


GO编程模式
Go编程模式:切片,接口,时间和性能 | 酷 壳 - CoolShell
在本篇文章中,我会对Go语言编程模式的一些基本技术和要点,这样可以让你更容易掌握Go语言编程。其中,主要包括,数组切片的一些小坑,还有接口编程,以及时间和程序运行性能相关的话题。
Slice
首先,我们先来讨论一下Slice,中文翻译叫“切片”,这个东西在Go语言中不是数组,而是一个结构体,其定义如下:
用图示来看,一个空的slice的表现如下:
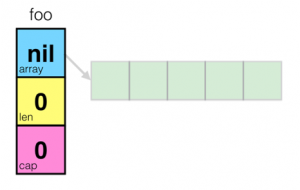 熟悉C/C++的同学一定会知道,在结构体里用数组指针的问题——数据会发生共享!下面我们来看一下slice的一些操作
熟悉C/C++的同学一定会知道,在结构体里用数组指针的问题——数据会发生共享!下面我们来看一下slice的一些操作
对于上面这段代码。
- 首先先创建一个foo的slice,其中的长度和容量都是5
- 然后开始对foo所指向的数组中的索引为3和4的元素进行赋值
- 然后,对foo做切片后赋值给bar,再修改bar[1]
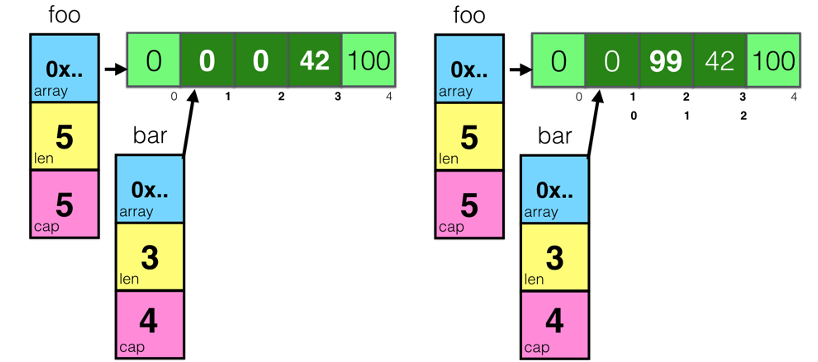
通过上图我们可以看到,因为foo和bar的内存是共享的,所以,foo和bar的对数组内容的修改都会影响到对方。
接下来,我们再来看一个数据操作 append() 的示例
上面这段代码中,把 a[1:16] 的切片赋给到了 b ,此时,a 和 b 的内存空间是共享的,然后,对 a做了一个 append()的操作,这个操作会让 a 重新分享内存,导致 a 和 b 不再共享,如下图所示:

从上图我们可以看以看到 append()操作让 a 的容量变成了64,而长度是33。这里,需要重点注意一下——append()这个函数在 cap 不够用的时候就会重新分配内存以扩大容量,而如果够用的时候不不会重新分享内存!
我们再看来看一个例子:
上面这个例子中,dir1 和 dir2 共享内存,虽然 dir1 有一个 append() 操作,但是因为 cap 足够,于是数据扩展到了dir2 的空间。下面是相关的图示(注意上图中 dir1 和 dir2 结构体中的 cap 和 len 的变化)
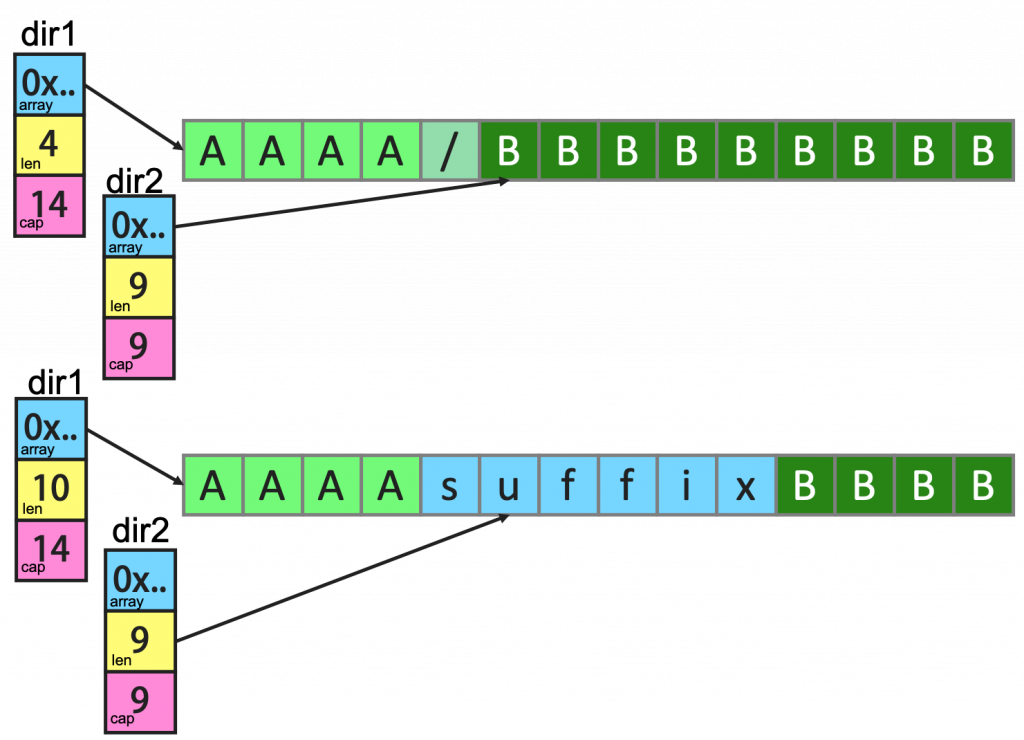
如果要解决这个问题,我们只需要修改一行代码。
修改为
新的代码使用了 Full Slice Expression,其最后一个参数叫“Limited Capacity”,于是,后续的 append() 操作将会导致重新分配内存。
深度比较
当我们复杂一个对象时,这个对象可以是内建数据类型,数组,结构体,map……我们在复制结构体的时候,当我们需要比较两个结构体中的数据是否相同时,我们需要使用深度比较,而不是只是简单地做浅度比较。这里需要使用到反射 reflect.DeepEqual() ,下面是几个示例
接口编程
下面,我们来看段代码,其中是两个方法,它们都是要输出一个结构体,其中一个使用一个函数,另一个使用一个“成员函数”。
你更喜欢哪种方式呢?在 Go 语言中,使用“成员函数”的方式叫“Receiver”,这种方式是一种封装,因为 PrintPerson()本来就是和 Person强耦合的,所以,理应放在一起。更重要的是,这种方式可以进行接口编程,对于接口编程来说,也就是一种抽象,主要是用在“多态”,这个技术,在《Go语言简介(上):接口与多态》中已经讲过。在这里,我想讲另一个Go语言接口的编程模式。
首先,我们来看一下,有下面这段代码:
其中,我们可以看到,其使用了一个 Printable 的接口,而 Country 和 City 都实现了接口方法 PrintStr() 而把自己输出。然而,这些代码都是一样的。能不能省掉呢?
我们可以使用“结构体嵌入”的方式来完成这个事,如下的代码所示,
引入一个叫 WithName的结构体,然而,所带来的问题就是,在初始化的时候,变得有点乱。那么,我们有没有更好的方法?下面是另外一个解。
上面这段代码,我们可以看到——我们使用了一个叫Stringable 的接口,我们用这个接口把“业务类型” Country 和 City 和“控制逻辑” Print() 给解耦了。于是,只要实现了Stringable 接口,都可以传给 PrintStr() 来使用。
这种编程模式在Go 的标准库有很多的示例,最著名的就是 io.Read 和 ioutil.ReadAll 的玩法,其中 io.Read 是一个接口,你需要实现他的一个 Read(p []byte) (n int, err error) 接口方法,只要满足这个规模,就可以被 ioutil.ReadAll这个方法所使用。这就是面向对象编程方法的黄金法则——“Program to an interface not an implementation”
接口完整性检查
另外,我们可以看到,Go语言的编程器并没有严格检查一个对象是否实现了某接口所有的接口方法,如下面这个示例:
我们可以看到 Square 并没有实现 Shape 接口的所有方法,程序虽然可以跑通,但是这样编程的方式并不严谨,如果我们需要强制实现接口的所有方法,那么我们应该怎么办呢?
在Go语言编程圈里有一个比较标准的作法:
声明一个 _ 变量(没人用),其会把一个 nil 的空指针,从 Square 转成 Shape,这样,如果没有实现完相关的接口方法,编译器就会报错:
cannot use (*Square)(nil) (type *Square) as type Shape in assignment: *Square does not implement Shape (missing Area method)
这样就做到了个强验证的方法。
时间
对于时间来说,这应该是编程中比较复杂的问题了,相信我,时间是一种非常复杂的事(比如《你确信你了解时间吗?》、《关于闰秒》等文章)。而且,时间有时区、格式、精度等等问题,其复杂度不是一般人能处理的。所以,一定要重用已有的时间处理,而不是自己干。
在 Go 语言中,你一定要使用 time.Time 和 time.Duration 两个类型:
- 在命令行上,
flag通过time.ParseDuration支持了time.Duration - JSon 中的
encoding/json中也可以把time.Time编码成 RFC 3339 的格式 - 数据库使用的
database/sql也支持把DATATIME或TIMESTAMP类型转成time.Time - YAML你可以使用
gopkg.in/yaml.v2也支持time.Time、time.Duration和 RFC 3339 格式
如果你要和第三方交互,实在没有办法,也请使用 RFC 3339 的格式。
最后,如果你要做全球化跨时区的应用,你一定要把所有服务器和时间全部使用UTC时间。
性能提示
Go 语言是一个高性能的语言,但并不是说这样我们就不用关心性能了,我们还是需要关心的。下面是一个在编程方面和性能相关的提示。
- 如果需要把数字转字符串,使用
strconv.Itoa()会比fmt.Sprintf()要快一倍左右 - 尽可能地避免把
String转成[]Byte。这个转换会导致性能下降。 - 如果在for-loop里对某个slice 使用
append()请先把 slice的容量很扩充到位,这样可以避免内存重新分享以及系统自动按2的N次方幂进行扩展但又用不到,从而浪费内存。 - 使用
StringBuffer或是StringBuild来拼接字符串,会比使用+或+=性能高三到四个数量级。 - 尽可能的使用并发的 go routine,然后使用
sync.WaitGroup来同步分片操作 - 避免在热代码中进行内存分配,这样会导致gc很忙。尽可能的使用
sync.Pool来重用对象。 - 使用 lock-free的操作,避免使用 mutex,尽可能使用
sync/Atomic包。 (关于无锁编程的相关话题,可参看《无锁队列实现》或《无锁Hashmap实现》) - 使用 I/O缓冲,I/O是个非常非常慢的操作,使用
bufio.NewWrite()和bufio.NewReader()可以带来更高的性能。 - 对于在for-loop里的固定的正则表达式,一定要使用
regexp.Compile()编译正则表达式。性能会得升两个数量级。 - 如果你需要更高性能的协议,你要考虑使用 protobuf 或 msgp 而不是JSON,因为JSON的序列化和反序列化里使用了反射。
- 你在使用map的时候,使用整型的key会比字符串的要快,因为整型比较比字符串比较要快。
Go 语言简介(上)— 语法 | 酷 壳 - CoolShell
Go 语言简介(下)— 特性 | 酷 壳 - CoolShell
程序员惯用的解释(Top 25) | 酷 壳 - CoolShell
关于闰秒
2012年6月30日,也就今天晚上,时间会多出现一秒,也就是我们所说的闰秒。我不知道大家对闰秒的了解有多少,所以写下这篇文章。
背景知识
闰秒是在在UTC(中文“世界标准时间”或“世界协调时间”/英文“Coordinated Universal Time”/法文“Temps Universel Cordonné”)是基于Atomic Clock(原子时钟)的一种时间,向太阳时(Solar Time )对齐的一种方法,因为太阳时是根据地球公转来计算的。所以,1972年制定的UTC为了确保其时间相对于UTC的时间误差不能超过0.9秒,因此在过一段时间后需要加一秒。下图是有UTC以来闰秒的调整表(来自Wikipedia闰秒的中文词条)

