诡异页面调试问题-crob,系统分层泛谈,ThreadLocal存储、泄露、TTL线程传递
记录一次诡异页面调试问题
现象:
在一个风平浪静的早上,收到运营同学反馈系统页面打不开要么报错,并且再次刷新后会调到一个公用的不同域名的错误页。
分析:
很熟练的打开了chrome的console页面,然后看到加载js的时候报了一个错Cross-Origin Read Blocking(CROB)的错误。
根据后面的提示打开了一个https://www.chromestatus.com/feature/5629709824032768的链接,以为是我们的script没有加类型导致(原来的引入js是<script src="xxx.js"/>),就满心欢喜规范了一下引入的js,但是上线后发现情况依旧。
看了很久,也没有发现什么端倪。请教了一个前端架构师,得到了一个很宝贵的建议,这个是不是请求就没到后端,后端做了什么拦截还没有到你的应用?
突然就好像明白了,原来访问后端应用服务器的时候有一台机器挂掉了,本来应该报404的错误,但是前面有一个登陆拦截,将404转成了500的错误,然后就出现了Corss-Origin Read Blocking(CROB)的错误。重启果然解决问题。
后记:
Cros和Crob不是很熟悉,导致解决问题很慢。
遇见前端请求失败时,需要注意到错误码不一定是自己应用返回的,难以通过前端来定位错误时,更多的需要从后端开始定位问题。
- 使用绑定host的方式来访问应用URL
- 添加后端URL监控
打印出来是null但是却不是null的情况
在今天看日志的时候,很明显看到sku.getWidth()打印出来的是null,但是使用sku.getWidth() == null 和Strings.isBlank(sku.getWidth())返回的都是false.
后来想起来width可能是"null"的字符串,所以打印出来是null,实际却不是。再往里看,原来用了String.valueOf()来设置width字段。
String.java
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}Objects.java
public static String toString(Object o) {
return String.valueOf(o);
}public static String toString(Object o, String nullDefault) {
return (o != null) ? o.toString() : nullDefault;
}所以比较安全的toString方法是Objects.toString(obj, "")
系统分层泛谈
今天同事提出了一个关于系统分层原因的问题。
做为后端研发工程师,我们基本都听过MVC模式/框架,但是目前我们系统拆分的情况,会遇到完全是服务端的系统,同时一个系统维护的研发人员并不多的情况下,那么是否依然需要遵循类似MVC模式/框架的思想,对系统进行分层呢?
如果需要是为什么呢?如果不需要又是为什么呢?
基于上面的问题,系统分层的意义究竟又是什么呢
对于这种设计类的问题,在工作中有一些零散的想法,正好借此机会结构一下。
这个问题初看起来就如问题本身来说的一样"显而易见", 分层当然会更容易管理,更容易实现。
从根本上来讲,分层追求的是降低系统的开发维护成本。这是因为对人类而言,一切复杂问题的处理思想都是分而治之。可以将人类看作只有一个"CPU线程"和"寄存器",但只要有处理能力的上限都会从分治的思想受益。正如<<超体>>中所说,分类只是为了简化。
我们只知道一加一等于二,可是一加一根本不等于二,世界本没有数字也没有字母,我们把我们的存在塞入人类的框架体系当中,使之便于理解,我们创造了一个体系,以便忘却原本难以理解的体系。
假如我们认可了分而治之的思想,那么将这种思想运用到所谓的软件中会产生什么样的反应和结果呢呢?
观其形
首先,我们有了MVC,MVVW, MVP等等设计模式。这种设计模式是一种功能框架,将一个完整的功能拆分到不同的组件。试想经历MVC等设计模式从无到有的开发者,一定会感觉有了这些很幸福。这些固定的模式就像青霉素一样,能不关心细菌的种类进行使用,并且很大情况下不会出现问题。
从分层方式可以知道,上面的组件解耦方式属于功能水平解耦,那么也肯定也会存在垂直解耦。例如现在的微服务就是最好的例子。与水平解耦模式不同的是,垂直解耦有了一些业务的味道在里面。
那么对于这两种组件解耦方式,是否可以找出共同的部分? 而且这些分层模式是否与现在火热的DDD有关系?
辩其象,识其形,悟其道。
经过不断探索,大师们总结组件设计原则SOLID和组件组合的原则REP, CCP, CRP等。这些原则理解起来比较绕,所以我们总结一下重点:
- 设计一个组件最重要的是单一职责和实现替换。
- 符合了单一职责的组件组装应该以稳定性顺序进行组合。
明白了这两点,那么DDD为什么会大火就有了一个合理的解释,也是为了更好地完成"单一职责"。
回答开题
不管分层还是不分层,我们最终目的都是为了减少成本。
为了达到这个目的,首先我们需要对系统职责有清晰的认知,其次需要对系统演进有一定的把握。
在此基础上,再对当前已存在的特定分层模式(MVC, Cola)是进行简化,来最大化分层模式的收益。
Maven私服(Best Practice - Using a Repository Manager)
A repository manager is a dedicated server application designed to manage repositories of binary components. The usage of a repository manager is considered an essential best practice for any significant usage of Maven.
译:一个库管理工具是一个单独的服务端程序,用来管理库里的二进制组件。使用库管理工具被认为是使用maven的一种最基本好的办法。
Purpose
A repository manager serves these essential purposes:
- act as dedicated proxy server for public Maven repositories
- provide repositories as a deployment destination for your Maven project outputs
译:一个管理库工具可以有以下目的:
* 作为Maven公开库的代理server
* 作为你的Maven工程部署文件的地址
Benefits and Features
Using a repository manager provides the following benefits and features:
- significantly reduced number of downloads off remote repositories, saving time and bandwidth resulting in increased build performance
- improved build stability due to reduced reliance on external repositories
- increased performance for interaction with remote SNAPSHOT repositories
- potential for control of consumed and provided artifacts
- creates a central storage and access to artifacts and meta data about them exposing build outputs to consumer such as other projects and developers, but also QA or operations teams or even customers
- provides an effective platform for exchanging binary artifacts within your organization and beyond without the need for building artifact from source
译:使用一个库管理工具将提供一下好处与特性:
* 很大程度减少了远程公开库的下载,节省时间和带宽,从而提供更好的性能.
* 提供build的稳定性,因为不需要再依赖到其他的库
* 增加与远程SNAPSHOT库交互的性能。
* 可能提供关于使用和提供工程的控制。
* 创建一个中央存储,并且访问工程和原数据给使用者比如工程开发人员,QA人员,甚至顾客。
Available Repository Managers
The following list (alphabetical order) of open source and commercial repository managers are known to support the repository format used by Maven. Please refer to the respective linked web sites for further information about repository management in general and the features provided by these products.
