linux中10个lsof命令示例,NET,浅谈容器网络
lsof意义LiSt Open Files用于找出哪些文件被哪个进程打开。众所周知Linux/Unix将所有内容都视为文件(pipes,sockets,directories,devices等等)。使用的原因之一lsof命令是当磁盘无法卸载时,因为它表示正在使用文件。借助此命令,我们可以轻松识别正在使用的文件。
1. 使用 lsof 命令列出所有打开的文件
在下面的示例中,它将显示打开文件的长列表,其中一些被提取出来以便更好地理解哪些显示列
Command,PID,USER,FD,TYPE等等。
# lsof
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
init 1 root cwd DIR 253,0 4096 2 /
init 1 root rtd DIR 253,0 4096 2 /
init 1 root txt REG 253,0 145180 147164 /sbin/init
init 1 root mem REG 253,0 1889704 190149 /lib/libc-2.12.so
init 1 root 0u CHR 1,3 0t0 3764 /dev/null
init 1 root 1u CHR 1,3 0t0 3764 /dev/null
init 1 root 2u CHR 1,3 0t0 3764 /dev/null
init 1 root 3r FIFO 0,8 0t0 8449 pipe
init 1 root 4w FIFO 0,8 0t0 8449 pipe
init 1 root 5r DIR 0,10 0 1 inotify
init 1 root 6r DIR 0,10 0 1 inotify
init 1 root 7u unix 0xc1513880 0t0 8450 socket
部分及其值是不言自明的。但是,我们将审查
FD & TYPE列更准确。
FD– 代表文件描述符,可能会看到一些值:
cwd当前工作目录rtd根目录txt程序文本(代码和数据)mem内存映射文件
- 也在
FD列号如1u是实际的文件描述符,后跟 u,r,w 其模式为:
r用于读取访问。w用于写访问。u用于读写访问。
TYPE– 文件及其标识。
DIR- 目录REG– 常规文件CHR– 字符特殊文件。FIFO– 先进先出
2. 列出用户特定打开的文件
下面的命令将显示用户所有打开文件的列表
rumenz.
# lsof -u rumenz
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 1838 rumenz cwd DIR 253,0 4096 2 /
sshd 1838 rumenz rtd DIR 253,0 4096 2 /
sshd 1838 rumenz txt REG 253,0 532336 188129 /usr/sbin/sshd
sshd 1838 rumenz mem REG 253,0 19784 190237 /lib/libdl-2.12.so
sshd 1838 rumenz mem REG 253,0 122436 190247 /lib/libselinux.so.1
sshd 1838 rumenz mem REG 253,0 255968 190256 /lib/libgssapi_krb5.so.2.2
sshd 1838 rumenz mem REG 253,0 874580 190255 /lib/libkrb5.so.3.3
3. 查找在特定端口上运行的进程
要找出特定端口的所有正在运行的进程,只需使用以下带有选项的命令
-i.下面的例子将列出端口的所有正在运行的进程22.
# lsof -i TCP:22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 1471 root 3u IPv4 12683 0t0 TCP *:ssh (LISTEN)
sshd 1471 root 4u IPv6 12685 0t0 TCP *:ssh (LISTEN)
4. 仅列出 IPv4 和 IPv6 打开的文件
在下面的例子中只显示
IPv4和IPv6网络文件使用单独的命令打开。
# lsof -i 4
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 1203 rpc 6u IPv4 11326 0t0 UDP *:sunrpc
rpcbind 1203 rpc 7u IPv4 11330 0t0 UDP *:954
rpcbind 1203 rpc 8u IPv4 11331 0t0 TCP *:sunrpc (LISTEN)
avahi-dae 1241 avahi 13u IPv4 11579 0t0 UDP *:mdns
avahi-dae 1241 avahi 14u IPv4 11580 0t0 UDP *:58600
# lsof -i 6
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 1203 rpc 9u IPv6 11333 0t0 UDP *:sunrpc
rpcbind 1203 rpc 10u IPv6 11335 0t0 UDP *:954
rpcbind 1203 rpc 11u IPv6 11336 0t0 TCP *:sunrpc (LISTEN)
rpc.statd 1277 rpcuser 10u IPv6 11858 0t0 UDP *:55800
rpc.statd 1277 rpcuser 11u IPv6 11862 0t0 TCP *:56428 (LISTEN)
cupsd 1346 root 6u IPv6 12112 0t0 TCP localhost:ipp (LISTEN)
5. 列出 TCP 端口范围 1-1024 的打开文件
列出所有打开文件的运行进程
TCP端口范围从1-1024.
# lsof -i TCP:1-1024
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 1203 rpc 11u IPv6 11336 0t0 TCP *:sunrpc (LISTEN)
cupsd 1346 root 7u IPv4 12113 0t0 TCP localhost:ipp (LISTEN)
sshd 1471 root 4u IPv6 12685 0t0 TCP *:ssh (LISTEN)
master 1551 root 13u IPv6 12898 0t0 TCP localhost:smtp (LISTEN)
sshd 1834 root 3r IPv4 15101 0t0 TCP 192.168.0.2:ssh->192.168.0.1:conclave-cpp (ESTABLISHED)
sshd 1838 rumenz 3u IPv4 15101 0t0 TCP 192.168.0.2:ssh->192.168.0.1:conclave-cpp (ESTABLISHED)
sshd 1871 root 3r IPv4 15842 0t0 TCP 192.168.0.2:ssh->192.168.0.1:groove (ESTABLISHED)
httpd 1918 root 5u IPv6 15991 0t0 TCP *:http (LISTEN)
httpd 1918 root 7u IPv6 15995 0t0 TCP *:https (LISTEN)
6. 用^字符排除用户
在这里,我们排除了
root用户。你可以使用排除特定用户^使用如上所示的命令。
# lsof -i -u^root
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 1203 rpc 6u IPv4 11326 0t0 UDP *:sunrpc
rpcbind 1203 rpc 7u IPv4 11330 0t0 UDP *:954
rpcbind 1203 rpc 8u IPv4 11331 0t0 TCP *:sunrpc (LISTEN)
rpcbind 1203 rpc 9u IPv6 11333 0t0 UDP *:sunrpc
rpcbind 1203 rpc 10u IPv6 11335 0t0 UDP *:954
rpcbind 1203 rpc 11u IPv6 11336 0t0 TCP *:sunrpc (LISTEN)
avahi-dae 1241 avahi 13u IPv4 11579 0t0 UDP *:mdns
avahi-dae 1241 avahi 14u IPv4 11580 0t0 UDP *:58600
rpc.statd 1277 rpcuser 5r IPv4 11836 0t0 UDP *:soap-beep
rpc.statd 1277 rpcuser 8u IPv4 11850 0t0 UDP *:55146
rpc.statd 1277 rpcuser 9u IPv4 11854 0t0 TCP *:32981 (LISTEN)
rpc.statd 1277 rpcuser 10u IPv6 11858 0t0 UDP *:55800
rpc.statd 1277 rpcuser 11u IPv6 11862 0t0 TCP *:56428 (LISTEN)
7. 找出谁在查看哪些文件和命令?
