MapReduce经典设计,给了我们哪些架构启示?(第85讲,超长文)
《架构师之路:架构设计中的100个知识点》
85.MapReduce架构启示
第一部分:MapReduce究竟解决什么问题。
很多时候,定义清楚问题比解决问题更难。
什么是MapReduce?
它不是一个产品,而是一种解决问题的思路,它有多个工程实现,Google在论文中也给出了它自己的工程架构实现。
MapReduce这个编程模型解决什么问题?
能够用分治法解决的问题,例如:
1. 网页抓取;
2. 日志处理;
3. 索引倒排;
4. 查询请求汇总;
5…
画外音:现实中有许多基于分治的应用需求。
为什么是Google,发明了这个模型?
Google网页抓取,分析,倒排的多个应用场景,当时的技术体系,解决不了Google大数据量高并发量的需求,Google被迫进行技术创新,思考出了这个模型。
画外音:谁痛谁想办法。
为什么MapReduce对“能够用分治法解决的问题”特别有效?
分治法,是将一个大规模的问题,分解成多个小规模的问题(分),多个小规模问题解决,再统筹小问题的解(合),就能够解决大规模的问题。
Google MapReduce为什么能够成功?
Google为了方便用户使用系统,提供给了用户很少的接口,去解决复杂的问题。
1. Map函数接口:处理一个基于key/value(后简称kv)的成对(pair)数据集合,同时也输出基于kv的数据集合;
2. Reduce函数接口:用来合并Map输出的kv数据集合;
画外音:MapReduce系统架构,能在大规模普通PC集群上实现并行处理,和GFS等典型的互联网架构类似。
用户仅仅关注少量接口,不用关心并行、容错、数据分布、负载均衡等细节,又能够解决很多实际的问题,还有这等好事!
能不能举一个例子,说明下MapReduce的Map函数与Reduce函数是如何解决实际问题的?
举例:假设要统计大量文档中单词出现的个数。
Map
输入KV:pair(文档名称,文档内容)
输出KV:pair(单词,1)
画外音:一个单词出现一次,就输出一个1。
Reduce
输入KV:pair(单词,1)
输入KV:pair(单词,总计数)
以下是一段伪代码:
Map(list<pair($doc_name, $doc_content)>){
foreach(pair in list)
foreach($word in $doc_content)
echo pair($word, 1); // 输出list<k,v>
}
画外音:如果有多个Map进程,输入可以是一个pair,不是一个list。
Reduce(list<pair($word, $count)>){// 大量(单词,1)
map<string,int> result;
foreach(pair in list)
result[$word] += $count;
foreach($keyin result)
echo pair($key, result[$key]); // 输出list<k,v>
}
画外音:即使有多个Reduce进程,输入也是list<pair>,因为它的输入是Map的输出。
最早在单机的体系下计算,输入数据量巨大的时候,处理很慢。如何能够在短时间内完成处理,很容易想到的思路是,将这些计算分布在成百上千的主机上,但此时,会遇到各种复杂的问题,例如:
1. 并行计算
2. 数据分发
3. 错误处理
4. 集群通讯
5…
这些综合到一起,就成为了一个困难的问题,这也是Google MapReduce工程架构要解决的问题。
第二部分:MapReduce的核心优化思路。
为了解决上述场景遇到的各种复杂问题,MapReduce的核心优化思路是:
1. 并行;
2. 先分再合;
下图简述了MR计算“词频统计”的过程。

从左到右四个部分,分别是:
1. 输入文件;
2. 分:M个并行的map计算实例;
3. 合:R个并行的reduce计算实例;
4. 输出结果;
先看最后一步,reduce输出最终结果。
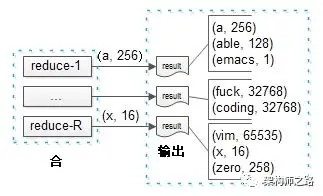
可以看到,R个reduce实例并发进行处理,直接输出最后的计数结果。
实例1输出:(a, 256)(able, 128)(emacs, 1)
实例2输出:(f*ck, 32768) (coding, 65535)
实例3输出:(vim,65535)(x, 16)(zero, 258)
画外音:这就是总结果,可以看到vim比emacs受欢迎很多。
需要理解的是,由于这是业务计算的最终结果,一个单词的计数不会出现在两个实例里。即:如果(a, 256)出现在了实例1的输出里,就一定不会出现在其他实例的输出里。
画外音:否则的话,还需要合并,就不是最终结果了。
再看中间步骤,map到reduce的过程。
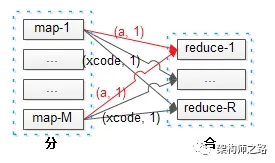
可以看到,M个map实例的输出,会作为R个reduce实例的输入。
潜在问题一:每个map都有可能输出(a, 1),而最终结果(a, 256)必须由一个reduce输出,那如何保证每个map输出的同一个key,落到同一个reduce上去呢?