- Apache Archiva (open source)
- JFrog Artifactory Open Source (open source)
- JFrog Artifactory Pro (commercial)
- Sonatype Nexus OSS (open source)
- Sonatype Nexus Pro (commercial)
译:以下是以字母为顺序的开源和商业的公认的Maven管理工具。
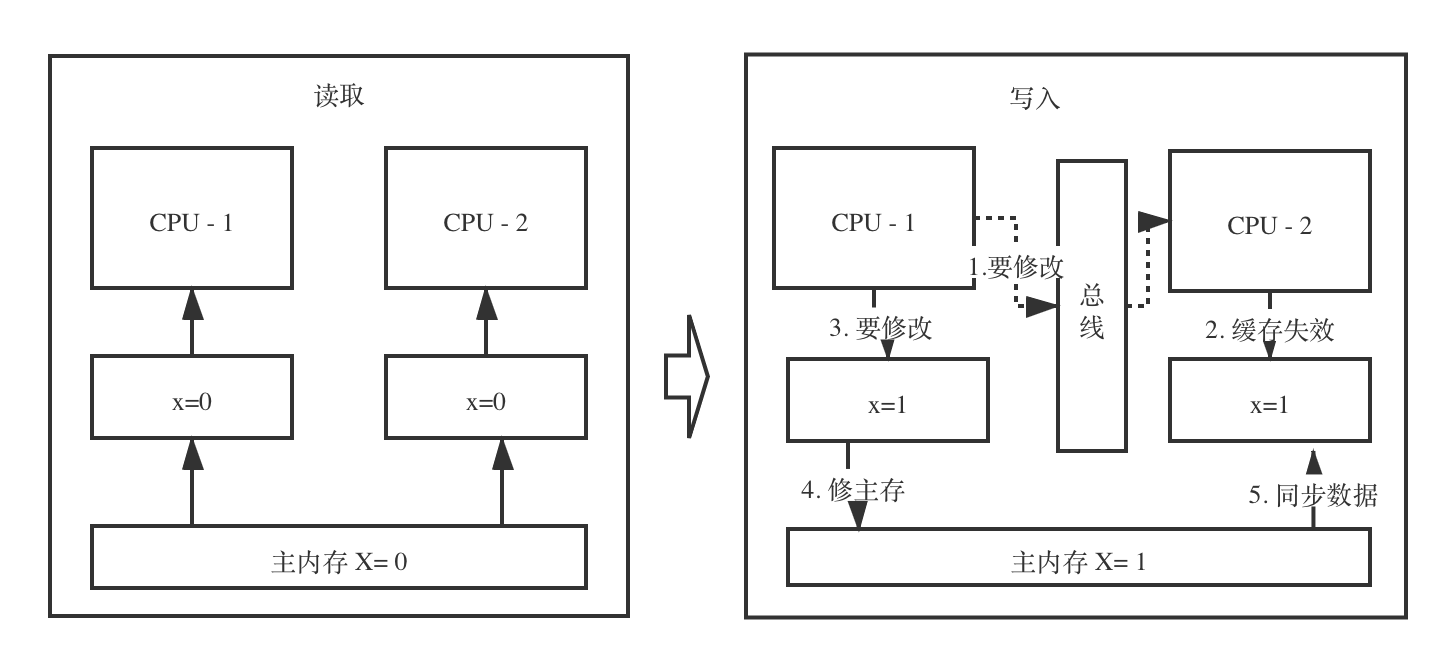
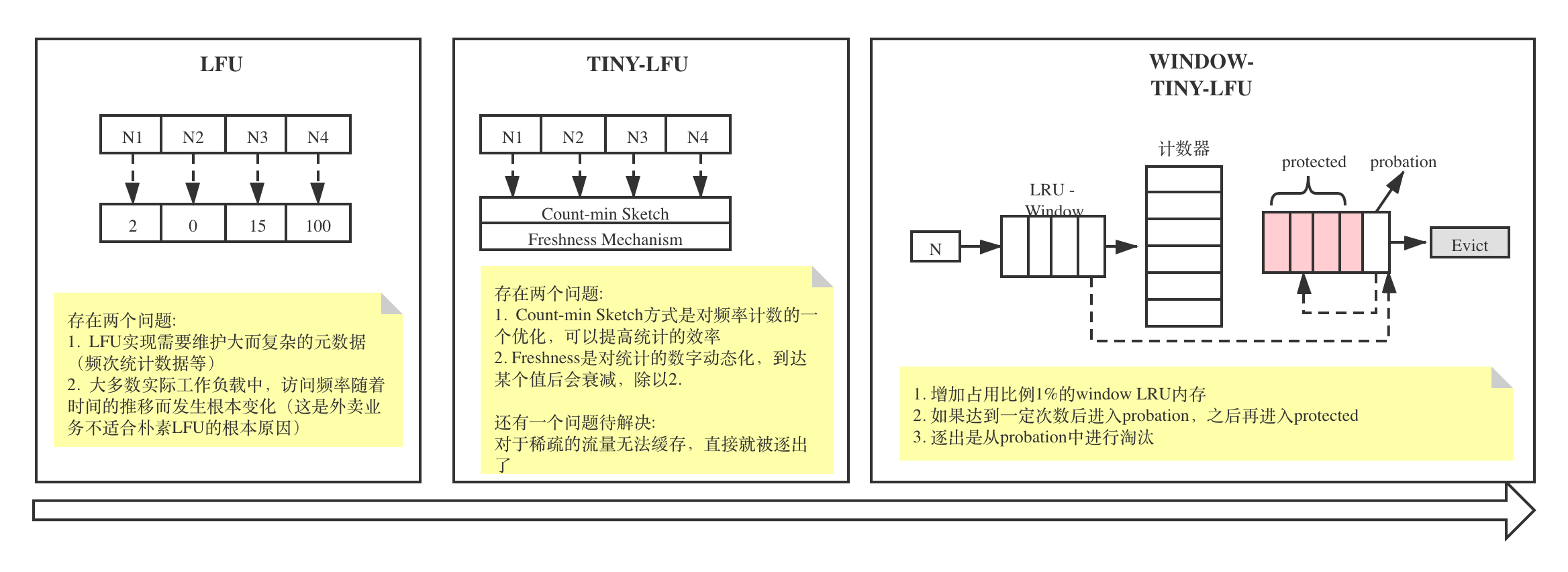
Guava Cache缓存机制说明_recursive load of-CSDN博客

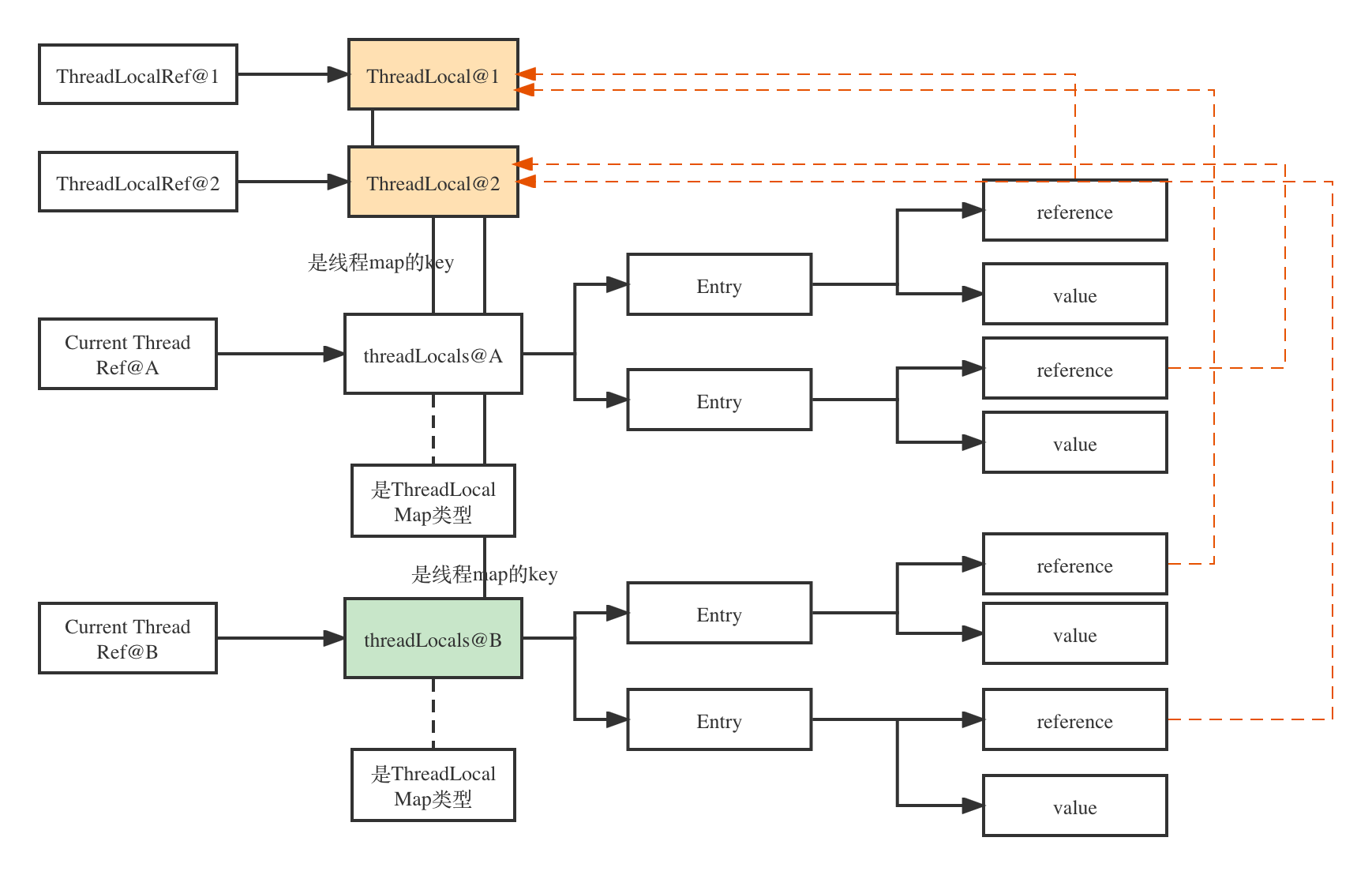
这里其实有点难以理解。这里来说一下要点。
- 每个Thread有自己的属性
threadLocals,是ThreadLocalMap类型,key是threahdLocal实例,value是线程使用这个threadlocal时的value - ThreadLocalMap是一个EntryTable,Entry拥有对threadLocal实例的弱引用和value
- ThreadLocal实例对象拥有两个引用,一个是它本身的强引用
ThreadLocalRef@1和ThreadLocalRef@2,另外一个则是弱引用CurrentThreadRef@A和CurrentThreadRef@B-> map -> entry --> reference。
内存泄露分析:
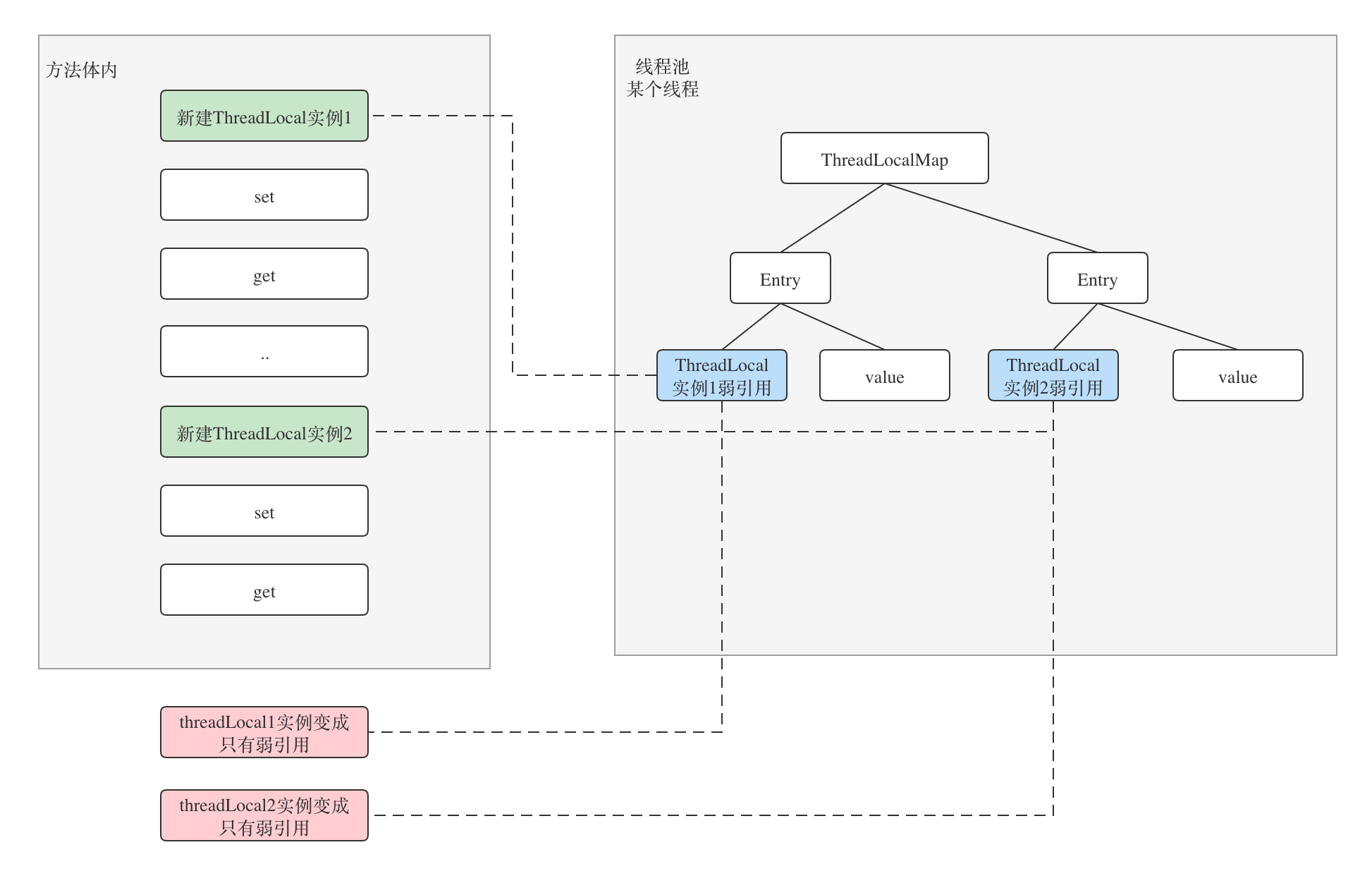
前提条件:
- ThreadLocal实例使用完被回收掉。因为ThreadLocalMap的Entry持有的是对ThreadLocal实例的弱引用,所以在方法结束后,ThreadLocal实例就会变成只有弱引用的对象,只要有GC就会被回收掉。
- Thread一直存在,如果不存在,那么挂在Thread上的threadlocals肯定都会被回收,就不存在泄露问题了。
原因分析:
