

学习笔记-Python-爬虫4-数据提取-正则、XML、XPath、BeautifulSoup4
# 页面解析、数据提取
- 结构化数据:先有结构,再谈数据
- JSON文件
- JSON Path
- 转换成Python类型进行操作(json类)
- XML文件
- 转换成Python类型(xmltodict)
- xpath
- css选择器
- 正则
- 非结构化数据:先有数据,再谈结构
- 文本
- 电话号码
- 邮箱地址
- 通常处理此类数据,使用正则表达式
- html文件
- 正则
- xpath
- css选择器
# 正则表达式
- 一套规则,可以再字符串文本中进行搜查替换等
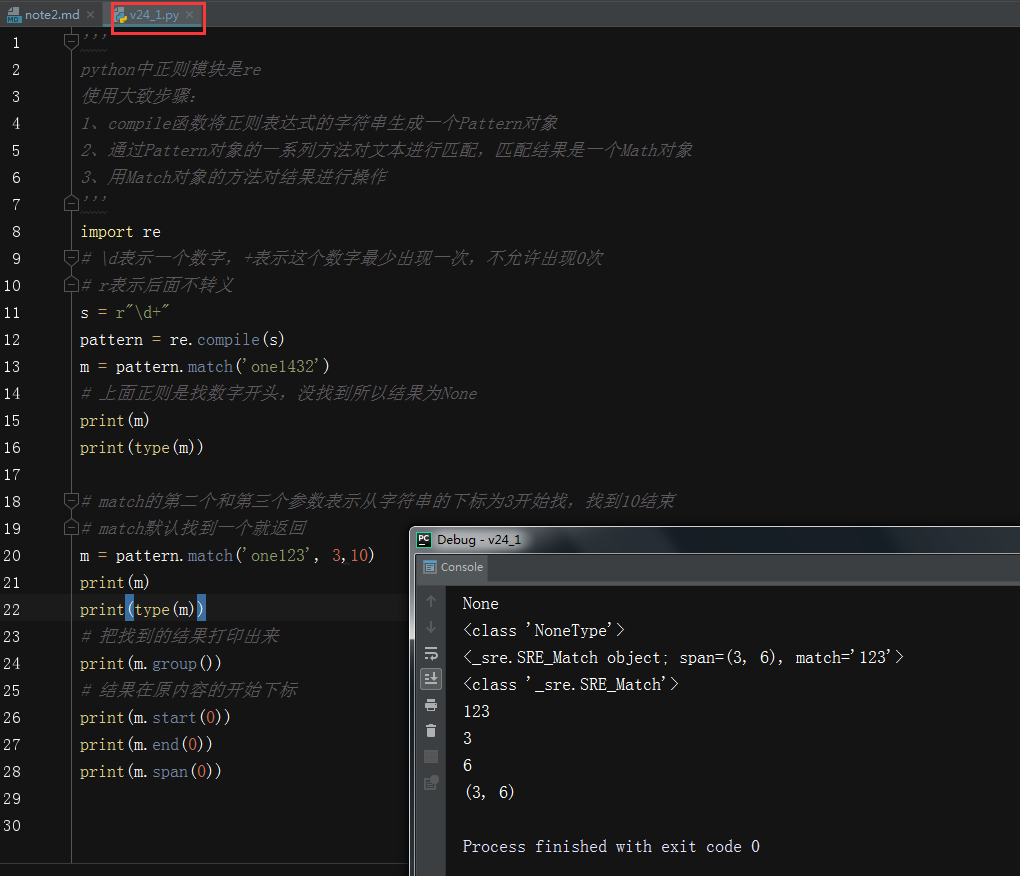
- 案例v24_1,re的基本使用
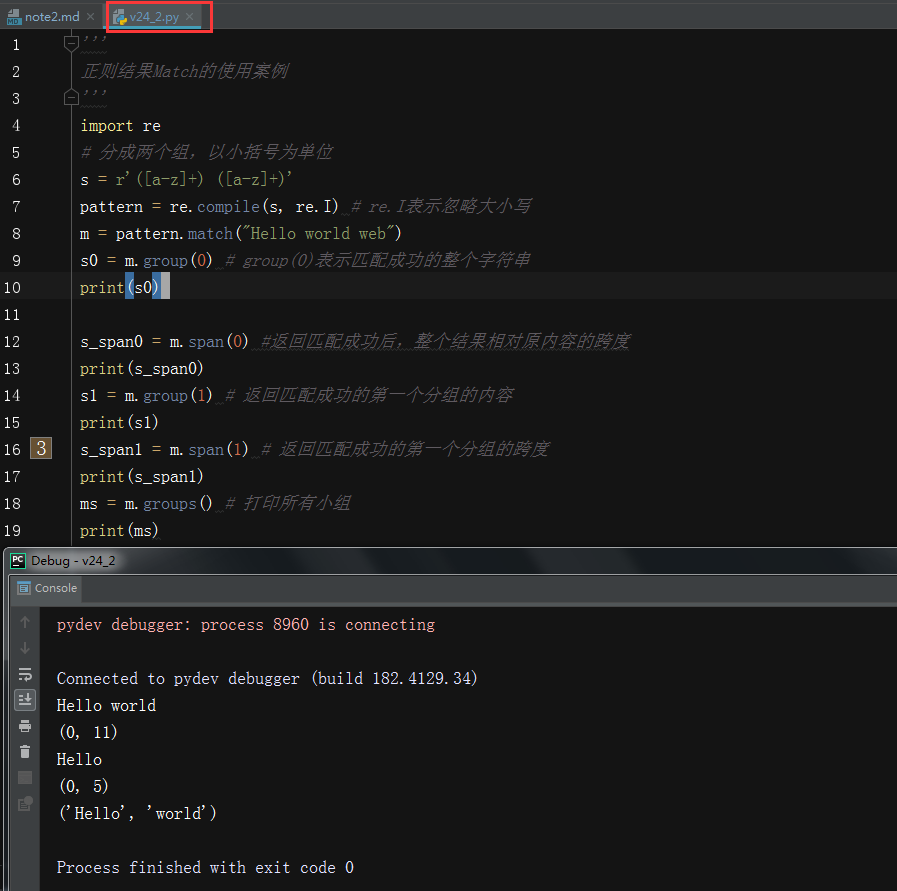
- 案例v24_2,match的基本使用
- 正则常用方法:
- match:从开始位置开始查找,一次匹配
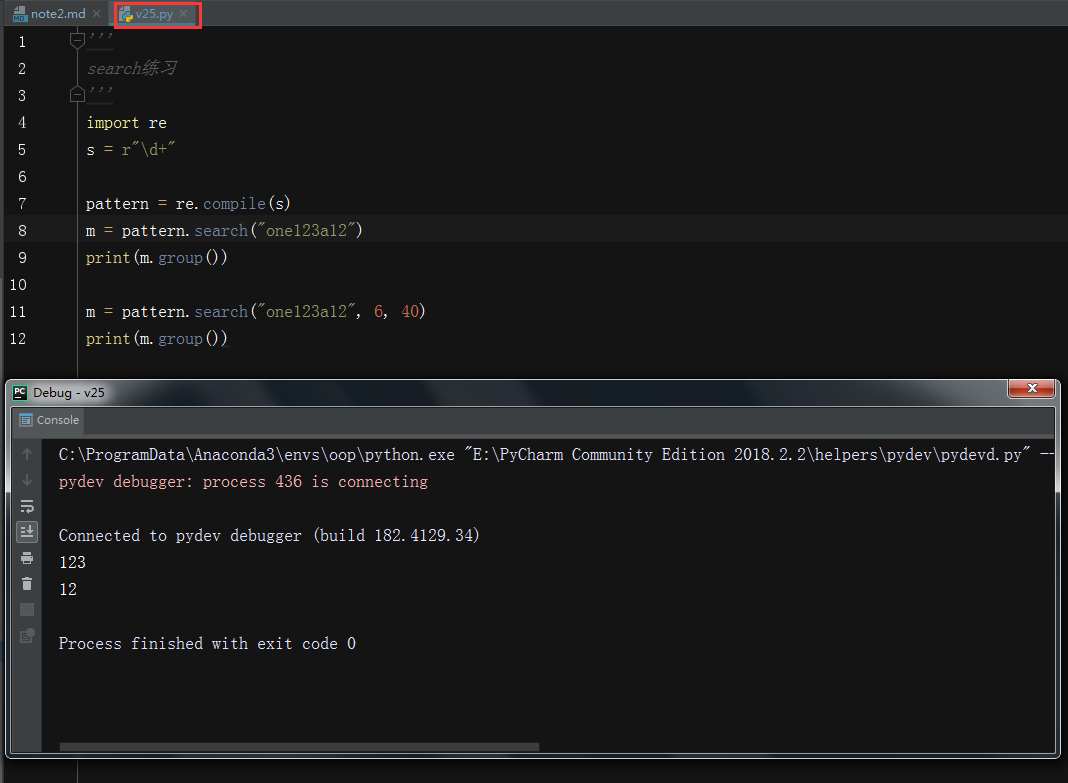
- search:从任何位置查找,一次匹配,案例v25
- findall:匹配多次,返回列表,案例v26
- finditer:匹配多次,返回迭代器,案例v26
- split:分割字符串,返回列表
- sub:替换
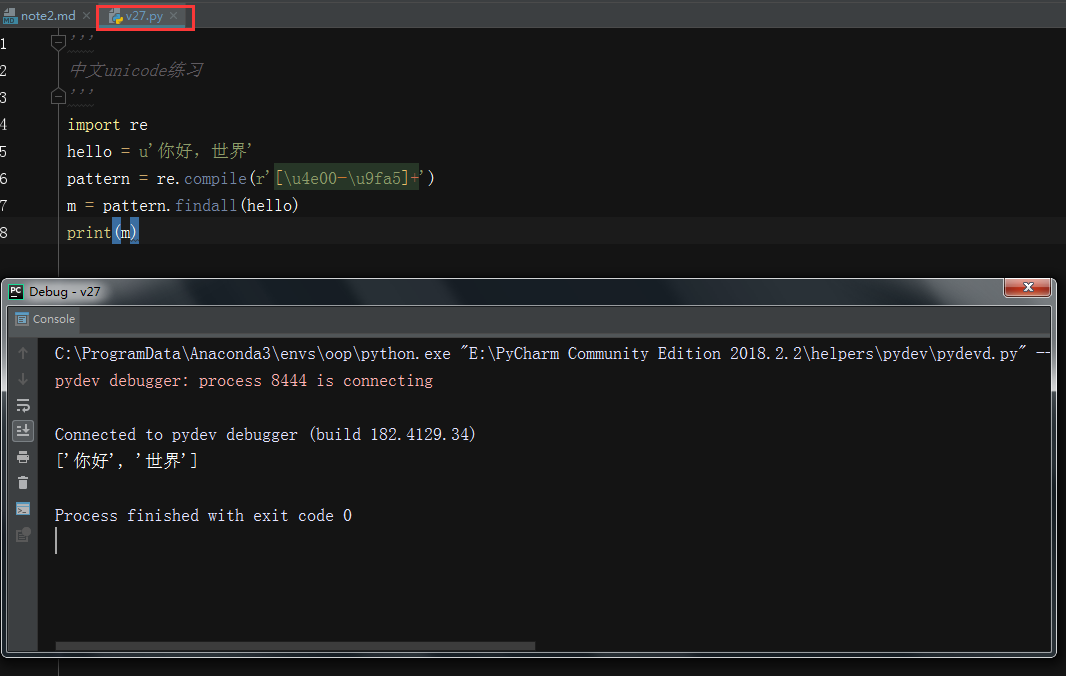