从上表中我们可以看到,从1972年到现在,在这四十年里已经进行过25次的闰秒调整。闰秒是在每年6月或12月的最后一天的最后一分钟进行跳秒或不跳秒。是否加入闰秒由位于巴黎的国际地球自转和参考坐标系统服务(IERS – International Earth Rotation and Reference Systems Service)决定。如果决定加入闰秒,那么这一秒是被加在第二天的00:00:00前的,也就是说,时间会出现23:59:60的情况,然后才是第二天的00:00:00。如果是负闰秒的话,23:59:58的下一秒就直接跳到第二天的00:00:00了。现在,所有闰秒都是正闰秒。
计算机处理闰秒
那么,对于我们的电脑系统来说,怎么处理这个闰秒呢?一般来说,我们需要为我们的电脑系统配置UTC时钟,并通过NTP (Network time protocol)来进行时间同步,NTP服务器会一级一级地下发闰秒事件通知直到最边缘的NTP服务器,然后NTP服务器就会把闰秒通知发给客户端的操作系统,由操作系统来处理闰秒通知。
虽然闰秒调整对普通民众的日常生活不会产生影响。不过,这个问题将影响部分开启ntp服务的Linux操作系统——会导致Linux内核Crash!Linux kernel是在2.6.18-164.e15之后的版本中解决了这个问题。换句话说,Linux kernel低于2.6.18-164的Linux系统,无论是什么公司的Linux都将受到影响。(今晚过后大家可以查看一下你的Linux系统日志,看看闰秒有没有发生)
可以参看下面的bug描述:
- LKML: Chris Adams: Re: Bug: Status/Summary of slashdot leap-second crash on new years 2008-2009
- Bug 479765 – Leap second message can hang the kernel
那么,我们的操作系统是怎么处理正闰秒通知的?通常来说有三种实现:
- 后退一秒。
- 停止一秒。
- 真正的增加一秒。
懂编程的人一眼就能看出来,前两种方式是以一种Workaround或Hack的方式解决这个问题。第一种方式会导致一些基于timestamp的消息通知乱序了,而第二种会导致出现两个一模一样的timestamp。最后一种不会出现timestamp的问题。对了,你还记得以前那篇《你确信你了解时间吗?》的文章吗?
最后,说说Windows,Windows Time Service不支持闰秒通知,所以,当闰秒发生的时候,你的Windows上的时间会比实际时间快一秒钟,这需要等下一次的时钟同步才会完成修正。你可以查看这篇文章:http://support.microsoft.com/kb/909614/en-us
编写无锁代码:更正的队列
正如我们上个月所看到的 [1],即使对于专家来说,无锁编码也很难。在那里,我剖析了一个已发布的无锁队列实现 [2] 并检查了为什么代码很糟糕。这个月,让我们看看如何正确地做到这一点。
无锁基础
在编写无锁代码时,请始终牢记以下要点:
关键概念。在交易中思考。知道谁拥有什么数据。
在编写无锁数据结构时,“在事务中思考”意味着确保对数据结构的每个操作都是原子的,相对于对同一数据的其他并发操作而言,要么全有要么全无。要使用的典型编码模式是将工作放在一边,然后通过单个原子写入或比较和交换“发布”对共享数据的每个更改。[3] 确保并发写入器不会相互干扰或与并发读取器相互干扰,并特别注意删除或移除并发操作可能仍在使用的数据的任何操作。
在任何给定时间高度了解谁拥有哪些数据;错误意味着两个线程认为它们可以继续进行相互冲突的工作的竞赛。通过查看说明它是谁的有序原子变量的值,您现在知道谁拥有给定的共享数据。要将某些数据的所有权移交给另一个线程,请在事务结束时使用单个原子操作执行此操作,这意味着“现在它是您的了”。
有序原子变量是一个“无锁安全”变量,具有以下属性,可以在没有任何显式锁定的情况下安全地跨线程读取和写入:
原子性。相对于该变量的所有其他读取和写入,每个单独的读取和写入都保证是原子的。变量通常适合机器的本机字大小,因此通常是指针 (C++)、对象引用(Java、.NET)或整数。
variable.compare_exchange( expectedValue, newValue ) ,作为原子操作执行以下操作:如果variable当前具有 value expectedValue,则将 value 设置为newValue并返回 true;否则返回假。一个常见的用法是if(variable.compare_exchange(x,y)),,您应该养成阅读的习惯,“如果我是将变量从 更改x为 的人y。”
有序的原子变量在流行的平台和环境中以不同的方式拼写。例如:
volatile在 C#/.NET 中,如在volatile int.
volatile或* Atomic* 在 Java 中,如volatile int, AtomicInteger。
atomic<T>在 C++0x 中,即将推出的 ISO C++ 标准,如atomic<int>.
在接下来的代码中,我将突出显示此类变量的关键读取和写入;这些变量应该跳出屏幕,你应该习惯于每次触摸它们时都非常清楚。
如果你的语言和平台上还没有有序的原子变量,你可以使用普通但对齐的变量来模拟它们,这些变量的读写保证是自然原子的,并通过使用特定于平台的有序 API 调用来强制排序(例如InterlockedCompareExchange用于比较和交换的Win32 )或特定于平台的显式内存栅栏/屏障(例如, Linux mb)。
修正的单生产者、单消费者无锁队列
现在让我们使用我们的基本工具来解决无锁队列。在第一次尝试中,为了更容易地与 [2] 中的原始代码进行比较,我将非常接近原始设计和实现,包括我将继续做出相同的简化假设,即只有一个消费者线程和一个生产者线程,这样我们就可以轻松安排它们始终在底层链表的不同部分工作。在图 1 中,第一个“未消费”项目是divider. 消费者增加divider表示它已经消费了一个项目。生产者递增last表示它已经生产了一个项目,并且还在divider.

