摘要:  GCC 编译 GCC的编译流程分为四个步骤,分别为: 预处理(Pre-Processing) 可以通过gcc -E hello.cc -o hello.i查看中间结果 编译(Compiling) 汇编(Assembling) 链接(Linking) gcc 命令只能编译C++源文件,而不能自动和C+ 阅读全文
GCC 编译 GCC的编译流程分为四个步骤,分别为: 预处理(Pre-Processing) 可以通过gcc -E hello.cc -o hello.i查看中间结果 编译(Compiling) 汇编(Assembling) 链接(Linking) gcc 命令只能编译C++源文件,而不能自动和C+ 阅读全文
GCC 编译 GCC的编译流程分为四个步骤,分别为: 预处理(Pre-Processing) 可以通过gcc -E hello.cc -o hello.i查看中间结果 编译(Compiling) 汇编(Assembling) 链接(Linking) gcc 命令只能编译C++源文件,而不能自动和C+ 阅读全文
posted @ 2021-04-11 11:59
Aurelius84
阅读(1774)
评论(0)
推荐(1)
摘要:  一、为什么慢? 重要的一个原因是C++的基本 头文件-源文件的编译模型: 每个源文件为一个编译单元 头文件数量多,可能会包含上百甚至上千个头文件 存在重复解析,每个编译单元中,这些头文件都要从硬盘里读取然后被解析 每个编译单元都会产生一个obj文件 这些obj文件被link到一起,此过程很难做到并行 阅读全文
