Hbase进阶
Hbase Shell
-
建表:create'表名','列族名1' ,'列族名2',
create 'student','info' -
插入数据 put '表名', '行键', '列名', '值'
put 'student','1001','info:name','Nick' -
查询(获得row key 为1001的数据)
get 'student','1001'
Hbase 表设计
-
需求1:通话记录
手机号 通话时长 对方手机号 日期 类型(主叫,被叫) -
设计:rowKey
<1>手机号:唯一标识 <2>时间戳(倒序):通话记录应该展示最新的,此字段迎合rowKey字典序 phone_(long.maxValue-timestamp) -
设计:列簇
cf:length=,cf:data=,cf:dnum=,cf:type= -
需求2:
表: 人员有多个角色 角色优先级 角色有多个人员 人员 删除添加角色 角色 可以添加删除人员 人员 角色 删除添加 数据: 001小红 班长100,学委200 002小白 学委,劳委300 003小黑 劳委,体委400 -
设计-一张表
【人员角色表】 rowkey: cf1:(基本信息) cf2:(角色列表) cf3:(人员列表) pid cf1:pname=,cf1:page= cf2:rid=?,cf2:rid2=? rid cf1:rname=?,cf1:rdesc=? cf3:pid=?,cf3:pid2=? -
设计-两张表
【psn】 rowkey: cf1:(人员信息) cf2:(角色列表) pid 001 cf1:name=小红 cf2:100=10,cf2:200=9 002 cf1:name=小白 cf2:200=10,cf2:300=9 003 cf1:name=小黑 cf2:300=10,cf2:400=9 004 cf1:name=小绿 【role】 rowkey: cf1:(角色信息) cf2:(人员列表) rid 100 cf1:name=班长 cf2:001=小红 200 cf1:name=学委 cf2:001=小红,cf2:002=小白 300 cf1:name=劳委 cf2:001=小黑,cf2:002=小白 400 cf1:name=体委 cf2:001=小黑, -
需求3
组织架构 部门-子部门 查询 顶级部门 查询 每个部门的所有子部门 部门 添加、删除子部门 部门 添加、删除 CEO300 develop 100 develop1 200 develop2 400 web800 web1 700 web2 1100 test 600 test1 500 test2 900 test3 1000 -
设计
