性能优化高频面试题集锦
性能优化高频面试题集锦 [ 配套教程 ] (smartan123.github.io)
tomcat部分
一、tomcat有哪些配置项可以优化?
1、server.xml文件中禁用ajp协议(新版中默认是屏蔽的),减少不必要的线程开销
<!--<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />-->2、server.xml文件修改元素,使用线程池提高性能
<!‐‐将注释打开(注释没打开的情况下默认10个线程,最小10,最大200)‐‐>
<Executor name="tomcatThreadPool" namePrefix="catalina‐exec‐"
maxThreads="500" minSpareThreads="50"
prestartminSpareThreads="true" maxQueueSize="100"/>
<!‐‐
参数说明:
maxThreads:最大并发数,默认设置 200,一般建议在 500 ~ 1000,根据硬件设施和业
务来判断
minSpareThreads:Tomcat 初始化时创建的线程数,默认设置 25
prestartminSpareThreads: 在 Tomcat 初始化的时候就初始化 minSpareThreads 的
参数值,如果不等于 true,minSpareThreads 的值就没啥效果了
maxQueueSize,最大的等待队列数,超过则拒绝请求
‐‐>
<!‐‐在Connector中设置executor属性指向上面的执行器‐‐>
<Connector executor="tomcatThreadPool" port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />3、server.xml文件中修改连接器,可以使用NIO2通道提高性能
设置nio2:
<Connector executor="tomcatThreadPool" port="8080"
protocol="org.apache.coyote.http11.Http11Nio2Protocol"
connectionTimeout="20000"
redirectPort="8443" />二、tomcat堆栈中有哪些常见线程?分别有什么用途?
1、main线程
main线程是tomcat的主要线程,其主要作用是通过启动包来对容器进行点火:
main线程一路启动了Catalina,StandardServer[8005],StandardService[Catalina],StandardEngine[Catalina]
engine内部组件都是异步启动,engine这层才开始继承ContainerBase,engine会调用父类的startInternal()方法,里面由startStopExecutor线程提交FutureTask任务,异步启动子组件StandardHost,
StandardEngine[Catalina].StandardHost[localhost]
main->Catalina->StandardServer->StandardService->StandardEngine->StandardHost,黑体开始都是异步启动。
->启动Connector
main的作用就是把容器组件拉起来,然后阻塞在8005端口,等待关闭。
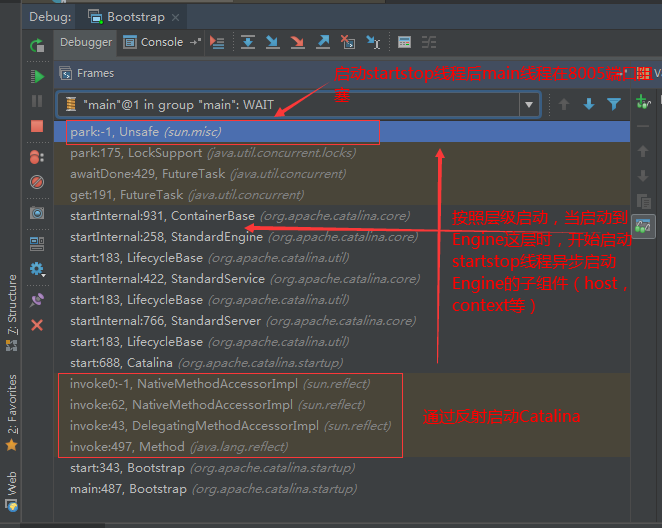
2、localhost-startStop线程
Tomcat容器被点火起来后,并不是傻傻的按照次序一步一步的启动,而是在engine组件中开始用该线程提交任务,按照层级进行异步启动,对于每一层级的组件都是采用startStop线程进行启动,我们观察一下idea中的线程堆栈就可以发现:启动异步,部署也是异步
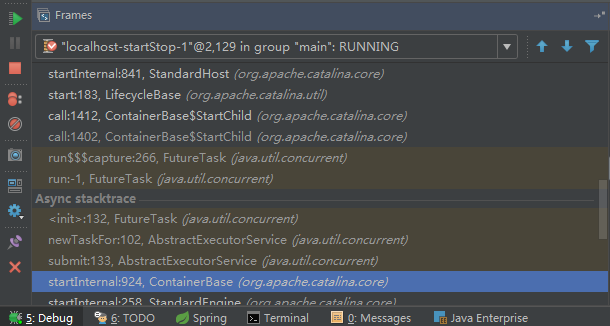
这个startstop线程实际代码调用就是采用的JDK自带线程池来做的,启动位置就是ContainerBase的组件父类的startInternal():
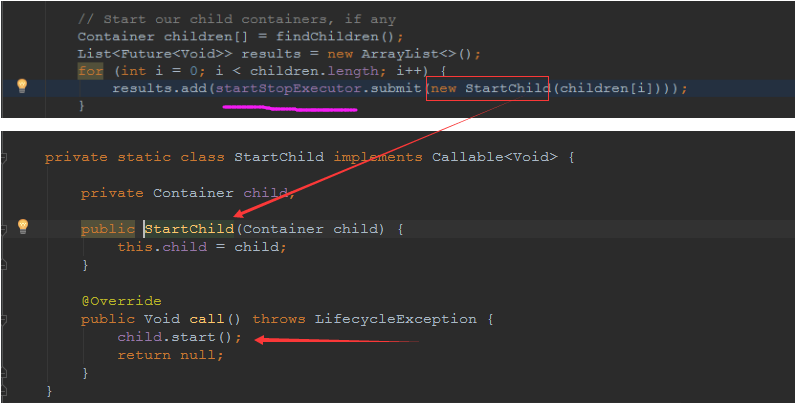
因为从Engine开始往下的容器组件都是继承这个ContainerBase,所以相当于每一个组件启动的时候,除了对自身的状态进行设置,都会启动startChild线程启动自己的孩子组件。
而这个线程仅仅就是在启动时,当组件启动完成后,那么该线程就退出了,生命周期仅仅限于此。
3、AsyncFileHandlerWriter线程
日志输出线程:
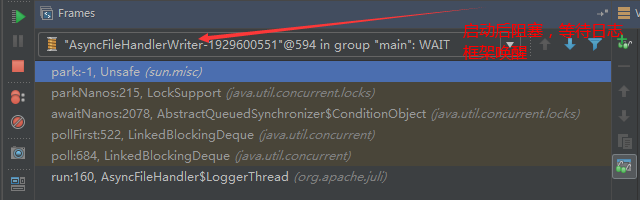
顾名思义,该线程是用于异步文件处理的,它的作用是在Tomcat级别构架出一个输出框架,然后不同的日志系统都可以对接这个框架,因为日志对于服务器来说,是非常重要的功能。
如下,就是juli的配置:

