


ElasticSearch
一、ElasticSearch是什么?
ElasticSearch(简称 ES) 是用 JAVA 开发的当前最流行的开源的企业级搜索引擎。
具有如下特点:实施搜索、快速、稳定、可靠,安装使用方便。
客户端支持:Java, .Net, PHP, Python, Ruby等多种语言。
1.1 ElasticSearch 与 Lucene 的关系
Lucene 是迄今为止性能较好、功能全面的搜索引擎库框架 (库),但是,如果在项目中想直接用 Lucene 框架,则必须用 Java 作为开发语言将 Lucene 集成到应用中,所以,Lucene 具有以下缺点:
- 只能在 Java 中使用,以 jar 包的方式集成到项目中。
- 创建索引 和 索引搜索的代码复杂,而且随着不同版本变化,代码有差异。
- 不支持集群,不能很好的支持大型项目。
- 索引数据在同一服务器,占用服务器硬盘,公用空间少。
1.2 ES 解决Lucene使用缺点的最好方案(对比 solr)
虽然 Solr 也是一个全文检索应用,但和 ES 还是有不同的地方。
总结如下:
- 当单纯的对已有数据进行搜索时,Solr 更快。
- 当实施建立索引时,Solr 会产生 io 阻塞,查询性能就会瞬间变差;ES 是准实时的,有明显的优势。
- Solr 利用 ZK 进行分布式管理,而 ES 自身带有分布式协调管理器。
- Solr 支持更多的数据格式, JSON, XML, CSV,而 ES 仅支持 JSON。
请看下面两张图,对已有的静态数据检索是,Solr 要更快(第一张图),但实时建立索引是,Solr 会产生 io 阻塞,查询性能瞬间跌到低谷;而 ES 则是准实时更新索引的,及时在更新数据是也可以提供很快的检索服务(第二张图)。


二、ES 与 关系型数据库对比理解
| 关系型数据库 | ES |
| Database(数据库) | Index(索引库) |
| Table(表) | Type(类型) |
| Row(行) | Document(文档) |
| Column(列) | Field(字段) |
三、ES 中的核心概念
3.1 索引 index
索引就是有相似特征的文档的集合, 比如:客户数据,产品数据 索引等。
一个索引由一个名字来标识(必须全部小写字母),相当于关系数据库的库名。
增删改查都要用到索引名称。
3.2 映射 mapping
mapping是处理数据的方式和规则方面做一下限制,确定 Document 里面字段的 数据类型、默认值、分词器、是否被索引、是否存储 等等。
3.3 字段 field
相当于关系型数据库的 字段(列)。
3.4 字段类型 type
每一个字段都要对应一个类型,这里是一些基本的数据类型:Text、keyword、byte、string、int、boolean 等。
还有复杂的数据类型:数组、JSON对象嵌套。
ES 还支持地理位置搜索。
3.5 文档 document
文档是可被索引的基础单元,类似 MySQL的一条记录,用 JSON 来表示。
3.6 集群 cluster
集群是由多个节点组织在一起,共同持有整个数据,并一起提供索引和搜索功能。
3.7 节点 node
一个节点就是集群里面的已一台服务器。
3.8 分片和副本 shards & replicas
3.8.1 分片
一个索引可以存储超出单个节点的大量数据,但是没有节点是有足够的磁盘空间的,即便有,单个节点处理搜索请求也太慢,为了解决这些问题,ES 提供了将索引划分成多份,这些份就是 分片。
3.8.2 副本
在网络环、云 里面,节点故障是避免不了的,在某个分片或者节点离线的情况下,有个故障转移机制是非常有用并且强烈推荐的。为此,ES 允许把创建分片拷贝成多份,有备无患,这些拷贝出来的就是 副本。
好的,ES 基础就介绍到这里吧~~~
总结
例如:ES 作为目前企业级搜索的最佳解决方案,了解完基本内容,马上上手使用起来。
一、分词器测试
在安装完 ES 之后,新建 索引 的时候,可以指定 分词器,首先对分词器进行一个测试。
POST /_analyze
{
"analyzer": "standard",
"text":"最好的时代,最坏的时代"
}二、索引的增删改
2.1 新建索引
2.1.1 新建最简单的 index
如果不指定 mapping, ES 会自动添加上 mapping。
PUT /<索引名称>2.1.2 新建带 mapping 的 index
PUT /<index name>
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"data": {
"properties": {
"product_name": {
"type": "text",
"index": true,
"store": true,
"analyzer": "standard"
},
"product_agency": {
"type": "keyword",
"index": true,
"store": true
},
"notice_type": {
"type": "keyword",
"index": true,
"store": true
},
"notice_type_id": {
"type": "integer",
"index": true,
"store": true
}
}
}
}
}type:字段类型 ,index:是否建立索引,store:是否存储
特别说明:在 7.x 版本后,在 mapping 中不用指定数据类型 data 。
2.2 删除索引
DELETE <索引名称>2.3 给 index 起别名
PUT /<索引名称>/_alias/<别名>2.4 拷贝索引
POST _reindex
{
"source": {
"index": "learn_test"
},
"dest": {
"index": "learn_test2"
}
}三 索引内容的增删改查
3.1 bulk 批量添加数据
POST /tender_test/_bulk
{"index":{"_index":"tender_test","_type":"data"}}
{"product_agency":"山东方中工程管理有限公司","notice_type_id":"23","product_name":"血培养仪","notice_type":"招标公告"}
{"index":{"_index":"tender_test","_type":"data"}}
{"product_agency":"","notice_type_id":"3","product_name":"全自动微生物鉴定药敏分析仪","notice_type":"招标公告"}3.2 bulk 批量修改数据
使用 _bulk 来修改数据时,注意,它是整体覆盖的,每次修改需要把全部的字段都包含了,要不就丢数据了。
POST /<索引名称>/_bulk
{"index":{"_index":"tender_test","_type":"data","_id":"bj5pNYABu8HGt75FTQyX"}}
{"product_agency":"山东方中工程管理有限公司","notice_type_id":"230","product_name":"血培养仪","notice_type":"招标公告"}
{"index":{"_index":"tender_test","_type":"data","_id":"bz5pNYABu8HGt75FTQyX"}}
{"product_agency":"","notice_type_id":"31","product_name":"全自动微生物鉴定药敏分析仪","notice_type":"招标公告"}3.2(补) _update_by_query 按条件修改数据
前段时间在支持运营部分修改数据时,发现需要修改部分数据,而且按照特定的条件,不能用 bulk,那就是能用 _update_by_search 来搞定了,query 是需要修改数据的条件,script 里面则是具体修改的内容,是用脚本的方式来实现的,紧急情况下还是蛮不错的,要不就的推数据了,很慢。
POST /<索引名称>/data/_update_by_query
{
"query": {
"bool": {
"must": [
{
"match": {
"notice_type_id": "3"
}
}
]
}
},
"script":{
"source":"[ctx._source['product_agency']=\"1\",ctx._source['notice_type']=\"招标公告2\",ctx._source['redmine']=\"是\"]"
}
}单个值修改(ES 7.x 版本操作)
POST electronics/_update_by_query
{
"query": {
"term": {
"_id": {
"value": "6"
}
}
},
"script":{
"source":"ctx._source['product_count']=3"
}
}3.3 按照id获取数据
这里的 data 是文档类型,ES7 之前,文档类型是自己定义的,但是到了 ES7.x 之后,改为了 _doc 了,默认可以不写。
GET <索引名称>/data/bj5pNYABu8HGt75FTQyX3.4 match_all 匹配所有数据
POST /tender_test/_search
{
"query": {
"match_all": {}
}
}3.5 term 精准搜索
POST /<索引名称>/_search
{
"query":{
"term":{
"notice_type": "招标公告"
}
}
}3.6 match 匹配搜索
POST tender_test/_search
{
"from": 0,
"size": 20,
"query": {
"match": {
"product_name": "鉴定"
}
}
}3.7 multi_match 多字段匹配
POST <索引名称>/_search
{
"query": {
"multi_match": {
"query": "微生物",
"fields": ["product_name","product_agency"]
}
}
}3.8 query_string 多值匹配
POST tender_test/data/_search
{
"query": {
"query_string": {
"query": "国际 OR 过敏"
}
}
}当然 and 就是: “query”: “国际 AND 过敏”。
3.9 range 范围匹配
POST <索引名称>/_search
{
"query": {
"range": {
"notice_type_id": {
"gte": 5,
"lte": 9
}
}
}
}3.10 match_phrase 短语匹配
POST tender_test/data/_search
{
"query": {
"match_phrase": {
"product_agency": "四川省工程项目管理咨询有限公司"
}
}
}3.11 prefix 前缀匹配
POST tender_test/_search
{
"query": {
"prefix": {
"notice_type": "招标"
}
}
}3.12 filter 过滤
POST <索引名称>/_search
{
"query": {
"bool": {
"filter": {
"term": {
"notice_type_id": "5"
}
}
}
}
}注:
此处有个面试题,filter 过滤 和 query 匹配区别是什么?
后文补充
四 高级搜索
4.1 highlight 高亮匹配
POST <索引名称>/data/_search
{
"query": {
"match": {
"product_name": "分析仪"
}
},
"highlight": {
"fields": {
"product_name": { },
"product_agency": {}
}
}
}4.2 组合高亮匹配
POST <索引名称>/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"product_name": "分析仪"
}
},
{
"match": {
"product_agency": "分析仪"
}
}
]
}
},
"highlight": {
"fields": {
"product_name": {},
"product_agency": {}
}
}
}4.3 聚合统计
POST <索引名称>/_search
{
"query": {
"match": {
"notice_type_id": "20"
}
},
"aggs": {
"groyp_by_notice_type": {
"terms": {
"field": "notice_type",
"order": {
"_count": "desc"
}
},
"aggs": {
"groyp_by_notice_type_id": {
"terms": {
"field": "notice_type_id",
"order": {
"_count": "desc"
}
}
}
}
}
},
"size": 0
}4.4 scroll 游标查询
POST <索引名称>/data/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "国际",
"fields": ["product_name","product_agency"]
}
},
"size": 2
}首先在查询的时候,可以带上 scroll=1m 参数,在url 中,查询结果中可以拿到 _scroll_id 的值,就是一个长字符串,再用这个字符串直接查询就可以了,如下:
GET _search/scroll?scroll=1m
{
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoBgAAAAAAAkF1Flh1eDNRcmpvUkVXVHJXSDMxV3BSdGcAAAAAAAJBeBZYdXgzUXJqb1JFV1RyV0gzMVdwUnRnAAAAAAACQXQWWHV4M1Fyam9SRVdUcldIMzFXcFJ0ZwAAAAAAAkF3Flh1eDNRcmpvUkVXVHJXSDMxV3BSdGcAAAAAAAJBdhZYdXgzUXJqb1JFV1RyV0gzMVdwUnRnAAAAAAACQXkWWHV4M1Fyam9SRVdUcldIMzFXcFJ0Zw=="
}多用于翻页查询中。
4.5 模板查询
POST <索引名称>/_search/template
{
"source": {
"query": {
"range": {
"notice_type_id": {
"gte": "{{start}}",
"lte": "{{end}}"
}
}
}
},
"params": {
"start": 10,
"end": 20
}
}4.6 模板重复使用
首先报错查询模板到 ES 中
POST _scripts/test
{
"script":{
"lang": "mustache",
"source":{
"query":{
"match":{
"product_name":"{{pn}}|"
}
}
}
}
}然后再通过模板传参查询
GET tender_data/_search/template
{
"id":"test",
"params": {
"pn":"分析仪"
}
}五 关联查询
5.1 新建index, mapping创建
PUT fashion_bolog
{
"mappings": {
"data": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"title": {
"type": "keyword"
},
"content": {
"type": "text"
}
}
}
}
}新添加的 index 名是 fashion_bolog,在 mapping 中添加了 blog 和 comment 的关系,在后面的插入数据的时候,首先插入 blog 数据,然后为没调 blog 数据插入它的子数据,并且添加上依赖关系,blog 被称为是 主表,comment 就是子表。
5.2 插入数据
下面插入了两条主表 blog 的数据。(两条博客)
PUT fashion_bolog/data/001
{
"title":"Nice day",
"content":"Today is a nice day, play game and eat fish",
"blog_comments_relation":{
"name":"blog"
}
}
PUT fashion_bolog/data/002
{
"title":"今天学习了啥",
"content":"今天学习了怎么用全文搜索技术Elasticsearch",
"blog_comments_relation":{
"name":"blog"
}
}下面为 id 是 001 的博客添加了几条评论,comment_x 是评论的 id, routing 指定关联的主表的数据的 id。
PUT fashion_bolog/data/comment_2?routing=001
{
"comment":"I m glad to hear that, good luck",
"username":"stephen",
"blog_comments_relation":{
"name":"comment",
"parent":"001"
}
}
PUT fashion_bolog/data/comment_3?routing=001
{
"comment":"Really, that good",
"username":"anji",
"blog_comments_relation":{
"name":"comment",
"parent":"001"
}
}
PUT fashion_bolog/data/comment_4?routing=001
{
"comment":"phen have a nice life",
"username":"zhenglei",
"blog_comments_relation":{
"name":"comment",
"parent":"001"
}
}5.3 查找 001 博客(按照主表查询)
下面查找 id 是 001 的博客的评论,使用 parent_id 查询主表。
POST fashion_bolog/_search
{
"query": {
"parent_id":{
"type":"comment",
"id":"001"
}
}
}5.4 按照博客主题查询 (按照主表查询)
下面查询了博客名称为 “Nice day” 的博客的评论。
POST fashion_bolog/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"match": {
"title": "Nice day"
}
}
}
}
}5.4 按照评论者用户名查询 (按照从表查询)
下面查询了评论的用户名是 “zhenglei” 的博客。
POST fashion_bolog/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match":{
"username":"zhenglei"
}
}
}
}
}总结
例如:以上就是在 kibana 中操作 index 的常规操作,工作中基本可以满足,语法记录在此,方便copy 出来在工作里面用,比较这语法还是写起来很费时的,这不耽误加班吗。
一、引入ES Client jar包
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.7.2</version>
</dependency>二、操作案例
2.0 实例化 ES Client 客户端
private static final String HOSTNAME = "192.168.*.*";