这就是“分区函数”的作用。
什么是分区函数?
分区函数,是使用MapReduce的用户需要实现的,决定map输出的每一个key应当落到哪个reduce上的函数。
画外音:如果用户没有实现,会使用默认分区函数。
以词频统计的应用为例,分区函数可能是:
(1) 以[a-g]开头的key落到第一个reduce实例;
(2) 以[h-n]开头的key落到第二个reduce实例;
(3) 以[o-z]开头的key落到第三个reduce实例;
画外音:有点像数据库水平切分的“范围法”。
分区函数实现要点是什么?
为了保证每一个reduce实例都能够差不多时间结束工作任务,分区函数的实现要点是:尽量负载均衡。
画外音:即数据均匀分摊。
上述词频统计的分区函数,就不是负载均衡的,有些reduce实例处理的单词多,有些reduce处理的单词少,这样就可能出现,所有reduce实例都处理结束,最后等待一个长尾reduce的情况。
对于词频统计,负载更为均衡的分区函数为:
hash(key) % 3
画外音:有点像数据库水平切分的“哈希法”。
潜在问题二:每个map都有可能输出多个(a, 1),这样无形中增大了网络带宽资源,以及reduce的计算资源,有没有办法进行优化呢?
这就是“合并函数”的作用。
什么是合并函数?
有时,map产生的中间key的重复数据比重很大,可以提供给用户一个自定义函数,在一个map实例完成工作后,本地就做一次合并,这样网络传输与reduce计算资源都能节省很多。
合并函数在每个map任务结束前都会执行一次,一般来说,合并函数与reduce函数是一样的,区别是:
1. 合并函数执行map实例本地数据合并;
2. reduce函数执行最终的合并,会收集多个map实例的数据;
对于词频统计应用,合并函数可以将:
一个map实例的多个(a, 1)合并成一个(a, $count)输出。
最后看第一个个步骤,输入文件到map的过程。
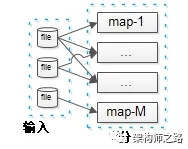
潜在问题三:如何确定文件到map的输入呢?
随意即可,只要负载均衡,均匀切分输入文件大小就行,不用管分到哪个map实例。
画外音:无论分到那个map都能正确处理。
结论,Google MapReduce实施了一系列的优化:
1. 分区函数:保证不同map输出的相同key,落到同一个reduce里;
2. 合并函数:在map结束时,对相同key的多个输出做本地合并,节省总体资源;
3. 输入文件到map如何切分:随意,切分均匀就行;
第三部分:MapReduce的工程架构实践。
上述优化后的执行流程,Google MapReduce通过怎样的工程架构实现的呢?
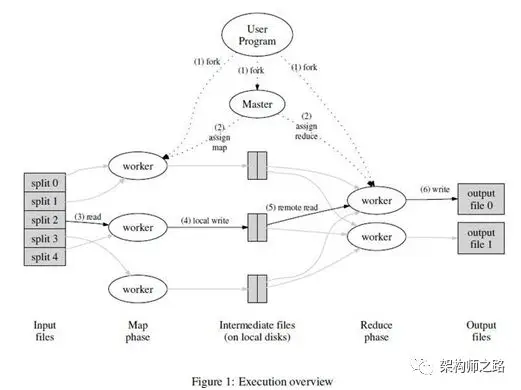
先看下总体架构图,有个直观的印象。
用户使用GoogleMR系统,必须输入的是什么?
1. 输入数据,必选
画外音:否则系统处理啥。
2. map函数,必选
3. reduce函数,必选
画外音:分治法,分与合的业务逻辑。
4. 分区函数,必选
画外音:保证同一个key,在合并阶段,必须落到同一个reduce上,系统提供默认hash(key)法。
5. 合并函数,可选
画外音:看用户是否需要在map结束阶段进行优化。
用户提供各个输入后,GoogleMR的执行流程是什么?