该线程主要的作用是通过一个LinkedBlockingDeque来与log系统对接,该线程启动的时候就有了,全生命周期。
4、ContainerBackgroundProcessor线程
Tomcat在启动之后,不能说是死水一潭,很多时候可能会对Tomcat后端的容器组件做一些变化,例如部署一个应用,相当于你就需要在对应的Standardhost加上一个StandardContext,也有可能在热部署开关开启的时候,对资源进行增删等操作,这样应用可能会重新reload。
也有可能在生产模式下,对class进行重新替换等等,这个时候就需要在Tomcat级别中有一个线程能实时扫描Tomcat容器的变化,这个就是ContainerbackgroundProcessor线程了:
(本地源码StandardContext类的5212行启动)
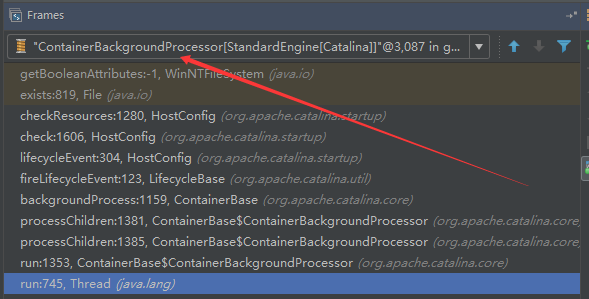
我们可以看到这个代码,也就是在ContainerBase中:
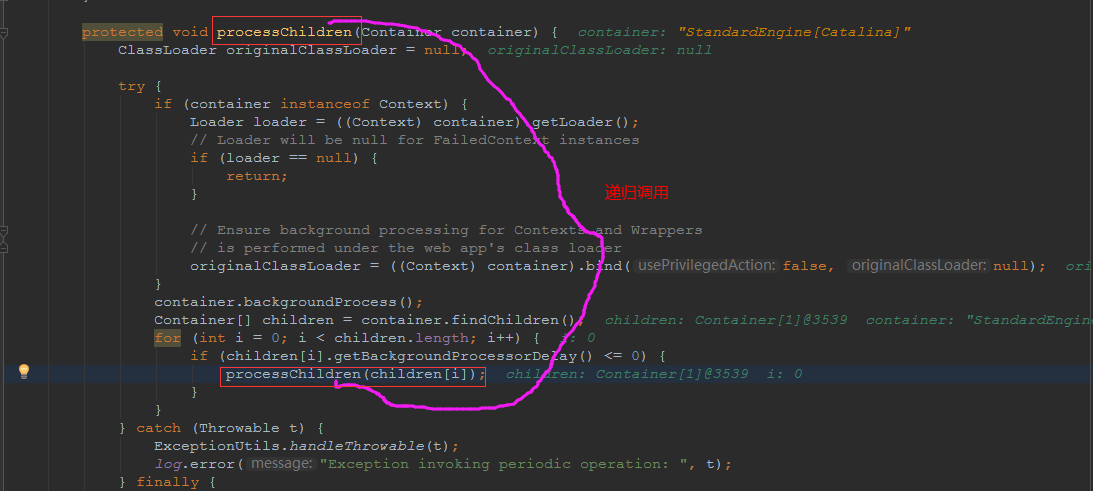
这个线程是一个递归调用,也就是说,每一个容器组件其实都有一个backgroundProcessor,而整个Tomcat就点起一个线程开启扫描,扫完儿子,再扫孙子(实际上来说,主要还是用于StandardContext这一级,可以看到StandardContext这一级:
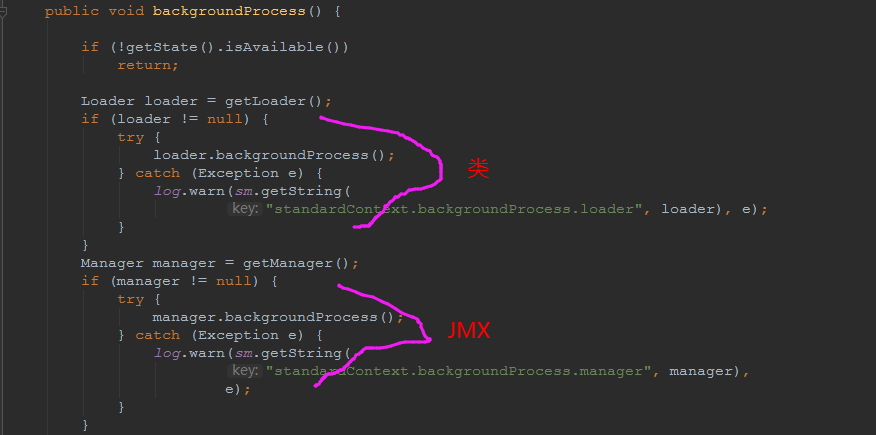
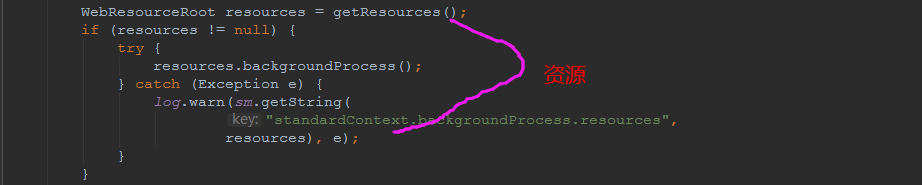
我们可以看到,每一次backgroundProcessor,都会对该应用进行一次全方位的扫描,这个时候,当你开启了热部署的开关,一旦class和资源发生变化,立刻就会reload。
tomcat9中已经被Catalina-Utility线程替代。
5、acceptor线程
Connector(实际是在AbstractProtocol类中)初始化和启动之时,启动了Endpoint,Endpoint就会启动poller线程和Acceptor线程。Acceptor底层就是ServerSocket.accept()。返回Socket之后丢给NioChannel处理,之后通道和poller线程绑定。
acceptor->poller->exec
无论是NIO还是BIO通道,都会有Acceptor线程,该线程就是进行socket接收的,它不会继续处理,如果是NIO的,无论是新接收的包还是继续发送的包,直接就会交给Poller,而BIO模式,Acceptor线程直接把活就给工作线程了:
如果不配置,Acceptor线程默认开始就开启1个,后期再随着压力增大而增长:
上述启动代码在AbstractNioEndpoint的startAcceptorThreads方法中。
6、ClientPoller线程
NIO和APR模式下的Tomcat前端,都会有Poller线程:
对于Poller线程实际就是继续接着Acceptor进行处理,展开Selector,然后遍历key,将后续的任务转交给工作线程(exec线程),起到的是一个缓冲,转接,和NIO事件遍历的作用,具体代码体现如下(NioEndpoint类):
上述的代码在NioEndpoint的startInternal中,默认开始开启2个Poller线程,后期再随着压力增大增长,可以在Connector中进行配置。
7、exe线程(默认10个)
也就是SocketProcessor线程,我们可以看到,上述几个线程都是定义在NioEndpoint内部线程类。NIO模式下,Poller线程将解析好的socket交给SocketProcessor处理,它主要是http协议分析,攒出Response和Request,然后调用Tomcat后端的容器:
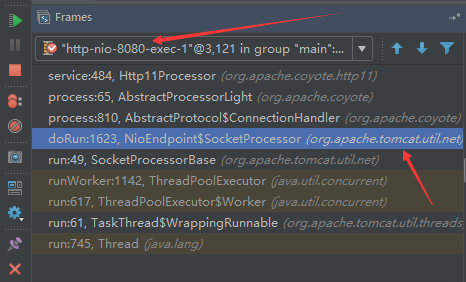
该线程的重要性不言而喻,Tomcat主要的时间都耗在这个线程上,所以我们可以看到Tomcat里面有很多的优化,配置,都是基于这个线程的,尽可能让这个线程减少阻塞,减少线程切换,甚至少创建,多利用。
下面就是NIO模式下创建的工作线程:
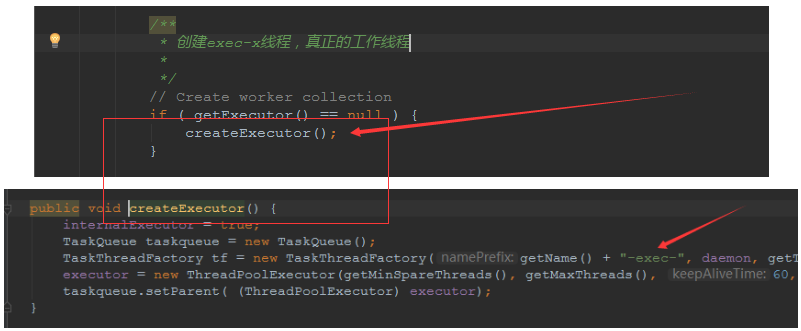
实际上也是JDK的线程池,只不过基于Tomcat的不同环境参数,对JDK线程池进行了定制化而已,本质上还是JDK的线程池。
8、NioBlockingSelector.BlockPoller(默认2个)
Nio方式的Servlet阻塞输入输出检测线程。实际就是在Endpoint初始化的时候启动selectorPool,selectorPool再启动selector,selector内部启动BlokerPoller线程。
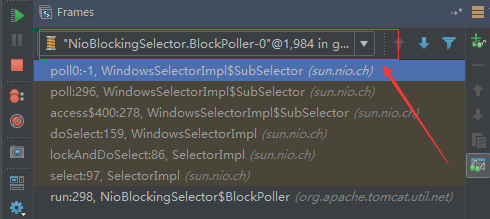
该线程在前面的NioBlockingPool中讲得很清楚了,其NIO通道的Servlet输入和输出最终都是通过NioBlockingPool来完成的,而NioBlockingPool又根据Tomcat的场景可以分成阻塞或者是非阻塞的,对于阻塞来讲,为了等待网络发出,需要启动一个线程实时监测网络socketChannel是否可以发出包,而如果不这么做的话,就需要使用一个while空转,这样会让工作线程一直损耗。
只要是阻塞模式,并且在Tomcat启动的时候,添加了—D参数 org.apache.tomcat.util.net.NioSelectorShared 的话,那么就会启动这个线程。
大体上启动顺序如下:
//bind方法在初始化就完成了
Endpoint.bind(){
//selector池子启动
selectorPool.open(){
//池子里面selector再启动
blockingSelector.open(getSharedSelector()){
//重点这句
poller = new BlockPoller();
poller.selector = sharedSelector;
poller.setDaemon(true);
poller.setName("NioBlockingSelector.BlockPoller-"+ (threadCounter.getAndIncrement()));
//这里启动
poller.start();
}
}
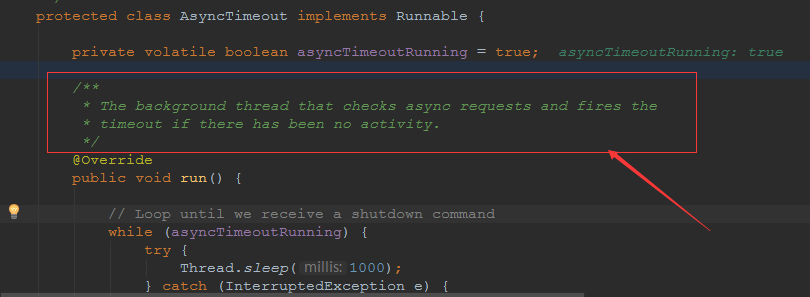
}9、AsyncTimeout线程
该线程为tomcat7及之后的版本才出现的,注释其实很清楚,该线程就是检测异步request请求时,触发超时,并将该请求再转发到工作线程池处理(也就是Endpoint处理)。
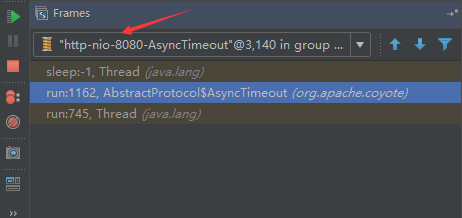
AsyncTimeout线程也是定义在AbstractProtocol内部的,在start()中启动。AbstractProtocol是个极其重要的类,他持有Endpoint和ConnectionHandler这两个tomcat前端非常重要的类
10、其他线程(例如ajp相关线程)
ajp工作线程处理的是ajp协议的相关请求,这个请求主要是用于http apache服务器和tomcat之间的数据交换,该数据交换用的就是ajp协议,和exec工作线程差不多,默认也是启动10个,端口号是8009。优化时如果没有用到http apache的话就可以把这个协议关掉。
Tomcat本身还有很多其它的线程,远远不止这些,例如如果开启了sendfile,那么对sendfile就是开启一个线程来进行操作,这种功能的线程开启还有很多。
Tomcat作为一款优秀的服务器,不可能就只有1个线程,而是多个线程之间相互配合完成功能,而且很多功能尽量异步处理,尽可能的减少线程切换。所以线程并不是越多越好,因此线程的控制也尤为关键。
三、Tomcat 的 bio 模式改为 nio 模式,是否能提高服务器的吞吐量?为什么在配置一样的情况下,两种模式压出来的吞吐量差不多?
这种情况主要就是要看是不是整个系统都异步化了,因为tomcat的nio只是将网络io异步化了,就是接收和读写异步化了,但是网络报文接受完后还是要交给业务线程池,如果你的业务是阻塞的或者较耗时的话是没办法提升整个系统的吞吐量的,除非将整个项目都异步化,现在压测cpu如果还没有打满的话就可以继续优化,但如果bio都能打满cpu就说明已经到物理极限了,只能在代码层去优化了。
四、对比nio,bio一开始能接收的量比nio大,什么原因?
bio接收请求是线程池里面的线程接收的,也就是说你的线程池如果设为600,就有600个线程能接收,自然就会满打满算,但是nio是只有cpu数个线程负责接收的(默认10个)。
五、nio的优势是什么?是不是 nio 模式下 tomcat 默认能保持10000条连接,而bio模式则达不到?
简单地说,nio模式最大化压榨了CPU,把时间片更好利用起来。通俗地说,bio hold住连接不干活也占用线程,nio hold住连接不干活也没关系,让需要处理的连接先执行就行了。
六、nio模式是不是更适合做tcp长连接,用少量线程hold住大量的连接,节省资源?但tomcat现在都是短连接,nio抗并发并没有比bio强吗?
nio适合大量长连接,而且大部分是只hold住但不处理的场景,如果你能将项目异步化的话nio肯定比bio扛得连接多。bio模式其实压测时是打不满CPU的,所以采用nio来压榨CPU,如果bio都能打满CPU,那就没必要设计nio 和异步化了,因为已经达到物理极限了,没有办法继续压榨了,只能去优化代码。
七、bio模式下将最大线程数不断调大,直到打满CPU,这种情况和nio异步比较,更倾向于哪一种?
bio模式达到峰值后会导致接收不了连接,操作系统层的连接队列满了则会拒绝连接。另外一个是,系统不可能开很多线程,bio开太多线程可能会直接卡死,线程切换花销很大,主要是要将阻塞的环节异步出来,这样线程就能高效干活了。nio模式还是比bio高效很多,因为bio模式光网络读写就可能阻塞很长时间了,而nio负责网络io的异步化,而其他步骤的异步化要自己另外考虑。
八、Tomcat中的NIO2通道是如何保证高性能的?
nio2通道是基于java AIO,采用的是proactor模式,是纯异步模式,这比NIO基于reacactor模式效率要高。所有的操作都是由操作系统回调异步完成。
九、研究过tomcat的NioEndpoint源码吗?请阐述下Reactor多线程模型在tomcat中的实现。
tomcat的底层网络NIO通信基于主从Reactor多线程模型。
它有三大线程组分别用于处理不同的逻辑:
Acceptor线程:等待和接收客户端连接。在接收到连接后,创建SocketChannel并将其注册到poller线程。 poller线程:将SocketChannel放到selector上注册读事件,轮询selector,获取就绪的SelectionKey,并将就绪的SelectionKey(或SocketChannel)委托给工作线程。 工作线程:执行真正的业务逻辑。 备注:Acceptor线程和poller线程之间有一个SocketChannel队列,Acceptor线程负责将SocketChannel推送到队列,poller线程负责从队列取出SocketChannel。poller线程从队列取出SocketChannel后,紧接着会把它放到selector上注册读事件。
主从Reactor多线程模型 主从Reactor线程模型的特点是:服务端用于接收客户端连接的不再是1个单独的NIO线程,而是一个独立的NIO线程池。Acceptor接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到IO线程池(sub reactor线程池)的某个IO线程上,由它负责SocketChannel的读写和编解码工作。Acceptor线程池仅仅只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的IO线程上,由IO线程负责后续的IO操作。
它的线程模型如下图所示:
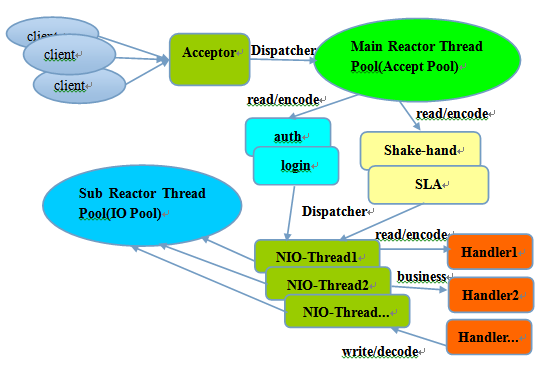
工作流程总结如下
从主线程池中随机选择一个Reactor线程作为Acceptor线程,用于绑定监听端口,接收客户端连接; Acceptor线程接收客户端连接请求之后创建新的SocketChannel,将其注册到主线程池的其它Reactor线程上,由其负责接入认证、IP黑白名单过滤、握手等操作; 步骤2完成之后,业务层的链路正式建立,将SocketChannel从主线程池的Reactor线程的多路复用器上摘除,重新注册到Sub线程池的线程上,用于处理I/O的读写操作。
mysql部分
一、SQL语句优化的总体原则有哪些?
- 优化更需要优化的SQL
- 定位优化对象的性能瓶颈
- 明确的优化目标
- 从Explain执行计划入手
- 多使用profile
- 永远用小结果集驱动大结果集
- 尽可能在索引中完成排序
- 只取出自己需要的列
- 仅仅使用最有效的过滤条件
- 尽可能避免复杂的Join和子查询
二、如何理解MySQL中加锁原理?
mysql加锁机制 :
根据类型可分为共享锁(SHARED LOCK)和排他锁(EXCLUSIVE LOCK)或者叫读锁(READ LOCK)和写锁(WRITE LOCK)。
根据粒度划分又分表锁和行锁。表锁由数据库服务器实现,行锁由存储引擎实现。
三、MySQL死锁形成的原因是什么?
争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去. 此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。 表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序。
四、请阐述建立索引的原则有哪些?
1、定义主键的数据列一定要建立索引。
2、定义有外键的数据列一定要建立索引。
3、对于经常查询的数据列最好建立索引。
4、对于需要在指定范围内的快速或频繁查询的数据列。
5、经常用在WHERE子句中的数据列。
6、经常出现在关键字order by、group by、distinct后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
7、对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8、对于定义为text、image和bit的数据类型的列不要建立索引。
9、对于经常存取的列避免建立索引。
10、限制表上的索引数目。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。
11、对复合索引,按照字段在查询条件中出现的频度建立索引。在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。
五、mysql性能调优主要是针对执行计划中的哪些属性进行优化?
主要关注type列,key列,extra列
type列依次性能从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引。一般来说,好的sql查询至少达到range级别,最好能达到ref。
key列正常情况要是非NULL,如果是NULL,表示没有用索引,性能低下。
extra列主要关注是不是用了临时表排序,索引等等。例如:using temporary,using filesort等都是需要优化的。
六、mysql中多表join的优化思路有哪些?
1、尽可能减少Join语句中的Nested Loop的循环总次数
如何减少Nested Loop的循环总次数?
最有效的办法只有一个,那就是让驱动表的结果集尽可能的小,永远用小结果集驱动大的结果集。为什么?因为驱动结果集越大,意味着需要循环的次数越多,也就是说在被驱动结果集上面所需要执行的查询检索次数会越多。比如,当两个表(表 A 和 表 B)Join的时候,如果表A通过WHERE条件过滤后有10条记录,而表B有20条记录。如果我们选择表A作为驱动表,也就是被驱动表的结果集为20,那么我们通过Join条件对被驱动表(表B)的比较过滤就会有10次。反之,如果我们选择表B作为驱动表,则需要有20次对表A的比较过滤。当然,此优化的前提条件是通过Join条件对各个表的每次访问的资源消耗差别不是太大。如果访问存在较大的差别的时候(一般都是因为索引的区别),我们就不能简单的通过结果集的大小来判断需要Join语句的驱动顺序,而是要通过比较循环次数和每次循环所需要的消耗的乘积的大小来得到如何驱动更优化。
2、优先优化Nested Loop的内层循环
这不仅仅是在数据库的Join中应该做的,实际上在我们优化程序语言的时候也有类似的优化原则。内层循环是循环中执行次数最多的,每次循环节约很小的资源,在整个循环中就能节约很大的资源。
3、保证Join语句中被驱动表上Join条件字段已经被索引
保证被驱动表上Join条件字段已经被索引的目的,正是针对上面两点的考虑,只有让被驱动表的Join条件字段被索引了,才能保证循环中每次查询都能够消耗较少的资源,这也正是优化内层循环的实际优化方法。
4、当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜Join Buffer的设置
当在某些特殊的环境中,我们的Join必须是All,Index,range或者是index_merge类型的时候, Join Buffer就会派上用场了。在这种情况下,Join Buffer的大小将对整个Join语句的消耗起到非常关键的作用。
七、请阐述order by语句的优化方案
利用索引实现数据排序的方法是MySQL中实现结果集排序的最佳做法。
因为这样可以完全避免因为排序计算所带来的资源消耗。所以,在我们优化sql语句中的ORDER BY的时候,尽可能利用已有的索引来避免实际的排序计算,可以很大幅度的提升ORDER BY操作的性能。在有些sql的优化过程中,即使为了避免实际的排序操作而调整索引字段的顺序,甚至是增加索引字段也是值得的。当然,在调整索 引之前,同时还需要评估调整该索引对其他sql所带来的影响,平衡整体得失。
八、group by语句实现的内部机制是什么?如何优化?
MySQL中,GROUP BY的实现有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成GROUP BY,另外一种为完全无法使用索引的场景下使用。
1、用松散(Loose)索引扫描实现GROUP BY 当MySQL完全利用索引扫描来实现GROUP BY的时候,并不需要扫描所有满足条件的索引键即可完成操作得出结果
什么松散索引扫描的效率会很高? 因为在没有WHERE子句,也就是必须经过全索引扫描的时候,松散索引扫描需要读取的键值数量与分组的组数量一样多,也就是说比实际存在的键值数目要少很多。而在WHERE子句包含范围判断式或者等值表达式的时候,松散索引扫描查找满足范围条件的每个组的第1个关键字,并且再次读取尽可能最少数量的关键字。
2、用紧凑(Tight)索引扫描实现GROUP BY 紧凑索引扫描实现GROUP BY和松散索引扫描的区别主要在于他需要在扫描索引的时候,读取所有满足条件的索引键,然后再根据读取的数据来完成GROUP BY操作得到相应结果。
3、用临时表实现 GROUP BY 前面两种GROUP BY的实现方式都是在有可以利用的索引的时候使用的,当MySQL Query Optimizer无法找到合适的索引可以利用的时候,就不得不先读取需要的数据,然后通过临时表来完成GROUP BY操作。
九、索引的弊端有哪些?
针对增、删、改比较频繁的操作列上,索引会带来额外的开销(索引裂变重排等操作)。
假设我们在Table ta中的Column ca列创建了索引idx_ta_ca,那么任何更新Column ca的操作,MySQL都需要在更新表中Column ca的同时,也更新Column ca的索引数据,调整因为更新所带来键值变化后的索引信息。而如果我们没有对Column ca进行索引的话,MySQL所需要做的仅仅只是更新表中Column ca的信息。这样,所带来的最明显的资源消耗就是增加了更新所带来的IO量和调整索引所致的计算量。此外,Column ca的索引idx_ta_ca是需要占用存储空间的,而且随着Table ta数据量的增长,idx_ta_ca所占用的空间也会不断增长。所以索引还会带来存储空间资源消耗的增长。
netty部分
一、请阐述Netty的执行流程。
1、创建ServerBootStrap实例
2、设置并绑定Reactor线程池:EventLoopGroup,EventLoop就是处理所有注册到本线程的Selector上面的Channel
3、设置并绑定服务端的channel
4、创建处理网络事件的ChannelPipeline和handler,网络时间以流的形式在其中流转,handler完成多数的功能定制:比如编解码 SSl安全认证
5、绑定并启动监听端口
6、当轮询到准备就绪的channel后,由Reactor线程:NioEventLoop执行pipline中的方法,最终调度并执行channelHandler
二、Netty高性能体现在哪些方面?
1、传输:IO模型在很大程度上决定了框架的性能,相比于bio,netty建议采用异步通信模式,因为nio一个线程可以并发处理N个客户端连接和读写操作,这从根本上解决了传统同步阻塞IO一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。正如源码中所示,使用的是NioEventLoopGroup和NioSocketChannel来提升传输效率。
2、协议:采用什么样的通信协议,对系统的性能极其重要,netty默认提供了对Google Protobuf的支持,也可以通过扩展Netty的编解码接口,用户可以实现其它的高性能序列化框架。
3、线程:netty使用了Reactor线程模型,但Reactor细分模型的不同,对性能的影响也非常大,下面介绍常用的Reactor线程模型有三种,分别如下:
- Reactor单线程模型:单线程模型的线程即作为NIO服务端接收客户端的TCP连接,又作为NIO客户端向服务端发起TCP连接,即读取通信对端的请求或者应答消息,又向通信对端发送消息请求或者应答消息。理论上一个线程可以独立处理所有IO相关的操作,但一个NIO线程同时处理成百上千的链路,性能上无法支撑,即便NIO线程的CPU负荷达到100%,也无法满足海量消息的编码、解码、读取和发送,又因为当NIO线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO线程的负载,最终会导致大量消息积压和处理超时,NIO线程会成为系统的性能瓶颈。
- Reactor多线程模型:有专门一个NIO线程用于监听服务端,接收客户端的TCP连接请求;网络IO操作(读写)由一个NIO线程池负责,线程池可以采用标准的JDK线程池实现。但百万客户端并发连接时,一个nio线程用来监听和接受明显不够,因此有了主从多线程模型。
- 主从Reactor多线程模型:利用主从NIO线程模型,可以解决1个服务端监听线程无法有效处理所有客户端连接的性能不足问题,即把监听服务端,接收客户端的TCP连接请求分给一个线程池。因此,在代码中可以看到,我们在server端选择的就是这种方式,并且也推荐使用该线程模型。在启动类中创建不同的EventLoopGroup实例并通过适当的参数配置,就可以支持上述三种Reactor线程模型。
三、Netty的零拷贝体现在哪里,与操作系统上的有什么区别?
Zero-copy就是在操作数据时, 不需要将数据buffer从一个内存区域拷贝到另一个内存区域。 少了一次内存的拷贝,CPU的效率就得到的提升。在OS层面上的Zero-copy 通常指避免在 用户态(User-space)与内核态(Kernel-space)之间来回拷贝数据。Netty的Zero-copy完全是在用户态(Java 层面)的, 更多的偏向于优化数据操作。
- Netty的接收和发送ByteBuffer采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty提供了组合Buffer对象,可以聚合多个ByteBuffer对象,用户可以像操作一个Buffer那样方便的对组合Buffer进行操作,避免了传统通过内存拷贝的方式将几个小Buffer合并成一个大的Buffer。
- Netty的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题。
四、原生的NIO存在Epoll bug、Netty是怎么解决的?
Java NIO Epoll会导致Selector空轮询,最终导致CPU100% 。
Netty对Selector的select 操作周期进行统计,每完成一次空的select操作进行一次计数,若在某个周期内连续发生 N次空轮询,则判断触发了Epoll死循环Bug 。
五、Netty自己实现的ByteBuf有什么优点?
1、它可以被用户自定义的缓冲区类型扩展
2、通过内置的符合缓冲区类型实现了透明的零拷贝
3、读和写使用了不同的索引
4、支持方法的链式调用
5、支持池化
六、Netty为什么要实现内存管理?
1、频繁分配、释放buffer时减少了GC压力。
2、在初始化新buffer时减少内存带宽消耗( 初始化时不可避免的要给buffer数组赋初始值 )。
3、及时的释放direct buffer。
七、TCP粘包/拆包的产生原因,应该这么解决?
TCP 是以流的方式来处理数据,所以会导致粘包/拆包 拆包:一个完整的包可能会被TCP拆分成多个包进行发送。 粘包:也可能把小的封装成一个大的数据包发送。
Netty中提供了多个Decoder解析类用于解决上述问题 FixedLengthFrameDecoder 、LengthFieldBasedFrameDecoder ,固定长度是消息头指定消息长度的一种形式,进行粘包拆包处理的。 LineBasedFrameDecoder 、DelimiterBasedFrameDecoder ,换行是于指定消息边界方式的一种形式,进行消息粘包拆包处理的。
八、netty业务handler中channelread方法造成内存泄漏的原因是什么?
如果业务handler继承的是ChannelInboundHandlerAdapter,那么在调用完channelRead方法之后,netty不会主动释放内存,必须进行手工释放。
九、netty并行执行优化策略有哪些?分别用在什么场景中?
1、使用netty提供的EventExecutorGroup线程组
如果客户端的并发连接数channel多,且每个客户端channel的业务请求阻塞不多,那么使用EventExecutorGroup
2、使用jdk提供的线程组ExecutorService
如果客户端并发连接数channel不多,但是客户端channel的业务请求阻塞较多(复杂业务处理和数据库处理),那么使用ExecutorService
JVM部分
一、Java会存在内存泄漏吗?请简单描述
内存泄漏是指不再被使用的对象或者变量一直被占据在内存中。理论上来说,Java是有GC垃圾回收机制的,也就是说,不再被使用的对象,会被GC自动回收掉,自动从内存中清除。
但是,即使这样,Java也还是存在着内存泄漏的情况,java导致内存泄露的原因很明确:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景。
二、请解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用JVM中的栈空间;
而通过new关键字和构造器创建的对象则放在堆空间,堆是垃圾收集器管理的主要区域,由于现在的垃圾收集器都采用分代收集算法,所以堆空间还可以细分为新生代和老生代,再具体一点可以分为Eden、Survivor(又可分为From Survivor和To Survivor)、Tenured;
方法区和堆都是各个线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量、JIT编译器编译后的代码等数据;
程序中的字面量(literal)如直接书写的100、”hello”和常量都是放在常量池中,常量池是方法区的一部分。
栈空间操作起来最快但是栈很小,通常大量的对象都是放在堆空间,栈和堆的大小都可以通过JVM的启动参数来进行调整,栈空间用光了会引发StackOverflowError,而堆和常量池空间不足则会引发OutOfMemoryError。
String str = new String("hello");上面的语句中变量str放在栈上,用new创建出来的字符串对象放在堆上,而”hello”这个字面量是放在方法区的。
补充1:较新版本的Java(从Java 6的某个更新开始)中,由于JIT编译器的发展和”逃逸分析”技术的逐渐成熟,栈上分配、标量替换等优化技术使得对象一定分配在堆上这件事情已经变得不那么绝对了。
补充2:运行时常量池相当于Class文件常量池具有动态性,Java语言并不要求常量一定只有编译期间才能产生,运行期间也可以将新的常量放入池中,String类的intern()方法就是这样的。 看看下面代码的执行结果是什么并且比较一下Java 7以前和以后的运行结果是否一致。
String s1 = new StringBuilder("go").append("od").toString();
System.out.println(s1.intern() == s1);
String s2 = new StringBuilder("ja").append("va").toString();
System.out.println(s2.intern() == s2);三、请解释StackOverflowError和OutOfMemeryError的区别?
StackOverflowError栈溢出,一般由于递归过多,调用方法过多导致。
OutOfMemeryError堆内存溢出,即OOM,由于堆内存中没有被GC回收的对象过多导致。
出现OOM的原因:
1、Java虚拟机的堆内存设置不够,可以通过参数-Xms和-Xmx来调优
2、程序中创建了大量对象,并且长时间不能被被垃圾回收器回收(存在引用)
四、JVM的引用类型有哪些?
强引用:当内存不足的时候,JVM宁可出现OutOfMemoryError错误停止,也需要进行保存,并且不会将此空间回收。在引用期间和栈有联系就无法被回收
软引用:当内存不足的时候,进行对象的回收处理,往往用于高速缓存中;mybatis就是
弱引用:不管内存是否紧张,只要有垃圾了就立即回收
幽灵引用:和没有引用是一样的
五、JVM的常用的涉及内存调优的参数有哪些?
两个
-Xms:堆内存初始化大小,一般默认为物理内存的六十四分之一
-Xmx:堆内存最大分配空间,一般默认为物理内存的四分之一
在内存泄漏问题排查时,采取主动内存调试法,往下调整内存大小,尽快让问题复现
六、什么是类的加载?
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
七、描述一下JVM加载class文件的原理机制?
JVM中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java中的类加载器是一个重要的Java运行时系统组件,它负责在运行时查找和装入类文件中的类。
由于Java的跨平台性,经过编译的Java源程序并不是一个可执行程序,而是一个或多个类文件。当Java程序需要使用某个类时,JVM会确保这个类已经被加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。
最后JVM对类进行初始化,包括:
- 如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类。
- 如果类中存在初始化语句,就依次执行这些初始化语句。
类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展加载器(Extension)、系统加载器(System)和用户自定义类加载器(java.lang.ClassLoader的子类)。
从Java 2(JDK 1.2)开始,类加载过程采取了父亲委托机制(PDM)。PDM更好的保证了Java平台的安全性,在该机制中,JVM自带的Bootstrap是根加载器,其他的加载器都有且仅有一个父类加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子类加载器自行加载。JVM不会向Java程序提供对Bootstrap的引用。下面是关于几个类加载器的说明:
- Bootstrap:一般用本地代码实现,负责加载JVM基础核心类库(rt.jar)。
- Extension:从java.ext.dirs系统属性所指定的目录中加载类库,它的父加载器是Bootstrap。
- System:又叫应用类加载器,其父类是Extension。它是应用最广泛的类加载器。它从环境变量classpath或者系统属性java.class.path所指定的目录中记载类,是用户自定义加载器的默认父加载器。
八、jvm是如何实现多线程的?
线程是比进程更轻量级的调度执行单位。线程可以把一个进程的资源分配和执行调度分开。一个进程里可以启动多条线程,各个线程可共享该进程的资源(内存地址,文件IO等),又可以独立调度。线程是CPU调度的基本单位。
主流OS都提供线程实现。Java语言提供对线程操作的同一API,每个已经执行start(),且还未结束的java.lang.Thread类的实例,代表了一个线程。
Thread类的关键方法,都声明为Native。这意味着这个方法无法或没有使用平台无关的手段来实现,也可能是为了执行效率。
程序计数器是一个线程隔离的数据区,说白了就是每一个线程都会单独开辟一块内存区域给程序计数器,并且线程之间这块内存区域是隔离的,是安全的。
这块内存区域会非常小,但是却非常关键,他的主要作用是存储一段字节码,这段字节码记录的是当前线程下一条需要执行的字节码地址。简单点说就是,记录着一个位置,这个位置就是当前线程下一次需要执行的代码位置。
然而对于一个单核cpu来说,只能同时执行一条指令,但是如何实现多线程的呢?
这时候程序计数器就会起到决定作用了。
java虚拟机的多线程是通过线程轮流切换分配处理执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条程序中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器,各条线程之间计数器互不影响,独立存储。
简单点说,对于单核处理器,是通过快速切换线程执行指令来达到多线程的,真正处理器就能同时处理一条指令,只是这种切换速度很快,我们根本不会感知到。
九、jvm中常见调优参数有哪些?请举例说明。
-Xms2g:初始化推大小为 2g;
-Xmx2g:堆最大内存为 2g;
-XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2; –XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。
垃圾回收部分
一、如何判断一个对象应该被回收?
1.该对象没有与GC Roots相连
2.该对象没有重写finalize()方法或finalize()已经被执行过则直接回收(第一次标记)、否则将对象加入到F-Queue队列中(优先级很低的队列)在这里finalize()方法被执行,之后进行第二次标记,如果对象仍然应该被GC则GC,否则移除队列。 (在finalize方法中,对象很可能和其他 GC Roots中的某一个对象建立了关联,finalize方法只会被调用一次,且不推荐使用finalize方法)
二、垃圾收集算法有哪些?
GC最基础的算法有三种: 标记 -清除算法、复制算法、标记-压缩算法,我们常用的垃圾回收器一般都采用分代收集算法。
- 标记 -清除算法,“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
- 复制算法,“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
- 标记-压缩算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
- 分代收集算法,“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
三、常用的垃圾回收器有哪些?
1、Serial收集器:串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。
2、ParNew收集器:ParNew收集器其实就是Serial收集器的多线程版本。
3、Parallel收集器:Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。
4、Parallel Old收集器:Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。
5、CMS收集器:CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
6、G1收集器:G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器,以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征。
四、方法区不在堆内,会被垃圾回收吗?
在jdk1.7中,方法区在永久代,而永久代本身就是垃圾回收概念下的产物,full gc时就会对方法区回收。
到了jdk1.8,虽然永久代被取消,但是新增了MaxMetaspaceSize参数,对于将死的类及类加载器的垃圾回收将在元数据使用达到“MaxMetaspaceSize”参数的设定值时进行。
所以,方法区会被回收。
五、什么叫OopMap?
在HotSpot中,虚拟机把对象内的什么偏移量上是什么类型的数据的信息存在到一个叫做“OopMap”的数据结构中。这样在计算引用链时直接查OopMap即可,不用到整个内存中去挨个找了,由此提高了分析速度。
六、简单说一下java的垃圾回收机制?
java采用分代回收,分为年轻代、老年代、永久代。
年轻代又分为E区、S1区、S2区。到jdk1.8,永久代被元空间取代了。
年轻代都使用复制算法,老年代的收集算法看具体用什么收集器。
默认是PS收集器,采用标记-整理算法。
七、如果对象的引用被置为 null,垃圾收集器是否会立即释放对象占用的内存?
不会。
对象回收需要一个过程,这个过程中对象还能复活。而且垃圾回收具有不确定性,指不定什么时候开始回收。
八、为什么要使用分代回收机制?
因为没有一种算法能适用所有场合。在对象存活率低的场景下,复制算法最合适。 对象存活率高时,标记清除或者标记整理算法最合适。 所以才需要分代来处理。
九、系统为什么会频繁的full gc?
full gc过于频繁有可能会造成oom,有可能不会。
full gc触发原因有很多种,但归根到底都是因为内存空间不足了(system.gc的情况不考虑)。
系统在频繁的full gc,但并没有出现oom,说明每次回收的时候,肯定清理了部分内存空间。那这里就有2种情况,gc之后清理的内存空间大不大?
1、如果每次gc之后剩余的空间不大,说明有一部分顽固对象一直没法被回收,导致可用内存变少。这种情况下很容易后续出现oom,比如说一次大对象的申请
2、如果每次gc之后剩余的空间比较大,意味着大部分对象都被清理了,但是系统又在频繁的full gc,说明很快老年代又会涌入大量对象。这个时候就应该检查下jvm的参数配置,很有可能是新生代设置的太小了,导致很多应该在minor gc阶段就清理出去的对象留到了老年代,这种可能性是最大的
新生代可以分为eden、survivor0、survivor1,正常的对象分配都是在eden完成的,如果eden空间不够了,会触发一次minor gc,存活的对象放在s0或s1中。随着每次minor gc,存活的对象会不断的从s0迁到s1,再从s1迁到s0,这个过程经过几次之后,如果对象还是存活的,就会晋升到老年代。
但如果新生代大小设置的太小,就会导致非常频繁的minor gc,s0->s1来回切换的速度加快,导致本身应该在minor gc就清理出去的对象跑到了老年代。
举个例子,正常情况下如果minor gc是1分钟一次,-XX:MaxTenuringThreshold默认配置是15的话,正常的小对象最长可以在新生代待15分钟左右,如果一个对象o的存活时间是5分钟,那它就可以在minor gc的时候被清理出去;但如果新生代设置过小,minor gc的频率降到10秒一次,那么o只能在新生代待150秒左右,然后就会晋升到老年代,这种对象一多,就会导致频繁的full gc。
nginx部分
一、fastcgi 与 cgi 的区别?
cgi
web服务器会根据请求的内容,然后会fork一个新进程来运行外部c程序(或perl脚本), 这个进程会把处理完的数据返回给web服务器,最后web服务器把内容发送给用户,刚才fork的进程也随之退出。如果下次用户还请求改动态脚本,那么web服务器又再次fork一个新进程,周而复始的进行。
fastcgi
web服务器收到一个请求时,他不会重新fork一个进程(因为这个进程在 web 服务器启动时就开启了,而且不会退出),web服务器直接把内容传递给这个进程(进程间通信,但fastcgi使用了别的方式,tcp方式通信),这个进程收到请求后进行处理,把结果返回给web服务器,最后自己接着等待下一个请求的到来,而不是退出。
所以区别就是是否重复 fork 进程,处理请求。
二、请列举Nginx和Apache之间的不同点
1、轻量级,同样起web服务,Nginx比Apach占用更少的内存及资源。 2、抗并发,Nginx处理请求是异步非阻塞的,而Apache则是阻塞型的,在高并发下Nginx能保持低资源低消耗高性能。 3、最核心的区别在于Apache是同步多进程模型,一个连接对应一个进程;Nginx是异步的,多个连接(万级别)可以对应一个进程。 4、Nginx高度模块化的设计,编写模块相对简单。
三、nginx 如何做到高性能和高扩展的?
nginx在web性能上的表现尤为出众,这完全得益于其设计方式,许多web和应用服务器都是基于线程或进程这种简单的架构,nginx用了一种精妙的事件驱动架构,在现代的硬件上,它可以处理成千上万的并发连接。他的线程模型和tomcat,netty,redis等如出一辙,都是基于事件驱动的异步非阻塞模式。
四、nginx如何开启gzip实现优化?
如下配置,开启Gzip压缩优化
server {
location / {
gzip on;
gzip_min_length 1k;
gzip_buffers 16 64k;
gzip_http_version 1.1;
gzip_comp_level 9;
gzip_types text/plain text/javascript application/javascript image/jpeg image/gif image/png application/font-woff application/x-javascript text/css application/xml;
gzip_vary on;
root html/subCharge;
index index.html index.htm;
}
*********
}五、nginx如何开启expires缓存实现优化?
在客户端缓存文件可以在很大程度上减轻服务器端的压力,试想如果每次请求都从服务器上获取资源,将浪费很多流量,因此我们要在客户端缓存文件。
那么,我们应该缓存什么样的文件呢?
- 图片文件,图片文件一般相对文本文件来说都比较大,且一般不会修改。
- css、js文件,这些文件能够独立为一个文件,相对改动的场合也较少。
- 静态html文件,不经常改动的静态html文件也可以做为缓存对象。
缓存文件有什么缺点吗?
任何功能不可能是完美的,有优点必然也有缺点,缓存的缺点就是万一要修改缓存的文件,如果还用原来的文件名,则客户端不会重新获取服务器上的资源,看到的仍然是本地缓存的东西,因此,当要修改缓存的对象时,最好能把文件名改掉,这样客户端才会获取新的资源并且重新缓存文件。
nginx配置缓存
location ~ .*\.(png|jpeg|jpg|gif|ico)$ {
expires 30d;
}六、nginx如何开启FastCGI参数实现优化?
fastcgi配置优化如下:
fastcgi_connect_timeout 600;
fastcgi_send_timeout 600;
fastcgi_read_timeout 600;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
fastcgi_temp_path /usr/local/nginx1.10/nginx_tmp;
fastcgi_intercept_errors on;
fastcgi_cache_path /usr/local/nginx1.10/fastcgi_cache levels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g;fastcgi_connect_timeout:指定连接到后端FastCGI的超时时间,如:600 fastcgi_send_timeout:向FastCGI传送请求的超时时间,如:600 fastcgi_read_timeout:指定接收FastCGI应答的超时时间,如:600 fastcgi_buffer_size:指定读取FastCGI应答第一部分需要用多大的缓冲区,默认的缓冲区大小为fastcgi_buffers指令中的每块大小,可以将这个值设置更小,如: 64k。 fastcgi_buffers:指定本地需要用多少和多大的缓冲区来缓冲FastCGI的应答请求,如果一个php脚本所产生的页面大小为256KB,那么会分配4个64KB的缓冲区来缓存,如果页面大小大于256KB,那么大于256KB的部分会缓存到fastcgi_temp_path指定的路径中,但是这并不是好方法,因为内存中的数据处理速度要快于磁盘。一般这个值应该为站点中php脚本所产生的页面大小的中间值,如果站点大部分脚本所产生的页面大小为256KB,那么可以把这个值设置为“8 32K”、“4 64k”等。如:4 64k fastcgi_busy_buffers_size:建议设置为fastcgi_buffers的两倍,繁忙时候的buffer,如:128k fastcgi_temp_file_write_size:在写入fastcgi_temp_path时将用多大的数据块,默认值是fastcgi_buffers的两倍,该数值设置小时若负载上来时可能报502BadGateway,如:128k fastcgi_temp_path:缓存临时目录 fastcgi_intercept_errors:这个指令指定是否传递4xx和5xx错误信息到客户端,或者允许nginx使用error_page处理错误信息,如:on fastcgi_cache_path:如: /usr/local/nginx1.10/fastcgi_cachelevels=1:2
七、nginx如何开启高效文件传输模式?
1、sendfile参数用于开启文件的高效传输模式,该参数实际上是激活了sendfile()功能,sendfile()是作用于两个文件描述符之间的数据拷贝函数,这个拷贝操作是在内核之中的,被称为 "零拷贝" ,sendfile()比read和write函数要高效得多,因为read和write函数要把数据拷贝到应用层再进行操作
2、tcp_nopush参数用于激活Linux 上的TCP_CORK socket选项,此选项仅仅当开启sendfile时才生效,tcp_nopush参数可以允许把http response header和文件的开始部分放在一个文件里发布,以减少网络报文段的数量。
相关配置如下:
cat /usr/local/nginx/conf/nginx.conf
......
http {
include mime.types;
server_names_hash_bucket_size 512;
default_type application/octet-stream;
sendfile on; # 开启文件的高效传输模式
tcp_nopush on; # 激活 TCP_CORK socket 选择
tcp_nodelay on; #数据在传输的过程中不进缓存
keepalive_timeout 65;
server_tokens off;
include vhosts/*.conf;
}八、Nginx如何配置防盗链?
相关配置如下:
server {
listen 80;
server_name www.test.com;
root /data/web/;
index index.php index.html;
access_log /data/logs/nginx/biao.madacode.access.log main;
location /{
root /home/data/;
}
error_page 404 /usr/local/nginx/html/404.html;
##防盗链核心配置
location ~ .*\.(wma|wmv|asf|mp3|mp4|mmf|zip|rar|jpg|gif|png|swf|flv)$
{
valid_referers none blocked server_names *.test.com http://IP;
if ($invalid_referer) {
return 403;
}
expires 24h;
access_log off;
}
location ~ /\.
{
deny all;
}
}配置说明:
vaild_referers有效的引用连接,如下,否则就进入$invaild_refere,返回403 forbiden。
1、none
"Referer" 来源头部为空的情况
2、blocked
"Referer"来源头部不为空,但是里面的值被代理或者防火墙删除了,这些值都不以http://或者https://开头.
3、server_names
"Referer"来源头部包含当前的server_names(当前域名)
九、nginx如何优化worker进程数?
Nginx有Master和worker两种进程,Master进程用于管理worker进程,worker进程用于Nginx服务,
worker进程数应该设置为等于CPU的核数,高流量并发场合也可以考虑将进程数提高至CPU核数 * 2
步骤如下:
1、grep -c processor /proc/cpuinfo # 查看CPU核数
2、vi /usr/local/nginx/conf/nginx.conf # 设置worker进程数
worker_processes 2;
user nginx nginx;
......
3、检查语法,并重新加载nginx
ps -ef | grep nginx | grep -v grep # 验证是否为设置的进程数
Tomcat性能调优
Mysql性能调优
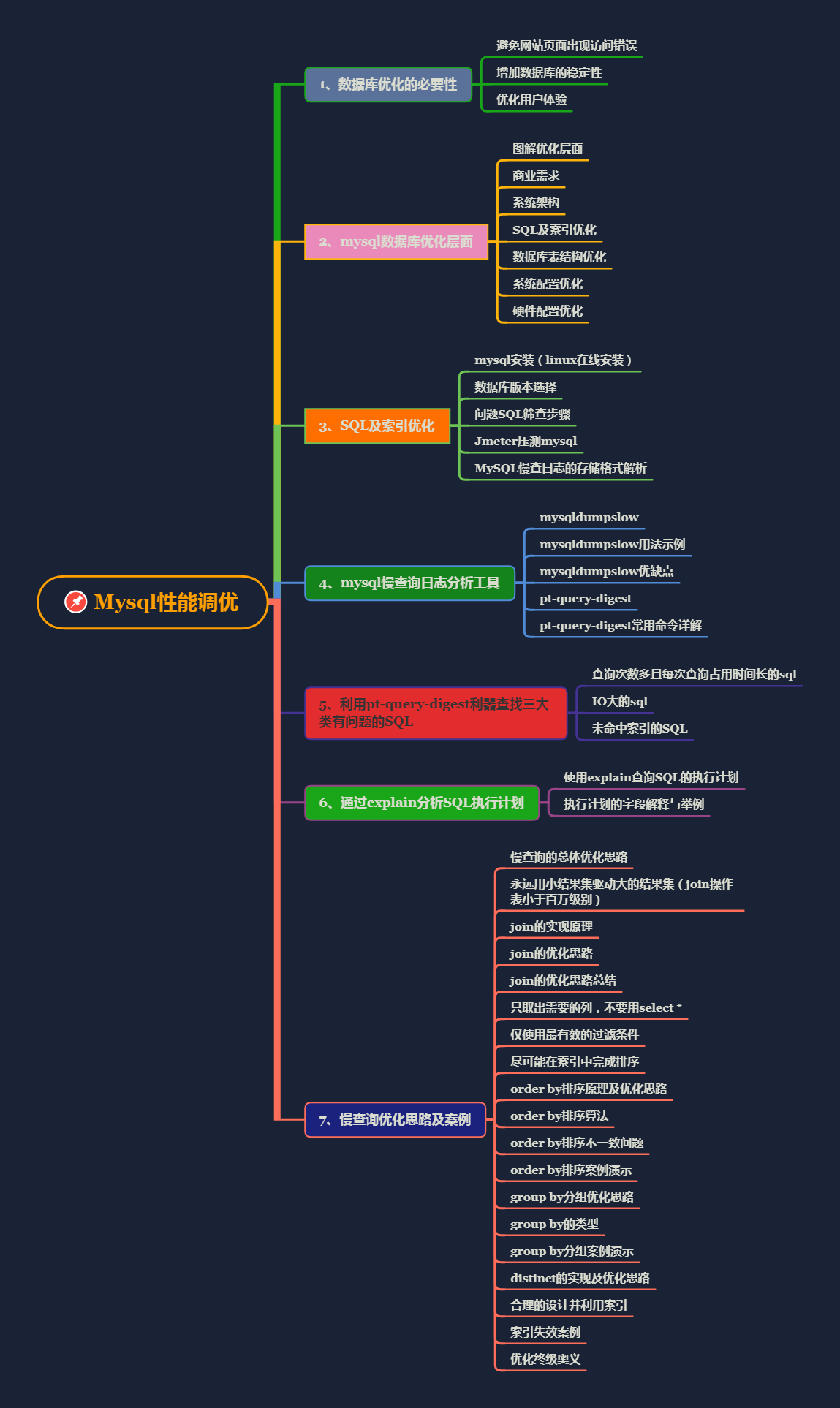
JVM调优-参数篇
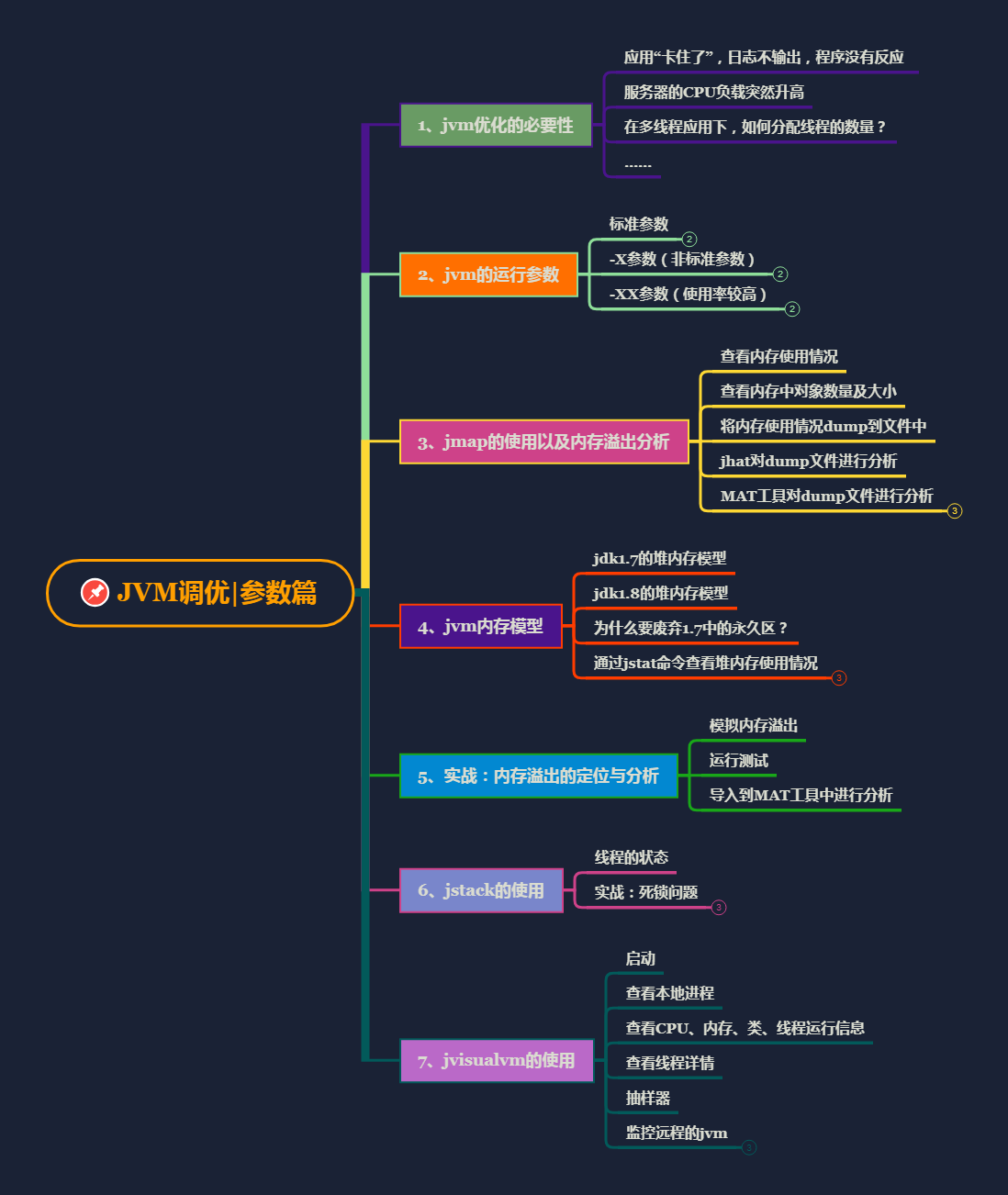
JVM调优-GC篇
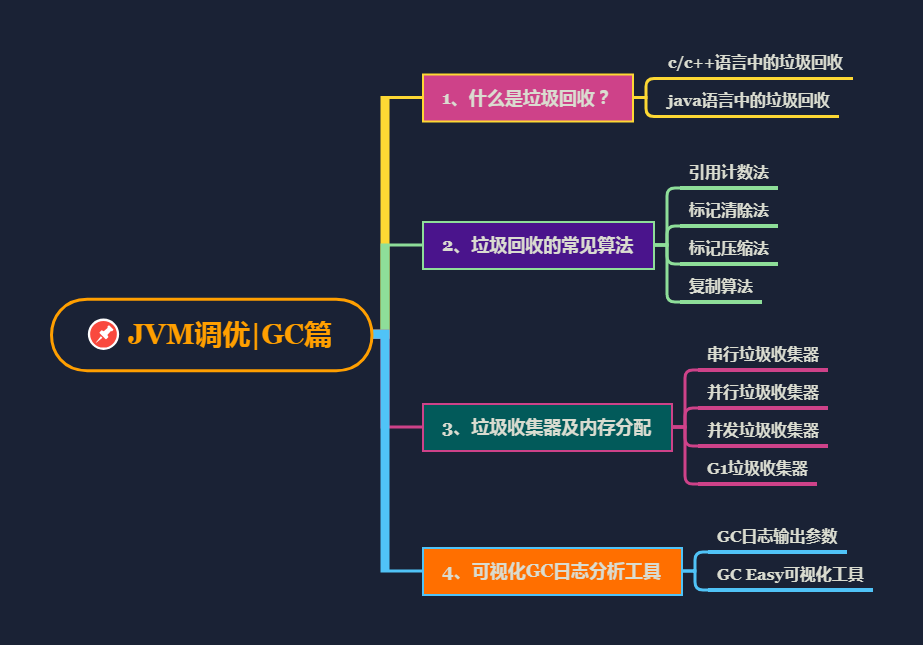
Netty性能调优
Nginx性能调优
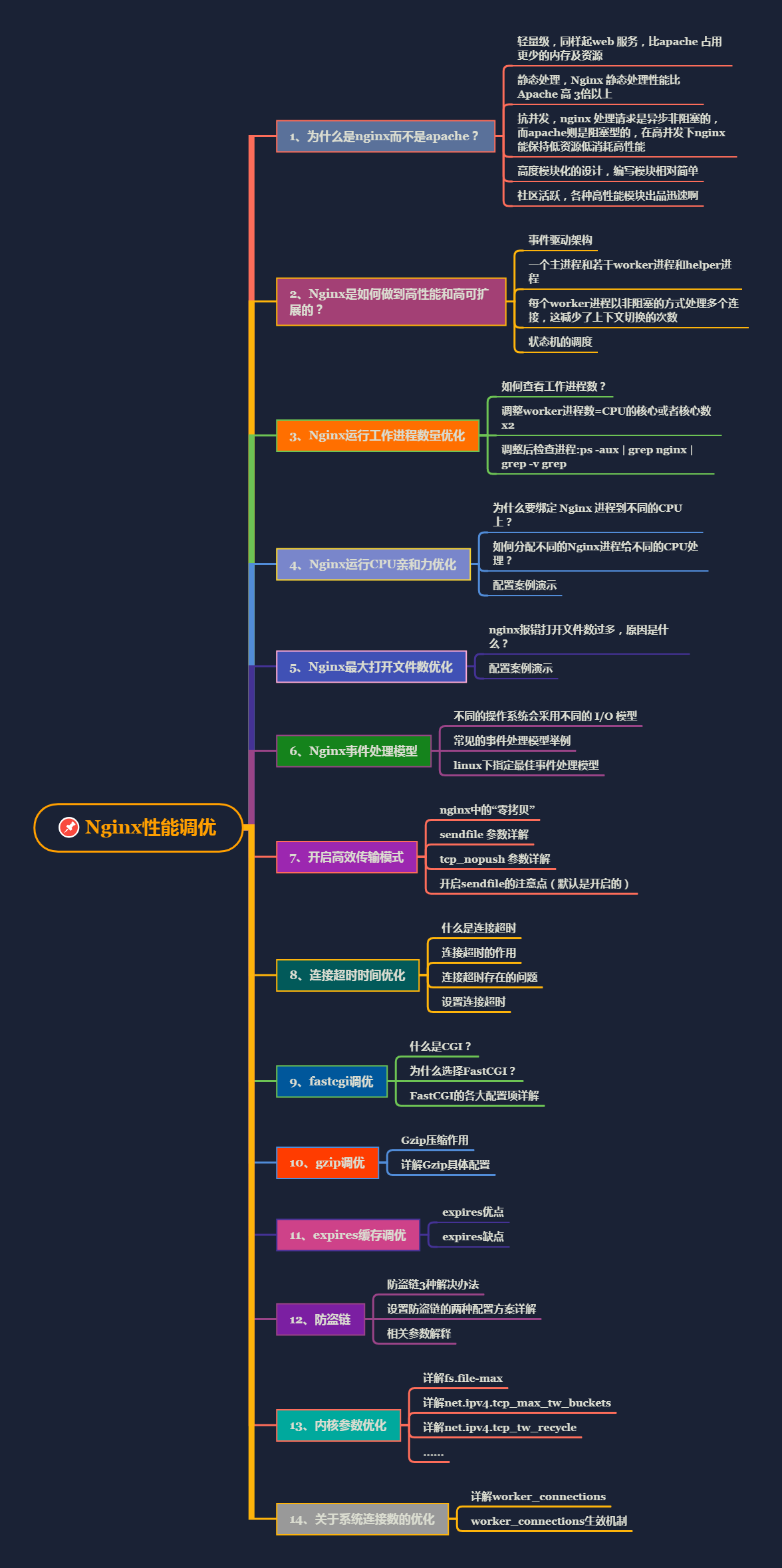
1、【练技术】如何通过精研线程模型,cpu调度,内存模型等性能优化核心?
性能优化无非就是线程,cpu调度,以及内存之间的配合,这三者中任何一个达到极限,都会造成系统整体性能下降,甚至瘫痪。
线程必然要由cpu调度才能活动起来,那么线程的活动也必须有自己的地盘,那么这个地盘就是内存区域。线程数越多,需要cpu的调度能力越强,需要的内存也就越大,那么线程不可能无限增大,总有个极限,当到达极限之后,系统性能将呈现抛物线形的状态急转往下。
所以我们必须不能让cpu等资源达到这个极限值,一般在85%左右就可以了。intel的工程师曾今说过,我们为什么要让cpu达到100%的性能呢,能够让他发挥到80%-85%就已经很完美了。
那么线程模型也是掣肘性能的一个重要因素,NIO优于BIO,reactor模型又是NIO模型的最佳实践,proactor模型又优于reactor模型。这些线程模型都是值得我们去深入研究的。
每种线程模型都有实际的产品落地,比如早期的tomcat就是BIO模型的,后来NIO起来之后,netty,redis等都基于reactor实现了相对不错的性能。proactor模式又落地到tomcat的NIO2通道中。这些都是优秀的线程模型的实现案例。
java领域里面,内存模型的研究的终极目标是如何更有效率的回收垃圾,从jdk迭代的版本我们可以看出jvm工程师在这方面的努力,在【jvm调优-GC篇】里我们着重讲了各种垃圾收集算法以及产品的落地,从最初的串行垃圾收集器到当前性能最好的G1垃圾收集器,这些都凝聚jvm工程师的心血。
在内存领域,各路大牛可谓都是绞尽脑汁的琢磨各种方案,也取得了一些成效,比如“零拷贝”,这个技术用在各大组件中,nginx,netty,kafka等组件里都有他的影子。他的理念就是干脆跨过堆内存,直接走内核,这样就没gc啥事了。
所以我们调优要做到心中有数,你究竟要调什么?究竟是线程模型呢,还是cpu调度呢,还是内存gc回收呢?针对不同的部分都有成熟的方案可选,不要盲目的去调优。
2、【学心法】如何从源码角度体会作者的设计思想?
我们在做项目时候一般会遇到下面的问题:
- 问题一是不知道如何去设计,比如刚入职场时,来一个需求需做概要设计,不知如何下手,不得不去看当前系统类似需求是如何设计的,然后仿照去设计。
- 问题二是设计的时候,考虑问题不周全,相比职场新手,这类人对一个需求依靠自己的经验已经能够拿出一个概要设计,但是设计中经常会遗漏一些异常细节,比如使用多线程有界队列执行任务,遇到机器宕机了,如果队列里面的任务不存盘的话,那么机器下次启动时候这些任务就丢失了。
对于这些问题,说到底主要是因为经验不够,而经验主要从项目实践中积累,所以招聘单位一般都会限定工作时间大于 3 年,因为这些人的项目经验相对较丰富,项目中遇到的场景相对较多。工作经验的积累来自于年限与实践,然而看源码可以扩展我们的思路,这是变相增加我们经验的不错方法。虽然不能短时间内通过时间积累经验,但是可以通过学习开源框架、开源项目来获取。
- 另外进职场后一般都要先熟悉现有系统,如果有文档还好,没文档的话就得自己去翻代码研究。如果大家之前对阅读源码有经验,那么在研究新系统的代码逻辑时就不会那么费劲了。
- 还有一点就是当你使用框架或者工具做开发时,如果你对它的实现有所了解,就能最大化的减少出故障的可能。比如并发队列 ArrayBlockingQueue 里面元素入队有个 offer 和 put 方法,虽然某个时间点你知道使用 offer 方法时,当队列满了就会丢弃要入队的元素,之后 offer 方法会返回 false,而不会阻塞当前线程;使用 put 方法时当队列满了,则会挂起当前线程,直到队列有空闲元素,入队成功后才返回。但是人是善忘的,当你一段时间不使用,就会忘记他们的区别,这时当你使用时,需进入 offer 和 put 的源码看他们的实现。进入 offer 方法一看,哦,原来队列满后直接返回了 false;进入 put 方法一看,哦,原来队列满后,直接使用条件变量的 await 方法挂起了当前线程;知道了他们的区别,你就可以根据自己的需求来选择了。
看源码最大的好处是可以开阔思维,提升架构设计能力。有些东西仅靠书本和自己思考是很难学到的,必须通过看源码,看别人如何设计,然后思考为何这样设计才能获取。能力的提高不在于你写了多少代码,做了多少项目,而在于给你一个业务场景时,你是否能拿出几种靠谱的解决方案,并且说出各自的优缺点。而如何才能拿出来,一来靠经验,二来靠归纳总结,而看源码可以快速增加你的经验。
3、【炼内功】如何在系统设计初期就能预测未来的性能状况?
在做系统架构设计的时候,我们对现有的资源,包括软硬件资源都应该有个清晰的了解。比如说现在公司机房里预备给我们系统上线的物理机的cpu是几核的,内存是多大的,硬盘是不是ssd的,带宽是多少,等等。这些信息都是我们设计人员必须要了解的,尤其是作为架构师,更要做到心中有数,这对你做架构设计的时候非常有参考意义。
举个简单的例子,你可能在一台2核4g的物理机上架构nginx+tomcat+redis吗?你把这3个组件都放在一台只有4G内存的机器上你认为能行吗?
答案肯定是不行的,光跑一个tomcat都费劲,对不对?所以硬件性能决定了你能用哪些组件,对于一些比较重的组件尽量少用,比如08,09年甚至更早的时候我们用的比较多的weblogic和websphere等等。光启动起来啥事不干就吃掉几个G的内存,如果再在上面跑业务那你的机器起码得配置到32g内存,所以这种重量级的组件也渐渐被我们淘汰了。所以针对不同的软硬件的组合我们该如何在软硬件性能受限的情况下设计出最合适的框架,这是个值得深思的问题。
当你根据现实情况设计出来框架后你也必然知道这个框架究竟能承受多少并发,这都是一目了然的。
4、【悟思维】项目架构决定性能?优秀的架构胜过一万次的调优
这个问题很容易理解,一个单节点(一台应用服务器+一台数据库服务器)的系统架构,任凭你使出浑身解数来调优也不可能让系统达到百万级并发,别说百万级了,上万并发都不可能。不说其他的,在一个性能相对不错的物理机上,mysql最多也就能承载3500-4500的QPS,你说你能调优调到上万并发??在目前来看如果不借助于其他组件或者其他技术手段是不太可能的。
首先大家要明白一个最底层的逻辑,所有的性能问题归根结底绝大多数都是要解决IO的读写性能问题。
我们在线程模型上面孜孜不倦的追求,从BIO到NIO,再到reactor,最后到proactor,对这些模型的追求本质上就是不断对IO性能的追求。
那IO又分为读IO和写IO,在单节点上,高并发上来之后,请求直接通过tomcat打到mysql上达到3500qps左右的时候,mysql就会报警了,这时候怎么办?
打到mysql上的请求无非就是读和写,所以我们分两种情况来处理:
- 一是解决读IO的问题,如何解决?最直接的就是我们把热点数据直接放内存里(走逻辑io),不走mysql了(走mysql实际是到磁盘去拿数据的,走的是物理IO),所以我们大名鼎鼎的redis就派上用场了。绝大部分热点数据都存放在redis,高并发时候,读IO绝大部分都走redis了,这样就减轻了mysql的负担。
- 二是解决写IO的问题,当大量的写需求到达mysql的时候,如果我们在mysql前面加上消息队列相关组件,让写请求先进队列,然后再通过队列慢慢依次的来对mysql进行写操作,那么这样不就减轻了mysql的写请求IO了吗?
所以我们的架构就从单一架构(比如说是tomcat+mysql)变成了(tomcat+mq+redis+mysql)的架构,这两种架构的性能有着天壤之别。因为mq和redis分别解决了高并发时的读写问题,这才是影响性能的根本因素。那么第二种架构还有很多的优化空间,比如我们继续给他增加多级缓存,redis再做集群,mq也做集群,甚至tomcat,mysql都做集群,那么这个系统将会变的非常庞大,也更加的复杂,但是带来的效果却是显而易见的,达到百万并发,千万并发甚至亿级并发都是有可能的。
5、【升境界】预防大于一切,不要等待项目灾难来临才想起去优化。
我们系统为什么都要配有监控系统,尤其是针对高并发的主营系统,监控系统是必备的。因为不管从技术层面还是从业务层面讲,主营系统的奔溃都会给公司带来不可估量的损失。
项目灾难让公司损失百万,千万的案例实在是多不胜数。所以预防大于一切这个说法一点也不为过。通常我们在监控系统上面设置的阈值都会比最大极限值要低5-10个百分点,如果最大极限值是85%,那我们设置告警值一般是75%就会告警,不会真的让你达到85%才告警,有些谨慎的公司这个值设置的更低。
这样会让运维人员和开发人员及时介入进行排查,不会让系统奔溃了再来排查,到那时候就晚了。所以如果一个功能经常性的达到阈值的75%从而触发报警,这时候开发人员就应该立即去排查这个故障,通过不断的修改和调优,这个功能逐渐的完善,报警也没有了。
所以这才是一个系统调优的正确姿势,绝对不能等到系统奔溃才去优化,我们要做的是尽可能的做到各个层面的预防,运维,开发,DBA等各司其职,保证系统7*24小时稳定运转。
6、【拓格局】反对没有经过验证人云亦云的性能调优经验。
做学问最忌讳人云亦云,尤其是在技术领域,没有经过验证的所谓经验最好不要一味的去相信,更不要在线上尝试一些根本没有依据的所谓调优经验,因为你有可能把一个正常的系统调奔溃。
比如tomcat某个参数的设置,其实是和版本相关的,你好像听别人说过可以调整这个参数,这时候你不管三七二十一拿过来就改,最后肯定不能达到自己的预期,还有可能把原来运转正常的系统搞奔溃。
像tomcat通道的配置都是根据版本的不同有不同的配置,比如你就不能在tomcat7上配置NIO2通道,因为NIO2虽然性能高,但是必须是tomcat8及以上版本才可以配置。如果你只是听别人这么说过NIO2通道性能高,自己从来没有尝试调试过,也没有尝试去配置过,然后就想当然的在tomcat7上面配置NIO2通道,最后必定会捅娄子,出纰漏。
所以对于调优经验还是要实事求是,经过研究的才有发言权,只有经过实践的你才敢去调,这样自己也不会心虚。
一、Tomcat配置优化
对于tomcat的优化,主要是从2个方面入手,一是,tomcat自身的配置,另一个是tomcat所运行的jvm虚拟机的调优。
1、部署安装tomcat9
1、下载并安装: https://tomcat.apache.org/download-90.cgi
2、wget镜像安装
cd /usr/local
wget https://mirrors.cnnic.cn/apache/tomcat/tomcat-9/v9.0.33/bin/apache-tomcat-9.0.33.tar.gz
tar ‐zxvf apache‐tomcat‐9.0.33.tar.gz
mv apache‐tomcat‐9.0.33 tomcat9
cd tomcat9/conf
#修改配置文件,配置tomcat的管理用户
vi tomcat‐users.xml
#写入如下内容:
<role rolename="manager"/>
<role rolename="manager‐gui"/>
<role rolename="admin"/>
<role rolename="admin‐gui"/>
<user username="tomcat" password="tomcat" roles="admin‐gui,admin,manager‐
gui,manager"/>
#保存退出
#如果是tomcat7,配置了tomcat用户就可以登录系统了,但是tomcat9中不行,还需要修改
另一个配置文件,否则访问不了,提示403
vim webapps/manager/META‐INF/context.xml
#将<Valve的内容注释掉
<Context antiResourceLocking="false" privileged="true" >
<!‐‐ <Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="127\.\d+\.\d+\.\d+|::1|0:0:0:0:0:0:0:1" /> ‐‐>
<Manager sessionAttributeValueClassNameFilter="java\.lang\.
(?:Boolean|Integer|Long|Number|String)|org\.apache\.catalina\.filters\.Cs
rfPreventionFilter\$LruCache(?:\$1)?|java\.util\.(?:Linked)?HashMap"/>
</Context>
#保存退出即可
#启动tomcat
cd /usr/local/tomcat9/bin/
./startup.sh && tail ‐f ../logs/catalina.out
#打开浏览器进行测试访问
http://192.168.0.108:8080/
点击“Server Status”,输入用户名、密码进行登录,tomcat/tomcat
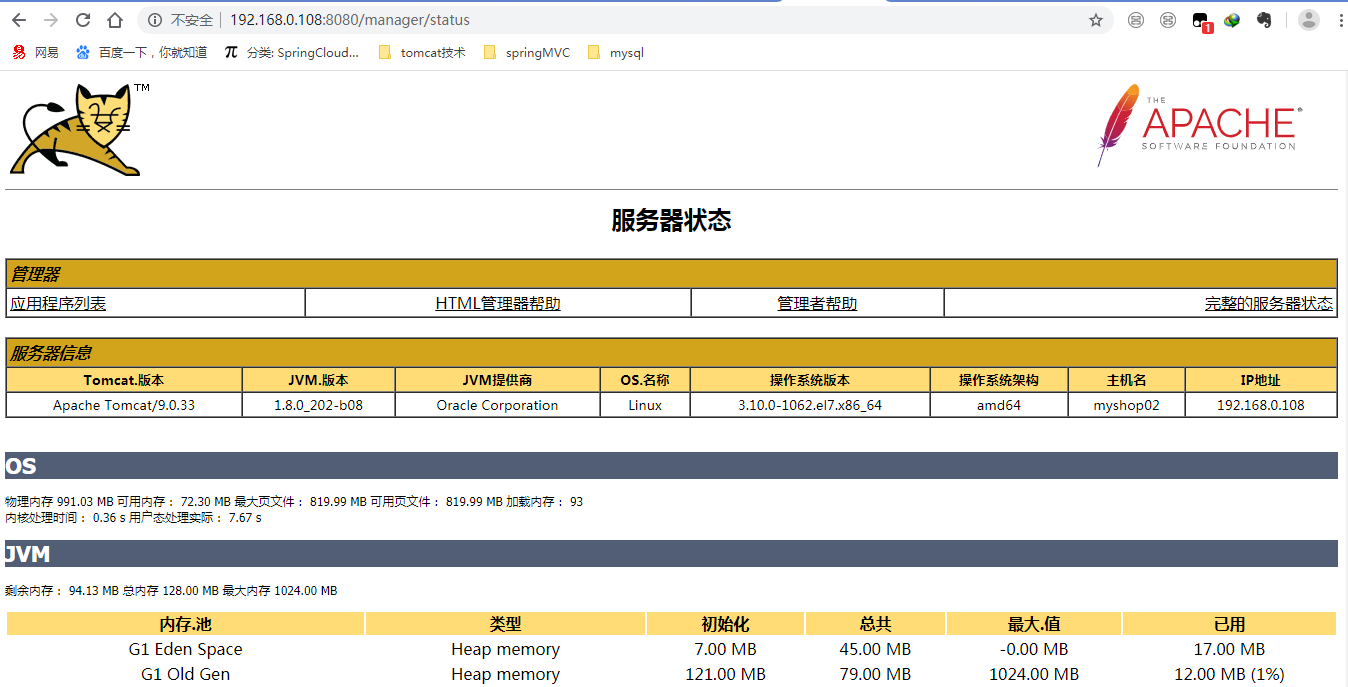
进入之后即可看到服务器的信息。(进去看看)
ps:安全起见,生产环境会禁用这个管理界面,最直接的办法是删除webapp下的默认项目。因为我们根本不需要从界面上部署。
2、禁用ajp协议(8.5.51之前的版本默认是开启的,后续的版都是禁用的)
在服务状态页面中可以看到,默认状态下会启用AJP服务,并且占用8009端口 。

ps:为了演示,需要把server.xml文件ajp connector屏蔽段放开
什么是AJP呢? AJP(Apache JServer Protocol) AJPv13协议是面向包的。WEB服务器和Servlet容器通过TCP连接来交互;为了节省SOCKET创建的昂贵代价,WEB服务器会尝试维护一个永久TCP连接到servlet容器,并且在多个请求和响应周期过程会重用连接。
我们一般是使用Nginx+tomcat的架构,所以用不着AJP协议,所以把AJP连接器禁用。 修改conf下的server.xml文件,将AJP服务禁用掉即可 。
<!--<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />-->重启tomcat,查看效果。
可以看到AJP服务以及不存在了。
ps:禁用ajp后,看节省了多少内存??查询某个pid占多少内存
3、执行器(线程池)
在tomcat中每一个用户请求都是一个线程,所以可以使用线程池提高性能。 修改server.xml文件:
<!‐‐将注释打开(注释没打开的情况下默认10个线程,最小10,最大200)‐‐>
<Executor name="tomcatThreadPool" namePrefix="catalina‐exec‐"
maxThreads="500" minSpareThreads="50"
prestartminSpareThreads="true" maxQueueSize="100"/>
<!‐‐
参数说明:
maxThreads:最大并发数,默认设置 200,一般建议在 500 ~ 1000,根据硬件设施和业
务来判断
minSpareThreads:Tomcat 初始化时创建的线程数,默认设置 25
prestartminSpareThreads: 在 Tomcat 初始化的时候就初始化 minSpareThreads 的
参数值,如果不等于 true,minSpareThreads 的值就没啥效果了
maxQueueSize,最大的等待队列数,超过则拒绝请求
‐‐>
<!‐‐在Connector中设置executor属性指向上面的执行器‐‐>
<Connector executor="tomcatThreadPool" port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />保存退出,重启tomcat,查看效果。
ps:idea中源码启动或者用jvisualvm查看线程的变化
4、3种运行模式
tomcat的运行模式有3种:
ps:每个模式都需要线程演示查看
1)、bio(tomcat7演示,压测看线程增长)
默认的模式,性能非常低下,没有经过任何优化处理和支持,tomcat8.5已经舍弃了该模式,默认就是nio模式。
2)、nio(nio2)
nio(new I/O),是Java SE 1.4及后续版本提供的一种新的I/O操作方式(即java.nio包及其子包)。Java nio是一个基于缓冲区、并能提供非阻塞I/O操作的Java API,因此nio也被看成是non-blocking I/O的缩写。它拥有比传统I/O操作(bio)更好的并发运行性能。NIO2异步的本质是数据从内核态到用户态这个过程是异步的,也就是说nio中这个过程必须完成了才执行下个请求,而nio2不必等这个过程完成就可以执行下个请求,nio2的模式中数据从内核态到用户态这个过程是可以分割的。
3)、apr
apr(Apache portable Run-time libraries/Apache可移植运行库)是Apache HTTP服务器的支持库。
安装起来最困难,但是从操作系统级别来解决异步的IO问题,大幅度的提高性能。推荐使用nio,不过,在tomcat8及后续的版本中有最新的nio2,速度更快,建议使用nio2。
设置nio2:
<Connector executor="tomcatThreadPool" port="8080"
protocol="org.apache.coyote.http11.Http11Nio2Protocol"
connectionTimeout="20000"
redirectPort="8443" />ps:为什么nio快呢?
简单地说,nio 模式最大化压榨了CPU,把时间片更好利用起来。通俗地说,bio hold住连接不干活也占用线程,nio hold住连接不干活也没关系,让需要处理的连接执行就行了。