当强引用ThreadLocalRef@1和ThreadLocalRef@2使用完成会变成不可达,ThreadLocal@1和ThreadLocal@2就处于游离态了,会被GC掉,这时候Entry的reference对象也就是null,造成value无法访问,也就是我们说的内存泄露。
那么使用static后,是否可以避免内存泄露呢?
在这里其实需要提一下内存泄露的定义,以下的定义来自wiki:
Memory leak occurs when a computer program incorrectly manages memory allocations in a way that memory which is no longer needed is not released.
可见内存泄露是内存如果是不会再使用又没有回收就是内存泄露。
所以本身来说, static 变量是一个GC ROOT, 如果一直没有使用也可以称之为内存泄露。
那为什么我们还建议使用static的ThreadLocal类型呢?
首先,主要的原因还是看怎么去看待它,是实例级别还是全局级别,从线程角度来看,它更符合全局的定义,所以使用了static。
其次是,ThreadLocalMap在get、set、remove时都会进行清理,也是避免了内存泄露,不过作为应用程序最好还是在使用后进行remove清理,否则可能会出现异常情况。
为什么要用弱引用不是强引用?
假如说我们使用强引用的话,会发生怎么样的情况呢? 当ThreadLocalRef引用设置为null后,这个对象因为线程存在无法回收,从而产生内存泄露,当线程或者ThreadLocal使用频繁的情况时,这种无法回收的对象会越来越多,最终甚至可能会导致OOM。
如何在线程之间传递ThreadLocal
现在普遍都会使用阿里的TTL框架(TransmittableThreadLocal),也是我们今天的主角。
其实JDK默认提供了父子线程的传递。
TTL的描述: JDK的InheritableThreadLocal类可以完成父线程到子线程的值传递。但对于使用线程池等会池化复用线程的执行组件的情况,线程由线程池创建好,并且线程是池化起来反复使用的;这时父子线程关系的ThreadLocal值传递已经没有意义,应用需要的实际上是把 任务提交给线程池时的ThreadLocal值传递到 任务执行时。
首先我们看下InheritableThreadLocal是怎么复制的,关键的代码在Thread.init()方法中.