下面的例子显示了用户
rumenz正在使用命令ping和/etc目录 。
# lsof -i -u rumenz
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 1839 rumenz cwd DIR 253,0 12288 15 /etc
ping 2525 rumenz cwd DIR 253,0 12288 15 /etc
8. 列出所有网络连接
带有选项的以下命令
‘-i’显示所有网络连接的列表'LISTENING & ESTABLISHED’.
# lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 1203 rpc 6u IPv4 11326 0t0 UDP *:sunrpc
rpcbind 1203 rpc 7u IPv4 11330 0t0 UDP *:954
rpcbind 1203 rpc 11u IPv6 11336 0t0 TCP *:sunrpc (LISTEN)
avahi-dae 1241 avahi 13u IPv4 11579 0t0 UDP *:mdns
avahi-dae 1241 avahi 14u IPv4 11580 0t0 UDP *:58600
rpc.statd 1277 rpcuser 11u IPv6 11862 0t0 TCP *:56428 (LISTEN)
cupsd 1346 root 6u IPv6 12112 0t0 TCP localhost:ipp (LISTEN)
cupsd 1346 root 7u IPv4 12113 0t0 TCP localhost:ipp (LISTEN)
sshd 1471 root 3u IPv4 12683 0t0 TCP *:ssh (LISTEN)
master 1551 root 12u IPv4 12896 0t0 TCP localhost:smtp (LISTEN)
master 1551 root 13u IPv6 12898 0t0 TCP localhost:smtp (LISTEN)
sshd 1834 root 3r IPv4 15101 0t0 TCP 192.168.0.2:ssh->192.168.0.1:conclave-cpp (ESTABLISHED)
httpd 1918 root 5u IPv6 15991 0t0 TCP *:http (LISTEN)
httpd 1918 root 7u IPv6 15995 0t0 TCP *:https (LISTEN)
clock-app 2362 narad 21u IPv4 22591 0t0 TCP 192.168.0.2:45284->www.gov.com:http (CLOSE_WAIT)
chrome 2377 narad 61u IPv4 25862 0t0 TCP 192.168.0.2:33358->maa03s04-in-f3.1e100.net:http (ESTABLISHED)
chrome 2377 narad 80u IPv4 25866 0t0 TCP 192.168.0.2:36405->bom03s01-in-f15.1e100.net:http (ESTABLISHED)
9. 按 PID 搜索
下面的例子只显示了谁
PID是1[One]。
# lsof -p 1
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
init 1 root cwd DIR 253,0 4096 2 /
init 1 root rtd DIR 253,0 4096 2 /
init 1 root txt REG 253,0 145180 147164 /sbin/init
init 1 root mem REG 253,0 1889704 190149 /lib/libc-2.12.so
init 1 root mem REG 253,0 142472 189970 /lib/ld-2.12.so
10. 杀死特定用户的所有活动
有时你可能必须终止特定用户的所有进程。下面的命令将杀死所有进程
rumenz用户。
# kill -9 `lsof -t -u rumenz`
Note:在这里,不可能给出所有可用选项的示例,本指南仅用于说明如何lsof命令可以使用。你可以参考手册页lsof命令以了解更多信息。如果你觉得这篇文章有用,请通过我们下面的评论框分享。The OSI seven-layer model is easy to understand
The Open Systems Interconnection (OSI) model defines a networking framework to implement protocols in layers, with control passed from one layer to the next. It is primarily used today as a teaching tool. It conceptually divides computer network architecture into 7 layers in a logical progression.
开放系统互连模型定义了一个网络框架来实现层协议,控制从一层传递到下一层。今天,它主要被用作一种教学工具。它在概念上将计算机网络体系结构按逻辑顺序划分为7个层次。
The lower layers deal with electrical signals, chunks of binary data, and routing of these data across networks. Higher levels cover network requests and responses, representation of data, and network protocols, as seen from a user's point of view.
底层处理电子信号、二进制数据块以及这些数据在网络上的路由。从用户的角度来看,更高的层次包括网络请求和响应、数据的表示和网络协议。
The OSI model was originally conceived as a standard architecture for building network systems, and many popular network technologies today reflect the layered design of OSI.
OSI 模型最初被认为是构建网络系统的标准体系结构,现在许多流行的网络技术反映了 OSI 的分层设计。
1 Physical Layer 1物理层
At Layer 1, the Physical layer of the OSI model is responsible for the ultimate transmission of digital data bits from the Physical layer of the sending (source) device over network communications media to the Physical layer of the receiving (destination) device.
在第一层,OSI 模型的物理层负责从发送(源)设备的物理层通过网络通信媒体向接收(目的)设备的物理层最终传输数字数据位。
Examples of layer 1 technologies include Ethernet cables and hubs. Also, hubs and other repeaters are standard network devices that function at the Physical layer, as are cable connectors.
第一层技术的例子包括以太网电缆和集线器。此外,集线器和其他中继器是在物理层起作用的标准网络设备,电缆连接器也是如此。
At the Physical layer, data is transmitted using the type of signaling supported by the physical medium: electric voltages, radio frequencies, or pulses of infrared or ordinary light.
在物理层,数据通过物理介质支持的信号类型进行传输: 电压、无线电频率或红外脉冲或普通光。
2 Data Link Layer 2数据链路层
When obtaining data from the Physical layer, the Data Link layer checks for physical transmission errors and packages bits into data frames. The Data Link layer also manages physical addressing schemes such as MAC addresses for Ethernet networks, controlling access of network devices to the physical medium.
当从物理层获取数据时,数据链路层检查物理传输错误,并将比特打包到数据帧中。数据链路层还管理物理寻址方案,例如以太网的 MAC 地址,控制网络设备对物理介质的访问。
Because the Data Link layer is the most complex layer in the OSI model, it is often divided into two parts: the Media Access Control sub-layer and the Logical Link Control sub-layer.
因为数据链路层是 OSI 模型中最复杂的一层,所以它通常被分成两部分: 媒体访问控制子层和逻辑链路控制子层。
3 Network Layer 3网络层
The Network layer adds the concept of routing above the Data Link layer. When data arrives at the Network layer, the source and destination addresses contained inside each frame are examined to determine if the data has reached its final destination. If the data has reached the final destination, layer 3 formats the data into packets delivered to the Transport layer. Otherwise, the Network layer updates the destination address and pushes the frame down to the lower layers.
网络层在数据链路层之上添加了路由的概念。当数据到达网络层时,将检查包含在每个帧中的源地址和目的地址,以确定数据是否已到达其最终目的地。如果数据已经到达最终目的地,第三层将数据格式化为分组传送到传输层。否则,网络层更新目标地址并将帧推送到较低的层。
To support routing, the Network layer maintains logical addresses such as IP addresses for devices on the network. The Network layer also manages the mapping between these logical addresses and physical addresses. In IPv4 networking, this mapping is accomplished through the Address Resolution Protocol (ARP); IPv6 uses Neighbor Discovery Protocol (NDP).
