《BERT 的优秀变体:ALBERT 论文图解介绍》2020-05,作者:amitness,译者:ronghuaiyang
ALBERT论文:https://arxiv.org/pdf/1909.11942.pdf
英文原文:https://amitness.com/2020/02/albert-visual-summary/
译文链接:https://www.6aiq.com/article/1589833968655
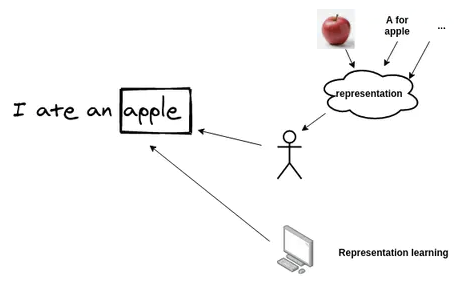
NLP 最新发展的基本前提是赋予机器学习这些表示的能力。
BERT
1. 掩码语言建模
传统的语言建模

BERT使用的掩码语言建模
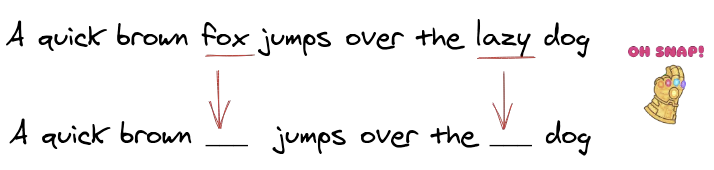
2. 下一个句子预测
“下一个句子预测”的目的是检测两个句子是否连贯。

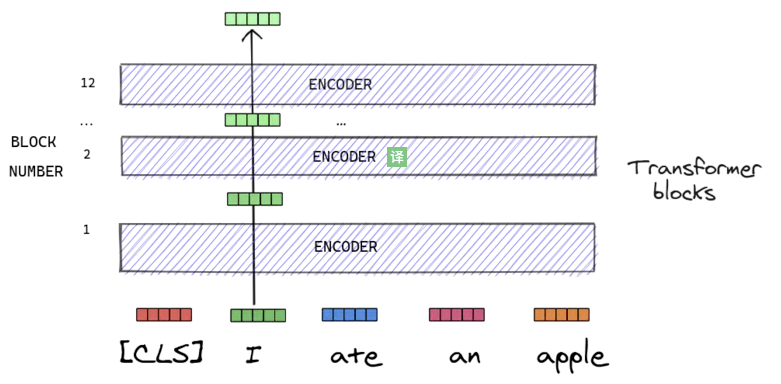
3. Transformer结构
将输入转换成大小为768的向量。关于Transformer和BERT非常好的文章:
ALBERT总结的BERT的两类问题
1. 内存限制和通信开销
BERT模型非常大,BERT-large有24个隐含层,约3.4亿参数,若想改进需要大量计算资源。
2. 模型退化
更大的模型,更好的性能? Albert作者将BERT-large的隐含层单元从1024增加到2048,在语言建模任务和阅读理解测试中,都有所下降。在阅读理解测试中从73.9%下降到54.3%。
从BERT到ALBERT
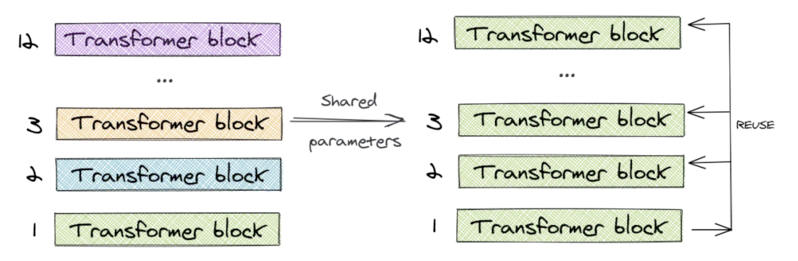
1. 跨层共享参数
BERT-large和BERT-base的参数量

