图像识别项目算法测试
一、前言
之前有一段时间在负责以图搜图项目的测试工作,接到这个项目的时候 有点懵,不知道从何开始,咨询了公司同一条业务线的大佬们,都没有接过这种算法项目,没办法,只能赶鸭子上架,自行百度查找各种AI算法相关的测试知识,所以想记录一下整个项目过程,以及通过这个项目学习到的一些算法相关的皮毛知识 ,整篇属于比较理论。
二、需求分析过程
1、了解需求
整个需求分析过程,总的来说,一头雾水,没有需求文档,以口相授,即是以图搜图,类似百度识图,可以搜索出相似的图片,所以我百度了下以图搜图的概念。
“以图搜图”正式的名称应该叫“相似图像搜索引擎”,也称为“反向图片搜索引擎”。最初的图像搜索引擎是基于文本关键字检索的,比如图像的文件名和路径名、图像周围的文本,以及Alt标签中的注释索引,然而有时图像周边的这些文本信息和图像并没有关系,会造成搜索出来的部分图像结果和查询关键词并不一致,所以为了提高准确率,同时也随着人工智能(特别是深度学习理论和技术)的发展,诸多主流图像搜索引擎纷纷引入了深度学习算法来提高图像搜索的准确率,像日常使用的百度、搜狗等通用搜索引擎均提供了相似图像检索功能,淘宝、京东等电商平台也利用自己庞大的商品图像库开发了垂直领域内的图像检索功能来满足消费者们不易用文字描述的商品搜索需求。
而我所要负责的项目,即是类似淘宝的图像检索,主要用于搜索衣服的布料图片,算是有自己的布料商品图像库吧。
2、算法是如何实现的
整个模型预测流程是怎么样的?数据是如何处理的?用的是什么算法?下面贴2张网上的算法内容图
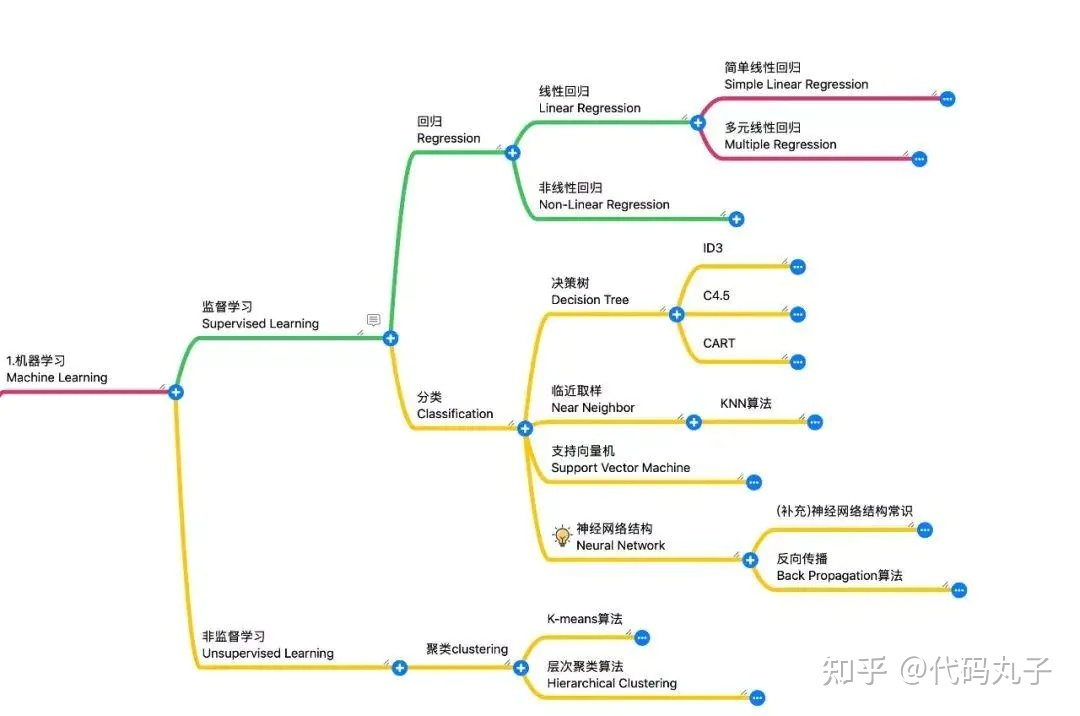
图1:机器学习

图2:深度学习
以图搜图的关键技术叫做“感知哈希算法”,这是一个很简单且快速的算法,其原理在于针对每一张图片都生成一个特定的“指纹”,然后采取一种相似度的度量方式得出两张图片的近似程度。图3是图像搜索引擎架构图,用于生成特征索引库的图像数据集,尽量扩充用于构建特征索引库的数据集的规模和覆盖面,使其有一定的广度和深度,收集一定量的垂直领域数据集来微调模型,使提取的特征更加符合该领域的特点。

图3:图像搜索引擎架构
3、测试人员需要给出的评价指标
领导灵魂拷问"如何判断搜出来的数据是准确的?",“有没有什么指标可以衡量?”,个人比较肤浅地认为,能搜出相似图片即可(比较主观)
三、测试流程
前面粗略了解完需求后,算法工程师需要测试去配合他们优化新开发的“图像搜索引擎”,如图4是大致的测试流程。然而针对流程中的几个环节,又开始着手准备进入扫盲阶段了。
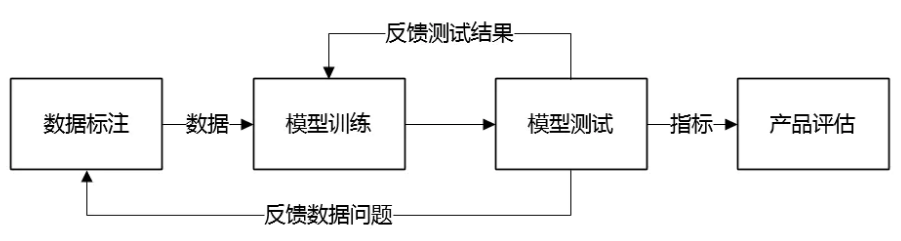
图4:图像搜索引擎优化流程
四、数据标注
这个阶段其实是准备图片数据集给算法工程师训练模型,一般算法工程师会将整个数据集,自己划分为训练集、验证集、测试集。或者训练集、验证集 等等。
1、什么是数据标注
数据标注是通过数据加工人员借助类似于BasicFinder或labelImg这样的标记工具,对人工智能学习数据进行加工的一种行为。通常数据标注的类型包括:图像标注、语音标注、文本标注、视频标注等种类。标记的基本形式有标注画框、3D画框、文本转录、图像打点、目标物体轮廓线等。