一、为什么慢? 重要的一个原因是C++的基本 头文件-源文件的编译模型: 每个源文件为一个编译单元 头文件数量多,可能会包含上百甚至上千个头文件 存在重复解析,每个编译单元中,这些头文件都要从硬盘里读取然后被解析 每个编译单元都会产生一个obj文件 这些obj文件被link到一起,此过程很难做到并行 阅读全文
一、为什么慢? 重要的一个原因是C++的基本 头文件-源文件的编译模型: 每个源文件为一个编译单元 头文件数量多,可能会包含上百甚至上千个头文件 存在重复解析,每个编译单元中,这些头文件都要从硬盘里读取然后被解析 每个编译单元都会产生一个obj文件 这些obj文件被link到一起,此过程很难做到并行 阅读全文
posted @ 2021-04-11 11:57
Aurelius84
阅读(1758)
评论(0)
推荐(0)
摘要: 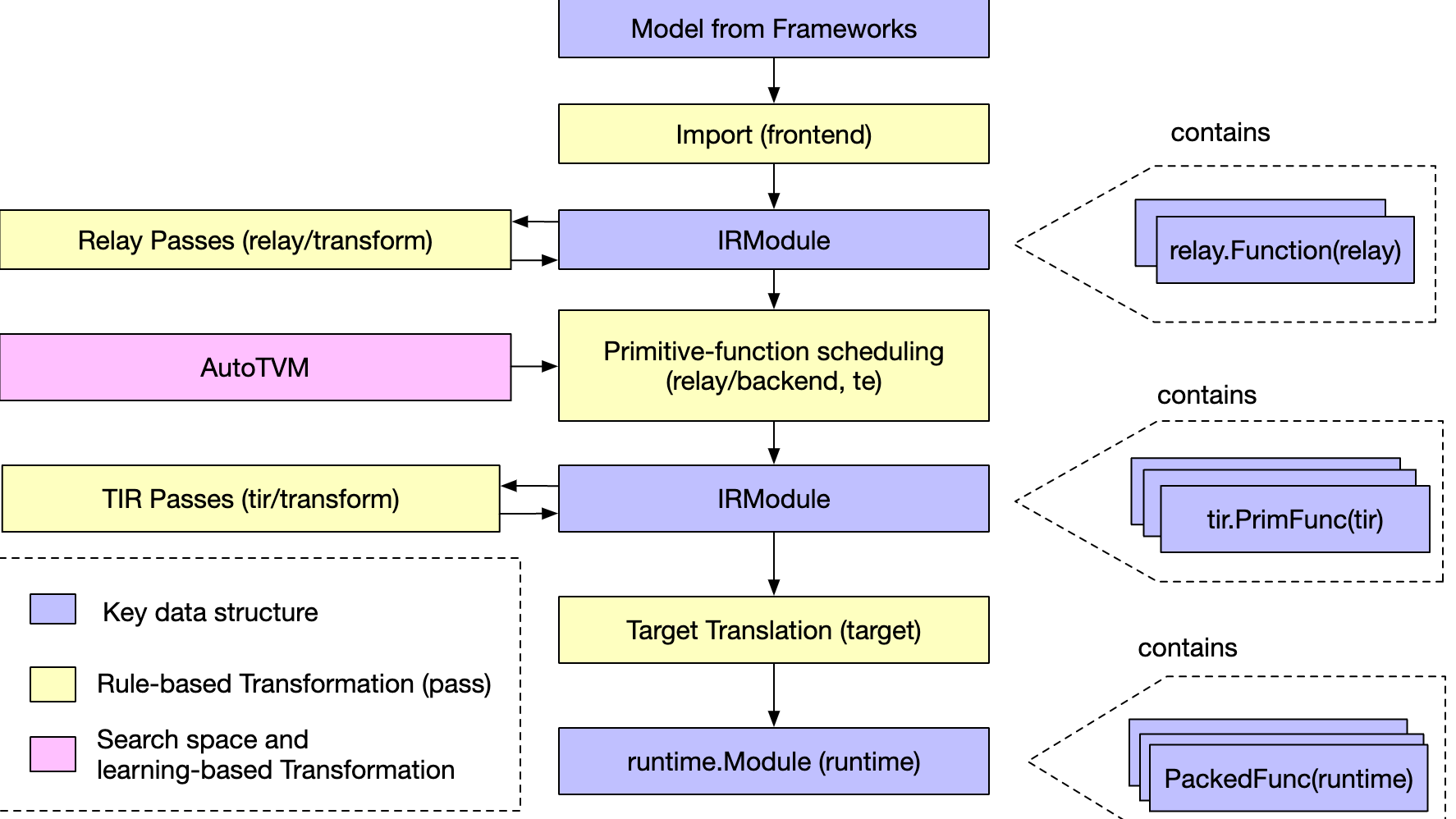 一、关键问题 TVM中的 IR 是什么,架构设计上分几层? 解答:TVM的整体结构图如下: 概念上,分为两层:上层为面向前端组网的Relay IR, 下层为面向LLVM的底层 IR。 但从设计实现上,底层通过 Object 元类实现统一的AST Node表示,借助一个 IRModule 贯穿上下层。 阅读全文
一、关键问题 TVM中的 IR 是什么,架构设计上分几层? 解答:TVM的整体结构图如下: 概念上,分为两层:上层为面向前端组网的Relay IR, 下层为面向LLVM的底层 IR。 但从设计实现上,底层通过 Object 元类实现统一的AST Node表示,借助一个 IRModule 贯穿上下层。 阅读全文