画外音:不妨假设,用户设置了M个map节点,R个reduce节点;例如:M=500,R=200。
(1) 在集群中创建大量可执行实例副本(fork);
(2) 这些副本中有一个master,其他均为worker,任务的分配由master完成, M个map实例和R个reduce实例由worker完成;
(3) 将输入数据分成M份,然后被分配到map任务的worker,从其中一份读取输入数据,执行用户的map函数处理,并在本地内存生成临时数据;
(4) 本地内存临时数据,通过分区函数,被分成R份,周期性的写到本地磁盘,由master调度,传给被分配到reduce任务的worker;
(5) 负责reduce任务的worker,从远程读取多个map输出的数据,执行用户的reduce函数处理,处理结果写入输出文件;
画外音:可能对key要进行外部排序。
(6) 所有map和reduce的worker都结束工作后,master唤醒用户程序,MapReduce调用返回,结果被输出到了R个文件中。
GoogleMR系统里的master和worker是啥?
(1) master:单点master会存储一些元数据,监控所有map与reduce的状态,记录哪个数据要给哪个map,哪个数据要给哪个reduce,掌控全局视野,做中控;
画外音:是不是和GFS的master非常像?
(2) worker:多个worker进行业务逻辑处理,具体一个worker是用来执行map还是reduce,是由master调度的;
画外音:是不是和工作线程池非常像?这里的worker是分布在多台机器上的而已。
master的高可用是如何保证的?
一个简单的方法是,将元数据固化到磁盘上,用一个shadow-master来做高可用。
画外音:GFS不就是这么干的么?
然而现实情况是:没有将元数据固化到磁盘上,元数据被存放在master的内存里用以提高工作效率,当master挂掉后,通知用户“任务执行失败”,让其选择重新执行。
画外音:
(1) 单点master,掌控全局视野,能让系统的复杂性降低非常多;
(2) master挂掉的概率很小;
(3) 不做高可用,能让系统的复杂性降低非常多;
worker的高可用是如何保证的?
master会周期性的ping每个worker,如果超时未返回,master会把对应的worker置为无效,把这个worker的工作任务重新执行:
1. 如果重新执行的是reduce任务,不需要有额外的通知;
2. 如果重新执行的是map任务,需要通知执行reduce的worker节点,输入数据换了一个worker;
随时都可能有map或者reduce挂掉,任务完成前重新被执行,会不会影响MR的最终结果?
在用户输入不变的情况下,MR的输出一定是不变的,这就要求MR系统必须具备幂等性:
1. 对相同的输入,不管哪个负责map的worker执行的结果,一定是不变的,产出的R个本地输出文件内容也一定是不变的;
2. 对于M个map,每个map输出的R个本地文件,只要这些输入不变,对应接收这些数据的reduce的worker执行结果,一定是不变的,输出文件内容也一定是不变的;
长尾效应怎么解决?
一个MR执行时间的最大短板,往往是“长尾worker”。
导致“长尾worker”的原因有很多:
(1) 用户的分区函数设计得不合理,导致某些reduce负载不均,要处理大量的数据;
画外音:
最坏的情况,所有数据最终都落到一个reduce上,分布式并行处理,转变为了单机串行处理;
所以,分区函数的负载均衡性,是用户需要考虑的。
(2) 因为系统的原因,worker所在的机器磁盘坏了,CPU有问题,也可能导致任务执行很慢;
GoogleMR有一个“备用worker”的机制,当某些worker的执行时间超出预期时,会启动另一个worker执行相同的任务,以尝试解决长尾效应。
总结
Google MapReduce架构,体现了很多经典架构实践:
1. 单点master简化系统复杂度;
2. 单点master不高可用,简化系统复杂度;
3. master对worker的监控以及重启,保证worker高可用;
4. 幂等性,保证结果的正确性;
5. 多个worker执行同一个任务优化长尾问题;
想成为一个合格的架构师,经历系统流量从10万到10亿,一定会面临以下九大场景,80个架构问题。
画外音:
(1)文章较长,建议收藏;
(2)文章底部有视频版本;
【第一章:技术选型】
创业初期架构方案怎么选型?
(1)要考虑业务的需求与特点,初期往往“快速实现”更重要,此时系统的特点是请求量小,数据量小,服务器资源也非常有限;
(2)这个阶段最重要的选型依据是:合伙人熟悉什么技术栈,使用什么技术栈;
(3)第一版往往采用ALL in one架构;
(4)这个阶段研发主要在写CURD业务逻辑,引入DAO和ORM能极大提高工程效率;
画外音:什么是ALL in one架构?