private static final int PORT = 9200;
private static final RestHighLevelClient client = getClient();
public static RestHighLevelClient getClient(){
RestClientBuilder builder = RestClient.builder(
new HttpHost(HOSTNAME, PORT, "http")
);
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}2.1 增
public static void addIndex(RestHighLevelClient client) throws IOException {
/*初始化 查询请求操作,指定操作 index 名称*/
IndexRequest indexRequest = new IndexRequest(INDEX_NAME);
/*实例化数据*/
Tender tender = new Tender("鉴定药敏分析仪"
,"四川国际招标有限责任公司"
,"招标结果"
,"5");
String json = JSONObject.toJSONString(tender);
/*设置 类型,7.x 不用设置,默认是 _doc*/
indexRequest.type("data");
/*数据转换成 json 添加进去*/
indexRequest.source(json, XContentType.JSON);
/*添加索引 */
client.index(indexRequest, RequestOptions.DEFAULT);
client.close();
}2.2 删
public static void deleteById(String id) throws IOException {
/*初始化 get 请求*/
GetRequest request = new GetRequest(INDEX_NAME, TYPE, id);
/*判断是否存在数据,用 id 查询*/
boolean exists = client.exists(request, RequestOptions.DEFAULT);
if(exists){
/*初始化 Delete 请求*/
DeleteRequest deleteRequest = new DeleteRequest(INDEX_NAME, TYPE, id);
/*执行 delete 操作*/
client.delete(deleteRequest, RequestOptions.DEFAULT);
}
client.close();
}2.3 改
2.3.1 Update by ID
按照 ID 进行简单的操作,此更新操作是更新整个文档。
public static void updateById(String id) throws IOException {
/*初始化 get 请求*/
GetRequest request = new GetRequest(INDEX_NAME, TYPE, id);
/*判断是否存在*/
boolean exists = client.exists(request, RequestOptions.DEFAULT);
if(exists){
/*初始化 Update 请求,按照 id更新*/
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, TYPE, id);
/*组装 数据*/
Tender tender = new Tender("鉴定药敏分析仪"
,"四川国际招标有限责任公司"
,"招标结果"
,"100");
updateRequest.doc(JSONObject.toJSONString(tender), XContentType.JSON);
/*执行更新操作*/
client.update(updateRequest, RequestOptions.DEFAULT);
}
client.close();
}2.3.2 Update by query(补)
Update by query操作和 kibana 中的 _update_by_query 操作一样,所以需要设施 script 参数,ES 不像关系型数据库表,可以更新单个字段,ES是以文档的方式存储的,所以如果要更新其中的一个字段,则需要用 script 脚本。
public static void updateByQuery(String typeId) throws IOException {
/*构建根据查询条件更新内容操作*/
UpdateByQueryRequest updateByQuery = new UpdateByQueryRequest();
/*设置更新条件*/
updateByQuery.setQuery(QueryBuilders.matchQuery("notice_type_id", typeId));
/*设置更新 INDEX*/
updateByQuery.indices(INDEX);
/*文档类型,ES8 默认为 doc,不用设置*/
updateByQuery.setDocTypes("data");
/*设置更新脚本,下面表示更新文档中的 product_agency,和 product_name 字段,如果是多个字段,也可以更新多个字段*/
updateByQuery.setScript(new Script("ctx._source['product_agency']='一二三集团';ctx._source['product_name']='抗敏药物'"));
long updated = client.updateByQuery(updateByQuery, RequestOptions.DEFAULT).getUpdated();
/*更新条数*/
System.out.println("修改成功:" + updated);
client.close();
}第二种写法(ES 7 之前版本):
注意:下面的这种写法是用 TransportClient 来操作的,如果ES是 7 之前的版本则可以用这个客户端操作,7 版本之后 TransportClient 弃用了,所以如果 ES 是 7.x 以后的版本,则用 RestHighLevelClient 客户端。
public static void updateByQueryAction(String typeId){
/*利用 UpdateByQueryAction 来构建一个 UpdateByQueryRequestBuilder*/
UpdateByQueryRequestBuilder builder = UpdateByQueryAction.INSTANCE.newRequestBuilder(transportClient);
/*设置更新脚本*/
Script script = new Script("ctx._source['product_agency']='三一集团';ctx._source['product_name']='抗老药物'");
BulkByScrollResponse response = builder.source(INDEX)
.script(script)
.filter(QueryBuilders.matchQuery("notice_type_id", typeId))
.abortOnVersionConflict(false).get();
long updated = response.getUpdated();
/*更新条数*/
System.out.println("修改成功:" + updated);
transportClient.close();
}TransportClient 客户端实例化如下(拷贝即可用),需要引入依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.7.2</version>
</dependency> public static TransportClient getTransportClient(){
try{
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName(HOSTNAME),9300));
return client;
}catch (UnknownHostException e){
e.printStackTrace();
}
return null;
}2.4 查
2.4.1 按照 ID 获取
public static Tender searchById(String id) throws IOException {
/*初始化 get 请求*/
GetRequest request = new GetRequest(INDEX_NAME, TYPE, id);
/*按照 ID 获取数据*/
GetResponse response = client.get(request, RequestOptions.DEFAULT);
Tender tender = JSONObject.parseObject(response.getSourceAsString(), Tender.class);
client.close();
return tender;
}2.4.2 多字段查询
public static List<Tender> searchList(String keyword) throws IOException {
/*初始化查询请求*/
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
/*初始化 构建 查询 builder*/
SearchSourceBuilder builder = new SearchSourceBuilder();
/*初始化 多字段 查询 builder*/
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keyword, "product_agency");
/*设置 查询 多字段查询*/
builder.query(multiMatchQueryBuilder);
/*把 构建好的 查询 封装到 查询请求中*/
searchRequest.source(builder);
/*执行查询*/
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
List<Tender> collect = Arrays.stream(hits).map(hit -> JSONObject.parseObject(hit.getSourceAsString(), Tender.class)).collect(Collectors.toList());
client.close();
return collect;
}2.4.3 分页查询
public static List<Tender> searchListByPages(String keyword, int pageNo, int pageSize) throws IOException {
/*构建查询请求*/
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
/*构建查询条件 builder*/
SearchSourceBuilder builder = new SearchSourceBuilder();
/*构建 多字段 查询*/
builder.query(QueryBuilders.multiMatchQuery(keyword, "product_name","product_agency"));
/*设置分页 每页大小*/
builder.size(pageSize);
/*设置 分页 page no*/
builder.from(pageNo > 1 ?(pageNo - 1) * pageSize : 0);
/*把组装好的 查询builder 设置到 查询请求中*/
searchRequest.source(builder);
/*执行查询*/
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
List<Tender> collect = Arrays.stream(hits).map(hit -> JSONObject.parseObject(hit.getSourceAsString(), Tender.class)).collect(Collectors.toList());
System.out.println(response.getHits().getTotalHits());
client.close();
return collect;
}2.4.4 按照游标(scroll)查询
public static List<Tender> searchListByScrollPages(String keyword, String scrollId, int pageSize) throws IOException {
SearchResponse response = null;
if(Objects.nonNull(scrollId)){
/*如果游标 id 不为空的话,直接按照 游标 获取数据*/
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
/*设置游标id, 有效时间 5 分钟*/
searchScrollRequest.scroll(TimeValue.timeValueMinutes(5));
response = client.scroll(searchScrollRequest, RequestOptions.DEFAULT);
}else{
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.multiMatchQuery(keyword, "product_name","product_agency"));
builder.size(pageSize);
searchRequest.source(builder);
searchRequest.scroll(TimeValue.timeValueMinutes(5));
response = client.search(searchRequest, RequestOptions.DEFAULT);
}
SearchHit[] hits = response.getHits().getHits();
System.out.println(response.getHits().getTotalHits());
System.out.println(response.getScrollId());
List<Tender> collect = Arrays.stream(hits).map(hit -> JSONObject.parseObject(hit.getSourceAsString(), Tender.class)).collect(Collectors.toList());
client.close();
return collect;
}2.4.5 分页、游标、高亮查询
public static List<Tender> searchListByScrollPageWithHighLight(String keyword, String scrollId, int pageSize) throws IOException {
SearchResponse response = null;
if(Objects.nonNull(scrollId)){
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(TimeValue.timeValueMinutes(5));
response = client.scroll(searchScrollRequest, RequestOptions.DEFAULT);
}else{
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.multiMatchQuery(keyword, "product_name","product_agency"));
//设置高亮查询 初始化 高亮 builder
HighlightBuilder highlightBuilder = new HighlightBuilder();
/*设置高亮的 字段*/
highlightBuilder.field("product_name");
/*设置高亮标签字段*/
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
/*把高亮builder 设置到 查询 builder 里面*/
builder.highlighter(highlightBuilder);
builder.size(pageSize);
searchRequest.source(builder);
searchRequest.scroll(TimeValue.timeValueMinutes(5));
response = client.search(searchRequest, RequestOptions.DEFAULT);
}
SearchHit[] hits = response.getHits().getHits();
System.out.println(response.getHits().getTotalHits());
System.out.println(response.getScrollId());
List<Tender> collect = Arrays.stream(hits).map(hit -> JSONObject.parseObject(hit.getSourceAsString(), Tender.class)).collect(Collectors.toList());
for (SearchHit hit : hits) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField productName = highlightFields.get("product_name");
if(Objects.nonNull(productName)){
System.out.println(productName);
}
}
client.close();
return collect;
}总结
以上是 java api 对 ES 的增删改查的简单案例,方便公司里面临时有需要对ES操作大量数据是,可以直接copy 执行。
不过 ES 随着版本的升级,客户端也随着升级,操作ES的 API 也会发生变化,不过 Spring 当然会对 ES 客户端进行整合,项目中可方便使用,请看
SpringBoot整合ES篇
一、加入Springboot Starter依赖
话不多说,直接copy,后面要用 Junit Test 测试,加入测试包
<!--整合 ES-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>二、application.yml 配置 & 创建单元测试类
2.1 application.yml 配置
server:
port: 8001
spring:
application:
name: xxxx-server #随便写个名字
elasticsearch: #以下配置 主要用于 ElasticsearchRepository (两种操作方式,方式一配置)
rest:
uris: http://localhost:9200 #连接地址
data: #以下配置主要用于 ElasticsearchRestTemplate (两种操作方式,方式二配置)
elasticsearch:
repositories:
enabled: true
client:
reactive:
endpoints: localhost:92002.2 单元测试类
package com.wesh.es;
import com.wesh.home.HomeApplication;
import com.wesh.home.dao.es.TenderTestRepository;
import com.wesh.home.model.Tender;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.Query;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
}三、单元测试前奏
3.1 创建一个实体Bean(Tender.java)
package com.wesh.home.model;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "tender_test3")
public class Tender {
@Id
private String id;
@Field(name = "product_agency", type = FieldType.Keyword)
private String productAgency;
@Field(name = "notice_type_id", type = FieldType.Keyword)
private String noticeTypeId;
@Field(name = "product_name", type = FieldType.Keyword)
private String productName;
@Field(name = "notice_type", type = FieldType.Keyword)
private String noticeType;
/*get set 方法省略*/3.2 添加xxxxRepository 查询接口
我们只需要定义接口即可进行相关的 ES 简单操作,不过要集成 Spring Data 提供的接口 ElasticsearchRepository。
Spring Data 提供的 接口中,按照 我们定义的方法名称 进行 ES 查询操作。具体规则可查阅 Spring官网总结方法命名规则
package com.wesh.home.dao.es;
import com.wesh.home.model.Tender;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface TenderTestRepository extends ElasticsearchRepository<Tender, String> {
/**
* 根据 productName 查询,根据 方法 名称查询
* @param productName
* @param pageRequest
* @return
*/
Page<Tender> findByProductName(String productName, PageRequest pageRequest);
}为什么我们集成了ES提供的 repositoty 接口就可以操作es, 因为 spirng 定义了CRUD 接口。

四 单元测试方法
4.1 新增
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
@Resource
private TenderTestRepository tenderTestRepository;
@Test
public void save(){
Tender tender = new Tender();
tender.setNoticeType("招标广告");
tender.setNoticeTypeId("12");
tender.setProductName("血培养仪");
tender.setProductAgency("山东方中工程管理有限公司");
tenderTestRepository.save(tender);
}
}4.2 id获取
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
@Resource
private TenderTestRepository tenderTestRepository;
@Test
public void get(){
Tender tender = tenderTestRepository.findById("kmfaxoABYWTnJb2BeotB").get();
System.out.println(tender);
}
}4.3 产品名称搜索
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
@Resource
private TenderTestRepository tenderTestRepository;
/**
* 这里调用的就是 根据 productName 字段查询,spring data 提供的接口会根据名称组装查询
*/
@Test
public void findByProductName(){
Page<Tender> tenders = tenderTestRepository.findByProductName("血培养仪", PageRequest.of(0,10));
tenders.forEach(tender -> System.out.println(tender));
}
}4.4 修改
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
@Resource
private TenderTestRepository tenderTestRepository;
@Test
public void update(){
Tender tender = tenderTestRepository.findById("kmfaxoABYWTnJb2BeotB").get();
tender.setProductAgency("微生物鉴定药敏鉴定器");
tender.setProductName("鉴定药敏鉴定器");
tenderTestRepository.save(tender);
}
}4.5 删除
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
@Resource
private TenderTestRepository tenderTestRepository;
@Test
public void delete(){
Tender tender = tenderTestRepository.findById("kmfaxoABYWTnJb2BeotB").get();
tenderTestRepository.delete(tender);
}
}4.6 ElasticsearchRestTemplate 查询
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HomeApplication.class)
public class ESTest {
@Autowired
private ElasticsearchRestTemplate esRestTemplate;
/**
* 用 restTemplate操作
*/
@Test
public void findByQuery(){
QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("山东方中工程管理有限公司", "product_agency");
Query query = new NativeSearchQueryBuilder().withQuery(queryBuilder).build();
SearchHits<Tender> tenderSearchHits = esRestTemplate.search(query, Tender.class, IndexCoordinates.of("tender_test3"));
tenderSearchHits.get().forEach(tenderSearchHit -> {
Tender content = tenderSearchHit.getContent();
System.out.println(content);
});
}
}总结
以上是Spring Data 提供的接口对 ES 的增删改查的简单案例,方便公司里面临时有需要对ES操作大量数据是,可以直接copy 执行。
后期有时间持续更新。
前言
今天工作中遇到嵌套类型的数据,查询总是查询不到,一开始感到疑惑,为啥 match_all 的时候有,但是精确操作就查不到,查了半天才发现,嵌套操作有点区别。
本文主要对ElasticSearch嵌套(Nested) 操作,以便上手 用 ElasticSearch。
一、嵌套数据类型
在基础篇中介绍了一些 ES 的数据类型,比如:Text、keyword、byte、string 等,这些类型的数据操作起来比较容易,在 ES简单操作中介绍了,不过 ES 有些数据结构上稍微复杂一点,使用嵌套类型就比较明显和容易维护。
比如说一个子弹是 productName ,但是这个字段有中英文、id、raw等不同的值,如果这些字段用 string 类型存储,那字段就会很多,那么我们可以用嵌套类型的数据结构,这样维护起来就方便点,不过需要用嵌套的方式进行查询。
类似这样:
{
"productName":{
"cn":"手机",
"en":"iphone",
"id": 100,
"raw":"苹果手机"
}
}二、添加数据
2.1 构建嵌套 mapping 映射
下面的 mapping 映射中,相当于 solr 的schema 定义固定的数据结构,我们也可以增加其他数据类型,不过在创建了映射之后就只能按照 mapping 来存放数据和操作。
productName 一个嵌套(nested)类型来存放的,在查询,排序等操作的时候就需要按照嵌套来操作。
PUT productinfo
{
"mappings": {
"properties": {
"productName":{
"type": "nested",
"properties": {
"cn":{
"type":"keyword",
"store":true
},
"en":{
"type":"keyword",
"store":true
},
"raw":{
"type":"keyword",
"store":true
},
"id":{
"type":"keyword",
"store":true
}
}
},
"productSize":{
"type": "keyword",
"store": true
},
"productDesc":{
"type": "text",
"store": true
}
}
}
}2.2 添加测试数据
我们用 bulk 来批量添加数据,按照 mapping 添加数据。
POST productinfo/_bulk
{"index":{"_index":"productinfo"}}
{"productName":{"cn":"苹果手机11","en":"iphone11","id":"1001","raw":"手机"},"productSize":16,"productDesc":"打电话,微信,拍照"}
{"index":{"_index":"productinfo"}}
{"productName":{"cn":"苹果手机12","en":"iphone12","id":"1002","raw":"手机"},"productSize":17,"productDesc":"打电话,微信,拍照3000像素"}
{"index":{"_index":"productinfo"}}
{"productName":{"cn":"小米手机","en":"xiaomi","id":"1003","raw":"手机"},"productSize":15,"productDesc":"打电话,微信,拍照,5G上网"}
{"index":{"_index":"productinfo"}}
{"productName":{"cn":"华为手机","en":"huawei","id":"1004","raw":"手机"},"productSize":14,"productDesc":"打电话,微信,拍照,打游戏"}2.3 添加mapping之外的数据
也可以添加没有 mapping 的字段,比如 commonProductName 就没有 mapping,不过查询操作也不用按照嵌套来查询。
{"index":{"_index":"productinfo"}}
{"commonProductName":"笔记本电脑","productSize":14,"productDesc":"上网,工作,打游戏,学习,看电影"}
{"index":{"_index":"productinfo"}}
{"commonProductName":"液晶屏电视","productSize":60,"productDesc":"上网,看电影,追剧"}2.4 查看添加的数据
用 match_all 来查看全部的数据。
这里有个不同之处,就是 es7 之前的版本,需要指定 dataType 类型,就像在 es 基础操作篇(见文档开头)那样,因为 基础篇是用 6.x 的版本写的。

三、嵌套操作
3.1 按照嵌套类型查询
说明:在搜索嵌套类型的字段的时候,需要指定 path 参数,来告诉 es 从 productName 字段下的 内嵌字段用 match、term、multi_match 等来搜索。
比如说现在要按照 productName 来搜索一个产品,搜索 “华为手机” 库里面有几个,搜索如下:
POST productinfo/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "productName",
"query": {
"bool": {
"should": [
{
"match": {
"productName.cn": "华为手机"
}
}
]
}
}
}
}
]
}
}
}搜索结果:
从搜索结果可以看到,进准搜索到了华为手机这个产品,当然,也可以模糊查询, 就像 es 操作的基础篇那样 (见文档开头系列目录),或者搜索 cn , en 另个字段,那么外面就是 should (or) 的关系 。
3.2 按照嵌套类型排序
下面按照 productName.cn 进行模糊搜索出来了两条数据,然后按照 productName.id 降序排序。
POST productinfo/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "productName",
"query": {
"bool": {
"should": [
{
"wildcard": {
"productName.cn": "*苹果*"
}
}
]
}
}
}
}
]
}
},
"sort": [
{
"productName.id": {
"order": "desc",
"nested_path": "productName"
}
}
]
}排序结果如下:
注意:es 提示了一行红字,意思是说 nested_path 已经弃用了,被 nested 替代了,不过我感觉还是用起来挺方便的。
那么官方推荐应该怎么写呢?如下:
下面的写法基本不变,不过坑的就是,nested 居然不提示,但是生效。
POST productinfo/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "productName",
"query": {
"bool": {
"should": [
{
"wildcard": {
"productName.cn": "*苹果*"
}
}
]
}
}
}
}
]
}
},
"sort": [
{
"productName.id": {
"order": "desc",
"nested":{
"path":"productName"
}
}
}
]
}3.3 嵌套类型分组统计
按照 productName 和 productName.cn 进行分组统计,如下:
POST productinfo/_search
{
"query": {
"match_all": {}
},
"aggs": {
"productName_count": {
"nested": {
"path": "productName"
},
"aggs": {
"cn_count": {
"terms": {
"field": "productName.cn",
"size": 10
}
}
}
}
}
}执行结果如下:
统计出来,productName.cn 字段,有 3 个苹果11, 华为、小米、苹果12 各 1个。

更复杂的分组统计可到官网查看,工作中大部分用到的以上的风阻统计就可以满足了,若有更复杂的,则继续在及过上过滤和统计。
3.4 修改嵌套类型字段值
修改按照 PUT 操作,带上 _id 即可修改。
PUT productinfo/_bulk
{"index":{"_index":"productinfo", "_id":"ZU8ga4MBZkN8aRGpIqAA"}}
{"productName":{"cn":"苹果手机12","en":"iphone11","id":"1008","raw":"手机"},"productSize":16,"productDesc":"打电话,微信,拍照"}修改结果:
四、总结
ElasticSearch 现在比较流行的全文搜索引擎,平时工作中用到的都是基础类型,有些情况下用到了嵌套类型字段,虽然数据在架构师清晰了,但是操作起来变的稍微复杂点,看情况使用吧。
前言
本文主要对ElasticSearch分词算法进行简单讲解,在了解算法之前,我们先要知道两点,什么是相关性和相关性算分。
站在用户的角度来看,检索是什么呢?检索是用户通过关键词查找针对这个关键词比较有相关性的结果,也就是说,用户其实主要关系的是搜索结果的相关性,主要涉及以下几个问题:
- 是否找到所有相关的内容。
- 是否得到了很多内容是不相关的。
- 排在最前面的搜索结果打分是否合理。
- 结合需求,结果排名是否平衡。
那如何衡量相关性呢?主要看三点:
- Precision(查准率),尽可能的返回较少的无相关的文档。
- Recall(查全率),尽量返回较多的相关的文档。
- Ranking(排序),能够按照相关性进行排序。
所以,相关性算分,描述了一个文档和查询语句匹配的程度。在 query 方式检索时,ES 会对每个匹配结果进行算分(_score)。打分的本质就是排序,把分值最高的放在最前面展示给用户。
在ES5之前使用的是 TF-IDF 算法,后面到现在8.x版本使用 BM25 算法。
一、TF-IDF
TF-IDF(Term frequency - inverse document frequency)是一种用户信息检索与数据挖掘的常用的加权技术,公认为是信息检索领域最重要的发明,而且在文献分类等其他相关领域应用非常广泛。
IDF 的概念,最早是剑桥大学的一个大佬(斯巴克.琼斯)提出来的,1972年——“关键词特殊性的统计解释和它在文献检索中的应用”,但是没有从理论上解释IDF应该是用log(全部文档数/检索词出现过的文档总数),而不是其他函数,也没有做进一步的研究,1970,1980年代萨尔顿和罗宾逊,进行了进一步的证明和研究,并用香农信息论做了证明http://www.staff.city.ac.uk/~sb317/papers/foundations_bm25_review.pdf,现代搜索引擎,对TF-IDF进行了大量细微的优化。
Lucene中的TF-IDF评分公式:
主要看这里:
- TF(Term frequency)是词频
- 检查的关键词在文档中出现的频率越高,相关性越高。