这是类定义,它小心地将共享变量标记为有序原子类型(使用 C++ 以最接近 [2] 中的原始代码):
template <typename T>class LockFreeQueue {private: struct Node { Node( T val ) : value(val), next(nullptr) { } T value; Node* next; }; Node* first; // for producer only atomic<Node*> divider, last; // shared |
构造函数只是使用虚拟元素初始化列表。析构函数(在 C# 或 Java 中,即方法)释放列表。在以后的专栏中,我将详细讨论为什么共享对象的构造函数和析构函数不需要担心并发性和与同一对象的方法的竞争;现在的简短答案是,创建或拆除对象应始终孤立运行,因此不需要内部同步。dispose
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public: LockFreeQueue() { first = divider = last = new Node( T() ); // add dummy separator } ~LockFreeQueue() { while( first != nullptr ) { // release the list Node* tmp = first; first = tmp->next; delete tmp; } } |
接下来,我们将介绍关键方法和 。图 2 显示了列表的另一个视图,通过颜色编码谁拥有哪些数据:生产者拥有之前的所有节点、节点内的指针以及更新和 的能力。使用者拥有其他所有内容,包括从开始节点中的值,以及更新的能力。ProduceConsumedividernextlastfirstlastdividerdivider
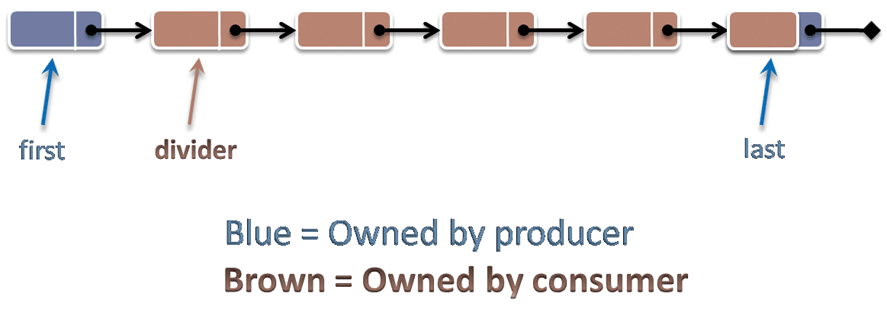
制片人
Produce仅在生产者线程上调用:
|
1
2
3
4
5
6
7
8
9
|
void Produce( const T& t ) { last->next = new Node(t); // add the new item last = last->next; // publish it while( first != divider ) { // trim unused nodes Node* tmp = first; first = first->next; delete tmp; }} |
首先,创建者创建一个包含该值的新节点,并将其链接到当前节点。此时,该节点尚未共享,但仍对生产者线程私有,即使存在指向它的链接;消费者不会跟随该链接,除非的值说它可以跟随它。最后,当所有实际工作都完成时(节点存在,其值被完全初始化,并且正确连接),然后,只有这样,我们才会写入"提交"更新并将其原子发布到使用者线程。使用者读取 ,然后看到旧值(并忽略新的部分构造元素,即使指针可能已经设置),或者正式祝福新节点作为队列的已批准部分的新值,准备使用。Nodelastlastlastlastlast->next
最后,创建器对现在未使用的节点执行延迟清理。因为我们总是在 之前停止,这不会与消费者在列表后面可能执行的任何操作发生冲突。如果我们在循环中,消费者正在消费物品并改变价值,该怎么办?没问题:每次我们读取 时,我们都会在使用者的任何并发更新之前或之后看到它,这两者都让生产者以一致的状态查看列表。dividerdividerdivider
消费者
Consume仅在使用者线程上调用:
|
1
2
3
4
5
6
7
8
9
|
bool Consume( T& result ) { if( divider != last ) { // if queue is nonempty result = divider->next->value; // C: copy it back divider = divider->next; // D: publish that we took it return true; // and report success } return false; // else report empty }}; |
首先,使用者通过原子读取、原子读取和比较来检查列表是否为非空。这种一次性检查是安全的,因为尽管在我们运行此方法的其余部分时,生产者可能会更改 '的值,但如果检查为真一次,即使移动也会保持为真,因为永远不会备份;它只能向前移动以发布新的尾部节点 - 这不会影响使用者,他们只关心之后的第一个节点。如果之后有一个有效节点,则使用者将复制其值,然后,最后,继续发布队列项已被删除。dividerlastlastlastlastdividerdividerdivider
是的,我们可以消除共享变量的需要:使用者仅使用 的值来检查 在 之后是否有另一个节点,我们可以让使用者只测试 ert 是否为非空。那很好,它可以让我们做一个普通的变量;但是如果我们这样做,我们还必须记住,此更改将使每个成员成为共享变量,因此为了使其安全,我们还必须将 的类型更改为 。我现在按原样离开,以便更容易地将此代码与[2]中的原始版本进行比较,后者确实使用这样的尾部迭代器在两个线程之间进行通信。lastlastdivider divider->nexlastnextnextatomic<Node*>last
完成工作,然后发布
您可能还注意到,[2] 中的原始代码以相反的顺序等效于行 C(复制)和 D(更新)。当你看到试图反向执行操作的代码时,你应该始终保持警惕和怀疑:请记住,我们应该把所有工作都放在一边(C行),然后才发布我们做了(D行),如前所述。divider
我敢肯定有人会指出,我们实际上可以在这段代码中编写D然后C。是的,但不要;这是一个坏习惯。确实,在这种特殊情况下,现在是一个有序的原子变量(在原始代码中并非如此),碰巧我们可以逃脱D然后C的编写,因为实现的细节与设计限制相结合:divider
我们始终在生产者和消费者之间维护一个占位符
分隔符元素,因此"发布"更改以分隔否则会太早一步,因此引用未使用的节点而不是消耗的节点,只要我们只领先一步,恰好是无害的。只有一个使用者线程,因此对Consume 的多个调用必须按顺序运行,并且永远无法提前两步。
但这仍然是一个坏习惯。依靠"快乐"的事故来偷工减料不是一个好主意,特别是因为打破正确的模式在这里没有多少好处。此外,即使我们现在写了D然后C,它可能只是我们下个月必须改变的另一件事,因为......
即将推出
下个月,我们将考虑如何推广多个生产者和使用者线程的队列。你的家庭作业:这带来了什么新问题?我们刚刚考虑的代码的哪些部分会在多个消费者面前被破坏,为什么?那么多个生产者呢?两者呢?发现问题后,您需要在代码和队列数据结构本身中更改哪些内容才能解决这些问题?
你有一个月的时间。想想你会如何处理它,当我们回来时,我们会接受挑战。
笔记
[1] H·萨特。"无锁代码:虚假的安全感"(DDJ,2008年9月)。(www.ddj.com/cpp/210600279)。
[2] P. Marginean."无锁队列"(2008 年 7 月)。(www.ddj.com/208801974)。DDJ
[3] 这就像一个规范的异常安全模式——把所有的工作都交给一边,然后承诺只使用非抛出操作来接受新状态。"在事务中思考"适用于任何地方,并且应该在我们编写代码的方式中无处不在。
[4] 比较和交换 (CAS) 是最广泛使用的基本无锁操作,因此我将在这里重点介绍它。但是,某些系统相反地提供同等强大的负载链接/存储条件(LL / SC)。
确认
感谢蒂姆·哈里斯对本文草稿的评论。
Writing Lock-Free Code: A Corrected Queue | Dr Dobb's
一、介绍
如今,改进具有高性能约束的应用程序有一个明显的选择:多线程。线程已经存在很长时间了。在过去,当大多数计算机只有 1 个处理器时,线程主要用作将总工作划分为更小的执行单元的一种方式,允许它们在其他较小的执行单元等待资源时进行实际工作(即“处理”)。一个简单的例子是一个网络应用程序,它侦听 TCP 端口并在请求通过该端口到达时进行一些处理。在单线程方法中,在处理每个请求之前,应用程序将无法响应更多请求,因此潜在用户可能会认为应用程序在工作时已关闭。在多线程方法中,一个新线程可以负责处理端,而主线程将随时准备响应潜在用户。
在单处理器机器下,急于处理的多线程应用程序可能不会得到预期的结果。所有线程最终可能会为了让处理器能够做一些工作而“争斗”,并且整体性能可能相同,甚至比只让 1 个处理单元来完成所有工作更糟,因为需要额外的开销在线程之间通信和共享数据。
但是,在对称多处理 ( SMP ) 机器中,以前的多线程应用程序确实会同时执行多项任务(并行化)。每个线程都有一个真正的物理处理器,而不是共享唯一可用的资源。在 N 处理器 SMP 系统中,N 线程应用程序理论上可以将此类应用程序所需的时间减少 N 倍(它总是更少,因为仍然有一些开销来跨线程通信或共享数据)。
过去 SMP 机器非常昂贵,只有对此类软件有浓厚兴趣的公司才能负担得起,但现在多核处理器相当便宜(现在出售的大多数计算机都有 1 个以上的内核),因此可以并行处理此类应用程序由于它对性能的巨大影响,它变得越来越流行。
但是多线程并不是一件容易的事。线程必须共享数据并相互通信,很快你就会发现自己面临着同样的老问题:死锁、对共享数据的不受控制的访问、跨线程的动态内存分配/删除等。此外,如果你足够幸运的话要在具有高性能约束的应用程序上工作,还会有一组不同的问题严重影响您心爱的多线程系统的整体性能:
- 缓存垃圾
- 对您的同步机制的争用。队列
- 动态内存分配
这篇文章是关于如何使用基于数组的无锁队列来最小化前 3 个与性能相关的问题。特别是动态内存分配的使用,因为这是这个无锁队列最初设计时的主要目标。
2. 同步线程如何降低整体性能
2.1 缓存清理
