线程池newScheduledThreadPool讲解,阿里规范问题
周期性线程池newScheduledThreadPool讲解_有梦想的king的博客-CSDN博客
//Timer和ScheduledThreadPoolExecutor的区别:
a.Timer是单线程运行,一旦任务执行缓慢,下一个任务就会推迟,而如果使用了ScheduledThreadPoolExecutor线程数可以自行控制
b.当Timer中的一个任务抛出异常时,会导致其他所有任务都不执行
c.ScheduledThreadPoolExecutor可以异步执行
ScheduledExecutorService接口继承了ExecutorService,在ExecutorService的基础上新增了以下几个方法:
①schedule方法:
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
command:执行的任务 Callable或Runnable接口实现类
delay:延时执行任务的时间
unit:时间单位
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
command:执行的任务 Callable或Runnable接口实现类
initialDelay:线程第一次执行任务延迟时间
period:两个连续线程之间的周期
unit:时间单位
③scheduleWithFixedDelay方法:
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
command:执行的任务 Callable或Runnable接口实现类
initialDelay:线程第一次执行任务延迟时间
period:两个连续线程之间的周期
unit:时间单位
案例:
package cn.itguanlin.threadpool.scheduledthreadpool;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import cn.itguanlin.threadpool.newCachedThreadPool.Task;
/*
* 案例: 演示周期性线程池newScheduledThreadPool
*/
public class ScheduledThreadPoolDemo {
public static void main(String[] args) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 定义一个newFixedThreadPool 里面的容量大小为5
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
//程序开始执行了,这是一个主方法,所以是主线程
System.out.println("程序开始时间:"+sdf.format(new Date()));
//这边new Task()是一个子线程
scheduledThreadPool.schedule(new Task(),5,TimeUnit.SECONDS);
// 执行1000次 从现在开始5s后开始执行
// for(int i=0;i<1000;i++) {
// scheduledThreadPool.schedule(new Task(),5,TimeUnit.SECONDS);
// }
//按照一定频率重复执行
// scheduledThreadPool.scheduleAtFixedRate(new Task(), 1, 3, TimeUnit.SECONDS);
System.out.println("程序结束时间:"+sdf.format(new Date()));
//最后执行结果是主线程先执行完,子线程才会执行
}
}
【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor 的方式。
说明: Executors返回的线程池对象的弊端如下:
(1)FixedThreadPool 和SingleThreadPool 运行的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM;
(2)CacheThreadPool 和ScheduledThreadPool 允许的创建线程数量为Integer.MAX_VALUE,可能 会创建大量的线程,从而导致OOM。
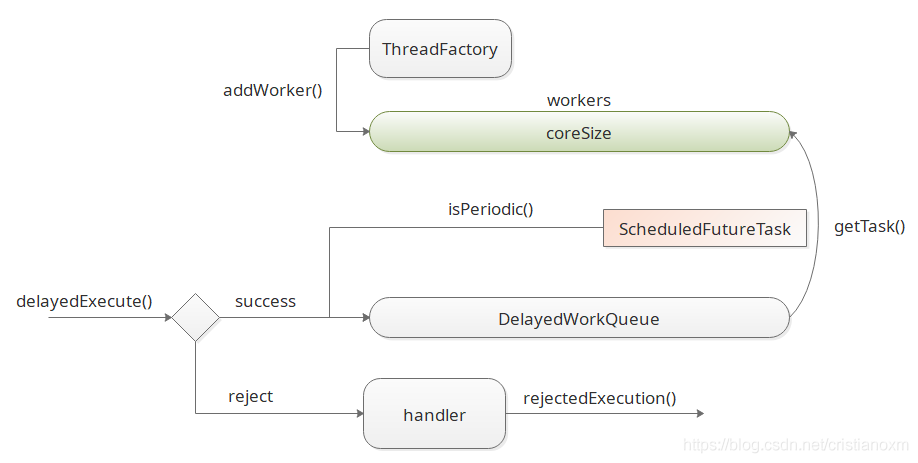
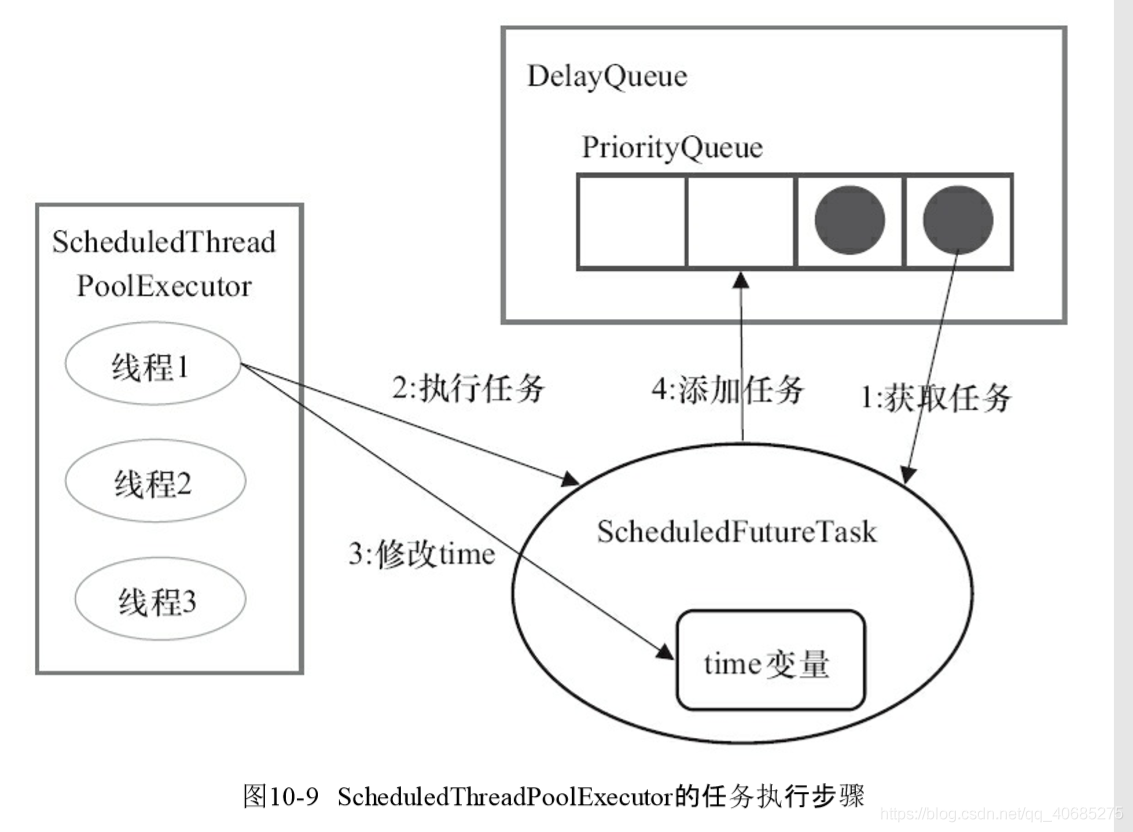
这个规范的错误是scheduledThreadPool 的最大线程数没有发挥作用。 从创建可调度线程的源码看最大线程数为什么没有发挥作用。
