AI 十大论文精讲(二):GPT-3 论文全景解析——大模型 + 提示词如何解锁 “举一反三” 能力?
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第二篇——《Language Models are Few-Shot Learners》论文。
@
- 系列文章前言
- 前言:AI 重大突破!GPT-3 论文横空出世
- 一、技术背景:为什么这篇论文能成为“突破”?
- 二、论文深度解读
- 结语:改变 AI 发展轨迹的“里程碑”
前言:AI 重大突破!GPT-3 论文横空出世
2020年,OpenAI 发表的《Language Models are Few-Shot Learners》(简称 GPT-3 论文)彻底改写了 AI 领域的发展轨迹。这篇论文没有提出全新的模型架构,却用“堆规模+提提示词”的简单逻辑,解锁了语言模型的“举一反三”能力,让 AI 从“需要专属训练”的工具,变成了“能听懂指令”的通用助手。下面我们将用通俗易懂的语言详细解读这篇里程碑式的论文。
一、技术背景:为什么这篇论文能成为“突破”?
此前 NLP 领域的主流范式是“预训练+任务特定微调”:模型先在海量文本上预训练,再针对每个下游任务(如翻译、问答),用数千至数万条标注数据微调。这种方法存在三大局限:一是需为每个任务单独准备大规模标注数据,难以覆盖海量潜在语言任务;二是模型易过度拟合任务特定分布,泛化到新场景时性能下滑;三是与人类学习模式脱节——人类仅需少量示例或自然语言指令就能掌握新任务。论文核心目标是突破这一范式,验证“模型规模扩大是否能解锁任务无关的少样本学习能力”。
例如:若要构建 “电影评论情感分析” 模型,需基于 IMDb 数据集(含 5 万条带 “正面 / 负面” 标签的评论)进行微调,每条数据都需人工标注情感倾向
二、论文深度解读
1、核心发现:模型规模+提示词,解锁“上下文学习”
论文的核心结论是“缩放语言模型能极大提升任务无关的少样本性能”:当 Transformer 模型参数规模扩大到 1750 亿(GPT-3),无需任何梯度更新或任务特定微调,仅通过文本交互(自然语言指令+少量任务示例),就能在翻译、问答、算术、单词重组等数十个 NLP 任务中实现高性能。这种能力被定义为“上下文学习(in-context learning)”——模型在推理时,通过输入序列中的任务描述和示例,自主识别任务模式并完成后续实例,本质是模型预训练阶段习得的通用模式识别能力在推理时的快速适配。
