


(Review cs231n) Training of Neural Network2
FFDNet---matlab 调用并批处理
format compact; global sigmas; % input noise level or input noise level map addpath(fullfile('utilities')); folderModel = 'models'; folderResult= 'results'; save_folder = 'datasets_c'; showResult = 1; useGPU = 0; % CPU or GPU. For single-threaded (ST) CPU computation, use "matlab -singleCompThread" to start matlab. pauseTime = 0; imageNoiseSigma = 50; % image noise level inputNoiseSigma = 50; % input noise level load(fullfile('models','FFDNet_gray.mat')); net = vl_simplenn_tidy(net); if useGPU net = vl_simplenn_move(net, 'gpu') ; end file_name = 'E:\QQ\401668597\FileRecv\af2019-cv-training-20190312\'; sub_file_name_list = dir(file_name); %获取所有子文件夹 num_sub_file = length(sub_file_name_list); if num_sub_file>0 for fn = 3:num_sub_file image_file = ['E:\QQ\401668597\FileRecv\af2019-cv-training-20190312\',sub_file_name_list(fn).name,'\']; image_file_b = [image_file,'*_c.jpg']; image_list = dir(image_file_b); %得到该文件夹的所有图像的名字 for in = 1:length(image_list) image_name = [image_file,image_list(in).name]; fprintf('%d,%s',in,image_name); %开始进行处理 label = imread(image_name); %打开图像 [w,h,~]=size(label); if size(label,3)==3 label = rgb2gray(label); end label = im2double(label); % add noise randn('seed',0); noise = imageNoiseSigma/255.*randn(size(label)); input = single(label + noise); if mod(w,2)==1 input = cat(1,input, input(end,:)) ; end if mod(h,2)==1 input = cat(2,input, input(:,end)) ; end % tic; if useGPU input = gpuArray(input); end % set noise level map sigmas = inputNoiseSigma/255; % see "vl_simplenn.m". % perform denoising res = vl_simplenn(net,input,[],[],'conserveMemory',true,'mode','test'); % matconvnet default % res = vl_ffdnet_concise(net, input); % concise version of vl_simplenn for testing FFDNet % res = vl_ffdnet_matlab(net, input); % use this if you did not install matconvnet; very slow % output = input - res(end).x; % for 'model_gray.mat' output = res(end).x; if mod(w,2)==1 output = output(1:end-1,:); input = input(1:end-1,:); end if mod(h,2)==1 output = output(:,1:end-1); input = input(:,1:end-1); end if useGPU output = gather(output); input = gather(input); end if showResult %imshow(cat(2,im2uint8(input),im2uint8(label),im2uint8(output))); imshow(cat(2,im2uint8(input),im2uint8(output))); save_dir = [save_folder,image_list(in).name] imwrite(output,save_dir); % %imwrite(im2uint8(output), fullfile(folderResultCur, [nameCur, '_' num2str(imageNoiseSigma,'%02d'),'_' num2str(inputNoiseSigma,'%02d'),'_PSNR_',num2str(PSNRCur*100,'%4.0f'), extCur] )); drawnow; pause(pauseTime) end end end end
Adam不会让你的学习速率降为0,因为它是leaky gradient; 如果使用的是Adagrad, 学习率最后会自动的下降为0。
集成学习
1. 对训练集中大量独立的模型进行训练,而不仅仅对于单一模型;
2.在测试的时候将结果进行平均。(效果可以提高2%的提升)
使用集成学习的小技巧
当你在训练神经网络时设置一些检查点,通常是每个时期建立一个,对每个检查点都去验证这在验证集中的表现。
这说明你可以在模型中设置不同的检查点,然后在处理集合中使用它们,这被证明能够使得结果有所改善,这样的话你不需要对不同的独立模型进行训练,而只需要训练一下,但是需要设置相应的检查点。
while True: data_batch = dataset.sample_data_batch() loss = networdk.forward(data_batch) dx = network.backward() x +=-learning_rate * dx x_test = 0.995*x_test + 0.005*x # use for test set 类似于一个加权的加权的概念
设定了另一个参数集合x_test,x_test是对我现在的参数x的一个指数衰减,当使用x_test和数据集和验证集的时候,得到的结果总是要比使用x更好,这就像一个之前一些参数进行加权的集合。
想一下对你的碗装函数进行优化,在最低点周围不停的移动,然后做一个对这些所有的一个平均值,能够更加接近最低点。
Regularization(dropout)
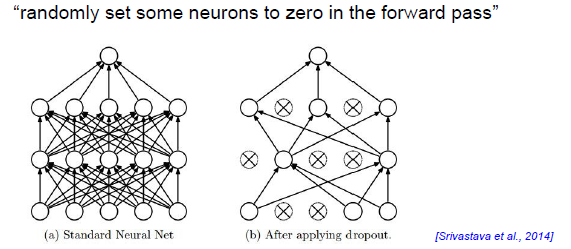
然你的神经网络的节点随机失活,随机把一些神经元置零,
p = 0.5 #probablity of keeping a unit active. higher = less dropout def train_setp(X): #forward pass for example 3-layer neural network H1 = np.maximum(0, np.dot(W1, X) + b1) # first dropout mask U1 = np.random.rand(*H1.shape) < p #产生了一个bool型的和 H1相同维度的矩阵,乘一个二进制数U1,U1为0或1,这个数取决于一个值大于0小于1的数
它比P大还是比P小,np.random.rand(*H1.shape)是一个和H1相同维度的数组.U1是一个以
50%概率输出0或1的过滤器,让隐藏层激活函数乘以这个过滤器,使得激活函数中的一半失活。
H1 *= U1
H2 = np.maximum(0,np.dot(W2,H1)+b)
U2 = np.random.rand(*H2.shape) <p
H2 *= U2
out = np.dot(H2, W3) + b3
前向传播中每一层都失活一半,在反向传播中也要使用随机失活; 随机失活一定在两个过程都要用,在反向传播中也要让梯度乘以U1和U2(两个随机失活过滤器),让一部分梯度失活。
失活的为什么好?
1. 我们只用网络的一半,网络的表达能力会变小很多,就能减小在训练中涉及的变量数(从而减少过拟合的概率)。
偏差-方差均衡的概念。

