第一次个人编程作业
https://github.com/CoupleYoghourt/SE1/tree/main/041903103
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 480 | 540 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 160 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 60 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 70 |
| · Coding | · 具体编码 | 300 | 280 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 45 |
| · Size Measurement | · 计算工作量 | 30 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| · 合计 | 1500 | 1360 |
二、计算模块接口
-
(3.1)计算模块接口的设计与实现过程。
-
拼音和拆字直接调库。
-
一个Word类:用于记录原始敏感词的内容、敏感词进行左右拆分后得到偏旁部首和敏感词的拼音(好吧,其实也不能完全叫做一个类,毕竟没有方法,只是用来记录信息)
-
七个函数(具体的传参和返回值见github上的代码注释):
- initChai():这个是第三方库的默认拆字功能的初始化函数
- doChai():对传入的内容进行偏旁部首的拆分
- doConvert():将敏感词转换成上面提到的Word实例对象
- createRe():创建每个敏感词对应用来进行敏感词匹配的正则表达式
- runRe():对传入的文本内容进行正则匹配
- subWord():对传入的文本内容进行同音字的替换
- check_and_output():对全文本的检测与输出
-
算法流程
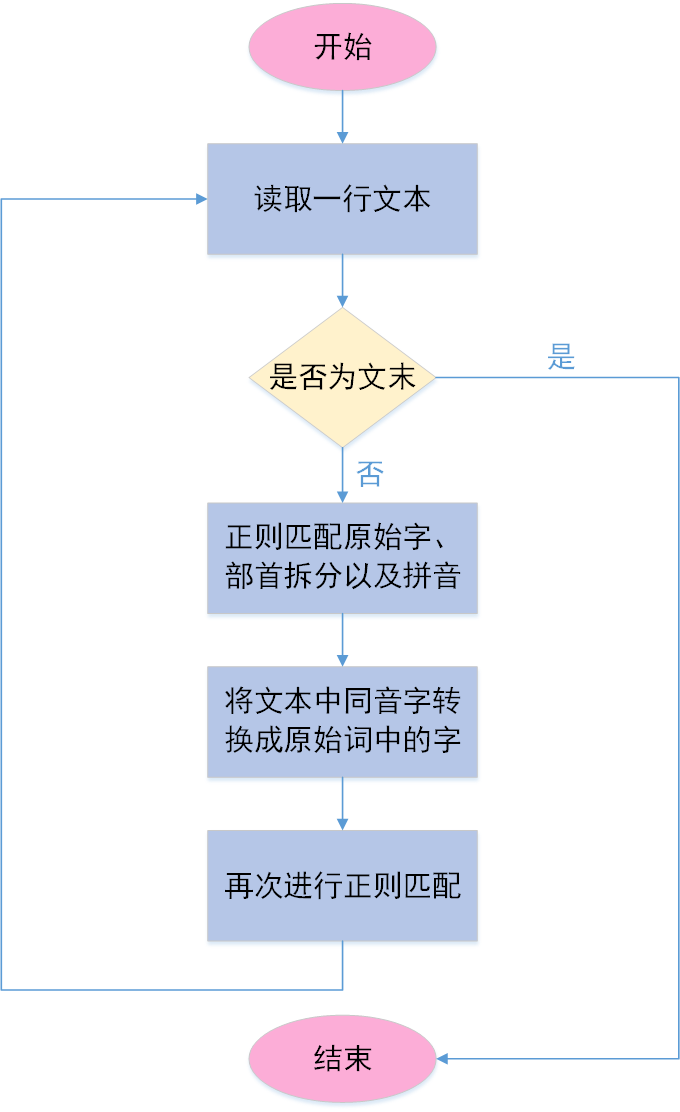
-
举几个例子
敏感词:白狐子
对应正则:(?:白|bai|b) [^\u4e00-\u9fa5]*(?:狐|犭瓜|hu|h) [^\u4e00-\u9fa5]*(?:子|zi|z)
文本1:白456781狐**[4z子长得很漂亮,标准的鹅蛋脸,柳叶细眉,明眸皓齿,盈盈纤腰,属于典型的古典美人。
文本2:拜zsds糊*[z紫长得很漂亮,标准的鹅蛋脸,柳叶细眉,明眸皓齿,盈盈纤腰,属于典型的古典美人。
对于文本1,根据正则可以很轻松的找到敏感词所在的内容。
对于文本2,先将“拜”“糊”“紫”这三个同音字转换为对应的“白”“狐”“子”三个字,再使用正则,依然可以轻松找到。 -
关键之处与独到之处
- 整个代码的关键其实是在正则式的构建,如何构建一个完美的正则,是我这个算法性能的瓶颈之一,具体的构建方法可以见源代码中createRe()函数,不在此赘述。
- 要说独到之处的话,可能就是跑的慢咯。整体上是建立在正则匹配的基础上,因此效率可能不像AC机、DFA那样那么快,有极端情况可能会一行文本用正则匹配好几次,但是写起来确实简单啊。
- 有一个优点就是过程中可以将同音字转换为原来敏感词中对应的字,然后会再进行一次正则匹配,因此可以简化诸如繁体等情况的考虑。
- 开始写代码之前,好像把题目的意思曲解了,以为不能引用其他文件,只能提交一个main.py,因此不需要其他文件辅助(当然也是基于这种情况,正则成为了我的首选解决方案)。
- 总体来说,算法简单明了,不用再补充其他文件,看完流程图基本上就能知道整个过程。
-
-
(3.2)计算模块接口部分的性能改进。
-
性能分析
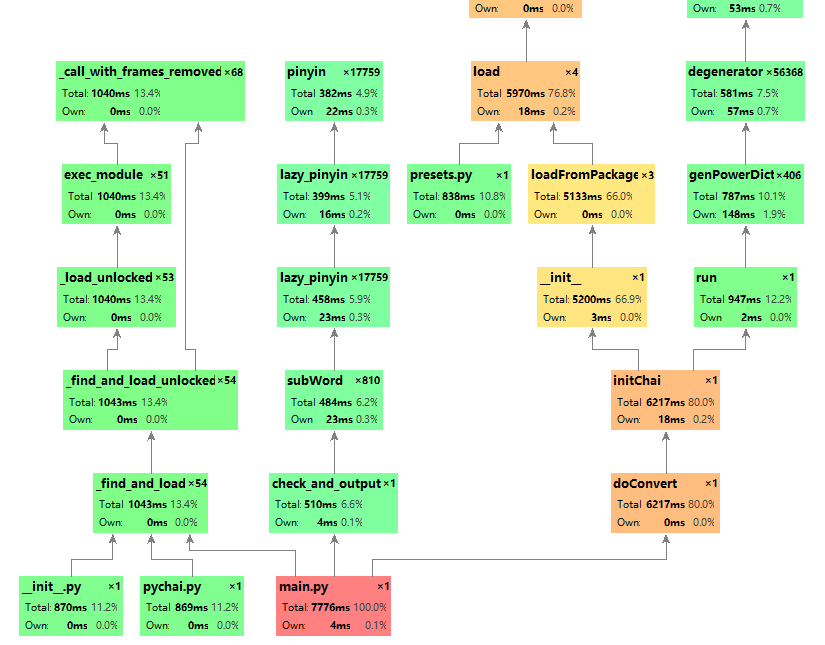

- 从性能分析工具得出的图中,可以很容易看出来其实“拆字”功能花费了很长时间,80%的时间都在初始化拆字(initChai()函数)上了。
-
改进思路
- 由于在编写代码期间有很长一段时间因为个人原因在忙别的事,所以对“拆字”功能的优化并没有真正落实。
但我想可以大体上从两个方面进行优化:- 不使用第三方库默认的拆字规则,当然默认的拆字规则更为完善,能够适应更多的情况,但就针对本次作业只拆左右结构的字来说,其实可以自行制定一个更为简练的规则,优化“拆字”功能。