线程是(来自维基百科):“操作系统可以调度的最小处理单元”。每个操作系统都有自己的线程实现,但基本上一个进程包含一组指令(代码)和进程本地的一块内存。线程运行一段代码,但与包含它的进程共享内存空间。在 Linux(我正在写的这个队列最初打算在这个操作系统中工作)中,线程只是另一个“执行上下文”,在这个操作系统中“没有线程的概念。Linux 将线程实现为标准进程。 Linux 内核并没有提供任何特殊的调度语义或数据结构来表示线程,线程只是一个进程与其他进程共享某些资源。
这些正在运行的任务、线程、执行上下文中的每一个或任何您可能想调用它们的东西,都使用 CPU 的一组寄存器来运行。它们包含任务的内部数据,例如当前正在运行的指令的地址、某些操作的操作数和/或结果、指向堆栈的指针等。这组信息称为“上下文”。任何抢先式操作系统(大多数现代操作系统都是抢先式的)必须能够在几乎任何时间停止正在运行的任务,将上下文保存在某处,以便将来可以恢复(很少有例外,例如声明自己在一段时间内不可抢占来做某事的进程)。一旦任务恢复,它将恢复它正在做的任何事情,就好像什么都没发生过一样。这是一件好事,处理器是跨任务共享的,因此可以抢占等待 I/O 的任务,从而允许另一个任务接管。单处理器系统可以表现得好像它们是多处理器一样,但是,就像生活中的一切一样,有一个权衡:处理器是共享的,但每次任务被抢占时,都会有开销来保存/恢复两个退出的上下文和进入任务。
在保存/恢复上下文中还有一个额外的隐藏开销:保存到缓存中的数据对于新进程将毫无用处,因为它是为以前的现有任务缓存的。重要的是要考虑到处理器比内存快几倍,因此等待内存读取/写入来自处理器的数据会浪费大量处理时间。这就是高速缓存被放置在标准 RAM 内存和处理器之间的原因。它们是更快、更小(而且更昂贵)的内存插槽,从标准 RAM 访问的数据被复制到其中,因为它可能会在不久的将来再次访问。在处理密集型应用程序中,缓存未命中非常重要 为了提高性能,因为当数据已经在缓存中时,处理时间会快很多倍。
因此,任何时候一个任务被抢占缓存都可能被以下进程覆盖,这意味着该进程在恢复运行后需要一段时间才能像在被抢占之前一样高效。(一些操作系统 - 例如,linux - 尝试恢复上次使用的处理器任务上的进程,但是根据后面的进程需要多少内存,缓存也可能没用)。当然我并不是说抢占不好,操作系统需要抢占才能正常工作,但是根据您的MT系统的设计,某些线程可能会经常被抢占,这会因现金垃圾而降低性能。
那么什么时候任务被抢占呢?这在很大程度上取决于您的操作系统,但中断处理、计时器和系统调用很可能导致操作系统抢占子系统决定将处理时间分配给系统中的其他一些进程。这实际上是操作系统难题的一个非常重要的部分,因为没有人希望进程空闲(饥饿)太久。一些系统调用是“阻塞的”,这意味着任务向操作系统请求资源并等待它准备好,因为该任务需要资源继续运行。这是可抢占任务的一个很好的例子,因为它在资源准备好之前什么都不做,所以操作系统会将该任务置于等待状态并将处理器交给其他一些任务来工作。
资源基本上是内存或硬盘、网络、外围设备中的数据,但也包括信号量或互斥锁等阻塞同步机制。如果一个任务试图进入一个已经被持有的互斥锁,它会被抢占,一旦互斥锁再次可用,该线程将被添加到“准备运行”的任务队列中。因此,如果您担心您的进程被过于频繁地抢占(和缓存垃圾),您应该尽可能避免阻塞同步机制。
但作为生活中的任何事情,它从来都不是那么容易。如果在避免阻塞同步机制时使用比物理处理器数量更多的线程来处理密集型任务,则系统延迟可能会受到影响。操作系统轮换任务的次数越少,当前不活动的进程越等待,直到它们找到要恢复的空闲处理器。 甚至可能会发生整个应用程序可能被命中的情况,因为它正在等待一个饥饿的线程在系统之前完成一些计算可以上前去做别的事情。没有有效的公式,它始终取决于您的应用程序、系统和操作系统. 例如,在处理密集型实时应用程序中,我会选择使用非阻塞机制来同步线程,并且线程比物理处理器少,尽管这可能并不总是可行的。在其他一些大部分时间都空闲等待来自网络的数据的应用程序中,非阻塞同步可能是一种矫枉过正(最终可能会杀死你)。这里没有秘诀,每种方法都有自己的优点和缺点,由您决定使用什么。
2.2 对同步机制的争论。队列
队列可以很容易地适用于各种不同的多线程情况。如果两个或多个线程需要按顺序传递事件,我首先想到的是队列。易于理解、易于使用、经过充分测试且易于教授(即便宜)。世界上的每个程序员都不得不处理队列。他们无处不在。
队列在单线程应用程序中很容易使用,并且它们可以“轻松”地适应多线程系统。您只需要一个不受保护的队列(例如std::queue在 C++ 中)和一些阻塞同步机制(例如互斥锁和条件变量)。我在文章中上传了一个使用 glib 实现的阻塞队列的简单示例(这使其与移植 glib 的各种操作系统兼容)。虽然没有真正需要用这样的队列重新发明轮子,因为GAsyncQueue [7] 是一个已经包含在 Glib 中的安全队列的实现,但是这段代码是一个很好的例子,说明了如何将标准队列转换为线程安全的。
让我们来看看队列中最常见的方法的实现:IsEmpty,Push和Pop。基本非受保护队列是std::queue已声明为std::queue<t> m_theQueue;</t>。我们将在这里看到的三种方法展示了非安全实现是如何用 GLib 互斥体和条件变量(声明为GMutex* m_mutexand Cond* m_cond)包装的。可以从本文下载的真实队列也包含TryPush并且TryPop如果队列已满或为空,则不会阻塞调用线程
template <typename T>
bool BlockingQueue<T>::IsEmpty()
{
bool rv;
g_mutex_lock(m_mutex);
rv = m_theQueue.empty();
g_mutex_unlock(m_mutex);
return rv;
}
IsEmpty如果队列没有元素,则预期返回 true,但在任何线程可以访问队列的非安全实现之前,它必须受到保护。这意味着调用线程可能会被阻塞一段时间,直到互斥锁被释放
template <typename T>
bool BlockingQueue<T>::Push(const T &a_elem)
{
g_mutex_lock(m_mutex);
while (m_theQueue.size() >= m_maximumSize)
{
g_cond_wait(m_cond, m_mutex);
}
bool queueEmpty = m_theQueue.empty();
m_theQueue.push(a_elem);
if (queueEmpty)
{
// wake up threads waiting for stuff
g_cond_broadcast(m_cond);
}
g_mutex_unlock(m_mutex);
return true;
}
Push将元素插入队列队列。如果另一个线程拥有保护队列的锁,则调用线程将被阻塞。如果队列已满,线程将在此调用中被阻塞,直到其他人从队列中弹出一个元素,但是调用线程在等待其他人从队列中弹出元素时不会使用任何 CPU 时间,因为它已被操作系统置于睡眠状态
template <typename T>
void BlockingQueue<T>::Pop(T &out_data)
{
g_mutex_lock(m_mutex);
while (m_theQueue.empty())
{
g_cond_wait(m_cond, m_mutex);
}
bool queueFull = (m_theQueue.size() >= m_maximumSize) ? true : false;
out_data = m_theQueue.front();
m_theQueue.pop();
if (queueFull)
{
// wake up threads waiting for stuff
g_cond_broadcast(m_cond);
}
g_mutex_unlock(m_mutex);
}
Pop从队列中提取一个元素(并将其从队列中移除)。如果另一个线程拥有保护队列的锁,则调用线程将被阻塞。如果队列为空,则线程将在此调用中被阻塞,直到其他人将元素推送到队列中,但是(正如 发生的那样Push)调用线程在等待其他人推送时不会使用任何 CPU 时间离开队列的元素,因为它已被操作系统置于睡眠状态
正如我在上一节中试图解释的那样,阻塞不是一个微不足道的动作。它涉及操作系统将当前任务“搁置”或休眠(等待而不使用任何处理器)。一旦某些资源(例如互斥锁)可用,被阻塞的任务就可以解除阻塞(唤醒),这也不是一个微不足道的操作,因此它可以继续进入互斥锁。在使用这些阻塞队列在线程之间传递消息的重负载应用程序中,可能会导致争用,也就是说,与实际使用该数据做“某事”相比,任务花费更多的时间来声明互斥锁(休眠、等待、唤醒)来访问队列中的数据。
在最简单的情况下,一个线程将数据插入队列(生产者),另一个线程将数据删除(消费者),两个线程都在“争夺”保护队列的唯一互斥锁。如果我们选择编写自己的队列实现而不是仅仅包装现有的队列,我们可以使用 2 个不同的互斥锁,一个用于插入,另一个用于从队列中删除项目。这种情况下的争用仅适用于极端情况,即队列几乎为空或几乎已满。现在,一旦我们需要超过 1 个线程从队列中插入或删除元素,我们的问题又回来了,消费者或生产者将争夺互斥锁。
这是非阻塞机制适用的地方。任务不会“争夺”任何资源,它们在队列中“保留”一个位置而不会被阻塞或解除阻塞,然后它们会从队列中插入/删除数据。这些机制需要一种称为CAS(Compare And Swap)的特殊操作,它(来自维基百科)定义为“一种特殊的指令,它以原子方式将内存位置的内容与给定值进行比较,并且仅当它们相同时,才修改该内存位置的内容为给定的新值”。例如:
volatile int a;
a = 1;
// this will loop while 'a' is not equal to 1. If it is equal to 1 the operation will atomically