用简单的话来说,就是AI 的“大脑”够大,再给它几句“提示”,它就会自己琢磨规律 。GPT-3 的“大脑”有 1750 亿个“神经元”(参数),相当于给模型装了一个超级知识库。它不用针对每个任务重新“上课”(微调),只要你用大白话描述需求,再给几个例子,它就懂了
论文将上下文学习定义为‘元学习的内循环’—— 外循环是模型在预训练阶段习得‘模式识别能力’(如识别‘示例→任务逻辑’的映射),内循环是推理时通过输入的‘指令 + 示例’,在 forward-pass 中快速适配任务(无需更新权重)。例如学习‘翻译’时,模型通过‘hello→bonjour’等示例,自主推断‘输入英文→输出对应法语’的逻辑,而非依赖任务特定微调的权重更新”。
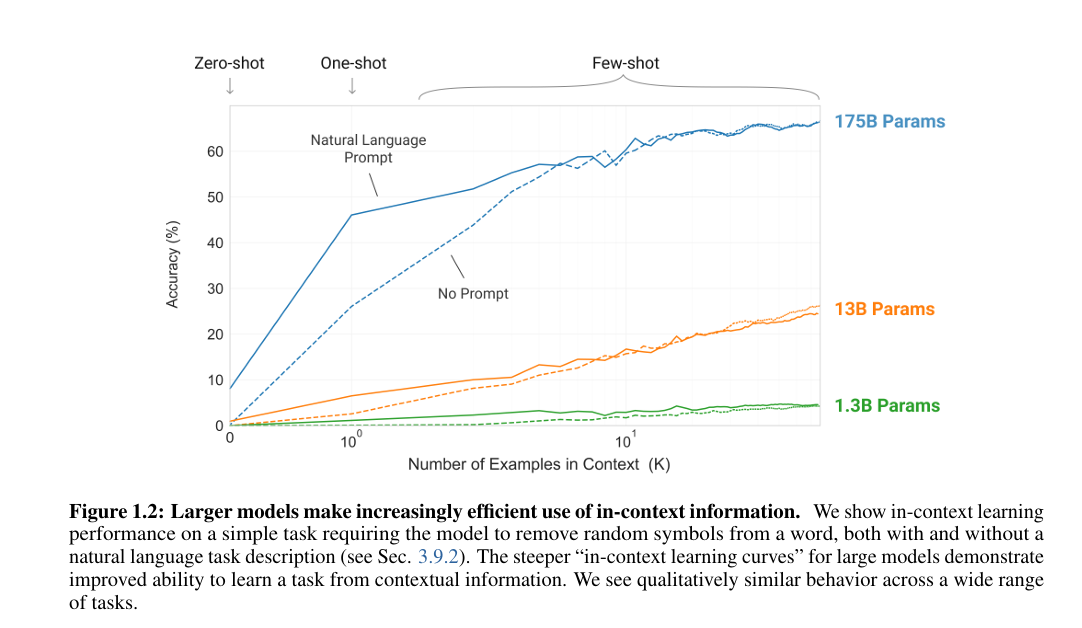
图 1.2:更大规模的模型对上下文信息的利用效率不断提升。我们展示了模型在一项简单任务上的上下文学习表现 —— 该任务要求模型从单词中移除随机符号,测试分为提供自然语言任务描述和不提供自然语言任务描述两种情况(见 3.9.2 节)。大模型更陡峭的 “上下文学习曲线” 表明,其从上下文信息中学习任务的能力有所提升。我们发现,在各类任务中,模型均表现出定性上相似的行为模式。
论文将学习场景分为三类:
- 零样本(Zero-shot):仅给自然语言指令,无任何示例;
- 单样本(One-shot):1 个任务示例+自然语言指令;
- 少样本(Few-shot):10-100 个任务示例(适配模型 2048 token 上下文窗口)+自然语言指令。
具体解释如下:
零样本(Zero-shot):仅用自然语言指令描述任务,如‘将以下英文翻译成法语’;
单样本(One-shot):1 个示例 + 指令,且示例需与任务格式一致,如‘翻译示例:hello→bonjour;请翻译:world’;
少样本(Few-shot):示例数量≤模型上下文窗口(GPT-3 为 2048 token),通常 10-100 个,且示例需随机从训练集抽取(避免数据污染),如 LAMBADA 任务因无训练集,示例从开发集抽取

2、GPT-3 模型与训练:超级大脑是怎么“练出来”的?