用神经网络计算猫的分数,随机失活的作用就是强制你的代码,使你的表示对于图片的表示是冗余的,你需要这个冗余,因为你并不能控制在随机失活的过程,所有你需要让猫的分数依赖更多的特征,每一个特征都可能失活,无论某个决定性特征是否被失活的情况下进行准确的分类。
2. 训练一个由很多小模型集成而成的大模型,每个子网络和原网络之间并不能很好的分享参数,在反向传播中只有我们在正向传播中用到的神经元的参数才会被更新,关闭就不会有梯度更新。
如果神经元失活,前一层的所有与这个神经元的连接都不会更新,所以在随即失活过程中,你其实只是训练了一个在某一次取样中,原网络的一部分。 换句话来说,每一个随机失活后的网络,都是一个新的模型,他只会被数据训练一次。
当你们失活一个神经元的时候,就是把这个神经元的输出值乘0,那么它对于损失函数没有影响,在反向传播中他的梯度就是0,他的值在计算损失函数中没有用到,权值就不再更新。
如果取样了网络的一部分,我们只会用一个数据点来训练这个子网络(因为每次循环中都有新的子网络)。
一般每次保留50%,用这种方式训练子网络都一样大。
每一层的结果乘失活的掩码,然后才得到失活的结果,也就是说没有对神经元进行改变,而只是对输出的值进行了改变。
在每次循环中,我们先得到一个mini-batch,然后在神经网络中取样,得到哪些没有失活的神经元,组成子网络。然后进行前向和反向的传播,从而得到梯度,更新参数。
失活的比例选择
对于参数规模比较大的,需要进行强正则的话,这些层可以失活很多神经元;在卷积神经网络中,规模比较小,失活的比例应该小一些。 前几层失活少,后多。
能不能针对每一个神经元进行一定概率的失活?
这招叫做 dropout connect
dropout的使用在测试和训练过程中的表现

这个神经元更新的期望值实际上是测试环节中的一半,所以在测试环节中,你想用全部的神经元,必须补偿多出来的一半,这个一半实际上是因为我们在失活的失活用的概率是50%。
所以在测试环节的前向传播,所以神经元都要乘0.5,如果不这样做,输出分布会改变。通过降低激活函数的输出值来改变输出的期望。
# 定义测试 的前向传播 def predict(X): #ensemble forward pass H1 = np.maximum(0,np.dot(W1,X)+b1) * p #Note:scale H2 = np.maximum(0,np.dot(W2,H1)+b2) *p # Note:scale out = np.dot(w3,H2) +b3
P就是随机失活的概率,在这里就是一半,这个P降低了激活函数的值,所以输出值的期望也就和训练环节中的期望值输出一样了,修正随机失活造成的影响。
使得使用dropout后的训练和测试的期望输出值能够匹配。
反向失活也是处理训练和测试差异的方法,如下
p = 0.5 #probablity of keeping a unit active. higher = less dropout def train_setp(X): #forward pass for example 3-layer neural network H1 = np.maximum(0, np.dot(W1, X) + b1) # first dropout mask U1 = np.random.rand(*H1.shape) < p /p #产生了一个bool型的和 H1相同维度的矩阵,乘一个二进制数U1,U1为0或1,这个数取决于一个值大于0小于1的数 它比P大还是比P小,np.random.rand(*H1.shape)是一个和H1相同维度的数组.U1是一个以 50%概率输出0或1的过滤器,让隐藏层激活函数乘以这个过滤器,使得激活函数中的一半失活。 H1 *= U1 H2 = np.maximum(0,np.dot(W2,H1)+b) U2 = np.random.rand(*H2.shape) <p /p H2 *= U2 out = np.dot(H2, W3) + b3
在H1乘以U1这个随机失活矩阵之前,让U1除以失活的概率,也是让U1值变大,训练过程中扩大,测试时就可以不乘以P,不管测试环节,让训练中的激活函数变大,修正了测试和训练之间的差异,这种反向失活最为常见。
反向失活对系统的影响最小,在反向传播中也是小的改动,能够让网络提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号