- IDF(Inverse document frequency)是逆向文本频率
- 每个检索词在索引中出现的频率,频率越高,相关性越低。
- 字段长度归一值(Field-length norm)
- 字段的长度是多少?字段越短,字段的权重越高。检索词出现在一个内容短的字段(title)要比出现在一个内容长的字段(content)权重更大。
以上三个因素 TF、IDF、Field-length norm 一起计算单个词在特定文档中的权重。
二、BM25
BM25 是对 TF-IDF 算法的改进,在 TD-IDF 算法中,TF 部分的值越大,整个计算公式返回的值就越大。BM25 就是针对这点进行优化的,随着 TF 部分值的逐步增大,那返回的值则会逐步趋于一个数值。
而在 ES 5开始,默认的算法就是 BM25。
当TF无限增加时,BM25算法会趋于一个数值,见下图:
BM25 公式如下:
三、Explain查看TF-IDF

四、小结
本文主要是针对 ElasticSearch 的分词算法在其搜索结果排序中的应用,ElasticSearch 作为一个强大的搜索引擎,其核心功能之一就是通过相关性算法为用户提供最相关的搜索结果。
本文中介绍了信息信息检索中的关键概念:查准率、查全率和排序,这些都是衡量搜索结果相关性的重要指标。
相关于 TF-IDF 算法,这是 ElasticSearch 在 5.x 版本之前使用的主要算法,通过计算词频(TF)和逆向文本频率(IDF)来评估文档与查询的相关性。
TF-IDF 算法的优化版本,BM25 算法,自 ElasticSearch 5.x 版本之后称为默认的算法,它通过引入衰减函数来避免词频过高导致的评分膨胀,使得评分更加合理。
此外,本文还介绍了如何使用Elasticsearch的Explain API来深入理解查询结果的评分细节,这对于开发者优化搜索算法和提高搜索结果质量非常有帮助。
前言
ELK技术栈由三个技术组成:Elasticsearch、Logstash和Kibana。每个技术都有自己的功能点和用法,同时它们也可以相互关联使用,形成一个完整的日志解决方案。此外,还有一个名为Beats的技术,它是一个轻量级的数据收集器,可以收集各种类型的数据并将其发送到Logstash或Elasticsearch进行处理和存储。
一、Elasticsearch
Elasticsearch是一个分布式的搜索和分析引擎,它可以快速地存储、搜索和分析大量数据。Elasticsearch使用Lucene搜索引擎来实现全文搜索,支持实时搜索和分析,可以通过API进行数据查询和聚合操作。Elasticsearch的优点包括高可用性、可扩展性、灵活性和性能优越。它的主要用途包括:
- 日志分析:Elasticsearch可以快速地存储和索引日志数据,并提供实时搜索和分析能力,适用于日志监控、安全审计等场景。
- 全文搜索:Elasticsearch可以支持全文搜索和自然语言查询,适用于搜索引擎、电子商务等场景。
- 指标分析:Elasticsearch可以支持实时聚合和分析数据,适用于性能监控、业务分析等场景。
Elasticsearch的功能包括:
- 分布式架构:Elasticsearch可以水平扩展,支持分布式部署和数据分片,可以处理大规模数据集。
- 实时搜索和分析:Elasticsearch可以提供实时搜索和分析能力,支持近实时的数据查询和聚合操作。
- 多数据源支持:Elasticsearch可以从多个数据源中收集数据,并支持多种数据格式和数据源。
- API支持:Elasticsearch提供了丰富的API,可以进行数据查询、聚合操作、索引操作等。
当前最新版本的Elasticsearch是8.x系列,它的主要特点包括:
- 更好的性能:8.x系列对性能进行了优化,可以提供更快的搜索和分析速度。
- 更好的安全性:8.x系列引入了更多的安全特性,包括加密通信、访问控制等。
- 更好的可用性:8.x系列引入了更多的高可用性特性,包括自动发现、自动恢复等。
- 更高级的功能:8.x系列加入了人工智能,对自然语言处理支持。
二、Logstash
Logstash是一个数据收集和处理引擎,用于收集、处理和转换各种数据源的数据。它可以从不同的数据源中收集数据,如文件、数据库、网络等,并将其转换为统一的格式,以便后续处理。Logstash支持多种插件,可以进行数据过滤、转换和输出。
Logstash的优点包括灵活性、可扩展性和强大的插件支持。它可以处理各种类型的数据,支持多种数据源和输出方式,可以方便地与Elasticsearch和Kibana等技术栈组件集成。此外,Logstash还支持多线程处理和事件模型,可以在大规模数据处理场景下提供高性能和可靠性。
缺点则包括性能较低和高耗费的CPU、内存资源,同时,Logstash的学习曲线较陡峭,需要一定的技术背景和经验。因此,在一些场景下,可能需要使用更轻量级的数据收集器,如Beats等。
三、Beats
Beats是ELK技术栈中的一个轻量级数据收集器,可以收集各种类型的数据并将其发送到Logstash或Elasticsearch进行处理和存储。Beats包括Metricbeat、Filebeat、Packetbeat、Winlogbeat等多个模块,可以适用于不同类型的数据收集场景。
功能:
- 日志收集:Beats可以收集各种类型的日志数据,如系统日志、应用日志、安全日志等。
- 指标收集:Beats可以收集各种类型的指标数据,如CPU、内存、网络、磁盘等。
- 事件收集:Beats可以收集各种类型的事件数据,如网络流量、系统事件等。
优点
- 轻量级:Beats是一个轻量级的数据收集器,可以快速安装、部署和配置。
- 易用性:Beats提供了简单易用的配置界面和命令行工具,可以方便地进行数据收集和管理。
- 灵活性:Beats支持多种数据源和输出方式,可以方便地与其他技术栈组件集成。
- 低资源消耗:Beats的资源消耗较低,可以在资源受限的设备上运行。
缺点
- 功能限制:相对于Logstash,Beats的功能较为有限,无法进行复杂的数据处理和转换。
- 不支持插件:Beats不支持自定义插件,无法进行自定义的数据过滤、转换和输出。
- 不适用于大规模数据:由于Beats本身是一个轻量级的数据收集器,不适用于大规模数据的收集和处理。
总的来说,Beats是一个轻量级、易用性好的数据收集器,适用于小规模数据的收集和处理。对于大规模数据的收集和处理,可能需要使用更为复杂、功能更为强大的数据收集引擎,如Logstash。
四:Kinaba
Kibana是一个数据可视化和分析工具,用于展示和分析从Elasticsearch中收集的数据。它可以通过可视化的方式展示数据,如图表、地图、仪表盘等,并支持实时查询和分析。Kibana还支持自定义仪表盘和可视化组件,可以根据需求自由定制数据展示方式。Kibana的优点包括易用性、可定制性和强大的可视化功能。缺点则包括不适用于大规模数据的查询和可视化。
常用功能
- 可视化展示:Kibana支持多种数据可视化方式,如图表、地图、仪表盘等,可以根据需求自由定制数据展示方式。
- 实时查询:Kibana支持实时查询和分析,可以快速地查看最新数据和结果。
- 仪表盘定制:Kibana支持自定义仪表盘和可视化组件,可以根据需求自由定制数据展示方式。
- 搜索:Kibana支持全文搜索和自然语言查询,可以方便地查询和过滤数据。
优点
- 易用性:Kibana提供了简单易用的界面和工具,可以方便地进行数据可视化和分析。
- 可定制性:Kibana支持自定义仪表盘和可视化组件,可以根据需求自由定制数据展示方式。
- 可视化功能:Kibana支持多种数据可视化方式,可以直观地展示数据和结果。
缺点
- 不适用于大规模数据:由于Kibana的查询和可视化功能较为复杂,不适用于大规模数据的查询和可视化。
- 学习曲线较陡峭:Kibana的学习曲线较陡峭,需要一定的技术背景和经验。
- 可视化功能较弱:相对于其他可视化工具,Kibana的可视化功能较为基础,无法进行复杂的数据可视化和分析。
总的来说,Kibana是一个易用性好、可定制性强的数据可视化和分析工具,适用于小规模数据的查询和可视化。对于大规模数据的查询和可视化,可能需要使用更为复杂、功能更为强大的可视化工具,如Tableau等。
五、总结
ELK技术栈的三个技术可以相互关联使用,形成一个完整的日志解决方案。Logstash负责收集和处理数据,将数据发送到Elasticsearch进行存储和索引,Kibana则用于展示和分析数据。这样的架构可以实现实时日志收集、存储、搜索和分析,适用于日志监控、安全审计、性能分析等领域。
总的来说,ELK技术栈具有灵活性、可扩展性和强大的数据处理和可视化能力,是一个优秀的日志解决方案。但同时也需要注意技术栈的学习曲线和性能问题。
前言
Logstash是一个收集与处理数据的引擎,就像ElasticSearch是专门用来检索的引擎一样,Logstash用于收集、处理和转换各种数据源(文件、数据库、网站等)的数据,并将其转换为统一的格式。
Logstash支持多种插件,进行数据过滤、转换和输出,可以方便地与 ES 和 Kibana 集成使用。
还支持多线程处理和事件模型,可以在大规模数据处理场景下提供高性能、高可用的服务。
一、什么是Logstash?
1.1 Logstash介绍
什么是Logstash呢,简单说就是它有很多数据处理管道,Logstash是免费开放的服务器数据处理管道,从多个来源采集数据、处理数据,再发送数据到指定的存储介质中去。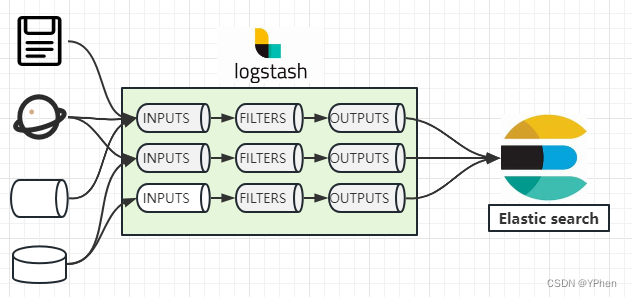
如上图所示,Logstash通过 INPUT(管道) 输入数据,通过 FILTERS(管道) 处理完成之后,再通过 OUTPUTS (管道)输出到 ES 中。
1.2 Logstash 核心概念
Pipeline :
- 包含了 input > filter > output 三个阶段的处理流程
- 插件生命周期管理
- 队列管理
Event :
数据在内部流转的一个具体表现形式,数据在 INPUT 阶段被转换成了 Event,在 OUTPUT 被转换为目标格式的数据,Event 就是一个 Java Object 对象,可在配置文件中对属性进行增删改查操作。
Codec(Code / Decode):
将原始数据 decode 成 Event, 再将 Event encode 成目标数据。
1.3 Logstash数据传输原理
- 数据采集与输入:Logstash支持各种输入选择,能够以连续的流式传输方式,轻松地从日志、指标、Web应用以及数据存储中采集数据。
- 实时解析和数据转换:通过Logstash过滤器解析各个事件,识别已命名的字段来构建结构,并将它们转换成通用格式,最终将数据从源端传输到存储库中。
- 存储与数据导出:Logstash提供多种输出选择,可以将数据发送到指定的地方。
1.4 Logstash配置文件结构
Logstash的管道配置文件对每种类型的插件都提供了一个单独的配置部分,用于处理管道事件。
input {
stdin { }
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { hosts => ["localhost:9200"]}
stdout { codec => rubydebug }
}每个配置部分可以包含一个或多个插件。例如,指定多个filter插件,Logstash会按照它们在配置文件中出现的顺序进行处理。
- Input Plugins(官网文档)
一个 Pipeline可以有多个input插件:File、jdbc 等 - Output Plugins (官网文档)
将Event发送到特定的目的地,是 Pipeline 的最后一个阶段,常见的是 Elasticsearch。 - Filter Plugins (官网文档)
内置的Filter Plugins: Mutate(一操作Event的字段)、Ruby (一执行Ruby 代码 )等。 - Codec Plugins(官网文档)
将原始数据decode成Event;将Event encode成目标数据,内置的Codec Plugins: Line / Multiline、JSON 等。 - Logstash Queue
In Memory Queue:进程Crash,机器宕机,都会引起数据的丢失
Persistent Queue:机器宕机,数据也不会丢失; 数据保证会被消费; 可以替代 Kafka等消息队列缓冲区的作用,可以通过如下配置打开持久化。
queue.type: persisted (默认是memory)
queue.max_bytes: 4gb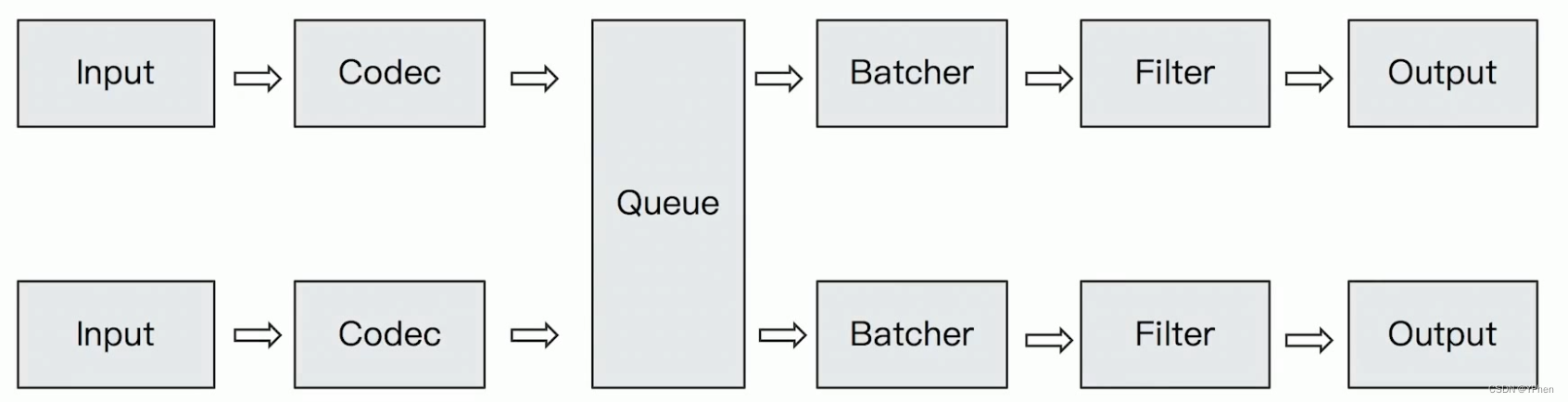
二、Logstash安装
- 从官网下载 Logstash并解压,Linux 直接用 wget 命令下载:
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.7.0-linux-x86_64.tar.gz
tar -zxvf logstash-8.7.0-linux-x86_64.tar.gz- 通过命令测试:
//-e选项表示,直接把配置放在命令中,可以快速进行测试
bin/logstash -e 'input { stdin { } } output { stdout {} }'当看到 Pipelines running … 表示启动完成,输入 “Hello” 测试,结果如下: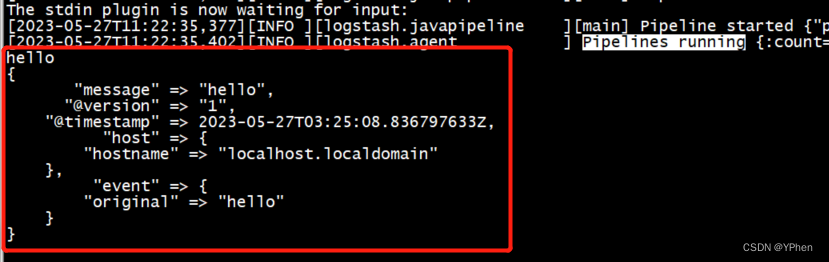
在我输入了 ‘Hello’ 之后,输入的信息通过 message 输出出来,测试成功。
- Codec Plugin测试
//此处 Codec 输入要求是json 格式的数据。
bin/logstash -e "input{stdin{codec=>json}}output{stdout{codec=> rubydebug}}"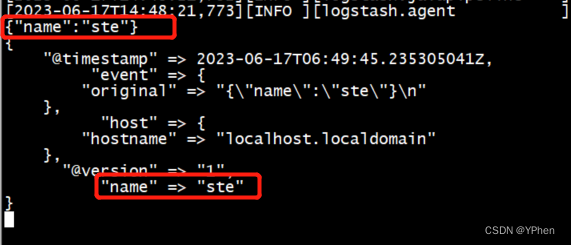
三、管道配置
3.1 通过文件读取数据
- 管道配置:
注: 在 Logstash 的管道中,mutate 是一个插件,它可以对数据进行变换和处理,用于对数据进行了多个变换操作。
内置了很多插件,这里只做一个示例。
//输入配置,从文件中输入
input {
file {
path => "/home/movies.csv"
//从文件起始位置开始读取
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
//处理器管道配置
filter {
//CSV过滤器:该过滤器接受来自CSV格式的数据,并使用逗号(,)分割,并且定义了每个列的名称。
csv {
separator => ","
columns => ["id","content","genre"]
}
//CSV转换器:该过滤器对 genre 字段用 "|" 进行了分割;移除了 "path","host","@timestamp","message" 列。
mutate {
split => {"genre" => "|"}
remove_field => ["path", "host", "@timestamp", "message"]
}
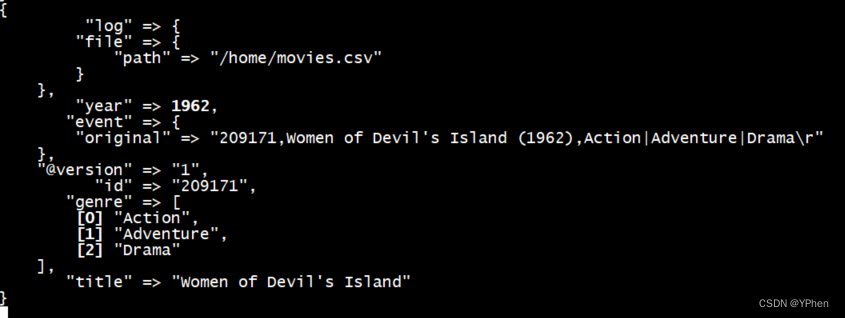
//对 content 字段用 "(" 进行切分,它将这些关键字用 "%{[content][0]}和 "%{[content][1]} 分别表示,增加了两个字段 title 和 year。;移除了 "path","host","@timestamp","message" 和 "content" 这些字段。
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
//把 year 字段值转换为 integer 类型;移除了字段。
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
//输出:该管道的最后一个部分是将数据发送到 Elasticsearch 中的 movies index。
output {
elasticsearch {
hosts => "http://192.168.1.10:9200"
index => "movies"
document_id => "%{id}"
}
//stdout 输出:该管道的最后一个部分是将日志输出到控制台。
stdout {}
}- 运行管道
bin/logstash -f config/logstash-stdin.conf- 管道运行中
3.2 JDBC读取数据
- 管道配置
input {
jdbc {
jdbc_driver_library => "/usr/local/software/logstash-8.7.0/driver/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.7:3306/wesh?useSSL=false"
jdbc_user => "root"
jdbc_password => "123456"
//启用追踪,如果为true,则需要指定tracking_column
use_column_value => true
//指定追踪的字段
tracking_column => "last_updated"
//追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认是数字类型
tracking_column_type => "numeric"
record_last_run => true
//上面运行结果的保存位置
last_run_metadata_path => "jdbc-position.txt"
statement => "SELECT * FROM user where last_updated >:sql_last_value;"
schedule => " * * * * * *"
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "users"
hosts => ["http://192.168.1.10:9200"]
}
stdout{
codec => rubydebug
}
}- 运行管道
bin/logstash -f config/logstash-jdbc.conf四:总结
logstash 是用插件的方式进行配置处理器的,默认提供了各类的插件,只需要在 filter 中配置 处理插件即可,从各种数据库或者网页中拉取数据,经过处理器在输出数据到 ES 中。
logstash 可以:
- 实现日志搜索和分析,从而识别、解决和跟踪故障和安全漏洞。
- 支持复杂的数据源,包括文件、数据库、Web 应用程序和其他传感器。
- 使用自定义模板,可以快速添加新的、高度可配置的特性和功能。
特点: - 强大的日志搜索和分析能力。
- 简单的管理和配置。
- 高度可扩展性,可以在生产环境中运行。
- 可定制性强,可以添加自定义模板和脚本。
- 支持各种数据源。
- 自动化和快速添加新的特性和功能。
工作中,可以有效的使用 logstash 来收集日志,方便来排查和追踪线上的问题;可以实时监控数据更新,同步上线更新数据等。
ElasticSearch 8.x 使用 snapshot(快照)进行数据迁移
前言
平时在工作中,很多时候都是需要搭建好几个测试平台来保证应用的运行是否流畅,有没有 Bug,数据是否正确,一般都是 dev、pre 等测试环境,通过一系列的测试之后没有什么问题,才会把 应用 和 数据 部署到 prod 环境,应用一般都是大包 prod 环境的部署包,直接部署,而数据则就需要很长的实际来同步了,如果是一些统计咨询类的企业应用,那数据上线就有可能花费掉大量的时间了。
此篇就来浅谈一下,项目中应用到了 ElasticSearch 来做数据检索,那在项目上线的时候,我们如何快速的把大量数据快速从一个 ElasticSearch索引迁移到另一个索引库。
A snapshot is a backup of a running Elasticsearch cluster.