为了支持路由,网络层为网络上的设备维护逻辑地址,如 IP 地址。网络层还管理这些逻辑地址和物理地址之间的映射。在 IPv4网络中,这种映射通过地址解析协议(ARP)完成; IPv6使用邻居发现协议(NDP)。
4 Transport Layer 4传输层
The Transport Layer delivers data across network connections. TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are the most common examples of Transport Layer 4 network protocols. Different transport protocols may support a range of optional capabilities, including error recovery, flow control, and support for re-transmission.
传输层通过网络连接传输数据。TCP (传输控制协议)和 UDP (用户数据报协议)是传输层4网络协议最常见的例子。不同的传输协议可能支持一系列可选功能,包括错误恢复、流控制和支持重新传输。
5 Session Layer 5会话层
The Session Layer manages the sequence and flow of events that initiate and tear down network connections. At layer 5, it is built to support multiple types of connections that can be created dynamically and run over individual networks.
会话层管理启动和关闭网络连接的事件的顺序和流程。在第5层,它被构建为支持多种类型的连接,这些连接可以动态创建并在单个网络上运行。
6 Presentation Layer 6表示层
The Presentation layer has the simplest function of any piece of the OSI model. At layer 6, it handles syntax processing of message data such as format conversions and encryption/decryption needed to support the Application layer above it.
表示层具有 OSI 模型中任何部分中最简单的功能。在第6层,它处理消息数据的语法处理,例如格式转换和加密/解密,这些是支持它上面的应用程序层所需的。
7 Application Layer 7应用层
The Application layer supplies network services to end-user applications. Network services are protocols that work with the user's data. For example, in a web browser application, the Application layer protocol HTTP packages the data needed to send and receive web page content. This layer 7 provides data to (and obtains data from) the Presentation layer.
应用程序层向终端用户应用程序提供网络服务。网络服务是处理用户数据的协议。例如,在 web 浏览器应用程序中,应用层协议 HTTP 将发送和接收网页内容所需的数据打包。该层7向表示层提供数据(并从表示层获取数据)。
41 | 案例篇:如何优化 NAT 性能?(上)
上一节,探究了网络延迟增大问题的分析方法,并通过一个案例,掌握了如何用 hping3、tcpdump、Wireshark、strace 等工具,来排查和定位问题的根源。简单回顾一下,网络延迟是最核心的网络性能指标。由于网络传输、网络包处理等各种因素的影响,网络延迟不可避免。但过大的网络延迟,会直接影响用户的体验。所以,在发现网络延迟增大的情况后,你可以先从路由、网络包的收发、网络包的处理,再到应用程序等,从各个层级分析网络延迟,等到找出网络延迟的来源层级后,再深入定位瓶颈所在。今天,来看看,另一个可能导致网络延迟的因素,即网络地址转换(Network Address Translation),缩写为 NAT。接下来,我们先来学习 NAT 的工作原理,并弄清楚如何优化 NAT 带来的潜在性能问题。NAT 原理
NAT 技术可以重写 IP 数据包的源 IP 或者目的 IP,被普遍地用来解决公网 IP 地址短缺的问题。它的主要原理就是,网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。你既可以在支持网络地址转换的路由器(称为 NAT 网关)中配置 NAT,也可以在 Linux 服务器中配置 NAT。如果采用第二种方式,Linux 服务器实际上充当的是“软”路由器的角色。NAT 的主要目的,是实现地址转换。根据实现方式的不同,NAT 可以分为三类:
- 静态 NAT,即内网 IP 与公网 IP 是一对一的永久映射关系;
- 动态 NAT,即内网 IP 从公网 IP 池中,动态选择一个进行映射;
- 网络地址端口转换 NAPT(Network Address and Port Translation),即把内网 IP 映射到公网 IP 的不同端口上,让多个内网 IP 可以共享同一个公网 IP 地址。
NAPT 是目前最流行的 NAT 类型,我们在 Linux 中配置的 NAT 也是这种类型。而根据转换方式的不同,我们又可以把 NAPT 分为三类。
- 第一类是源地址转换 SNAT,即目的地址不变,只替换源 IP 或源端口。SNAT 主要用于,多个内网 IP 共享同一个公网 IP ,来访问外网资源的场景。
- 第二类是目的地址转换 DNAT,即源 IP 保持不变,只替换目的 IP 或者目的端口。DNAT 主要通过公网 IP 的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实 IP 地址。
- 第三类是双向地址转换,即同时使用 SNAT 和 DNAT。当接收到网络包时,执行 DNAT,把目的 IP 转换为内网 IP;而在发送网络包时,执行 SNAT,把源 IP 替换为外部 IP。
双向地址转换,其实就是外网 IP 与内网 IP 的一对一映射关系,所以常用在虚拟化环境中,为虚拟机分配浮动的公网 IP 地址。为了帮你理解 NAPT,我画了一张图。我们假设:
- 本地服务器的内网 IP 地址为 192.168.0.2;
- NAT 网关中的公网 IP 地址为 100.100.100.100;
- 要访问的目的服务器 baidu.com 的地址为 123.125.115.110。
那么 SNAT 和 DNAT 的过程,就如下图所示:从图中,你可以发现:
- 当服务器访问 baidu.com 时,NAT 网关会把源地址,从服务器的内网 IP 192.168.0.2 替换成公网 IP 地址 100.100.100.100,然后才发送给 baidu.com;
- 当 baidu.com 发回响应包时,NAT 网关又会把目的地址,从公网 IP 地址 100.100.100.100 替换成服务器内网 IP 192.168.0.2,然后再发送给内网中的服务器。
了解了 NAT 的原理后,我们再来看看,如何在 Linux 中实现 NAT 的功能。iptables 与 NAT
Linux 内核提供的 Netfilter 框架,允许对网络数据包进行修改(比如 NAT)和过滤(比如防火墙)。在这个基础上,iptables、ip6tables、ebtables 等工具,又提供了更易用的命令行接口,以便系统管理员配置和管理 NAT、防火墙的规则。其中,iptables 就是最常用的一种配置工具。要掌握 iptables 的原理和使用方法,最核心的就是弄清楚,网络数据包通过 Netfilter 时的工作流向,下面这张图就展示了这一过程。(图片来自 Wikipedia)在这张图中,绿色背景的方框,表示表(table),用来管理链。Linux 支持 4 种表,包括 filter(用于过滤)、nat(用于 NAT)、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。跟 table 一起的白色背景方框,则表示链(chain),用来管理具体的 iptables 规则。每个表中可以包含多条链,比如:
- filter 表中,内置 INPUT、OUTPUT 和 FORWARD 链;
- nat 表中,内置 PREROUTING、POSTROUTING、OUTPUT 等。
当然,你也可以根据需要,创建你自己的链。灰色的 conntrack,表示连接跟踪模块。它通过内核中的连接跟踪表(也就是哈希表),记录网络连接的状态,是 iptables 状态过滤(-m state)和 NAT 的实现基础。iptables 的所有规则,就会放到这些表和链中,并按照图中顺序和规则的优先级顺序来执行。针对今天的主题,要实现 NAT 功能,主要是在 nat 表进行操作。而 nat 表内置了三个链:
- PREROUTING,用于路由判断前所执行的规则,比如,对接收到的数据包进行 DNAT。
- POSTROUTING,用于路由判断后所执行的规则,比如,对发送或转发的数据包进行 SNAT 或 MASQUERADE。
- OUTPUT,类似于 PREROUTING,但只处理从本机发送出去的包。
熟悉 iptables 中的表和链后,相应的 NAT 规则就比较简单了。我们还以 NAPT 的三个分类为例,来具体解读一下。SNAT
根据刚才内容,我们知道,SNAT 需要在 nat 表的 POSTROUTING 链中配置。我们常用两种方式来配置它。第一种方法,是为一个子网统一配置 SNAT,并由 Linux 选择默认的出口 IP。这实际上就是经常说的 MASQUERADE:$ iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE第二种方法,是为具体的 IP 地址配置 SNAT,并指定转换后的源地址:$ iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100DNAT
再来看 DNAT,显然,DNAT 需要在 nat 表的 PREROUTING 或者 OUTPUT 链中配置,其中, PREROUTING 链更常用一些(因为它还可以用于转发的包)。$ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2双向地址转换
双向地址转换,就是同时添加 SNAT 和 DNAT 规则,为公网 IP 和内网 IP 实现一对一的映射关系,即:
iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100 iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2 在使用 iptables 配置 NAT 规则时,Linux 需要转发来自其他 IP 的网络包,所以你千万不要忘记开启 Linux 的 IP 转发功能。你可以执行下面的命令,查看这一功能是否开启。如果输出的结果是 1,就表示已经开启了 IP 转发:
sysctl net.ipv4.ip_forward net.ipv4.ip_forward = 1 如果还没开启,你可以执行下面的命令,手动开启:
sysctl -w net.ipv4.ip_forward=1 net.ipv4.ip_forward = 1 当然,为了避免重启后配置丢失,不要忘记将配置写入 /etc/sysctl.conf 文件中:
cat /etc/sysctl.conf | grep ip_forward net.ipv4.ip_forward=1 讲了这么多的原理,那当碰到 NAT 的性能问题时,又该怎么办呢?结合我们今天学过的 NAT 原理,你先自己想想,动手试试,下节课我们继续“分解”。小结
今天,我们一起学习了 Linux 网络地址转换 NAT 的原理。NAT 技术能够重写 IP 数据包的源 IP 或目的 IP,所以普遍用来解决公网 IP 地址短缺的问题。它可以让网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,也为局域网中机器起到安全隔离的作用。Linux 中的 NAT ,基于内核的连接跟踪模块实现。所以,它维护每个连接状态的同时,也会带来很高的性能成本。具体 NAT 性能问题的分析方法,我们将在下节课继续学习。思考最后,给你留一个思考题。MASQUERADE 是最常用的一种 SNAT 规则,常用来为多个内网 IP 地址提供共享的出口 IP。假设现在有一台 Linux 服务器,使用了 MASQUERADE 的方式,为内网的所有 IP 提供出口访问功能。那么,当多个内网 IP 地址的端口号相同时,MASQUERADE 还可以正常工作吗?如果内网 IP 地址数量或请求数比较多,这种方式有没有什么隐患呢?欢迎在留言区和我讨论,也欢迎你把这篇文章分享给你的同事、朋友。我们一起在实战中演练,在交流中进步。42 | 案例篇:如何优化 NAT 性能?(下)
上一节,我们学习了 NAT 的原理,明白了如何在 Linux 中管理 NAT 规则。先来简单复习一下。NAT 技术能够重写 IP 数据包的源 IP 或目的 IP,所以普遍用来解决公网 IP 地址短缺的问题。它可以让网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,也为局域网中机器起到安全隔离的作用。Linux 中的 NAT ,基于内核的连接跟踪模块实现。所以,它维护每个连接状态的同时,也对网络性能有一定影响。那么,碰到 NAT 性能问题时,我们又该怎么办呢?接下来,我就通过一个案例,带你学习 NAT 性能问题的分析思路。案例准备
下面的案例仍然基于 Ubuntu 18.04,同样适用于其他的 Linux 系统。我使用的案例环境是这样的:机器配置:2 CPU,8GB 内存。预先安装 docker、tcpdump、curl、ab、SystemTap 等工具,比如
# Ubuntu apt-get install -y docker.io tcpdump curl apache2-utils # CentOS curl -fsSL https://get.docker.com | sh yum install -y tcpdump curl httpd-tools 大部分工具,你应该都比较熟悉,这里我简单介绍一下 SystemTap 。SystemTap
SystemTap 是 Linux 的一种动态追踪框架,它把用户提供的脚本,转换为内核模块来执行,用来监测和跟踪内核的行为。关于它的原理,你暂时不用深究,后面的内容还会介绍到。这里你只要知道怎么安装就可以了:
# Ubuntu apt-get install -y systemtap-runtime systemtap # Configure ddebs source echo "deb http://ddebs.ubuntu.com $(lsb_release -cs) main restricted universe multiverse deb http://ddebs.ubuntu.com $(lsb_release -cs)-updates main restricted universe multiverse deb http://ddebs.ubuntu.com $(lsb_release -cs)-proposed main restricted universe multiverse" | \ sudo tee -a /etc/apt/sources.list.d/ddebs.list # Install dbgsym apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F2EDC64DC5AEE1F6B9C621F0C8CAB6595FDFF622 apt-get update apt install ubuntu-dbgsym-keyring stap-prep apt-get install linux-image-`uname -r`-dbgsym # CentOS yum install systemtap kernel-devel yum-utils kernel stab-prep 本次案例还是我们最常见的 Nginx,并且会用 ab 作为它的客户端,进行压力测试。案例中总共用到两台虚拟机,我画了一张图来表示它们的关系。接下来,我们打开两个终端,分别 SSH 登录到两台机器上(以下步骤,假设终端编号与图示 VM 编号一致),并安装上面提到的这些工具。注意,curl 和 ab 只需要在客户端 VM(即 VM2)中安装。同以前的案例一样,下面的所有命令都默认以 root 用户运行。如果你是用普通用户身份登陆系统,请运行 sudo su root 命令,切换到 root 用户。如果安装过程中有什么问题,同样鼓励你先自己搜索解决,解决不了的,可以在留言区向我提问。如果你以前已经安装过了,就可以忽略这一点了。接下来,我们就进入到案例环节。案例分析
为了对比 NAT 带来的性能问题,我们首先运行一个不用 NAT 的 Nginx 服务,并用 ab 测试它的性能。在终端一中,执行下面的命令,启动 Nginx,注意选项 --network=host ,表示容器使用 Host 网络模式,即不使用 NAT:docker run --name nginx-hostnet --privileged --network=host -itd feisky/nginx:80然后到终端二中,执行 curl 命令,确认 Nginx 正常启动:
curl http://192.168.0.30/ ... <p><em>Thank you for using nginx.</em></p> </body> </html> 继续在终端二中,执行 ab 命令,对 Nginx 进行压力测试。不过在测试前要注意,Linux 默认允许打开的文件描述数比较小,比如在我的机器中,这个值只有 1024:
# open files ulimit -n 1024 所以,执行 ab 前,先要把这个选项调大,比如调成 65536:
# 临时增大当前会话的最大文件描述符数 ulimit -n 65536 接下来,再去执行 ab 命令,进行压力测试:
# -c 表示并发请求数为 5000,-n 表示总的请求数为 10 万 # -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30/ ... Requests per second: 6576.21 [#/sec] (mean) Time per request: 760.317 [ms] (mean) Time per request: 0.152 [ms] (mean, across all concurrent requests) Transfer rate: 5390.19 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 177 714.3 9 7338 Processing: 0 27 39.8 19 961 Waiting: 0 23 39.5 16 951 Total: 1 204 716.3 28 7349 ... 关于 ab 输出界面的含义,我已经在 怎么评估系统的网络性能 文章中介绍过,忘了的话自己先去复习。从这次的界面,你可以看出:
- 每秒请求数(Requests per second)为 6576;
- 每个请求的平均延迟(Time per request)为 760ms;
- 建立连接的平均延迟(Connect)为 177ms。
记住这几个数值,这将是接下来案例的基准指标。注意,你的机器中,运行结果跟我的可能不一样,不过没关系,并不影响接下来的案例分析思路。接着,回到终端一,停止这个未使用 NAT 的 Nginx 应用:docker rm -f nginx-hostnet再执行下面的命令,启动今天的案例应用。案例应用监听在 8080 端口,并且使用了 DNAT ,来实现 Host 的 8080 端口,到容器的 8080 端口的映射关系:docker run --name nginx --privileged -p 8080:8080 -itd feisky/nginx:natNginx 启动后,你可以执行 iptables 命令,确认 DNAT 规则已经创建:
iptables -nL -t nat Chain PREROUTING (policy ACCEPT) target prot opt source destination DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL ... Chain DOCKER (2 references) target prot opt source destination RETURN all -- 0.0.0.0/0 0.0.0.0/0 DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:8080 你可以看到,在 PREROUTING 链中,目的为本地的请求,会转到 DOCKER 链;而在 DOCKER 链中,目的端口为 8080 的 tcp 请求,会被 DNAT 到 172.17.0.2 的 8080 端口。其中,172.17.0.2 就是 Nginx 容器的 IP 地址。接下来,我们切换到终端二中,执行 curl 命令,确认 Nginx 已经正常启动:
curl http://192.168.0.30:8080/ ... <p><em>Thank you for using nginx.</em></p> </body> </html> 然后,再次执行上述的 ab 命令,不过这次注意,要把请求的端口号换成 8080:
# -c 表示并发请求数为 5000,-n 表示总的请求数为 10 万 # -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... apr_pollset_poll: The timeout specified has expired (70007) Total of 5602 requests completed 果然,刚才正常运行的 ab ,现在失败了,还报了连接超时的错误。运行 ab 时的 -s 参数,设置了每个请求的超时时间为 2s,而从输出可以看到,这次只完成了 5602 个请求。既然是为了得到 ab 的测试结果,我们不妨把超时时间延长一下试试,比如延长到 30s。延迟增大意味着要等更长时间,为了快点得到结果,我们可以同时把总测试次数,也减少到 10000:
ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/ ... Requests per second: 76.47 [#/sec] (mean) Time per request: 65380.868 [ms] (mean) Time per request: 13.076 [ms] (mean, across all concurrent requests) Transfer rate: 44.79 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 1300 5578.0 1 65184 Processing: 0 37916 59283.2 1 130682 Waiting: 0 2 8.7 1 414 Total: 1 39216 58711.6 1021 130682 ... 再重新看看 ab 的输出,这次的结果显示:
- 每秒请求数(Requests per second)为 76;
- 每个请求的延迟(Time per request)为 65s;
- 建立连接的延迟(Connect)为 1300ms。
显然,每个指标都比前面差了很多。那么,碰到这种问题时,你会怎么办呢?你可以根据前面的讲解,先自己分析一下,再继续学习下面的内容。在上一节,我们使用 tcpdump 抓包的方法,找出了延迟增大的根源。那么今天的案例,我们仍然可以用类似的方法寻找线索。不过,现在换个思路,因为今天我们已经事先知道了问题的根源——那就是 NAT。回忆一下 Netfilter 中,网络包的流向以及 NAT 的原理,你会发现,要保证 NAT 正常工作,就至少需要两个步骤:
- 第一,利用 Netfilter 中的钩子函数(Hook),修改源地址或者目的地址。
- 第二,利用连接跟踪模块 conntrack ,关联同一个连接的请求和响应。
是不是这两个地方出现了问题呢?我们用前面提到的动态追踪工具 SystemTap 来试试。由于今天案例是在压测场景下,并发请求数大大降低,并且我们清楚知道 NAT 是罪魁祸首。所以,我们有理由怀疑,内核中发生了丢包现象。我们可以回到终端一中,创建一个 dropwatch.stp 的脚本文件,并写入下面的内容:
#! /usr/bin/env stap ############################################################ # Dropwatch.stp # Author: Neil Horman <nhorman@redhat.com> # An example script to mimic the behavior of the dropwatch utility # http://fedorahosted.org/dropwatch ############################################################ # Array to hold the list of drop points we find global locations # Note when we turn the monitor on and off probe begin { printf("Monitoring for dropped packets\n") } probe end { printf("Stopping dropped packet monitor\n") } # increment a drop counter for every location we drop at probe kernel.trace("kfree_skb") { locations[$location] <<< 1 } # Every 5 seconds report our drop locations probe timer.sec(5) { printf("\n") foreach (l in locations-) { printf("%d packets dropped at %s\n", @count(locations[l]), symname(l)) } delete locations } 这个脚本,跟踪内核函数 kfree_skb() 的调用,并统计丢包的位置。文件保存好后,执行下面的 stap 命令,就可以运行丢包跟踪脚本。这里的 stap,是 SystemTap 的命令行工具:
stap --all-modules dropwatch.stp Monitoring for dropped packets 当你看到 probe begin 输出的 “Monitoring for dropped packets” 时,表明 SystemTap 已经将脚本编译为内核模块,并启动运行了。接着,我们切换到终端二中,再次执行 ab 命令:ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/然后,再次回到终端一中,观察 stap 命令的输出:
10031 packets dropped at nf_hook_slow 676 packets dropped at tcp_v4_rcv 7284 packets dropped at nf_hook_slow 268 packets dropped at tcp_v4_rcv 你会发现,大量丢包都发生在 nf_hook_slow 位置。看到这个名字,你应该能想到,这是在 Netfilter Hook 的钩子函数中,出现丢包问题了。但是不是 NAT,还不能确定。接下来,我们还得再跟踪 nf_hook_slow 的执行过程,这一步可以通过 perf 来完成。我们切换到终端二中,再次执行 ab 命令:ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/然后,再次切换回终端一,执行 perf record 和 perf report 命令
# 记录一会(比如 30s)后按 Ctrl+C 结束 perf record -a -g -- sleep 30 # 输出报告 perf report -g graph,0 在 perf report 界面中,输入查找命令 / 然后,在弹出的对话框中,输入 nf_hook_slow;最后再展开调用栈,就可以得到下面这个调用图:从这个图我们可以看到,nf_hook_slow 调用最多的有三个地方,分别是 ipv4_conntrack_in、br_nf_pre_routing 以及 iptable_nat_ipv4_in。换言之,nf_hook_slow 主要在执行三个动作。
- 第一,接收网络包时,在连接跟踪表中查找连接,并为新的连接分配跟踪对象(Bucket)。
- 第二,在 Linux 网桥中转发包。这是因为案例 Nginx 是一个 Docker 容器,而容器的网络通过网桥来实现;
- 第三,接收网络包时,执行 DNAT,即把 8080 端口收到的包转发给容器。
到这里,我们其实就找到了性能下降的三个来源。这三个来源,都是 Linux 的内核机制,所以接下来的优化,自然也是要从内核入手。根据以前各个资源模块的内容,我们知道,Linux 内核为用户提供了大量的可配置选项,这些选项可以通过 proc 文件系统,或者 sys 文件系统,来查看和修改。除此之外,你还可以用 sysctl 这个命令行工具,来查看和修改内核配置。比如,我们今天的主题是 DNAT,而 DNAT 的基础是 conntrack,所以我们可以先看看,内核提供了哪些 conntrack 的配置选项。我们在终端一中,继续执行下面的命令:
sysctl -a | grep conntrack net.netfilter.nf_conntrack_count = 180 net.netfilter.nf_conntrack_max = 1000 net.netfilter.nf_conntrack_buckets = 65536 net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 ... 你可以看到,这里最重要的三个指标:
- net.netfilter.nf_conntrack_count,表示当前连接跟踪数;
- net.netfilter.nf_conntrack_max,表示最大连接跟踪数;
- net.netfilter.nf_conntrack_buckets,表示连接跟踪表的大小。
所以,这个输出告诉我们,当前连接跟踪数是 180,最大连接跟踪数是 1000,连接跟踪表的大小,则是 65536。回想一下前面的 ab 命令,并发请求数是 5000,而请求数是 100000。显然,跟踪表设置成,只记录 1000 个连接,是远远不够的。实际上,内核在工作异常时,会把异常信息记录到日志中。比如前面的 ab 测试,内核已经在日志中报出了 “nf_conntrack: table full” 的错误。执行 dmesg 命令,你就可以看到:
dmesg | tail [104235.156774] nf_conntrack: nf_conntrack: table full, dropping packet [104243.800401] net_ratelimit: 3939 callbacks suppressed [104243.800401] nf_conntrack: nf_conntrack: table full, dropping packet [104262.962157] nf_conntrack: nf_conntrack: table full, dropping packet 其中,net_ratelimit 表示有大量的日志被压缩掉了,这是内核预防日志攻击的一种措施。而当你看到 “nf_conntrack: table full” 的错误时,就表明 nf_conntrack_max 太小了。那是不是,直接把连接跟踪表调大就可以了呢?调节前,你先得明白,连接跟踪表,实际上是内存中的一个哈希表。如果连接跟踪数过大,也会耗费大量内存。其实,我们上面看到的 nf_conntrack_buckets,就是哈希表的大小。哈希表中的每一项,都是一个链表(称为 Bucket),而链表长度,就等于 nf_conntrack_max 除以 nf_conntrack_buckets。比如,我们可以估算一下,上述配置的连接跟踪表占用的内存大小:
# 连接跟踪对象大小为 376,链表项大小为 16 nf_conntrack_max* 连接跟踪对象大小 +nf_conntrack_buckets* 链表项大小 = 1000*376+65536*16 B = 1.4 MB 接下来,我们将 nf_conntrack_max 改大一些,比如改成 131072(即 nf_conntrack_buckets 的 2 倍):
sysctl -w net.netfilter.nf_conntrack_max=131072 sysctl -w net.netfilter.nf_conntrack_buckets=65536 然后再切换到终端二中,重新执行 ab 命令。注意,这次我们把超时时间也改回原来的 2s:
ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... Requests per second: 6315.99 [#/sec] (mean) Time per request: 791.641 [ms] (mean) Time per request: 0.158 [ms] (mean, across all concurrent requests) Transfer rate: 4985.15 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 355 793.7 29 7352 Processing: 8 311 855.9 51 14481 Waiting: 0 292 851.5 36 14481 Total: 15 666 1216.3 148 14645 果然,现在你可以看到:
- 每秒请求数(Requests per second)为 6315(不用 NAT 时为 6576);
- 每个请求的延迟(Time per request)为 791ms(不用 NAT 时为 760ms);
- 建立连接的延迟(Connect)为 355ms(不用 NAT 时为 177ms)。
这个结果,已经比刚才的测试好了很多,也很接近最初不用 NAT 时的基准结果了。不过,你可能还是很好奇,连接跟踪表里,到底都包含了哪些东西?这里的东西,又是怎么刷新的呢?实际上,你可以用 conntrack 命令行工具,来查看连接跟踪表的内容。比如:
# -L 表示列表,-o 表示以扩展格式显示 conntrack -L -o extended | head ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744
# 统计总的连接跟踪数 conntrack -L -o extended | wc -l 14289 # 统计 TCP 协议各个状态的连接跟踪数 conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}' SYN_RECV 4 CLOSE_WAIT 9 ESTABLISHED 2877 FIN_WAIT 3 SYN_SENT 2113 TIME_WAIT 9283 # 统计各个源 IP 的连接跟踪数 conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10 14116 192.168.0.2 172 192.168.0.96 这里统计了总连接跟踪数,TCP 协议各个状态的连接跟踪数,以及各个源 IP 的连接跟踪数。你可以看到,大部分 TCP 的连接跟踪,都处于 TIME_WAIT 状态,并且它们大都来自于 192.168.0.2 这个 IP 地址(也就是运行 ab 命令的 VM2)。这些处于 TIME_WAIT 的连接跟踪记录,会在超时后清理,而默认的超时时间是 120s,你可以执行下面的命令来查看:
sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 所以,如果你的连接数非常大,确实也应该考虑,适当减小超时时间。除了上面这些常见配置,conntrack 还包含了其他很多配置选项,你可以根据实际需要,参考 nf_conntrack 的文档来配置。小结