类比机器学习,我们要教他认识一个苹果,你直接给它一张苹果的图片,它是完全不知道这是个啥玩意的。我们得先有苹果的图片,上面标注着“苹果”两个字,然后机器通过学习了大量的图片中的特征,这时候再给机器任意一张苹果的图片,它就能认出来了。
机器学习分为有监督学习和无监督学习,无监督学习的效果是不可控的,常常是被用来做探索性的实验。而在实际产品应用中,通常使用的是有监督学习,有监督的机器学习就需要有标注的数据来作为先验经验。
2、训练集和测试集的概念
训练集和测试集都是标注过的数据,还是以苹果为例子,假设我们有1000张标注着“苹果”的图片,那么我们可以拿900涨作为训练集,100张作为测试集。机器从900张苹果的图片中学习得到一个模型,然后我们将剩下的100张机器没有见过的图片去给它识别,然后我们就能够得到这个模型的准确率了。
3、数据收集方向
思考什么情况下可能会影响到算法识别,所以需要考虑以下问题:
- 需要什么样的测试数据——真实用户场景:商品库包含纯色面料和花型图
- 测试数据要多少,照片数据覆盖是否全面——覆盖纯色面料图和花型图
- 测试数据的数量和训练数据的比例合理——当数据量比较小时,可以使用 7 :3 训练数据和测试数据
- (西瓜书中描述 常见的做法是将大约 2/3 ~ 4/5 的样本数据用于训练,剩余样本用于测试)
4、测试数据的标注
- 纯色面料图:每组3-5张图片,共20组左右
- 花型图:每组花型包含3-5张图片,共500组左右
- 不分组:200张图片左右,包含纯色和花型图
五、模型训练
一般情况下,模型训练是由算法部门来进行完成的,对于模型训练来说,产品方一定要给到具体的需求,这样既可以提高效率,也能够增加准确率。
六、模型测试
1、模型测试指标
- 精确率:识别为正确的样本数/识别出来的样本数
- 召回率:识别为正确的样本数/所有样本中正确的数
2、测试脚本
测试脚本主要功能:批量运行所有测试数据,记录模型预测值,和标注值进行,计算得出评价指标。
3、竞品对比测试
跟百度识图进行对比测试:
- 通过百度识图拿到的图片数据,进行数据清洗
- 将清洗过的图片数据,生成商品库数据
- 后台成功建立特征索引库后,在图像识别工具进行搜索,将搜索的结果跟百度识图进行对比
- 最后将对比结果反馈给开发
4、结果分析
查看评价指标。
七、产品评估&上线
不管是机器学习,推荐系统,图像识别还是自然语言处理,都需要有一定量的测试数据来进行运行测试。
算法测试的核心是对学习器的泛化误差进行评估。为此是使用测试集来测试学习器对新样本的差别能力。然后以测试集上的测试误差作为泛化误差的近似。测试人员使用的测试集,只能尽可能的覆盖正式环境用户产生的数据情况。正式环境复杂多样的数据情况,需要根据上线后,持续跟进外网数据。算法模型的适用性一定程度上取决于用户数据量,当用户量出现大幅增长,可能模型会随着数据的演化而性能下降,这时模型需要用新数据来做重新训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号