ALBERT只学习第一个块的参数,并在剩下的 11 个层中重用该块,而不是为 12 个层中每个层都学习不同的参数。(可以只共享 feed-forward 层的参数,只共享注意力参数,也可以共享整个块的参数。论文对整个块的参数进行了共享)
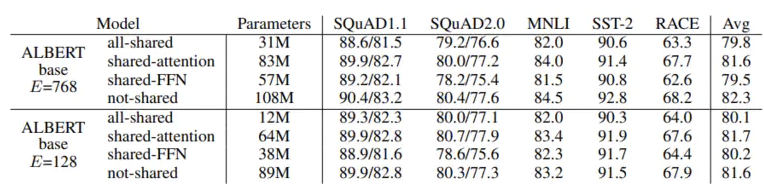
- 与BERT-base相比,12层768单元的all-shared ALBERT只有3100万个参数;
- 而在12层128单元的情况下,BERT-base和all-shared ALBERT的精度差异很小;
- 精度下降主要是shared-FFN;
- shared-attention对精度影响最小;
2. 句子顺序预测(SOP)
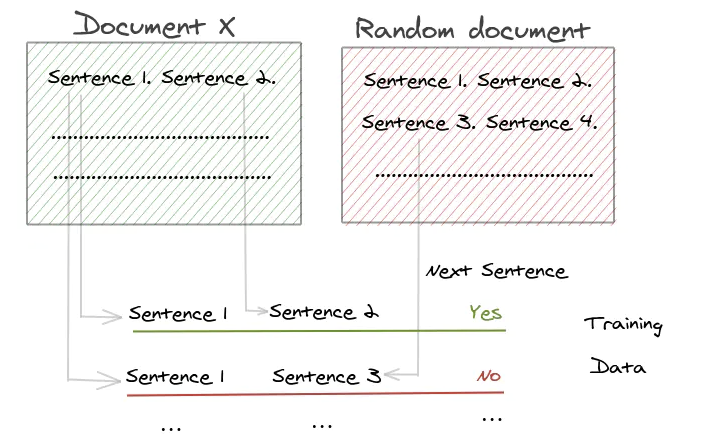
BERT使用了“下一句子预测”,即NSP任务的二分类损失:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同的文档中随机创建一对段落作为负样本
ROBERTA和XLNET等论文都阐明了NSP无效,且发现它对下游任务影响不可靠,甚至取消NSP之后多个任务的性能都提高了。
ALBERT提出了另一个任务“句子顺序预测”:
- 从同一个文档中取两个连续的段落作为一个正样本
- 交换这两个段落的顺序,并使用它作为一个负样本

ALBERT 推测 NSP 是无效的,因为与掩码语言建模相比,它并不是一项困难的任务。在单个任务中,它混合了主题预测和连贯性预测。主题预测部分很容易学习,因为它与掩码语言建模的损失有重叠。因此,即使 NSP 没有学习连贯性预测,它也会给出更高的分数。
ALBERT论文中NSP和SOP的对比

3. 嵌入参数分解
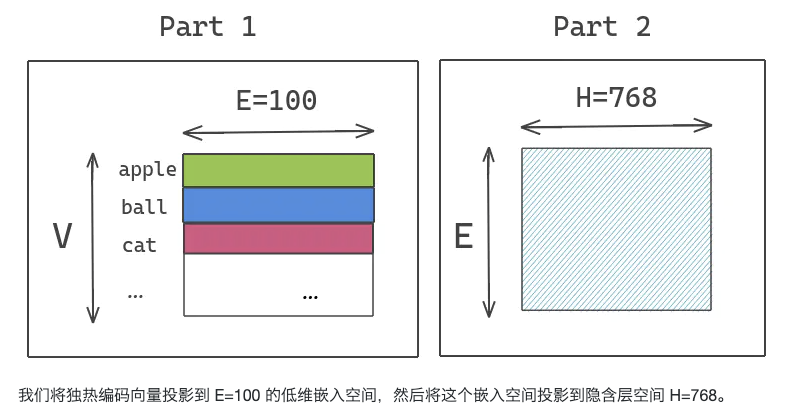
在 BERT 中,使用的 embeddings(word piece embeddings)大小被链接到 transformer 块的隐藏层大小。Word piece embeddings 使用了大小为 30,000 的词汇表的独热编码表示。这些被直接投射到隐藏层的隐藏空间。
假设我们有一个大小为 30K 的词汇表,大小为 E=768 的 word-piece embedding 和大小为 H=768 的隐含层。如果我们增加了块中的隐藏单元尺寸,那么我们还需要为每个嵌入添加一个新的维度。这个问题在 XLNET 和 ROBERTA 中也很普遍。

ALBERT 通过将大的词汇表嵌入矩阵分解成两个小的矩阵来解决这个问题。这将隐藏层的大小与词汇表嵌入的大小分开。这允许我们在不显著增加词汇表嵌入的参数大小的情况下增加隐藏的大小。
结果
- 比 BERT-large 模型缩小了 18x 的参数
- 训练加速 1.7x
- 在 GLUE, RACE 和 SQUAD 得到 SOTA 结果:
- RACE:89.4%[提升 45.3%]
- GLUE Benchmark:89.4
- SQUAD2.0 f1 score:92.2

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号