一、关键问题 TVM中的 IR 是什么,架构设计上分几层? 解答:TVM的整体结构图如下: 概念上,分为两层:上层为面向前端组网的Relay IR, 下层为面向LLVM的底层 IR。 但从设计实现上,底层通过 Object 元类实现统一的AST Node表示,借助一个 IRModule 贯穿上下层。 阅读全文
posted @ 2021-04-11 11:48
Aurelius84
阅读(6433)
评论(0)
推荐(1)
 TensorFlow Runtime,简称 TFRT,它提供了统一的、可扩展的基础架构层,可以极致地发挥CPU多线程性能,支持全异步编程(无锁队列+异步化语义)。TFRT 可以减少开发、验证和部署企业级模型所需的时间。
TensorFlow Runtime,简称 TFRT,它提供了统一的、可扩展的基础架构层,可以极致地发挥CPU多线程性能,支持全异步编程(无锁队列+异步化语义)。TFRT 可以减少开发、验证和部署企业级模型所需的时间。 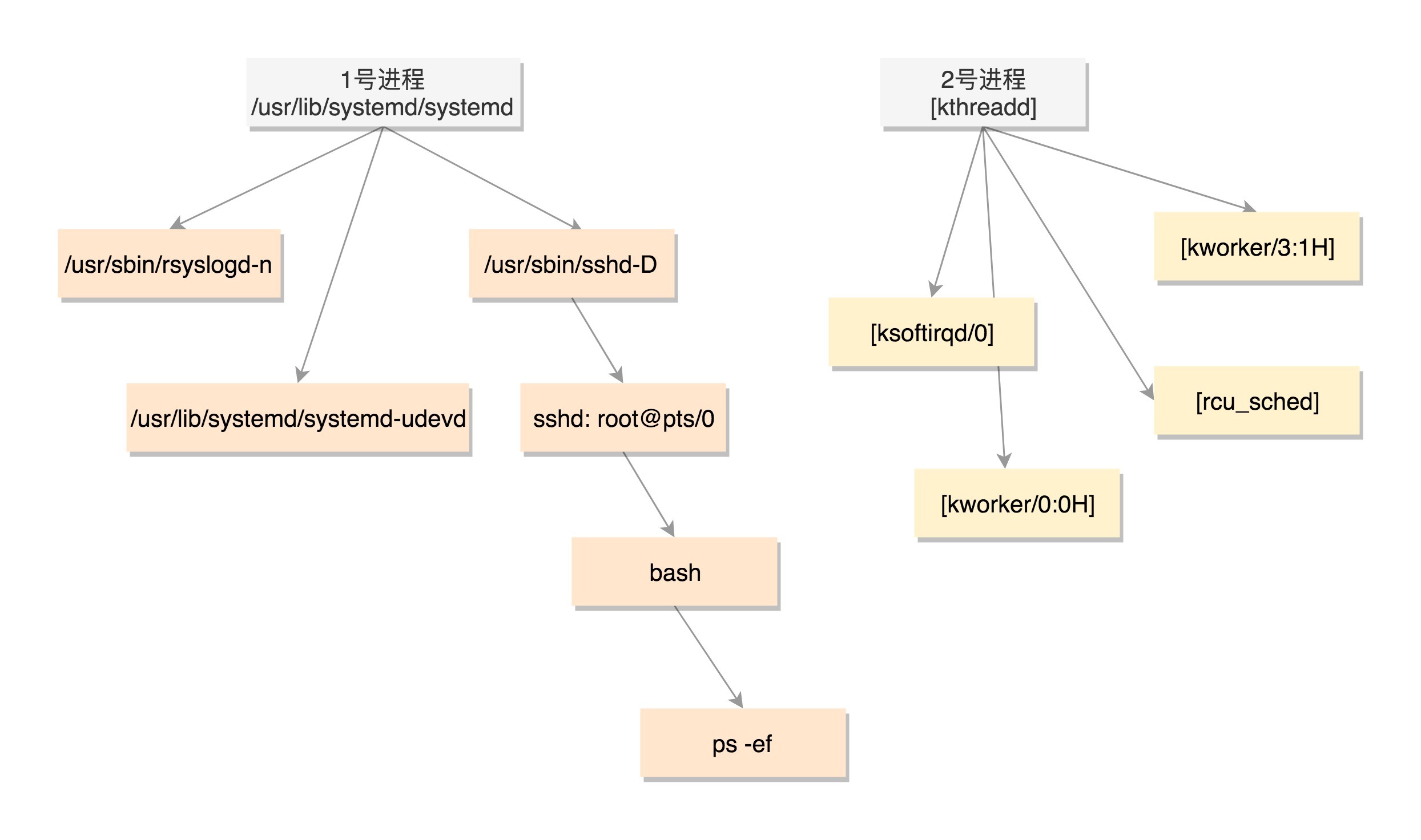 所有进程的祖宗进程,就是系统启动时的 init进程。init进程会启动很多daemon进程,为系统运行提供服务。然后启动getty,让用户登录,登录后运行shell。
所有进程的祖宗进程,就是系统启动时的 init进程。init进程会启动很多daemon进程,为系统运行提供服务。然后启动getty,让用户登录,登录后运行shell。 