-
模型架构:基于 GPT-2 的 autoregressive Transformer 架构,采用交替密集型和局部带状稀疏注意力模式,上下文窗口为 2048 token;共训练 8 个模型变体,参数规模从 1.25 亿到 1750 亿,核心模型 GPT-3 含 96 层、12288 维模型维度、96 个注意力头。
-
训练数据:混合过滤后的 Common Crawl(开放网页爬取数据仓库,4100 亿 token,占比 60%)、WebText2(OpenWebText 数据集的增强版本,190 亿 token)、Books1/2(互联网书籍语料库,670 亿 token)、Wikipedia(Wikimedia 基金会运营的 免费协作式百科全书,30 亿 token),总计约 5000 亿 token;通过质量过滤、模糊去重提升数据质量,训练时按数据质量加权采样。
-
训练过程:使用 Adam 优化器,批量大小 3200 万 token,学习率余弦衰减,训练总量 3000 亿 token,依托微软高带宽 GPU 集群完成训练,总计算量达数千 petaflop/s-days。
3、实验验证:多任务场景下的性能拆解与深度分析
论文围绕“零样本(Zero-shot)、单样本(One-shot)、少样本(Few-shot)”三大场景,在 9大类40+ NLP任务 中系统验证了GPT-3的能力——从传统语言建模到即时推理,从闭卷问答到文本生成,覆盖“理解”与“生成”两大核心能力。以下结合论文原文的任务定义、实验设置、成绩对比,逐类拆解关键结果。
3.1 语言建模、Cloze与文本完成任务:夯实长文本理解基础
这类任务聚焦“模型对文本规律的捕捉能力”,包括传统语言建模(测单词预测)、Cloze任务(测上下文补全)、长文本完成(测长距离依赖),是语言模型的核心基础能力。
3.1.1 传统语言建模(Penn Tree Bank, PTB)
- 任务背景:PTB是经典语言建模数据集,包含华尔街日报文本,需模型预测下一个单词,以“困惑度(Perplexity,越低越好)”为指标。论文选择PTB的核心原因是“其诞生早于现代互联网,无训练数据污染风险”(其他维基类数据集因含于GPT-3训练数据,未纳入)。
- 实验设置:仅零样本场景(因PTB无明确“示例-任务”划分,无法设计单/少样本),直接输入PTB测试集文本,让模型预测下一个单词。
- GPT-3成绩:零样本困惑度 20.5。
- 对比SOTA:此前零样本SOTA为GPT-2的35.8,GPT-3降低15.3个点,降幅超40%,证明大模型对“基础语言规律”的捕捉能力显著提升。
3.1.2 LAMBADA:长距离依赖建模的突破
- 任务背景:LAMBADA是测“长文本理解”的标杆任务——给定一段长段落(平均200词),模型需准确预测最后一个单词(需关联段落前文信息,而非局部上下文)。此前研究认为“模型规模翻倍仅带来1.5%准确率提升”,质疑规模的价值。
- 实验设置:
- 零样本:直接让模型预测最后一个词,无任何示例;
- 单/少样本:设计“填空格式”引导模型(如“Alice was friends with Bob. Alice went to visit her friend . →Bob”),少样本K=15(适配2048 token窗口),因LAMBADA无训练集,示例从开发集抽取。
- GPT-3成绩(表3.2):
- 零样本:准确率76.2%,困惑度3.00;
- 单样本:准确率72.5%,困惑度3.35(单样本性能略低,因模型需多个示例理解“填空格式”);
