TensorFlow 学习报告
TensorFlow学习报告
1.从张量开始
1.1实际数据转为浮点数
-
Tensorflow提供 constant 这个函数:
constant(value, dtype=None, shape=None, name="Const", verify_shape=False)
-
零维张量
t = tf.constant(1, tf.float32)
-
一维张量
t = tf.constant([1, 2, 3, 4], tf.float32)
-
二维张量
t = tf.constant( [ [7, 8, 9, 10], [1, 2, 3, 4] ], tf.float32 )
-
三维张量
- 三维张量可以理解为多个二维张量在深度上的一个组合,
t = tf.constant( [ [[1, 2], [3, 4]], [[5, 6], [7, 8]], [[9, 10],[11, 12]] ], tf.float32 )
相当于在第一个深度上有
[[1, 3],[5, 7],[9, 11]]
,而在第二个深度上有
[[2, 4],[6, 8],[10, 12]]
-
四维张量
- 四维张量可以理解为多个三维张量
t = tf.constant( [ # 第一个2行2列深度为2的三维张量 [ [[1, 2], [3, 4]], [[5, 6], [7, 8]] ], # 第二个2行2列深度为2的三维向量 [ [[9, 10], [11, 12]], [[13, 14], [15, 16]] ] ] )
2.TensorFlow基本用法
TensorFlow是一种较为完善的深度学习框架,支持所有流行编程语言开发,如Python,C++等,此外还可在多种平台上工作。
在Tensorflow 2.x 的基本用法中,介绍两种风格的代码,一种使用低阶API进行代码编写,一种使用高阶API进行代码编写。整体上,我们推荐使用TensorFlow中的高阶API-tf.keras进行代码编写,但也需要读懂低阶API代码。
- 先建立模型,再编译模型
2.1 低阶API
2.1.1模型搭建常用函数
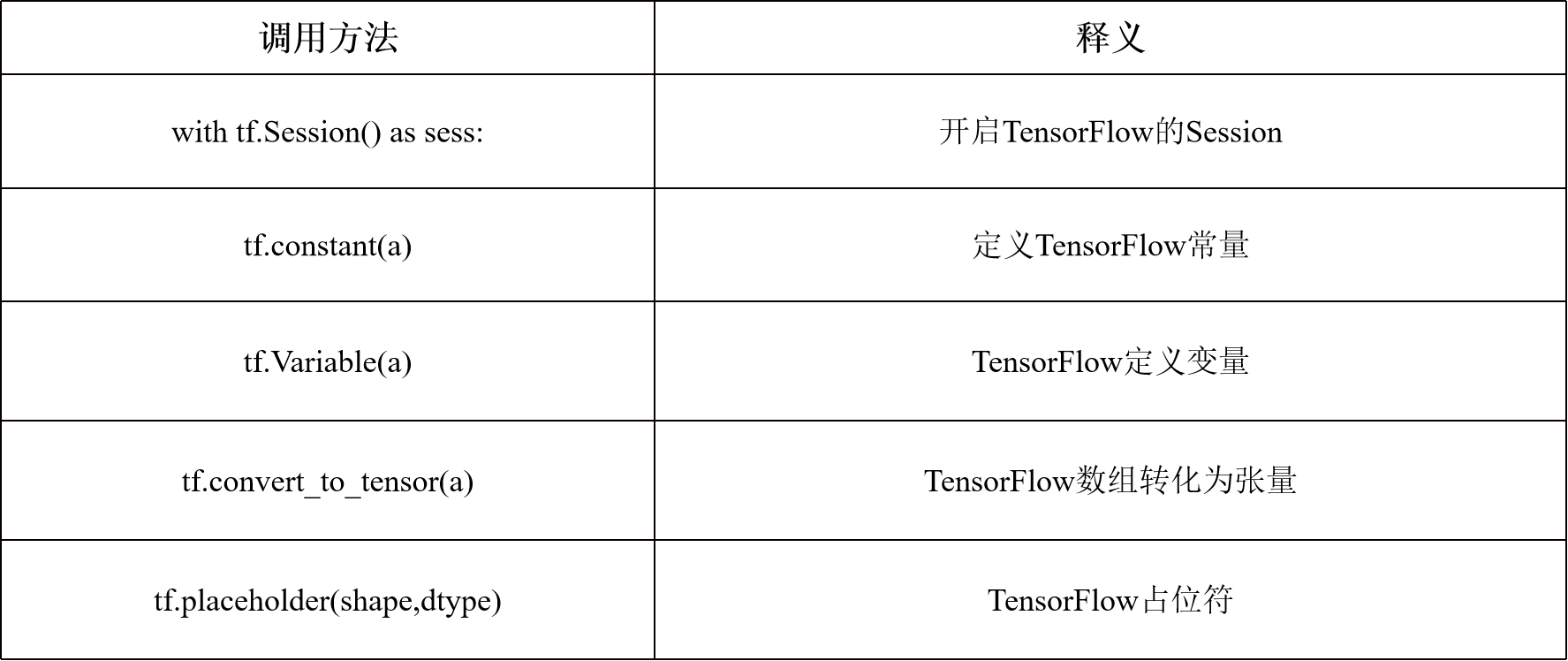

2.1.2 重点:损失函数
#MSE损失函数,主要用序列预测 tf.losses.MeanSquaredError #交叉熵损失函数,主要用于分类 tf.losses.categorical_crossentropy
2.2 高阶API
2.2.1 tf.keras构建模型
(1)“序贯式”
先通过构造函数创建一个Sequential模型,再通过model.add依次添加不同层
model = tf.keras.Sequential() #创建一个全连接层,神经元个数为256,输入为784,激活函数为relu model.add(tf.keras.layers.Dense(256,activation='relu',input_dim=784)) model.add(tf.keras.layers.Dense(128,activation='relu')) model.add(tf.keras.Dense(10,activation='softmax'))
(2)“函数式”
使用tf.keras构建函数模型,常用于更复杂的网络构建。
inputs = tf.keras.layers.Input(shape=(4)) x = tf.keras.layers.Dense(32,activation='relu')(inputs) x = tf.keras.layers.Dense(64,activation='relu')(x) outputs = tf.keras.layers.Dense(3,activation='softmax')(x) model = tf.keras.Model(inputs = inputs,outputs = outputs)
2.2.2 model.compile编译模型
oplimizer:优化器,可从 tf.keras.optimizers 中选择;
loss :损失函数,可从 tf.keras.losses 中选择;
metrics :评估指标,可从 tf.keras.metrics 中选择。
model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=[tf.keras.metrics.sparse_categorical_accuracy] )
2.2.3 Model.fit模型训练
tf.keras.Model.fit接受的一些重要参数:
x :训练数据;
y :目标数据(数据标签);
epochs :将训练数据迭代多少遍;
batch_size :批次的大小;
validation_data :验证数据,可用于在训练过程中监控模型的性能。
model.fit(data_loader.train_data, # 训练集数据 data_loader.train_label, # 训练集标签 epochs=num_epochs, # 训练轮次 batch_size=batch_size # 批量大小 )
2.2.4 模型评估与测试
evaluate:该函数将对所有输入和输出对预测,并且收集分数,包括损失还有其他指标。提供测试数据及标签即可。
model.evaluate(data_loader.test_data, data_loader.test_label)
predict:该函数给出模型输入对应的输出。
model.predict(data_loader.test_data)
3. 课后练习
3.1、局部连接:层间神经只有局部范围内的连接,在这个范围内采用全连接的方式,超过这个范围的神经元则没有连接;连接与连接之间独立参数,相比于去全连接减少了感受域外的连接,有效减少参数规模。
全连接:层间神经元完全连接,每个输出神经元可以获取到所有神经元的信息,有利于信息汇总,常置于网络末尾;连接与连接之间独立参数,大量的连接大大增加模型的参数规模。