官网上说,一个快照就是一个备份在 Elasticsearch 集群上运行的时候,快照可以用于以下几点:
- 集群服务不停的情况下定期备份数据;
- 删除或者硬件出错后恢复数据;
- 在两台集群中间传输数据;
- 通过在冷和冻结数据层中使用可搜索的快照来降低存储成本;
那具体什么是快照呢?
一、什么是ES的快照
Elasticsearch 的快照就是指对数据和元数据的定期备份。因为快照中不仅包含了所有数据,也包含了所有的相关信息,比如:映射、配置等;这些快照可以保存在本地文件系统,也可以保存在共享文件系统或者专门存储快照的地方。
在快照的概念中,数据并不都是每次全部备份一遍,而是采用增量的方式进行进行备份。首次备份会进行全力备份,而后续的备份则是在上一次备份后的更新的数据,增量备份可以有效地减少备份所需的存储空间和节省时间。
对于 Elasticsearch 的迁移,快照和恢复则是很常用的一种强大的方式,在源集群上创建索引的快照,拷贝到其他集群后在恢复,也可以用 API 的方式来进行快照和恢复,这里就用 JAVA + Elasticsearch Client 实现,这样在我们后台应用就可以完成数据迁移了。
二、快照生成
2.1 新建仓库
2.1.1 Kibana操作
可以通过 Kibana 指令来注册快照,命令如下:
POST _snapshot/productInfo
{
"type": "fs",
"settings": {
"location": "/data/esbackup/product_info"
}
}执行以上指令,有可能报错,一般会报如下错误:
"caused_by": {
"type": "repository_exception",
"reason": "[productInfo] location [/data/esbackup] doesn't match any of the locations specified by path.repo because this setting is empty"
}报上述错误一般是 Elasticsearch 服务没有配置 path.repo 这个参数,只需要在 elasticsearch.yml 中配置 path.repo: /data/repository 即可。
如果报错如下:
"caused_by": {
"type": "access_denied_exception",
"reason": "/data/repository/tests-gU8mf7EvREG_1qMc3ZMApQ"
}说明你配置的 path.repo 的路径没有访问权限,赋予权限即可:chown -R elasticsearch:elasticsearch /data/esbackup/productInfo/
2.1.2 JAVA API操作
2.1.2.1 引入 pom 依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.3.2</version>
</dependency>注意: 再次感受到 elasticsearch-rest-high-level-client 对版本的严格区分,可能是我的 ElasticSearch 配置或者是其他原因,低版本的客户端使用 BulkProcessor 是没有问题的,但是在 获取快照 操作测报错,高版本的客户端在 获取快照时没问题,但是在 BulkProcessor 批量操作数据时报错,你的是否也有这个问题呢?
2.1.2.2 初始化客户端
/**
* 通过认证连接ES,获取客户端
*/
public static RestHighLevelClient createClient(){
String hostname = "192.168.*.*";
int port = 9200;
String username = "your username";
String password = "your password";
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(hostname, port))
.setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(restClientBuilder);
}2.1.2.3 创建仓库(参数方式)
/**
* 创建仓库
*/
public static void createRepository(RestHighLevelClient client, String repositoryName) {
GetRepositoriesRequest getRepositoriesRequest = new GetRepositoriesRequest(new String[]{repositoryName});
boolean hasRepository = false;
try {
GetRepositoriesResponse repository = client.snapshot().getRepository(getRepositoriesRequest, RequestOptions.DEFAULT);
List<RepositoryMetadata> repositories = repository.repositories();
for (RepositoryMetadata repositoryMetadata : repositories) {
if(repositoryMetadata.name().equals(repositoryName)){
hasRepository = true;
break;
}
}
} catch (ElasticsearchStatusException ee) {
System.out.println("仓库不存在:" + ee.getMessage());
} catch (IOException ioException) {
// 客户端版本略低,所以用异常捕获方式判断,索引存在会抛到这里异常
System.err.println(ioException.getMessage());
hasRepository = true;
}
if(!hasRepository){
try {
PutRepositoryRequest repositoryRequest = new PutRepositoryRequest();
repositoryRequest.name(repositoryName);
repositoryRequest.verify(false);
repositoryRequest.name(repositoryName);
repositoryRequest.type("fs");
repositoryRequest.settings(Settings.builder().put("location", "/data/esbackup/productInfo"));
AcknowledgedResponse acknowledgedResponse = client.snapshot().createRepository(repositoryRequest, RequestOptions.DEFAULT);
if (acknowledgedResponse.isAcknowledged()) {
System.out.println("创建仓库成功: " + repositoryName);
}
} catch (IOException e) {
e.printStackTrace();
}
}
try {
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}2.1.2.3 创建仓库(配置文件方式)
- 配置文件如下:
src/main/resources/productInfo.json
{
"type": "fs",
"settings": {
"location": "/data/esbackup/productInfo",
"compress": true
}
}- 读取配置,创建仓库:
注意:仓库名称 repositoryName 必须小写
/**
* 创建仓库
*/
public static void createRepository(RestHighLevelClient client, String settingPath, String repositoryName) {
GetRepositoriesRequest getRepositoriesRequest = new GetRepositoriesRequest(new String[]{repositoryName});
boolean hasRepository = false;
try {
GetRepositoriesResponse repository = client.snapshot().getRepository(getRepositoriesRequest, RequestOptions.DEFAULT);
List<RepositoryMetadata> repositories = repository.repositories();
for (RepositoryMetadata repositoryMetadata : repositories) {
if(repositoryMetadata.name().equals(repositoryName)){
hasRepository = true;
break;
}
}
} catch (ElasticsearchStatusException ee) {
System.out.println("仓库不存在:" + ee.getMessage());
} catch (IOException ioException) {
// 客户端版本略低,所以用异常捕获方式判断,索引存在会抛到这里异常
System.err.println(ioException.getMessage());
hasRepository = true;
}
if(!hasRepository){
try {
String jsonString = new String(Files.readAllBytes(Paths.get(settingPath)), StandardCharsets.UTF_8);
// 解析 json
PutRepositoryRequest repositoryRequest = new PutRepositoryRequest();
XContentParser contentParser = XContentFactory.xContent(XContentType.JSON).createParser(NamedXContentRegistry.EMPTY, DeprecationHandler.THROW_UNSUPPORTED_OPERATION, jsonString);
repositoryRequest.name(repositoryName);
repositoryRequest.verify(false);
repositoryRequest.source(contentParser.map());
AcknowledgedResponse acknowledgedResponse = client.snapshot().createRepository(repositoryRequest, RequestOptions.DEFAULT);
if (acknowledgedResponse.isAcknowledged()) {
System.out.println("创建仓库成功: " + repositoryName);
}
} catch (IOException e) {
e.printStackTrace();
}
}
try {
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}2.2 生成快照
2.2.1 Kibana操作
POST _snapshot/product_info/product_info2.2.2 JAVA API操作
注: 快照名称 snapshotName 必须小写
/**
* 生成快照
*/
public static boolean createSnapshot(RestHighLevelClient client, String snapshotName, String repositoryName, String... indexes) {
CreateSnapshotRequest createSnapshotRequest = new CreateSnapshotRequest();
createSnapshotRequest.indices(indexes);
createSnapshotRequest.snapshot(snapshotName);
createSnapshotRequest.repository(repositoryName);
createSnapshotRequest.waitForCompletion(true);
createSnapshotRequest.includeGlobalState(false);
try {
CreateSnapshotResponse snapshotResponse = client.snapshot().create(createSnapshotRequest, RequestOptions.DEFAULT);
SnapshotInfo snapshotInfo = snapshotResponse.getSnapshotInfo();
if (snapshotInfo.status().getStatus() == 200) {
System.out.println("快照创建成功:" + snapshotInfo);
return true;
}
} catch (IOException e){
e.printStackTrace();
} finally {
try {
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return false;
}快照生成成功,如图:
2.3 删除快照
2.3.1 Kibana操作
DELETE _snapshot/product_info2.3.2 JAVA API操作
/**
* 删除快照
*/
public static boolean deleteSnapshot(RestHighLevelClient client, String repositoryName) {
DeleteSnapshotRequest deleteSnapshotRequest = new DeleteSnapshotRequest();
deleteSnapshotRequest.snapshots(repositoryName);
deleteSnapshotRequest.repository(repositoryName);
try {
AcknowledgedResponse deleteSnapshotResponse = client.snapshot().delete(deleteSnapshotRequest, RequestOptions.DEFAULT);
if (deleteSnapshotResponse.isAcknowledged()) {
System.out.println("快照删除成功!");
return true;
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return false;
}三、恢复快照
3.1 Kibana操作
POST _snapshot/product_info/product_info/_restore
{
"indices": "product_info"
}3.2 JAVA API操作
/**
* 恢复快照
*/
public static void restoreSnapshot(RestHighLevelClient client, String snapshotName, String repositoryName, String indexes){
RestoreSnapshotRequest restoreSnapshotRequest = new RestoreSnapshotRequest();
restoreSnapshotRequest.snapshot(snapshotName);
restoreSnapshotRequest.repository(repositoryName);
restoreSnapshotRequest.indices(indexes);
try {
RestoreSnapshotResponse restoreSnapshotResponse = client.snapshot().restore(restoreSnapshotRequest, RequestOptions.DEFAULT);
System.out.println("快照恢复成功:" + restoreSnapshotResponse.getRestoreInfo().toString());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}前言
在之前的项目中都是用 SearchRequestBuilder 来构件 ElasticSearch 检索请求的,然后使用了新的 High Level Client 之后新的客户端构建查询是用了 SearchSourceBuilder 来构建检索请求的,若使使用新的检索方式请移步《Elasticsearch Java API 如何使用》查看。
那用 SearchSourceBuilder 进行构建查询时需要使用 RestHighLevelClient 客戶端来发送请求的,简单代码如下:
RestHighLevelClient client = createClient();
SearchRequest searchRequest = new SearchRequest();
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequest.source(sourceBuilder);
sourceBuilder.from(0).size(10);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);以上这种写法就是 High Level Client 常见的写法。
那如果特殊情况下,比如需要和老项目融合的时候,可能需要使用到 SearchRequestBuilder 来检索,该如何做呢?