- 少样本:准确率 86.4%,困惑度1.92。
- 对比SOTA:此前SOTA为Turing-NLG(17B参数)的68.0%(Tur20),GPT-3少样本提升18.4个点,直接打破“规模对长距离依赖无效”的质疑。论文指出:“少样本格式解决了传统LM的核心痛点——模型无需猜测‘是否预测最后一词’,通过示例明确任务目标”。
3.1.3 StoryCloze与HellaSwag:文本逻辑连贯度验证
- 任务背景:
- StoryCloze(2016):给定5句故事的前4句,需选择“符合逻辑的第5句结尾”(测故事逻辑连贯);
- HellaSwag:从4个选项中选“最合理的动作/事件续句”(如“妈妈在烤蛋糕,接下来会?”),选项为对抗性设计(机器难但人类易,人类准确率95.6%)。
- 实验设置:
- StoryCloze:少样本K=70(示例从开发集抽取);
- HellaSwag:少样本K=20,单/零样本直接给指令。
- GPT-3成绩(表3.2):
任务 零样本准确率 单样本准确率 少样本准确率 此前SOTA StoryCloze 83.2% 84.7% 87.7% 91.8%(LDL19,微调BERT) HellaSwag 78.9% 78.1% 79.3% 85.6%(LCH+20,微调ALUM) - 关键结论:GPT-3少样本成绩虽未超微调SOTA,但较零样本提升4-5个点,证明“示例可帮助模型捕捉文本逻辑”;且HellaSwag成绩超早期微调模型(如1.5B参数LM的75.4%),说明大模型的“常识逻辑”已接近部分微调模型。
3.2 闭卷问答:参数化知识的“记忆与调用”
闭卷问答(Closed-Book QA)是“无外部检索”的问答任务——模型需仅依赖预训练时内化的知识回答问题,而非调用搜索引擎,核心测“知识的参数化存储能力”。论文选择3个经典数据集:Natural Questions(NQs)、WebQuestions(WebQs)、TriviaQA。
3.2.1实验设置
- 任务定义:NQs/WebQs是“开放域短答案问答”(如“埃菲尔铁塔在哪”),TriviaQA是“常识类长答案问答”(如“《哈利·波特》作者是谁”);
- 场景设计:
- 零样本:仅给指令“回答以下问题”;
- 单/少样本:示例为“问题+正确答案”(如“Q:地球自转周期?A:24小时”),少样本K=64。
3.2.2GPT-3成绩与对比(表3.3)
| 数据集 | 场景 | GPT-3成绩 | 对比SOTA(微调模型) |
|---|---|---|---|
| TriviaQA | 零样本 | 64.3% | T5-11B(闭卷):60.5% |
| 单样本 | 68.0% | RAG(开卷+微调):68.0% | |
| 少样本 | 71.2% | 超所有闭卷微调模型,追平开卷模型 | |
| WebQuestions | 零样本 | 14.4% | T5-11B(闭卷):37.4% |
| 单样本 | 25.3% | - | |
| 少样本 | 41.5% | 接近T5-11B+SSM(44.7%) | |
| Natural Qs | 零样本 | 14.6% | T5-11B+SSM(闭卷):36.6% |
| 单样本 | 23.0% | - | |
| 少样本 | 29.9% | 差距较大,但较零样本翻倍 |
3.2.3关键发现
-
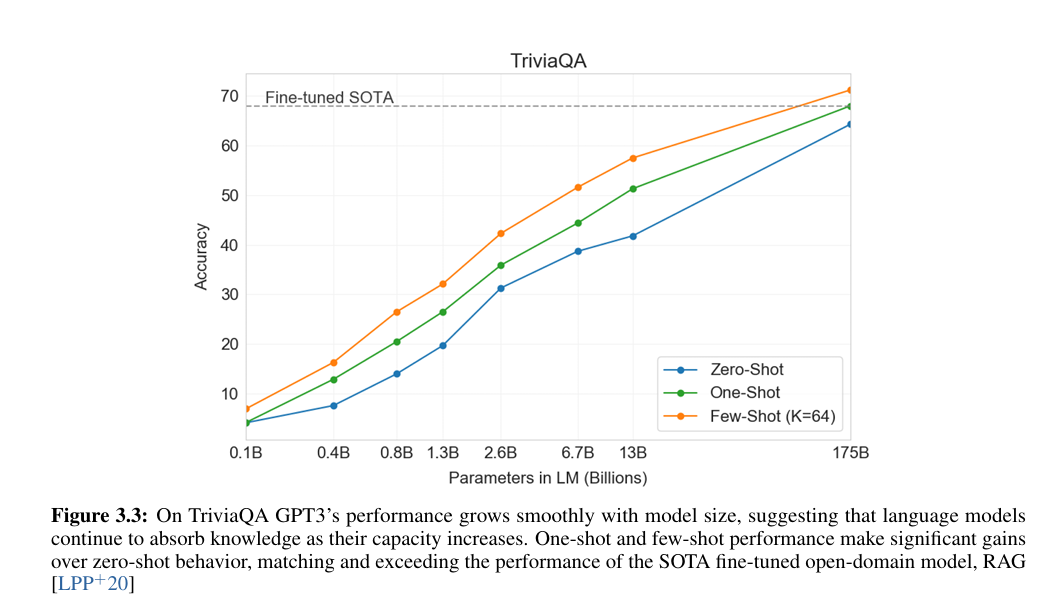