【dept】 rowkey: cf:(部门信息) cf2:(子部门列表) did 300 cf:name=ceo, cf2:100=,cf2:800=?,cf2:600=? 100 cf:name=develop,cf:fid=300 cf2:200=, 200 cf:name=develop1,cf:fid=100 400 cf:name=develop2,cf:fid=100 800 cf:name=web,cf:fid=300 cf2:700=?,cf:1100=? 700 cf:name=web1,cf:fid=800 1100 cf:name=web2,cf:fid=800
Hbase MR
-
Runner
// 配置文件设置 Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "node1,node2,node3"); conf.set("fs.defaultFS", "hdfs://node1:8020"); Job job = Job.getInstance(conf); job.setJarByClass(WCRunner.class); job.setMapperClass(WCMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class);
TableMapReduceUtil.initTableReducerJob("wc", WCReducer.class, job, null, null, null, null, false);
FileInputFormat.addInputPath(job, new Path("/usr/wc"));
// reduce端输出的key和value的类型
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Put.class);
// job.setOutputFormatClass(cls);
// job.setInputFormatClass(cls);
job.waitForCompletion(true);
-
mapper
String[] splits = value.toString().split(" "); for (String string : splits) { context.write(new Text(string), new IntWritable(1)); } -
reducer
public class WCReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> iter, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable intWritable : iter) { sum+=intWritable.get(); } Put put = new Put(key.toString().getBytes()); put.add("cf".getBytes(), "cf".getBytes(), String.valueOf(sum).getBytes()); context.write(null, put); } }