// set a to 2 and return true
while (!CAS(&a, 1, 2))
{
;
}
使用CAS实现无锁队列不是一个全新的课题。有很多数据结构实现的例子,其中大部分使用链表。看看 [2] [3] 或 [4]。本文的目的不是描述无锁队列是什么,但基本上是:
- 到插入新的数据到一个新的节点被分配(用malloc)队列和它被插入到使用所述队列
CAS操作 - 为了从队列中移除一个元素,它使用 CAS 操作来移动链表的指针,然后它检索被移除的节点来访问数据
这是一个基于链表的无锁队列的简单实现示例(复制自 [2],谁基于 [5])
typedef struct _Node Node;
typedef struct _Queue Queue;
struct _Node {
void *data;
Node *next;
};
struct _Queue {
Node *head;
Node *tail;
};
Queue*
queue_new(void)
{
Queue *q = g_slice_new(sizeof(Queue));
q->head = q->tail = g_slice_new0(sizeof(Node));
return q;
}
void
queue_enqueue(Queue *q, gpointer data)
{
Node *node, *tail, *next;
node = g_slice_new(Node);
node->data = data;
node->next = NULL;
while (TRUE) {
tail = q->tail;
next = tail->next;
if (tail != q->tail)
continue;
if (next != NULL) {
CAS(&q->tail, tail, next);
continue;
}
if (CAS(&tail->next, null, node)
break;
}
CAS(&q->tail, tail, node);
}
gpointer
queue_dequeue(Queue *q)
{
Node *node, *tail, *next;
while (TRUE) {
head = q->head;
tail = q->tail;
next = head->next;
if (head != q->head)
continue;
if (next == NULL)
return NULL; // Empty
if (head == tail) {
CAS(&q->tail, tail, next);
continue;
}
data = next->data;
if (CAS(&q->head, head, next))
break;
}
g_slice_free(Node, head); // This isn't safe
return data;
}
在那些没有垃圾收集器(C++ 就是其中之一)的编程语言中,对 g_slice_free 的最新调用并不安全,因为所谓的ABA 问题:
- 线程 T1 读取要出队的值并在第一次调用 CAS 之前停止
queue_dequeue - 线程 T1 被抢占。T2 尝试
CAS删除同一个节点 T1 即将出列的操作 - 它成功并释放为该节点分配的内存
- 同一个线程(或一个新线程,对于 instace T3)将排队一个新节点。对 malloc 的调用返回与在步骤 2-3 中删除的节点使用的地址相同的地址。它将该节点添加到队列中
- T1再次占用处理器,
CAS由于地址相同,操作不正确,但它不是同一个节点。T1删除错误的节点
该ABA问题可以固定添加参考计数器到每个节点。在假设 CAS 操作是正确的以避免 ABA 问题之前,必须检查这个引用计数器。好消息是本文所讨论的队列没有遇到 ABA 问题,因为它不使用动态内存分配。
2.3 动态内存分配
在多线程系统中,必须认真考虑内存分配。该标准的内存分配机制将阻止所有共享内存空间的任务从堆上保留内存时,它是为一个任务分配空间(所有进程的线程)。这是一种简单的做事方式,而且很有效,无法为 2 个线程分配相同的内存地址,因为它们不能同时分配空间。但是当线程经常分配内存时它很慢(并且必须注意,诸如将元素插入标准队列或标准映射之类的小事情会在堆上分配内存)
有一些库会覆盖标准分配机制,以提供无锁内存分配机制来减少堆争用,例如libhoard [6]。这种类型有很多不同的库,如果您从标准 C++ 分配器切换到这些基于无锁的内存分配器之一,它们会对您的系统产生重大影响。但有时它们不仅仅是系统所需要的,软件必须加倍努力并改变其同步机制。
3. 基于循环数组的无锁队列
所以,最后,这是基于循环数组的无锁队列,这篇文章的初衷就是这个。它的开发旨在降低上述 3 个问题的影响。其特性可以概括为以下特征列表:
- 作为一种无锁同步机制,它降低了进程被抢占的频率,从而减少了缓存垃圾。
- 此外,作为任何无锁队列,线程之间的争用会大大减少,因为没有锁来保护任何数据结构:线程基本上首先要求空间,然后用数据占用它。
- 它不需要像其他无锁队列实现那样在堆中分配任何东西。
- 它也不受 ABA 问题的影响,尽管它在数组处理中增加了一定程度的开销。
3.1 它是如何工作的?
队列基于一个数组和 3 个不同的索引:
writeIndex: 将插入新元素的位置。readIndex: 从哪里提取下一个元素。maximumReadIndex: 它指向插入最新“提交”数据的位置。如果它与 writeIndex 不同,则表示有待“提交”到队列的写入,这意味着保留了数据的位置(数组中的索引)但数据仍然不在队列中,因此尝试读取的线程将不得不等待其他线程将数据保存到队列中。
值得一提的是,需要 3 个不同的索引,因为队列允许根据需要设置尽可能多的生产者和消费者。已经有一篇关于单生产者和单消费者配置队列的文章 [11]。它的简单方法绝对值得一读(我一直很喜欢KISS 原则)。事情变得更加复杂,因为队列对于所有类型的线程配置都必须是安全的。
3.1.1 CAS 操作
这个无锁队列的同步机制是基于比较和交换 CPU 指令的。CAS 操作包含在 4.1.0 版的 GCC 中。因为我用GCC 4.4编译这个算法,我决定采取内置GCC CAS操作所谓的优势__sync_bool_compare_and_swap(这是描述在这里)。为了支持多个编译器,此操作在文件中CAS使用 a被“映射”到单词:#defineatomic_ops.h
/// @brief Compare And Swap
/// If the current value of *a_ptr is a_oldVal, then write a_newVal into *a_ptr
/// @return true if the comparison is successful and a_newVal was written
#define CAS(a_ptr, a_oldVal, a_newVal) __sync_bool_compare_and_swap(a_ptr, a_oldVal, a_newVal)
如果你打算用其他编译器编译这个队列,你需要做的就是定义一个操作 CAS 以某种方式与你的编译器一起工作。它必须适合以下接口:
- 第一个参数是要改变的变量的地址
- 第二个参数是旧值
- 第三个参数是如果等于第二个将保存到第一个的值
- 如果成功则返回真(非零)。否则为假
3.1.2 向队列中插入元素
这是负责在队列中插入新元素的代码:
/* ... */
template <typename ELEM_T, uint32_t Q_SIZE>
inline
uint32_t ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(uint32_t a_count)
{
return (a_count % Q_SIZE);
}
/* ... */
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::push(const ELEM_T &a_data)
{
uint32_t currentReadIndex;
uint32_t currentWriteIndex;
do
{
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if (countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
// the queue is full
return false;
}
} while (!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex + 1)));
// We know now that this index is reserved for us. Use it to save the data
m_theQueue[countToIndex(currentWriteIndex)] = a_data;
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while (!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield();
}
return true;
}
下图描述了队列的初始配置。每个方块描述了队列中的一个位置。如果它用大 X 标记,则它包含一些数据。空白方块是空的。在这种特殊情况下,当前有 2 个元素插入到队列中。WriteIndex指向将插入新数据的位置。ReadIndex指向将在下一次调用中清空的槽pop。
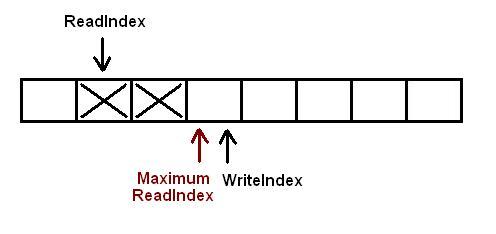
基本上,当一个新元素将被写入队列时,生产者线程“保留”队列中的空间递增WriteIndex。MaximumReadIndex指向包含有效(提交)数据的最后一个槽。

