行并行访问TLB & Cache吗?很显然不能,如下
缓存大小:64KB = 216 -------------》 C = 16
组相联:2 -------------》 A = 1
页大小: 4KB = 212 --------------》P >= 12
那么问题又来了,对于一个16位的虚拟地址,页大小为64字节,缓存大小为256b,采用8路相联的1级缓存且有16块,那么可以并行访问TLB &Cache吗?请输出原因。
总结
本节我们详细介绍了TLB &Cache二者的关系,采用并行访问通过VPN查找TLB,VPO查询缓存同时进行来提高访问速度。下一节我们进入页表数据结构的详细讲解,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号