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
...
// 如果是是可继承的threadlocal并且父线程的inheritableThreadLocal不为空,就复制到一个新的map中
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
...
}create方法调用了new ThreadLocalMap(ThreadLocalMap parentMap),所以我们来看下具体的方法体。
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}总结一下,InheritableThreadLocal是新建了一个Map和Entry,但是里面的key和value并没有clone。
阿里的TTL理解起来并不容易,所以我们先讲讲原理。

重点说明:
- 首先是注册两个Transmittee的实现。Transmittee的有两部分组成,C - 获取的数据 和 B - 原来获取数据的Backup,这两个类型对于ttlTransmittee都是HashMap。
- 当ThreadLocal开始进行set时,除了原始的threadlocal的set功能,还会调用
addThisToHolder。holder是一个静态的可继承的ThreadLocal变量,所以每个线程都可以有自己的。这个变量里存储的类型是WeakHashMap,key是TransmitThreadLocal,value是null。每个线程都可以有自己的WeakHashMap,可以有多个TransmitThreadLocal变量。 - 在ttlTransmittee的操作中,会对holder进行循环遍历。capture是获取holder中的threadlocal和value,replay是先备份,然后设置value,restore则是对backup进行恢复。
- 最后就是TtlRunnable中调用Transmitter的caputre/replay/restore。capture是在实例化的时候调用的,值得注意的是实例化其实在父线程中完成的,然后运行过程中获取父线程实例的值,之后在replay和restore。
如果只想了解原理,那么到这里就可以结束了,对代码细节感兴趣的同学我们继续向下。
TransmittableThreadLocal继承了InheritableThreadLocal,所以具备父子复制的能力。然后我们接着TTL官方的图来解释。
如果以装饰模式来看待这个问题,就会很容易发现TtlRunnable是真正把TransmittableThreadLocal起来的类。TtlRunnable的关键代码是:
public final class TtlRunnable implements Runnable, TtlWrapper<Runnable>, TtlEnhanced, TtlAttachments {
// 从父线程传递的值
private final AtomicReference<Object> capturedRef;
// 原始的runnable
private final Runnable runnable;
// 是否运行后清除
private final boolean releaseTtlValueReferenceAfterRun;
private TtlRunnable(@NonNull Runnable runnable, boolean releaseTtlValueReferenceAfterRun) {
// 调用了Transmitter静态的capture 先下结论是会返回父线程的Transmitter和Value(被称为Snapshot),之后我们看是如何返回的
this.capturedRef = new AtomicReference<>(capture());
this.runnable = runnable;
this.releaseTtlValueReferenceAfterRun = releaseTtlValueReferenceAfterRun;
}
public void run() {
// 获取Snapshot
final Object captured = capturedRef.get();
// 如果snapshot为null或者要释放没成功,就抛出异常
if (captured == null || releaseTtlValueReferenceAfterRun && !capturedRef.compareAndSet(captured, null)) {
throw new IllegalStateException("TTL value reference is released after run!");
}
// 执行前backup一下
final Object backup = replay(captured);
try {
// 任务执行
runnable.run();
} finally {
// 恢复backup
restore(backup);
}
}
... 我们看到在run的方法里执行了获取的capture -> replay -> restore,从Transmitter的注释来看,他们分别代表了以下含义:
Thread A capture: 捕获当前线程的threadlocal的值
Thread B replay: 将capture到的线程重放到当前线程(完成父子线程的值传递),返回当前线程的backup
Thread B restore: 将backup的线程值恢复到当前线程
阿里官方文档称这个操作是CRR,从我搜索的资料看应该他们自己的简写,没有相关的专业术语。
接下来我们来解析这个过程是怎么发生的。一切的一切要从com.alibaba.ttl.TransmittableThreadLocal#set说起。
@Override
public final void set(T value) {
if (!disableIgnoreNullValueSemantics && null == value) {
// may set null to remove value
remove();
} else {
// 调用ThreadLocal的set方法 完成当前线程的threadlocalMap创建工程
super.set(value);
// 这一步是关键 把当前TransmittableThreadLocal添加到了holder
addThisToHolder();
}
}com.alibaba.ttl.TransmittableThreadLocal#addThisToHolder方法:
@Override
private void addThisToHolder() {
if (!holder.get().containsKey(this)) {
holder.get().put((TransmittableThreadLocal<Object>) this, null); // WeakHashMap supports null value.
}
}我们看看holder的结构是什么:
private static final InheritableThreadLocal<WeakHashMap<TransmittableThreadLocal<Object>, ?>> holder =
new InheritableThreadLocal<WeakHashMap<TransmittableThreadLocal<Object>, ?>>() {
@Override
protected WeakHashMap<TransmittableThreadLocal<Object>, ?> initialValue() {
return new WeakHashMap<>();
}
@Override
protected WeakHashMap<TransmittableThreadLocal<Object>, ?> childValue(WeakHashMap<TransmittableThreadLocal<Object>, ?> parentValue) {
return new WeakHashMap<TransmittableThreadLocal<Object>, Object>(parentValue);
}
};holder是一个InheritableThreadLocal,能够支持父子类型传递。里面存储的是WeakHashMap,可以保存多个TransmittableThreadLocal。
放入holder之后就完成了ThreadLocal的关联。接下来让我们看看Transmitter的代码:
public static class Transmitter {
@NonNull
public static Object capture() {
// 新建一个HashMap,来存放Transmittee和它的值
final HashMap<Transmittee<Object, Object>, Object> transmittee2Value = new HashMap<>(transmitteeSet.size());
// 循环transmitteeSet
for (Transmittee<Object, Object> transmittee : transmitteeSet) {
try {
// 放入到新建的map中
transmittee2Value.put(transmittee, transmittee.capture());
} catch (Throwable t) {
if (logger.isLoggable(Level.WARNING)) {
logger.log(Level.WARNING, "exception when Transmitter.capture for transmittee " + transmittee +
"(class " + transmittee.getClass().getName() + "), just ignored; cause: " + t, t);
}
}
}
// 返回快照
return new Snapshot(transmittee2Value);
}
@NonNull
public static Object replay(@NonNull Object captured) {
// 快照是从capture拿到的HashMap,里面存储的是transmittee和原来捕获的值
final Snapshot capturedSnapshot = (Snapshot) captured;
// 新建一个value
final HashMap<Transmittee<Object, Object>, Object> transmittee2Value = new HashMap<>(capturedSnapshot.transmittee2Value.size());
// 循环快照
for (Map.Entry<Transmittee<Object, Object>, Object> entry : capturedSnapshot.transmittee2Value.entrySet()) {
Transmittee<Object, Object> transmittee = entry.getKey();
try {
// 获取原来transmittee捕获的值
Object transmitteeCaptured = entry.getValue();
// 放入transmittee和值,这里调用replay的作用按照原来的有两个作用,一个是用来备份,一个是用来将捕获的值放到当前线程中
transmittee2Value.put(transmittee, transmittee.replay(transmitteeCaptured));
} catch (Throwable t) {
if (logger.isLoggable(Level.WARNING)) {
logger.log(Level.WARNING, "exception when Transmitter.replay for transmittee " + transmittee +
"(class " + transmittee.getClass().getName() + "), just ignored; cause: " + t, t);
}
}
}
// 返回备份的值
return new Snapshot(transmittee2Value);
}
...