- 匹配中文
- 中文unicode访问主要在[\u4e00-\u9fa5]
- 案例v27
- 贪婪与非贪婪
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
- Python里面数量词默认是贪婪模式
- 例如:
- 查找文本addsadsadd
- re是 ab*
- 贪婪模式结果是:abbbbbbb
- 非贪婪模式结果是:a
# XML
- XML(ExtensibleMarkupLanguage)
- http://www.w3school.com.cn/xml/index.asp
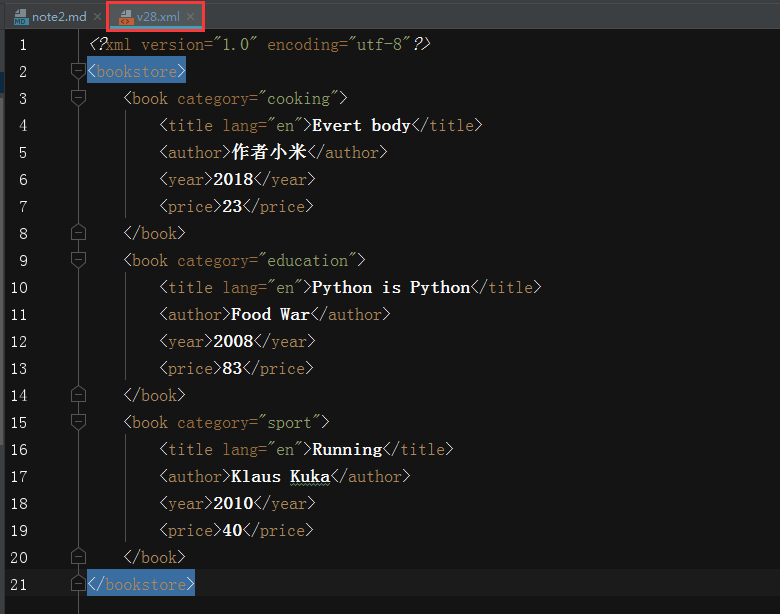
- 案例v28.xml
- 概念:父节点、子节点、先辈节点(父、祖父等)、兄弟节点、后代节点(子、孙等)
# XPath
- XPath(XML Path Language)是一门在XML文档中查找信息的语言
- 官方文档:http://www.w3school.com.cn/xpath/index.asp
- XPath开发工具
- 开源的Xpath表达式工具:XMLQuire
- chrome插件:XPath Helper
- Firefox:XPath Checker
- 常用的路径表达式:
- nodename:选取此节点的所有子节点
- /:表示从根节点开始
- //:选取元素,而不考虑元素的具体位置