TriviaQA的突破:少样本71.2%不仅超闭卷微调模型(T5-11B的60.5%),还追平“开卷+微调”的RAG模型(68.0%),证明“大模型可将海量常识内化为参数,无需外部检索”(论文图3.3显示:模型规模每扩大10倍,TriviaQA准确率提升约15个点,呈线性增长);
![在这里插入图片描述]()
图 3.3:在 TriviaQA 数据集上,GPT-3 的性能随模型规模稳步提升,这表明语言模型会随着容量的增加持续吸收知识。单样本(one-shot)和少样本(few-shot)场景下的性能相较于零样本(zero-shot)有显著提升,其表现已达到并超越了最先进的微调开放域模型 RAG(检索增强生成)。 -
WebQs/NQs的差距:零样本成绩差(14%-15%),但少样本提升显著(WebQs从14.4%→41.5%),论文推测“这两个数据集的问题风格(如NQs依赖维基细节)与GPT-3训练数据分布差异大,示例帮助模型适配格式”。
3.3 机器翻译:跨语言能力的“少样本激活”
GPT-3的训练数据以英文为主(93%),但包含7%其他语言(来自Common Crawl),论文测试其在6个语言对的翻译能力,核心测“少样本示例能否激活跨语言映射能力”。
3.3.1实验设置
- 语言对:En→Fr、Fr→En、En→De、De→En、En→Ro、Ro→En(均为WMT经典测试集);
- 评价指标:BLEU分数(越高越好,用XLM的tokenization计算,便于对比无监督SOTA);
- 场景设计:
- 零样本:指令“将{源语言}翻译成{目标语言}”;
- 单/少样本:示例为“源句+译句”(如“En→Fr:hello→bonjour”),少样本K=64。
3.3.2GPT-3成绩与对比(表3.4)
| 语言对 | 场景 | GPT-3 BLEU | 对比无监督SOTA(XLM/MASS) |
|---|---|---|---|
| Fr→En | 零样本 | 21.2 | XLM:33.3 |
| 单样本 | 33.7 | 接近XLM | |
| 少样本 | 39.2 | 超MASS(34.9),接近监督SOTA(35.0) | |
| De→En | 零样本 | 27.2 | XLM:34.3 |
| 单样本 | 30.4 | - | |
| 少样本 | 40.6 | 超MASS(35.2),追平监督SOTA(40.2) | |
| En→Ro | 零样本 | 14.1 | XLM:33.3(差距大) |
| 单样本 | 20.6 | - | |
| 少样本 | 21.0 | 仍低于无监督SOTA |
3.3.3关键结论
- “入英优势”明显:GPT-3在“非英→英”(Fr→En、De→En)的少样本BLEU超无监督SOTA,甚至追平监督模型;但“英→非英”(En→Fr、En→De)成绩差——论文解释“训练数据英文占比高,模型更擅长将其他语言映射到英文,反之则因目标语言数据少,能力弱”;
- 小语种短板:En→Ro(罗马尼亚语)成绩低,因GPT-2的BPE分词器为英文设计,对罗马尼亚语的子词拆分不合理,导致跨语言映射误差大。
3.4 Winograd与常识推理:语义歧义的“理解能力”
这类任务测“模型对语义歧义的消解能力”——人类可通过常识判断代词指代或物理规律,但机器易受语法歧义干扰。论文重点测试Winograd Schema、Winogrande(对抗性Winograd)、PIQA(物理常识)、ARC(科学常识)等任务。
3.4.1 Winograd与Winogrande:代词指代消解