一旦保留了新空间,当前线程就可以花时间将数据复制到队列中。然后它增加MaximumReadIndex

现在有 3 个元素完全插入队列中。在下一步中,另一个任务尝试向队列中插入一个新元素

它已经预留了其数据将占用的空间,但在此任务可以将新数据复制到预留槽之前,不同的线程预留了一个新槽。有 2 个任务同时插入元素。

线程现在将它们的数据复制到它们保留的插槽中,但必须以严格的顺序完成:第一个生产者线程将递增MaximumReadIndex,然后是第二个生产者线程。严格的顺序约束很重要,因为在允许消费者线程将其从队列中弹出之前,我们必须确保插槽中保存的数据已完全提交。

第一个线程将数据提交到插槽中。现在,第二个线程允许增加MaximumReadIndex以及

第二个线程也增加了MaximumReadIndex。现在队列中有 5 个元素
3.1.3 从队列中移除元素
这是从队列中删除元素的一段代码:
/* ... */
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::pop(ELEM_T &a_data)
{
uint32_t currentMaximumReadIndex;
uint32_t currentReadIndex;
do
{
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if (countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex))
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_theQueue[countToIndex(currentReadIndex)];
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if (CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
return true;
}
// it failed retrieving the element off the queue. Someone else must
// have read the element stored at countToIndex(currentReadIndex)
// before we could perform the CAS operation
} while(1); // keep looping to try again!
// Something went wrong. it shouldn't be possible to reach here
assert(0);
// Add this return statement to avoid compiler warnings
return false;
}
这与“在队列中插入元素”部分中的起始配置相同。目前有 2 个元素插入到队列中。WriteIndex指向将插入新数据的位置。ReadIndex指向将在下一次调用 pop 时清空的插槽。

即将读取的消费者线程复制指向的元素ReadIndex并尝试对CAS相同的ReadIndex. 如果CAS操作成功,线程从队列中检索元素,并且由于CAS操作是原子的,一次只有一个线程可以增加 this ReadIndex。如果CAS操作没有成功,它将用指向的下一个插槽重试ReadIndex

另一个线程(或同一个线程)读取下一个元素。队列为空

现在一个任务正在尝试向队列中添加一个新元素。它成功保留了插槽,但更改正在等待提交。任何其他尝试弹出值的线程都知道队列不为空,因为另一个线程已经在队列中保留了一个插槽(writeIndex不等于readIndex),但它无法读取该插槽中的值,因为MaximumReadIndex仍然等于readIndex。这个尝试弹出值的线程将在pop调用中循环,直到将更改提交到队列的任务增加MaximumReadIndex或直到队列再次为空(如果生产者线程增加了MaximumReadIndex另一个消费者线程之前弹出它,则可能发生这种情况我们的线程尝试过,所以writeIndex并readIndex指向相同插槽再次)