public static void restore(@NonNull Object backup) {
// 循环backup的值
for (Map.Entry<Transmittee<Object, Object>, Object> entry : ((Snapshot) backup).transmittee2Value.entrySet()) {
Transmittee<Object, Object> transmittee = entry.getKey();
try {
// 获取backup的值
Object transmitteeBackup = entry.getValue();
// 恢复backup的值到当前线程
transmittee.restore(transmitteeBackup);
} catch (Throwable t) {
if (logger.isLoggable(Level.WARNING)) {
logger.log(Level.WARNING, "exception when Transmitter.restore for transmittee " + transmittee +
"(class " + transmittee.getClass().getName() + "), just ignored; cause: " + t, t);
}
}
}
}这里出现了一个新的角色: Transmittee。Transmittee是一个接口,实现是匿名类的方式,有两个实现。
TransmittableThreadLocal的实现:
private static final Transmittee<HashMap<TransmittableThreadLocal<Object>, Object>, HashMap<TransmittableThreadLocal<Object>, Object>> ttlTransmittee = new Transmittee<HashMap<TransmittableThreadLocal<Object>, Object>, HashMap<TransmittableThreadLocal<Object>, Object>>() {
@NonNull
public HashMap<TransmittableThreadLocal<Object>, Object> capture() {
// 从holder中取出来TransmitThreadLocal的数量 新建一个HashMap来存储
HashMap<TransmittableThreadLocal<Object>, Object> ttl2Value = new HashMap(((WeakHashMap)TransmittableThreadLocal.holder.get()).size());
// 循环holder中的TransmitThreadLocal
Iterator var2 = ((WeakHashMap)TransmittableThreadLocal.holder.get()).keySet().iterator();
while(var2.hasNext()) {
TransmittableThreadLocal<Object> threadLocal = (TransmittableThreadLocal)var2.next();
// 放入threadlocal和threadlocal复制的值
ttl2Value.put(threadLocal, threadLocal.copyValue());
}
return ttl2Value;
}
@NonNull
public HashMap<TransmittableThreadLocal<Object>, Object> replay(@NonNull HashMap<TransmittableThreadLocal<Object>, Object> captured) {
// 获取holder的size 新建backup的HashMap
HashMap<TransmittableThreadLocal<Object>, Object> backup = new HashMap(((WeakHashMap)TransmittableThreadLocal.holder.get()).size());
// 循环holder中的变量
Iterator<TransmittableThreadLocal<Object>> iterator = ((WeakHashMap)TransmittableThreadLocal.holder.get()).keySet().iterator();
while(iterator.hasNext()) {
TransmittableThreadLocal<Object> threadLocal = (TransmittableThreadLocal)iterator.next();
// 放入backup的threadLocal和threadLocal的值