可以看到已经设置为nio2了 。
如果通道选择apr,apr需要独立安装。
apr安装步骤:
1、先安装gcc, expat-devel,perl-5
yum install gcc
yum install expat-devel
cd /usr/local
wget ftp://mirrors.ustc.edu.cn/CPAN/src/5.0/perl-5.30.1.tar.gz
tar -xzf perl-5.30.1.tar.gz
cd perl-5.30.1
./Configure -des -Dprefix=$HOME/localperl
make
make install2、安装apr
cd /usr/local
wget https://mirrors.cnnic.cn/apache/apr/apr-1.6.5.tar.gz
tar -zxvf apr-1.6.5.tar.gz
cd apr-1.6.5
./configure --prefix=/usr/local/apr && make && make install3、安装apr-util
cd /usr/local
wget https://mirrors.cnnic.cn/apache/apr/apr-util-1.6.1.tar.gz
##安装apr-util前请确认系统是否安装了expat-devel包,如没安装请安装,不然会报错。yum install expat-devel
tar -zxvf apr-util-1.6.1.tar.gz
cd apr-util-1.6.0
./configure --prefix=/usr/local/apr-util --with-apr=/usr/local/apr && make && make install4、安装openssl
cd /usr/local
wget https://www.openssl.org/source/openssl-1.0.2l.tar.gz
tar -zxvf openssl-1.0.2l.tar.gz
cd openssl-1.0.2l
./configure --prefix=/usr/local/openssl shared zlib && make && make install
##缺少zlib,会报错,所以得先安装zlib
cd /usr/local
**wget http://www.zlib.net/zlib-1.2.11.tar.gz**
tar -zxvf zlib-1.2.1.tar.gz
cd zlib-1.2.11
##因为要用共享方式安装,所以执行以下命令
make clean && ./configure --shared && make test && make install
cp zutil.h /usr/local/include
cp zutil.c /usr/local/include
##重新执行
./configure --prefix=/usr/local/openssl shared zlib && make && make install
##检查openssl是否安装成功
/usr/local/openssl/bin/openssl version -a 显示1.0.2l版本为成功5、安装tomcat-native
tar /usr/local/tomcat9/bin/tomcat-native.tar.gz
cd /usr/local/tomcat9/bin/tomcat-native-1.2.12-src/native
./configure --with-apr=/usr/local/apr --with-java-home=/usr/local/jdk/ --with-ssl=/usr/local/openssl/ && make && make install6、使tomcat支持apr配置apr库文件
##方式1:配置坏境变量:
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/apr/lib" >> /etc/profile
echo "export LD_RUN_PATH=$LD_RUN_PATH:/usr/local/apr/lib" >> /etc/profile && source /etc/profile##方式2:catalina.sh脚本文件:在注释行# Register custom URL handlers下添加一行
JAVA_OPTS="$JAVA_OPTS -Djava.library.path=/usr/local/apr/lib"7、修改tomcat server.xml文件(把protocol修改成org.apache.coyote.http11.Http11AprProtocol)
<Connector port="8080" protocol="org.apache.coyote.http11.Http11AprProtocol"
connectionTimeout="20000"
redirectPort="8443" />8、启动tomcat
cd /usr/local/tomcat8/bin
./startup.sh9、查看tomcat是否以http-apr模式运行,可以查看tomcat管理界面,也可以远程jmx监控查看
##连接远程jmx监控需要在catalina.sh文件中加上
CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote -Djava.rmi.server.hostname=192.168.0.107 -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"查看管理页面

二、部署测试用的java web项目
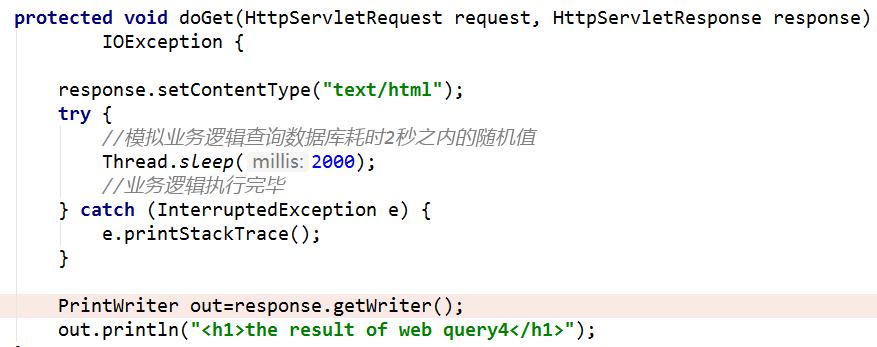
1、部署web应用
部署一个简单的servlet测试用例,模拟业务耗时2000ms
2、准备好test-web.war上传到linux服务器,进行部署安装
部署过程见视频
3、访问首页,查看是否已经启动成功:http://192.168.0.108:8080/test-web

出现此页面说明部署成功!
三、使用Apache JMeter进行测试
1、下载安装:
http://jmeter.apache.org/download_jmeter.cgi
2、修改主题和语言:主题修改为白底黑字,语言修改为中文
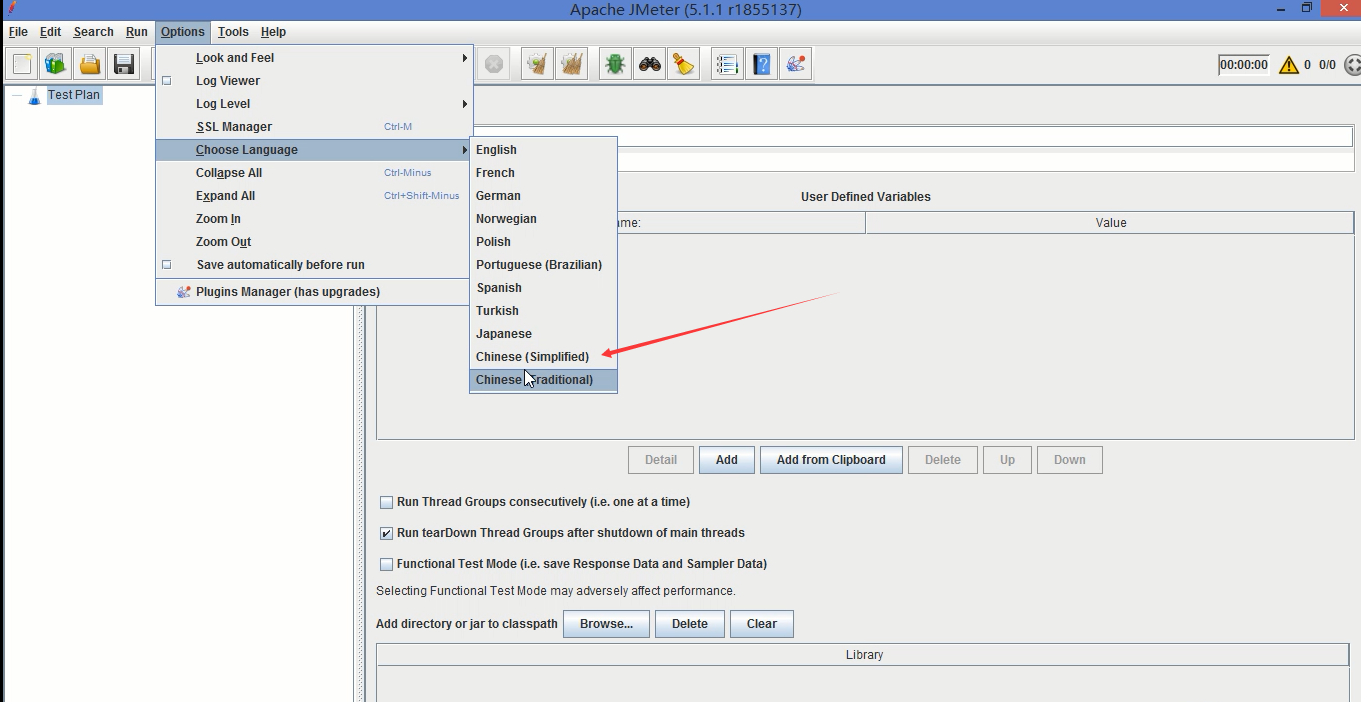
3、创建首页的测试用例:详见操作
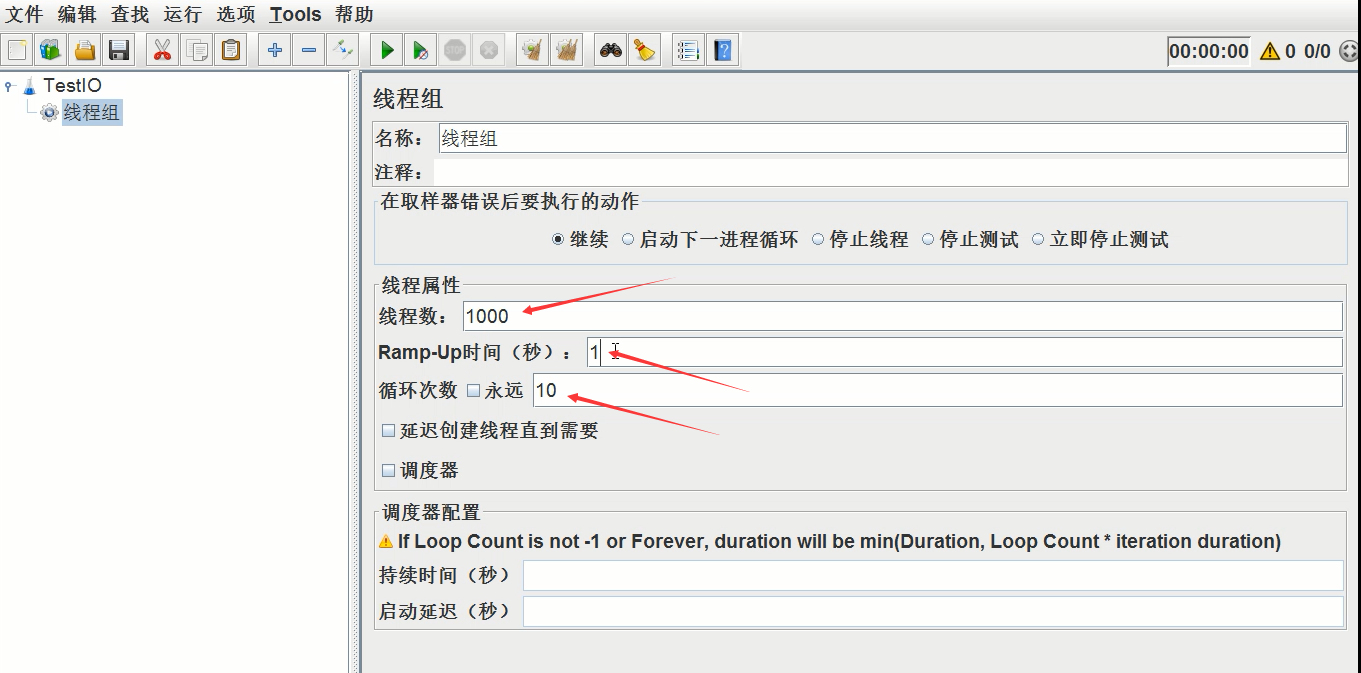
线程组设置:1000个线程,每个线程循环10次,间隔为1秒(具体其他设置见视频)
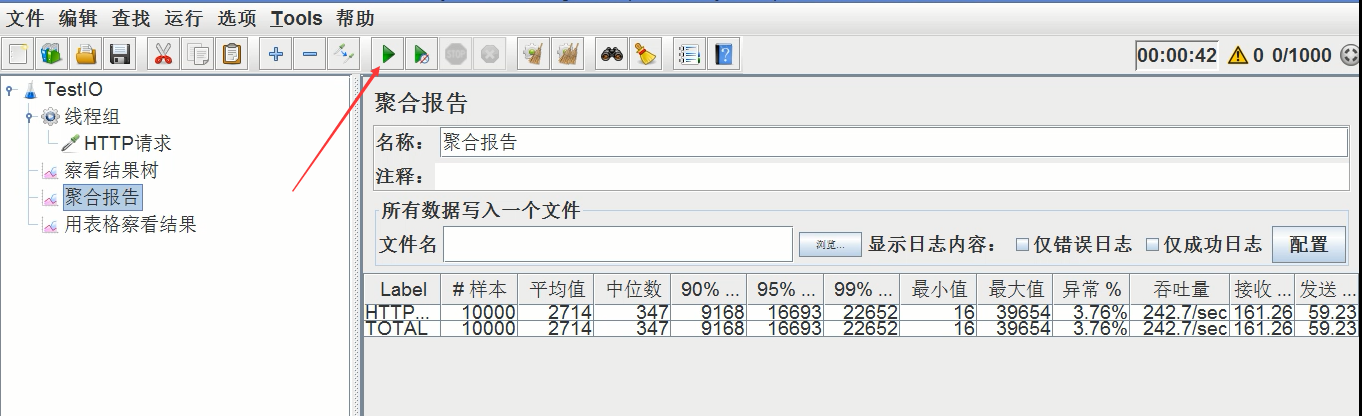
4、启动、进行测试:详见操作
设置完毕后点击绿色的三角按钮启动压测(具体其他操作见视频)
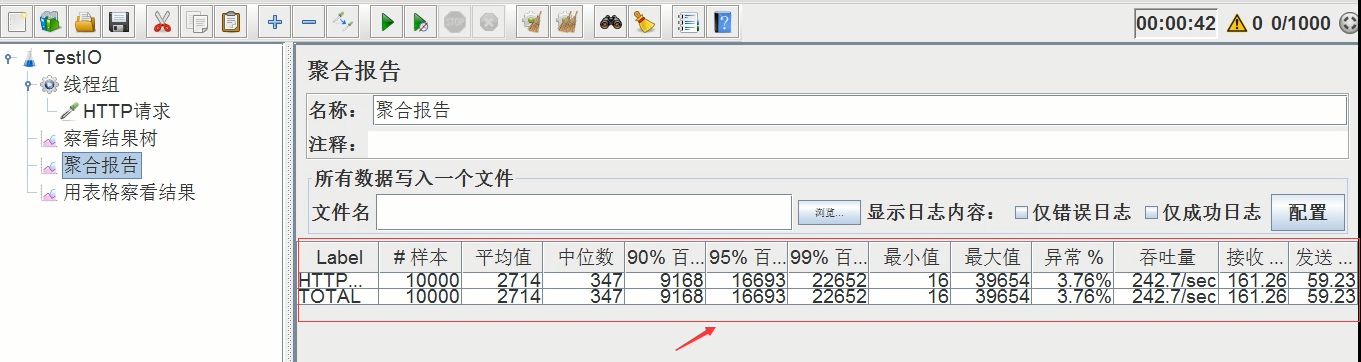
5、聚合报告:聚合报告中要具体查看吞吐量
具体的压测结果在聚合报告中查看,如下图所示
四、调整tomcat参数进行优化
以下所有步骤的具体演示见视频
1、禁用AJP服务
具体禁用操作:在conf/server.xml中禁用以下配置:
(tomcat曝出ajp漏洞后,官方已打完补丁,现在该配置默认是屏蔽的。本人在b站有使用python脚本模拟黑客利用ajp漏洞进行攻击获取class文件的免费视频演示,感兴趣的同学可以去看下):

禁用后进行压测,查看吞吐量
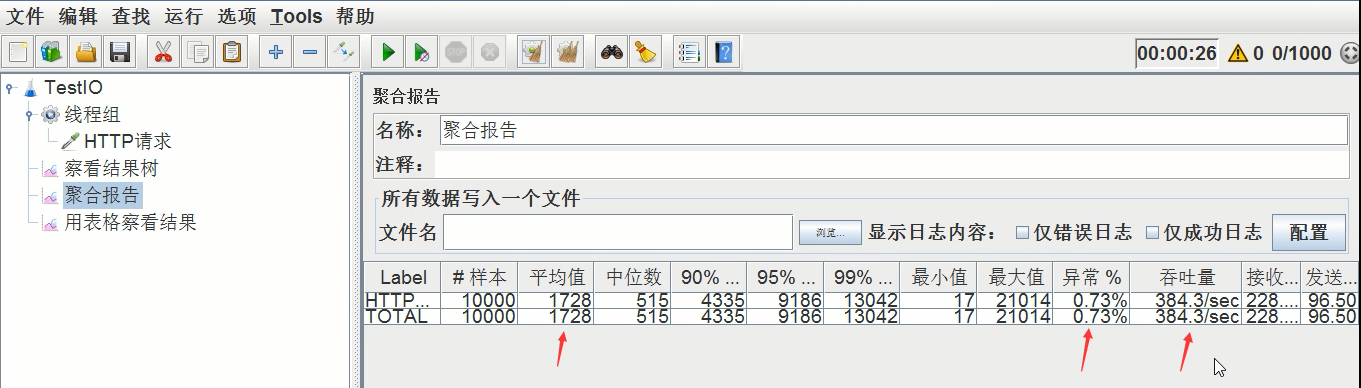
压测结果如下(禁用ajp)
平均时间:1.728s,异常率:0.73%,吞吐量:384.3/s
取消ajp屏蔽后,重启tomcat,继续压测,查看吞吐量
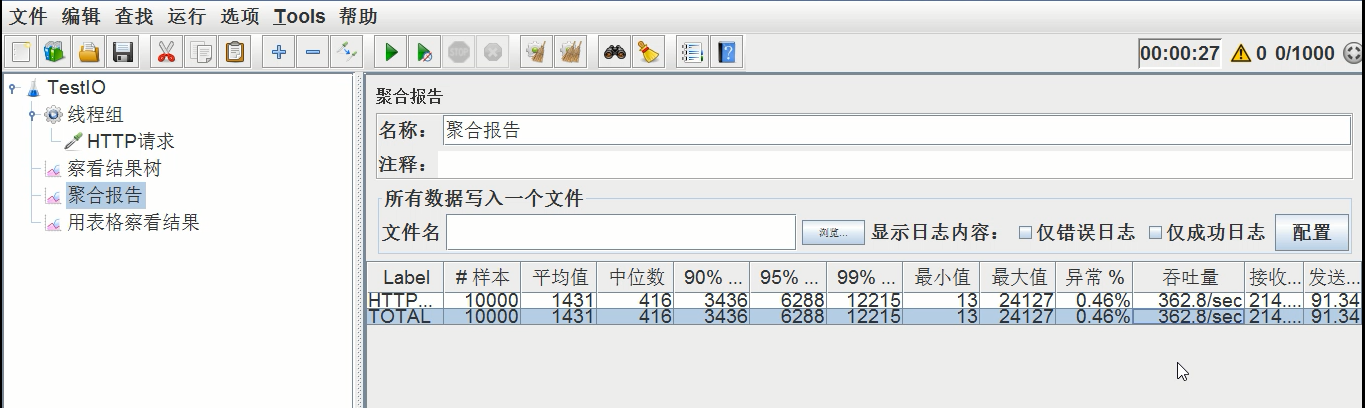
压测结果如下(使用ajp)
平均时间:1.431s,异常率:0.46%,吞吐量:362.8/s
比较两次压测结果发现,禁用后吞吐量是有所上升的。
2、设置线程池
1)、不设置线程池,业务延时设置1000ms,压测后的吞吐量如下
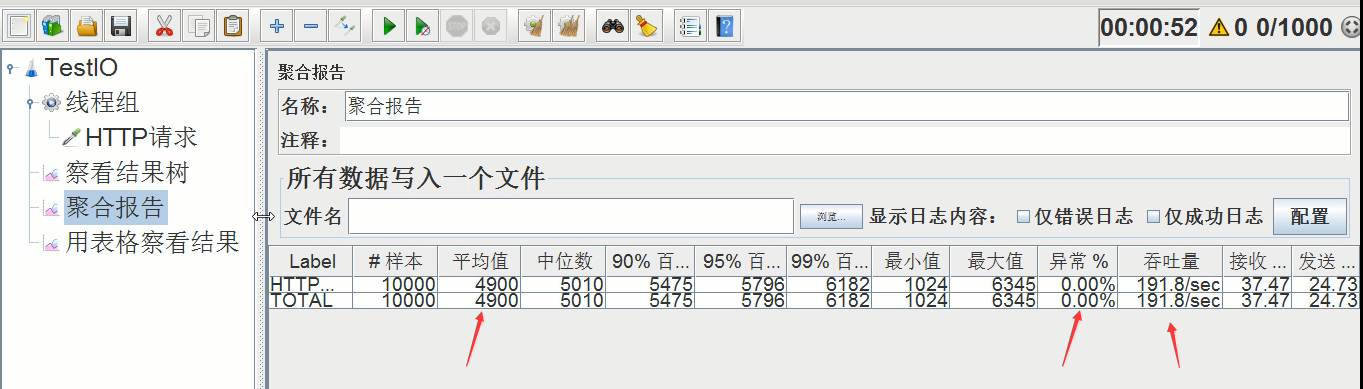
平均时间:4900ms,异常率:0.00%,吞吐量:191.8/s
2)、不设置线程池,业务延时设置2000ms,压测后的吞吐量如下
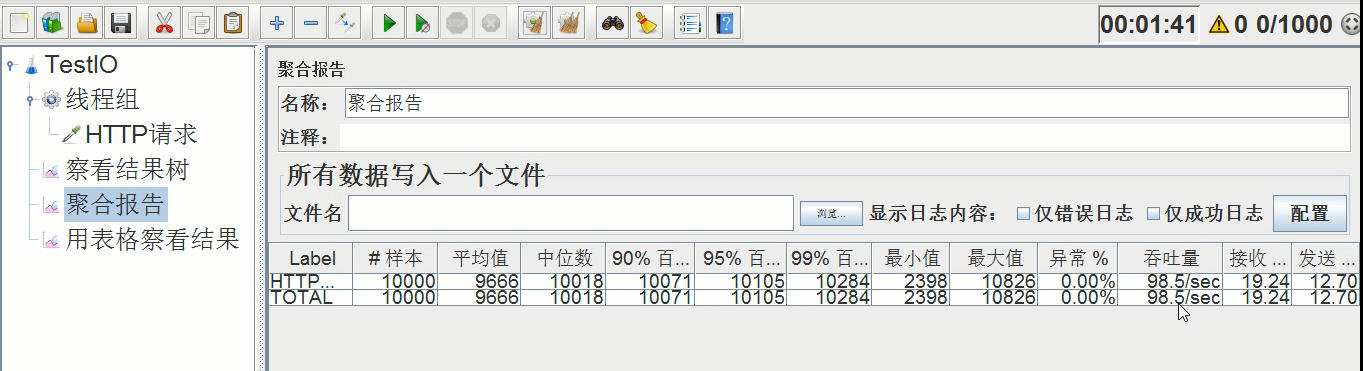
平均时间:9666ms,异常率:0.00%,吞吐量:98.5/s
业务延时之后,平均时间翻了一倍,吞吐量减少一半,总体性能下降了两倍。
由此可见,业务时间执行的长短直接影响吞吐量和执行时间
3)、设置线程池,最大线程设置200(跟不设置线程池时是一样的,默认最大就是200个线程),继续压测

压测后吞吐量如下
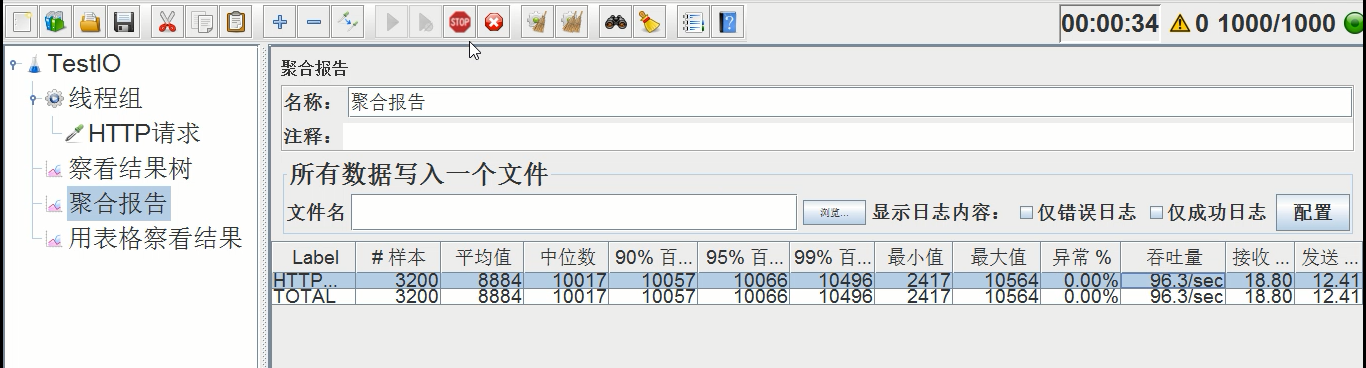
平均时间:8884ms,异常率:0.00%,吞吐量:96.3/s
跟第二次的压测结果差不多(因为虽然加了线程池,但是最大线程设置的是200,和不加线程池是一样的)
4)、设置线程池,最大线程设置为400(最大线程数扩大了1倍),继续压测

压测后吞吐量如下
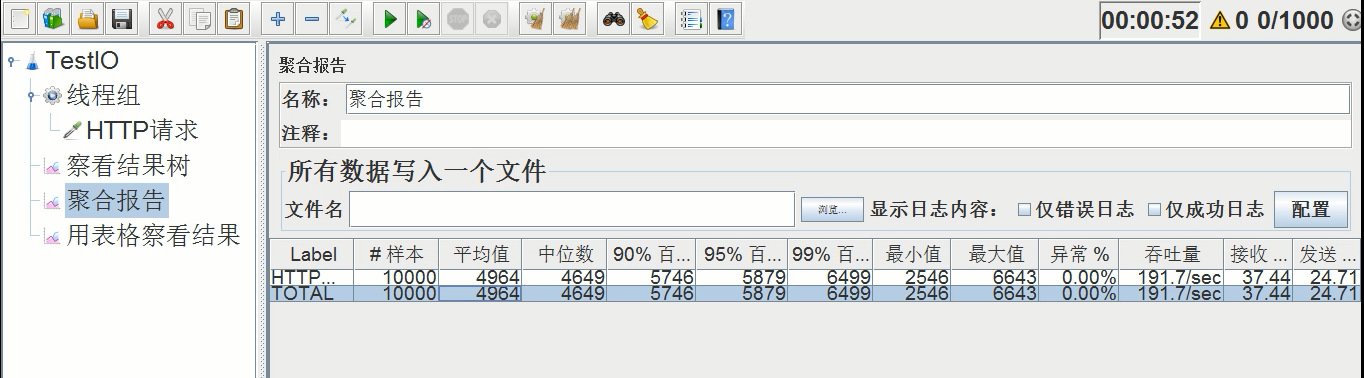
平均时间:4946ms,异常率:0.00%,吞吐量:191.7/s
由此可见,最大线程扩大1倍后,平均时间缩短了1倍,吞吐量还扩大了1倍,总体性能提升2倍
5)、设置线程池,最大线程扩大到800(最大线程数扩大了4倍),继续压测

压测后吞吐量如下
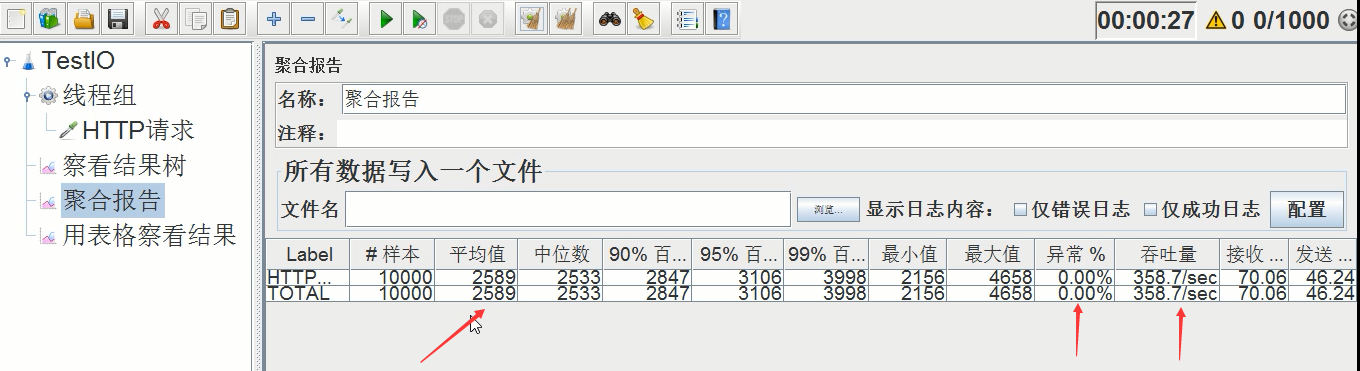
平均时间:2589ms,异常率:0.00%,吞吐量:358.7/s
由此可见,线程数再一次扩大后,时间又缩短了1倍,吞吐量又上升了接近1倍,总体性能提升近2倍
6)、设置线程池,最大线程扩大到1600(最大线程数扩大了8倍),继续压测(看什么时候出现异常)

压测后吞吐量如下
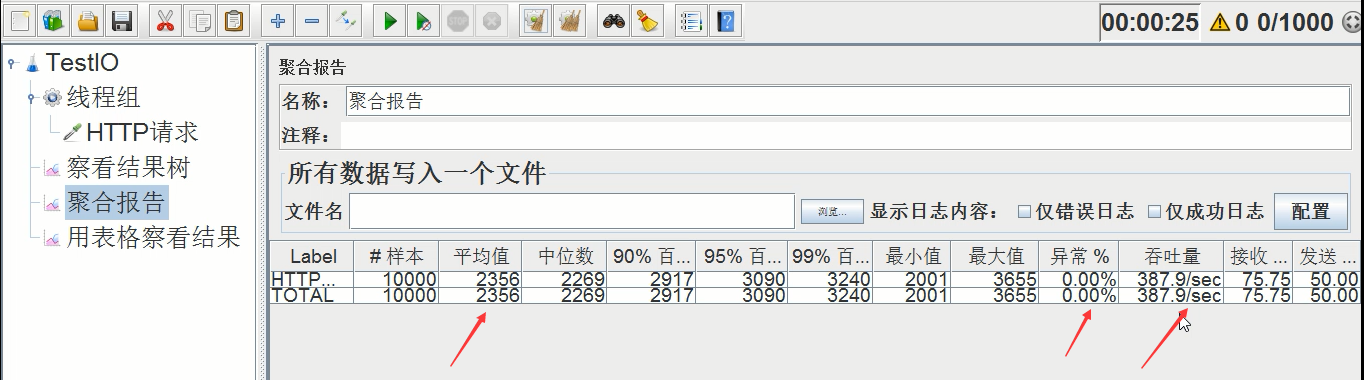
平均时间:2356ms,异常率:0.00%,吞吐量:387.9/s
由于jmeter设置的总线程数是1000,这就压制了我们设置的1600的线程总数,所以压测结果和第三次差不多
7)、设置线程池,最大线程1600不变,将jmeter的压测线程设置为2000,继续压测(这时候还是没有出现异常)
压测后吞吐量如下(下图右上角jmeter压测线程数改成了2000)
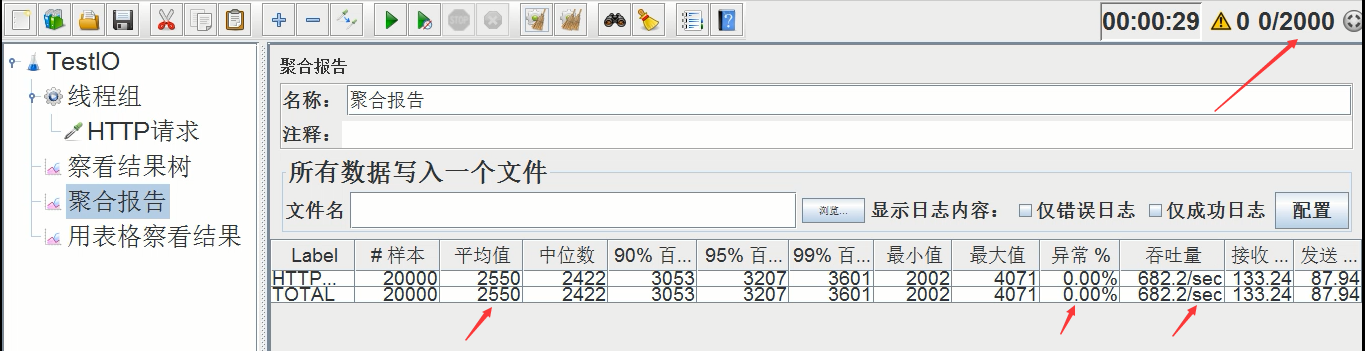
平均时间:2550ms,异常率:0.00%,吞吐量:682.2/s
平均时间差不多,但是吞吐量还是上升了1倍左右,总体性能提升1倍(总体性能的提升幅度比前几次下降了1倍),因此并不是可以无限制的扩大线程数来提升性能,总有出现瓶颈的时候
8)、设置线程池,最大线程扩到3000,继续压测(看会不会出现异常)