- .:当前节点
- ..:父节点
- @:选取属性
- 例如,此处以v28.xml为例:
- bookstore:选取bookstore下面的所有子节点
- /bookstore:从根节点开始,选取bookstore
- bookstore/book:选取bookstore下面所有为book的子元素
- //book:选取book子元素
- //@lang:选取名称为lang的所有属性
- 谓语(Predicates)
- 谓语用来查找某个特定的节点,写在方括号里面
- /bookstore/book[1]:选取第一个属于bookstore下叫book的元素
- /bookstore/book[last()]:选取最后一个属于bookstore下叫book的元素
- /bookstore/book[last()-1]:选取倒数第二个属于bookstore下叫book的元素
- /bookstore/book[possition()<3]:选取属于bookstore下叫book的前两个元素
- /bookstore/book[@lang]:选取属于bookstore下叫book的并且含有属性lang的元素
- /bookstore/book[@lang='cn']:选取属于bookstore下叫book的并且含有属性lang,而且lang的值是cn的元素
- /bookstore/book[@price<80]:选取属于bookstore下叫book的并且含有属性price,而且price的值小于80的元素
- /bookstore/book[@price<80]/title:选取属于bookstore下叫book的并且含有属性price,而且price的值小于80的元素的子元素title
- 通配符
- '*':任何元素节点
- @*:匹配任何属性节点
- node():匹配任何类型的节点
- 选取多个路径
- //book/title \ //book/author:选取book元素里面的title和author元素
- //title \ // price:选取文档中所有的title和price元素
# lxml库
- python的HTML/XML的解析器
- 官方文档:http://lxml.de/index.html
- 安装:conda install lxml
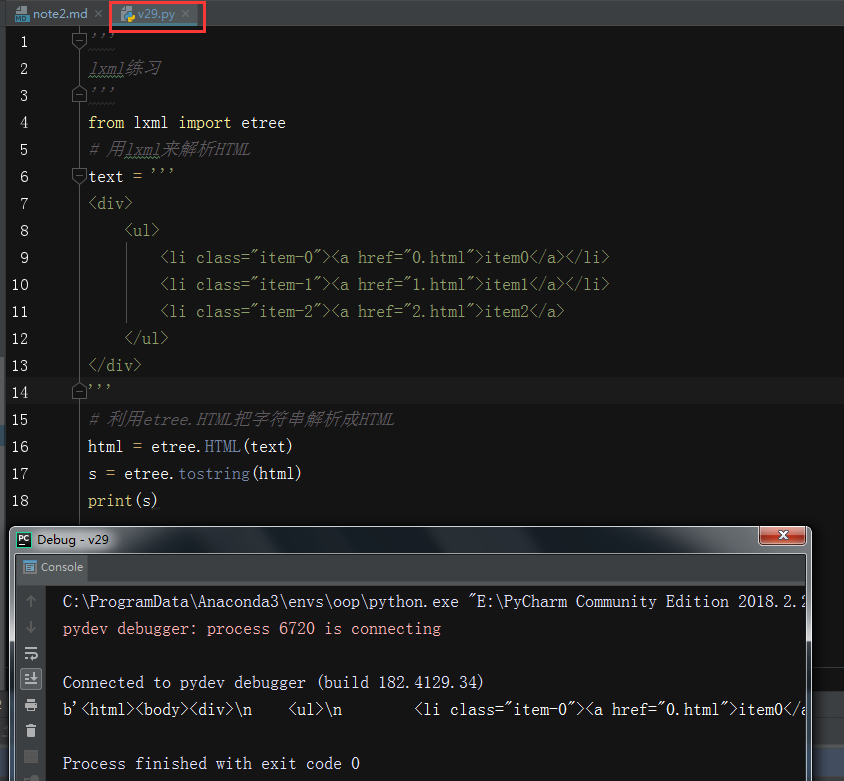
- 案例v29
- 功能:
- 解析HTML
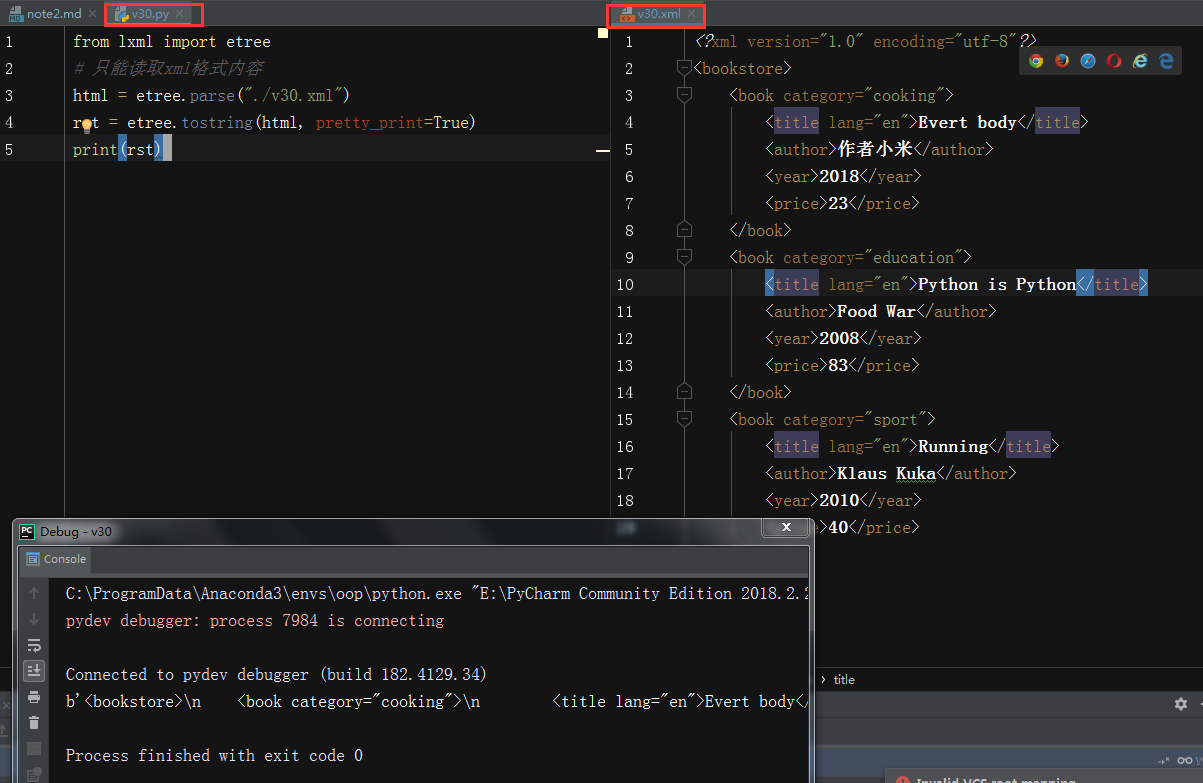
- 文件读取,案例v30.xml,v30.py
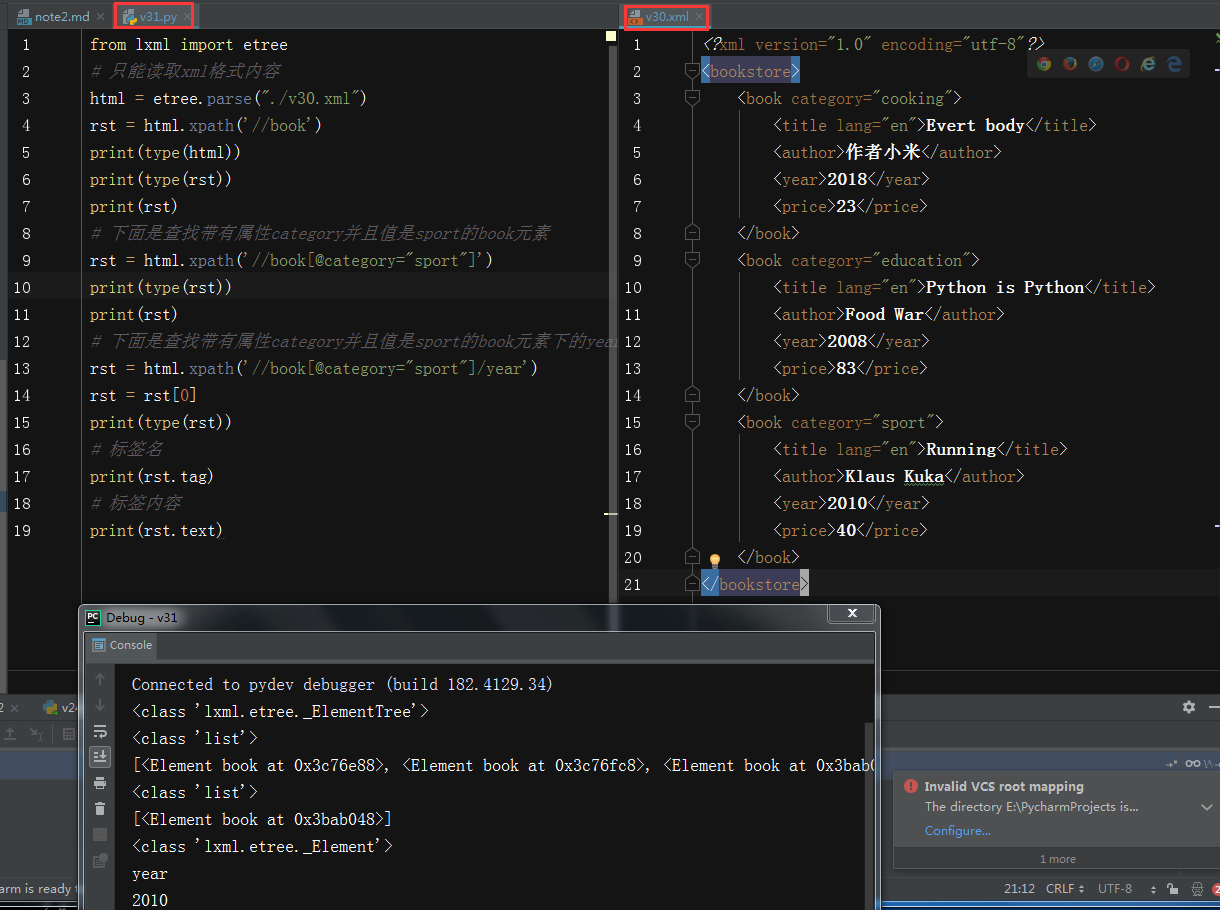
- etree和xpath配合使用,案例v31.py
# CSS选择器 BeautifulSoup4
- 现在使用BeautifulSoup4