就是用 ElasticsearchClient 来包装 RestHighLevelClient 来执行查询,真正的检索使用 RestHighLevelClient 来执行的,而 ElasticsearchClient 则是构建为了融合并初始化 SearchRequestBuilder 而创建的。
一:pom 依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.16</version>
</dependency>二:初始化客户端
2.1 初始化 HighLevelClient 客户端
这里首先要初始化 HighLevelClient 客户端,因为真正的检索需要使用此客户端来执行的。
/**
* 初始化客户端
* @return RestHighLevelClient
*/
private static RestHighLevelClient getClient(){
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("Your username", "Your password"));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost("192.168.*.*", 9200))
.setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
RestHighLevelClient highLevelClient = new RestHighLevelClient(restClientBuilder);
return highLevelClient;
}2.2 初始化 ElasticsearchClient 客户端
这里我们来初始化 ElasticsearchClient 客户端,为什么要初始化此客户端呢?ElasticsearchClient 就像是一个代理客户端,调用了 HighLevelClient 来执行查询。
这里,我们把 RestHighLevelClient 作为参数传入,用于封装。
private static ElasticsearchClient getEsClient(RestHighLevelClient highLevelClient){
return new ElasticsearchClient() {
@Override
public <Request extends ActionRequest, Response extends ActionResponse> ActionFuture<Response> execute(ActionType<Response> action, Request request) {
if (action.equals(SearchAction.INSTANCE) && request instanceof SearchRequest) {
return new ActionFuture<Response>() {
@Override
public Response actionGet() {
try {
// 执行检索
return (Response) highLevelClient.search((SearchRequest) request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
@Override
public Response actionGet(String timeout) {
try {
// 将字符串形式的时间转换为 TimeValue
TimeValue timeValue = TimeValue.parseTimeValue(timeout, "timeout");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(timeValue);
SearchRequest searchRequest = new SearchRequest();
searchRequest.source(sourceBuilder);
// 执行检索
return (Response) highLevelClient.search((SearchRequest) request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public Response actionGet(long timeoutMillis) {
try {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(TimeValue.timeValueMillis(timeoutMillis));
SearchRequest searchRequest = new SearchRequest();
searchRequest.source(sourceBuilder);
// 执行检索
return (Response) highLevelClient.search((SearchRequest) request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public Response actionGet(long timeout, TimeUnit unit) {
return null;
}
@Override
public Response actionGet(TimeValue timeout) {
return null;
}
@Override
public boolean cancel(boolean mayInterruptIfRunning) {
return false;
}
@Override
public boolean isCancelled() {
return false;
}
@Override
public boolean isDone() {
return false;
}
@Override
public Response get() throws InterruptedException, ExecutionException {
return null;
}
@Override
public Response get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
return null;
}
};
} else {
throw new UnsupportedOperationException("Unsupported action: " + action.name());
}
}
@Override
public <Request extends ActionRequest, Response extends ActionResponse> void execute(ActionType<Response> action, Request request, ActionListener<Response> listener) {
if (action.equals(SearchAction.INSTANCE) && request instanceof SearchRequest) {
highLevelClient.searchAsync((SearchRequest) request, RequestOptions.DEFAULT, (ActionListener<SearchResponse>) listener);
} else {
throw new UnsupportedOperationException("Unsupported action: " + action.name());
}
}
@Override
public ThreadPool threadPool() {
return null;
}
};
}以上初始化的 ElasticsearchClient 客户端中,只实现了常用的部分 actionGet 方法,其他方法在使用时再实现,实现方法基本上都差不多。
三:执行查询
ElasticsearchClient 则是可以通过 SearchRequestBuilder 来调用执行检索,在 new SearchRequestBuilder() 时,ElasticsearchClient 作为参数传递,则直接可以通过 execute().actionGet() 来执行检索并得到结果了。
public static void main(String[] args) {
RestHighLevelClient highLevelClient = getClient();
ElasticsearchClient esClient = getEsClient(highLevelClient);
SearchRequestBuilder requestBuilder = new SearchRequestBuilder(esClient, SearchAction.INSTANCE);
requestBuilder.setIndices("product_info");
requestBuilder.setFrom(0);
requestBuilder.setSize(10);
requestBuilder.setQuery(QueryBuilders.matchAllQuery());
requestBuilder.addAggregation(AggregationBuilders.terms("productName").field("productName.keyword"));
// 执行检索并获取检索结果
String s = requestBuilder.execute().actionGet().toString();
System.out.println("检索结果:" + s);
JSONObject jsonObject = JSONObject.parseObject(s);
// 获取到 agg 统计结果
JSONObject aggregations = jsonObject.getJSONObject("aggregations");
System.out.println(aggregations);
try {
highLevelClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
代码解读执行结果:
检索结果:{"took":0,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":2,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"product_info","_id":"1001","_score":1.0,"_source":{"productName":"小米汽车","productDescription":"相当于保时捷特斯拉的小米超跑","color":"海蓝色","price":19}},{"_index":"product_info","_id":"1002","_score":1.0,"_source":{"productName":"小米手机","productDescription":"小米,智能手机,价格实惠便宜","color":"黑色","price":2999}}]},"aggregations":{"sterms#productName":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"小米手机","doc_count":1},{"key":"小米汽车","doc_count":1}]}}}
统计结果:{"sterms#productName":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"doc_count":1,"key":"小米手机"},{"doc_count":1,"key":"小米汽车"}]}}前言
在平时测试环境中,我们可以通过 IP 地址 或者 域名【http://***】来简单粗暴的连接 ElasticSearch 服务,比较内网测试没必要考虑别的,连接上能进行索引的操作即可;不过到了生产环境,安全问题成了 头号杀手,毕竟数据无价嚒,不过目前很多企业应用都会部署到云端,应用 和 ElasticSearch 服务之前其实也是属于内网连接,并不会暴漏链接到外面,再加上云服务自身的安全和防火前的保护,所以安全基本上不用考虑了。
可以公司是有规范的,无论是 DB 数据库还是缓存,还是像 ElasticSearch 这种搜索引擎必须要有 用户名和密码 这层安全校验的,这是安全最基本的,所以应对不同的环境 或许 就需要不同的连接方式了。
一:pom 依赖
对于 ElasticSearch 客户端的版本,不需要太高,稳定很重要,对于有些莫名其妙的问题,换一个 版本的 客户端有可能就好了,亲身经历。
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.15.2</version>
</dependency>二:开放式连接方式
public static RestHighLevelClient getClient(){
RestClientBuilder builder = RestClient.builder(
new HttpHost(HOSTNAME, 9200, "http")
);
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}三:用户名密码验证方式
这种方式在其他博客中已经提到好几次了,放到这里只为有需要的 码友 们拷贝代码。
private static RestHighLevelClient createClient(){
String hostname = "192.168.0.67";
int port = 9200;
String esUsername = "your es username";
String esPassword = "your es password";
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(esUsername, esPassword));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(hostname, port))
.setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(restClientBuilder);
}四:忽略 SSL证书 和 主机名验证
生产环境的 ElasticSearch 有时可能是通过域名来访问的,并且是 https 开头的,那就需要 SSL/TLS 认证了,但是我们并不需要,那只能忽略了。
4.1 忽略 SSL 认证
按上面说的,ElasticSearch 访问地址是 https://***,而只配置了 用户名密码,那用客户端链接则 可能 会报如下错误:
javax.net.ssl.SSLHandshakeException:PKIX path building failed:sun.security.provider.certpath.SunCertPathBuilderException:unable to find valid certification path to requested target
at org.elasticsearch.client.RestClient.extractAndWrapCause(RestClient.java:783)
at org.elasticsearch.client.RestClient.performRequest(RestClient.java:218)
at org.elasticsearch.client.RestClient.performRequest(RestClient.java:205)
at org.elasticsearch.client.RestHighLevelclient.internalPerformRequest(RestHighLevelclient.java:1454)
at org.elasticsearch.client.RestHighLevelclient.performRequest(RestHighLevelclient.java:1424)此时我们需要忽略 SSL 认证,然忽略 SSL 的写法也有好几种。
注意: 以下三种方式选择其中一种就可以,那种适合就用那种。
方式一
首先获取 TLS 的 SSLContext 实例,再进行初始化,初始化的时候什么都不做。
public static RestHighLevelClient createClient(){
String hostname = "es.test.com";
int port = 9200;
String esUsername = "your es username";
String esPassword = "your es password";
// 配置用户名和密码
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(esUsername, esPassword));
RestClientBuilder clientBuilder = RestClient.builder(new HttpHost(hostname, port, "https"));
clientBuilder.setHttpClientConfigCallback( httpAsyncClientBuilder -> {
// 配置认证支持
httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
// 忽略证书配置
try {
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, new TrustManager[] {
new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[] x509Certificates, String s)
throws CertificateException {
// 忽略证书错误 信任任何客户端证书
}
@Override
public void checkServerTrusted(X509Certificate[] x509Certificates, String s)
throws CertificateException {
// 忽略证书错误 信任任何客户端证书
}
@Override
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[0];
}
}
},
null);
httpAsyncClientBuilder.setSSLContext(sslContext);
} catch (NoSuchAlgorithmException | KeyManagementException e) {
System.out.println("忽略证书错误");
}
// 忽略 hostname 校验认证
httpAsyncClientBuilder.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE);
return httpAsyncClientBuilder;
});
return new RestHighLevelClient(clientBuilder);
}方式二
首先创建一个信任策略的 TrustStrategy,再通过策略构建一个 SSLContext 。
public static RestHighLevelClient createClient(){
String hostname = "es.test.com";
int port = 9200;
String esUsername = "your es username";
String esPassword = "your es password";
// 配置用户名和密码
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(esUsername, esPassword));
RestClientBuilder clientBuilder = RestClient.builder(new HttpHost(hostname, port, "https"));
clientBuilder.setHttpClientConfigCallback(httpAsyncClientBuilder -> {
httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
try {
// 创建一个信任所有证书的 TrustStrategy 策略
TrustStrategy acceptTrustStrategy = (chain, authType) -> true;
// 使用 SSLContextBuilder 创建 SSLContext
SSLContext sslContext = SSLContextBuilder.create().loadTrustMaterial(null, acceptTrustStrategy).build();
httpAsyncClientBuilder.setSSLContext(sslContext);
} catch (NoSuchAlgorithmException | KeyStoreException | KeyManagementException e) {
e.printStackTrace();
}
return httpAsyncClientBuilder;
});
return new RestHighLevelClient(clientBuilder);
}方式三
这里需要一个引入一个第三方的 jar 包,封装了我们需要的 SSL 认证实例。
<dependency>
<groupId>io.github.hakky54</groupId>
<artifactId>sslcontext-kickstart</artifactId>
<version>8.1.4</version>
</dependency>下面通过第三方 jar 包提供的 SSLFactory 来得到 SSLContext 。
public static RestHighLevelClient createClient(){
String hostname = "es.test.com";
int port = 9200;
String esUsername = "your es username";
String esPassword = "your es password";
// 用户名和密码认证
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(esUsername, esPassword));
// 配置策略工厂
SSLFactory sslFactory = SSLFactory.builder()
.withUnsafeTrustMaterial()
.withUnsafeHostnameVerifier()
.build();
RestClientBuilder clientBuilder = RestClient.builder(new HttpHost(hostname, port, "https"));
clientBuilder.setHttpClientConfigCallback(httpAsyncClientBuilder -> {
httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
// 通过策略工厂获取一个 SSLContext
httpAsyncClientBuilder.setSSLContext(sslFactory.getSslContext());
return httpAsyncClientBuilder;
});
return new RestHighLevelClient(clientBuilder);
}4.2 忽略 主机名验证
处理 SSL 认证,还有可能包如下错误:
java.io.IOException: Host name 'devintes.jibo.cn' does not match the certificate subject provided by the peer (CN=elasticsearch-devint-master)我们接着忽略,只需要在忽略 SSL 是再忽略 主机名验证就可以了,代码如下:
httpAsyncClientBuilder.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE);其实再上面的 方式三 中,用 SSLFactory 也是可以忽略的。
前言
经常在工作中遇到如下情况,就是一对多的情况,数据 A 关联到多个 数据 B,那这种情况在关系型数据库中存储是非常简单且方便的,只需要加入一个外键就可以用 join 来检索了,不用很关心 数据 B 的量有多大,反正对于关系型数据库来说一个 join 不成大问题;
那对于 ES 来说,这种情况只能有两种方式来做了,第一就是字段嵌套,需要定义一个 nested(嵌套)类型的字段,字段中有多个 对象,第二就是本文要讲到的 父子文档嵌套并用 has_child、has_parent 来检索。
一、Kibana 中操作
1.1 Join 类型字段
首先我们在 Kibana 中用如下指令创建一个索引(my-index-000001),并且添加 添加 join 类型的字段,下面案例摘自官网,感兴趣可以点击 “我要去官网学习” 去瞅瞅。
我要去官网学习!