压测后吞吐量如下
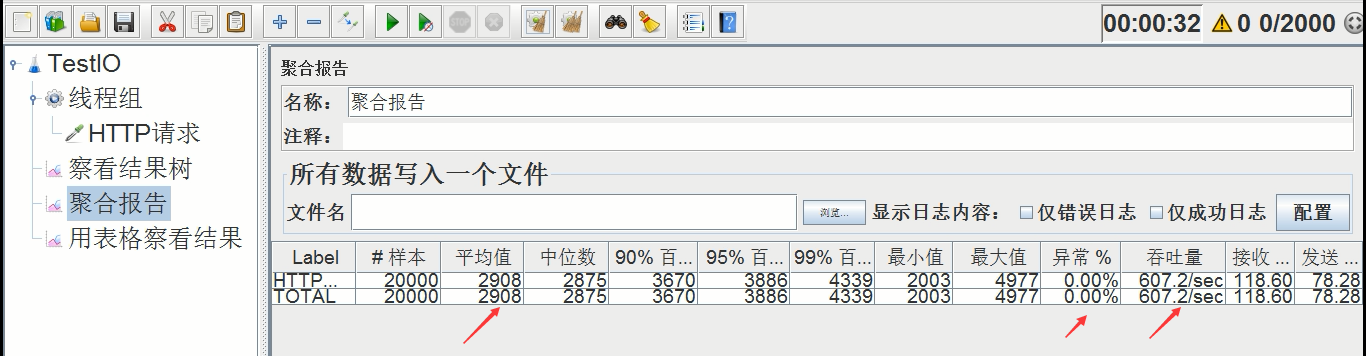
平均时间:2908ms,异常率:0.00%,吞吐量:607.2/s
比上次稍微差点,因为jmeter的线程总数还是2000个,都已经打满,时间增加了,吞吐量也下降了,所以线程超过1600之后,貌似总体性能开始下滑
9)、设置线程池,最大线程3000不变,jmeter线程增加到4000,继续压测(看会不会出现异常)
压测后吞吐量如下
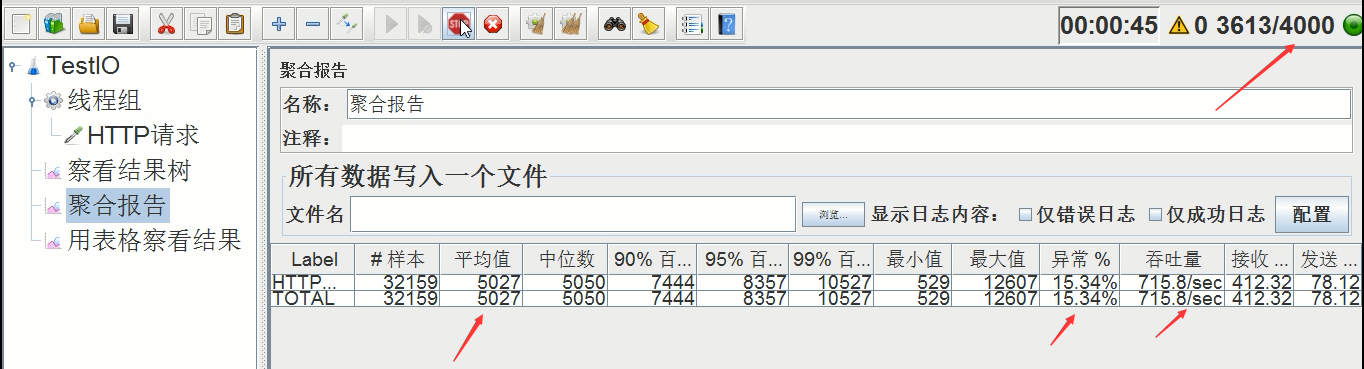
终于出现异常了!
平均时间:5027ms,异常率:15.34%(最大达到50%+),吞吐量:715.8/s
和上次比,时间拉长了近1倍,异常达到15%,吞吐量比上次多了一点 。由此可见,我的机器的极限就是吞吐量在600-700/s,能承受的线程总数也就是在2000-3000之间。
下面还有设置NIO2通道等多种情况的压测性能演示,大家可以观看视频教程,本文不再赘述。
3、总结
性能压测必须经过多次的调试压测,最终才能获得一个较为理想的结果,而且不同的软硬件环境压测出来的结果都是不一样的,所以压测建议在灰度环境压,如果情况允许的话可以直接在生产上压,这样得出的结果更准。
五、Tomcat堆栈中常见线程
Tomcat作为一个服务器来讲,必然运行着很多的线程,而每一个线程究竟是干什么的,这个需要非常的清楚,无论是打印断点,还是通过jstack进行线程栈分析,这都是必须要掌握的技能。 本文带你基于Tomcat7,8,9的版本,识别Tomcat堆栈中的线程。
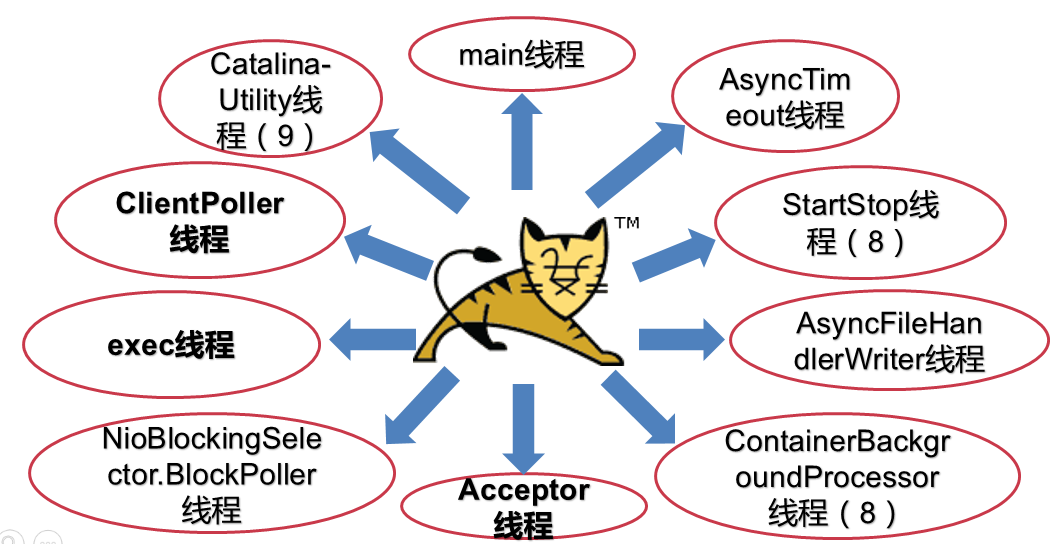
1、main线程
main线程是tomcat的主要线程,其主要作用是通过启动包来对容器进行点火:
main线程一路启动了Catalina,StandardServer[8005],StandardService[Catalina],StandardEngine[Catalina]
engine内部组件都是异步启动,engine这层才开始继承ContainerBase,engine会调用父类的startInternal()方法,里面由startStopExecutor线程提交FutureTask任务,异步启动子组件StandardHost,
StandardEngine[Catalina].StandardHost[localhost]
main->Catalina->StandardServer->StandardService->StandardEngine->StandardHost,黑体开始都是异步启动。
->启动Connector
main的作用就是把容器组件拉起来,然后阻塞在8005端口,等待关闭。
2、localhost-startStop线程
Tomcat容器被点火起来后,并不是傻傻的按照次序一步一步的启动,而是在engine组件中开始用该线程提交任务,按照层级进行异步启动,对于每一层级的组件都是采用startStop线程进行启动,我们观察一下idea中的线程堆栈就可以发现:启动异步,部署也是异步
这个startstop线程实际代码调用就是采用的JDK自带线程池来做的,启动位置就是ContainerBase的组件父类的startInternal():
因为从Engine开始往下的容器组件都是继承这个ContainerBase,所以相当于每一个组件启动的时候,除了对自身的状态进行设置,都会启动startChild线程启动自己的孩子组件。
而这个线程仅仅就是在启动时,当组件启动完成后,那么该线程就退出了,生命周期仅仅限于此。
3、AsyncFileHandlerWriter线程
日志输出线程:
顾名思义,该线程是用于异步文件处理的,它的作用是在Tomcat级别构架出一个输出框架,然后不同的日志系统都可以对接这个框架,因为日志对于服务器来说,是非常重要的功能。
如下,就是juli的配置:
该线程主要的作用是通过一个LinkedBlockingDeque来与log系统对接,该线程启动的时候就有了,全生命周期。
4、ContainerBackgroundProcessor线程
Tomcat在启动之后,不能说是死水一潭,很多时候可能会对Tomcat后端的容器组件做一些变化,例如部署一个应用,相当于你就需要在对应的Standardhost加上一个StandardContext,也有可能在热部署开关开启的时候,对资源进行增删等操作,这样应用可能会重新reload。
也有可能在生产模式下,对class进行重新替换等等,这个时候就需要在Tomcat级别中有一个线程能实时扫描Tomcat容器的变化,这个就是ContainerbackgroundProcessor线程了:
(本地源码StandardContext类的5212行启动)
我们可以看到这个代码,也就是在ContainerBase中:
这个线程是一个递归调用,也就是说,每一个容器组件其实都有一个backgroundProcessor,而整个Tomcat就点起一个线程开启扫描,扫完儿子,再扫孙子(实际上来说,主要还是用于StandardContext这一级,可以看到StandardContext这一级:
我们可以看到,每一次backgroundProcessor,都会对该应用进行一次全方位的扫描,这个时候,当你开启了热部署的开关,一旦class和资源发生变化,立刻就会reload。
tomcat9中已经被Catalina-Utility线程替代。
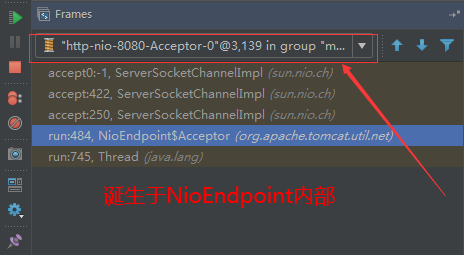
5、acceptor线程
Connector(实际是在AbstractProtocol类中)初始化和启动之时,启动了Endpoint,Endpoint就会启动poller线程和Acceptor线程。Acceptor底层就是ServerSocket.accept()。返回Socket之后丢给NioChannel处理,之后通道和poller线程绑定。
acceptor->poller->exec
无论是NIO还是BIO通道,都会有Acceptor线程,该线程就是进行socket接收的,它不会继续处理,如果是NIO的,无论是新接收的包还是继续发送的包,直接就会交给Poller,而BIO模式,Acceptor线程直接把活就给工作线程了:
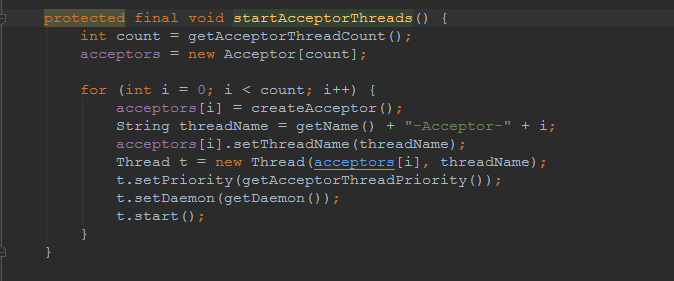
如果不配置,Acceptor线程默认开始就开启1个,后期再随着压力增大而增长:
上述启动代码在AbstractNioEndpoint的startAcceptorThreads方法中。
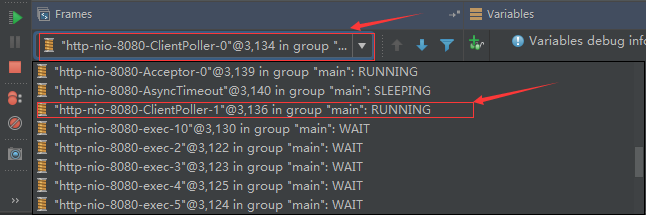
6、ClientPoller线程
NIO和APR模式下的Tomcat前端,都会有Poller线程:
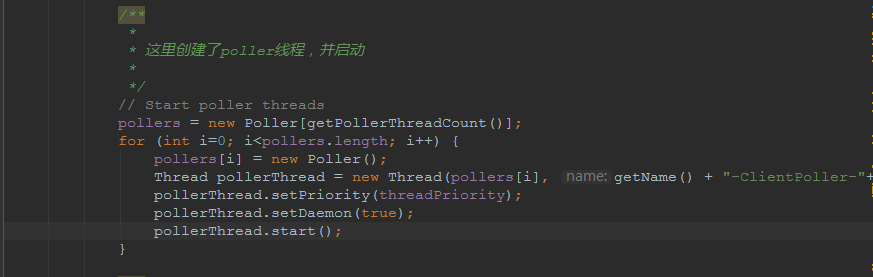
对于Poller线程实际就是继续接着Acceptor进行处理,展开Selector,然后遍历key,将后续的任务转交给工作线程(exec线程),起到的是一个缓冲,转接,和NIO事件遍历的作用,具体代码体现如下(NioEndpoint类):
上述的代码在NioEndpoint的startInternal中,默认开始开启2个Poller线程,后期再随着压力增大增长,可以在Connector中进行配置。
7、exe线程(默认10个)
也就是SocketProcessor线程,我们可以看到,上述几个线程都是定义在NioEndpoint内部线程类。NIO模式下,Poller线程将解析好的socket交给SocketProcessor处理,它主要是http协议分析,攒出Response和Request,然后调用Tomcat后端的容器:
该线程的重要性不言而喻,Tomcat主要的时间都耗在这个线程上,所以我们可以看到Tomcat里面有很多的优化,配置,都是基于这个线程的,尽可能让这个线程减少阻塞,减少线程切换,甚至少创建,多利用。
下面就是NIO模式下创建的工作线程:
实际上也是JDK的线程池,只不过基于Tomcat的不同环境参数,对JDK线程池进行了定制化而已,本质上还是JDK的线程池。
8、NioBlockingSelector.BlockPoller(默认2个)
Nio方式的Servlet阻塞输入输出检测线程。实际就是在Endpoint初始化的时候启动selectorPool,selectorPool再启动selector,selector内部启动BlokerPoller线程。
该线程在前面的NioBlockingPool中讲得很清楚了,其NIO通道的Servlet输入和输出最终都是通过NioBlockingPool来完成的,而NioBlockingPool又根据Tomcat的场景可以分成阻塞或者是非阻塞的,对于阻塞来讲,为了等待网络发出,需要启动一个线程实时监测网络socketChannel是否可以发出包,而如果不这么做的话,就需要使用一个while空转,这样会让工作线程一直损耗。
只要是阻塞模式,并且在Tomcat启动的时候,添加了—D参数 org.apache.tomcat.util.net.NioSelectorShared 的话,那么就会启动这个线程。
大体上启动顺序如下:
//bind方法在初始化就完成了
Endpoint.bind(){
//selector池子启动
selectorPool.open(){
//池子里面selector再启动
blockingSelector.open(getSharedSelector()){
//重点这句
poller = new BlockPoller();
poller.selector = sharedSelector;
poller.setDaemon(true);
poller.setName("NioBlockingSelector.BlockPoller-"+ (threadCounter.getAndIncrement()));
//这里启动
poller.start();
}
}
}9、AsyncTimeout线程
该线程为tomcat7及之后的版本才出现的,注释其实很清楚,该线程就是检测异步request请求时,触发超时,并将该请求再转发到工作线程池处理(也就是Endpoint处理)。
AsyncTimeout线程也是定义在AbstractProtocol内部的,在start()中启动。AbstractProtocol是个极其重要的类,他持有Endpoint和ConnectionHandler这两个tomcat前端非常重要的类
10、其他线程(例如ajp相关线程)
ajp工作线程处理的是ajp协议的相关请求,这个请求主要是用于http apache服务器和tomcat之间的数据交换,该数据交换用的就是ajp协议,和exec工作线程差不多,默认也是启动10个,端口号是8009。优化时如果没有用到http apache的话就可以把这个协议关掉。
Tomcat本身还有很多其它的线程,远远不止这些,例如如果开启了sendfile,那么对sendfile就是开启一个线程来进行操作,这种功能的线程开启还有很多。
Tomcat作为一款优秀的服务器,不可能就只有1个线程,而是多个线程之间相互配合完成功能,而且很多功能尽量异步处理,尽可能的减少线程切换。所以线程并不是越多越好,因此线程的控制也尤为关键。
以上线程的源码分析详细讲解请观看视频
六、NIO连接器前端整体框图
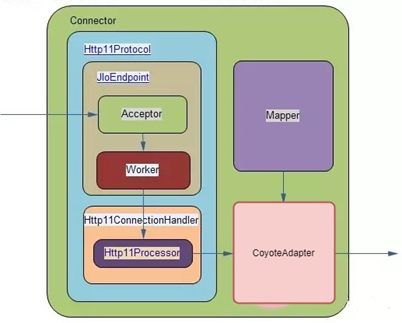
1、图解tomcat总体流程(源码详细分析解读见视频)
连接器在Tomcat中是一个重要的组件,叫做Tomcat前端,这个前端框架不是通常我们讲的Web前端,那是structs,javascript,jsp这些内容,这里讲的是以NIO的方式,来描述从socket请求到Request对象的过程,而我们理解的Tomcat后端,通常是以CoyoteAdapter为分界点,后端框架通过Mapper进行映射,可以总结为下面的示意图:
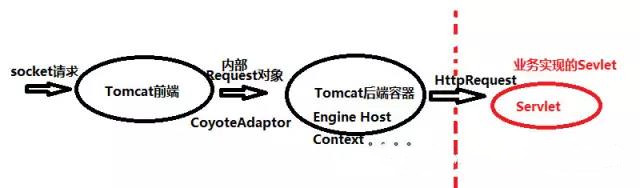
Tomcat前端接受的是Socket请求,通过前端框架组件进行http解析,并基于Connector配置的属性做进一步的处理,转化为Tomcat内部的Request对象。
这个位置相当于是一个分界点,也就是CoyoteAdapter类,之后通过Mapper类直接找到Tomcat后端容器中的对应的Servlet,这其中会传过Engine,Host,Context等各种后端容器组件的解析。
最后,转化为Servlet规范的httprequest,作为参数传到业务实现的Servlet中,完成整个请求的过程。
到这里为止,Tomcat前端这块就很清晰明了,在没有见到架构图之前,我们推测,应该貌似有这些处理机制:
1).应该会有线程池做线程支撑的
2).解析http的组件
3).很多线程池是分开的,例如工作线程池和前端socket处理线程池
4).因为我们这篇文章分析的是NIO,所以肯定会有Selector的内容
下面这两张图就是NIO完整的业务流程图和关键组件架构图
2、图解tomcat前端详细流程(源码详细分析解读见视频)
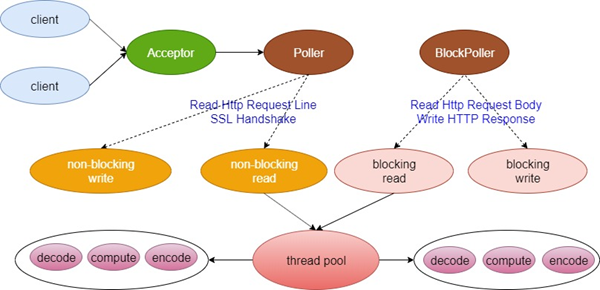
工作流程的源码注释:


3、源码解读tomcat前端关键组件初始化和启动过程(详细分析解读见视频)
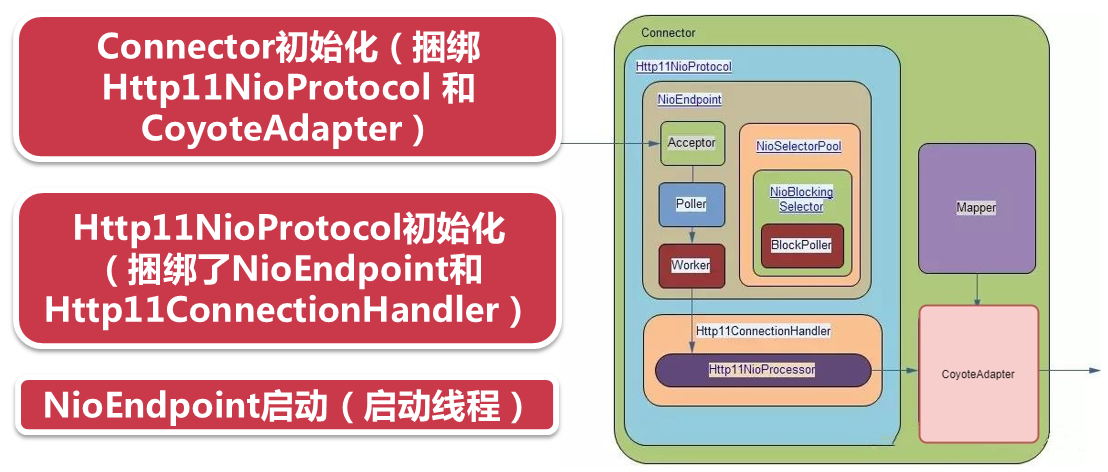
4、Http11NioProtocol(源码详细分析见视频)
http1.1的协议类,实际上这个类的初始化是由对应的Connector类进行初始化,我们可以看看server.xml中关于连接器的配置:

对应的协议是HTTP/1.1,对于Connector来讲,有很多的协议处理器:

对于普通的NIO连接器,其就是Http11NioProtocol这个类。
从源码分析上来看,直接使用当前线程上下文的类加载器进行加载Http11NioProtocol,并对其构造方法进行初始化。
Http11NioProtocol作为协议的实现者,它持有两大组件:
一是Endpoint,默认的就是NioEndpoint,这个类是线程池,socoket的转接类,将NIO通道中的socket组包,交给handler来进行处理。
二就是Handler,也就是Http11ConnectionHandler,设置给Endpoint,这个Http11ConnectionHandler类主要的作用是将前面组包socket包,转换成内部的Request对象,最后发给Tomcat的后端。
这两大组件其实也就是上图的最主要的核心部分,是Tomcat前端框架的灵魂。
该组件详细源码讲解见视频
5、NioEndPoint(源码详细分析见视频)
NioEndPoint类持有三大线程池:
Acceptor(tomcat9版本独立出来了)
PollerEvent
Poller(相当于是reactor)
Worker(exec即SocketProcessor)
从以下类的注释就可以看出来:
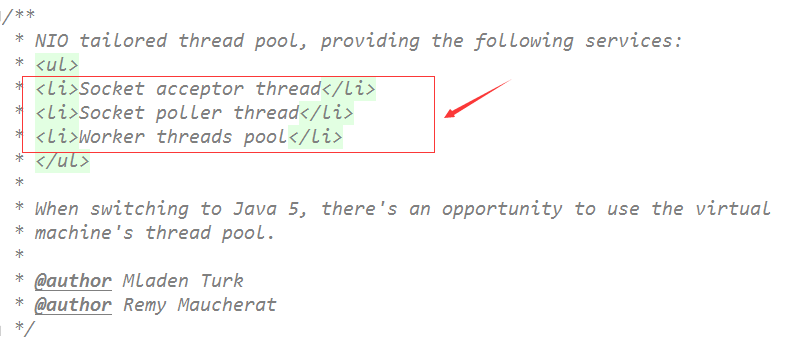
a.socket acceptor线程池
这个线程池中里面的每一个线程中运行的就是NioEndPoint.Acceptor类。这个Acceptor主要的作用并不是直接将这个socket的流取过来,双方进行交互,如果这么做的话,那Tomcat基本就和一个普通的socket程序没有什么区别了。
这个Acceptor首先根据是否是SSL配置,使用Tomcat自身扩展的NioChannel来包装SocketChannel,之所以包装的目的是要给对NIO的channel加很多的功能,NioChannel持有socketChannel的一个引用,如果是SSL配置的话,那么就启用的是SecurityNioChannel类进行包装。
b.PollerEvent数组
PollerEvent是poller线程池处理的任务单元,这个类也是一个Runable线程。
PollerEvent不单单还有前面包装的NioChannel,还持有NioEndPoint.KeyAttachment类的一个引用,KeyAttachment类的作用主要是对Connector中的一些socket属性进行解析,然后设置到对应的SocketChannel通道中。
因为Tomcat作为前端的服务器,网络请求很多,所以对于一个Poller线程池,上述的从Acceptor过来的PollerEvent事件会非常的多,因此这里采用一个队列的模式做一下缓冲
c.socket poller线程池
Poller中维护者的是一个Selector对象,其实在Tomcat的前端中存在了n多个的Selector对象,当前这个Selector主要是用于从Acceptor传过来的NioChannel进行感兴趣事件的NIO注册操作,并轮询感兴趣的事件发生。
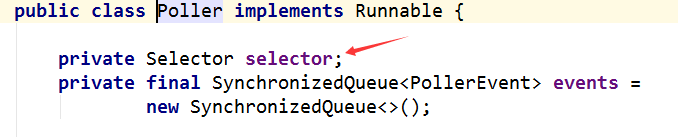
这里还有一个Queue队列,这里采用的是SynchronizedQueue,需要注意的是,这里并不是JDK包中的SynchronizedQueue同步队列,而是tomcat中自定义实现的SynchronizedQueue,不要产生混淆,实现思路很简单,就是一个普通的数组演变的。
总结一下就是,poller线程主要是完成了NIO的selectkey的操作,这一步比较关键,之所以在前面又加了一个Acceptor线程,是因为每一次数据报进来后,都需要对其进行“加工一下”,再转发给poller进行selectkey感兴趣事件的获取。
到这里为止,poller线程仍旧没有进行处理,它继续将接力棒交接给工作线程池。
d.工作线程池
poller线程中最后一步时候processKey方法,这个方法最终会调用processSocket方法:
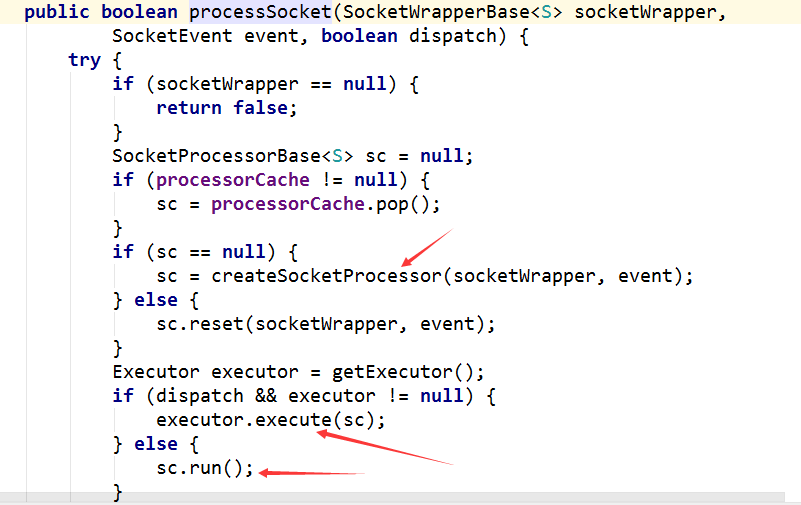
SocketProcessor是工作线程池中的工作方法,上述工作线程池中一共有两个选择,当JDK5之前,SocketProcessor类本身也是一个Runable线程,直接可以执行run方法,这就没有什么线程池的概念了;而在JDK5之后,ThreadExecutor是JDK默认的线程池,Tomcat中集成了进来,也就是调用其executor.execute方法,将SocketProcessor任务传进去。
对于Tomcat的工作线程池的分解,在前面已经做过专题的讲解。
SocketProcessor任务中,一共分两个步骤,第一步是进行socket的handshake,也就是握手,对于正常的http来讲没有什么多余的操作,对于SSL可以看到在握手阶段,按照SSL的会话的交互,双方进行密码协商,这一步默认的话是调用JSSE的SSLEngine进行交互,返回SSLEngineResult,当握手成功后,该请求就可以交给给handler进行处理,这个handler就是下面要讲的Http11ConnectionHandler。
6、Http11ConnectionHandler(源码详细分析见视频)
Http11ConnectionHandler两个分析重点:
1)、Http11ConnectionHandler持有Http11NioProcessor类,Http11NioProcesso负责解析http协议。
2)、Http11NioProcesso解析完http协议,攒出request和response传递给CoyoteAdaptor,经过容器层层转发后抵达业务Servlet。
到这里为止,NIO的前端的逻辑就完成了。
7、总结
NIO的前端框架主要是由三个不同的线程依次分工协作:
1)、Acceptor线程将socketchannel取出, 传递给Poller线程(会产生线程阻塞,因此包装成PollEvent加入缓存队列)。
2)、Poller线程执行的就是NIO的selectkey,拿到通道中感兴趣的事件,轮询获取,然后将感兴趣的selectkey和keyattachment传递给工作线程池进行处理。 3)、工作线程池调用http11ConnectionHandler进行http协议的解析,然后将解析出来的内容包装成Request,Reponse对象,传递给分界点CoyoteAdapter,最终执行到业务中。
七、BIO连接器前端整体框图
1、BIO框图源码解读(tomcat8.5后抛弃)(源码详细分析解读见视频)
上一讲讲解过NIO的框图,可以看到,NIO通道是目前Tomcat7以后的默认的通道的推荐配置,在Tomcat6和以前的配置中,BIO是主流的配置。
只需要修改protocol协议部分即可,而后续还有APR协议,NIO2.0的协议,都是修改这个字段。
对于BIO的整体框图,基本和NIO保持类似,整体流程变化不大,如下图所示:
2、Http11Protocol类详解
与NIO一样,这个Http11Protocol是默认的BIO的http1.1协议的处理类,Tomcat除了有NIO,BIO,其实还有两个通道:
1)、APR是高性能通道,
2)、NIO2是基于纯异步IO的通道,这个会在后面的Tomcat中进行讲解。
Http11Protocol类中,依然持有Endpoint和handler的引用,只不过,BIO对应的Endpoint是JIOEndpoint,对应的handler是Http11ConnectionHandler。
3、JIoEndPoint(tomcat7.x版本)
JIoEndpoint是BIO的端点类,它和NIO一样,也是维护着线程池,只不过因为没有Selector.select,没有SocketChannel的通道的注册,所以相比NIO模式,没有Poller线程是非常容易理解的,反倒是NIO的三个线程不容易理解,BIO可以看做就是基于Socket进行操作。
首先,初始化的JIoEndpoint的时候,会调用bind方法绑定Serversocket到对应的端口,bind方法是初始化构造JIoEndpoint的重要步骤,他的主要作用就是建立ServerSocketFactory。
根据SSL信道或者是普通的http的信道,Tomcat都实现了ServerSocketFactory,普通的http通道的ServerSocketFactory就是DefaultServerSocketFactory类,其工厂方法就是创建ServerSocket,很容易理解。
对于SSL通道的ServerSocketFactory是JSSEServerSocketFactory这个类创建的是SSLServerSocket。
其次,JIoEndpoint启动的时候,会将Acceptor线程和工作线程池启动起来。
除此之外,还启动了一个专门的线程,这个线程就是检查异步请求的Timeout的,后续会有专门的介绍针对于Tomcat的异步请求。
工作线程池,使用的就是JDK自带的ThreadPoolExecutor。
可以从线程的堆栈看到,对应的http-bio-8443-exec-n 这种线程都是工作线程池。
如果在tomcat中没有指定工作线程池的设置,那么都走的是JDK自带的ThreadPoolExecutor的默认值。
JIoEndpoint是BIO的端点类,它和NIO一样(NIO里面是NioEndpoint),也是维护着线程池,只不过因为没有Selector.select,所有只有2个线程池:
1)、acceptor
2)、worker(exec)
4、Acceptor线程
Acceptor线程的主要作用和NIO一样,如果没有网络IO数据,该线程会一直serversocket.accept阻塞住。
当有数据的时候,首先将socekt数据设置Connector配置的一些属性,然后将该接力棒传递给工作线程池。
最后一步processSocket方法,也是非常简单。
直接调用工作线程池,将SocketProcessor作为工作任务传入到工作线程池中执行。
这一步相比NIO的架构,缺少了NIO通道中的PollerEvent一个缓存队列,NIO中有这样的一个队列是因为需要从Acceptor到Poller线程,中间传递需要一个缓存的地方,而可以看到上述的BIO中的代码,如果工作线程池已经满载了,会根据JDK的ThreadPoolExecutor的策略是缓存,还是直接拒绝,或者是timeout等待,只不过BIO将这块的策略决断交给了ThreadPoolExecutor来做了。
对于Acceptor线程中还有一个重要的作用,就是控制连接的个数,这个在NIO通道的分析中没有讲解,这里看一下,Acceptor线程在while轮询的时候,每一次最开始都会检查一下当前的最大的连接数超出没有,如果超出了,就直接按照既定的序列调用LimitLatch进行锁定。
我们发现,实际上LimitLatch也是模仿JDK中的读写锁,内部持有一个Sync的类,这个类继承了JDK中隐藏功与名的AQS队列,这个AQS队列还是比较著名的,之前我的课中在分析JDK源码的时候,多次在n个并发类中都看到过他的踪迹,其实现几乎全部是CAS锁的实现。
5、SocketProcessor线程
SocketProcessor是工作任务,用于传入到工作线程池中,输入就是Acceptor传过来的socketWapper包装。
如果是SSL交互的话,Tomcat开放了握手的这个环节,但是并没有对应的实现,这个是因为SSL下的握手实现在SUN的包中做的,JDK提供的SSLServerSocket的接口已经隐藏了这个细节,我们可以从handshake这个第二步看到(这部分视频中有详细分析)
Tomcat中直接就可以拿到SSLSession,这个类可以获得相当于SSL已经是握手成功了,否则就会出现失败。
对于为什么保留beforeHandShake和handshake这两个步骤,是为了和NIO通道中的SSLEngine交互的接口做个兼容而已。
暂且不用管它,最重要的步骤就是第3步,也就是handler.process这一步,通过Http11ConenctionHandler进行处理http协议,并封装出Response和Request两个对象,传递给后端的容器。
SocketProcessor工作任务就是将Acceptor传过来的socketWapper包装传入到工作线程池中。
6、总结
BIO的流程基本上和NIO通道一样,BIO的结构因为缺少了selector和轮询,相比NIO少了一部分的内容,整体上就是使用的ServerSocket来进行通信的,一线程一请求的模式,代码看起来清晰易懂。但是,由于BIO的模型比较落后,在大多数的场景下,不如NIO,而现在Tomcat新版本也是NIO是默认的配置,8.5版本之后完全抛弃了BIO通道。
八、Tomcat的BIO和NIO通道及对性能的影响
1、BIO的缺点
前面两个章节,我们分别看了BIO和NIO两种Tomcat通道的实现方式。
BIO的方式,就是传统的一线程,一请求的模式,也就是说,当同时有1000个请求过来,如果Tomcat设置了最大Accept线程数为500,那么第一批的500个线程直接进入线程池中进行执行,而其余500个根据Accept的限制的数量在服务器端的操作系统的内核位置的socket缓冲区进行阻塞,一直到前面500个线程处理完了之后,Acceptor组件再逐步的放进来。
分析一下,这种模式的好处就是可以让一个请求在cpu轮转时间片切换中最大限度的执行,如果业务请求不是很长时间的事务处理,通常在一个时间片内肯定能做完当前的请求,这样的效率算是相当的高了,因为其减少了最耗时也是最头疼的线程上下文切换。
1.但是,如果事务执行比较长的时间,例如等待一个IO数据库的操作,那么这个工作线程就会根据cpu轮转不断的进行切换,因为请求数在大并发的时候有很多,所以不得不设置一个很高的Accept线程数,那么从cpu的耗费的资源上来看,甚至有70%的时间浪费在线程切换中,而没有真正的时间去做请求处理和业务,这是第一个问题。
2.其次,BIO每一次链接的建立和释放都需要重新来过一遍,例如一个socket进来之后,通常会对其SocketOptions的属性进行设置,包括各种Connector中配置都要与其进行一一对应,加上前面说的socket的建立,很多请求通道的资源的初始化都得重新创建,得不到复用,这个是第二个问题。
3.最后,BIO的方式,网络IO的阻塞等待是会让Accept线程工作效率降低很多的。
所以,基于这3个问题,特别是最后一个问题,引出了NIO的模型。
总结一下就是:
1、如果IO处理时间长,那么bio大多数时间耗在线程切换中
2、IO通道得不到复用
3、Acceptor线程工作效率较低
2、NIO的解决之道
NIO的架构分为三个线程池,这里再次梳理一下:
1).Acceptor专门接socket请求,当发现又请求进来后,基于Tomcat配置的SocketOptions和一些属性的设置完毕,包装成SocketChannel,也就是NIO的socket通道抽象,塞入PollerEvent直接扔到队列当中。
2).Poller线程从队列中挨个获取PollerEvent,调用Poller线程自己持有的selector选择器,注册SocketChannel到当前的selector选择器中,然后进行selectKey的工作,这样Acceptor传递过来的SocketChannel中感兴趣的事件,就会被轮询出来,当接收事件接收之后,需要注册OP_READ事件或者OP_WRITE事件,当OP_READ事件或者OP_WRITE事件发生时,开始调用工作线程池。
3).工作线程池就是SocketProcessor,这个就是具体的工作线程,SocketProcessor的任务就是Poller线程从SocketChannel通道中轮询出来的数据包,进行解析,传递给后端的handler进行http的解析,解析出来的Request,Reponse对象,,直接调用CoyoteAdapter传递到后端的容器,通过Mapper,映射到对应的业务Servlet中。可以看到,从SocketProcessor一直到最终的业务Servlet实现,这些都是一个线程,这个线程就是工作线程。
对比Tomcat的BIO的架构,因为没有selector轮询的操作,所以并没有Poller线程,BIO中的Acceptor线程的作用依然是对socket简单的处理和属性包装,然后将socket直接扔到工作线程中来。NIO相当于是多了一个线程池,从流程上来讲,应该是多了一道手续,但是通过NIO本身基于事件触发的机制造成,Acceptor线程没必要设置的过多,这样从线程的数量上来看,大大的减少线程切换的频率,其次基于事件进行触发,将Acceptor线程执行效率中的网络IO延迟降低到最低,大大提升了Acceptor线程的执行效率。从这两点上来看,Tomcat的NIO在前面分析的BIO的三个问题中第一个问题,和第三个问题都有所改善,特别是第三个问题,全面进行了升级。
但是,对于BIO中的第一个问题,由后端事务时间过长导致工作线程池一直在运行,并且运行在一个高峰的数值,不断的进行切换,这种问题,NIO通道也没办法进行处理,这个是由业务来决定的,NIO只能保证降低的是Acceptor线程线程数,对业务帮助也是无能为力的,如果要提升这部分的效率,那就需要应用进行修改,优化JDBC和数据库,或者将业务切段来做,让事务时间尽量控制在一个可控的范畴之内。
对于第二个问题,无论是单纯的NIO和BIO通道都没有办法进行解决,但是HTTP协议中对链接的复用进行更新,在HTTP1.1中,这个keepalive是加到http请求头中的:
Keep-Alive: timeout=5, max=100 timeout:过期时间5秒(对应httpd.conf里的参数是:KeepAliveTimeout);
max是最多能承受一百次请求的共享复用,就是在timeout时间内又有新的连接过来,同时max会自动减1,直到为0,强制断掉。
对应的Tomcat的服务器端的配置:

keepAliveTimeout:表示在下次请求过来之前,tomcat保持该连接多久。这就是说假如客户端不断有请求过来,且为超过过期时间,则该连接将一直保持。
maxKeepAliveRequests:表示该连接最大支持的请求数。超过该请求数的连接也将被关闭(此时就会返回一个Connection: close头给客户端)。
如果配置了上述的内容,可以解决BIO上面提出的第二个问题,当一个页面中的第一个请求后,后面的连接可以复用这个socket或者是socketchannel,不用再accept三次握手或者SSL握手了,相当于高效的推动了整体Tomcat的时间链条的处理效率,而对于keepAlive属性的加入,通过BIO和NIO对比测试发现,相当于放大了NIO的优势,导致NIO的测试结果要明显高于BIO一个水平线上,这也就是目前http1.1协议中,为什么Tomcat后续版本默认就是NIO的原因;而如果没有keepAlive属性加入,在大多数的场景下,NIO并没有拉开与BIO太大的差距,甚至有一些场景上,Tomcat的BIO模式反倒是比NIO要高。
这里单纯的对比性能没有任何的意义,因为性能测试是测试在不同应用类型,不同硬件环境,不同软件版本,甚至是不同jdk性能差异都很大,客观因素很多。
NIO优点总结一下就是:
增加了poller线程池做轮询
提高了acceptor执行效率
3、NIO vs BIO(详细分析及演示见视频)
以下4个场景分别是:单线程BIO,多线程BIO,模拟NIO,NIO
4个场景最大的不同就是处理IO流部分,所以性能的高低直接取决于如何处理IO这一步。
因为演示步骤比较复杂,详细的分析请大家观看视频,这里不再赘述了。
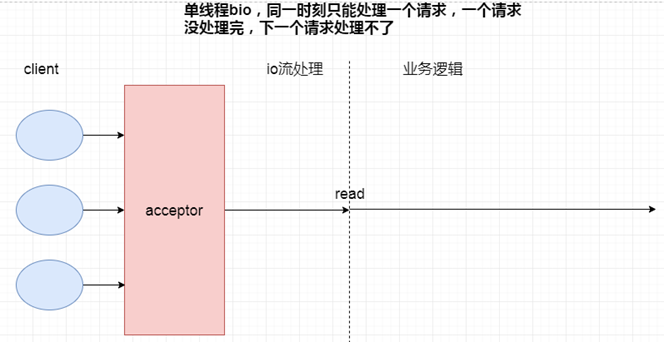