- 任务背景:Winograd Schema(如“市议员拒绝给抗议者颁发许可,因为他们害怕暴力”——“他们”指议员),Winogrande是对抗性版本(选项更难,人类准确率94%);
- 实验设置:用“部分评估法”(对比“正确上下文+答案”与“错误上下文+答案”的概率,取更高者为正确),少样本K=7(Winograd)、K=50(Winogrande);
- GPT-3成绩(表3.5):
任务 零样本准确率 单样本准确率 少样本准确率 此前SOTA(微调) Winograd 88.3%* 89.7%* 88.6%* 90.1%(SBBC19) Winogrande 70.2% 73.2% 77.7% 84.6%(LYN+20) 注:带因检测到部分数据污染,干净子集成绩下降2.6%,但仍接近SOTA。
3.4.2 PIQA与ARC:物理/科学常识推理
-
任务背景:
- PIQA(物理常识):测“日常物理动作的合理性”(如“如何给木头涂密封剂?A:用刷子涂满/B:滴上去”);
- ARC(科学常识):3-9年级科学题,分“Easy”(简单检索可答)和“Challenge”(需推理,如“植物光合作用需要什么”);
-
实验设置:PIQA少样本K=50,ARC少样本K=50;
-
GPT-3成绩(表3.6):
任务 场景 GPT-3成绩 此前SOTA(微调) PIQA 零样本 80.5%* 79.4%(RoBERTa) 单样本 80.5%* - 少样本 82.8%* 超SOTA(测试集成绩) ARC(Easy) 零样本 68.8% 92.0%(UnifiedQA) 单样本 71.2% - 少样本 70.1% 超RoBERTa基线(55.9%) ARC(Challenge) 少样本 51.5% 低于UnifiedQA(78.5%) -
关键结论:GPT-3在“物理常识(PIQA)”上表现突出,少样本超微调模型,证明“大模型可内化日常物理规律”;但“科学常识(ARC Challenge)”差距大,因需专业知识(如化学公式、生物原理),而GPT-3训练数据中这类结构化知识少。
3.5 阅读理解:复杂文本的“信息提取能力”
阅读理解任务测“从给定文本中提取答案的能力”,论文选择5个数据集(CoQA、DROP、QuAC、SQuADv2、RACE),覆盖“对话式、数值推理、多轮问答、多选”等不同格式。
3.5.1实验设置
- 任务差异:
- CoQA:对话式问答(如“Q1:谁写了《三体》?Q2:他还写了什么?”),评F1;
- DROP:数值推理问答(如“文本中提到3个人,2个离开,还剩几个?”),评F1;
- RACE:高中英语多选阅读(4个选项,评准确率);
- 场景设计:少样本K=5(CoQA)、K=20(DROP),示例为“文本+问题+答案”。
3.5.2GPT-3成绩与对比
| 任务 | 场景 | GPT-3成绩 | 此前SOTA(微调) |
|---|---|---|---|
| CoQA | 零样本 | 81.5 F1 | 90.7 F1(JN20) |
| 单样本 | 84.0 F1 | - | |
| 少样本 | 85.0 F1 | 仅差5.7 F1,接近人类水平(88 F1) | |
| DROP | 零样本 | 23.6 F1 | 89.1 F1(RLL+19) |
| 单样本 | 34.3 F1 | - | |
| 少样本 | 36.5 F1 | 超早期BERT基线(23 F1),但差SOTA多 | |