首先,我们来写一个创建scheduleThreadPool 的例子,测试代码如下:
/**
* 可调度线程
*/
@Test
public void testNewScheduledThreadPool(){
ScheduledExecutorService scheduledThreadPoolExecutor = Executors.newScheduledThreadPool(2);
for (int i=0;i<2;i++){
scheduledThreadPoolExecutor.scheduleAtFixedRate(new TargetTask(),0,500, TimeUnit.MILLISECONDS);
}
ThreadUtil.sleepSeconds(1000);
// 关闭线程池
scheduledThreadPoolExecutor.shutdown();
}测试代码可以看出,通过new方法创建一个可调度线程池, 然后scheduledThreadPoolExecutor.scheduleAtFixedRate(…)方法去提交任务,我们需要看的提交任务后源码具体做了什么,条任务的源码如下:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}从源码中可以看出,首先是把任务包装一下 RunnableScheduledFuture t = decorateTask(command, sft);然后调用延迟执行 delayedExecute(t);接着我们来看下延迟执行是如何完成,源码如下:
/**
* Main execution method for delayed or periodic tasks. If pool
* is shut down, rejects the task. Otherwise adds task to queue
* and starts a thread, if necessary, to run it. (We cannot
* prestart the thread to run the task because the task (probably)
* shouldn't be run yet.) If the pool is shut down while the task
* is being added, cancel and remove it if required by state and
* run-after-shutdown parameters.
*
* @param task the task
*/
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}首先我们来翻译一下延迟执行delayedExecute(…)的方法说明:
延迟或定时执行的主要执行方法,如果线程池已经关闭则拒绝任务,否则添加线程任务到队列并启动线程,在有需要时执行线程,(我们不能预先启动线程并执行线程,因为任务还不应该执行),当线程池关闭时,如果任务正在添加、取消或者移除的时候线程状态发生了变化就会先执行完后再关闭参数。
接下来我们再看看delayedExecute(…)的源码做了什么事,先把包装好的任务放到延迟队列中super.getQueue().add(task);,然后确保线程启动ensurePrestart();接着我们看下线程动ensurePrestart()的源码:
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}在线程启动ensurePrestart()中首先拿到当前的线程数,如果当前工作线程数小于核心线程数或者当前工作线程数等于0的时候则创建线程, 那么当前工作线程数大于核心线程数或者当前工作线程数也不等于0的话,什么也没有做,在此可以看出最大线程数根本没有发挥作用,最多也就是创建核心线程数的线程,当超过核心线程数时,不会像普通线程池继续创建线程,
接着我们来看下延迟队列如果空间不足时,是如何扩容的,扩容代码如下:
private void grow() {
int oldCapacity = queue.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // grow 50%
if (newCapacity < 0) // overflow
newCapacity = Integer.MAX_VALUE;
queue = Arrays.copyOf(queue, newCapacity);
}从代码中我们可以看出,每次增长的幅度是自己当前容量的50%;然后复制一下队列的数组内容 Arrays.copyOf(queue, newCapacity),这一步是相当耗性能的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号