- 缩小字库,让字库变为常用字字库,删减那些使用极少的生僻字。
- 由于在编写代码期间有很长一段时间因为个人原因在忙别的事,所以对“拆字”功能的优化并没有真正落实。
-
-
(3.3)计算模块部分单元测试展示。
- 构造测试用例的思路
- 第一次接触到单元测试这个名词,没什么经验,没什么思路,硬编就完了,觉得哪个比较不好搞,就测哪个。
- 测试拆字功能
doChai模块部分测试用例def test_chai1(self): word = "你" ans = [['亻','尔']] chaifen = doChai(word, Test_Chai.chai) assert ans == chaifen def test_chai2(self): word = "好" ans = [['女', '子']] chaifen = doChai(word, Test_Chai.chai) assert ans == chaifen - 测试替换同音字功能
subWord模块部分测试用例def test_subWord1(self): word = Word("操", Test_subWord.chai) Re_dict = {word:''} content = '草场' ans = '操场' subContent, _ = subWord(content, Re_dict) assert ans == subContent def test_subWord2(self): word = Word("帅", Test_subWord.chai) Re_dict = {word:''} content = '确实蟀啊' ans = '确实帅啊' subContent, _ = subWord(content, Re_dict) assert ans == subContent - 测试覆盖率

- 构造测试用例的思路
-
(3.4)计算模块部分异常处理说明。
-
命令行输入异常
if len(sys.argv) == 1: # 未输入任何参数时,采用默认的配置 forbiddenFile = "words.txt" checkFile = "org.txt" ansFile = "ans.txt" elif len(sys.argv) == 4: # 正确输入三个参数 forbiddenFile = sys.argv[1] checkFile = sys.argv[2] ansFile = sys.argv[3] else: # 输入的参数少于3个或者多于3个 print("输入不符合规范,请重新输入") exit(0)- 当在命令行中输入
程序给出python main.py words.txt org.txt输入不符合规范,请重新输入
- 当在命令行中输入
-
文件打开错误异常
def TryOpen(filePath): try: with open(filePath, 'r', encoding='utf-8') as f: pass except Exception as msg: print(msg) exit(0)- 当输入一个不存在的文件
程序直接抛出python main.py words666.txt org.txt ans.txt
然后,正常结束程序[Errno 2] No such file or directory: 'words666.txt'
- 当输入一个不存在的文件
-
确实是没什么开发经验,就能想到两个比较明显的异常处理。
-
三、心得
- 拾起了很久没用的github,在github上能搜索到很多好用的东西,可以说是面向github编程了。
- 能够在第三方库文档没有完整给出一个使用样例的情况下(说的就是pychai!),不断摸索,完成对第三方库函数的调用,对于自己来说是一个很大的进步。当然有点遗憾的就是没能自己写一个规则更为简练的拆字配置文件,用库里自带的规则拆字,有点复杂,影响效率。
- 已经不记得上一次写这么多代码是什么时候了,希望这一次是一个新的起点,能为以后的编程之路开一个好头。
- 当做出来的东西得到的结果比测评组给的答案多的时候,其实是比较开心的,但是能不能过所有的测试点就不知道了,毕竟面向数据编程。