backup.put(threadLocal, threadLocal.get());
// 如果父线程中没有这个threadlocal 就从holder的循环中移除掉
if (!captured.containsKey(threadLocal)) {
iterator.remove();
threadLocal.superRemove();
}
}
// 将captured的value设置到capture的threadlocal里
TransmittableThreadLocal.Transmitter.setTtlValuesTo(captured);
TransmittableThreadLocal.doExecuteCallback(true);
return backup;
}
@NonNull
public HashMap<TransmittableThreadLocal<Object>, Object> clear() {
return this.replay(new HashMap(0));
}
public void restore(@NonNull HashMap<TransmittableThreadLocal<Object>, Object> backup) {
TransmittableThreadLocal.doExecuteCallback(false);
// 循环holder
Iterator<TransmittableThreadLocal<Object>> iterator = ((WeakHashMap)TransmittableThreadLocal.holder.get()).keySet().iterator();
while(iterator.hasNext()) {
TransmittableThreadLocal<Object> threadLocal = (TransmittableThreadLocal)iterator.next();
// 如果backup的没有包括此threadlocal 就移除掉
if (!backup.containsKey(threadLocal)) {
iterator.remove();
threadLocal.superRemove();
}
}
// 将backup的值进行还原
TransmittableThreadLocal.Transmitter.setTtlValuesTo(backup);
}
};threadlocal的实现大体一致,只不过是存储的类型从TransmittableThreadLocal变成了ThreadLocal,这里就不进行展开了。
总的来说,TTL实现的功能并不复杂,但代码很复杂,难以理解。这或许是我们常说的那句: 美都是肤浅的。
ThreadLocal存储、泄露、TTL线程传递详解_ttlrunnable-CSDN博客
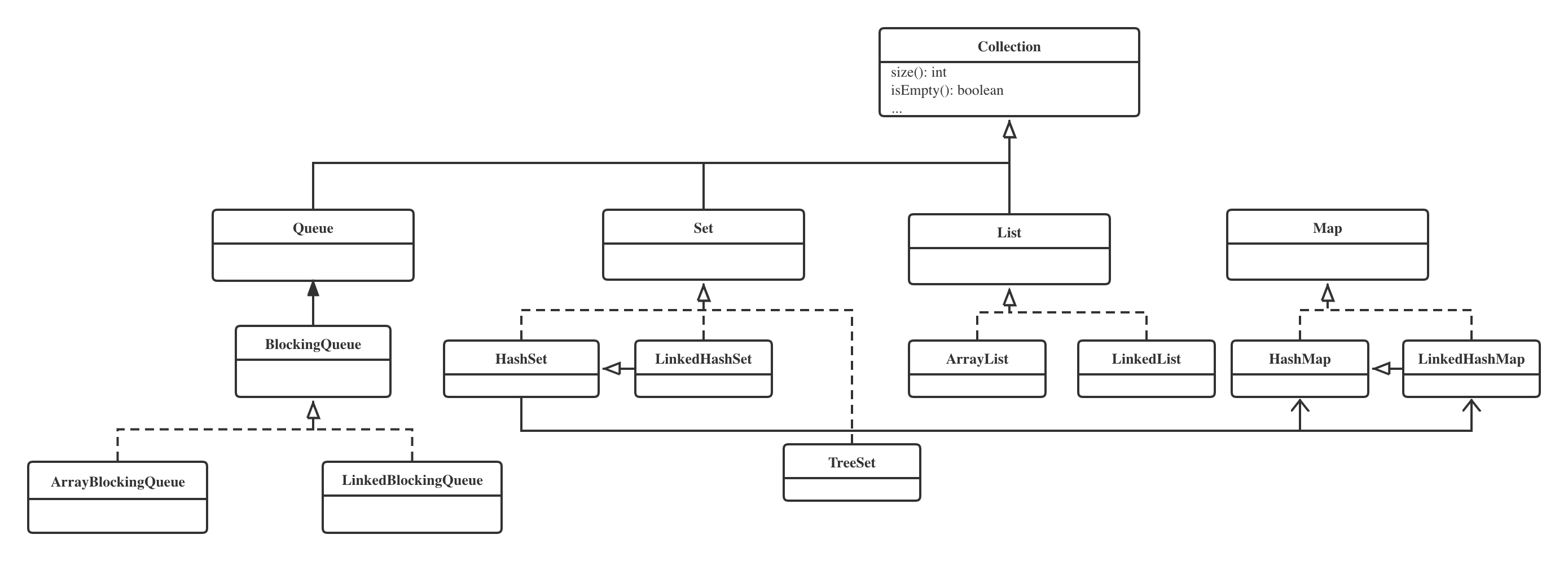
注意这里Map并没有继承Collection的接口
关键点介绍:
- HashSet是依赖于
HashMap实现的,值是固定的 - LinkedHashSet是继承了
HashSet,使用HashSet的构造函数,通过无意义的参数区分,使用的是LinkedHashMap - TreeSet是有序唯一的集合,红黑树结构
- ArrayList内部是Object[]集合
- LinkedList是双向链表
- LinkedHashMap保存了一个双向链表。Linked会保证遍历时候的顺序,不过大多数场景都是没有用的,在某些特殊的场景,比如购物车Map会有一些作用,能够按照顾客添加的顺序进行展示。
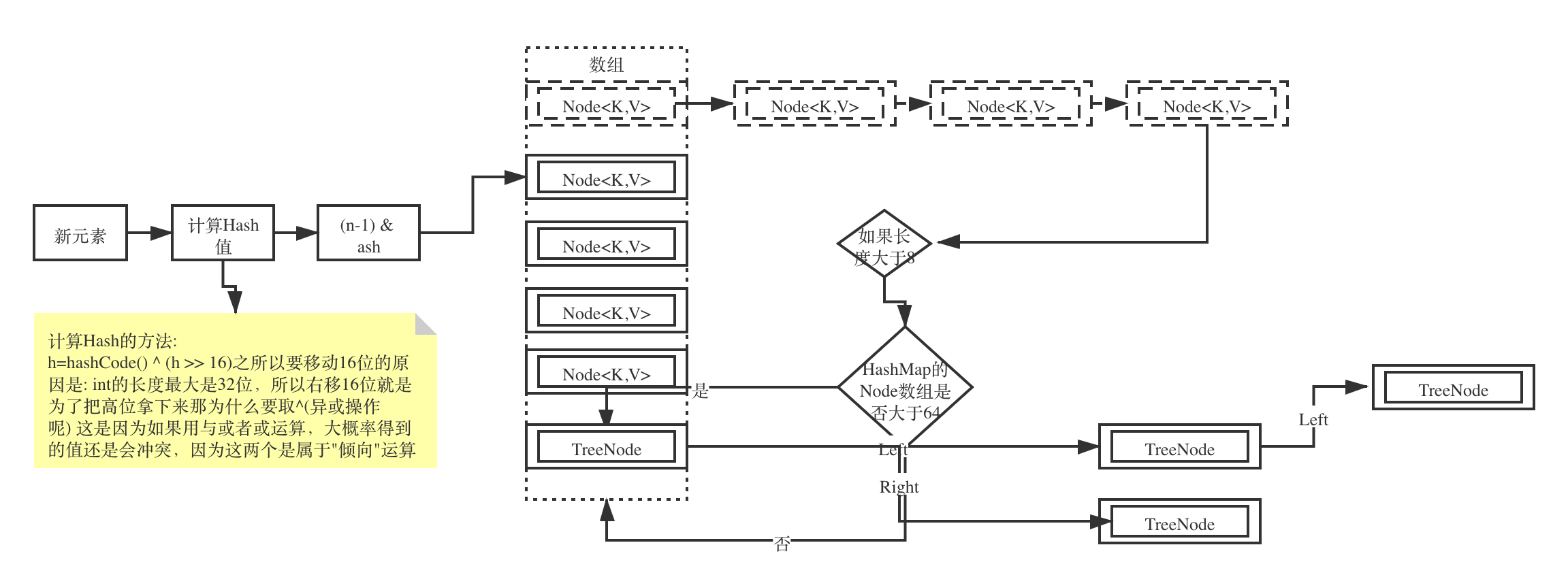
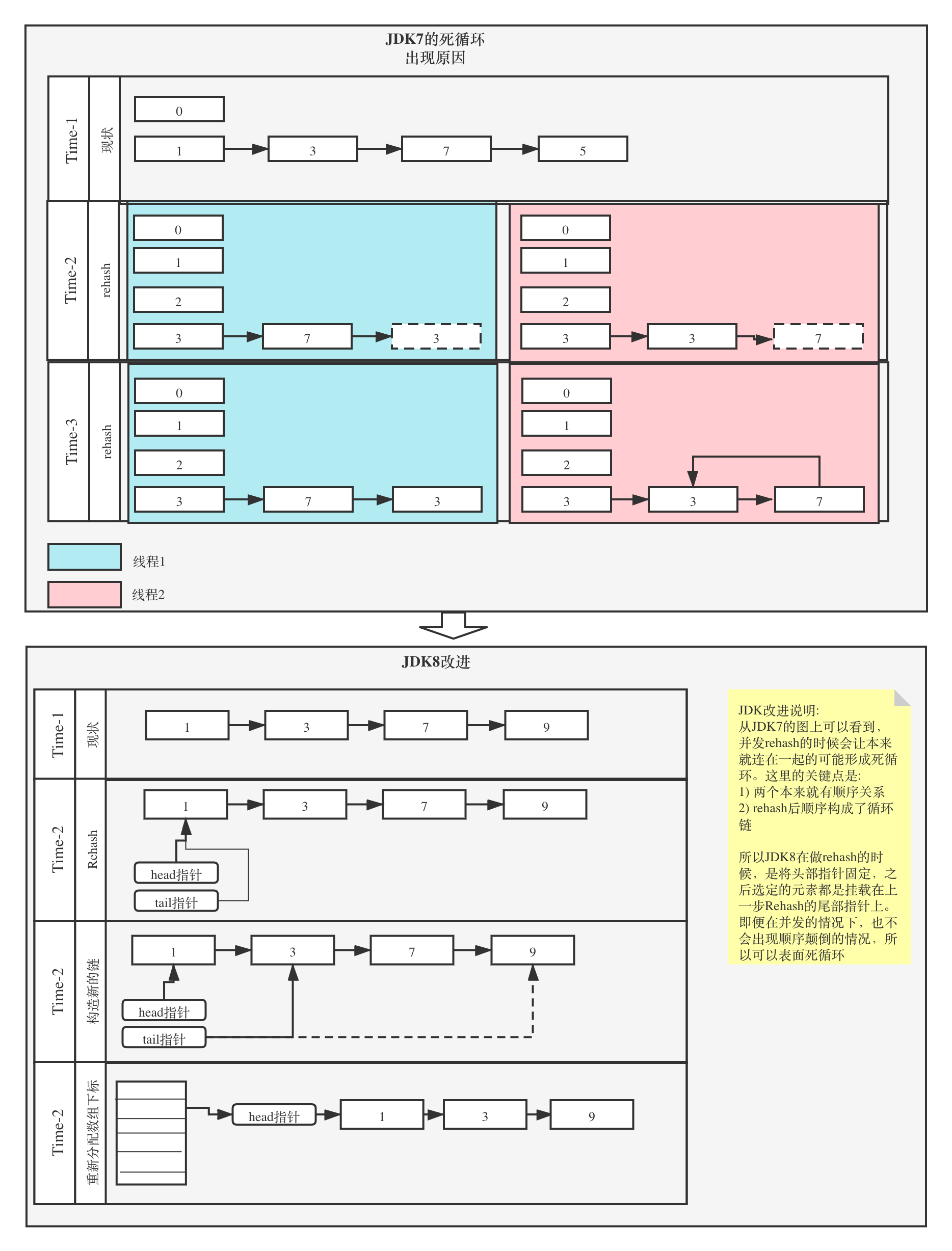
默认初始大小、LoadFactor、扩容倍数
LoadFactor是装载因子,代表HashMap数组的存储使用比例。
| 集合名称 | 默认初始大小 | LoadFactory | 扩容倍数 |
|---|---|---|---|
| HashMap | 16 | 0.75 | 2倍 |
| ArrayList | 10 | - | 1.5倍,如果还不满足就按+1去做 |
作为TW技术咨询师,为多家企业进行架构和 Fintech 创新相关技术咨询,如架构设计、遗留系统上云迁移及规划、各种技术赋能、企业技术相关平台的生态规划及落地建设,创新实验室的技术部分筹建等等。此前,10多年的投行研发经验,包括外汇交易等核心系统,涉猎从架构、开发、Scrum Master、运维等多个角色。个人创业经验经历涉及互联网、金融和教育行业,并在广州多所重点大中院校担任创客导师。

又一年的DDD-China大会,碰上北京的初雪,这次终于没有因为太干燥而病倒了。
今年在大会的互动区给大家准备了一个事件风暴的小体验,参加了的小伙伴说“很爽”,那这里就把这个小案例分享一下,让更多人来一起爽 ^_^
故事背景
场景源于一个打劫案件,当劫匪拿出他的枪,来自未来的超能摄像头发现危险马上自动报警。同时,各位正义英雄暗地里开始出动!