| RACE-h(高中) | 少样本 | 46.8% | 90.0%(SPP+19) |
3.5.3关键结论
- 对话式阅读(CoQA)优势:少样本85.0 F1接近人类,因CoQA格式贴近日常对话,与GPT-3训练数据中的“对话文本”分布匹配;
- 数值推理(DROP)短板:成绩低因需“离散计算”(如计数、减法),而GPT-3的上下文学习擅长“模式匹配”,不擅长显式逻辑计算;
- 考试类阅读(RACE)差:RACE题型为“多选+细节定位”,需严格匹配文本细节,而GPT-3易受“常识干扰”(如文本说“小明10岁”,选项说“小明9岁”,模型可能因常识“儿童多为9-10岁”误选)。
3.6 即时推理与合成任务:“举一反三”的核心能力
论文专门设计3类“合成任务”——算术、单词重组、新闻生成,测GPT-3的“即时学习能力”(即“看到新任务→通过示例快速掌握”),这些任务无公开SOTA,重点对比模型规模的影响。
3.6.1 算术任务:基础计算能力
-
任务设计:生成10类算术题(2-5位数加减、2位数乘法、1位数复合运算,如“6+(4*8)”),每类2000个随机实例,要求模型生成精确答案;
-
实验设置:少样本K=10(示例为“Q:1+1=?A:2”);
-
GPT-3成绩(表3.9):
任务 零样本准确率 单样本准确率 少样本准确率 2位数加法 76.9% 99.6% 100.0% 3位数减法 48.3% 78.7% 94.2% 2位数乘法 19.8% 27.4% 29.2% 1位数复合运算 9.8% 14.3% 21.3% -
关键发现:
- 小位数运算(2-3位加减)表现好,少样本接近100%;大位数(4-5位)或复杂运算(乘法、复合)成绩下降,但仍超所有小模型(如13B模型2位数加法仅50%);
- 无记忆污染:搜索训练数据仅0.8%的3位数加法题重叠,证明模型是“真正计算”而非“记忆答案”,错误多为“进位遗漏”(如“199+201=390”而非400)。
3.6.2 单词重组:符号 manipulation 能力
-
任务设计:5类单词操作(如“循环字母:lyinevitab→inevitably”“随机插入符号:s.u!c/c!e.s s i/o/n→success”),每类10000个实例(选自高频词);
-
实验设置:少样本K=100;
-
GPT-3成绩(表3.10):
- 随机插入符号(RI):少样本67.2%(最易,因仅需删除符号);
- 循环字母(CL):少样本37.9%;
- 反向单词(RW):所有场景<1%(最难,因需逐字母反转,模型难捕捉)。
-
关键结论:模型擅长“简单符号删除”,但难处理“复杂字母重排”,证明上下文学习的“符号推理能力”有限。
3.6.3 新闻生成:文本合成质量的“人类级”验证
-
任务设计:给GPT-3 3篇真实新闻作为示例,加新标题(如“美国卫理公会同意历史性分裂”),让模型生成200字新闻;
-
人类评估:找80名美国参与者判断“文章是人类写还是AI写”,准确率越低说明生成质量越高;
-
结果
- 人类对GPT-3生成文章的判断准确率仅 52%(接近随机50%);
- 对比小模型:125M模型的准确率76%,13B模型55%,证明“规模越大,生成文本越接近人类”;
- 长文本验证:500字新闻的人类判断准确率仍为52%,说明GPT-3的长文本连贯性也达标。
-
关键局限:生成文本存在“事实错误”(如虚构分裂时间)、“重复表述”,但人类难以察觉,需结合事实核查工具验证。
3.7 实验总结:GPT-3的“能力边界”