3.2、利用快速傅里叶变换把图片和卷积核变换到频域,频域把两者相乘,把结果利用傅里叶逆变换得到特征图。
3.3、池化操作作用:池化层同样基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。
激活函数作用:将A-NN模型中一个节点的输入信号转换成一个输出信号。该输出信号现在被用作堆叠中下一个层的输入。
3.4、局部归一化的作用:对局部神经元的活动创建了竞争环境,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛华能力。
3.5、 寻找损失函数的最低点,就像我们在山谷里行走,希望找到山谷里最低的地方。那么如何寻找损失函数的最低点呢?在这里,我们使用了微积分里导数,通过求出函数导数的值,从而找到函数下降的方向或者是最低点(极值点)。损失函数里一般有两种参数,一种是控制输入信号量的权重(Weight, 简称 ),另一种是调整函数与真实值距离的偏差(Bias,简称
)。我们所要做的工作,就是通过梯度下降方法,不断地调整权重
和偏差b,使得损失函数的值变得越来越小。而随机梯度下降算法只随机抽取一个样本进行梯度计算。
4.程序
# TensorFlow and tf.keras import tensorflow as tf from tensorflow import keras # Helper libraries import numpy as np import matplotlib.pyplot as plt #print(tf.__version__) fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False) plt.show() train_images = train_images / 255.0 test_images = test_images / 255.0 plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]]) plt.show() """构建模型""" model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10) ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) """训练模型""" model.fit(train_images, train_labels, epochs=10) """评估准确率""" test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print('\nTest accuracy:', test_acc) """进行预测""" probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()]) predictions = probability_model.predict(test_images) predictions[0] np.argmax(predictions[0]) test_labels[0] def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array, true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array, true_label[i] plt.grid(False) plt.xticks(range(10)) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue') i = 0 plt.figure(figsize=(6, 3)) plt.subplot(1, 2, 1) plot_image(i, predictions[i], test_labels, test_images) plt.subplot(1, 2, 2) plot_value_array(i, predictions[i], test_labels) plt.show() i = 12 plt.figure(figsize=(6, 3)) plt.subplot(1, 2, 1) plot_image(i, predictions[i], test_labels, test_images) plt.subplot(1, 2, 2) plot_value_array(i, predictions[i], test_labels) plt.show() # Plot the first X test images, their predicted labels, and the true labels. # Color correct predictions in blue and incorrect predictions in red. num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2 * 2 * num_cols, 2 * num_rows)) for i in range(num_images): plt.subplot(num_rows, 2 * num_cols, 2 * i + 1) plot_image(i, predictions[i], test_labels, test_images) plt.subplot(num_rows, 2 * num_cols, 2 * i + 2) plot_value_array(i, predictions[i], test_labels) plt.tight_layout() plt.show()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号