当生产者线程将值完全插入队列时,size 将为 1,消费者线程将能够读取该值

3.1.4 生产者线程多于1个时需要让出处理器
读者此时可能已经注意到,该push函数可能会调用 funcion ( sched_yield()) 来让出处理器,这对于声称是无锁的算法来说似乎有点奇怪。正如我在本文开头试图解释的那样,多线程影响整体性能的一种方式是缓存垃圾。每当线程被抢占时,都会发生缓存垃圾回收的典型方式,操作系统必须将退出进程的状态(上下文)保存到内存中,并恢复进入进程的上下文。但是,除了这种浪费的时间之外,保存在缓存中的数据对于新进程将毫无用处,因为它是为以前的现有任务缓存的。
所以,当这个算法调用sched_yield()它时,它专门告诉操作系统:“请你能把其他人放在这个处理器上吗,因为我必须等待一些事情发生?”。无锁和阻塞同步机制之间的主要区别应该是这样一个事实,即在使用无锁算法时我们不需要被阻塞来同步线程,那么我们为什么要请求操作系统抢占呢?这个问题的答案并非微不足道。它与生产者线程如何将新数据存储到队列中有关:它们必须按 FIFO 顺序执行2 个 CAS 操作,一个用于分配队列中的空间,另一个用于通知读者他们可以读取已经存在的数据”承诺”。
如果我们的应用程序只有 1 个生产者线程(这是该队列最初设计的目的),sched_yield()则永远不会调用,因为第二个 CAS 操作(“提交”队列中的数据的那个)可以'失败。当队列中只有一个线程插入内容时(因此修改 writeIndex 和 maximumReadIndex),此操作不可能按 FIFO 顺序完成
当有超过 1 个线程将元素插入队列时,问题就开始了。在队列中插入新元素的整个过程在 3.1.2 节中解释,但基本上生产者线程执行 1 CAS 操作来“分配”存储新数据的空间,然后在数据有后执行 2 CAS 操作被复制到分配的空间中以通知消费者线程有新数据可供读取。此第二个 CAS 操作必须按 FIFO 顺序完成,即以与第一个 CAS 操作相同的顺序完成。这就是问题开始的地方。让我们考虑以下场景,有 3 个生产者 1 消费者线程:
- 线程 1、2 和 3 为按该顺序插入数据分配空间。第二个 CAS 操作必须以相同的顺序完成,即首先是线程 1,然后是线程 2,最后是线程 3。
- 线程 2 首先到达有问题的第二个 CAS 操作,但由于线程 1 还没有完成,所以它失败了。同样的事情发生在线程 3 上。
- 两个线程(2 和 3)将继续循环尝试执行它们的第二个 CAS 操作,直到线程 1 首先执行它。
- 线程 1 终于执行了它。现在线程 3 必须等待线程 2 执行其 CAS 操作。
- 线程 2 成功,线程 1 已完成,其数据已完全插入队列中。线程 3 也停止循环,因为它的 CAS 操作在线程 2 之后也成功了
在前一种情况下,生产者线程在尝试执行第二个 CAS 操作时可能会一直旋转,同时等待另一个线程执行相同操作(按顺序)。在空闲物理处理器多于使用队列的线程的多处理器机器中这可能不是那么重要:线程将在尝试对持有 maximumReadIndex 的 volatile 变量执行 CAS 操作时卡住,但是它们正在等待的线程分配了一个物理处理器,因此最终它将在运行时执行其第二个 CAS 操作在另一个物理处理器上,另一个旋转线程在执行第二个 CAS 操作时也会成功。因此,总而言之,该算法可能会保持线程循环,但这种行为是预期的(并且是期望的),因为这是它尽可能快地工作的方式。因此,没有必要为sched_yield()。事实上,应该删除该调用以实现最大性能,因为我们不想告诉操作系统在没有真正需要的时候让出处理器(以及相关的开销)。
但是,sched_yield()当生产者线程超过 1 个且物理处理器数小于总线程数时,调用 to对队列的性能非常重要。再想想之前的场景,当 3 个线程试图向队列中插入新数据时:如果线程 1 在队列中分配新空间后被抢占,但在执行第二个 CAS 操作之前,线程 2 和 3 将永远循环等待在线程 1 被唤醒之前永远不会发生的事情。这是sched_yield()调用的需要,操作系统不能保持线程 2 和 3 循环,必须尽快阻塞它们以尝试让线程 1 执行第二个 CAS 操作,以便 2 和 3 可以前进并将它们的数据提交到队列也是。
4. 队列已知问题
此无锁队列的主要目标是提供一种无需动态内存分配即可拥有无锁队列的方法。它已经成功实现,但该算法确实有一些已知的缺点,在生产环境中使用它之前应该考虑这些缺点。
4.1 使用多个生产者线程
正如第 3.1.4 节中所述(在尝试将此队列与超过 1 个生产者线程一起使用之前,您必须仔细阅读该部分)如果有超过 1 个生产者线程,它们可能最终会在尝试更新时旋转太长时间的MaximumReadIndex,因为它必须在FIFO顺序进行。这个队列最初设计的场景只有一个生产者,而且在有多个生产者线程的情况下,这个队列肯定会显示出显着的性能下降。
此外,如果您打算使用只有 1 个生产者线程的这个队列,则不需要第二个 CAS 操作(将元素提交到队列中的那个)。随着第 2 次 CAS 操作,m_maximumReadIndex应删除volatile 变量,并将对其的所有引用更改为 m_writeIndex。因此push,pop应该由以下代码片段交换:
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::push(const ELEM_T &a_data)
{
uint32_t currentReadIndex;
uint32_t currentWriteIndex;
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if (countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
// the queue is full
return false;
}
// save the date into the q
m_theQueue[countToIndex(currentWriteIndex)] = a_data;
// No need to increment write index atomically. It is a
// requierement of this queue that only one thred can push stuff in
m_writeIndex++;
return true;
}
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::pop(ELEM_T &a_data)
{
uint32_t currentMaximumReadIndex;
uint32_t currentReadIndex;
do
{
// m_maximumReadIndex doesn't exist when the queue is set up as
// single-producer. The maximum read index is described by the current
// write index
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_writeIndex;
if (countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex))
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_theQueue[countToIndex(currentReadIndex)];
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if (CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
return true;
}
// it failed retrieving the element off the queue. Someone else must
// have read the element stored at countToIndex(currentReadIndex)
// before we could perform the CAS operation
} while(1); // keep looping to try again!
// Something went wrong. it shouldn't be possible to reach here
assert(0);
// Add this return statement to avoid compiler warnings
return false;
}
如果您计划在只有 1 个生产者和 1 个消费者线程的场景中使用此队列,那么查看 [11] 绝对值得,其中详细解释了设计用于此特定配置的类似循环队列.
4.2 使用智能指针队列
如果队列被实例化为保存智能指针,注意插入队列的智能指针保护的内存不会被完全删除(智能指针的引用计数器等于0),直到元素被存储的索引被一个新的智能指针。这在繁忙的队列中应该不是问题,但是程序员应该考虑到,一旦队列第一次被完全填满,应用程序占用的内存量不会减少,即使队列是空的。
4.3 计算队列大小
原始函数size可能返回虚假值。这是它的代码片段:
template <typename ELEM_T>
inline uint32_t ArrayLockFreeQueue<ELEM_T>::size()
{
uint32_t currentWriteIndex = m_writeIndex;
uint32_t currentReadIndex = m_readIndex;
if (currentWriteIndex >= currentReadIndex)
{
return (currentWriteIndex - currentReadIndex);
}
else
{
return (m_totalSize + currentWriteIndex - currentReadIndex);
}
}
以下场景描述了此函数返回虚假数据的情况:
- 当语句
currentWriteIndex = m_writeIndex运行时,m_writeIndex为 3 和m_readIndex2。实际大小为 1。 - 此后此线程被抢占。当这个线程处于非活动状态时,有 2 个元素被插入并从队列中移除,所以
m_writeIndex是 5m_readIndex4。实际大小仍然是 1。 - 现在当前线程从抢占中返回并读取
m_readIndex.currentReadIndex是 4。 currentReadIndex大于currentWriteIndex,因此m_totalSize + currentWriteIndex - currentReadIndex返回,即,当队列几乎为空时,它返回队列几乎已满。
上传到本文的队列包含了这个问题的解决方案。它包括添加一个新的类成员,该成员包含队列的当前元素数,可以使用AtomicAdd/AtomicSub操作递增/递减。这个解决方案增加了一个重要的开销,因为这些原子操作很昂贵,因为它们不能被编译器轻松优化。
例如,在以 2.13 Ghz(2 个硬件处理器)运行的 core 2 duo E6400 中的测试运行中,需要 2 个线程(1 个生产者 + 1 个消费者)将 10,000k 元素插入初始化为 1k 大小的无锁队列中没有可靠大小变量的插槽大约 2.64 秒,如果该变量由队列维护,则大约 3.42 秒(大约多22%)。在相同环境下使用 2 个消费者和 1 个生产者时,它也需要 22% 的时间:不可靠大小版本的队列需要 3.98 秒,另一个大约需要 5.15 秒。
这就是为什么由开发人员来激活大小变量的开销。它始终取决于队列所用于的应用程序类型来决定该开销是否值得。在array_lock_free_queue.h调用 中有一个编译器预处理器变量ARRAY_LOCK_FREE_Q_KEEP_REAL_SIZE。如果它被定义,则“可靠大小”开销被激活。如果未定义,则开销将被停用并且 size 函数可能最终返回虚假值。
5. 编译代码
文章中包含的无锁队列和Glib阻塞队列都是基于模板的C++类。模板化代码必须位于头文件中,因此在 .cpp 文件中使用它之前不会对其进行编译。我将两个队列都包含在一个 .zip 文件中,该文件包含每个队列的示例文件以显示其使用情况,并测量每个队列完成多线程测试所需的时间。
测试代码是使用 gomp 编写的,gomp 是 OpenMP 应用程序编程接口 (API) 的 GNU 实现,用于在 C/C++ [9] 中进行多平台共享内存并行编程,自 4.2 版起就包含在 GCC 中。OpenMP 是一个简单灵活的接口,用于为不同平台开发并行应用程序,它是编写多线程代码的一种非常简单的方法。
所以,本文所附的代码有3个部分,每个部分都有不同的要求:
1. 基于数组的无锁队列:
- 有两个不同版本的无锁队列。一个用于任何线程配置,另一个用于只有 1 个生产者线程的环境。它们存储在
array_lock_free_queue.h和array_lock_free_queue_single_producer.h - GCC 更新或等于 4.1.0 用于原子操作(
CAS、AtomicAdd和AtomicSub)。如果要使用另一个编译器,则必须在 atomic_ops.h 中定义这些操作(它们可能取决于编译器或您的平台或两者) - 您可能还需要定义
uint32_t此类型是否未包含在stdint.h您的环境的实现中。它包含在 GNU-Linux 中,但不在 Windows 中。在大多数现代环境中,您所要做的就是:C++复制代码typedef unsigned int uint32_t; // int is (normally) 32bit in both 32 and 64bit machines还需要注意的是,此队列尚未在 64 位环境中进行测试。如果 64 位类型变量不支持原子操作,GCC 可能会出现编译时错误,这就是为什么选择 32 位类型变量来实现队列的原因(在 32 位机器中可能没有 64 位原子操作)。如果您的机器支持对 64 位变量的原子操作,我不明白为什么队列在使用 64 位索引时会失败 - 所有线程配置的无锁队列(
CAS每个push操作执行 2 个操作的队列)也使用调用来让处理器:sched_yield(). 根据文档,这个调用是 POSIX [10] 的一部分,所以任何兼容 POSIX 的操作系统应该编译它没有问题。
2. 基于 Glib 的阻塞队列:
- 您将需要在您的系统中使用 glib。这在 GNU-Linux 系统中非常简单,但在其他平台系统下可能会更复杂。整个 GTK+ 库的即用型软件包可安装在 GNU-Linux、Windows 和 OSX 中:http : //www.gtk.org/download.html
- 它还使用互斥体和条件变量的 glib 实现,它们是 gthread 库的一部分,因此,如果您决定包含此队列,则在编译应用程序时还必须链接到它
3.测试应用:
- 满足 Lock-free 和 Glib 阻塞队列的要求
- 用于处理 makefile的GNU make应用程序。您可以将编译时选项传递给编译过程,如
复制代码
make N_PRODUCERS=1 N_CONSUMERS=1 N_ITERATIONS=10000000 QUEUE_SIZE=1000在哪里:- N_PRODUCERS 是生产者线程的数量。
- N_CONSUMERS 是消费者线程的数量。
- N_ITERATIONS 是将从队列中插入和删除的项目总数。
- QUEUE_SIZE 是队列的最大槽数
- GCC,至少4.2版本才能编译Gomp
- 还需要
'OMP_NESTED=TRUE'在运行测试应用程序之前添加到命令行,如`OMP_NESTED=TRUE ./test_lock_free_q`
6. 几个数字
下图显示了在具有不同设置和线程配置的 2 核机器(2 个硬件处理器)中运行本文中包含的测试应用程序的结果。
6.1. 对第二次 CAS 操作性能的影响
当只有一个生产者线程时,队列的一个已知问题是备用的第二个 CAS 操作。下图显示了当只有 1 个 procuder 线程(越低越好)时,在 2 核机器上删除它的影响。它显示同时插入和提取 100 万个元素所需的秒数提高了约 30%。