哪知道这班劫匪也不是盖的,某正义英雄(请自动脑补蝙蝠侠)虽然第一个到场,和劫匪激战一轮居然也还没拿下,无奈中只能触发身上的升级预警装置通知总部增援。
总部系统收到通知马上召集了其他英雄线上会议商讨对策,作战计划一出,第二批英雄马上抵达现场,几经周折终于把劫匪抓获。

这里用一个简化版的用户旅程地图描述了这个场景。通常地,类似的用户旅程就正是掀起事件风暴的优秀开端~
现在让我们假设,作为英雄总部,我们计划基于这个场景构建一个自动预警系统,从而让整个预警过程更加智能更加顺畅,那我们IT民工该怎么和总部一起设计这个系统呢?
事件风暴-拉开序幕
当开启事件风暴,第一件事情是必须把自己的视角切换到自动预警系统的设计师这个角色上来,谨记,我们关注的是这个系统在这个场景下应该怎么运作,系统以外的细节我们可以暂且忽略。换而言之,“自动预警”就应该是核心域。
在正统的事件风暴过程中:
- 第一步就是寻找事件并以“XX已YY”(如“订单已提交”)完成时态描述这个事件
- 第二步就是寻找这个事件对应的命令,通常是一个动宾结构(如“提交订单”)
而在这里,对于不太复杂的系统我会倾向与合二为一,同时去列举出“角色/读模型/命令/事件”。这里举一个?说明一下“角色/读模型/命令/事件”分别是什么:
- 角色 简单来说就是主语,可以是人物,可以是类似于定时任务的规则,可以是外部系统
- 读模型 (Optional)角色是基于什么信息做之后的决定的,不一定每步都有
- 决策/命令 原译Command,但叫“业务决策”可能更好理解,反正就是描述做了什么决定
- 事件 描述之前的决定触发了什么事情,或者说决策导致某东西的状态变了为什么。

当然,如果在做的过程中发现这样连起来想不清楚,那就还原基本步,按照原来的事件->命令这样小步走就好了.
Step 1. 命令风暴
下面是我自己设计的命令风暴,结果跟大家在互动区设计的还是差不多的。(我这个贴法跟正宗的有点不一样,主要是为了糊墙的时候省地方)

这个并不是标准答案,而且也并不存在标准答案。因为我们是在设计,一百个人就有一百个哈姆雷特,按团队商量统一一个思路走就可以了。
再列几个在这过程中常见的疑问:
在我的风暴中,会议商量出来的叫“作战计划”,现场童鞋商量出来的是“抓捕计划”,这个就是传说中的统一语言的过程,只要得到一个团队一致认可的名字就可以了。
风暴中,有“预警通知”、“警报”、“升级预警通知”,有童鞋会问是不是可以统一叫“通知”,这个其实也是统一语言和对业务的理解问题,如果觉得三个场景都是发送一样的通知就可以了,那统一叫“预警通知”是个不错的选择,但如果希望每次发送的内容都不一样,那还是得取个不一样的名字方便后续辨认区分。
现场童鞋曾经出现一个场景写到“英雄->登出会议->会议已结束”。这里会考虑登出和结束之间是不是漏了一些步骤,因为按套路走的话应该是“登出会议->会议已登出“,”结束会议->会议已结束“。现在写的决策和事件并不对应,可见应该有遗漏。
过程中,比如开会怎么商量,作战计划怎么执行,这些其实不是这个预警系统关注的事情,所以不需要进一步展开.
Step 2. 识别业务对象
简单来说,就是要找出之前那个”决策/命令“打算要操作什么东西?或者说那个“事件”里面“XX已YY“的XX说的是什么。

如果第一步是严格按照“XX已YY”的写法进行,这里应该难度不是特别大。
当然,如果在第一步里面把一些查询或者打开页面这类的动作也放进命令风暴的话,有可能那些步骤会找不出一个业务对象,或者就成为“XX页面”。这也是为什么通常在命令风暴中不考虑一些查询动作的原因,打开页面的动作并没有实际改变什么东西的状态。
Step3. 分析业务对象生命周期
在通常的事件风暴介绍中,“分析生命周期”经常就是一句话带过,但这里我会建议大家显式地把生命周期画出来,这样对于后续分辨聚合根/实体/值对象会很有帮助。

有一些信息只出现了一次,所以画出来就成了一个点,明显的这些可以先归为值对象,因为他们只是某个值,而没有生命周期,不需要id之类的标识。
另一类是一条线段,可见他们是有生命周期的,期间是带有状态的,这些就是传说中的实体了。
那哪些是聚合根呢?
- 简单来看,就是看这些点和线的归属。比如上图中,“案件记录”的生命周期是最长的,也包含了其他所有的业务对象生命周期,那看起来它就应该是聚合根。
- 再看“警报升级会议”,看起来没有案件就没有它的存在,所以它应该是属于“案件记录”这个聚合根里面的一个实体,但如果我们扩展一下分析的场景,比如假设有另外一个场景是说在平常其实英雄也需要开例会,而且对应的也是一样的创建/登入/登出/结束,我们觉得它们可以统一处理,那这样“会议”就会是另外一个聚合
- 同理,“警报升级通知“等的三个值对象,如果只在案件周期内存在,那他们就是隶属于案件的值对象。但如果我们有其他场景是会比如配置这些通知的不同模版的, 那这些通知就有了自己的生命周期,可能自己会独立成为聚合根
所以,看生命周期还得全面的看,在集合了多个场景之后才会比较准确。当然,里面也会有一些业务常识在,比如“会议”如果一开始我们就选择了Zoom之类的外部系统实现,那很明显它就应该独立出去自己聚合了。
Step4.
这里第四步包括了两部分:聚合细化 & 上下文分析,这两部分其实是相辅相成的,并没有绝对的顺序,有时候还会根据其中一步的分析结果来回调整另一步,所以这里我把它们归到一起。
Step4a. 细化聚合根分析
这里我们先假设,会议有其他场景也用到,所以它属于另一个聚合。
那下面我们就可以把上面的业务对象按照聚合的方式细化分析他们之间的关系了。并可以补充上一些关键的属性

Step4b. 识别上下文和调用关系
同理也可以划分出上下文以及他们之间的调用关系。(这里的U我是指消费者/调用方,而D是生产者/被调用方)

留意,这里说的是上下文,也就是业务边界,它跟服务划分并没有绝对的关系。
要问如果对应到服务划分,其实我们还得多看几个维度综合考虑,比如:
- 组织架构(康威定律)- 比如上面预警系统如果都是一个团队管,那会议和案件不太复杂的时候放在一个服务也不是不可以,但如果分别两个团队管,那还是分开好,免得吵架。
- 业务边界(上下文)
- 变更频率 - 比如营销活动上下文里面有营销活动的规则,活动的元素基本固定,但活动规则经常变,这样我们可以考虑从活动上下文中再分出活动规则
- 高并发、低延时等的非功能性需求 - 比如某些高并发场景需要读写分离,那就会把一个上下文再拆开读和写两部分
- 技术层面需求 - 比如因某些特性需要用不同的语言编写
- 安全等其他层面要求
事件风暴过程全体验-上篇-腾讯云开发者社区-腾讯云 (tencent.com)
推荐 | 事件风暴 (eventstorming.net.cn)
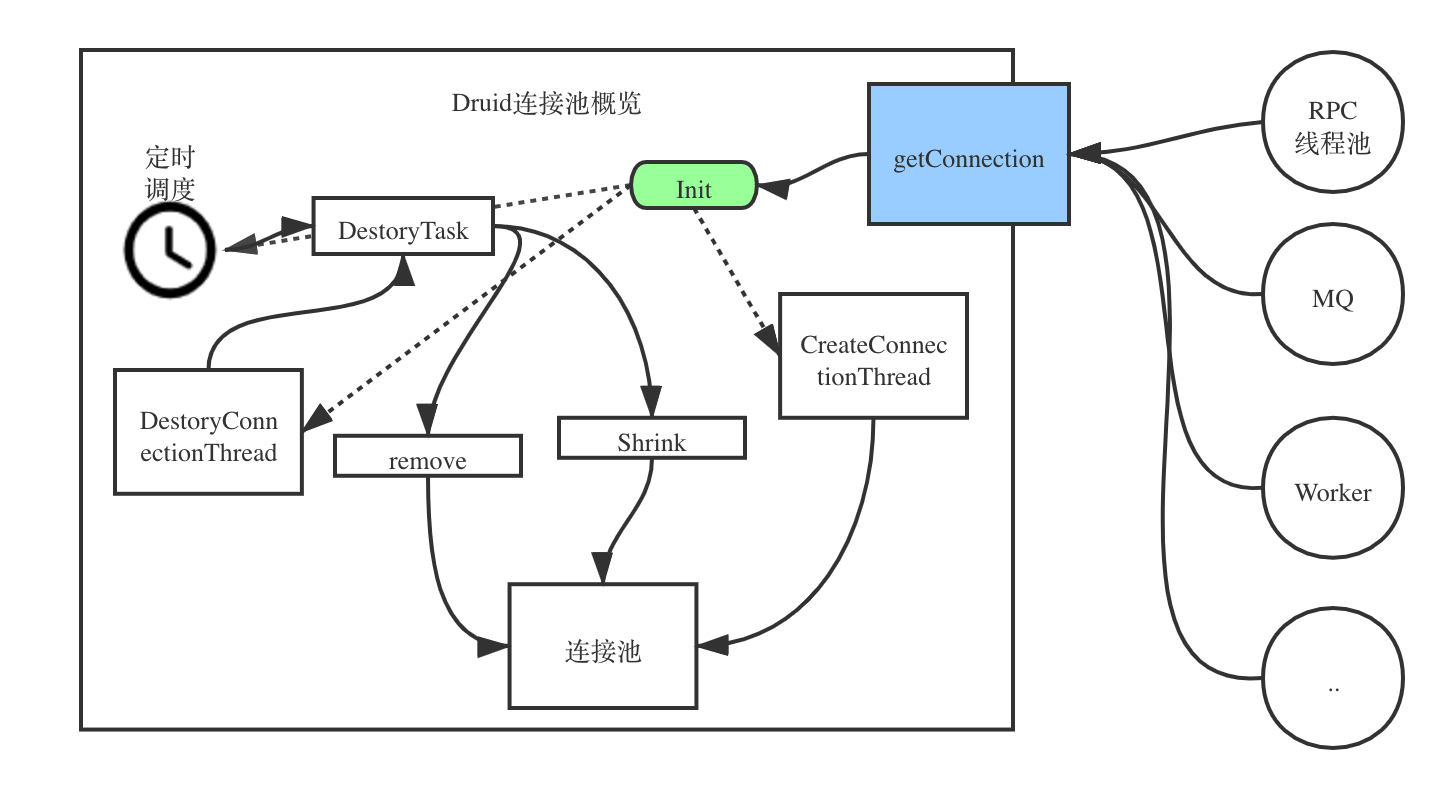
中断原因调查
-
首先是打印druid的日志。