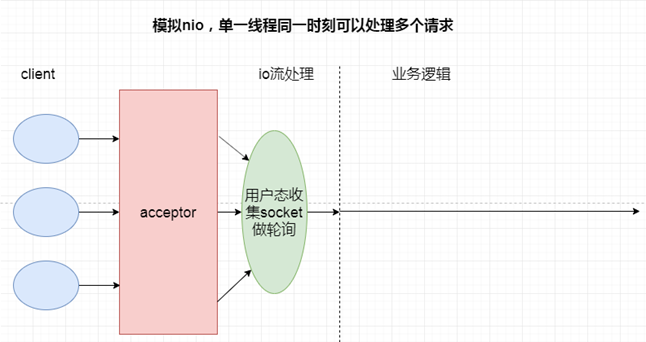
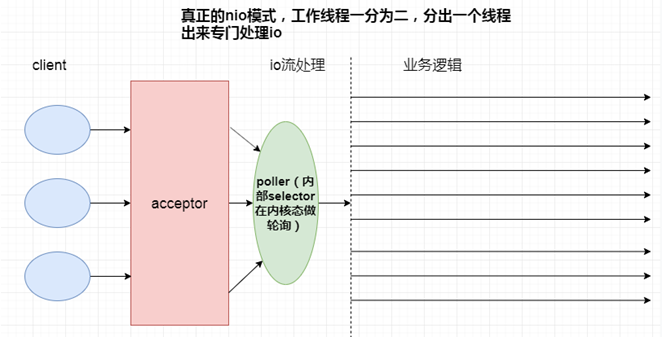
4、总结
1)、BIO比NIO少了poller线程池的轮询机制,请求模式为一线程一请求的模式,这就导致了BIO中存在大量的线程上下文切换。
2)、NIO的多路复用的本质是用更少的线程处理多个IO流。
九、Tomcat中NIO2通道原理及性能
从Tomcat8开始出现了NIO2通道,这个通道利用了NIO2中的最重要的特性,异步IO的java API。
从性能角度上来说,从纸面上看该IO模型是非常优秀的,这也是很多书籍推崇的最优秀的IO模型,例如《Unix网络编程》这本圣经,但取决于目前操作系统的支持程度和环境,还有业务逻辑代码的编写,NIO2的程序调用并不一定比NIO,甚至比BIO的效率要高。
我们在没有实测的情况之下,本文从源码的角度去分析一下Tomcat8中的这个NIO2通道,后续在相应的章节中,我们会进一步的分析一下Tomcat的4个通道的性能差异。
1、NIO2的框图源码解读(源码详细分析解读见视频)
前面我们已经了解了Tomcat的BIO,NIO,APR这三个通道,对于NIO2的通道框图大体上和这些没有太大的区别,如下图所示,少了一个poller线程,多了一个CompletionHandler。
和其他通道一样,Tomcat最前端工作的依然是Endpoint类中的Acceptor线程,该线程主要任务是接收socket包,简单解析并封装socket,对其进行包装为SocketWrapper后,交给工作线程。
在NIO2的通道下,Acceptor线程结束之后,并不会直接调用工作线程也就是SocketProcessor,而是利用NIO2的机制,利用CompleteHandler完成处理器去异步处理任务。
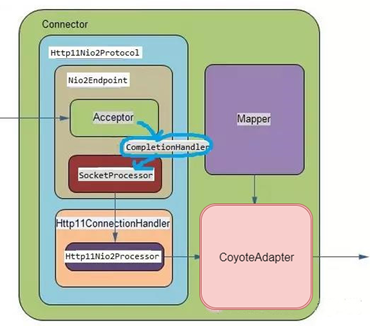
这正是CompleteHandler完成处理器的一个特性。
再对比NIO,BIO两个通道:
我们不用像BIO通道那样去拿着SockerWrapper在工作线程进行阻塞读,这样工作线程中的时间会占据网络IO读取的时间,导致大并发模式下工作线程暴涨,这也就是经常我们看到很多cpu为什么被占到99%的原因,再怎么设置工作线程无济于事,因为大量的cpu线程切换太耗时间了;
而NIO通道采用Reactor的模式去做这个事,Selector承担了多路分离器这个角色,对于BIO是一大改进,其次java NIO的牛B之处就是操作系统内核缓冲区的就绪通知;
2、异步IO的运用(具体源码分析见视频)
经过以上分析我们得知三件事:
1).NIO2这种纯异步IO,必须要有操作系统支持,并且性能和这个内核态的事件分离器有着非常大的关系。
2).对于内核分离器通知CompleteHandler的时机是什么,对比NIO的缓冲区,实质是当内核态缓冲区的数据已经复制到用户态缓冲区时候,这个时候触发CompleteHandler,这相当于比NIO的模式更进一步,如下图:
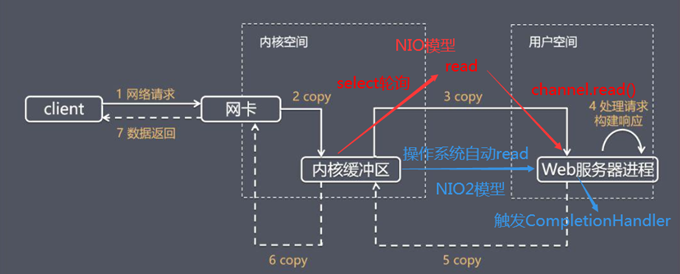
NIO只是内核缓冲区就绪才告诉客户端去读,这个时候用户态缓冲区是空的,你得执行完socketChannel.read之后,用户态缓冲区才会填满;
3).因为NIO2的优势,事件分离器分离器实际是在操作系统内核态的功能,所以不需要用户态搞一个Selector做事件分发。因此,对比NIO的通道框图,可以看到缺少了Poller线程这一个环节。
以下是部分源码解析(详细解析见视频)
从代码的角度来看看,Tomcat的NIO2的通道,主要集中在NIO2Endpoint这个类的bind方法。
关注两个点:
1).AsynchronousChannelGroup是异步通道线程组,通过这个类可以给AsynchronousChannel定义线程池的环境,而ExecutorService就是Tomcat中的特有的线程池。
TaskQueue是队列,Thread工厂针对于创建的线程名称进行了一下修改,并且对于线程池的最大,最小,时间都进行了限定,这个线程池在BIO,NIO通道中也是这个,都是一样的。
定义完AsynchronousChannelGroup的通道线程组,AsynchronousChannel的read就是运行在通道组中的线程组中,包括从操作系统的内核态多路分离器响应的CompleteHandler,也是从该线程池中取出线程进行运行,这个是很重要的,如果每一次都new Thread的话,会有很大的消耗,所以不如都放在一个线程组中随取随用,用完再还;
2).随即开启 AsynchronousChannel通道,并绑定到对应的端口中,这个API使用的就是JAVA NIO2的API。
之后,Acceptor线程获得socket包,直接进行包装为SocketWrapper,之后的流程如第一节中的源码分析一样,随着读取的执行,异步操作就执行完了,转而Acceptor线程进行下一个循环,读取新socket包;
这时候需要注意的是,在NIO模式下,这个时刻是将SocketWrapper扔给Poller线程,Poller线程中的Selector去轮询key值,而不是NIO2这种的直接就不管不问了,从这一点上也可以看出,NIO2的异步优势就在这,事件触发的机制直接由内核通知,我搞一个CompleteHandler就行,无需在用户态轮询。
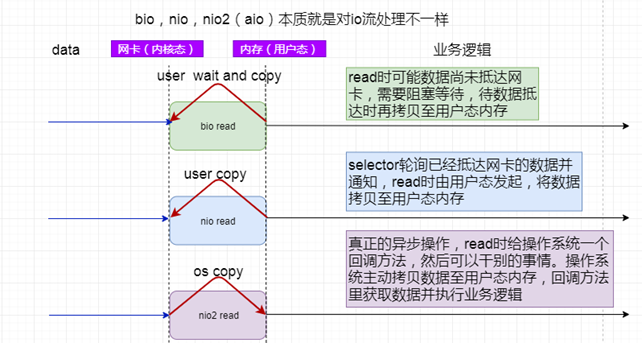
3、总结
由下图可见,bio,nio都是由用户态发起数据拷贝(read操作),而nio2(aio)则是由操作系统发起数据拷贝,所有的io操作都是由操作系统主动完成。所以io操作和用户业务逻辑的执行都是异步化的。
所以从账面上来讲,NIO2通道相比NIO效率高,因为proactor模式本来就比reactor模式要好,另外还省去了Poller线程,但由于多路事件分离器是内核提供的,不同内核提供的多路事件分离器的事件处理效率不一,对NIO2的通道需要基于实际环境和场景压测才能得出最终的结论。
在后续的章节中,会对Tomcat各通道进行压力实际测试对比,并基于各个通道的实测结果进行详细的对比和分析。
十、APR通道到底是个怎么回事?
APR通道是Tomcat比较有特色的通道,在早期的JDK的NIO框架不成熟的时候,因为java的网络包的低效,Tomcat使用APR开源项目做网络IO,这样有效的缓解了java语言的不足,提供了一个高性能的直接通过jni接口进行底层IO通信内存使用的这么一个通道。
但是,当JDK的后续版本推出之后,JDK的网络底层库的性能也上来了,各种先进的IO模型,线程模型和APR开源项目几乎不相上下,这个时候,经常会出现一种测试场景是,加上APR通道之后并没有太多的实质提升,这是可以理解的,但是JDK中的SSL信道的性能至少从目前的角度来看,和APR通道基于openssl的引擎信道实现,还有不小的差距,因为SSL协议中定义的握手协议,交互次数比较多,而openssl项目经历多年,性能极为高效,因此从目前的Tomcat的APR通道来看,主推的就是这个SSL/TLS协议的高效支持。
1、TomcatAPR通道的架构图
APR通道底层最终是通过tomcat-native实现的,具体的源码分析讲解请观看视频
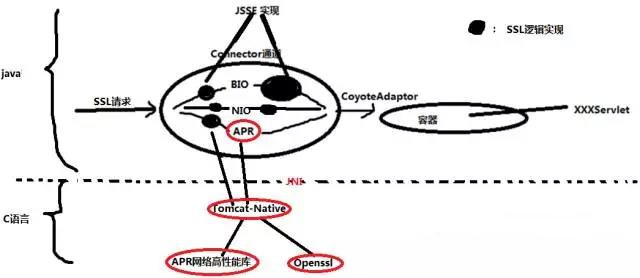
2、APR通道详解(见源码分析视频)
从上图中可以看到,对于Connector通道总共有这么几种通道:BIO是阻塞式的通道,NIO是利用高性能的linux(windows也有)的poll或者epoll模型,APR通道就是本文中讲的内容,对于目前的JDK还支持NIO2的通道,对于APR来讲,SSL Support区别最大,使用的是openssl作为SSL的信道支持,另外从IO模型角度来看,对于Http请求头的读取,SSL握手因为调用的JNI也是阻塞的,这个是与NIO和NIO2的差距,但是从SSL信道的支持上用的是高效的openssl。APR通道中依然有Acceptor接收线程池,Poller轮询,Worker工作线程池,这些和其它通道的架构区别不大,重要的是其关于socket调用和SSL的握手等内容。这部分的源码分析见视频
总之一句话
APR通道的Socket全部来自c语言实现的socket,非jdk的socket,直接在tomcat层级调用native方法。
APR通道的SSL信道上下文直接来自于native底层
3、Tomcat-Native子项目
tomcat中对于这些jni的调用部分,做出了一个tomcat的子项目,叫做Tomcat-native,在这个调用层级中,一部分是java部分,也就是AprEndpoint类中看到的native方法,这些native方法有很多,这些java的包,对应调用的就是jni的native的C的代码,是一一对应的,如下图所示:
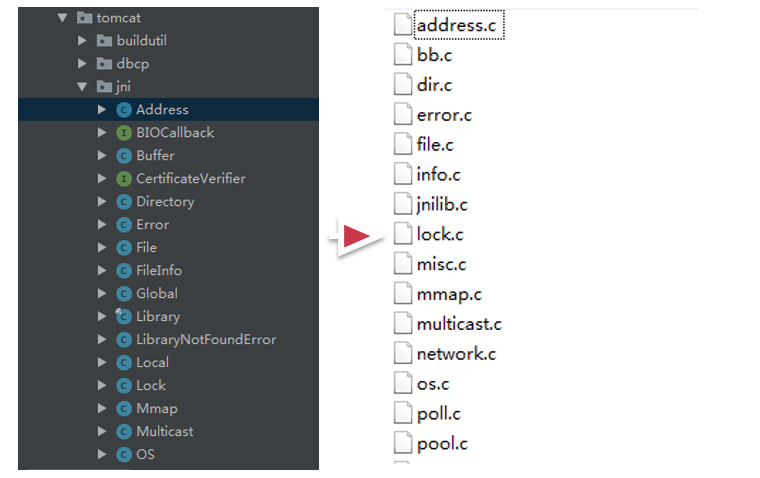
对于tomcat-native最好的教程应该是在example目录中,这个目录使用一个例子完整的复现了Tomcat前端APREndpoint的几个线程组件的工作模式;对于test目录也可以从这个点切入进去,是一个好的调试tomcat-native代码的过程。
4、APR高性能网络库(Apache Portable Runtime (APR) project)
下载:https://mirrors.cnnic.cn/apache/apr/apr-1.6.5.tar.gz
tomcat-native项目,可以说是作为一个集成包,有点类似于TomEE对于JAVA EE规范的集成,它集成的内容一个是openssl,这个是ssl信道的实现,另外一个就是高性能的apr网络库。
Apache Portable Runtime (APR) project,这个库定位于在操作系统的底层封装出一层抽象的高性能库,在于屏蔽掉操作系统的差异。可以分析出来,APR相当于JDK的一个角色了,只不过它关注的大多在网络IO相关的这块,有原子类,编解码,文件IO,锁,内存申请与释放,内存映射,网络IO,IO多路复用,线程池等等。APR库对众多操作系统都有支持。
总结一下就是,APR提供了对于底层高性能的网络IO的处理,可以解决Tomcat早期网络IO低效的问题。
5、Openssl库
tomcat-native除了调用APR网络库保证高性能的网络传输以外,对于SSL/TLS的支持还调用了openssl。对于OpenSSL项目来说,市面上大多数的SSL信道实现都是用OpenSSL做的,这也就是说,如果要OpenSSL暴露出一个漏洞出来,那破坏性都是惊人的。
6、总结
APR通道只有很小的一部分是java,大部分的源码都是C的,而且和操作系统的环境有着密切的关系,不同操作系统定制的接口不同,性能特色也不同。
如下图所示,java这一层调用的是jni,相当于是一个接口,然后底层tomcat-native,相当于是实现,只不过是用c实现的,然后apr和openssl又是独立的c组件。
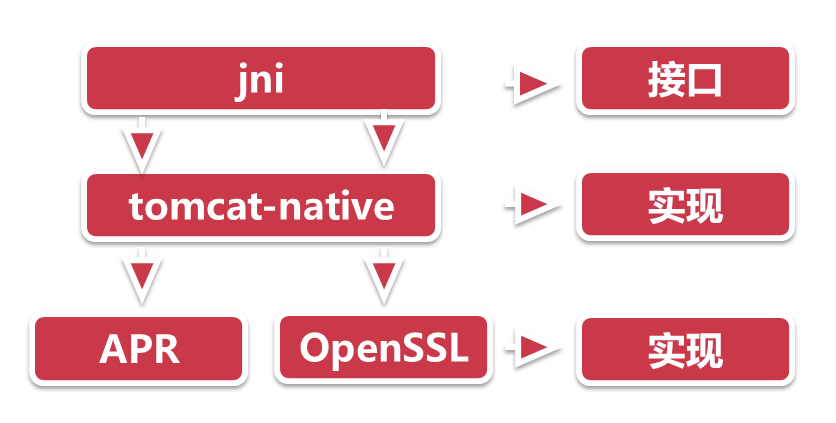
十一、Tomcat中各通道的sendfile支持
sendfile实质是linux系统中一项优化技术,用以发送文件和网络通信时,减少用户态空间与磁盘倒换数据,而直接在内核级做数据拷贝,这项技术是linux2.4之后就有的,现在已经很普遍的用在了C的网络端服务器上了,而对于java而言,因为java是高级语言中的高级语言,至少在C语言的层面上可以提供sendfile级别的接口,举个例子,java中可以通过jni的方式调用c的库,而这种在tomcat中其实就是APR通道,通过tomcat-native去调用类似于APR库,这种调用思路虽然增大了java调用链条,但可以在java层级中获得如sendfile的这种linux系统级优化的支持,可谓是一举多得。
上述的内容,实际就是本章的背景,本文就从系统调用的层级,逐步讲解tomcat中的sendfile是怎么实现的。
1、传统的网络传输机制
大家可以在linux上执行 man sendfile 这个命令,查看sendfile的定义
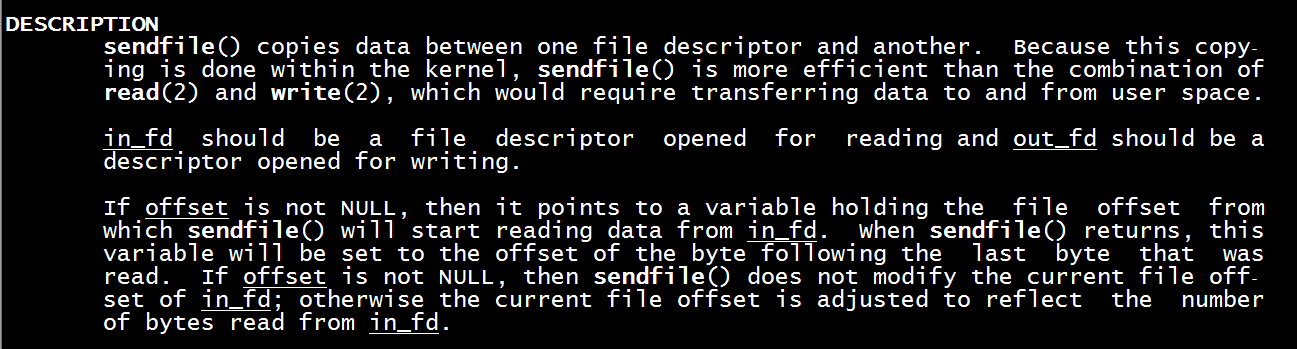
上述定义可以看出,sendfile()实际是作用于数据拷贝在两个文件描述符之间的操作函数.这个拷贝操作是在内核中完成的,所以称为"零拷贝".sendfile函数比起read和write函数高效得多,因为read和write是要把数据拷贝到用户应用层操作,多了一个步骤,如下图所示:
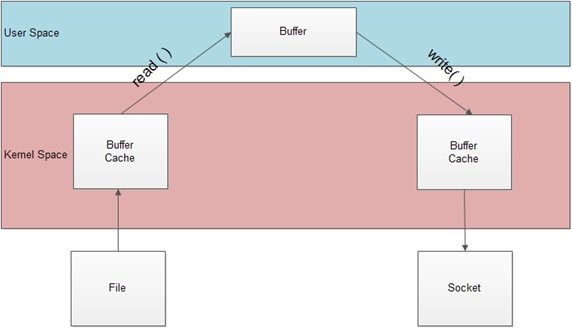
那么经过sendfile优化过的拷贝机制如下图所示,直接在内核态拷贝,不用经过用户态了,这大大提高了执行效率。
2、linux的sendfile机制(零拷贝)
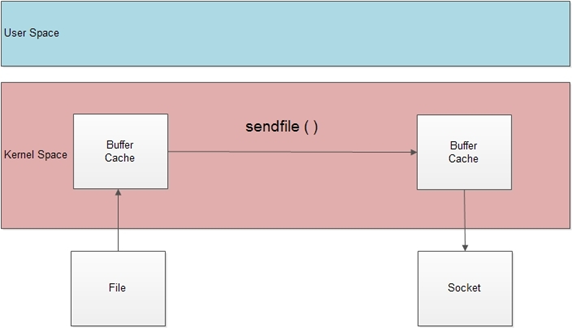
3、DefaultServlet的sendfile逻辑(具体源码跟踪分析见视频)
对于Tomcat中的静态资源处理,直接对应的就是DefaultServlet了,这个类是嵌入在Tomcat源码中,专门处理静态资源的类,静态资源一般不需要经过处理(也就是不需要拿到用户态内存中去)直接从服务器返回,所以此类文件最适合走sendfile方式,以下是DefaultServlet中和sendfile相关的源码逻辑。
这部分源码详细分析请查看视频
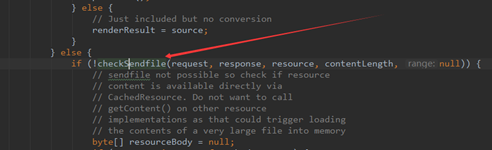
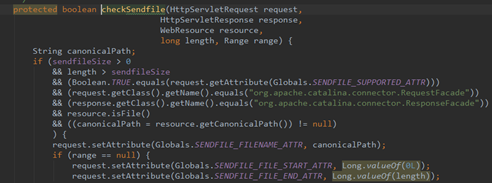
值得注意的一点是,一般http响应的数据包都会进行压缩,这样的好处是能极大的减小带宽占用,而响应头中发现了compression压缩属性,浏览器会自动首先进行解压缩,从而正确的将response响应主体刷到页面中。
但是,当sendfile属性开启后,这个compression压缩属性就不生效了(后面一章会讲解sendfile和compression的互斥性),因此,当需要传输的文件非常大的时候,而网络带宽又是瓶颈的时候,sendfile显然并不是合适之举。
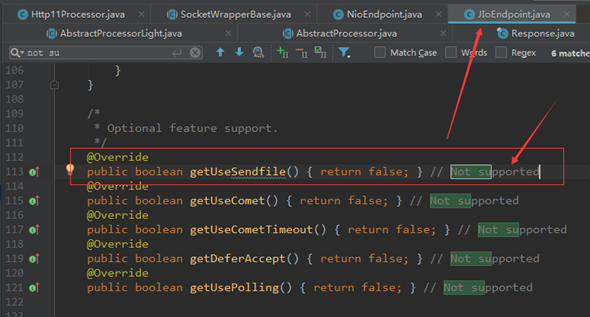
4、sendfile在BIO通道中的实现(不支持)(具体源码跟踪分析见视频)
以Tomcat9为例,不同的Tomcat前端通道中的sendfile的java包装是不同的,但实际上都是在调用系统调用sendfile。
对于BIO(从tomcat8开始已经抛弃BIO通道了,下面源码截图来自于tomcat7)来说,JIOEndpoint是不支持sendfile的,这个可以通过代码中看出来:
5、sendfile在NIO通道中的实现(具体源码跟踪分析见视频)
在NIO通道中,有一个useSendfile属性,这个useSendfile属性是做什么的呢?
这个是可以设置在Connector中的,以NIO通道为例,这个useSendfile属性是允许request进行sendfile的总体开关(前面讲的org.apache.tomcat.sendfile.support 属性是针对于每一个request的),这个useSendfile属性在NIO通道中默认就是打开的,当reqeust设置org.apache.tomcat.sendfile.support 属性为true的时候,response就会准备一个SendFileData的数据结构,这个数据结构就是NIO通道下的sendfile的媒介。
因此,NIO的sendfile实现可以分为三个阶段(具体的源码解析请查看视频):
第一阶段,实际上就是前面的XXXDefaultServlet中(不仅仅是DefaultServlet,其它的Servlet只要设置这个属性也可以调用sendfile)对Request的sendfile属性的设置,当该请求设置上述的属性后,证明该请求为sendfile请求。
第二阶段,servlet处理完之后,业务逻辑完成,对应的Response该commit了,而在Response的准备阶段,会初始化这个SendFileData的数据结构,这块的代码逻辑都在Http11NioProcessor类中,下图中的prepareSendfile方法就是从前面DefaultServlet中设置的reqeust属性中拿到file名称,字符位置的start,end,然后将这些属性作为传入的参数,初始化SendFileData实例。
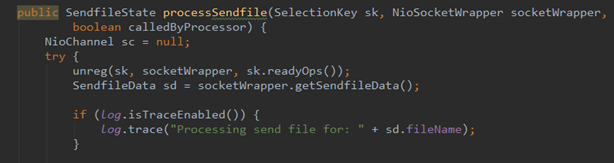
第三阶段,我们记得NIO前端通道的Acceptor,Poller线程,Worker线程的三个线程,当Worker线程干完活之后,返回给客户端,依然要通过Poller线程,也就是会重新注册KeyEvent,读取KeyAttachment,这个时候当为sendfile的时候,前面初始化的SendFileData实例是会注册在KeyAttachment上的,上图的processSendfile就是Poller线程的run中的一个判断分支,当为sendfile的时候,Poller线程就对SendFileData数据结构中的file名字取出,通过FileChannel的transferTo方法,这个transferTo方法本质上就是sendfile在tomcat源码中的具体体现,如下图所示
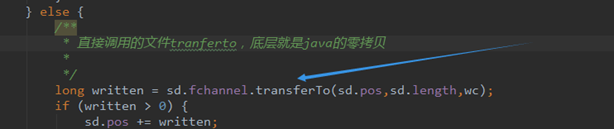
6、sendfile在APR通道中的实现(具体源码跟踪分析见视频)
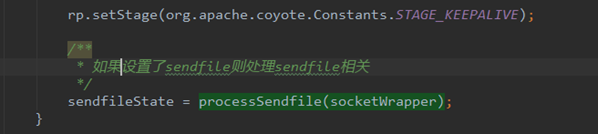
在NIO通道中sendfile实现算是比较复杂的了,在APR通道中更加的复杂,我们可以回过头先看看NIO通道中的sendfile,实际是通过每一个Poller线程中的FileChannel的transferTo方法来实现的,对于transferTo方法是阻塞的,这也就意味着,当文件进行sendfile的时候,Poller线程是阻塞的,而我们前面研究过Tomcat前端,Poller线程是很珍贵的,不仅仅是为某几个sendfile服务的,这样会导致Poller线程产生瓶颈,从而拖慢了整个Tomcat前端的效率。
APR通道是开辟一个独立的线程来处理sendfile的,如下图所示,这样做的好处不言自明,Poller就干Poller的事,而遇到Sendfile的需求的时候,sendfile线程就挺身而出,把活儿给接了。
最后,对于APR通道是通过JNI调用的APR库,sendfile自然就不是java的API了


7、总结
SendFile实际上是操作系统的优化,Tomcat中基于在不同的通道中有不同的实现,配置也不尽相同,但实际上都是底层操作系统的SendFile的系统调用!
十二、Tomcat中的compression压缩属性优化
1、http响应头中压缩相关属性
这里着重讲解3个属性。
传输内容编码:Content-Encoding
内容编码,即整个数据信息是在服务器端经过怎样的编码处理,然后客户端会以怎么的编码来反向处理,以得到原始的内容,这里的内容编码主要是指压缩编码,即服务器端压缩,客户端解压缩。 可以参考的值为:gzip,compress,deflate和identity。
通常压缩方式都是gzip格式的,当选择gzip的时候,整个html文本会被进行一次gzip格式的压缩。java版本的实现有GZIPOutputstream可以进行gzip的实现了,并且对于servlet可以通过查看httprequest来查看这个属性是否支持gzip,如果支持的话,那么浏览器端也会进行gzip相应的解压。
传输数据编码:Transfer-Encoding
数据编码,即表示数据在网络传输当中,使用怎么样的保证方式来保证数据是安全成功地传输处理。可以可以是分段传输,也可以是不分段,直接使用原数据进行传输。 有效的值为:chunked和Identity.
传输内容格式:Content-Type
内容格式,即接收的数据最终是以何种的形式显示在浏览器中。
可以是一个图片,还是一段文本,或者是一段html,内容格式额外支持可选参数,charset,即实际内容的字符集。通过字符集,客户端可以对数据进行解编码,以最终显示可以看得懂的文字(而不是一段byte[]或者是乱码)。
Content-Type是代表着格式,这个一般不会混淆,
而Content-encoding这个是内容编码格式,实际上就是压不压缩传输,
Trandfer-encoding这个是传输的方式,大白话也就是分不分块,
上述的三个属性就是http响应头中的格式,我们主要关注的是Content-encoding,当然我们在解析Tomcat的代码时,还会看到其余的两个属性的踪影。
2、Tomcat源码中的压缩实现
以下是总体概述,具体的源码分析请观看视频
对于压缩的处理,是在Tomcat中的响应头中,也就是Response的commit的时候,开始对输出流进行处理,而如果Content-encoding是gzip的话,那么会在Http11Processor中的输出流filter链条中,加上一个GzipOutputFilter。
Http11Processor是Tomcat前端比较重要的处理类,Work工作线程将任务交给Http11Processor开始继续干活,Http11Processor接着会攒出Request和Response,并基于Mapper进行调用,从而进入容器中。
而XXXFilter这里的filter不是容器端的filter,而是在Response进行commit提交的时候,基于响应头的Tomcat的配置,是否执行相关的处理。
以这个compression为例,当在Tomcat中配置了compression的话,GzipOutputFilter就开始自动执行过滤,从上面的代码逻辑可以看到,实际上就是基于流的包装机制,使用GzipOutPutStream来再对当前的流进行一次包装,然后在OutputBuffer最终commit的时候,调用这个GzipOutputFilter,最终执行doWrite方法,让输出流中的字节进行压缩。
从上述的分析可以看出,Tomcat的压缩实现实际上就是GzipOutputStream,只不过采用了GzipOutputFilter责任链的模式,通过流的一层一层的包装,将输出的字节进行了压缩。
具体的源码分析请观看视频
3、compression压缩属性设置
设置非常简单,但是要注意一点,usesendfile和compression属性必须同时设置,且互斥,如下图所示:
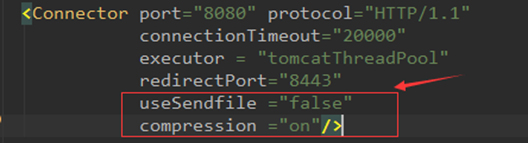
4、与sendfile的互斥性
我们了解的sendfile,实际是一种操作系统级别的优化手段,直接跳过内存转接,直接从内核缓冲区到网卡缓冲区,相当高效;
但是我们在查询Tomcat文档的时候,发现sendfile和compression是不兼容的,也就是上图中的红色字体部分,这个是为什么呢?
可以这么来理解,对于compression必然需要在用户空间内存转接中(压缩必须拿到用户态内存中来压)进行操作,也就是下图中用户空间部分,但是sendfile又要求不经过用户空间,所以两者是矛盾的。
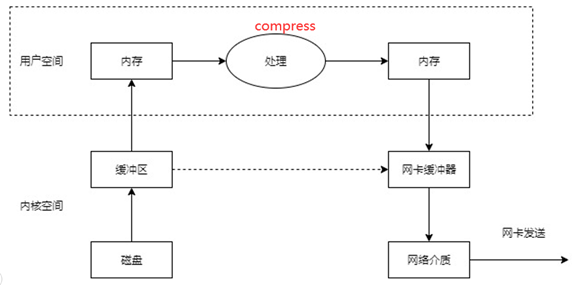
5、总结
1)、经源码启动分析测试,当配置Compression为gzip时,在Tomcat中是采用GzipOutputStream来实现压缩优化,压缩比约为7:1,压缩比很大,节约了带宽。
2)、当配置Compression为gzip时,在Tomcat中是采用GzipOutputStream来实现的,而更要记住的是,Sendfile和Compression这两个优化选项只能选择其一来使用!
十三、Tomcat优化之deferAccept参数
1、TCP中的TCP_DEFER_ACCEPT优化参数
在Tomcat中,有很多的web服务器的参数可以配置,很多是Tomcat基于自身逻辑的,如线程池大小调整等等。
但是,也有很多是操作系统级别的参数在Tomcat中的映射。本文中的讲述就是一个TCP协议栈内核级别的deferAccept参数。
我们先来看看一般的TCP三次握手和传输阶段:
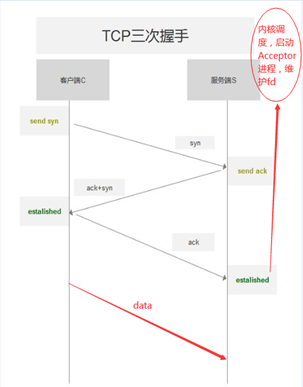
首先,客户端发出一个SYN包,这个包的作用是与服务器端开始尝试进行链接;
然后,服务器端如果存在,基于这个SYN包,回复一个SYN+ACK的包,告知客户端我存在,连吧;
最后,客户端最后回复一个ACK,告知服务器端,客户端已经准备发送数据了,服务器端你准备好吧;
整体的TCP握手的链接阶段就宣告成功,下一阶段开始进入数据传输的第二阶段了;
上述的流程没什么可说的,只不过我们关注于右侧上图中红色标记的部分。
当客户端回复的ACK之后,服务器端知道客户端要开始发包了,这样服务器端通过内核的协调,需要唤醒一个数据接收进程,这个Acceptor进程会绑定一个IO句柄用于进行接收,这个句柄按照系统调用来进行理解,也就是网络传输的文件描述符fd。
而我们看看,在服务器端的ESTABLISED建立成功之后,到数据传输可能还有一段距离,假设客户端的程序阻塞,加上网络延时,这个时间就非常的大;
而当前是什么状态?
这个状态是服务器端已经消耗了一个进程去等待资源,已经搞了一个fd,甚至操作系统内核级也要时刻准备着,去维护这些状态变化,可以看到,服务器端空消耗这些,而客户端还迟迟不来请求。
有什么办法优化这个呢?
可以设想一种机制,服务器端对客户端的最后一个ACK进行视而不见,直接丢弃,这样的话,服务器端就不会启动Acceptor进程,也不会有fd,也不会有上述的消耗,而当客户端真正把数据发送过来了,这个时候服务器端才开始开启Acceptor进程,开始上述的操作。
而这个优化,其实就是TCP_DEFER_ACCEPT属性。
2、Tomcat中的deferAccept属性配置与实现
启动本机tomcat后, 查看参数http://127.0.0.1:8080/docs/config/http.html
我们可以看到,TCP_DEFER_ACCEPT其实是一个操作系统内核级,TCP/IP协议栈的优化参数,只能在系统调用中进行设置,而java语言在包装socket api的时候,并没有开放这块内容,严格意义上来讲,至少目前JVM中没有实现,因此从这个意义上来讲,Tomcat中的NIO,BIO,甚至NIO2通道中都不会有这个参数的优化。
但是,在APR通道中,因为Tomcat前端代码是通过JNI调用的tomcat-native,tomcat-native调用的APR库作为Socket封装,而APR库的socket封装就来源于系统调用的socket,因此这个参数应该是能开放出来。
3、总结
Tomcat中的deferAccept属性实际上是操作系统级别的TCP_DEFER_ACCEPT参数的优化,只在APR通道中有实现。
十四、Tomcat对keep-alive的实现逻辑及优化
1、什么是keepalive?
http协议的早期是,每开启一个http链接,是要进行一次socket,也就是新启动一个TCP链接。
使用keep-alive可以改善这种状态,即在一次TCP连接中可以持续发送多份数据而不会断开连接。通过使用keep-alive机制,可以减少tcp连接建立次数。
举一个例子,用户浏览一个网页时,除了网页本身外,还引用了多个 javascript 文件,多个 css 文件,多个图片文件,并且这些文件都在同一个 HTTP 服务器上,算作一个http请求,而如果浏览器支持keepalive的话,那么请求头中会有如下connection属性,如下图所示:

对于keepalive的部分,主要集中在Connection属性当中,这个属性可以设置两个值:
close(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,断开连接,不要等待本次连接的后续请求了)。
keepalive(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,保持连接,等待本次连接的后续请求)。
从整体可以再看看keepalive的优化的结果如下:
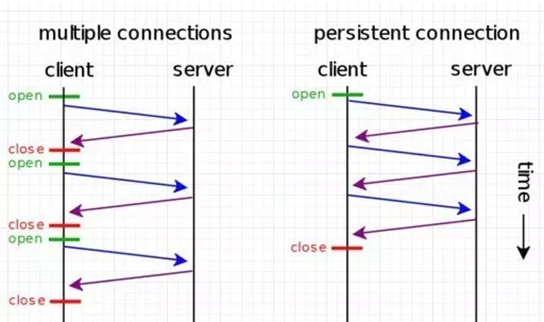
从上面的分析来看,keepalive这个选项相当好,是否所有的场景都适合开启keepalive呢?
情况1:如果用户浏览一个网页时,除了网页本身外,顶多能引入1,2个 javascript 文件,1,2个图片文件。 情况2:如果用户浏览的是一个动态网页,由程序即时生成内容,并且不引用其他内容。
当情况1的时候,keepalive的作用就不那么明显了,而情况2来说,keepalive开启与不开启没有任何的关系,因为整个网页是动态形成的,在服务器端对html页面进行组装的,因此开不开启都是一个TCP链接。
另外,需要澄清两个事情:
第一个,keep-alive与TIME_WAIT的关系,使用http keep-alive,可以减少服务端TIME_WAIT数量(因为由服务端httpd守护进程主动关闭连接)。道理很简单,相较而言,启用keep-alive,建立的tcp连接更少了,自然要被关闭的tcp连接也相应更少了。
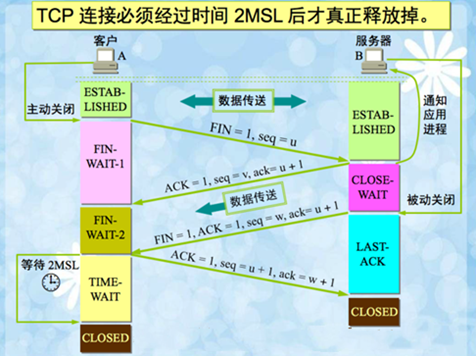
什么是TIME_WAIT呢?
通信双方建立TCP连接后,主动关闭连接的一方就会进入TIME_WAIT状态。
客户端主动关闭连接时,会发送最后一个ack后,然后会进入TIME_WAIT状态,再停留2个MSL时间,进入CLOSED状态,原理如下图所示:
2、keepalive的配置实现(两个参数)
在不同的web服务器中,肯定都有keepalive的配置,一般配置如下两个参数:
keepAliveTimeout:此时间过后连接就close了,单位是milliseconds
maxKeepAliveRequests:最大长连接个数(1表示禁用,-1表示不限制个数,默认100个,一般设置在100~200之间)
在tomcat中,http11之后,keepalive默认就是开启的。
3、Tomcat中Keepalive的实现原理
以下是总体的步骤,具体详细的源码分析请观看视频。
步骤1:准备阶段
首先准备SocketWrapper,SocketWrapper实际就是socket的包装类,而通过这个包装类加上一些属性,例如keepaliveout时间,keepaliveRequest的次数;其次,keepalive默认就是true,如果当前发现SocketWrapper包装类是不支持keepalive的,这种情况直接keepalive就是false,后续任凭你咋配置tomcat的keepalive的属性,keepalive也不能工作。
步骤2:启动大循环,识别该请求没有结束(是否keepalive模式开启后,连续的几个请求)跳出循环,释放或者出让工作线程
首先开启一个大循环,然后判断请求是否是该keepalive期间的最后的一个请求,如果是的话,那么在这里直接就进行break掉,释放掉该工作线程,因为活都已经干完了嘛,如果发现不是最后一个请求,或者后续还有可能有请求,那么这里务必需要将keepalive的模式的状态还要保持住,这些属性如openSocket和readComplete等状态,来保证下一次请求这些状态能正常工作。
通过这段代码就可以分析,在keepalive期间,工作线程池是可以进行释放或者出让的,至少从程序的逻辑上来看,保留了入口。
步骤3:通过prepareRequest方法解析请求头,基于客户端状态设置keepalive
这一步其实比较清晰,就是解析http请求头,看看是否支持keepalive;
先看看http协议,再看看请求头中的Connection字段,如果不是keepalive的话,是close的话,那么就需要强制关闭了,最后看看客户端浏览器的agent是否支持,如果上面都可以的话,keepalive就可以设置了,如果一点不行,那么这里面直接就不能执行keepalive的逻辑,如果是Connection:close的话,处理完直接链接关闭。
从这一步上来看,keepalive也不是那么容易就开启的;
步骤4:设置Tomcat的keepalive
到这一步了,说明至少环境上是可以满足keepalive了,但是前面讲过Tomcat的配置可以让keepalive停掉;
例如maxKeepAliveRequests如果设置成1了,这里直接keepalive就为false,相当于给禁止了,如果maxKeepAliveRequests大于0,走到这里执行了一次,需要减1,这就用到了前面准备阶段中的SocketWrapper的计数器。
步骤5:执行Tomcat容器部分,如果出现异常,关掉Keepalive
这一步就是执行容器,然后基于反馈,如果错误,直接置响应头为Connection:close,keepalive直接就没用了,链接都关了。
步骤6:设置request的keepalive阶段,看是否各变量符合跳出大循环
到这里,大循环任务已经完成,最后检验一下,如果出现错误,这里就会通过breakKeepAliveLoop跳出大循环;
如果一切正常,当前的Request的阶段就是STAGE_KEEPALIVE阶段;
4、总结
本文关注keepalive的原理,Tomcat中的配置与Tomcat中对keepalive的基本实现,大家还可以从线程池的视角,看看通过不同通道在keepalive下,究竟有哪些异同,从而分析出keepalive参数对性能为什么这么关键的原因。
十五、调整和tomcat相关的JVM参数进行优化
1、设置串行垃圾回收器(nio模式,最大线程1000)
压测步骤:
1)、在tomcat启动脚本catalina.sh里设置以下脚本:
年轻代、老年代均使用串行收集器,初始堆内存64M,最大堆内存512M,打印gc时间戳等信息,生成gc日志文件
JAVA_OPTS="-XX:+UseSerialGC -Xms64m -Xmx512m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX: +PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:../logs/gc.log"
2)、设置后启动tomcat,使用jmeter进行压测(jmeter设置线程为1000,每个线程循环10次),访问test_web
3)、查看吞吐量
压测结果:平均时间1.585s,吞吐量378.6/s,异常1.12%
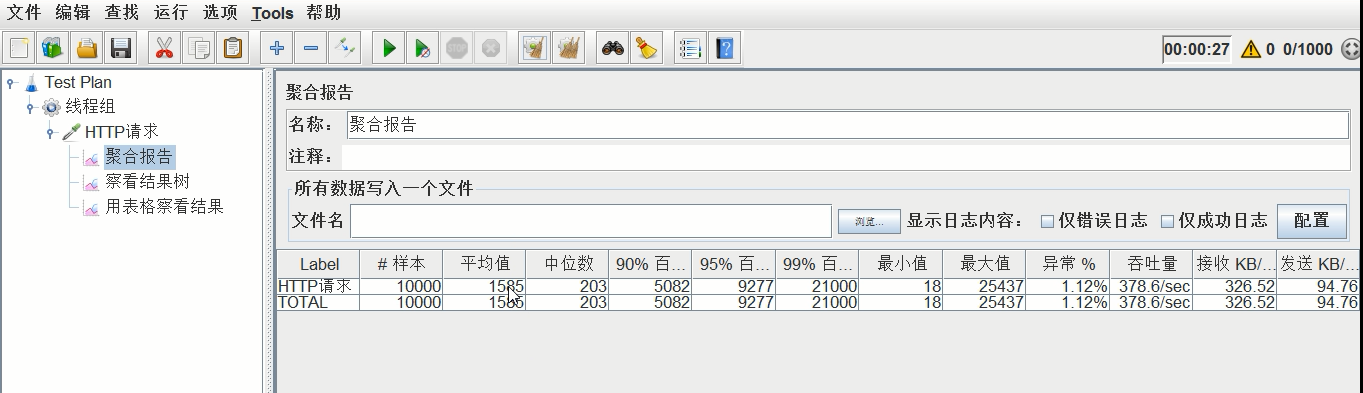
将gc.log拷贝出来,改名gc1.log。预备比较
2、设置并行垃圾回收器(nio模式,最大线程1000)
压测步骤:
1)、在tomcat启动脚本catalina.sh里设置以下脚本:
年轻代、老年代均改成并行垃圾收集器,初始堆内存64M,最大堆内存512M,打印gc时间戳等信息,生成gc日志文件。
#JAVA_OPTS="-XX:+UseParallelGC -XX:+UseParallelOldGC -Xms64m -Xmx512m -XX:+PrintGCDetails -XX :+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:../logs/gc.log"
2)、删除gc.log
rm -rf gc.log
3)、设置后重启tomcat,使用jmeter进行压测(jmeter设置线程为1000,每个线程循环10次),访问test_web,查看吞吐量
压测结果:平均时间1.161s,吞吐量407.7/s,异常0.40%
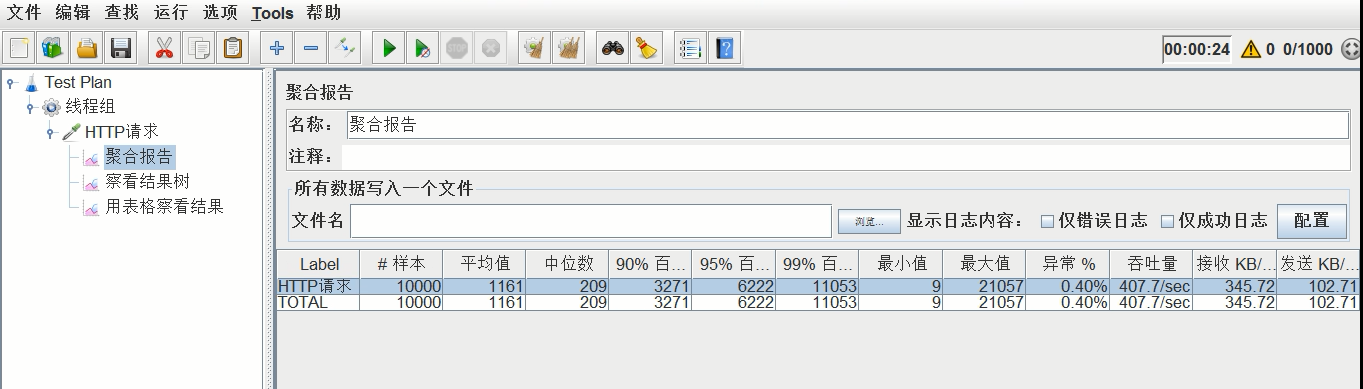
将gc.log拷贝出来,改名gc2.log。预备比较
分析结论:
可以看出设置成并行垃圾收集器之后平均执行时间减少了,吞吐量增加了,异常率也减少了,总体性能有了很大的提高。
3、查看gc日志文件
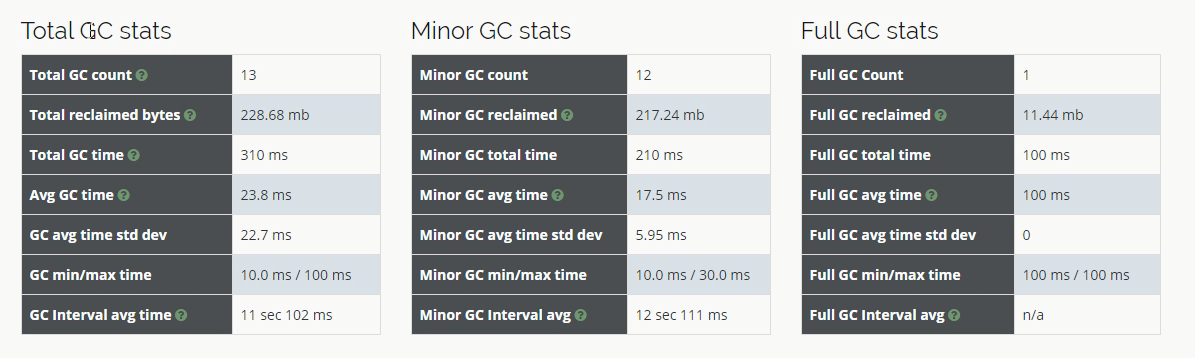
将gc1.log和gc2.log文件分别上传到gceasy.io进行在线分析,分析结果如下:
gc1.log中的gc总次数是13次
gc2.log中gc总次数12次,比串行时少了1次,性能是有所提升的。
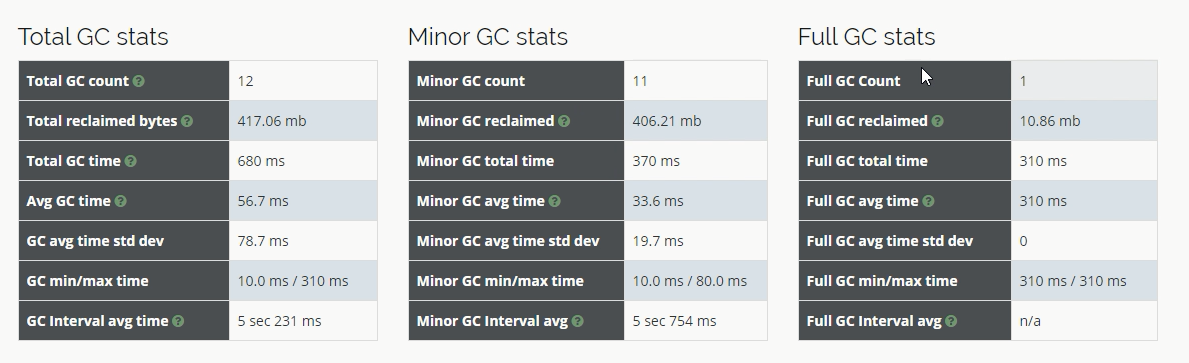
4、调整年轻代大小
再次重新设置启动参数,依然是并行垃圾收集器,不过我们增加了初始化堆内存和最大堆内存,分别设置为128m和1024m。
JAVA_OPTS="-XX:+UseParallelGC -XX:+UseParallelOldGC -Xms128m -Xmx1024m -XX:NewSize=64m -XX:M axNewSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHe apAtGC -Xloggc:../logs/gc.log"
设置完后再次重启,用jmeter进行压测(压测参数不变),结果如下:
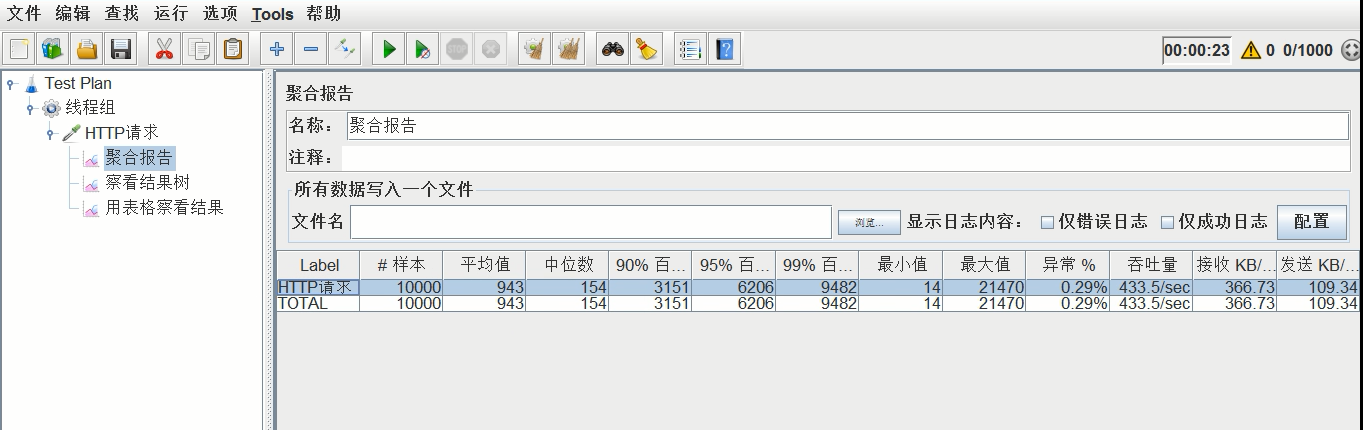
压测结果:平均时间0.943s,吞吐量433.5/s,异常0.29%
性能再一次的得到了提升。再次分析gc.log 如下图:
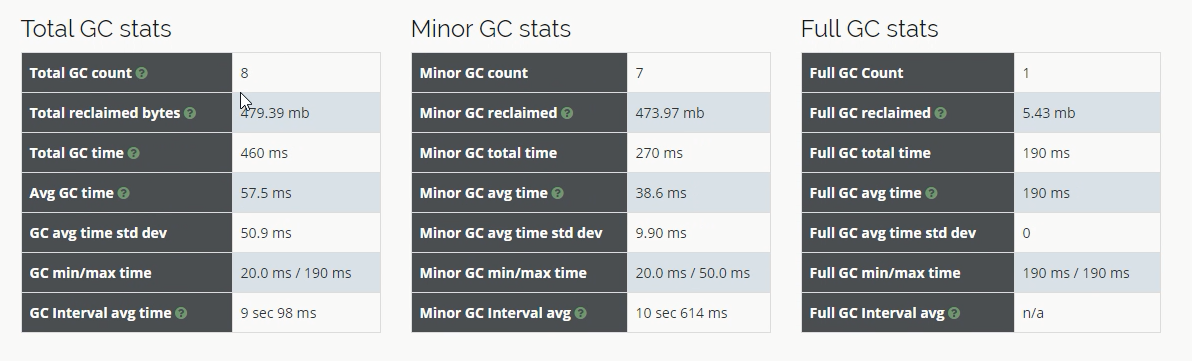
gc收集总次数减少为8次,从gc的收集次数也再次证明了调整参数后性能的确得到了极大的提升。
5、设置G1垃圾回收器(jdk9之后默认G1,测试用的jdk8)
再次重新设置启动参数,修改垃圾收集器为G1收集器,参数如下:
JAVA_OPTS="-XX:+UseG1GC -Xms128m -Xmx1024m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+Pr intGCDateStamps -XX:+PrintHeapAtGC -Xloggc:../logs/gc.log"
重启tomcat后使用jmeter再次压测(压测参数不变),压测结果如图:
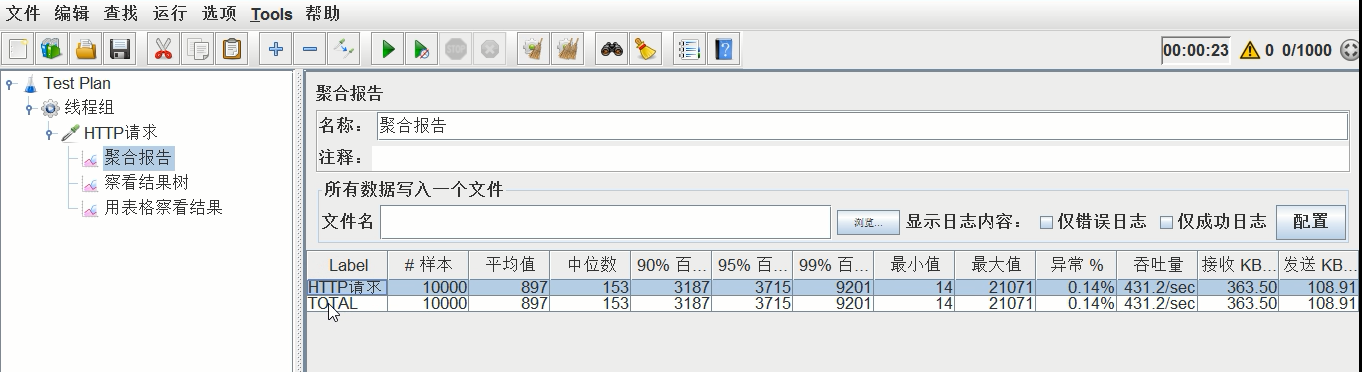
压测结果:平均时间0.897s,吞吐量431.2/s,异常0.14%
总体性能再一次得到了提升。
6、总结
通过不断的调优,我们得出4次压测结果如下:
第1次压测结果:平均时间1.585s,吞吐量378.6/s,异常1.12%
第2次压测结果:平均时间1.161s,吞吐量407.7/s,异常0.40%
第3次压测结果:平均时间0.943s,吞吐量433.5/s,异常0.29%
第4次压测结果:平均时间0.897s,吞吐量431.2/s,异常0.14%
平均时间一次比一次短,吞吐量一次比一次大,异常率一次比一次少,所以总体性能一次比一次优越。
结论:对tomcat性能优化需要不断的进行参数调整,然后测试结果,可能每次调优结果都有差异,这就需要借助于gc的可视化工具来看gc的情况,再帮我我们做出决策应该调整哪些参数,从而达到一个相对理想的优化效果。
一、数据库优化的必要性
1、避免网站页面出现访问错误
1)、数据库连接timeout产生页面5xx错误
这个问题也是最直观的问题,页面上出现错误,在应用层面找开发的同学来排查,开发同学发现应用层面代码没有问题,最后检查发现是因为数据库超时引起的。那数据库层面为什么会超时呢?这里的原因可能有很多,比如数据库连接池已经满了,或者查询的数据量比较大,引起数据库线程的挂死,既然这些问题产生于数据库层面,那么就需要对数据库进行调优。
2)、慢查询造成页面无法加载
最典型的就是用户点开页面后屏幕一片白,为什么?说明你的数据没有加载进来,比如说电商系统,你点开了这个商品列表,在5秒之内还没有打开,那么这个时候你的系统基本上已经废了,这系统已经到了不得不优化的程度了。5秒钟,这个时间太夸张了,其实用户的极限基本上在1秒之内,系统数据超时达到了5秒,那肯定是页面一片白。这个原因说白了就是你数据查询比较慢,或者说你的表里的数据量很大,可能有上百万,或者千万的数据。如果开发的同学当时还忘记了在条件列加索引,那这简直就是一种灾难,别说5分钟了,半个小时都有可能出不来。
3)、阻塞造成数据无法提交
那这也是有可能的,用户在页面上比如提交一个付款的动作,那么你的后台如果线程繁忙引起阻塞,那这时候的阻塞基本上就是锁表之内的了。
其实我们优化数据库的时候。不应该等他出现问题的时候才想起去优化,我们应该在数据库设计之初就应该考虑的到各种问题出现的可能性,做好防范。等到数据库出现问题的时候再去优化就有点嫌晚了,因为这时候优化成本就大了。
2、增加数据库的稳定性
1)、很多数据库问题都是由于低效的查询引起的。
那么什么叫低效呢?低效最直接的体现就是你查询时候进行全表扫描,说白了就是没有经过索引,那么出现这个问题有可能是开发人员在开发的时候忘记加索引了。
系统可能在上线初期不会出现问题,为什么呢?因为你的用户量比较少,低并发,所以不会发现问题。但是当你的系统跑了2-3年之后,你的用户量暴增,这时候就会出现问题。比如你的公司已经成长为一个小独角兽了,用户量达到了上百万,那么这时候问题可能就来了,因为并发量上来了,并发上来之后对数据库资源的争抢就开始了。所以开发人员可能在设计表字段的初期没有预测到这个字段将来会作为条件查询,所以就没有在这个字段上加索引。或者呢虽然加了索引,由于随着时间的推移,这个字段的重复率可能越来越高,那么索引的威力就大大减弱了。
2)、随着时间的推移,系统变得极其臃肿,数据库中的数据量越来越大,数据检索越来越困难,对整个系统带来的资源消耗也就越来越大,系统越发不稳定。
这个问题其实刚讲到的,系统上线之后初期可能不会发生问题,但是随着你的业务量不断的膨胀,你的数据库必然会产生问题。所以数据库的调优工作是个长期的工作,现在各大互联网公司都有自己的dba,对数据库做24小时监控。
而且我们发现其实系统绝大部分性能问题都是出在数据库层面。因为公司的数据实际上是公司的核心资产,说白了你那些项目代码弄丢了其实都无所谓。但是呢,你数据库里的数据万万不能丢的,所以对数据库的维护优化应该作为一个头等大事。
3、优化用户体验
1)、流畅的页面访问速度
这个也是我们开发人员所追求的一个目标。就是说系统访问页面要非常的流畅,你不能动不动一个查询就是3-5秒钟,那这样的话你的客户就得跑光了。比如说电商系统,我在你家买东西,每次点页面,他都给我3-5秒的响应,那客户肯定会奔溃的,必然抛弃你去其他家去买了,因为你的系统太烂了。所以我们在应用层面页面都是做成静态页面,通过nginx+redis缓存来做了,热点数据直接就不走数据库了。
2)、良好的网站功能体验
这个也非常重要,如果说你的网站里面的功能动不动就不能用,动不动就一片白,那这种用户体验是非常差的。基本上用户来几次就跑光了,我们的目标是把访问页面控制在1秒之内,其实1秒都嫌多啦,像我们公司,优化的目标在500ms-600ms,这是我们的终极目标,1s是最极限的容忍程度。
二、mysql数据库优化层面
1、图解优化层面
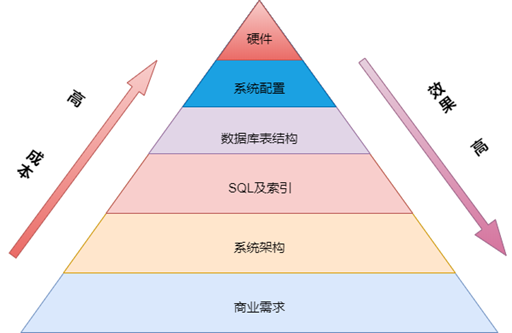
2、商业需求
1)、不合理需求造成资源投入产出比过低
需求是否合理很多时候可能并不是很容易界定,尤其是作为技术人员来说,可能更难以确定一个需求的合理性。即使指出,也不一定会被产品经理们认可。那作为技术人员的我们怎么来证明一个需求是否合理呢?
第一、每次产品经理们提出新的项目(或者功能需求)的时候,应该要求他们同时给出该项目的预期收益的量化指标,以备项目上先后统计评估投入产出比率; 第二、在每次项目进行过程中,应该详细记录所有的资源投入,包括人力投入,硬件设施的投入,以及其他任何项目相关的资源投入; 第三、项目(或者功能需求)上线之后应该及时通过收集相关数据统计出项目的实际收益值,以便计算投入产出比率的时候使用; 第四、技术部门应该尽可能推动设计出一个项目(或者功能需求)的投入产出比率的计算规则。在项目上线一段时间之后,通过项目实际收益的统计数据和项目的投入资源量,计算出整个项目的实际投入产出值,并公布给所有参与项目的部门知晓,同时存放以备后查。
有了实际的投入产出比率,我们就可以和项目立项之初产品经理们的预期投入产出比率做出比较,判定出这个项目做的是否值得。而且当积累了较多的项目投入产出比率之后,我们可以根据历史数据分析出一个项目合理的投入产出比率应该是多少。这样,在项目立项之初,我们就可以判定出产品经理们的预期投入产出比率是否合理,项目是否真的有进行的必要。
有了实际的投入产出比率之后,我们还可以拿出数据给老板们看,让他知道功能并不是越多越好,让他知道有些功能是应该撤下来的,即使撤下该功能可能需要投入不少资源。实际上,一般来说,在产品开发及运营部门内部都会做上面所说的这些事情的。但很多时候可能更多只是一种形式化的过程。在有些比较规范的公司可能也完成了上面的大部分流程,但是要么数据不公开,要么公开给其他部门的数据存在一定的偏差,不具备真实性。为什么会样?其实就一个原因,就是部门之间的利益冲突及业绩冲突问题。产品经理们总是希望尽可能的让用户觉得自己设计的产品功能齐全,让老板觉得自己做了很多事情。但是从来都不会去关心因为做一个功能所带来的成本投入,或者说是不会特别的关心这一点。而且很多时候他们也并不能太理解技术方面带来的复杂度给产品本身带来的负面影响。
2)、无用功能堆积使系统过度复杂影响整体性能
很多时候,为系统增加某个功能可能并不需要花费太多的成本,而要想将一个已经运行了一段时间的功能从原有系统中撤下来却是非常困难的。
首先,对于开发部门,可能要重新整理很多的代码,找出可能存在与增加该功能所编写的代码有交集的其他功能点,删除没有关联的代码,修改有关联的代码;
其次,对于测试部门,由于功能的变动,必须要回归测试所有相关的功能点是否正常。可能由于界定困难,不得不将回归范围扩展到很大,测试工作量也很大,如果你有自动化测试可能还会好一点。
最后,所有与撤除下线某个功能相关的工作参与者来说,又无法带来任何实质性的收益,而恰恰相反的是,带来的只可能是风险。
由于上面的这几个因素,可能很少有公司能够有很完善的项目(或者功能)下线机制,也很少有公司能做到及时将系统中某些不合适的功能下线。
所以,我们所面对的应用系统可能总是越来越复杂,越来越庞大,短期内的复杂可能并无太大问题,但是随着时间的积累,我们所面对的系统就会变得极其臃肿。不仅维护困难,性能也会越来越差。尤其是有些并不合理的功能,在设计之初或者是刚上线的时候由于数据量较小,带来不了多少性能损耗。可随着时间的推移,数据库中的数据量越来越大,数据检索越来越困难,对整个系统带来的资源消耗也就越来越大。而且,由于系统复杂度的不断增加,给后续其他功能的开发带来实现的复杂度,可能很多本来很简单的功能,因为系统的复杂而不得不增加很多的逻辑判断,造成系统应用程序的计算量不断增加,本身性能就会受到影响。而如果这些逻辑判断还需要与数据库交互通过持久化的数据来完成的话,所带来的性能损失就更大,对整个系统的性能影响也就更大了。
3、系统架构
1)、数据库中存放的数据都是适合在数据库中存放的吗?
对于有些开发人员来说,数据库就是一个操作最方便的万能存储中心,希望什么数据都存放在数据库中,不论是需要持久化的数据,还是临时存放的过程数据,不论是普通的纯文本格式的字符数据,还是多媒体的二进制数据,都喜欢全部塞进数据库中。因为对于应用服务器来说,数据库很多时候都是一个集中式的存储环境,不像应用服务器那样可能有很多台;而且数据库有专门的 DBA 去帮忙维护,而不像应用服务器很多时候还需要开发人员去做一些维护;还有一点很关键的就是数据库的操作非常简单统一,不像文件操作或者其他类型的存储方式那么复杂。
其实我个人认为,现在的很多数据库为我们提供了太多的功能,反而让很多并不是太了解数据库的人错误的使用了数据库的很多并不是太擅长或者对性能影响很大的功能,最后却全部怪罪到数据库身上。
实际上,以下几类数据都是不适合在数据库中存放的:
-
二进制多媒体数据 将二进制多媒体数据存放在数据库中,一个问题是数据库空间资源耗用非常严重,另一个问题是这些数据的存储很消耗数据库主机的CPU资源。这种数据主要包括图片,音频、视频和其他一些相关的二进制文件。这些数据的处理本不是数据的优势,如果我们硬要将他们塞入数据库,肯定会造成数据库的处理资源消耗严重。
-
流水队列数据 我们都知道,数据库为了保证事务的安全性(支持事务的存储引擎)以及可恢复性,都是需要记录所有变更的日志信息的。而流水队列数据的用途就决定了存放这种数据的表中的数据会不断的被 INSERT, UPDATE 和 DELETE,而每一个操作都会生成与之对应的日志信息。在 MySQL 中,如果是支持事务的存储引擎,这个日志的产生量更是要翻倍。而如果我们通过一些成熟的第三方队列软件(例如rabbitmq,rocketmq,kafka等)来实现这个Queue数据的处理功能,性能将会成倍的提升。
-
超大文本数据 对于 5.0.3 之前的 MySQL 版本, VARCHAR 类型的数据最长只能存放 255 个字节,如果需要存储更长的文本数据到一个字段,我们就必须使用 TEXT 类型(最大可存放 64KB)的字段,甚至是更大的LONGTEXT 类型(最大 4GB)。而TEXT类型数据的处理性能要远比 VARCHAR 类型数据的处理性能低下很多。从 5.0.3 版本开始, VARCHAR 类型的最大长度被调整到 64KB 了,但是当实际数据小于 255Bytes 的时候,实际存储空间和实际的数据长度一样,可一旦长度超过 255 Bytes 之后,所占用的存储空间就是实际数据长度的两倍。所以,超大文本数据存放在数据库中不仅会带来性能低下的问题,还会带来空间占用的浪费问题。
2)、是否合理的利用了应用层 Cache 机制?
对于 Web 应用,活跃数据的数据量总是不会特别的大,有些活跃数据更是很少变化。对于这类数据,我们是否有必要每次需要的时候都到数据库中去查询呢?如果我们能够将变化相对较少的部分活跃数据通过应用层的Cache机制Cache 到内存中,对性能的提升肯定是成数量级的,而且由于是活跃数据,对系统整体的性能影响也会很大。
当然,通过 Cache 机制成功的案例数不胜数,但是失败的案例也同样并不少见。如何合理的通过Cache 技术让系统性能得到较大的提升也不是通过寥寥几笔就能说明的清楚,这里我仅根据以往的经验列举一下什么样的数据适合通过 Cache 技术来提高系统性能:
-
系统各种配置及规则数据; 由于这些配置信息变动的频率非常低,访问概率又很高,所以非常适合存使用 Cache;
-
活跃用户的基本信息数据; 虽然我们经常会听到某某网站的用户量达到成百上千万,但是很少有系统的活跃用户量能够都达到这个数量级。也很少有用户每天没事干去将自己的基本信息改来改去。更为重要的一点是用户的基本信息在应用系统中的访问频率极其频繁。所以用户基本信息的 Cache,很容易让整个应用系统的性能出现一个质的提升。
-
活跃用户的个性化定制信息数据; 虽然用户个性化定制的数据从访问频率来看,可能并没有用户的基本信息那么的频繁,但相对于系统整体来说,也占了很大的比例,而且变更频率一样不会太多。现在普遍使用nosql的组件,例如用redis作为热点数据的存储引擎实现用户个性化定制数据,我们就能看出对这部分信息进行Cache 的价值了,Cache 技术的合理利用和扩充造就了项目整体的成功。
-
准实时的统计信息数据; 所谓准实时的统计数据,实际上就是基于时间段的统计数据。这种数据不会实时更新,也很少需要增量更新,只有当达到重新 Build 该统计数据的时候需要做一次全量更新操作。虽然这种数据即使通过数据库来读取效率可能也会比较高,但是执行频率很高之后,同样会消耗不少资源。既然数据库服务器的资源非常珍贵,我们为什么不能放在应用相关的内存 Cache 中呢?
-
其他一些访问频繁但变更较少的数据; 除了上面这四种数据之外,在我们面对的各种系统环境中肯定还会有各种各样的变更较少但是访问很频繁的数据。只要合适,我们都可以将对他们的访问从数据库移到Cache中。
3)、数据层实现都是最精简的吗?
以往的经验来看,一个合理的数据存取实现和一个拙劣的实现相比,在性能方面的差异经常会超出一个甚至几个数量级。
我们先来分析一个非常简单且经常会遇到类似情况的示例: 比如一个网站系统中,现在要实现每个用户查看各自相册列表(假设每个列表显示 10 张相片)的时候,能够在相片名称后面显示该相片的留言数量。这个需求大家认为应该如何实现呢?我想90%的开发开发工程师会通过如下两步来实现该需求:
- 通过“SELECT id,subject,url FROM photo WHERE user_id = ? limit 10” 得到第一页的相片相关信息;
- 通过第 1 步结果集中的 10 个相片 id 循环运行十次“ SELECT COUNT(*) FROM photo_comment WHERE photh_id = ?” 来得到每张相册的回复数量然后再拼装展现对象。
此外可能还有部分人想到了如下的方案:
- 和上面完全一样的操作步骤;
- 通过程序拼装上面得到的 10 个 photo 的 id,再通过 in 查询“SELECT photo_id,count(*) FROM photo_comment WHERE photo_id in (?) GROUP BY photo_id” 一次得到 10 个 photo 的所有回复数量,再组装两个结果集得到展现对象。
我们来对以上两个方案做一下简单的比较:
- 从 MySQL 执行的 SQL 数量来看 ,第一种解决方案为11(1+10=11)条SQL语句,第二种解决方案 为2条SQL语句(1+1);
- 从应用程序与数据库交互来看,第一种为11次,第二种为2次;
- 从数据库的IO操作来看,简单假设每次SQL为1个IO,第一种最少11次IO,第二种小于等于11次IO,而且只有当数据非常之离散的情况下才会需要11次;
- 从数据库处理的查询复杂度来看,第一种为两类很简单的查询,第二种有一条SQL语句有GROUP BY 操作,比第一种解决方案增加了排序分组操作;
- 从应用程序结果集处理来看,第一种11次结果集的处理,第二种2次结果集的处理,但是第二种解决方案中第二次结果处理数量是第一次的10倍;
- 从应用程序数据处理来看,第二种比第一种多了一个拼装photo_id 的过程。
我们先从以上 6 点来做一个性能消耗的分析:
- 由于MySQL对客户端每次提交的 SQL 不管是相同还是不同,都需要进行完全解析,这个动作主要消耗的资源是数据库主机的CPU,那么这里第一种方案和第二种方案消耗CPU的比例是11:2。SQL语句的解析动作在整个 SQL 语句执行过程中的整体消耗的CPU比例是较多的;
- 应用程序与数据库交互所消耗的资源基本上都在网络方面,同样也是11:2;
- 数据库 IO 操作资源消耗为小于或者等于1:1;
- 第二种解决方案需要比第一种多消耗内存资源进行排序分组操作,由于数据量不大,多出的消耗在语句整体消耗中占用比例会比较小,大概不会超过 20%,大家可以针对性测试;
- 结果集处理次数也为11:2,但是第二种解决方案第二次处理数量较大,整体来说两次的性能消耗区别不大;
- 应用程序数据处理方面所多出的这个photo_id的拼装所消耗的资源是非常小的,甚至比应用程序与MySQL做一次简单的交互所消耗的资源还要少。
综合上面的这6点比较,我们可以很容易得出结论,从整体资源消耗来看,第二种方案会远远优于第一种解决方案。而在实际开发过程中,我们的程序员却很少选用。主要原因其实有两个,一个是第二种方案在程序代码实现方面可能会比第一种方案略为复杂,尤其是在当前编程环境中面向对象思想的普及,开发工程师可能会更习惯于以对象为中心的思考方式来解决问题。还有一个原因就是我们的程序员同学可能对SQL语句的使用并不是特别的熟悉,并不一定能够想到第二条SQL 语句所实现的功能。对于第一个原因,我们可能只能通过加强开发工程师的性能优化意识来让大家能够自觉纠正,而第二个原因的解决就正是需要我们这个专题的重点。SQL语句的调优正是我们必须要具备的,定期对初级开发工程师进行一些相应的数据库知识包括SQL语句方面的优化培训,可能会给大家带来意想不到的收获的。这里我们还仅仅只是通过一个很长见的简单示例来说明数据层架构实现的区别对整体性能的影响,实际上可以简单的归结为过渡依赖嵌套循环的使用或者说是过渡弱化 SQL 语句的功能造成性能消耗过多的实例。后面我将进一步分析一下更多的因为架构实现差异所带来的性能消耗差异。
4、SQL及索引优化
这个主题将是我们研究的重点,我们从以下两个方面来阐述。
1)、根据需求写出良好的SQL,并创建有效的索引,实现某一种需求可以多种写法,我们就要选择一种效率最高的写法,这个时候就要了解sql优化。
下面我们将通过一两个具体的示例来分析写法不一样而功能完全相同的两条 SQL 的在性能方面的差异。 示例一 需求:取出某个 group(假设 id 为 100)下的用户编号(id),用户昵称(nick_name)、用户性别( sexuality )、用户签名( sign )和用户生日( birthday ),并按照加入组的时间(user_group.gmt_create)来进行倒序排列,取出前 20 个。
解决方案一
SELECT id,nick_name
FROM user,user_group
WHERE user_group.group_id = 1
and user_group.user_id = user.id
limit 100,20;解决方案二
SELECT user.id,user.nick_name
FROM (
SELECT user_id
FROM user_group
WHERE user_group.group_id = 1
ORDER BY gmt_create desc
limit 100,20) t,user
WHERE t.user_id = user.id;我们先来看看执行计划:
mysql> explain
-> SELECT id,nick_name
-> FROM user,user_group
-> WHERE user_group.group_id = 1
-> and user_group.user_id = user.id
-> ORDER BY user_group.gmt_create desc
-> limit 100,20\G
************************* 1. row ***************************
id: 1
select_type: SIMPLE
table: user_group
type: ref
possible_keys: user_group_uid_gid_ind,user_group_gid_ind
key: user_group_gid_ind
key_len: 4
ref: const
rows: 31156Extra: Using where; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: user
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: example.user_group.user_id
rows: 1
Extra:
mysql> explain
-> SELECT user.id,user.nick_name
-> FROM (
-> SELECT user_id
-> FROM user_group
-> WHERE user_group.group_id = 1
-> ORDER BY gmt_create desc
-> limit 100,20) t,user
-> WHERE t.user_id = user.id\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 20
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: user
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: t.user_id
rows: 1
Extra:
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: user_group
type: ref
possible_keys: user_group_gid_ind
key: user_group_gid_ind
key_len: 4
ref: const
rows: 31156
Extra: Using filesort执行计划对比分析:
解决方案一中的执行计划显示 MySQL 在对两个参与 Join 的表都利用到了索引, user_group 表利用了 user_group_gid_ind 索引( key: user_group_gid_ind ), user 表利用到了主键索引( key:PRIMARY),在参与 Join 前 MySQL 通过 Where 过滤后的结果集与 user 表进行 Join,最后通过排序取出Join 后结果的“limit 100,20” 条结果返回。
解决方案二的 SQL 语句利用到了子查询,所以执行计划会稍微复杂一些,首先可以看到两个表都和解决方案 1 一样都利用到了索引(所使用的索引也完全一样),执行计划显示该子查询以 user_group为驱动,也就是先通过user_group 进行过滤并马上进行这一论的结果集排序,也就取得了 SQL 中的“limit 100,20” 条结果,然后与 user 表进行 Join,得到相应的数据。这里可能有人会怀疑在自查询中从user_group表所取得与user 表参与 Join的记录条数并不是 20条,而是整个group_id=1 的所有结果。
那么请大家看看该执行计划中的第一行,该行内容就充分说明了在外层查询中的所有的 20 条记录全部被返回。 通过比较两个解决方案的执行计划,我们可以看到第一种解决方案中需要和 user 表参与 Join 的记录 数 MySQL 通过统计数据估算出来是 31156,也就是通过 user_group 表返回的所有满足 group_id=1 的记录 数(系统中的实际数据是 20000)。
而第二种解决方案的执行计划中, user 表参与 Join 的数据就只有 20条,两者相差很大,通过本节最初的分析,我们认为第二中解决方案应该明显优于第一种解决方案。
2)、sql优化的目的之一就是减少中间结果集,降低物理IO
例如:如何优化select t1.id,t2.name from t1,t2 where t1.pid=t2.id;
以这条sql语句为例我们来看一下他的执行流程
- from语句把t1表 和 t2表从数据库文件加载到内存中。
- 这时候相当于对两张表做了乘法运算,把t1表中的每一行记录按照顺序和t2表中记录依次匹配。
- 匹配完成后,我们得到了一张有 (t1表中记录数 × t2表中记录数)条的临时表。 在内存中形成的临时表称为‘笛卡尔积表’。
针对以上的理论,我们提出一个问题,难道表连接的时候都要先形成一张笛卡尔积表吗?如果两张表的数据量都比较大的话,那样就会占用很大的内存空间这显然是不合理的。所以,我们在进行表连接查询的时候一般都会使用JOIN xxx ON xxx的语法,ON语句的执行是在JOIN语句之前的,也就是说两张表数据行之间进行匹配的时候,会先判断数据行是否符合ON语句后面的条件,再决定是否JOIN。
因此,有一个显而易见的SQL优化的方案是,当两张表的数据量比较大,又需要连接查询时,应该使用 FROM table1 JOIN table2 ON xxx的语法,避免使用 FROM table1,table2 WHERE xxx 的语法,因为后者会在内存中先生成一张数据量比较大的笛卡尔积表,增加了内存的开销。
5、数据库表结构优化
1)、根据数据库的范式,设计表结构,表结构设计的好坏直接关系到SQL语句的复杂度
正常情况之下我们都会依据数据库设计范式来设计数据库。针对一般的系统我们会设计到第三范式就差不多了,最多到BC范式。
那如果对系统分类特别严格的,我们一般是先判断当前系统是OLTP系统还是OLAP系统,如果是OLAP系统的话,那么查询语句会相对比较多,那我们在设计表的时候就会适当的进行数据冗余,可以设计到第二范式,这样设计的结果就是“少表多字段”,这样人为的设计成冗余字段的表在查询数据的时候就减少了多表联表查询,从而减少了中间的结果集,本质上就是减少了IO,提高了查询效率。这是典型的以空间换时间的案例。
那如果是OLTP系统,那么增,删,改操作比较多,那我们可以设计成“多表少字段”,将表尽量拆分,此类系统一般不需要索引或者只要少量索引,因为如果索引多了会影响效率,因为做增,删,改操作的时候,对应字段的索引页需要被维护(索引会自行进行裂变等消耗资源的操作)。
2)、适当的将表进行拆分,原本需要做join的查询只需要一张单表查询就可以了
这就是上面提到的OLAP系统的情况。这里不再赘述。
6、系统配置优化
大多数运行在Linux机器上,如tcp连接数的限制、打开文件数的限制、安全性的限制,因此我们要对这些配置进行相应的优化。
7、硬件配置优化
1)、数据库主机的IO性能是需要最优先考虑的一个因素
2)、数据库主机和普通的应用程序服务器相比,资源要相对集中很多,单台主机上所需要进行的计算量自然也就比较多,所以数据库主机的CPU处理能力也是一个重要的因素
3)、数据库主机的网络设备(一般指网卡等)的性能也可能会成为系统的瓶颈
三、SQL及索引优化
要进行sql优化,我们得先安装mysql。
1、mysql安装(linux在线安装)
1)、访问:https://dev.mysql.com/downloads/repo/yum/
我的操作系统是centos7,所以我选择如下的版本,大家可以根据自己的系统版本选择对应的版本来安装。
2)、点击Download,选择最下面的No thanks,just start my download,如下图:
3)、安装过程
-
先移除mariadb数据库:
yum remove mariadb-libs.x86_64 -
创建mysql目录:
mkdir /etc/mysql cd /etc/mysql -
下载安装
wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm -
添加到本地
yum localinstall mysql80-community-release-el7-3.noarch.rpm -
正式安装
yum install mysql-community-server -
启动测试
service mysqld start service mysqld status -
查看默认密码并且登录
查看默认密码:cat /var/log/mysqld.log | grep password 使用默认密码登陆:mysql -uroot -p -
修改密码
set global validate_password.policy=0; set global validate_password.length=1; ALTER USER "root"@"localhost" IDENTIFIED BY "123456"; ##新密码为123456 -
退出
exit -
输入密码即可登录
mysql -uroot -p
2、数据库版本选择
1)、查看数据库的版本
执行命令
select @@version;注意:这里是2个@符号
我们用的是当前最新的mysql8.0.20版本。
2)、准备数据
我们要演示的案例的sql脚本来源于官网的sakila这个数据库,这是一个影片租售商店的系统数据库,大概10几张表,下面带大家下载并导入。
访问mysql官网。
示例数据:https://dev.mysql.com/doc/sakila/en/sakila-installation.html
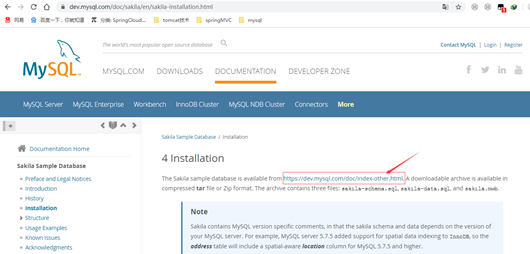
具体的下载操作请同学们观看视频,这里不再赘述。
3)、导入数据
参照官网:https://dev.mysql.com/doc/sakila/en/sakila-installation.html
官网上每一步都有具体说明,同学们可以参考官网说明一步一步操作;或者跟着我的视频操作也是可以的。
4)、表结构关系
这里有个简单的表结构关系,这是pdman导出的物理模型。
我在视频讲解中也带大家用pd导出了整个sakila库的表物理模型,通过物理模型,我们可以对表与表之间的关系有一个清晰的了解。
为什么要带大家做这个导出物理模型的事情呢?因为导出物理模型在开发中还是很常见的,比如我们接手了一个老的项目,整个项目的相关文档早就缺失了,当年做这个项目的同学也早就跳槽了,那么我们要维护这样的一个什么资料都没有,也没有人可以咨询的这样的一个遗留系统的话,我们该如何去理清它的业务逻辑呢?这时候物理模型就能派上用场,导出来之后我们可以一目了然的看到表与表之间的关系,通过这层关系有助于我们理解整个系统的业务逻辑。
3、问题SQL筛查步骤
1)、检查慢查日志是否开启:
执行如下命令,查看是否开启:OFF为关闭,ON为开启
show slow_query_log
2)、检查慢查日志路径:
执行如下命令查看日志路径
show variables like‘%slow_query_log%';
3)、开启慢查日志:
执行如下命令开启慢查日志
set global slow_query_log=on;
4)、慢查日志判断标准(默认查询时间大于10s的sql语句):
show variables like 'long_query_time';为了测试方便可以修改为1秒
set global long_query_time=1;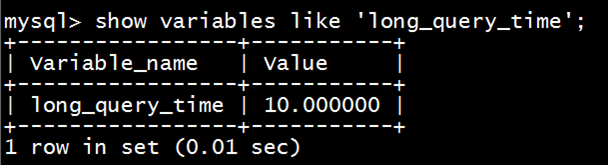
5)、慢查日志测试:
执行如下sql,休眠11秒,超过10秒,迫使该sql进慢查日志
select sleep(11);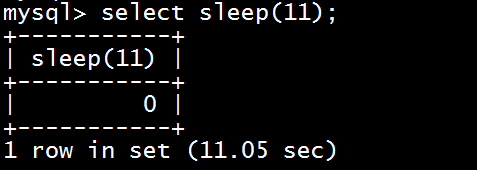
执行
tail -f /var/lib/mysql/myshop02-slow.log检查慢查日志记录情况,发现已经记录进来了。
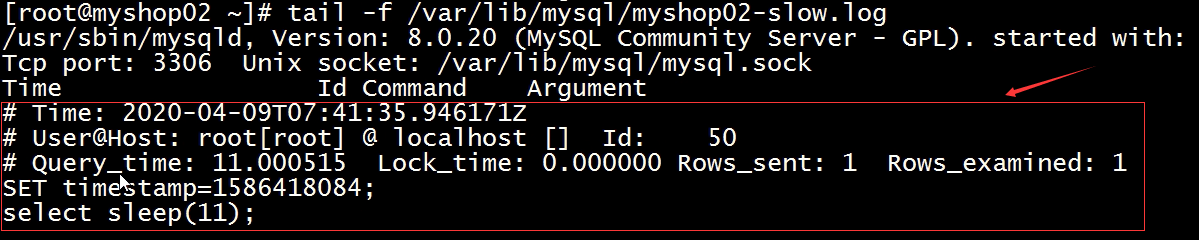
6)为了测试方便,所有查询都记录进慢查日志:
先检查下使用索引情况
show variables like'%log%';设置开启即可
set global log_queries_not_using_indexes=on;
4、Jmeter压测mysql
打开jmeter,加入相关测试配置项,具体操作请观看视频
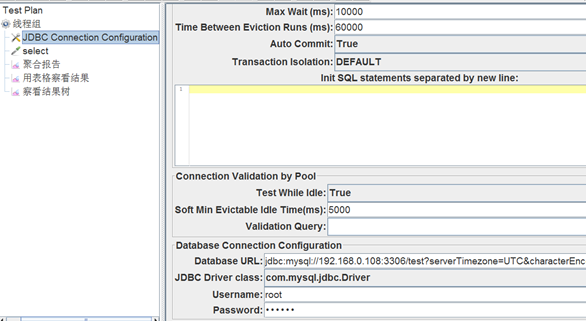
5、MySQL慢查日志的存储格式解析
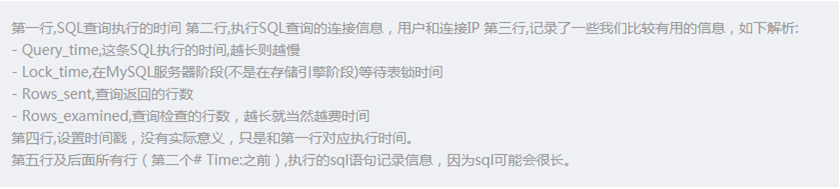
具体的详细解析请观看视频。
四、mysql慢查询日志分析工具
1、mysqldumpslow
1)、简介:
如果开启了慢查询日志,就会生成大量的数据,然后我们就可以通 过对日志的分析,生成分析报表,通过报表进行优化。
2)、用法:
执行 mysqldumpslow --help 查看详细用法
注意:在mysql数据库所在的服务器上,而不是在mysql>命令行中
3)、 执行结果:
mysqldumpslow --help
具体参数讲解请观看视频
2、mysqldumpslow用法示例
查看慢查询日志的前10条记录
mysqldumpslow -t 10 /var/lib/mysql/myshop02-slow.logmysqldumpslow 分析的结果如下:

日志显示:select sleep(N)语句共执行了4次,共花费了36s,平均9s/次,锁表时间0.00s,共返回行rows=4,平均1行。
更详细的解释请观看视频
3、mysqldumpslow优缺点
这个工具是最常用的工具,通过安装mysql进行附带安装,但是该工具统计的结果比较少,对我们的优化所提供的信息还是比较少,比如cpu,io等信息都没有,所以我们需要更强大的工具,就是我们下节要讲的
pt-query-digest。
4、pt-query-digest
1)、简介
pt-query-digest是用于分析mysql慢查询的一个第三方工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。
可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
2)、pt-query-digest本质是perl脚本,所以首先安装perl模块
执行如下命令安装perl
yum install -y perl-CPAN perl-Time-HiRes
3)、快速安装
执行wget命令,wget下载后进行本地安装,执行yum localinstall -y,命令如下
wget https://www.percona.com/downloads/percona-toolkit/3.2.0/binary/redhat/7/x86_64/percona-toolkit-3.2.0-1.el7.x86_64.rpm && yum localinstall –y percona-toolkit-3.2.0-1.el7.x86_64.rpm4)、检查是否安装完成
执行
pt-query-digest --help如出现下图信息表示已经安装成功。
5、pt-query-digest常用命令详解
1)、查看服务器信息
命令:
pt-summary
可以看到服务器相关的具体信息:有系统日期,主机,更新时间,内核,平台,进程数等。
具体信息详细解释请观看视频
2)、查看磁盘开销使用信息
命令:
pt-diskstats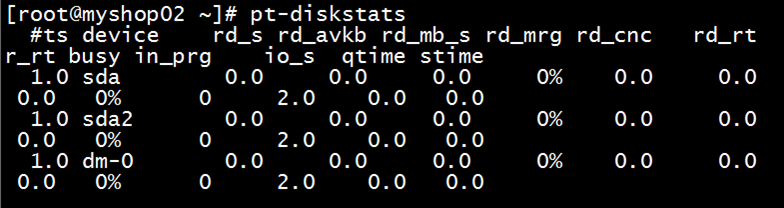
可以看到磁盘开销相关的具体信息:磁盘使用率,繁忙度等信息。
具体信息详细解释请观看视频
3)、查看mysql数据库信息
命令:
pt-mysql-summary --user=root --password=123456
可以看到mysql相关的具体信息:有系统时间,数据库实例,msyql服务路径,主从信息等信息。
具体信息详细解释请观看视频
4)、分析慢查询日志(重点)
命令:
pt-query-digest /var/lib/mysql/myshop02-slow.log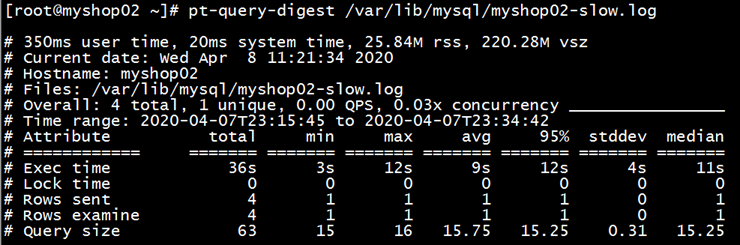
这个统计信息内容有很多,以总-分的形式统计了慢查询日志的分析信息,有执行总时间,最小时间,最大时间,平均时间,达到95%的时间是多少,标准时间,中位时间(也就是从小到大排列,排在中间的值)等详细信息,该日志非常重要,是我们判断慢查询的重要依据。
具体信息的剖析我在视频课程里都有详细的讲解。
5)、查找mysql的从库和同步状态
命令:
pt-slave-find --host=localhost --user=root --password=123456
这个命令通常DBA同学会用到,这是做完集群之后,查看主从之间的同步状态的。
6)、查看mysql的死锁信息
命令:
pt-deadlock-logger --run-time=10 --interval=3 --create-dest-table --dest D=test,t=deadlocks u=root,p=123456
这个命令开发的同学经常会用,通常会用来进行故障排查,当怀疑系统发生死锁的时候或者已经发生死锁的时候就可以执行这个命令进行查看。
具体死锁演示和日志信息解释见视频课程
7)、从慢查询日志中分析索引使用情况
命令:
pt-index-usage --user=root --password=123456 --host=localhost /var/lib/mysql/myshop02-slow.log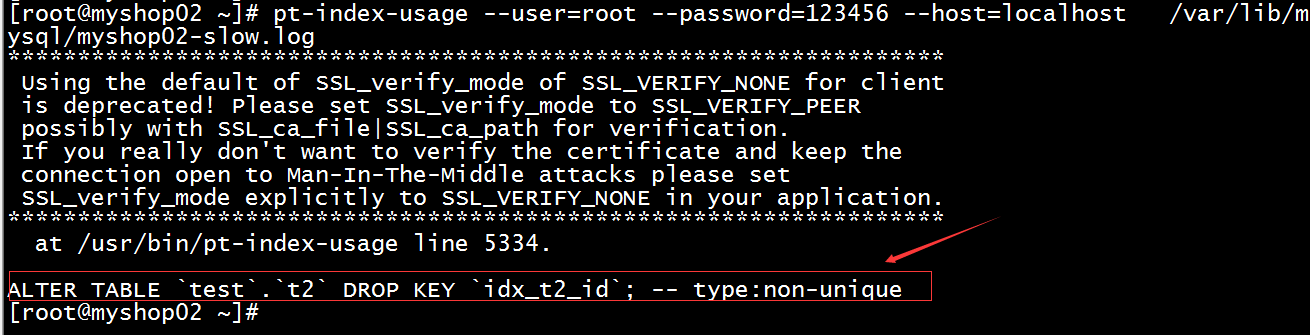
这里日志显示,我对test库的t2表做了删除索引“idx_t2_id”这个动作。
8)、从慢查找数据库表中重复的索引
命令:
pt-duplicate-key-checker --host=localhost --user=root --password=123456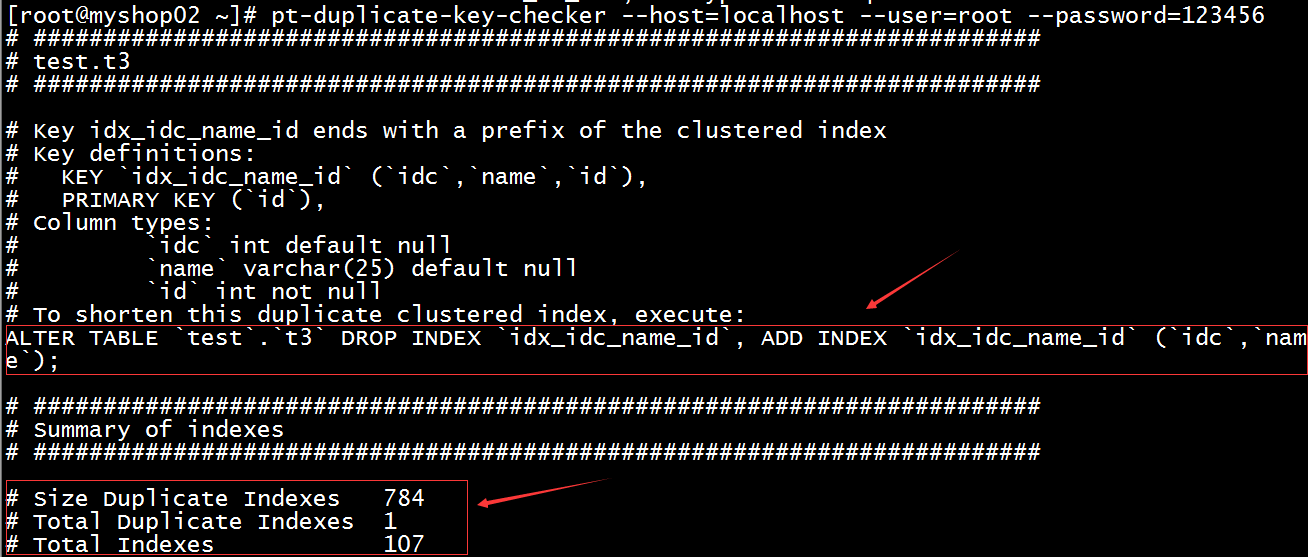
日志显示,我对test库的t3表做了删除索引“idx_idc_name_id”后,又新增了这个索引。
最后三行显示了重复索引相关信息。
9)、查看mysql表和文件的当前活动IO开销(不要在高峰时用)
命令:
pt-ioprofile
当没有大量IO的时候,查询不到信息,因为没有IO开销
10)、查看不同mysql配置文件的差异(集群常用,双方都生效的变量)
命令:
pt-config-diff /etc/my.cnf /root/my_master.cnf
这个通常也是用在集群中,主从复制或者出现问题排查,主机和从机差异的时候经常用到。
具体演示可以参见视频,这里不再赘述。
11)、pt-find查找mysql表和执行命令,示例如下:
- 查找数据库里大于1M的表
pt-find --user=root --password=123456 --tablesize +1M
这里显示有4张表的大小超过1M,这个命令通常可以用来决定当表膨胀之后,比如达到百万级,这时候就需要判断是否要对表做水平或者垂直拆分,那么判断标准就可以看表的大小。
- 查看表和索引大小并排序
pt-find --user=root --password=123456 --printf "%T\t%D.%N\n" | sort -rn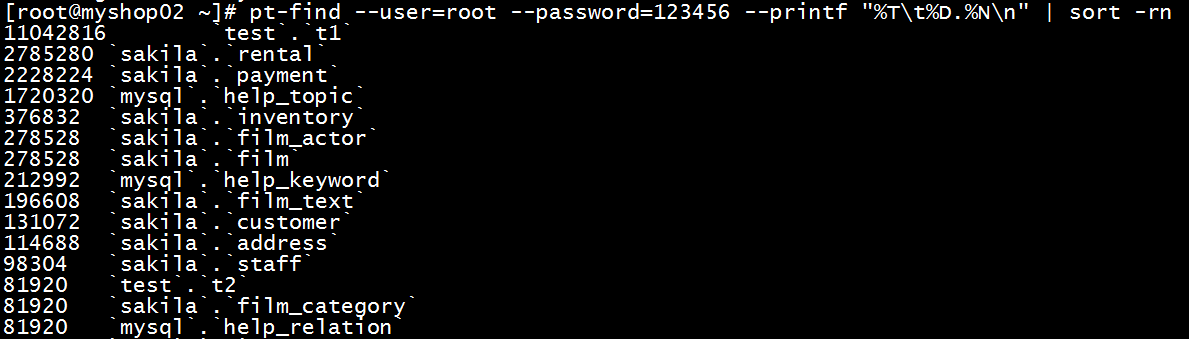
可以看到都已经从大到小进行排列了,最大的是test库t1表。
12)、pt-kill 杀掉符合标准的mysql进程,示例如下:
- 显示查询时间大于3秒的查询
pt-kill --user=root --password=123456 --busy-time 3 --print这个命令只打印信息,不kill进程,如需要强杀进程可执行下面的命令
- kill掉大于3秒的查询
pt-kill --user=root --password=123456 --busy-time 3 --kill13)、查看mysql授权(集群常用,授权复制),示例如下:
pt-show-grants --user=root --password=123456
pt-show-grants --user=root --password=123456 --separate --revoke
可以看到大量的授权信息,这个命令主要也是用在集群的时候,在从机上需要和主机上进行一模一样的授权,直接可以通过这个命令获取所有的授权,然后复制过去就ok了。
14)、验证数据库复制的完整性(集群常用,主从复制后检验),示例如下:
pt-table-checksum --user=root --password=123456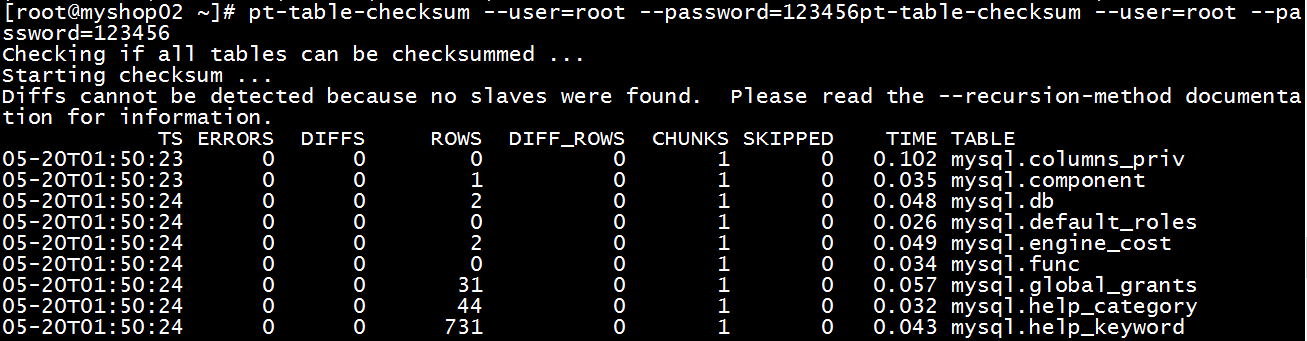
这个信息主要查看点是ERRORS和DIFFS的信息,如果不为0就要注意了,检查主从复制的时候是不是出现了问题。
五、利用pt-query-digest利器查找三大类有问题的SQL
1、查询次数多且每次查询占用时间长的sql
通常为pt-query-digest分析的前几个查询,该工具可以很清楚的看出每个SQL执行的次数及百分比等信息,执行的次数多,占比比较大的SQL
具体的排查分析讲解请观看视频
2、IO大的sql
注意pt-query-digest分析中的Rows examine项,扫描的行数越多,IO越大。
Rows examine项的具体讲解在日志分析的视频课程中,请自行查看
3、未命中索引的SQL
pt-query-digest分析中的Rows examine 和Rows Send的对比。说明该SQL的索引命中率不高,对于这种SQL,我们要重点进行关注。
Rows examine 和Rows Send的关系和区别在视频中有详细讲解。
六、通过explain分析SQL执行计划
1、使用explain查询SQL的执行计划
SQL的执行计划反映出了SQL的执行效率,在执行的SQL前面加上explain即可