PUT my-index-000001
{
"mappings": {
"properties": {
"my_id": {
"type": "keyword"
},
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}my_join_field: join 类型字段名称。
relations: 定义关系,“question”: “answer” 表示 question 是 answer 的父文档。
1.2、写入关联数据
- 首先写入父文档,也就是我们定义的 mapping 中的 relations 的关系是 question,可以看下面两条示例数据,字段
my_join_field的值是question。
PUT my-index-000001/_doc/1?refresh
{
"my_id": "1",
"text": "This is a question 001",
"my_join_field": {
"name": "question"
}
}
PUT my-index-000001/_doc/2?refresh
{
"my_id": "2",
"text": "This is another question 002",
"my_join_field": {
"name": "question"
}
}- 紧接着写入子文档,也就是定义的 relation 的关系是 answer,可以看下面两条示例数据,字段
my_join_field的值是answer。
PUT my-index-000001/_doc/3?routing=1&refresh
{
"my_id": "3",
"text": "This is an answer for question 001",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
PUT my-index-000001/_doc/4?routing=1&refresh
{
"my_id": "4",
"text": "This is another answer for question 001",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}注意: 在写入子文档时,要注意以下三点:
- 必须指定 routing,routing 表示路由,路由值是必须的,因为父子文档必须在同一分片上进行索引。
- my_join_field 字段需要指定是 answer。
- 需要指定 parent,就是父文档的 id。
1.3、数据检索
下面通过 has_child 和 has_parent 来执行检索,需要注意的是如果你是要在父或者子文档中继续用条件检索,在 里面的 query 中继续添加检索条件,下面示例中都是 match_all 。
1.3.1 has_child 检索
GET my-index-000001/_search
{
"query": {
"has_child": {
"type": "answer",
"query": {
"match_all": {}
}
}
}
}通过 has_child 就可以检索出来拥有子文档的文档,也就是我们最终得到的是 父文档 的内容,也就是 question。
1.3.2 has_parent 检索
GET my-index-000001/_search
{
"query": {
"has_parent": {
"parent_type": "question",
"query": {
"match_all": {}
}
}
}
}通过 has_child 就可以检索出拥有父文档的子文档,那我们最终拿到的是 “子文档” 的内容,也就是 answer。
四、High Level REST Client 操作
4.0 初始化 ES 客户端
/**
* 通过认证连接ES,获取客户端
*/
public static RestHighLevelClient createClient(){
String hostname = "192.168.*.*";
int port = 9200;
String username = "your es username";
String password = "your es password";
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(hostname, port))
.setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(restClientBuilder);
}4.1 创建索引(join字段)
我们要创建一个带有 join 字段的索引,所以在创建索引的时候需要提供 mapping,下面是 mapping 示例,是一个 json 文件。
src/main/resources/mapping/myIndexMapping.json
{
"mappings": {
"properties": {
"my_id": {
"type": "keyword"
},
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}写好了 mapping ,下面就来创建索引。
/**
*创建 mapping 索引
*/
private static void createSchemaIndex() {
String indexName = "my-index-000001";
// 获取客户端实例
RestHighLevelClient client = createClient();
try {
// 读取 classpath 下的 JSON 文件内容
String file = ClasspathResourceLoader.class.getResource("/mapping/myIndexMapping.json").getFile();
BufferedInputStream inputStream = new BufferedInputStream(new FileInputStream(file));
byte[] buffer = new byte[inputStream.available()];
inputStream.read(buffer);
String jsonMapping = new String(buffer);
// 创建索引请求
CreateIndexRequest request = new CreateIndexRequest(indexName);
// 设置 schema
request.source(jsonMapping, XContentType.JSON);
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
if (createIndexResponse.isAcknowledged()) {
System.out.println("成功创建索引:" + indexName);
} else {
System.out.println("创建索引失败");
}
} catch (IOException e){
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}4.2 添加数据
- 添加
question数据,代码如下:
/**
* 添加 question 数据
*/
private static void addData2Index(){
String indexName = "my-index-000001";
// 获取客户端实例
RestHighLevelClient client = createClient();
// 准备question测试数据
JSONObject question = new JSONObject();
question.put("my_id", "1");
question.put("text", "This is a question 001");
JSONObject join = new JSONObject();
join.put("name", "question");
question.put("my_join_field", join);
try {
IndexRequest request = new IndexRequest(indexName).id("1").source(question.toJSONString(), XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 打印插入结果
System.out.println(response.getResult().name());
}catch (IOException e){
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}- 添加
answer数据,代码如下:
/**
* 添加 answer 数据
*/
private static void addData2Index(){
String indexName = "my-index-000001";
// 获取客户端实例
RestHighLevelClient client = createClient();
// 准备question测试数据
JSONObject question = new JSONObject();
question.put("my_id", "3");
question.put("text", "This is an answer for question 001");
JSONObject join = new JSONObject();
join.put("name", "answer");
join.put("parent", "1");
question.put("my_join_field", join);
try {
IndexRequest request = new IndexRequest(indexName).id("3");
request.routing("1");
request.source(question.toJSONString(), XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 打印插入结果
System.out.println(response.getResult().name());
}catch (IOException e){
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}4.3 检索数据
/**
* 查询
*/
private static void searchIndex(){
String indexName = "my-index-000001";
// 获取客户端实例
RestHighLevelClient client = createClient();
try {
SearchRequest request = new SearchRequest(indexName);
SearchSourceBuilder builder = new SearchSourceBuilder();
// has_child 查询
//HasChildQueryBuilder hasChildQueryBuilder = JoinQueryBuilders.hasChildQuery("answer", QueryBuilders.matchAllQuery(), ScoreMode.None);
//builder.query(hasChildQueryBuilder);
// has_parent 查询
HasParentQueryBuilder hasParentQueryBuilder = JoinQueryBuilders.hasParentQuery("question", QueryBuilders.matchAllQuery(), false);
builder.query(hasParentQueryBuilder);
builder.from(0);
builder.size(10);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}catch (IOException e){
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}ElasticSearch如何实现近实时搜索,如何提效【面试题,面道既学到】
一、ElasticSearch数据写入方式
ElasticSearch 写入数据有好多种方式,HTTP REST API 、ES 客户端、Logstash、Beats、Bulk API、ES River插件 ,这么多种写入方式大致分为 单条写入 和 批量写入 两种,那不管是 单条发送 还是 批量写入,ElasticSearch 都是会先写入 Buffer(缓存) 中,然后再 Flush 和 Commit,最终写入到 磁盘 中,具体更新流程在下面 【如何实现近实时更新数据】细讲。
那如何能高效数据写入呢?
1.1 Bulk API