Hbase&Hive
-
Hive简介
(1) 数据仓库 Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。 (2) 用于数据分析、清洗 Hive适用于离线的数据分析和清洗,延迟较高。 (3) 基于HDFS、MapReduce Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。 -
Hive架构
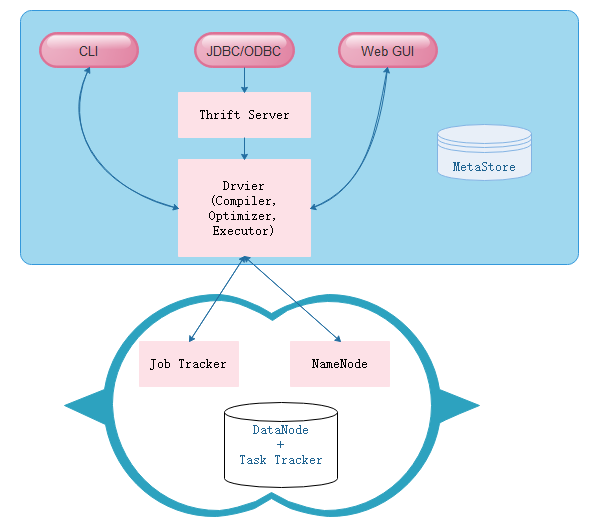
-
Hive建表-插入数据-MRSQL
【建表-外部表内部表】 create table psn ( id int, name string, likes array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; 【load加载数据】 1,小明1,lol-book-movie,beijing:shangxuetang-shanghai-pudong 2,小明2,lol-book-movie,beijing:shangxeutang-shanghai-pudong 【查询-分区-分桶-触发MR】 select splite(line,' ') from wc result: ["A","B"] ["A","B","C"] ["A","B","C","D"] [explode(ARRAY) 列表中的每个元素生成一行] select explode(splite(line,' ')) from wc result: A B A B C [word是别名] from (select explode(split(line,' ')) word from wc) t insert into wc_result select word,count(word) group by word; -
Hbase架构
-
Hbase简介
(1) 数据库 是一种面向列存储的非关系型数据库。 (2) 用于存储结构化和非结构化的数据 适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。 (3) 基于HDFS 数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。 (4) 延迟较低,接入在线业务使用 面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
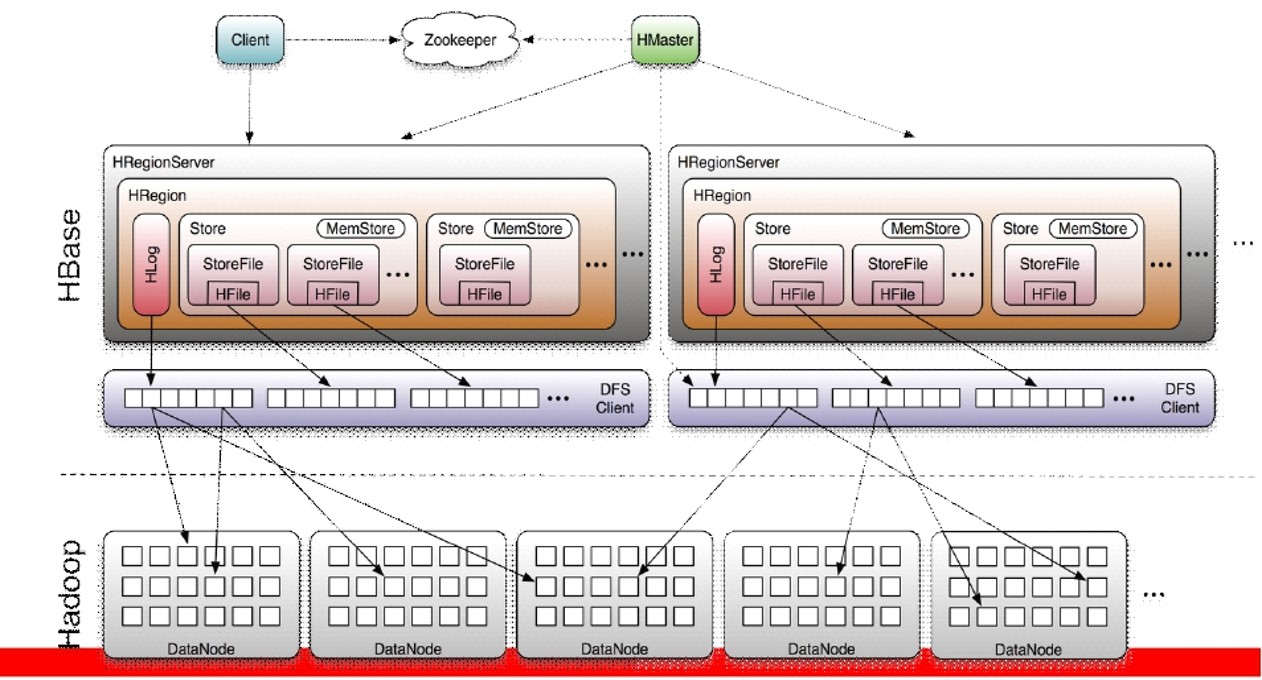
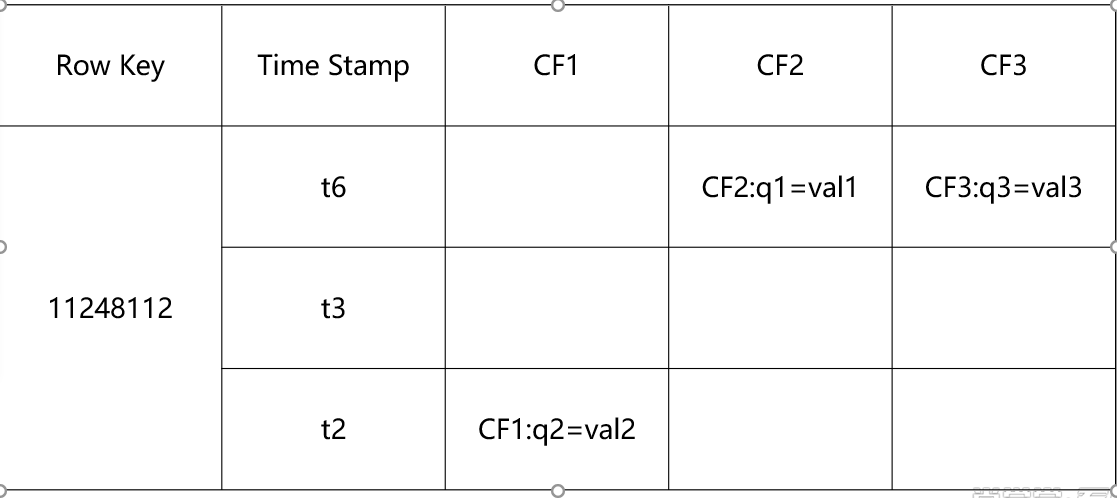
- Hbase Shell增删改查
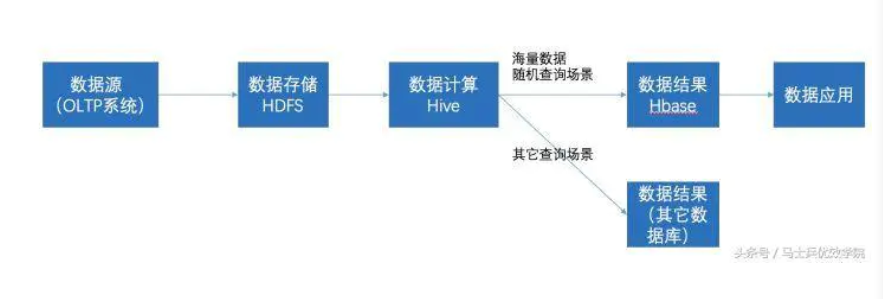
Hive和Hbase的配合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号