- 安装pip install beautifulsoup4
- 官网http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
- 几个常用提取信息工具的比较:
- 正则:很快,不好写,无需安装
- beautifulsoup:慢,使用简单,安装简单
- lxml:比较快,使用简单,安装简单
- 案例v33
- 四大对象
- Tag
- NavigableString
- BeautifulSoup
- Comment
- Tag
- 对应html中的标签
- 可以通过soup.tag_name
- tag两个重要属性
- name
- attrs
- 案例v34
- NavigableString
- 对应内容值
- 案例v34
- BeautifulSoup
- 表示的是一个文档的内容,大部分的时候可以把它当做tag对象
- 一般我们可以用soup表示
- Comment
- 特殊类型的NavigableString对象
- 其输出的内容,不包括注释符号(会把原本注释掉的内容输出)
- 举例:
# 打印a标签里面的文本
print(soup.a.string)
- 遍历文档对象
- contents:tag的子节点以列表的方式输出
- children:子节点以迭代器形式返回
- descendants:所有子孙节点
- string
- 案例v34
- 搜索文档对象
- find_all(name, attrs, recursive, text, **kwargs)
- name:按照哪个字符串搜索,可以传入的内容为:
- 字符串
- 正则表达式
- 列表
- keyword参数,可以用来表示属性
- text:对应tag文本的值
- 案例34
- css选择器
- 使用soup.select,返回一个列表
- 通过标签名:soup.select("title")
- 通过类名:soup.select(".content")
- 通过id名:soup.select("#name_id")
- 通过上面组合查找:soup.select("div #input_content")
- 通过属性查找:soup.select("meta[content='always']")
- 获取tag内容:tag.get_text
- 案例v35

# 案例v34 from urllib import request from bs4 import BeautifulSoup url = "http://www.baidu.com" rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content, 'lxml') # prettify让页面更友好漂亮的显示,也就是转码 content = soup.prettify() print("==" * 12) print(soup.link) print(soup.link.name) print(soup.link.attrs) print(soup.link.attrs['type']) soup.link.attrs['type'] = 'ads' print(soup.link) print("==" * 12) print(soup.title) print(soup.title.name) print(soup.title.attrs) print(soup.title.string) print("==" * 12) print(soup.name) print(soup.attrs) print("==" * 12) # 打印head下面名字是meta的子节点 for node in soup.head.contents: if node.name == 'meta': print(node) if node.name == 'title': print(node.string) print("==" * 12) tags = soup.find_all(name='meta') print(tags) print("==" * 12) import re tags = soup.find_all(re.compile('^me.*$'), content="always") print(tags)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号