<logger name="druid.sql" additivity="false"> <appender-ref ref="sql_appender"/> </logger> <logger name="com.alibaba.druid.pool" additivity="false"> <appender-ref ref="druid_appender"/> </logger>为什么一个是druid.sql一个是com.alibaba.druid.pool,这是因为LoggerFactory.getLogger给的参数不同。
-
运行一段时间后,终于观察到了罪魁祸首!!!还是挺兴奋的
2021-04-27 19:48:48.323 [ClusterManager] ERROR com.alibaba.druid.pool.DruidDataSource - CreateConnectionThread线程被中断了!!!:thread=ClusterManager, trace=[{"className":"java.lang.Thread","fileName":"Thread.java","lineNumber":1552,"methodName":"getStackTrace","nativeMethod":false},{"className":"com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread","fileName":"DruidDataSource.java","lineNumber":2720,"methodName":"interrupt","nativeMethod":false},{"className":"java.lang.ThreadGroup","fileName":"ThreadGroup.java","lineNumber":639,"methodName":"interrupt","nativeMethod":false},{"className":"com.xx.mq.client.consumer.GroupConsumer","fileName":"GroupConsumer.java","lineNumber":177,"methodName":"doStop","nativeMethod":false},{"className":"com.xx.registry.util.Service","fileName":"Service.java","lineNumber":122,"methodName":"stop","nativeMethod":false},{"className":"com.xx.registry.util.Closeables","fileName":"Closeables.java","lineNumber":118,"methodName":"close","nativeMethod":false},{"className":"com.xx.mq.client.consumer.TopicConsumer","fileName":"TopicConsumer.java","lineNumber":704,"methodName":"removeGroupConsumer","nativeMethod":false},{"className":"com.xx.mq.client.consumer.TopicConsumer$TopicClusterListener","fileName":"TopicConsumer.java","lineNumber":915,"methodName":"onEvent","nativeMethod":false},{"className":"com.xx.mq.client.consumer.TopicConsumer$TopicClusterListener","fileName":"TopicConsumer.java","lineNumber":898,"methodName":"onEvent","nativeMethod":false},{"className":"com.xx.registry.util.EventManager","fileName":"EventManager.java","lineNumber":309,"methodName":"publish","nativeMethod":false},{"className":"com.xx.registry.util.EventManager$EventDispatcher","fileName":"EventManager.java","lineNumber":433,"methodName":"run","nativeMethod":false},{"className":"java.lang.Thread","fileName":"Thread.java","lineNumber":745,"methodName":"run","nativeMethod":false}]从堆栈里去看到是因为
com.xx.mq.client.consumer.GroupConsumer.doStop方法引起的,代码如下:@Override protected void doStop() { super.doStop(); threadGroup.interrupt();我们可以看到它退出的时候,会使用threadGroup的方式进行退出。会把Group里所有的线程给退出。而Druid的初始化又是根据谁来获取Connection来定义的group,所以就会联动退出。
如何解决
解决的方式采取的是在初始化DruidDataSource后获取一下Connection,这样就不会受到mq线程的影响。
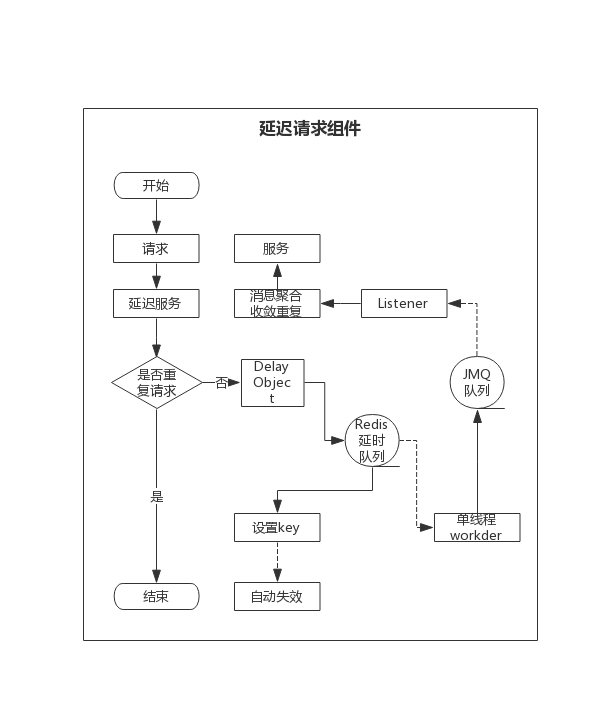
idea如何排除自动引入哪些包
背景
在使用idea作为IDE时,我们定义了一个SystemException,然后引入的时候经常会自动引入为org.omg.CORBA.SystemException。需要手动更换。
解决办法
在Editor > General > Auot Import中Exclude from import and completion中增加特定的package或者包。
官方说明: Auto import

结论
- 使用配置的方式进行exclude
- 推动包含
@EnableAutoConfiguration的去掉,因为jar包内不应该有。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号