- 通过 Bulk API 进行批量写入,基于 Java 的 RestHighLevelClient 客户端进行批量写入实现可移步《BulkProcessor 实现批量添加数据》篇 阅。
1.2 Logstash
- 通过 Logstash 管道写入数据,什么是 Logstash 以及如何搭建可移步《Logstash部署与使用》篇 阅。
1.3 其他方式
其他方式等有应用到再做博客分享。
以上是常用的两种数据写入方式,集群方式看下面【ElasticSearch 集群写入流程】。
二、ElasticSearch 如何实现近实时搜索?

官网注释,基于 ElasticSearch 2.x 版本,有些内容可能过时,但是不影响我们学习底层思想。
2.1 近实时搜索(Near real-time search)?
当文档存储在 ElasticSearch 中时,文档就会被索引,并且在接近实时(1秒)内进行搜索,即 近实时搜索,也就是 动态更新索引,怎样在索引不变的前提下实现倒排索引的更新?
答案是 用更多的索引,通过增加新的补充索引进来,而不是直接重写整个倒排索引,每一个倒排索引都会被轮流查询到,然后对结果进行合并。
点击 【Near real-time search(近实时搜索)】了解更多,细细品味。
2.2 逐段搜索(Per-segment search)?
ElasticSearch 基于 Java 库的 Lucene 引入了逐段搜索的概念。每一段类似于方向索引,在 Lucene 中的 index(索引)意思是 几个段的集合加上一个提交点 ,提交之后会将一个新的段添加到提交点,然后清理缓冲区。
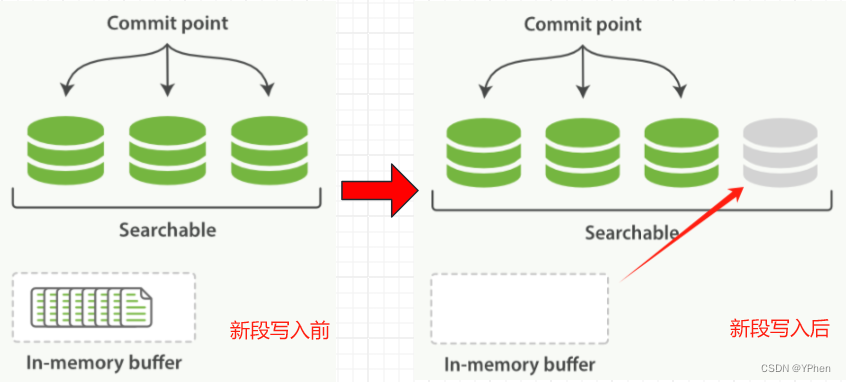
位于 ElasticSearch 和 磁盘之间是文件系统缓存,如上图,图左边是内存索引缓冲区被成功写入新段则如图右边。新段首先写入文件系统缓存性能很快,然后刷新到磁盘则比较消耗性能。不过呢,在缓冲区中的文件是可以其他文件一样打开和读取。
写入和打开新段的过程称为刷新,刷新使自上次刷新以来对索引执行的操作都可用户搜索,可以通过以下方式来控制刷新:
- 配置等待刷新间隔
- 设置 ?refresh 选项
- 调用刷新 API 显式完成刷新(POST _refresh)
默认情况下,ElasticSearch 每秒定时刷新一次索引,但限于过去 30 秒内收到一个或多个搜索请求的索引,这就是 ElasticSearch 近乎实时搜索,文档改变不会立即搜索,但是在一定时间范围内即可见。
2.3 持久化变更(Making Changes Persistent)
上面提到,ElasticSearch 实现了 近实时搜索,引入了逐段搜索的概念,每次有数据更新是先把数据存在了缓冲区中,是一个索引段,然后把索引段写入到提交点再刷到磁盘中,那如果没有用 fsync 把数据从文件系统缓冲区及时刷到磁盘中,就不能保证在出现异常【比如:断电、服务挂掉、运维 Kill -9】情况下甚至是程序正常退出之后不丢失数据,为了保证 ElasticSearch 能可靠的把变化数据持久化到磁盘,ElasticSearch增加了 translog, 或者叫 事务日志。
通过 translog 来更新数据整体流程如下:
- 一个文档索引写入之后,会先写入到内存缓冲区,并且还会追加到
Translog,如下图 。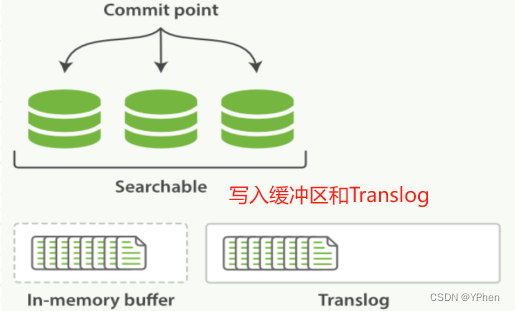
- 在刷新(
refresh)完成后,缓存会被清空,但是Translog会保留下来,继续添加文档,还是写入缓冲区中,再次追加到Translog中,如图所示 。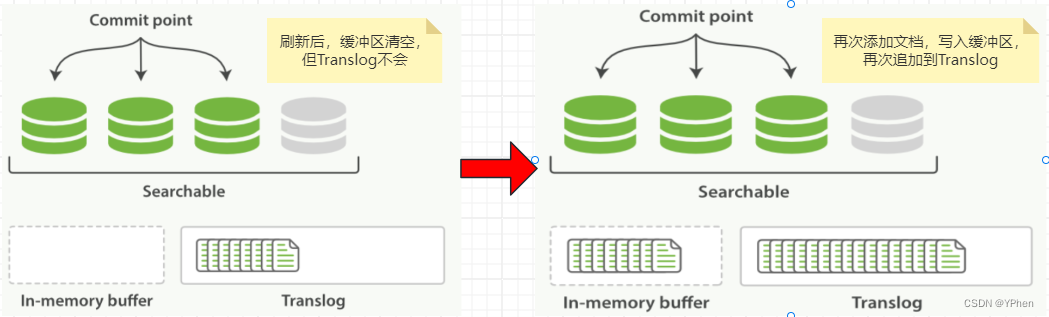
- 刷新(refresh)是从缓冲区(In-memory buffer)刷到一个新的索引段中,分片每秒被刷新一次,且没有
fsync操作 。- 这个段被打开,即可以被搜索 。
- 内存缓冲区被清空 , 但是 Translog 保留,以免异常情况出现。
- 在大刷(
flush)之后,索引段被全量提交,并且清空Translog【清空事务日志】。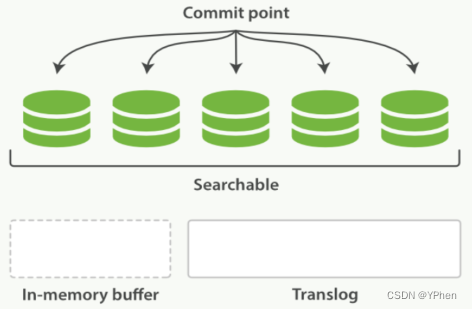
- 每隔一段时间,Translog 变得越来越大,索引被刷新,一个新的 Translog 创建,并且一个全量的提交被执行。
- 所有内存缓冲区的文档写入一个新的段 。
- 缓冲区被清空 。
- 一个提交点写入磁盘 。
- 文件系统缓存通过
fsync被刷新 。- 老的 Translog 被删除 。
Flush API :
在执行一个提交并且截断 Translog 的行为被称为 flush,每 30 分钟被自动刷新(flush),或者在 Translog 太大时也会被刷新,或者也可以 调用 Flush API 来刷新。
#刷新索引
POST /index_name/_flush
#刷新所有的索引并且等待所有的刷新在返回前完成
POST /_flush?wait_for_ongoing注意:基本上我们很少用手动刷新操作,通常情况下,自动刷新就足够了,除非写入数据量庞大并且写入频率不稳定。
点击 【Making Changes Persistent】了解更多,细细品味。
2.4 段合并(Segment Merging)
到这里,我们都知道了 ElasticSearch 的 近实时搜索 特性,那同时也会面临着一个问题,ElasticSearch 自动每秒会创建一个新的 段,那就会导致一段时间内会有产生大量的 段。每个段会消耗文件句柄、内存和CPU的运行周期,而且每次搜索都会轮流搜索每个段,所以段的暴增会使数据更新变慢,搜索变慢。
ElasticSearch 通过后台段合并 来解决由于短时间内段暴增而导致的性能问题,小的段合并成大的段,大的段再次合并为更大的段,段合并的同时会把那些旧的已删除的文档清除掉。
- 段合并 是 ElasticSearch 后台进行的,并不需要我们过多的去关注,在 ElasticSearch 进行索引和搜索时会自动进行,这个流程如图所示。
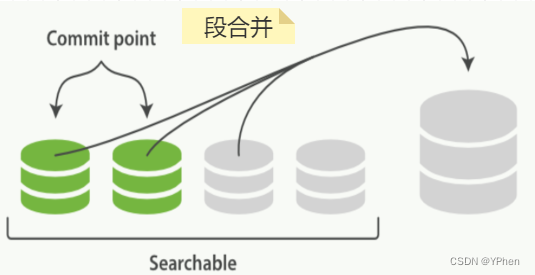
- 当索引的时候,刷新(refresh)操作会创建新的段并打开以提供搜索服务。
- 段合并会选择一些大小相似的段,在后台将小段们合并为一个大段,并且这并不会影响索引和搜索。
- 段删除 是在 段合并 完成之后进行的,一旦段合并结束,老的段就会被删除,看图理解。
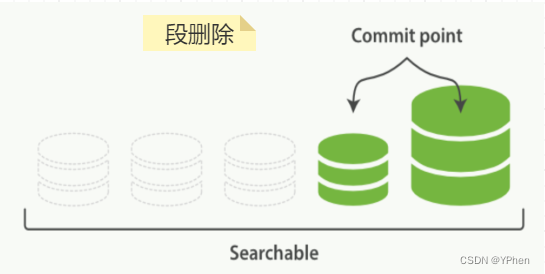
- 合并比较大的段会消耗大量的 IO、CPU 资源,如果频繁一直合并的话会影响搜索性能,所以 ElasticSearch 在默认情况下会对合并进行资源限制,以保证搜索有足够的资源。
三、ElasticSearch 集群写入流程
一般企业内数据实时要求比较高,并且数据量庞大,每小时近千万数据量进来,那单机版的ElasticSearch 肯定是难以支持的,必定是基于高效的集群模式的,下面是 ElasticSearch 官网提供的一张图,清晰明了。
3.1 集群副本
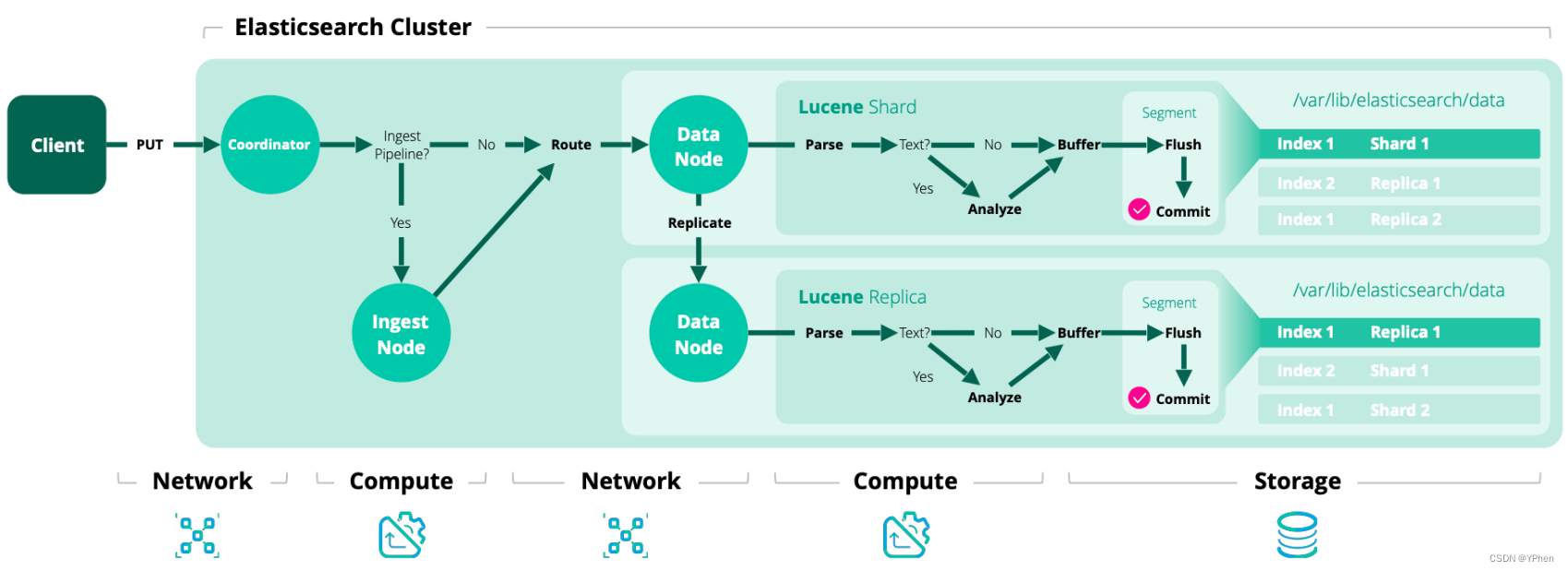
在 ElasticSearch 中每个索引都被划分为多个碎片,每个碎片可以有多个副本,这些副本称之为复制组,那么在添加删除文档则必须要保持同步,否则从一个副本中搜索的结果和从其他副本搜索的结果截然不同,保持副本同步并提供读取操作的过程称之为 数据副本模型 (Data replication model.)。
ElasticSearch 的数据复制模型是基于主备份(Primary-backup)模型,该模型基于复制组中作为主碎片的副本,其他副本称为副本碎片。主碎片是索引操作的入口,负责验证并且确保数据是正确的,一旦主碎片接受索引操作,则主碎片还要负责该操作复制到其他副本。
因为副本可以脱机,所以主副本(主节点)不需要将主副本复制到所有副本,那 ElasticSearch 维护了一个有效副本的列表,被保证已经处理了所有向用户确认的索引和删除操作。
3.2 副本复制流程
主节点的复制流程如下:
- 验证接收到的数据结构无效则拒接写入(Eg:schema不符合) 。
- 在本节点执行操作,即索引或者删除相关文档,也会验证字段和内容,并在需要时拒接写入(Eg:关键字值过长)。
- 把操作转发到当前可同步的每个副本中(多个副本并行操作)。
- 等所有副本成功执行了操作并响应了主节点,主节点才会确认操作成功并返回客户端结果。
注:每个副本也会在本地执行索引操作,也会有一个副本自己的副本。
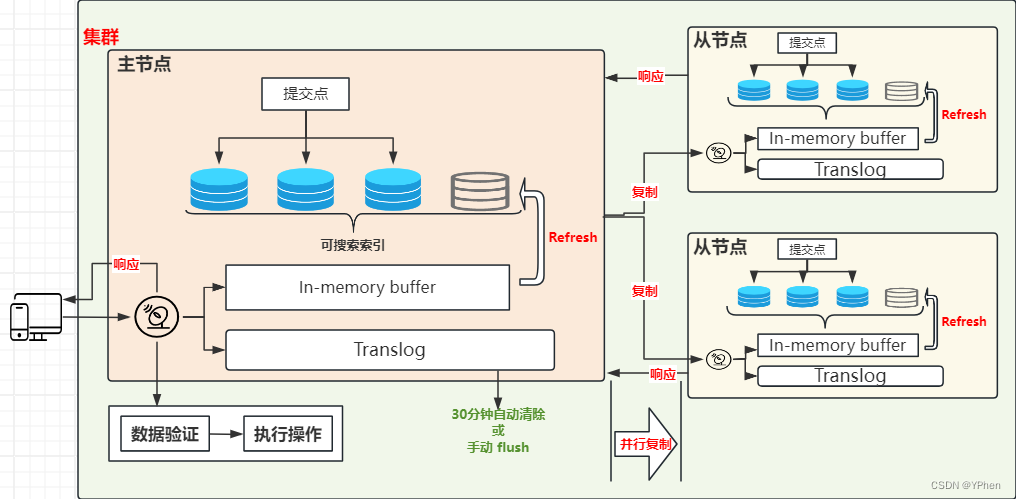
四、ElasticSearch 写入慢如何优化呢?
4.1 ChatGPT
- 调整 Bulk 请求大小:将大量写入操作合并成一个 Bulk 请求发送到 ElasticSearch。适当增加每个 Bulk 请求中的文档数量可以减少通信开销,提高写入效率,但是要注意不能将 Bulk 请求设置过大,以免超出 ElasticSearch 节点处理能力。
- 优化 Mapping:在大量数据写入之前,确保索引的 mapping 合理,避免使用动态 Mapping,这样可以减少 ElasticSearch 工作量。
- 考虑使用 Refresh Interval:默认情况下,ElasticSearch 在索引数据后会自动刷新,使新写入的数据可搜索。但是如果写入操作很频繁,可以考虑减少刷新操作,以提高写入性能。
- 考虑水平扩展:单个ElasticSearch 无法满足需求,可以考虑通过水平扩展集群来提高写入效率。
- 使用异步写入:考虑使用异步写入方式,将写入操作提交到队列中由后台线程处理。
- 关闭索引刷新:在批量写入之前,可以暂时关闭索引自动刷新功能,等数据批量写入之后再手动执行刷新操作。
4.2 Kimi 给我的答案
- 客户端策略
- 预定义索引映射(Mapping):预先定义好映射可避免 ElasticSearch 写入时动态推断字段类型,提高效率。
- Bulk API:批量操作减少网络开销。
- 并行化:水平扩展,将数据分布到多个工作进程中并行写入。
- 响应过滤:使用 filter_path 参数减少 ElasticSearch 返回响应体大小,减少网络传输时间。
- 保存前汇总:对于频繁更新的操作,可以先在内存中聚合再写入。
- 索引策略
- 调整 Refresh Interval:增加 refresh 间隔可以减少索引过程中的资源消耗,但可能会稍微影响搜索的实时性。
- 使用自动生成的 ID:让 Elasticsearch 自动生成 ID 可以避免检查唯一性,提高写入速度。
- 禁用副本:在批量索引作业期间禁用副本可以提高索引速度,之后再启用副本以保证数据的高可用性。
- 节点策略
- 调整 Indexing Buffer Size:根据需要调整索引缓冲区的大小,以优化内存使用。
- 优化 Translog:调整事务日志的大小,可以在磁盘上创建更大的段,减少刷新操作的频率。
- 操作系统和服务器策略
- 禁用交换(Swapping):确保 Elasticsearch 节点的内存足够,避免因为内存不足而触发交换,影响性能。
- 优化文件系统缓存:确保有足够的 RAM 用于文件系统缓存,以提高 I/O 性能。
- 选择合适的存储类型:使用 SSD 而不是传统的旋转磁盘,或者使用高性能的网络存储解决方案。
- 硬件升级
- 升级硬件:如果硬件性能成为瓶颈,考虑升级服务器硬件,如使用更快的 CPU、更多的 RAM 或 SSD。
- 集群架构
- 合理分配分片:确保分片均匀分布在集群中,避免某些节点负载过高。
- 使用合适的副本策略:根据需要调整副本数量,以平衡写入性能和数据的高可用性。
- 其他策略
- 监控和调优 JVM:确保 JVM 配置得当,避免长时间的 Full GC。
- 合理设计分词器:不合理的分词器设计可能会导致 CPU 计算过多和过度分词,影响写入性能。
五、小结
数据库排行:https://db-engines.com/en/ranking/search+engine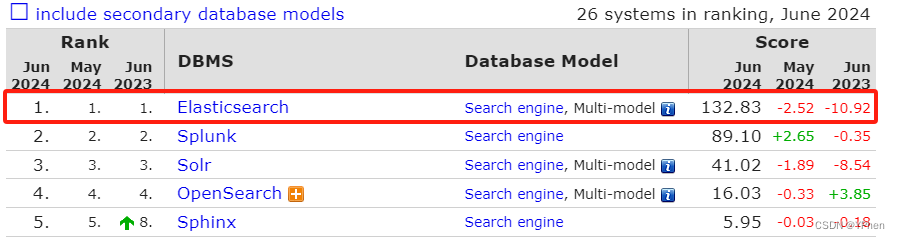
ElasticSearch 是目前最流行的、企业级搜索最多的全文搜索引擎,高效的全文检索和近实时的数据更新,这无疑成为企业级应用开发时首选的搜索引擎。在互联网发展如此迅速的时代,对从事 IT 行业的我们来说,不仅要掌握其使用方式,更要了解其核心思想以及如何优化,ElasticSearch 搜索是快,但是正对于互联网项目或者电商这种对高并发、高可用、高可扩展 的应用来说,单机版是很难维持的,必须使用集群方式来提高效率。
但是话说回来,每个项目都独有自己的业务场景和对服务的要求不同,所以我们必须要很清晰的了解其内部原理和根据不同的业务场景来针对性的优化,才能在其位上做到 及格。
参考文献
- ElasticSearch官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-replication.html
- ElasticSearch官方中文网:https://www.elastic.co/guide/cn/elasticsearch/guide/current/dynamic-indices.html
- DB-Engines Ranking:https://db-engines.com/en/ranking/search+engine
- 协助 AI:ChatGPT、Kimi

 浙公网安备 33010602011771号
浙公网安备 33010602011771号