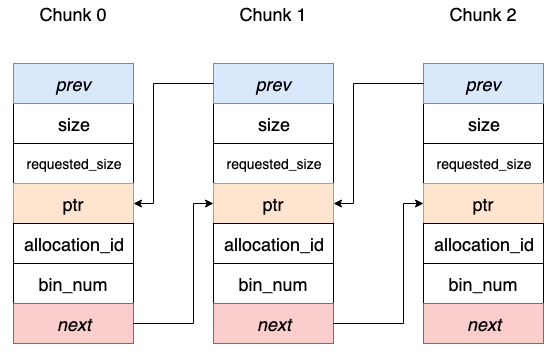 前言 在深度学习模型训练中,每次迭代过程中都涉及到Tensor的创建和销毁,伴随着的是内存的频繁 malloc和free操作,可能对模型训练带来不必要的 overhead。 在主流的深度学习框架中,会借助 chunk 机制的内存池管理技术来避免这一点。通过实事先统一申请不同 chunk size 的
前言 在深度学习模型训练中,每次迭代过程中都涉及到Tensor的创建和销毁,伴随着的是内存的频繁 malloc和free操作,可能对模型训练带来不必要的 overhead。 在主流的深度学习框架中,会借助 chunk 机制的内存池管理技术来避免这一点。通过实事先统一申请不同 chunk size 的  常见的通用寄存器有:
EAX寄存器:累加器,常用于算数运算、布尔操作、逻辑操作、返回函数等。
EBX寄存器:基址寄存器,常用于存档内存地址。
CX寄存器:计数寄存器,常用于存放循环语句的循环次数,字符串操作中也常用。
EDX寄存器:数据寄存器,常和 EAX一起使用。
常见的通用寄存器有:
EAX寄存器:累加器,常用于算数运算、布尔操作、逻辑操作、返回函数等。
EBX寄存器:基址寄存器,常用于存档内存地址。
CX寄存器:计数寄存器,常用于存放循环语句的循环次数,字符串操作中也常用。
EDX寄存器:数据寄存器,常和 EAX一起使用。  Make工具因遵循不同的规范和标准,执行的Makefile的格式也是不同。主流的Make工具包括:
GNU Make
QT的qmake
微软的 MS nmake
BSD的 pmake
每个平台都有自己的工具,则带来了很大的平台兼容性问题。CMake是一种跨平台的编译工具。