从40+任务的结果可清晰看到GPT-3的优势与短板:
- 优势场景:语言建模(长距离依赖)、闭卷常识问答(TriviaQA)、物理常识(PIQA)、对话式阅读(CoQA)、少样本翻译(非英→英)、简单算术与文本生成——这些任务的共性是“依赖通用语言规律或海量常识,无需专业知识/显式逻辑”;
- 短板场景:自然语言推理(ANLI,准确率40.2%)、数值推理(DROP)、考试类阅读(RACE)、小语种翻译(En→Ro)——这些任务需“专业知识、显式逻辑计算或小众数据”,而GPT-3的训练数据或能力尚未覆盖;
- 核心启示:规模是“解锁上下文学习”的关键,但非万能——后续需通过“指令微调(Instruct GPT)”“人类反馈(RLHF)”弥补“实用性短板”,通过“检索增强(RAG)”补充“专业知识”。
4、行业影响:从“专人专岗”到“通用助手”的革命
- 范式转变:打破“预训练+微调”的依赖,确立“通用大模型+提示词工程”的新范式,降低 NLP 任务落地的标注数据成本;
- 能力扩展:证明语言模型可通过规模提升实现跨任务迁移,解锁文本生成、即时推理、领域适配等多元能力,推动对话机器人、内容创作、代码生成等应用落地;
- 研究方向:启发后续指令微调(Instruct GPT)、人类反馈强化学习(RLHF)等技术,聚焦大模型的对齐与实用性优化。
5、论文的局限性:超级模型也有“短板”
- 任务适配不均:在自然语言推理(ANLI 数据集准确率仅 40.2%)、部分阅读理解(RACE 高中英语考试准确率 46.8%)等任务中表现不佳,尤其不擅长句子对比类任务;
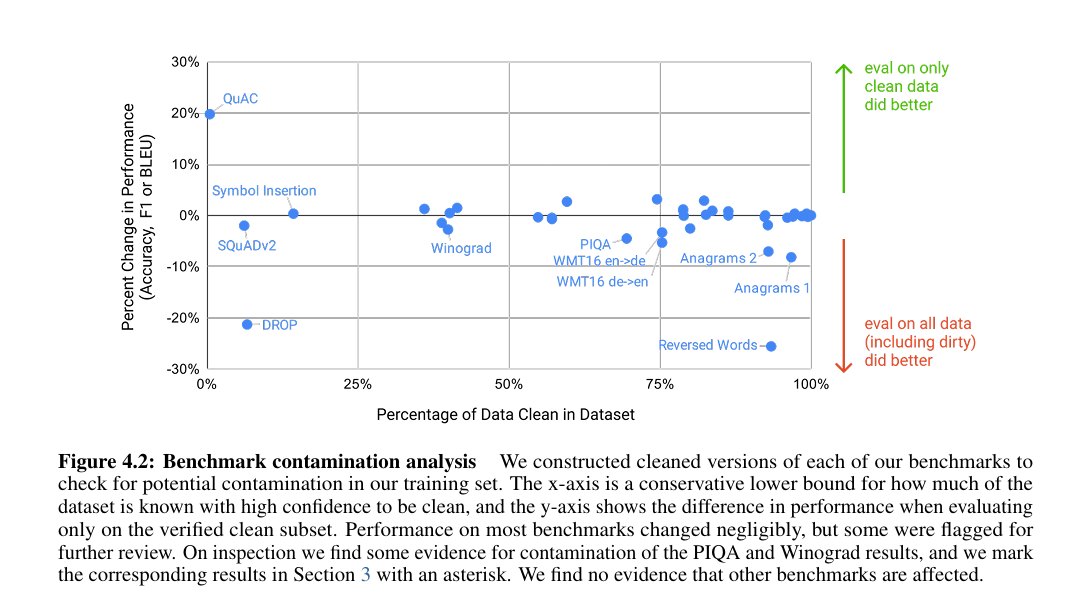
- 数据与伦理问题:训练数据存在潜在污染(部分基准数据集片段被纳入训练),模型存在性别、种族偏见(如职业与性别关联刻板印象),易生成虚假信息;如论文中图所示
![在这里插入图片描述]()
图 4.2:基准测试污染分析 我们为每个基准测试构建了清洗后版本,以检查训练集中可能存在的污染情况。横轴代表经高可信度确认的洁净数据占比的保守下界,纵轴表示仅在已验证的洁净子集上评估时的性能差异。大多数基准测试的性能变化微乎其微,但部分测试需进一步审查。经核查,我们发现 PIQA 和 Winograd 的结果存在污染迹象,并在 3 节中对相应结果标注了星号。未发现其他基准测试受影响的证据。 - 效率与可解释性:1750 亿参数模型推理成本高,无法在普通硬件部署,且决策过程黑箱化,难以追溯错误原因;
- 上下文学习本质争议:模型是否真正“学习”新任务,还是仅识别预训练数据中的相似模式,仍需进一步验证。
结语:改变 AI 发展轨迹的“里程碑”
《Language Models are Few-Shot Learners》的价值,不在于提出新架构,而在于证明了“规模即能力”——当语言模型足够大,就能解锁上下文学习能力,让 AI 更接近人类的学习模式。这篇论文不仅催生了 GPT 系列的后续发展,更确立了“大模型+提示词”的行业范式,让 AI 从“实验室里的技术”变成了“能快速落地的工具”。
虽然 GPT-3 还有不少局限,但它为 AI 行业指明了方向:未来的 AI 不需要为每个任务“量身定制”,而是通过提升通用能力,配合简单的人类指令,就能适配千变万化的需求。这篇 2020 年的论文,至今仍在影响着 AI 技术的发展轨迹,是每个关注 AI 领域的人都值得深入理解的经典之作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号