如果硬要问我,会选择什么技术栈,我会二选一:
PHP体系(Linux,Apache,MySQL,PHP)
或者
Java体系(Linux,Tomcat,MySQL,Java)
使用开源框架组件还是自研?
我的观点是:
(1)早期不建议自研;
(2)随着规模的扩大,要控制技术栈;
(3)要浅浅的封装一层;
(4)适当的时候,造一些契合业务的轮子;
画外音:为什么要控制技术栈?为什么要封装一层?
什么情况下要进行容量评估?
至少在三种情况下,要进行容量评估:
(1)新系统上线;
(2)临时运营活动;
(3)系统容量有质变性增长;
系统层面,要评估哪些重要指标?
主要评估网络带宽、CPU、内存容量、磁盘容量、磁盘IO等资源指标,系统层面主要看吞吐量指标。
画外音:容量设计五大步骤是啥?
创业初期,系统层面存在瓶颈的时候,优化原则是什么?
(1)最低成本,初期最大的成本是时间成本;
(2)用“钱”和“资源”快速解决系统问题,而不是过早的系统重构;
(3)将ALL in one架构升级为伪分布式架构,是此阶段的最佳实践;
伪分布式的核心是什么?
伪分布式的本质是单机变多机,但又不是真正的高可用,其核心是垂直拆分:
(1)业务垂直拆分;
(2)代码垂直拆分;
(3)数据库垂直拆分;
(4)研发团队垂直拆分;
画外音:伪分布式的优化细节是啥?
【第二章:接入层架构】
如何解决接入层的扩展性问题?
引入反向代理。
最常见的反向代理是什么?
Nginx。
引入反向代理之后,要解决什么新的问题?
(1)集群负载均衡;
(2)反向代理高可用;
画外音:有哪些常见的负载均衡方法?如何保证反向代理高可用?
站点流量从小到大,接入层架构如何演进?
整体可以分为五个阶段:
(1)有反向代理技术之前,单体架构要解决扩展性问题,可使用DNS轮询架构;
(2)有反向代理技术之后,初期可以使用反向代理解决扩展性问题;
(3)然后,需要升级为高可用反向代理架构;
(4)多级反向代理,引入LVS&F5进一步扩充性能;
(5)想要无限性能,必须用DNS轮询架构;
画外音:每个阶段的逻辑与细节到底是怎么样的?
Session,是接入层架构非常关注的问题,如何保证Session一致性?
通常有四种方案:
(1)客户端层解决;
(2)反向代理层解决;
(3)web-server层解决;
(4)后端服务层解决
画外音:每种方案细节又是怎么样的?
CDN,是接入层不得不谈的问题,CDN架构有哪些要了解?
引入CDN架构,至少要考虑这五个问题:
(1)什么样的资源适合静态加速;
(2)CDN的架构是怎么样的;
(3)CDN是怎么实现“就近访问的”;
(4)如何保证源站和镜像站数据的一致性;
(5)资源更新,是推还是拉?
画外音:学CDN,千万不要去百度“斯塔尔报告”。
TCP接入,架构上要考虑哪些问题?
至少要考虑这四个架构设计点:
(1)TCP如何快速实现接入;
(2)TCP如何快速实现扩展,以及高可用;
(3)TCP如何快速实现负载均衡;
(4)TCP如何保证扩展性与耦合性的平衡;
画外音:有没有综合方案,系统性解决负载均衡 + 高可用 + 可扩展 + 解耦合等一系列问题?

(1)每秒100w请求,秒杀架构 (2)千万粉丝,feed架构 (3)千万同时在线,IM架构 (4)每秒100w检索,搜索引擎内核架构 (5)MQ内核细节 (6)RPC内核细节 (7)数据库架构 (8)多机房多活架构与细节 (9)分布式调用链追踪架构与细节 (10)3周自研自动化上线平台 (11)区块链中的架构理念 (12)数据库性能瓶颈定位 (13)反范式数据库设计 (14)微服务抽离与解耦 (15)经典架构10问 (16)微服务与数据库架构10问 (17)技术人职业发展规划 (18)InnoDB内核架构与细节
第一阶:技术选型(5节,已放出) 第二阶:接入层架构(5节,已放出) 第三阶:极速性能优化(3节,已放出) 第四阶:微服务架构(7节,已放出) 第五阶:数据库架构(6节,已放出) 第六阶:缓存架构(7节,已放出) 第七阶:架构解耦(6节,已放出) 第八阶:架构分层(5节,已放出) 第九阶:架构进阶(6节,已放出)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号