Make工具因遵循不同的规范和标准,执行的Makefile的格式也是不同。主流的Make工具包括:
GNU Make
QT的qmake
微软的 MS nmake
BSD的 pmake
每个平台都有自己的工具,则带来了很大的平台兼容性问题。CMake是一种跨平台的编译工具。 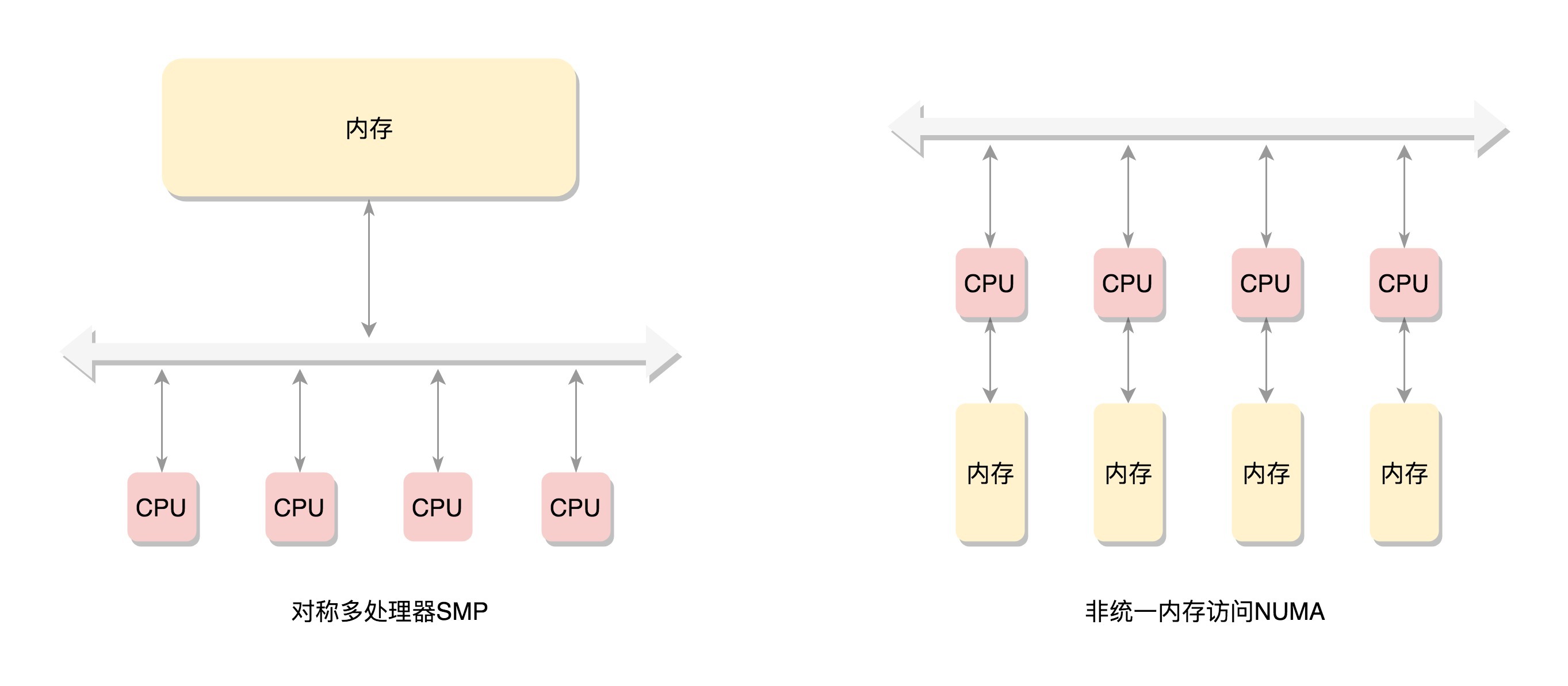 物理内存的组织方式:物理内存是由连续的一页一页的块组成,每个物理页都有页号; 每个页由`struct page`表示,放进数组里—平坦内存模型。
物理内存的组织方式:物理内存是由连续的一页一页的块组成,每个物理页都有页号; 每个页由`struct page`表示,放进数组里—平坦内存模型。 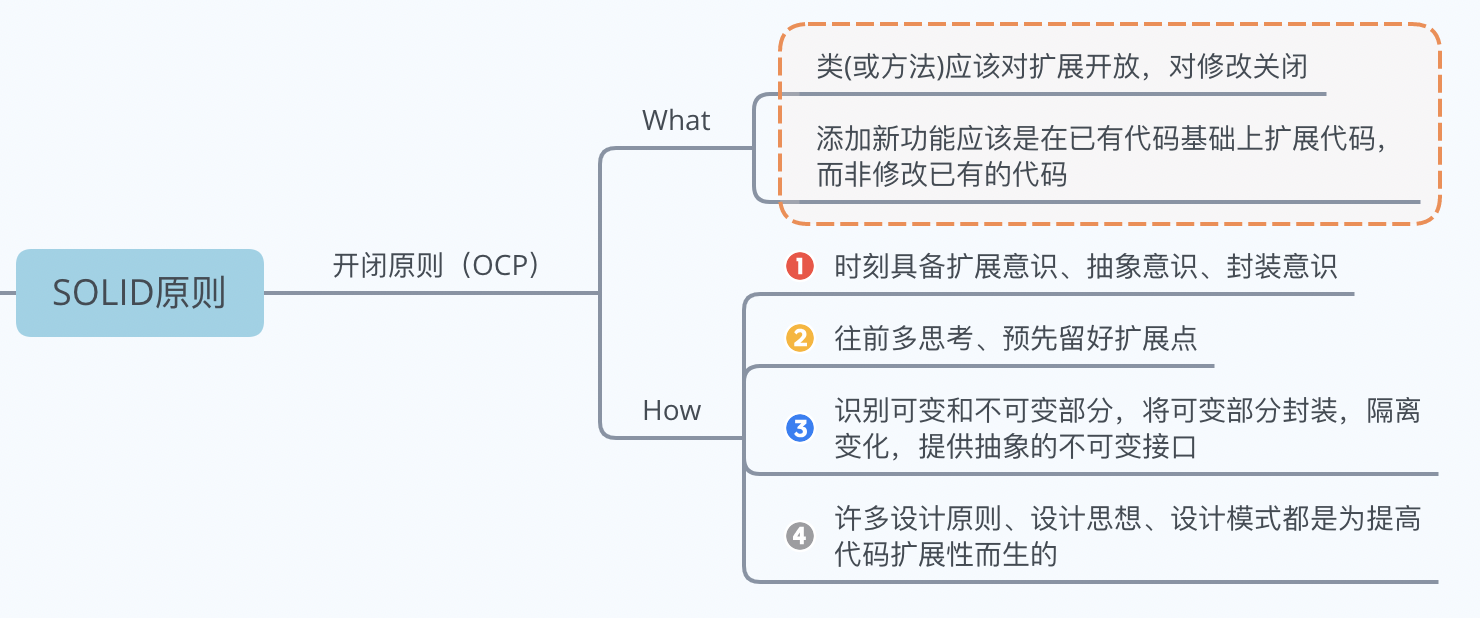 开闭原则的英文是Open Closed Principle,简称OCP。在添加一个新的功能时,应该是在已有的代码基础上扩展代码(如新增模块、类、方法等),而非修改已有的代码。我们要时刻具备扩展意识、抽象意识、封装意识,识别可变和不可变部分,将可变部分封装,隔离变化,提供抽象的不可变接口。
开闭原则的英文是Open Closed Principle,简称OCP。在添加一个新的功能时,应该是在已有的代码基础上扩展代码(如新增模块、类、方法等),而非修改已有的代码。我们要时刻具备扩展意识、抽象意识、封装意识,识别可变和不可变部分,将可变部分封装,隔离变化,提供抽象的不可变接口。  浙公网安备 33010602011771号
浙公网安备 33010602011771号