2、执行计划的字段解释与举例
以下列出了常见的字段解释,具体举例请观看视频
1)、id列
数字越大越先执行,如果数字一样大,那么就从上往下依次执行,id列为null就表示这是一个结果集,不需要使用它来进行查询。
2)、select_type列
- simple:表示不需要union操作或者不包含子查询的简单select查询,有连接查询时,外层的查询为simple,且只有一个。
- primary:一个需要union操作或者含有子查询的select,位于最外层的查询,select_type即为primary,且只有一个。
- union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union。
- union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null。
- dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响。
- subquery:除了from子句中包含的子查询外,其他地方出现的子查询都可能是subquery。
- dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响。
- derived:from子句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select。
- materialization :物化通过将子查询结果作为一个临时表来加快查询执行速度,正常来说是常驻内存,下次查询会再次引用临时表。
3)、table列
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的,与类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。
4)、type列
- system:表中只有一行数据或者是空表,且只能用于myisam和memory表,如果是Innodb引擎表,type列在这个情况通常都是all或者index。
- const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const,其他数据库也叫做唯一索引扫描。
- eq_ref:出现在要连接多个表的查询计划中,驱动表循环获取数据,这行数据是第二个表的主键或者唯一索引,作为条件查询只返回一条数据,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref。
- ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
- fulltext:全文索引检索,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引。
- ref_or_null:与ref方法类似,只是增加了null值的比较,实际用的不多。
- unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值。
- index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
- range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
- index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取多个索引,性能可能大部分时间都不如range。
- index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
- all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
type列总结:
依次性能从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引。一般来说,好的sql查询至少达到range级别,最好能达到ref。
5)、possible_keys列
查询可能使用到的索引。
6)、key列
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
7)、key_len列
用于处理查询的索引长度,如果是单列索引,那就是整个索引长度,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
8)、ref列
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
9)、rows列
这里是执行计划中估算的扫描行数,不是精确值。
10)、extra列
- no tables used:不带from字句的查询或者From dual查询。
- NULL:查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是纯粹地用到了索引,也不是完全没用到索引。
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
- Using where:查询的列未被索引覆盖,where筛选条件非索引的前导列。
- Using where Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一但是不是索引的前导列,意味着无法直接通过索引查找来查询到符合条件的数据。
- Using index condition:与Using where类似,查询的列不完全被索引覆盖,where条件中是一个前导列的范围。
- using temporary:表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
- using filesort:mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的。
- using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集。
- using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集。
- using sort_union和using sort_intersection:用and和or查询信息量大时,先查询主键,然后进行排序合并后返回结果集。
- firstmatch(tb_name):5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个。
- loosescan(m..n):5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个。
11)、filtered列
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
七、慢查询优化思路及案例
1、慢查询的总体优化思路
- 优化更需要优化的SQL
- 定位优化对象的性能瓶颈
- 明确的优化目标
- 从explain执行计划入手
- 永远用小结果集驱动大的结果集
- 尽可能在索引中完成排序
- 只取出自己需要的列,不要用select *
- 仅使用最有效的过滤条件
- 尽可能避免复杂的join和子查询
- 小心使用order by,group by,distinct语句
- 合理设计并利用索引
以上优化思路的具体说明请观看视频
2、永远用小结果集驱动大的结果集(join操作表小于百万级别)
1)、驱动表的定义
当进行多表连接查询时, [驱动表] 的定义为:
- 指定了联接条件时,满足查询条件的记录行数少的表为[驱动表]
- 未指定联接条件时,行数少的表为[驱动表]
2)、mysql关联查询的概念
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,最后合并结果。
3)、left join,right join,inner join的区别
具体说明见视频
-
left join
select * from t2 left join t3 on t2.id =t3.id and t3.id in(1,2,3) order by t2.id desc;
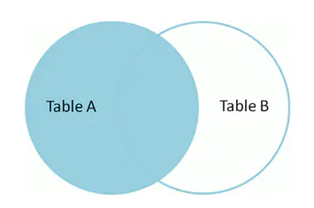
-
right join
select * from t2 right join t3 on t2.id =t3.id and t3.id in(1,2,3);
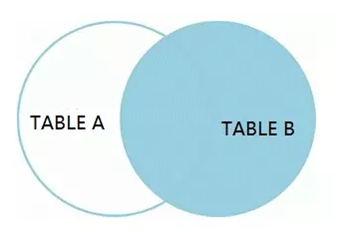
-
inner join
select * from t2 inner join t3 on t2.id =t3.id and t3.id in(1,2,3);
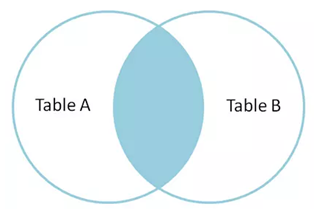
3、join的实现原理
具体的原理讲解请观看视频
1)、mysql只支持一种join算法:
Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种:
- Simple Nested-Loop Join(简单嵌套循环)
- Index Nested-Loop Join(索引嵌套循环)
- Block Nested-Loop Join(块嵌套循环)
2)、Simple Nested-Loop Join(简单嵌套循环)
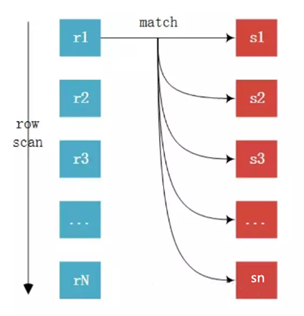
3)、Index Nested-Loop Join(索引嵌套循环)
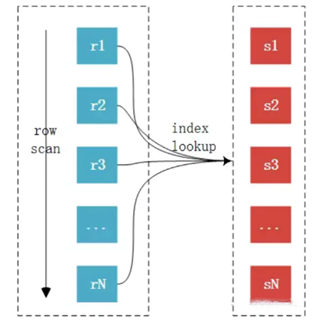
4)、Block Nested-Loop Join(块嵌套循环)
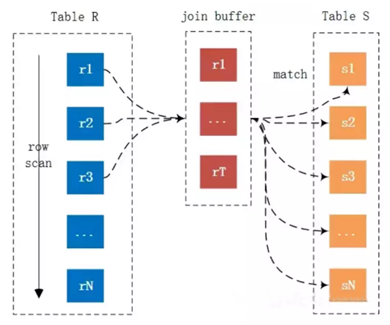
5)、Block Nested-Loop Join(3表)
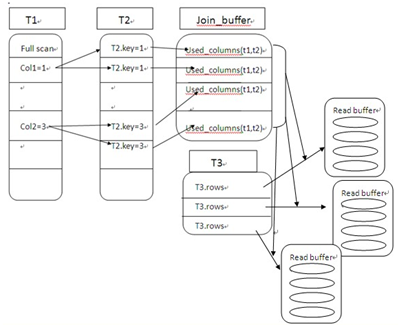
4、join的优化思路
具体的思路讲解见视频
1)、尽可能减少join语句中的Nested Loop的循环总次数
2)、优先优化Nested Loop的内层循环
3)、保证join语句中被驱动表上join条件字段已经被索引
4)、无法保证被驱动表的 Join 条件字段被索引且内存资源充足的前提下,不要太吝惜join Buffer的设置
5、join的优化思路总结
1)、并发量太高的时候,系统整体性能可能会急剧下降。
2)、复杂的 Join 语句,所需要锁定的资源也就越多,所阻塞的其他线程也就越多
3)、复杂的 Query 语句分拆成多个较为简单的 Query 语句分步执行
6、只取出需要的列,不要用select *
1)、如果取出的列过多,则传输给客户端的数据量必然很大,浪费带宽
2)、若在排序的时候输出过多的列,则会浪费内存(Using filesort)
3)、若在排序的时候输出过多的列,还有可能改变执行计划
具体讲解及演示见视频
7、仅使用最有效的过滤条件
1)、Where字句中条件越多越好吗?
2)、若在多种条件下都使用了索引,那如何选择?
3)、最终选择方案:key_len的长度决定使用哪个条件
具体讲解及演示见视频
8、尽可能在索引中完成排序
- order by 字句中的字段加索引(扫描索引即可,内存中完成,逻辑io)。
- 若不加索引的话会可能会启用一个临时文件辅助排序(落盘,物理io)。
具体讲解及演示见视频
9、order by排序原理及优化思路
- order by排序可利用索引进行优化,order by子句中只要是索引的前导列都可以使索引生效,可以直接在索引中排序,不需要在额外的内存或者文件中排序。
- 不能利用索引避免额外排序的情况,例如:排序字段中有多个索引,排序顺序和索引键顺序不一致(非前导列)
具体讲解及演示见视频
10、order by排序算法
MySQL对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序
1)、order by常规排序算法
步骤:
- 从表t1中获取满足WHERE条件的记录。
- 对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer。
- 如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
- 若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的。
- 循环执行上述过程,直到所有满足条件的记录全部参与排序。
- 扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)。
- 将获取的结果集返回给用户。
2)、order by优化排序算法
常规排序方式除了排序本身,还需要额外两次IO。
优化的排序方式相对于常规排序,减少了第二次IO。
主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。
3)、order by优先队列排序算法
5.6及之后的版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。
对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
11、order by排序不一致问题
1)、MySQL5.6发现分页出现了重复值
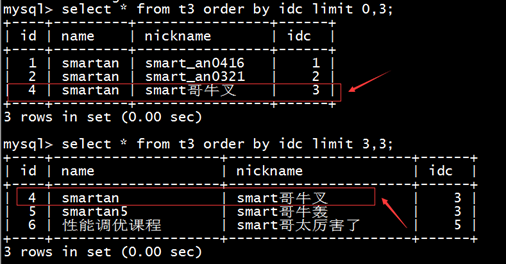
2)、MySQL8查询正常
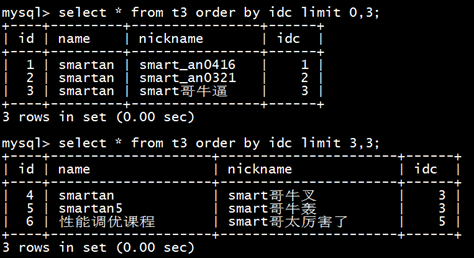
3)、原因分析及解决方案
针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by idc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于idc为3的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上唯一值,比如主键id,这样由于id是唯一的,确保参与排序的key值不相同。
12、order by排序案例演示
演示sql及思路:
explain select idc, max(name) from t3 where id>2 and id<10 order by idc,name,id\G分别在查询字段,where条件,分组字段上做出各种可能的组合,主要就是看有无索引,索引在以上三个关注点上的生效情况。
order by排序的多种案例优化演示请观看视频
13、group by分组优化思路
group by本质上也同样需要进行排序操作,而且与 order by相比,group by主要只是多了排序之后的分组操作。如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在group by的实现过程中,与group by一样也可以利用到索引。
具体案例及优化演示讲观看视频
14、group by的类型
三种实现类型:
- Loose Index Scan(松散的索引扫描)
扫描过程:
先根据group by后面的字段进行分组,分组不需要读取所有索引的key,例如index(key1,key2,key3),group by key1,key2。此时只要读取索引中的key1,key2。然后再根据where条件进行筛选。
- Tight Index Scan(紧凑的索引扫描)
扫描过程:
紧凑索引扫描需要在扫描索引的时候,读取所有满足条件的索引键,然后再根据读取的数据来完成 GROUP BY 操作得到相应结果。
两者区别就是紧凑索引扫描是先执行where操作,再进行分组,松散索引扫描刚好相反
- Using temporary 临时表实现 (非索引扫描)
扫描过程:
MySQL 在进行GROUP BY 操作的时候当MySQL Query Optimizer无法找到合适的索引可以利用的时候,就不得不先读取需要的数据,然后通过临时表来完成 GROUP BY操作。
15、group by分组案例演示
演示sql及思路:
explain select idc, max(name) from t3 where id>2 and id<10 group by idc,name,id\G和order by一样,分别在查询字段,where条件,分组字段上做出各种可能的组合,主要就是看有无索引,索引在以上三个关注点上的生效情况。
具体案例及优化演示讲观看视频
16、distinct的实现及优化思路
1)、distinct的原理
distinct实际上和 GROUP BY 的操作非常相似,在GROUP BY之后的每组中只取出一条记录而已。所以,DISTINCT的实现和GROUP BY的实现也基本差不多,同样可以通过松散索引扫描或者是紧凑索引扫描来实现,当然,在无法仅仅使用索引即能完成DISTINCT的时候, MySQL只能通过临时表来完成。但是,和GROUP BY有一点差别的是,DISTINCT并不需要进行排序。
2)、distinct案例演示
演示sql及思路:
explain select distinct name from t3 where idc=3\G(索引中完成,索引默认是排好序的)
explain select distinct name from t3 where idc>1\G(非索引中完成,暗藏排序问题)
具体案例及优化演示讲观看视频
17、合理的设计并利用索引
索引原理
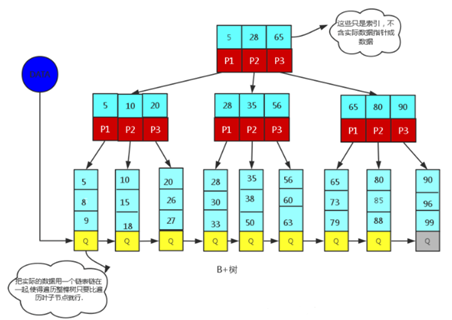
18、索引失效案例
具体案例见视频
19、优化终级奥义
- 针对百万数量级,放弃在mysql中的join操作,推荐分别根据索引单表取数据,然后在程序里面做join,merge数据。
- 尽量使用nosql,例如redis, memcached 等来缓存热点数据,从而缓解mysql压力。
一、jvm优化的必要性
在本地开发环境中我们很少会遇到需要对jvm进行优化的需求,但是到了生产环境,我们可能将会碰到下面的问题
1、应用夯住,日志不输出,程序没有反应
原因有很多,内存溢出,tomcat假死都有可能出现这种情况。
详细描述见视频
2、服务器的CPU负载突然升高
你的线程量不断爆发,就像bio模型,一请求,一线程的这种模式,线程不断创建,回收不及时,那cpu肯定会居高不下,这种问题你在开发环境根本不会出现,因为就你一个人在跑,没有高并发,也就不会出现线程暴增的情况。
详细描述见视频
3、在多线程应用下,如何分配线程的数量?
上线之后才会出现多线程的情况,在本地开发环境是不会有这个需求的,因为就你一个人在开发这个功能,就一个线程在跑,所以上线后会有这个需求,线程分配的数量会根据系统软硬件环境,业务并发量做综合考量。
详细描述见视频
4、系统频繁FULL GC,最后内存泄漏
这种问题通常在上线之后的一段时间内会出现,原因也有很多,比如说代码原因,造成对象回收不及时,最后存活对象在老年代越来越多,最终没有内存可分配,导致内存泄漏。
在本次课程中,我们将对jvm更深入的学习,我们不仅要让程序能跑起来,而且是可以跑的更快!可以分析解决在生产环境中所遇到的各种“棘手”的问题 。
二、jvm的运行参数
在jvm中有很多的参数可以设置,这样可以让jvm在各种环境中都能够高效的运行。 绝大部分的参数保持默认即可,这一节介绍比较常见的以及比较经常设置的一些参数。
1、标准参数
1)、-help,-version,-D参数
jvm的标准参数,一般都是很稳定的,在未来的JVM版本中不会改变,可以使用java -help 检索出所有的标准参数。 通过以下命令查看:
java -help
可以看到我们经常会用到的 -sever,-version等参数。
实战1:查看JVM版本
java -version
jvm版本是1.8.0_202,而且是64位,server,混合模式。
实战2:通过-D设置系统属性参数
先写一段代码:
public class TestVM {
public static void main(String[] args) {
String name = System.getProperty("name");
if(name!=null){
System.out.println(name);
}
else{
System.out.println("ling");
}
}
}运行上面这段代码,通过-D带入一个参数name,根据name的值进行判断如果name不为null,则打印,如果为null则打印 ling。
# 在root下创建一个文件夹下创建这个文件
vi TestJVM.java
#把上面的java代码复制进去
#执行代码
[root@localhost test]# javac TestJVM.java
[root@localhost test]# java TestJVM
ling
#设置参数进行,设置系统属性:‐D<名称>=<值>
[root@localhost test]# java -Dname=smart哥
smart哥2)、-server,-client参数
可以通过-server或-client设置jvm的运行参数。 它们的区别是:
- Server VM的初始堆空间会大一些,默认使用的是并行垃圾回收器,启动慢运行快。
- Client VM相对来讲会保守一些,初始堆空间会小一些,使用串行的垃圾回收器,它 的目标是为了让JVM的启动速度更快,但运行速度会比Serverm模式慢些。
- JVM在启动的时候会根据硬件和操作系统自动选择使用Server还是Client类型的 JVM。
-
32位操作系统:
- 如果是Windows系统,不论硬件配置如何,都默认使用Client类型的JVM。
- 如果是其他操作系统上,机器配置有2GB以上的内存同时有2个以上CPU的话默 认使用server模式,否则使用client模式。
-
64位操作系统
- 只有server类型,不支持client类型。
测试如下:
[root@myshop02 ~]# java -client -showversion TestVM
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
ling可以看出因为服务器是64位的,所以都是server启动!
2、-X参数(非标准参数)
jvm的-X参数是非标准参数,在不同版本的jvm中,参数可能会有所不同,可以通过java -X查看非标准参数。
[root@myshop02 ~]#java -X
‐Xmixed 混合模式执行 (默认)
‐Xint 仅解释模式执行
‐Xbootclasspath:<用 : 分隔的目录和 zip/jar 文件>
设置搜索路径以引导类和资源
‐Xbootclasspath/a:<用 : 分隔的目录和 zip/jar 文件>
附加在引导类路径末尾
‐Xbootclasspath/p:<用 : 分隔的目录和 zip/jar 文件>
置于引导类路径之前
‐Xdiag 显示附加诊断消息
‐Xnoclassgc 禁用类垃圾收集
‐Xincgc 启用增量垃圾收集
‐Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳)
‐Xbatch 禁用后台编译
‐Xms<size> 设置初始 Java 堆大小
‐Xmx<size> 设置最大 Java 堆大小
‐Xss<size> 设置 Java 线程堆栈大小
‐Xprof 输出 cpu 配置文件数据
‐Xfuture 启用最严格的检查, 预期将来的默认值
‐Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档)
‐Xcheck:jni 对 JNI 函数执行其他检查
‐Xshare:off 不尝试使用共享类数据
‐Xshare:auto 在可能的情况下使用共享类数据 (默认)
‐Xshare:on 要求使用共享类数据, 否则将失败。
‐XshowSettings 显示所有设置并继续
‐XshowSettings:all
显示所有设置并继续
‐XshowSettings:vm 显示所有与 vm 相关的设置并继续
‐XshowSettings:properties
显示所有属性设置并继续
‐XshowSettings:locale
显示所有与区域设置相关的设置并继续
‐X 选项是非标准选项, 如有更改,恕不另行通知。1)、-Xint、-Xcomp、-Xmixed
- 在解释模式(interpreted mode)下,-Xint标记会强制JVM执行所有的字节码,当然这 会降低运行速度,通常低10倍或更多。
- -Xcomp参数与它(-Xint)正好相反,JVM在第一次使用时会把所有的字节码编译成 本地代码,从而带来最大程度的优化。 然而,很多应用在使用-Xcomp也会有一些性能损失,当然这比使用-Xint损失的 少,原因是-xcomp没有让JVM启用JIT编译器的全部功能。JIT编译器可以对是否 需要编译做判断,如果所有代码都进行编译的话,对于一些只执行一次的代码就 没有意义了。
- -Xmixed是混合模式,将解释模式与编译模式进行混合使用,由jvm自己决定,这是 jvm默认的模式,也是推荐使用的模式。
测试:
#强制设置为解释模式
[root@myshop02 ~]# java -showversion -Xint TestVM
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, interpreted mode)
ling
#强制设置为编译模式
#注意:编译模式下,第一次执行会比解释模式下执行慢一些,注意观察。
[root@myshop02 ~]# java -showversion -Xcomp TestVM
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, compiled mode)
ling
#默认的混合模式
[root@myshop02 ~]# java -showversion TestVM
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
ling3、-XX参数(使用率较高)
-XX参数也是非标准参数,主要用于jvm的调优和debug操作。
-XX参数的使用有2种方式,一种是boolean类型,一种是非boolean类型:
-
boolean类型
- 格式:-XX:[±]
- 如:-XX:+DisableExplicitGC 表示禁用手动调用gc操作,也就是说调用 System.gc()无效
-
非boolean类型
- 格式:-XX:
- 如:-XX:NewRatio=1 表示新生代和老年代的比值
用法:
[root@myshop02 ~]# java -showversion -XX:+DisableExplicitGC TestVM
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
ling4、-Xms与-Xmx参数
-Xms与-Xmx分别是设置jvm的堆内存的初始大小和最大大小。
-Xmx2048m:等价于-XX:MaxHeapSize,设置JVM最大堆内存为2048M。
-Xms512m:等价于-XX:InitialHeapSize,设置JVM初始堆内存为512M。 适当的调整jvm的内存大小,可以充分利用服务器资源,让程序跑的更快。
示例:
[root@myshop02 ~]# java -Xms512m -Xmx2048m TestVM
ling5、查看jvm的运行参数
有些时候我们需要查看jvm的运行参数,这个需求可能会存在2种情况:
第一,运行java命令时打印出运行参数;
运行java命令时打印参数,需要添加-XX:+PrintFlagsFinal参数即可。
如:
[root@myshop02 ~]#java -XX:+PrintFlagsFinal -version
[Global flags]
intx ActiveProcessorCount = -1 {product}
uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}
uintx AdaptiveSizePausePolicy = 0 {product}
uintx AdaptiveSizePolicyCollectionCostMargin = 50 {product}由上述的信息可以看出,参数有boolean类型和数字类型,值的操作符是=或:=,分别代 表默认值和被修改的值。
[root@myshop02 ~]# java -XX:+PrintFlagsFinal -XX:+VerifySharedSpaces -version
bool C1ProfileVirtualCalls = true {C1 product}
bool C1UpdateMethodData = true {C1 product}
intx CICompilerCount := 2 {product}
bool CICompilerCountPerCPU = true {product}
bool CITime = false {product}
#可以看到CICompilerCount这个参数已经被修改了。第二,查看正在运行的java进程的参数;
如果想要查看正在运行的jvm就需要借助于jinfo命令查看。
首先,启动一个tomcat用于测试,来观察下运行的jvm参数。 我们就用之前部署的tomcat9
##启动tomcat9
[root@myshop02 ~]# cd /usr/local/tomcat9/bin
[root@myshop02 bin]# ./startup.sh
##启动后查看是否启动成功,jps查看进程,pid 3694,已经启动了
[root@myshop02 bin]# jps -l
4972 sun.tools.jps.Jps
3694 org.apache.catalina.startup.Bootstrap
##执行jinfo -flags 3694查看信息
[root@myshop02 bin]# jinfo -flags 3694
Attaching to process ID 3694, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08
Non-default VM flags: -XX:CICompilerCount=2 -XX:ConcGCThreads=1 -XX:G1HeapRegionSize=1048576 -XX:InitialHeapSize=134217728 -XX:+ManagementServer -XX:MarkStackSize=4194304 -XX:MaxHeapSize=1073741824 -XX:MaxNewSize=643825664 -XX:MinHeapDeltaBytes=1048576 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseG1GC
Command line: -Djava.util.logging.config.file=/usr/local/tomcat9/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -XX:+UseG1GC -Xms128m -Xmx1024m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:../logs/gc.log -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK=0027 -Dcom.sun.management.jmxremote -Djava.rmi.server.hostname=192.168.0.108 -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dignore.endorsed.dirs= -Dcatalina.base=/usr/local/tomcat9 -Dcatalina.home=/usr/local/tomcat9 -Djava.io.tmpdir=/usr/local/tomcat9/temp
##这是所有的信息,还可以查看单个信息,查看某一参数的值,用法:jinfo ‐flag <参数名> <进程id>
[root@myshop02 bin]# jinfo -flag MaxHeapSize 3694
-XX:MaxHeapSize=1073741824三、jvm内存模型
jvm的内存模型在1.7和1.8有较大的区别,虽然本套课程是以1.8为例进行讲解,但是我们也是需要对1.7的内存模型有所了解,所以接下里,我们将先学习1.7再学习1.8的内存模型。
1、jdk1.7的堆内存模型
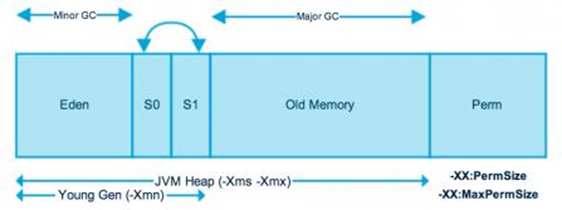
-
Young 年轻区(代):
Young区被划分为三部分,Eden区和两个大小严格相同的Survivor区,其中, Survivor区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制 对象用,在Eden区间变满的时候, GC就会将存活的对象移到空闲的Survivor区间 中,根据JVM的策略,在经过几次垃圾收集后,任然存活于Survivor的对象将被移动到Tenured区间。
-
Tenured 年老区:
Tenured区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在Young 复制转移一定的次数以后,对象就会被转移到Tenured区,一般如果系统中用了 application级别的缓存,缓存中的对象往往会被转移到这一区间。
-
Perm 永久区:
Perm代主要保存class,method,filed对象,这部份的空间一般不会溢出,除非一次性 加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到 java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因 就有可能是每次都重新部署,但是重新部署后,类的class没有被卸载掉,这样就造 成了大量的class对象保存在了perm中,这种情况下,一般重新启动应用服务器可以 解决问题。
-
Virtual区:
最大内存和初始内存的差值,就是Virtual区。
2、jdk1.8的堆内存模型
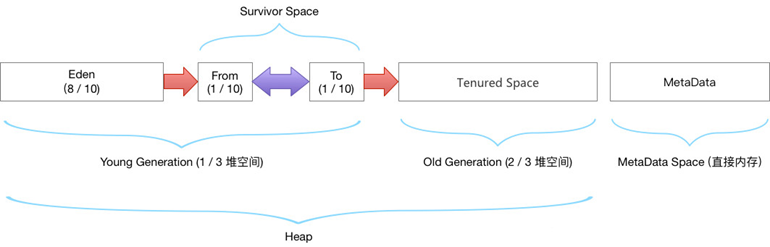
由上图可以看出,jdk1.8的内存模型是由2部分组成,年轻代 + 年老代。 年轻代:Eden + 2*Survivor 年老代:OldGen 在jdk1.8中变化最大的Perm区,用Metaspace(元数据空间)进行了替换。 需要特别说明的是:Metaspace所占用的内存空间不是在虚拟机内部,而是在本地内存 空间中,这也是与1.7的永久代最大的区别所在 。
3、为什么要废弃1.7中的永久区?
官网给出了解释:http://openjdk.java.net/jeps/122
This is part of the JRockit and Hotspot convergence effort. JRockit
customers do not need to configure the permanent generation (since JRockit
does not have a permanent generation) and are accustomed to not
configuring the permanent generation.
移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,
不需要配置永久代。现实使用中,由于永久代内存经常不够用或发生内存泄露,报出异常 java.lang.OutOfMemoryError: PermGen。 基于此,将永久区废弃,而改用元空间,改为了使用本地内存空间。
4、通过jstat命令查看堆内存使用情况
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量。
命令的格式如下:
jstat [-命令选项] [vmid] [间隔时间/毫秒] [查询次数]
-
查看class加载数统计
[root@myshop02 bin]# jps 5030 Jps 3694 Bootstrap [root@myshop02 bin]# jstat -class 3694 Loaded Bytes Unloaded Bytes Time 3367 6665.3 0 0.0 6.06说明:
Loaded:加载class的数量
Bytes:所占用空间大小
Unloaded:未加载数量
Bytes:未加载占用空间
Time:时间
-
查看编译统计
[root@myshop02 bin]# jstat -compiler 3694 Compiled Failed Invalid Time FailedType FailedMethod 2485 0 0 16.95 0说明: Compiled:编译数量。 Failed:失败数量 Invalid:不可用数量 Time:时间 FailedType:失败类型 FailedMethod:失败的方法
-
垃圾回收统计
[root@myshop02 bin]# jstat -gc 3694 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 0.0 4096.0 0.0 4096.0 77824.0 26624.0 49152.0 14074.5 21296.0 20696.2 2432.0 2274.5 11 0.430 0 0.000 0.430说明:
S0C:第一个Survivor区的大小(KB)
S1C:第二个Survivor区的大小(KB)
S0U:第一个Survivor区的使用大小(KB)
S1U:第二个Survivor区的使用大小(KB)
EC:Eden区的大小(KB)
EU:Eden区的使用大小(KB)
OC:Old区大小(KB)
OU:Old使用大小(KB)
MC:方法区大小(KB)
MU:方法区使用大小(KB)
CCSC:压缩类空间大小(KB)
CCSU:压缩类空间使用大小(KB)
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
四、jmap的使用以及内存溢出分析
前面通过jstat可以对jvm堆的内存进行统计分析,而jmap可以获取到更加详细的内容。如:内存使用情况的汇总、对内存溢出的定位与分析。
1、查看内存使用情况
[root@myshop02 bin]# jmap -heap 3694
Attaching to process ID 3694, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08
##我这边用的是G1垃圾收集器
using thread-local object allocation.
Garbage-First (G1) GC with 1 thread(s)
Heap Configuration:#堆内存配置信息
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 643825664 (614.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:# 堆内存的使用情况
G1 Heap:#G1堆情况
regions = 1024
capacity = 1073741824 (1024.0MB)
used = 45869552 (43.74461364746094MB)
free = 1027872272 (980.2553863525391MB)
4.271934926509857% used
G1 Young Generation:#年轻代
Eden Space:
regions = 26
capacity = 79691776 (76.0MB)
used = 27262976 (26.0MB)
free = 52428800 (50.0MB)
34.21052631578947% used
Survivor Space:
regions = 4
capacity = 4194304 (4.0MB)
used = 4194304 (4.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:##G1老年代
regions = 14
capacity = 50331648 (48.0MB)
used = 14412272 (13.744613647460938MB)
free = 35919376 (34.25538635253906MB)
28.63461176554362% used
16879 interned Strings occupying 1583944 bytes.2、查看内存中对象数量及大小
#查看所有对象,包括活跃以及非活跃的
jmap ‐histo <pid> | more
#查看活跃对象
jmap ‐histo:live <pid> | more
[root@myshop02 bin]# jmap -histo:live 3694 | more
num #instances #bytes class name
----------------------------------------------
1: 31130 2898400 [C
2: 1402 802944 [B
3: 30895 741480 java.lang.String
4: 16607 531424 java.util.HashMap$Node
5: 3728 422344 java.lang.Class
6: 4621 406648 java.lang.reflect.Method
7: 7931 253792 java.util.concurrent.ConcurrentHashMap$Node
8: 4409 240128 [Ljava.lang.Object;
9: 1138 197296 [Ljava.util.HashMap$Node;
10: 1979 129448 [I
11: 112 107808 [Ljava.util.concurrent.ConcurrentHashMap$Node;
12: 1800 86400 java.util.HashMap
13: 5325 85200 java.lang.Object
14: 2608 55976 [Ljava.lang.Class;
15: 1292 51680 java.util.LinkedHashMap$Entry
16: 100 50304 [Ljava.util.WeakHashMap$Entry;
17: 1544 49408 java.util.Hashtable$Entry#对象说明 B byte C char D double F float I int J long Z boolean [ 数组,如[I表示int[] [L+类名 其他对象
3、将内存使用情况dump到文件中
有些时候我们需要将jvm当前内存中的情况dump到文件中,然后对它进行分析,jmap也是支持dump到文件中的。
#用法:
jmap ‐dump:format=b,file=dumpFileName <pid>
#示例
jmap ‐dump:format=b,file=/root/dump.dat 3694
已经在/root下生成了dump.dat文件
4、jhat对dump文件进行分析
在上一小节中,我们将jvm的内存dump到文件中,这个文件是一个二进制的文件,不方便查看,这时我们可以借助于jhat工具进行查看。
#用法:
jhat ‐port <port> <file>
#示例:
[root@myshop02 ~]# jhat -port 9998 /root/dump.dat
Reading from /root/dump.dat...
Dump file created Mon Apr 06 15:10:56 CST 2020
Snapshot read, resolving...
Resolving 269315 objects...
Chasing references, expect 53 dots.....................................................
Eliminating duplicate references.....................................................
Snapshot resolved.
Started HTTP server on port 9998
Server is ready.打开浏览器进行访问:http://192.168.0.108:9998
如果访问不了,需要防火墙开放9998端口。
[root@myshop02 ~]# firewall-cmd --zone=public --add-port=9998/tcp --permanent;
success
[root@myshop02 ~]# systemctl restart firewalld.service;在最后面有OQL查询功能 。
点开之后可以执行OQL查询语句,如下,左侧是查询结果,字符串长度>=100的都查询出来了
5、MAT工具对dump文件进行分析
1)、MAT工具介绍
MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具,是一个快速、功能丰富的JAVA heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。
2)、下载安装
官网下载地址:https://www.eclipse.org/mat/downloads.php
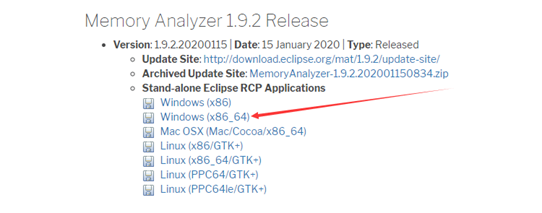
下载解压后,双击打开
3)、使用
打开一个dump文件
选择自动检测
可疑对象查找
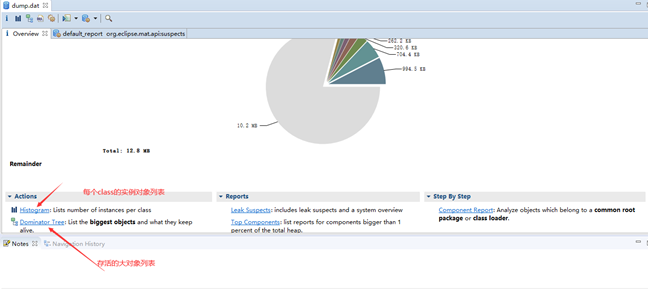
点击Histogram
点击dominator_tree查看依赖对象
查看可能存在内存泄露的分析
五、实战:内存溢出的定位与分析
内存溢出在实际的生产环境中经常会遇到,比如,不断的将数据写入到一个集合中,出 现了死循环,读取超大的文件等等,都可能会造成内存溢出。
如果出现了内存溢出,首先我们需要定位到发生内存溢出的环节,并且进行分析,是正 常还是非正常情况,如果是正常的需求,就应该考虑加大内存的设置,如果是非正常需 求,那么就要对代码进行修改,修复这个bug,我们需要借助 于jmap与MAT工具进行定位分析。
接下来,我们模拟内存溢出的场景。
1、模拟内存溢出
编写代码,向List集合中添加100万个字符串,每个字符串由1000个UUID组成。如果程序能够正常执行,最后打印ok(idea编辑器中需要设置内存溢出相关参数)
#参数如下:
‐Xms8m ‐Xmx8m ‐XX:+HeapDumpOnOutOfMemoryError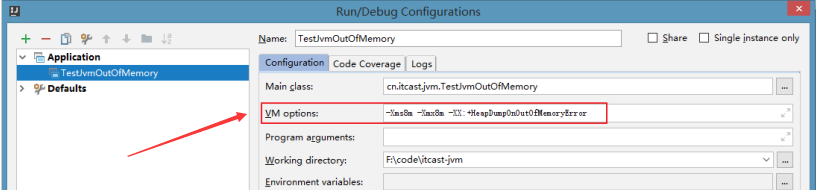
package com.zte.oom;
import java.util.ArrayList;
import java.util.UUID;
/**************************************************
*
* @title qq184480602
* @desc ling
* @author smart哥
*
**************************************************/
public class TestOOM {
public static void main(String[] args) {
ArrayList<String> stringArrayList = new ArrayList<>();
for (int i = 0; i <1000000 ; i++) {
String str="";
for (int j = 0; j <1000 ; j++) {
str=str+UUID.randomUUID().toString();
}
stringArrayList.add(str);
}
System.out.println("it is over!!");
}
}2、运行测试
运行一段时间后会抛出java.lang.OutOfMemoryError: Java heap space 异常。
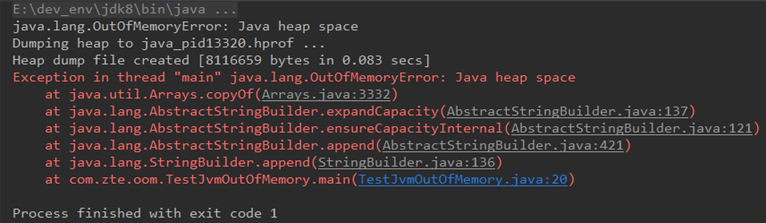
可以看到,发生了内存溢出,此时会dump文件到java_pid13320.hprof文件中。
3、导入到MAT工具中进行分析
查看Leak Suspects视图
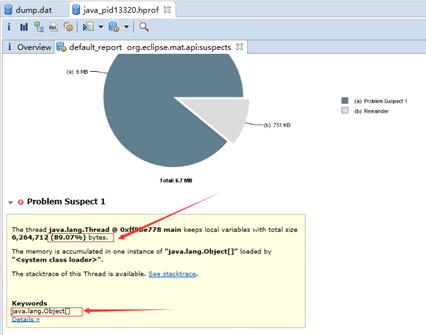
可以看到,有89.07%的内存由Object[]数组占有,所以比较可疑。 分析:这个可疑是正确的,因为已经有超过89%的内存都被它占有,这是非常有可能出现内存溢出的。 查看Object Details视图详情如下
查看Object Details视图
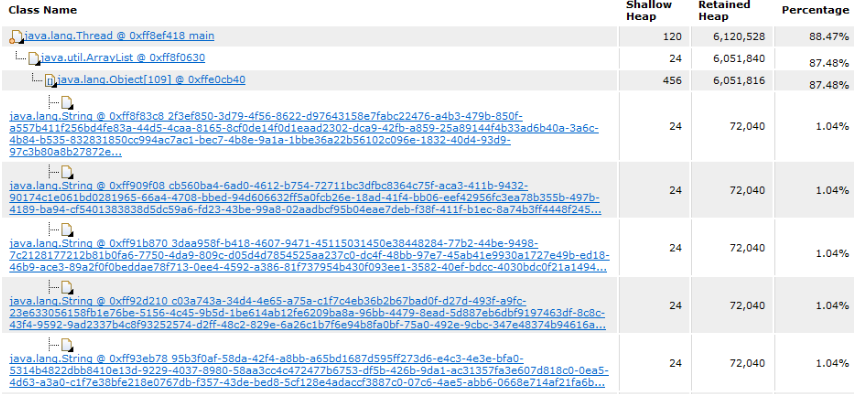
可以看到集合中存储了大量的uuid字符串。
继续查看dominator视图进一步验证。
查看dominator视图
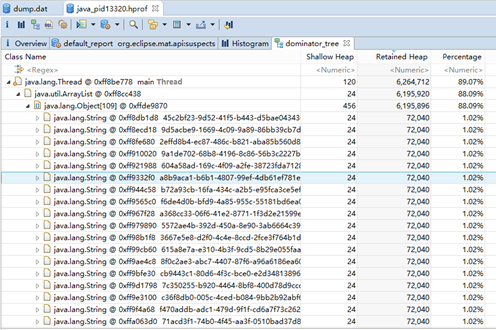
具体分析过程请观看视频
六、jstack的使用
有些时候我们需要查看下jvm中的线程执行情况,比如,发现服务器的CPU的负载突然增 高了、出现了死锁、死循环等,我们该如何分析呢?
由于程序是正常运行的,没有任何的输出,从日志方面也看不出什么问题,所以就需要 看下jvm的内部线程的执行情况,然后再进行分析查找出原因。
这个时候,就需要借助于jstack命令了,jstack的作用是将正在运行的jvm的线程情况进 行快照,并且打印出来 :
#用法:jstack <pid>
[root@myshop02 ~]# jstack 3694
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.202-b08 mixed mode):
"Attach Listener" #32 daemon prio=9 os_prio=0 tid=0x00007fed14008800 nid=0x138c waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Catalina-utility-2" #31 prio=1 os_prio=0 tid=0x00007fed2005c000 nid=0xe91 waiting on condition [0x00007fed0cfc9000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c030dbc8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1088)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
......1、线程的状态
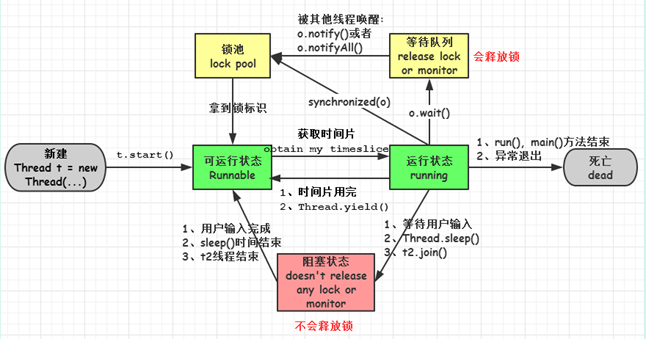
由上图可知,在Java中线程的状态一共被分成6种:
1)、初始态(NEW)
创建一个Thread对象,但还未调用start()启动线程时,线程处于初始态。
2)、运行态(RUNNABLE)
在Java中,运行态包括 就绪态和运行态。
就绪态:
该状态下的线程已经获得执行所需的所有资源,只要CPU分配执行权就能运 行。
所有就绪态的线程存放在就绪队列中。
运行态:
获得CPU执行权,正在执行的线程。
由于一个CPU同一时刻只能执行一条线程,因此每个CPU每个时刻只有一条 运行态的线程。
3)、阻塞态(BLOCKED)
当一条正在执行的线程请求某一资源失败时,就会进入阻塞态。
而在Java中,阻塞态专指请求锁失败时进入的状态。
由一个阻塞队列存放所有阻塞态的线程。
处于阻塞态的线程会不断请求资源,一旦请求成功,就会进入就绪队列,等待执行。
4)、等待态(WAITING)
当前线程中调用wait、join、park函数时,当前线程就会进入等待态。
也有一个等待队列存放所有等待态的线程。
线程处于等待态表示它需要等待其他线程的指示才能继续运行。
进入等待态的线程会释放CPU执行权,并释放资源(如:锁)
5)、超时等待态(TIMED_WAITING)
当运行中的线程调用sleep(time)、wait、join、parkNanos、parkUntil时,就 会进入该状态;
它和等待态一样,并不是因为请求不到资源,而是主动进入,并且进入后需要其 他线程唤醒;
进入该状态后释放CPU执行权 和 占有的资源。
与等待态的区别:到了超时时间后自动进入阻塞队列,开始竞争锁。
6)、终止态(TERMINATED)
线程执行结束后的状态。
2、实战:死锁问题
如果在生产环境发生了死锁,我们将看到的是部署的程序没有任何反应了,这个时候我们可以借助jstack进行分析,下面我们实战下查找死锁的原因。
-
构造死锁
思路:两个线程thread1,thread2,thread1拥有obj1锁,thread2拥有obj2锁。此时thread1想要获取obj2锁,thread2也想要获取obj1锁,于是出现死锁。
代码如下:
public class TestDeadLock { private static Object obj1 = new Object(); private static Object obj2 = new Object(); public static void main(String[] args) { new Thread(new Thread1()).start(); new Thread(new Thread2()).start(); } private static class Thread1 implements Runnable { @Override public void run() { synchronized (obj1) { try { System.out.println(">>>>>>>>>>>" + Thread.currentThread().getName() + "获取了obj1锁"); Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (obj2) { System.out.println(">>>>>>>>>>>" + Thread.currentThread().getName() + "获取了obj2锁"); } } } } private static class Thread2 implements Runnable { @Override public void run() { synchronized (obj2) { try { System.out.println(">>>>>>>>>>>" + Thread.currentThread().getName() + "获取了obj2锁"); Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (obj1) { System.out.println(">>>>>>>>>>>" + Thread.currentThread().getName() + "获取了obj1锁"); } } } } }
-
编码测试
E:\dev_env\jdk8\bin\java "-javaagent:E:\smart_an1\devtool\JetBrains\IntelliJ IDEA 2018.1\lib\idea_rt.jar=20149:E:\smart_an1\devtool\JetBrains\IntelliJ IDEA 2018.1\bin" -Dfile.encoding=UTF-8 -classpath E:\dev_env\jdk8\jre\lib\charsets.jar;E:\dev_env\jdk8\jre\lib\deploy.jar;E:\dev_env\jdk8\jre\lib\ext\access-bridge-64.jar;E:\dev_env\jdk8\jre\lib\ext\cldrdata.jar;E:\dev_env\jdk8\jre\lib\ext\dnsns.jar;E:\dev_env\jdk8\jre\lib\ext\jaccess.jar;E:\dev_env\jdk8\jre\lib\ext\jfxrt.jar;E:\dev_env\jdk8\jre\lib\ext\localedata.jar;E:\dev_env\jdk8\jre\lib\ext\nashorn.jar;E:\dev_env\jdk8\jre\lib\ext\sunec.jar;E:\dev_env\jdk8\jre\lib\ext\sunjce_provider.jar;E:\dev_env\jdk8\jre\lib\ext\sunmscapi.jar;E:\dev_env\jdk8\jre\lib\ext\sunpkcs11.jar;E:\dev_env\jdk8\jre\lib\ext\zipfs.jar;E:\dev_env\jdk8\jre\lib\javaws.jar;E:\dev_env\jdk8\jre\lib\jce.jar;E:\dev_env\jdk8\jre\lib\jfr.jar;E:\dev_env\jdk8\jre\lib\jfxswt.jar;E:\dev_env\jdk8\jre\lib\jsse.jar;E:\dev_env\jdk8\jre\lib\management-agent.jar;E:\dev_env\jdk8\jre\lib\plugin.jar;E:\dev_env\jdk8\jre\lib\resources.jar;E:\dev_env\jdk8\jre\lib\rt.jar;E:\dev_env\IdeaProjects\performance-tuning\out\production\oom com.zte.deadlock.TestDeadLock >>>>>>>>>>>Thread-0获取了obj1锁 >>>>>>>>>>>Thread-1获取了obj2锁 //程序卡死在这里,互相等待锁
-
使用jstack进行分析
使用jstack命令查看死锁结果并分析如下:
在输出的信息中,已经看到,发现了1个死锁,关键看这个
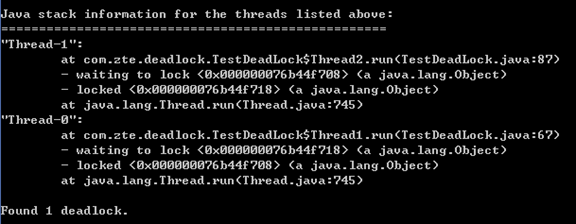
七、jvisualvm的使用
使用jvisualvm能够监控线程,内存情况,查看方法的CPU时间和内存中的对象,已被GC的对象,反向查看分配的堆栈(如100个String对象分别由哪几个对象分配出来的)。
jvisualvm使用简单,几乎0配置,功能还是比较丰富的,几乎囊括了其它JDK自带命令的所有功能。
- 内存信息
- 线程信息
- Dump堆(本地进程)
- Dump线程(本地进程)
- 打开堆Dump。堆Dump可以用jmap来生成。
- 打开线程Dump
- 生成应用快照(包含内存信息、线程信息等等)
- 性能分析。CPU分析(各个方法调用时间,检查哪些方法耗时多),内存分析(各类 对象占用的内存,检查哪些类占用内存多)
- ……
1、启动
在jdk的安装目录的bin目录下,找到jvisualvm.exe,双击打开即可
2、查看本地进程
在本地进程页(idea)可以看到jvm基本信息及参数信息
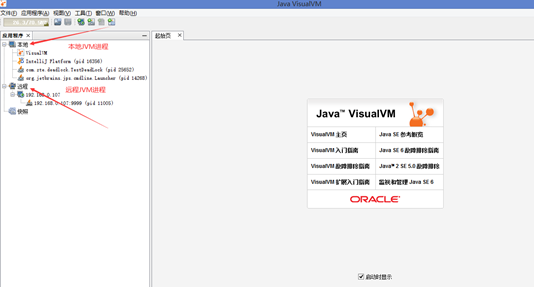
3、查看CPU、内存、类、线程运行信息
4、查看线程详情
点击右上角Dump线程,将线程的信息导出,其实就是执行的jstack命令
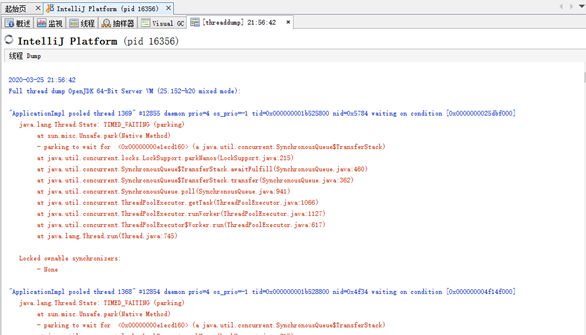
5、抽样器
抽样器可以对CPU、内存在一段时间内进行抽样,以供分析
6、监控远程的jvm
jvisualvm不仅是可以监控本地jvm进程,还可以监控远程的jvm进程,需要借助于JMX技术实现。
-
什么是JMX?
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系 统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络 传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。
-
监控远程的tomcat
想要监控远程的tomcat,就需要在远程的tomcat进行对JMX配置,配置完毕重启tomcat
#在tomcat的bin目录下,修改catalina.sh,添加如下的参数 CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote -Djava.rmi.server.hostname=192.168.0.108 -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" #这几个参数的意思是: #‐Dcom.sun.management.jmxremote :允许使用JMX远程管理 #‐Dcom.sun.management.jmxremote.port=9999 :JMX远程连接端口 #‐Dcom.sun.management.jmxremote.authenticate=false :不进行身份认证,任何用户都可以连接 #‐Dcom.sun.management.jmxremote.ssl=false :不使用ssl
-
使用jvisualvm连接远程tomcat
添加远程主机(右击远程,添加主机)
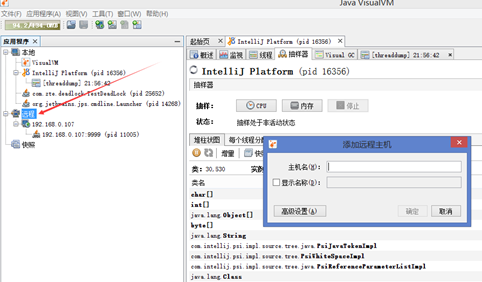
在一个主机下可能会有很多的jvm需要监控,所以在该主机上添加需要监控的jvm
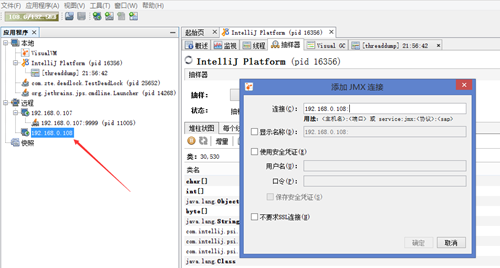
添加成功,如下图所示
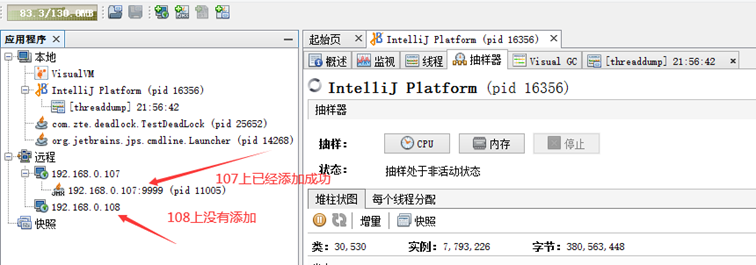
八、本章小结
一、什么是垃圾回收?
程序的运行必然需要申请内存资源,无效的对象资源如果不及时处理就会一直占有内存资源,最终将导致内存溢出,所以对内存资源的管理是非常重要了,对无效对象的内存回收就叫做垃圾回收。
1、c/c++语言中的垃圾回收
在C/C++语言中,没有自动垃圾回收机制,是通过new关键字申请内存资源,通过delete关键字释放内存资源。
如果,程序员在某些位置没有写delete进行释放,那么申请的对象将一直占用内存资源,最终可能会导致内存溢出 。
2、java语言中的垃圾回收
为了让程序员更专注于代码的实现,而不用过多的考虑内存释放的问题,所以,在Java语言中,有了自动的垃圾回收机制,也就是我们熟悉的GC。
有了垃圾回收机制后,程序员只需要关心内存的申请即可,内存的释放由系统自动识别完成。
换句话说,自动的垃圾回收的算法就会变得非常重要了,如果因为算法的不合理,导致内存资源一直没有释放,同样也可能会导致内存溢出的。
当然,除了Java语言,C#、Python等语言也都有自动的垃圾回收机制。
二、垃圾回收的常见算法
自动化的管理内存资源,垃圾回收机制必须要有一套算法来进行计算,哪些是有效的对象,哪些是无效的对象,对于无效的对象就要进行回收处理。
常见的垃圾回收算法有:引用计数法、标记清除法、标记压缩法、复制算法、分代算法等。
1、引用计数法
引用计数是历史最悠久的一种算法,最早George E. Collins在1960的时候首次提出,60年后的今天,该算法依然被很多编程语言使用。
1)、原理
假设有一个对象A,任何一个对象对A的引用,那么对象A的 引用计数器+1,当引用失败时,对象A的引用计数器就-1,如果对象A的计数器的值为0,就说明对象A没有引用了,可以被回收。
2)、优缺点
优点:
- 实时性较高,无需等到内存不够的时候,才开始回收,运行时根据对象的计数器是否为0,就可以直接回收。
- 在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报outofmemory 错误。
- 区域性,更新对象的计数器时,只是影响到该对象,不会扫描全部对象。
缺点:
- 每次对象被引用时,都需要去更新计数器,有一点时间开销。
- 浪费CPU资源,即使内存够用,仍然在运行时进行计数器的统计。
- 无法解决循环引用问题。(最大的缺点)
什么是循环引用?
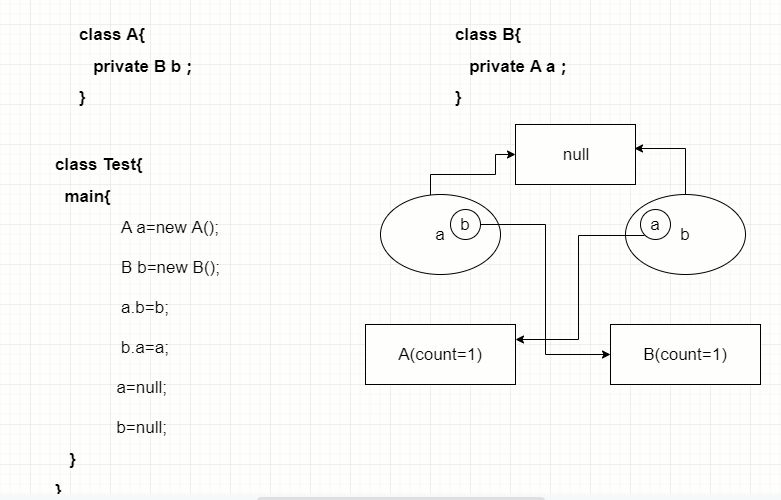
具体讲解请观看视频
2、标记清除法
标记清除算法是将垃圾回收分为2个阶段,分别是标记和清除。
标记:从根节点开始标记引用的对象
清除:未被标记引用的对象就是垃圾对象,可以被清理
1)、原理
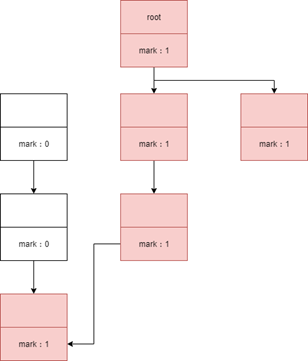
上面这张图代表的是程序运行期间所有对象的状态,它们的标志位全部是0(也就是未标记,以下默认0就是未标记,1为已标记),假设这会儿有效内存空间耗尽了,JVM将会停止应用程序的运行并开启GC线程,然后开始进行标记工作,按照根搜索算法,标记完以后,所有从root对象可达的对象就被标记为了存活的对象,此时已经完成了第一阶段标记。接下来,就要执行第二阶段清除了,那么清除完以后,剩下的对象以及对象的状态如下图所示 :
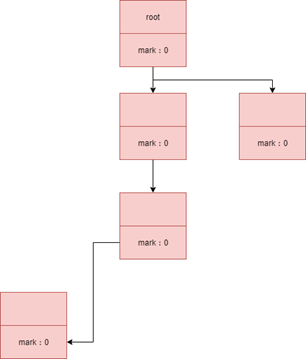
可以看到,没有被标记的对象将会回收清除掉,而被标记的对象将会留下,并且会将标记位重新归0。接下来就不用说了,唤醒停止的程序线程,让程序继续运行即可。
2)、优缺点
优点:
- 标记清除算法解决了引用计数算法中的循环引用的问题,没有从root节点引用的对象都会被回收。
缺点:
- 效率较低,标记和清除两个动作都需要遍历所有的对象,并且在GC时,需要停止应用程序,对于交互性要求比较高的应用而言这个体验是非常差的。
- 通过标记清除算法清理出来的内存,碎片化较为严重,因为被回收的对象可能存在于内存的各个角落,所以清理出来的内存是不连贯的。
3、标记压缩法
标记压缩算法是在标记清除算法的基础之上,做了优化改进的算法。和标记清除算法一样,也是从根节点开始,对对象的引用进行标记,在清理阶段,并不是简单的清理未标记的对象,而是将存活的对象压缩到内存的一端,然后清理边界以外的垃圾,从而解决了碎片化的问题。
1)、原理
2)、优缺点
优缺点同标记清除算法,解决了标记清除算法的碎片化的问题,同时,标记压缩算法多了一步,对象移动内存位置的步骤,其效率也有一定的影响。
4、复制算法
复制算法的核心就是,将原有的内存空间一分为二,每次只用其中的一块,在垃圾回收时,将正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换两个内存的角色,完成垃圾的回收。
如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该方式并且效率比较高,反之,则不适合。
1)、原理
具体分析讲解见视频
2)、JVM中年轻代内存空间
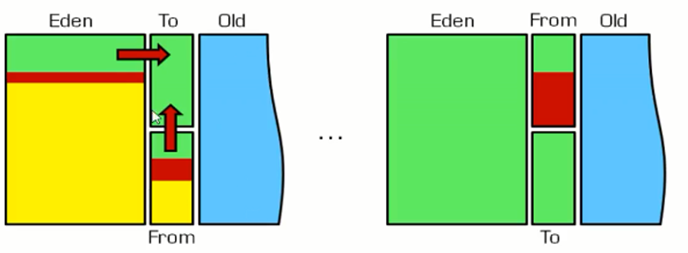
- 在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。
- 紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。
- 经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。不管怎样,都会保证名为To的Survivor区域是空的。
- GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
3)、优缺点
优点:
- 在垃圾对象多的情况下,效率较高 。
- 清理后,内存无碎片。
缺点:
- 在垃圾对象少的情况下,不适用,如:老年代内存。
- 分配的2块内存空间,在同一个时刻,只能使用一半,内存使用率较低
5、分代算法
前面介绍了多种回收算法,每一种算法都有自己的优点也有缺点,谁都不能替代谁,所以根据垃圾回收对象的特点进行选择,才是明智的选择。
分代算法其实就是这样的,根据回收对象的特点进行选择,在jvm中,年轻代适合使用复制算法,老年代适合使用标记清除或标记压缩算法。
三、垃圾收集器及内存分配
前面我们讲了垃圾回收的算法,还需要有具体的实现,在jvm中,实现了多种垃圾收集器,包括:串行垃圾收集器、并行垃圾收集器、CMS(并发)垃圾收集器、G1垃圾收集器,接下来,我们一个个的了解学习。
垃圾收集器种类
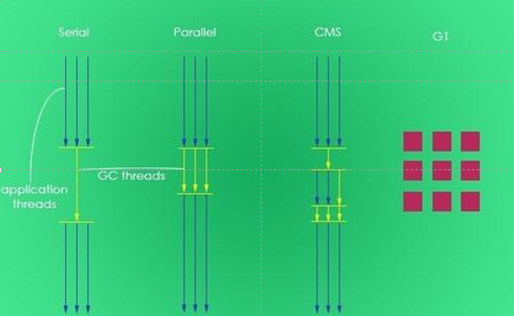
HotSpot虚拟机所包含的收集器
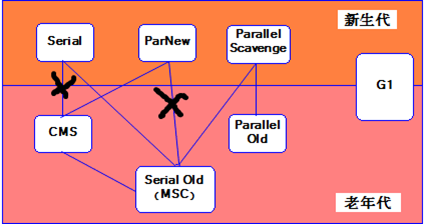
垃圾收集器部分源码
垃圾收集器后台日志参数说明与配对关系
- DefNew - Default New Generation
- Tenured - Old
- ParNew - Parallel New Generation
- PSYoungGen - Parallel Scavenge
- ParOldGen - Parallel Old Generation
以上不同种类,已经回收器的配对使用分析讲解见视频
1、串行垃圾收集器
串行垃圾收集器是最基本的、发展历史最悠久的收集器。
特点:单线程、简单高效(与其他收集器的单线程相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。收集器进行垃圾回收时,必须暂停其他所有的工作线程,直到它结束(Stop The World)。
串行垃圾收集器运行示意图
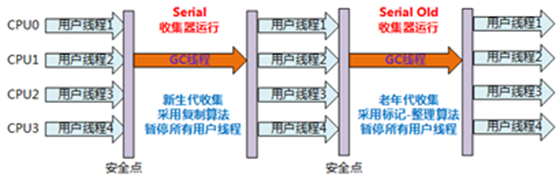
串行垃圾收集器原理分析见视频
1)、编写测试代码
思路:while循环中不断拼接字符串,直到oom异常,查看gc情况
import java.util.UUID;
/**************************************************
*
* @title
* @desc ling
* @author smart哥
*
**************************************************/
public class TestGC1 {
/**
* java -XX:+PrintCommandLineFlags -version
*
* @param args
*/
public static void main(String[] args) {
String str = "smart哥";
while (true) {
str += str + UUID.randomUUID();
str.intern();
}
}
}2)、设置垃圾回收为串行收集器
在程序运行参数中添加2个参数,如下:
-XX:+UseSerialGC 指定年轻代和老年代都使用串行垃圾收集器
-XX:+PrintGCDetails 打印垃圾回收的详细信息
3)、启动程序,GC日志信息解读
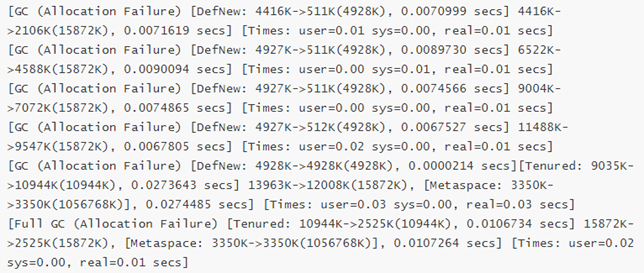
具体解读请观看视频
2、并行垃圾收集器
并行垃圾收集器在串行垃圾收集器的基础之上做了改进,将单线程改为了多线程进行垃圾回收,这样可以缩短垃圾回收的时间。(这里是指,并行能力较强的机器)
当然了,并行垃圾收集器在收集的过程中也会暂停应用程序,这个和串行垃圾回收器是一样的,只是并行执行,速度更快些,暂停的时间更短一些。
并行垃圾收集器-ParNew运行示意图
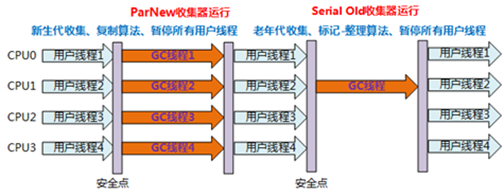
ParNew垃圾收集器
通过-XX:+UseParNewGC参数设置年轻代使用ParNew回收器,老年代使用的依然是串行收集器
通过-XX:+ParallelGCThreads可以限制GC线程数量,默认开启和cpu数目相同的线程数
具体讲解见视频
1)、编写测试代码
同之前的代码
2)、设置垃圾回收为并行收集器ParNew
在程序运行参数中添加1个参数,如下
-XX:+UseParNewGC
3)、启动程序,GC日志信息解读
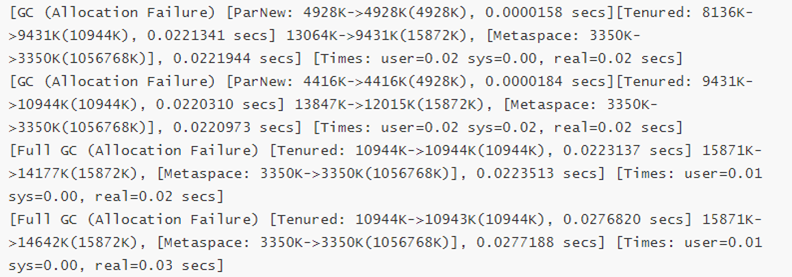
具体解读请观看视频
并行垃圾收集器-ParallelGC运行示意图
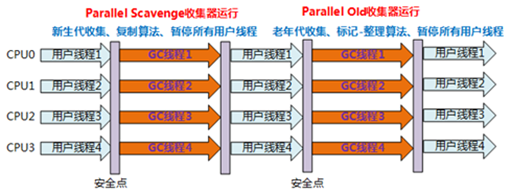
ParallelGC垃圾收集器
ParallelGC收集器工作机制和ParNewGC收集器一样,只是在此基础之上,新增了两个和系统吞吐量相关的参数,使得其使用起来更加的灵活和高效。
具体讲解见视频
1)、编写测试代码
同之前的代码
2)、设置垃圾回收为并行收集器ParallelGC
ParallelGC垃圾收集器相关参数如下:
-XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis -XX:ParallelGCThreads=N
3)、启动程序,GC日志信息解读
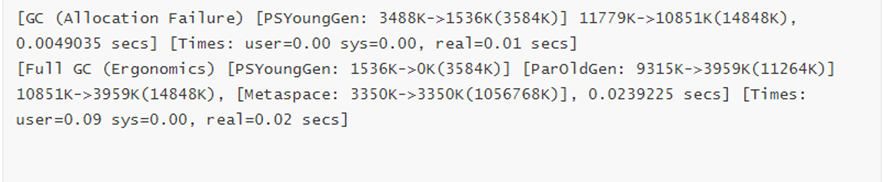
具体解读见视频
3、CMS垃圾收集器
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,该回收器是针对老年代垃圾回收的,通过参数-XX:+UseConcMarkSweepGC进行设置。
CMS垃圾收集器运行示意图:
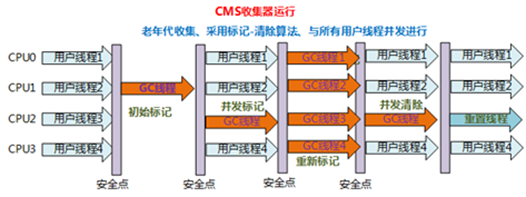
示意图原理讲解见视频
CMS垃圾回收器的执行过程如下:
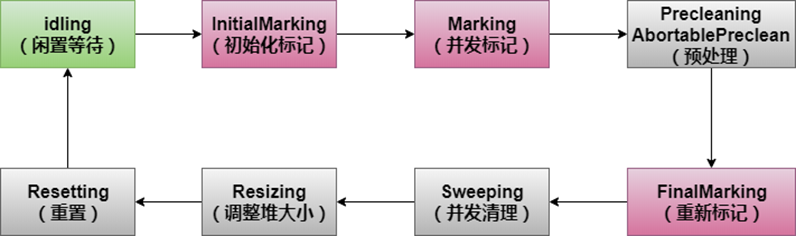
执行过程具体讲解见视频
1)、编写测试代码
同之前的代码
2)、设置CMS垃圾回收参数
-‐XX:+UseConcMarkSweepGC
注意:开启后将采用ParNew+CMS+Serial Old收集器组合
3)、启动程序,GC日志信息解读

具体解读见视频
4、G1垃圾收集器
G1垃圾收集器是在jdk1.7update4中正式使用的全新的垃圾收集器,oracle官方在jdk9中将G1变成默认的垃圾收集器,以替代CMS。
G1的设计原则就是简化JVM性能调优,开发人员只需要简单的三步即可完成调优:
- 第一步,开启G1垃圾收集器
- 第二步,设置堆的最大内存
- 第三步,设置最大的停顿时间
- G1中提供了三种模式垃圾回收模式,Young GC、Mixed GC 和 Full GC,在不同的条件下被触发。
G1垃圾收集器相对比其他收集器而言,最大的区别在于它取消了年轻代、老年代的物理划分,取而代之的是将堆划分为若干个区域(Region),这些区域中包含了有逻辑上的年轻代、老年代区域。这样做的好处就是,我们再也不用单独的空间对每个代进行设置了,不用担心每个代内存是否足够。
G1垃圾收集器(将新生代,老年代的物理空间划分取消了),示意图如下
G1垃圾收集器(G1算法将堆划分为若干个区域-Region)
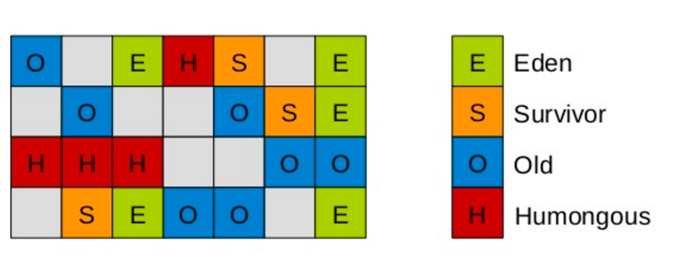
G1垃圾收集器原理
在G1划分的区域中,年轻代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。
这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有cms内存碎片问题的存在了。
在G1中,有一种特殊的区域,叫Humongous区域。如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。
这些巨型对象,默认直接会被分配在老年代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。
为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
针对Young GC主要是对Eden区进行GC,它在Eden空间耗尽时会被触发。Eden空间的数据移动到Survivor空间中,如果Survivor空间不够,Eden空间的部分数据会直接晋升到年老代空间。
Survivor区的数据移动到新Survivor区中,也有部分数据晋升到老年代空间中。最终Eden空间的数据为空,GC停止工作,应用线程继续执行。
G1垃圾回收模式:Young GC
具体模式讲解见视频
G1垃圾回收模式:Mixed GC
分2步:
- 全局并发标记(global concurrent marking)
- 拷贝存活对象(evacuation)
G1垃圾收集器运行示意图
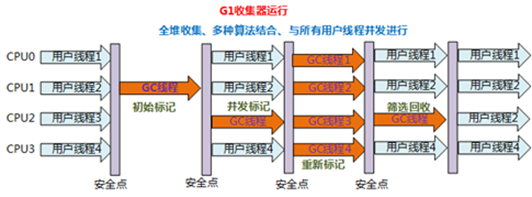
具体讲解见视频
1)、编写测试代码
同之前的代码
2)、设置G1垃圾回收参数
‐XX:+PrintGC 输出GC日志 ‐XX:+PrintGCDetails 输出GC的详细日志 ‐XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式) ‐XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013‐05‐04T21:53:59.234+0800) ‐XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息 ‐Xloggc:F://test//gc.log 日志文件的输出路径
3)、启动程序,GC日志信息解读
G1垃圾收集器 vs CMS垃圾收集器
- G1不会产生碎片
- G1可以精准控制停顿,它把整堆划分为多个固定大小的区域,每次根据停顿时间去收集垃圾最多的区域
G1垃圾收集器优化建议
-
年轻代大小
- 避免使用 -Xmn 选项或 -XX:NewRatio 等其他相关选项显式设置年轻代大小
- 固定年轻代的大小会覆盖暂停时间目标
-
暂停时间目标不要太过严苛
- G1 GC 的吞吐量目标是 90% 的应用程序时间和 10%的垃圾回收时间
- 评估 G1 GC 的吞吐量时,暂停时间目标不要太严苛。目标太过严苛表示您愿意承受更多的垃圾回收开销,而这会直接影响到吞吐量
五、可视化GC日志分析工具
1、GC日志输出参数
前面通过-XX:+PrintGCDetails可以对GC日志进行打印,我们就可以在控制台查看,这样虽然可以查看GC的信息,但是并不直观,可以借助于第三方的GC日志分析工具进行查看。 在日志打印输出涉及到的参数如下:
‐XX:+PrintGC 输出GC日志
‐XX:+PrintGCDetails 输出GC的详细日志
‐XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
‐XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013‐05‐
04T21:53:59.234+0800)
‐XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
‐Xloggc:../logs/gc.log 日志文件的输出路径测试:
‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=100 ‐Xmx256m ‐XX:+PrintGCDetails ‐
XX:+PrintGCTimeStamps ‐XX:+PrintGCDateStamps ‐XX:+PrintHeapAtGC ‐
Xloggc:F://test//gc.log最后生成gc.log,我们利用下面的可视化工具进行分析。
2、GC Easy可视化工具
GC Easy是一款在线的可视化工具,易用、功能强大, GCEasy官网地址:http://gceasy.io/
打开官网上传gc.log,点击分析即可。分析完之后它会给我们出相关的分析报告,那查看指标如何解读呢?
具体解读见视频
GC Easy查看gc报告
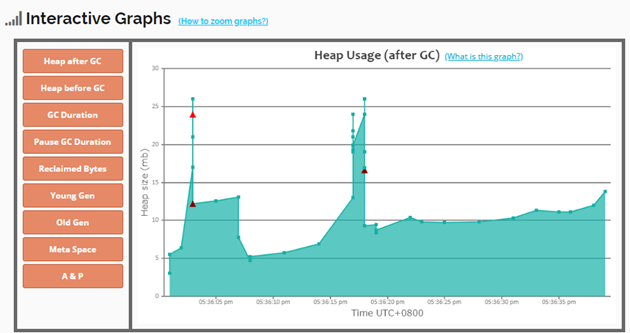
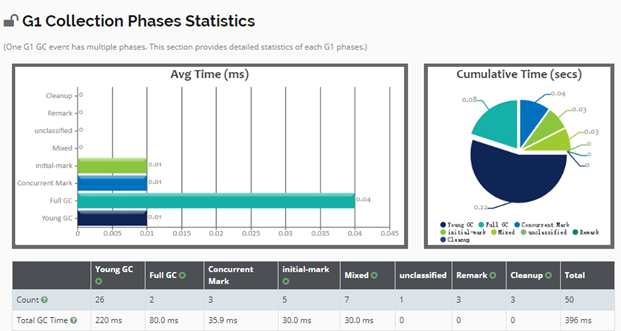
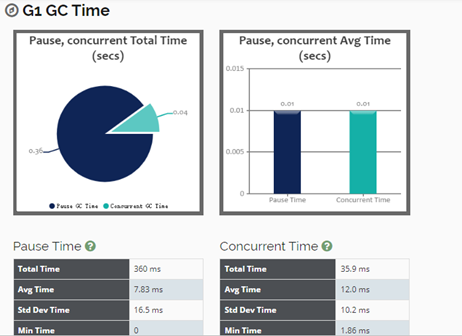
分析报告解读请观看视频
六、本章小结
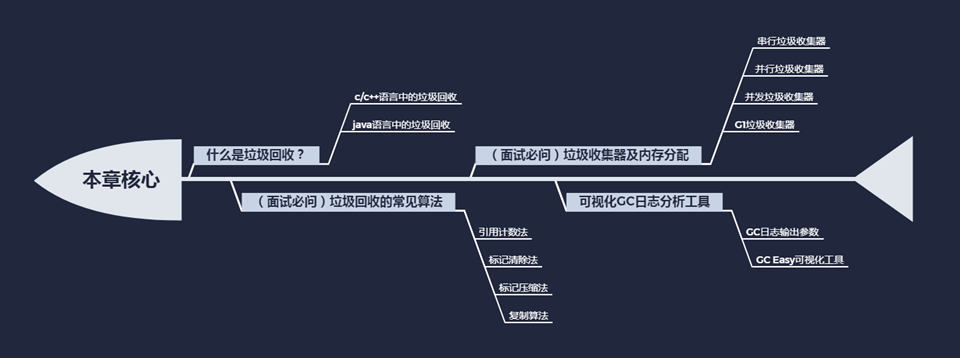

 浙公网安备 33010602011771号
浙公网安备 33010602011771号