今天,我带你一起学习了,如何排查和优化 NAT 带来的性能问题。由于 NAT 基于 Linux 内核的连接跟踪机制来实现。所以,在分析 NAT 性能问题时,我们可以先从 conntrack 角度来分析,比如用 systemtap、perf 等,分析内核中 conntrack 的行文;然后,通过调整 netfilter 内核选项的参数,来进行优化。其实,Linux 这种通过连接跟踪机制实现的 NAT,也常被称为有状态的 NAT,而维护状态,也带来了很高的性能成本。所以,除了调整内核行为外,在不需要状态跟踪的场景下(比如只需要按预定的 IP 和端口进行映射,而不需要动态映射),我们也可以使用无状态的 NAT (比如用 tc 或基于 DPDK 开发),来进一步提升性能。思考最后,给你留一个思考题。你有没有碰到过 NAT 带来的性能问题?你是怎么定位和分析它的根源的?最后,又是通过什么方法来优化解决的?你可以结合今天的案例,总结自己的思路。32 | 浅谈容器网络
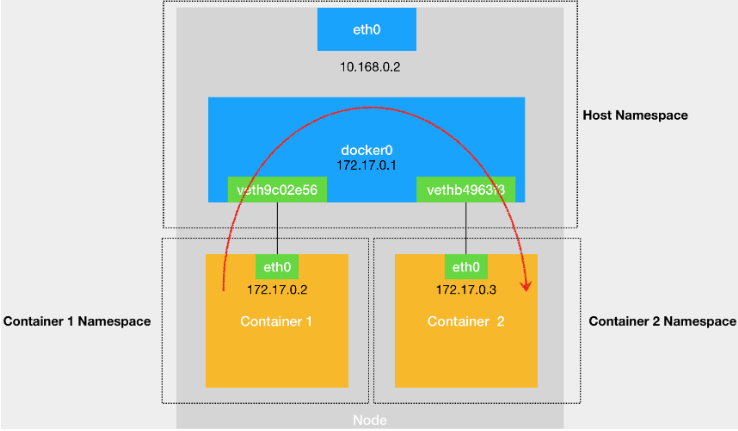
在前面讲解容器基础时,我曾经提到过一个 Linux 容器能看见的“网络栈”,实际上是被隔离在它自己的 Network Namespace 当中的。网络栈
而所谓“网络栈”,就包括了:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。对于一个进程来说,这些要素,其实就构成了它发起和响应网络请求的基本环境。$ docker run –d –net=host --name nginx-host nginx在这种情况下,这个容器启动后,直接监听的就是宿主机的 80 端口。像这样直接使用宿主机网络栈的方式,虽然可以为容器提供良好的网络性能,但也会不可避免地引入共享网络资源的问题,比如端口冲突。所以,在大多数情况下,我们都希望容器进程能使用自己 Network Namespace 里的网络栈,即:拥有属于自己的 IP 地址和端口。这时候,一个显而易见的问题就是:这个被隔离的容器进程,该如何跟其他 Network Namespace 里的容器进程进行交互呢?为了理解这个问题,你其实可以把每一个容器看做一台主机,它们都有一套独立的“网络栈”。如果你想要实现两台主机之间的通信,最直接的办法,就是把它们用一根网线连接起来;而如果你想要实现多台主机之间的通信,那就需要用网线,把它们连接在一台交换机上。网桥
在 Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge)。它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上。当然,至于为什么这些主机之间需要 MAC 地址才能进行通信,这就是网络分层模型的基础知识了。不熟悉这块内容的读者,可以通过这篇文章来学习一下。docker0
而为了实现上述目的,Docker 项目会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信。可是,我们又该如何把这些容器“连接”到 docker0 网桥上呢?Veth Pair
这时候,我们就需要使用一种名叫Veth Pair的虚拟设备了。Veth Pair 设备的特点是:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。这就使得 Veth Pair 常常被用作连接不同 Network Namespace 的“网线”。比如,现在我们启动了一个叫作 nginx-1 的容器:$ docker run –d --name nginx-1 nginx然后进入到这个容器中查看一下它的网络设备:
# 在宿主机上 $ docker exec -it nginx-1 /bin/bash # 在容器里 root@2b3c181aecf1:/# ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.0.2 netmask 255.255.0.0 broadcast 0.0.0.0 inet6 fe80::42:acff:fe11:2 prefixlen 64 scopeid 0x20<link> ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet) RX packets 364 bytes 8137175 (7.7 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 281 bytes 21161 (20.6 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 $ route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 可以看到,这个容器里有一张叫作 eth0 的网卡,它正是一个 Veth Pair 设备在容器里的这一端。通过 route 命令查看 nginx-1 容器的路由表,我们可以看到,这个 eth0 网卡是这个容器里的默认路由设备;所有对 172.17.0.0/16 网段的请求,也会被交给 eth0 来处理(第二条 172.17.0.0 路由规则)。而这个 Veth Pair 设备的另一端,则在宿主机上。你可以通过查看宿主机的网络设备看到它,如下所示:
# 在宿主机上 ... docker0 Link encap:Ethernet HWaddr 02:42:d8:e4:df:c1 inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0 inet6 addr: fe80::42:d8ff:fee4:dfc1/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:309 errors:0 dropped:0 overruns:0 frame:0 TX packets:372 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:18944 (18.9 KB) TX bytes:8137789 (8.1 MB) veth9c02e56 Link encap:Ethernet HWaddr 52:81:0b:24:3d:da inet6 addr: fe80::5081:bff:fe24:3dda/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:288 errors:0 dropped:0 overruns:0 frame:0 TX packets:371 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:21608 (21.6 KB) TX bytes:8137719 (8.1 MB) bridge name bridge id STP enabled interfaces docker0 8000.0242d8e4dfc1 no veth9c02e56 通过 ifconfig 命令的输出,你可以看到,nginx-1 容器对应的 Veth Pair 设备,在宿主机上是一张虚拟网卡。它的名字叫作 veth9c02e56。并且,通过 brctl show 的输出,你可以看到这张网卡被“插”在了 docker0 上。这时候,如果我们再在这台宿主机上启动另一个 Docker 容器,比如 nginx-2:
$ docker run –d --name nginx-2 nginx $ brctl show bridge name bridge id STP enabled interfaces docker0 8000.0242d8e4dfc1 no veth9c02e56 vethb4963f3 你就会发现一个新的、名叫 vethb4963f3 的虚拟网卡,也被“插”在了 docker0 网桥上。同宿主机不同容器通信
这时候,如果你在 nginx-1 容器里 ping 一下 nginx-2 容器的 IP 地址(172.17.0.3),就会发现同一宿主机上的两个容器默认就是相互连通的。这其中的原理其实非常简单,我来解释一下。当你在 nginx-1 容器里访问 nginx-2 容器的 IP 地址(比如 ping 172.17.0.3)的时候,这个目的 IP 地址会匹配到 nginx-1 容器里的第二条路由规则。可以看到,这条路由规则的网关(Gateway)是 0.0.0.0,这就意味着这是一条直连规则,即:凡是匹配到这条规则的 IP 包,应该经过本机的 eth0 网卡,通过二层网络直接发往目的主机。而要通过二层网络到达 nginx-2 容器,就需要有 172.17.0.3 这个 IP 地址对应的 MAC 地址。所以 nginx-1 容器的网络协议栈,就需要通过 eth0 网卡发送一个 ARP 广播,来通过 IP 地址查找对应的 MAC 地址。备注:ARP(Address Resolution Protocol),是通过三层的 IP 地址找到对应的二层 MAC 地址的协议。我们前面提到过,这个 eth0 网卡,是一个 Veth Pair,它的一端在这个 nginx-1 容器的 Network Namespace 里,而另一端则位于宿主机上(Host Namespace),并且被“插”在了宿主机的 docker0 网桥上。一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。从设备会被“剥夺”调用网络协议栈处理数据包的资格,从而“降级”成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥。所以,在收到这些 ARP 请求之后,docker0 网桥就会扮演二层交换机的角色,把 ARP 广播转发到其他被“插”在 docker0 上的虚拟网卡上。这样,同样连接在 docker0 上的 nginx-2 容器的网络协议栈就会收到这个 ARP 请求,从而将 172.17.0.3 所对应的 MAC 地址回复给 nginx-1 容器。有了这个目的 MAC 地址,nginx-1 容器的 eth0 网卡就可以将数据包发出去。而根据 Veth Pair 设备的原理,这个数据包会立刻出现在宿主机上的 veth9c02e56 虚拟网卡上。不过,此时这个 veth9c02e56 网卡的网络协议栈的资格已经被“剥夺”,所以这个数据包就直接流入到了 docker0 网桥里。docker0 处理转发的过程,则继续扮演二层交换机的角色。此时,docker0 网桥根据数据包的目的 MAC 地址(也就是 nginx-2 容器的 MAC 地址),在它的 CAM 表(即交换机通过 MAC 地址学习维护的端口和 MAC 地址的对应表)里查到对应的端口(Port)为:vethb4963f3,然后把数据包发往这个端口。而这个端口,正是 nginx-2 容器“插”在 docker0 网桥上的另一块虚拟网卡,当然,它也是一个 Veth Pair 设备。这样,数据包就进入到了 nginx-2 容器的 Network Namespace 里。所以,nginx-2 容器看到的情况是,它自己的 eth0 网卡上出现了流入的数据包。这样,nginx-2 的网络协议栈就会对请求进行处理,最后将响应(Pong)返回到 nginx-1。以上,就是同一个宿主机上的不同容器通过 docker0 网桥进行通信的流程了。我把这个流程总结成了一幅示意图,如下所示:需要注意的是,在实际的数据传递时,上述数据的传递过程在网络协议栈的不同层次,都有 Linux 内核 Netfilter 参与其中。所以,如果感兴趣的话,你可以通过打开 iptables 的 TRACE 功能查看到数据包的传输过程,具体方法如下所示:
# 在宿主机上执行 $ iptables -t raw -A OUTPUT -p icmp -j TRACE $ iptables -t raw -A PREROUTING -p icmp -j TRACE 通过上述设置,你就可以在 /var/log/syslog 里看到数据包传输的日志了。这一部分内容,你可以在课后结合iptables 的相关知识进行实践,从而验证我和你分享的数据包传递流程。熟悉了 docker0 网桥的工作方式,你就可以理解,在默认情况下,被限制在 Network Namespace 里的容器进程,实际上是通过 Veth Pair 设备 + 宿主机网桥的方式,实现了跟同其他容器的数据交换。宿主机访问容器
与之类似地,当你在一台宿主机上,访问该宿主机上的容器的 IP 地址时,这个请求的数据包,也是先根据路由规则到达 docker0 网桥,然后被转发到对应的 Veth Pair 设备,最后出现在容器里。这个过程的示意图,如下所示:容器连接另外一个宿主机
同样地,当一个容器试图连接到另外一个宿主机时,比如:ping 10.168.0.3,它发出的请求数据包,首先经过 docker0 网桥出现在宿主机上。然后根据宿主机的路由表里的直连路由规则(10.168.0.0/24 via eth0)),对 10.168.0.3 的访问请求就会交给宿主机的 eth0 处理。所以接下来,这个数据包就会经宿主机的 eth0 网卡转发到宿主机网络上,最终到达 10.168.0.3 对应的宿主机上。当然,这个过程的实现要求这两台宿主机本身是连通的。这个过程的示意图,如下所示:所以说,当你遇到容器连不通“外网”的时候,你都应该先试试 docker0 网桥能不能 ping 通,然后查看一下跟 docker0 和 Veth Pair 设备相关的 iptables 规则是不是有异常,往往就能够找到问题的答案了。跨主通信
不过,在最后一个“Docker 容器连接其他宿主机”的例子里,你可能已经联想到了这样一个问题:如果在另外一台宿主机(比如:10.168.0.3)上,也有一个 Docker 容器。那么,我们的 nginx-1 容器又该如何访问它呢?这个问题,其实就是容器的“跨主通信”问题。在 Docker 的默认配置下,一台宿主机上的 docker0 网桥,和其他宿主机上的 docker0 网桥,没有任何关联,它们互相之间也没办法连通。所以,连接在这些网桥上的容器,自然也没办法进行通信了。不过,万变不离其宗。如果我们通过软件的方式,创建一个整个集群“公用”的网桥,然后把集群里的所有容器都连接到这个网桥上,不就可以相互通信了吗?说得没错。这样一来,我们整个集群里的容器网络就会类似于下图所示的样子:可以看到,构建这种容器网络的核心在于:我们需要在已有的宿主机网络上,再通过软件构建一个覆盖在已有宿主机网络之上的、可以把所有容器连通在一起的虚拟网络。所以,这种技术就被称为:Overlay Network(覆盖网络)。而这个 Overlay Network 本身,可以由每台宿主机上的一个“特殊网桥”共同组成。比如,当 Node 1 上的 Container 1 要访问 Node 2 上的 Container 3 的时候,Node 1 上的“特殊网桥”在收到数据包之后,能够通过某种方式,把数据包发送到正确的宿主机,比如 Node 2 上。而 Node 2 上的“特殊网桥”在收到数据包后,也能够通过某种方式,把数据包转发给正确的容器,比如 Container 3。甚至,每台宿主机上,都不需要有一个这种特殊的网桥,而仅仅通过某种方式配置宿主机的路由表,就能够把数据包转发到正确的宿主机上。这些内容,我在后面的文章中会为你一一讲述。总结
在今天这篇文章中,我主要为你介绍了在本地环境下,单机容器网络的实现原理和 docker0 网桥的作用。这里的关键在于,容器要想跟外界进行通信,它发出的 IP 包就必须从它的 Network Namespace 里出来,来到宿主机上。而解决这个问题的方法就是:为容器创建一个一端在容器里充当默认网卡、另一端在宿主机上的 Veth Pair 设备。上述单机容器网络的知识,是后面我们讲解多机容器网络的重要基础,请务必认真消化理解。思考题
尽管容器的 Host Network 模式有一些缺点,但是它性能好、配置简单,并且易于调试,所以很多团队会直接使用 Host Network。那么,如果要在生产环境中使用容器的 Host Network 模式,你觉得需要做哪些额外的准备工作呢?
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-finalv1-2-ct-ed94d33e885a41748071ca15289605c9.png)
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-finalv1-3-ct-9d3e1bf44a554e3db31f706201fc69f6.png)
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-finalv1-4-ct-9ffde2c7142849819c3fcf5e305a242f.png)
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-final-5-ct-373fc5a9edc74359819021555f37467d.png)
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-finalv1-6-ct-f21bdae22e54415b881d77babe8ca51d.png)
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-finalv1-7-ct-e102db1b79da4926b510f944183989f8.png)
:max_bytes(150000):strip_icc():format(webp)/layers-of-the-osi-model-illustrated-818017-finalv1-8-ct-089b2573bf47462d85f9343f50329f72.png)








 浙公网安备 33010602011771号
浙公网安备 33010602011771号