6.2. 无锁与阻塞队列。线程数
下图显示了根据线程设置(队列大小已设置为 16384)同时推送和弹出 100 万个元素(越低越好)所需的时间量的比较。当只有一个生产者线程时,无锁队列优于标准阻塞算法。当使用多个生产者线程(都同样贪婪地将元素推入队列)时,无锁队列的性能会迅速降低。

6.3. 使用 4 个线程的性能
下图显示了使用不同线程配置推入和弹出 100 万个项目时不同队列的整体性能。
6.3.1 一个生产者线程

6.3.2 两个生产者线程

6.3.3 三个生产者线程

6.3.1 一个消费者线程

6.3.2 两个消费者线程

6.3.3 三个消费者线程

6.4 4核机
当有 4 个物理处理器可用时,最好在 4 核机器上运行相同的测试来研究整体性能。这些测试还可用于查看sched_yield()调用在没有真正需要时对性能的影响。
7. 结论
这种基于数组的无锁队列已被证明可以在其 2 个版本中工作,一个在多个生产者线程配置中是线程安全的,另一个不是(类似于 [11] 但允许多个消费者线程)。这两个队列都可以安全地用作多线程应用程序中的同步机制,因为:
- 由于该
CAS操作是原子操作,因此尝试将元素并行推入或弹出队列的线程不会陷入死锁。 - 多个线程试图同时将元素推入队列,无法写入数组的同一个槽中,从而踩到彼此的数据。
- 多个试图同时从队列中弹出元素的线程不能多次删除同一个项目。
- 一个线程不能推新数据放入队列已满或从弹出数据空一个
- push 和 pop 都不受ABA问题的影响。
然而,重要的是要注意,即使该算法是线程安全的,它在多生产者环境中的性能也优于简单的基于块的队列。因此,仅在以下配置之一下,选择此队列而不是标准的基于块的队列才有意义:
- 目前只有1生产者线程(第2单生产版本速度更快)。
- 有 1 个繁忙的生产者线程,但我们仍然需要队列是线程安全的,因为在某些情况下,不同的线程可以将内容推入队列。
GO 编程模式:错误处理
错误处理一直以一是编程必需要面对的问题,错误处理如果做的好的话,代码的稳定性会很好。不同的语言有不同的出现处理的方式。Go语言也一样,在本篇文章中,我们来讨论一下Go语言的出错出处,尤其是那令人抓狂的 if err != nil 。
在正式讨论Go代码里满屏的 if err != nil 怎么办这个事之前,我想先说一说编程中的错误处理。这样可以让大家在更高的层面理解编程中的错误处理。
C语言的错误检查
首先,我们知道,处理错误最直接的方式是通过错误码,这也是传统的方式,在过程式语言中通常都是用这样的方式处理错误的。比如 C 语言,基本上来说,其通过函数的返回值标识是否有错,然后通过全局的 errno 变量并配合一个 errstr 的数组来告诉你为什么出错。
为什么是这样的设计?道理很简单,除了可以共用一些错误,更重要的是这其实是一种妥协。比如:read(), write(), open() 这些函数的返回值其实是返回有业务逻辑的值。也就是说,这些函数的返回值有两种语义,一种是成功的值,比如 open() 返回的文件句柄指针 FILE* ,或是错误 NULL。这样会导致调用者并不知道是什么原因出错了,需要去检查 errno 来获得出错的原因,从而可以正确地处理错误。
一般而言,这样的错误处理方式在大多数情况下是没什么问题的。但是也有例外的情况,我们来看一下下面这个 C 语言的函数:
这个函数是把一个字符串转成整型。但是问题来了,如果一个要传的字符串是非法的(不是数字的格式),如 “ABC” 或者整型溢出了,那么这个函数应该返回什么呢?出错返回,返回什么数都不合理,因为这会和正常的结果混淆在一起。比如,返回 0,那么会和正常的对 “0” 字符的返回值完全混淆在一起。这样就无法判断出错的情况。你可能会说,是不是要检查一下 errno,按道理说应该是要去检查的,但是,我们在 C99 的规格说明书中可以看到这样的描述——
7.20.1The functions atof, atoi, atol, and atoll need not affect the value of the integer expression errno on an error. If the value of the result cannot be represented, the behavior is undefined.
像atoi(), atof(), atol() 或是 atoll() 这样的函数是不会设置 errno的,而且,还说了,如果结果无法计算的话,行为是undefined。所以,后来,libc 又给出了一个新的函数strtol(),这个函数在出错的时会设置全局变量 errno :
虽然,strtol() 函数解决了 atoi() 函数的问题,但是我们还是能感觉到不是很舒服和自然。
因为,这种用 返回值 + errno 的错误检查方式会有一些问题:
- 程序员一不小心就会忘记返回值的检查,从而造成代码的 Bug;
- 函数接口非常不纯洁,正常值和错误值混淆在一起,导致语义有问题。
所以,后来,有一些类库就开始区分这样的事情。比如,Windows 的系统调用开始使用 HRESULT 的返回来统一错误的返回值,这样可以明确函数调用时的返回值是成功还是错误。但这样一来,函数的 input 和 output 只能通过函数的参数来完成,于是出现了所谓的 入参 和 出参 这样的区别。
然而,这又使得函数接入中参数的语义变得复杂,一些参数是入参,一些参数是出参,函数接口变得复杂了一些。而且,依然没有解决函数的成功或失败可以被人为忽略的问题。
Java的错误处理
Java语言使用 try-catch-finally 通过使用异常的方式来处理错误,其实,这比起C语言的错处理进了一大步,使用抛异常和抓异常的方式可以让我们的代码有这样的一些好处:
- 函数接口在 input(参数)和 output(返回值)以及错误处理的语义是比较清楚的。
- 正常逻辑的代码可以与错误处理和资源清理的代码分开,提高了代码的可读性。
- 异常不能被忽略(如果要忽略也需要 catch 住,这是显式忽略)。
- 在面向对象的语言中(如 Java),异常是个对象,所以,可以实现多态式的 catch。
- 与状态返回码相比,异常捕捉有一个显著的好处是,函数可以嵌套调用,或是链式调用。比如:
int x = add(a, div(b,c));Pizza p = PizzaBuilder().SetSize(sz).SetPrice(p)...;
Go语言的错误处理
Go 语言的函数支持多返回值,所以,可以在返回接口把业务语义(业务返回值)和控制语义(出错返回值)区分开来。Go 语言的很多函数都会返回 result, err 两个值,于是:
- 参数上基本上就是入参,而返回接口把结果和错误分离,这样使得函数的接口语义清晰;
- 而且,Go 语言中的错误参数如果要忽略,需要显式地忽略,用 _ 这样的变量来忽略;
- 另外,因为返回的
error是个接口(其中只有一个方法Error(),返回一个string),所以你可以扩展自定义的错误处理。
另外,如果一个函数返回了多个不同类型的 error,你也可以使用下面这样的方式:
我们可以看到,Go语言的错误处理的的方式,本质上是返回值检查,但是他也兼顾了异常的一些好处 – 对错误的扩展。
资源清理
出错后是需要做资源清理的,不同的编程语言有不同的资源清理的编程模式:
- C语言 – 使用的是
goto fail;的方式到一个集中的地方进行清理(有篇有意思的文章可以看一下《由苹果的低级BUG想到的》) - C++语言- 一般来说使用 RAII模式,通过面向对象的代理模式,把需要清理的资源交给一个代理类,然后在析构函数来解决。
- Java语言 – 可以在finally 语句块里进行清理。
- Go语言 – 使用
defer关键词进行清理。
下面是一个Go语言的资源清理的示例:
Error Check Hell
好了,说到 Go 语言的 if err !=nil 的代码了,这样的代码的确是能让人写到吐。那么有没有什么好的方式呢,有的。我们先看如下的一个令人崩溃的代码。
要解决这个事,我们可以用函数式编程的方式,如下代码示例:
上面的代码我们可以看到,我们通过使用Closure 的方式把相同的代码给抽出来重新定义一个函数,这样大量的 if err!=nil 处理的很干净了。但是会带来一个问题,那就是有一个 err 变量和一个内部的函数,感觉不是很干净。
那么,我们还能不能搞得更干净一点呢,我们从Go 语言的 bufio.Scanner()中似乎可以学习到一些东西:
上面的代码我们可以看到,scanner在操作底层的I/O的时候,那个for-loop中没有任何的 if err !=nil 的情况,退出循环后有一个 scanner.Err() 的检查。看来使用了结构体的方式。模仿它,我们可以把我们的代码重构成下面这样:
首先,定义一个结构体和一个成员函数
然后,我们的代码就可以变成下面这样:
有了上面这个技术,我们的“流式接口 Fluent Interface”,也就很容易处理了。如下所示:
相信你应该看懂这个技巧了,但是,其使用场景也就只能在对于同一个业务对象的不断操作下可以简化错误处理,对于多个业务对象的话,还是得需要各种 if err != nil的方式。
包装错误
最后,多说一句,我们需要包装一下错误,而不是干巴巴地把err给返回到上层,我们需要把一些执行的上下文加入。
通常来说,我们会使用 fmt.Errorf()来完成这个事,比如:
另外,在Go语言的开发者中,更为普遍的做法是将错误包装在另一个错误中,同时保留原始内容:
当然,更好的方式是通过一种标准的访问方法,这样,我们最好使用一个接口,比如 causer接口中实现 Cause() 方法来暴露原始错误,以供进一步检查:
这里有个好消息是,这样的代码不必再写了,有一个第三方的错误库(github.com/pkg/errors),对于这个库,我无论到哪都能看到他的存在,所以,这个基本上来说就是事实上的标准了。代码示例如下:
GO 编程模式:FUNCTIONAL OPTIONS
配置选项问题
在我们编程中,我们会经常性的需要对一个对象(或是业务实体)进行相关的配置。比如下面这个业务实体(注意,这仅只是一个示例):
在这个 Server 对象中,我们可以看到:
- 要有侦听的IP地址
Addr和端口号Port,这两个配置选项是必填的(当然,IP地址和端口号都可以有默认值,当这里我们用于举例认为是没有默认值,而且不能为空,需要必填的)。 - 然后,还有协议
Protocol、Timeout和MaxConns字段,这几个字段是不能为空的,但是有默认值的,比如:协议是tcp, 超时30秒 和 最大链接数1024个。 - 还有一个
TLS这个是安全链接,需要配置相关的证书和私钥。这个是可以为空的。
所以,针对于上述这样的配置,我们需要有多种不同的创建不同配置 Server 的函数签名,如下所示(代码比较宽,需要左右滚动浏览):
因为Go语言不支持重载函数,所以,你得用不同的函数名来应对不同的配置选项。
配置对象方案
要解决这个问题,最常见的方式是使用一个配置对象,如下所示:
我们把那些非必输的选项都移到一个结构体里,于是 Server 对象变成了:
于是,我们只需要一个 NewServer() 的函数了,在使用前需要构造 Config 对象。
这段代码算是不错了,大多数情况下,我们可能就止步于此了。但是,对于有洁癖的有追求的程序员来说,他们能看到其中有一点不好的是,Config 并不是必需的,所以,你需要判断是否是 nil 或是 Empty – Config{}这让我们的代码感觉还是有点不是很干净。
Builder模式
如果你是一个Java程序员,熟悉设计模式的一定会很自然地使用上Builder模式。比如如下的代码:
仿照上面这个模式,我们可以把上面代码改写成如下的代码(注:下面的代码没有考虑出错处理,其中关于出错处理的更多内容,请参看《Go 编程模式:出错处理》):
于是就可以以如下的方式来使用了
上面这样的方式也很清楚,不需要额外的Config类,使用链式的函数调用的方式来构造一个对象,只需要多加一个Builder类,这个Builder类似乎有点多余,我们似乎可以直接在Server 上进行这样的 Builder 构造,的确是这样的。但是在处理错误的时候可能就有点麻烦(需要为Server结构增加一个error 成员,破坏了Server结构体的“纯洁”),不如一个包装类更好一些。
如果我们想省掉这个包装的结构体,那么就轮到我们的Functional Options上场了,函数式编程。
Functional Options
首先,我们先定义一个函数类型:
然后,我们可以使用函数式的方式定义一组如下的函数:
上面这组代码传入一个参数,然后返回一个函数,返回的这个函数会设置自己的 Server 参数。例如:
- 当我们调用其中的一个函数用
MaxConns(30)时 - 其返回值是一个
func(s* Server) { s.MaxConns = 30 }的函数。
这个叫高阶函数。在数学上,就好像这样的数学定义,计算长方形面积的公式为: rect(width, height) = width * height; 这个函数需要两个参数,我们包装一下,就可以变成计算正方形面积的公式:square(width) = rect(width, width) 也就是说,squre(width)返回了另外一个函数,这个函数就是rect(w,h) 只不过他的两个参数是一样的。即:f(x) = g(x, x)
好了,现在我们再定一个 NewServer()的函数,其中,有一个可变参数 options 其可以传出多个上面上的函数,然后使用一个for-loop来设置我们的 Server 对象。
于是,我们在创建 Server 对象的时候,我们就可以这样来了。
怎么样,是不是高度的整洁和优雅?不但解决了使用 Config 对象方式 的需要有一个config参数,但在不需要的时候,是放 nil 还是放 Config{}的选择困难,也不需要引用一个Builder的控制对象,直接使用函数式编程的试,在代码阅读上也很优雅。
所以,以后,大家在要玩类似的代码时,强烈推荐使用Functional Options这种方式,这种方式至少带来了如下的好处:
- 直觉式的编程
- 高度的可配置化
- 很容易维护和扩展
- 自文档
- 对于新来的人很容易上手
- 没有什么令人困惑的事(是nil 还是空)
GO编程模式:委托和反转控制
反转控制IoC – Inversion of Control 是一种软件设计的方法,其主要的思想是把控制逻辑与业务逻辑分享,不要在业务逻辑里写控制逻辑,这样会让控制逻辑依赖于业务逻辑,而是反过来,让业务逻辑依赖控制逻辑。在《IoC/DIP其实是一种管理思想》中的那个开关和电灯的示例一样,开关是控制逻辑,电器是业务逻辑,不要在电器中实现开关,而是把开关抽象成一种协议,让电器都依赖之。这样的编程方式可以有效的降低程序复杂度,并提升代码重用。
嵌入和委托
结构体嵌入
在Go语言中,我们可以很方便的把一个结构体给嵌到另一个结构体中。如下所示:
上面的示例中,我们把 Widget嵌入到了 Label 中,于是,我们可以这样使用:
如果在 Label 结构体里出现了重名,就需要解决重名,例如,如果 成员 X 重名,用 label.X表明 是自己的X ,用 label.Wedget.X 表示嵌入过来的。
有了这样的嵌入,就可以像UI组件一样的在结构构的设计上进行层层分解。比如,我可以新出来两个结构体 Button 和 ListBox:
方法重写
然后,我们需要两个接口 Painter 用于把组件画出来,Clicker 用于表明点击事件:
当然,
- 对于
Lable来说,只有Painter,没有Clicker - 对于
Button和ListBox来说,Painter和Clicker都有。
下面是一些实现:
这里,需要重点提示一下,Button.Paint() 接口可以通过 Label 的嵌入带到新的结构体,如果 Button.Paint() 不实现的话,会调用 Label.Paint() ,所以,在 Button 中声明 Paint() 方法,相当于Override。
嵌入结构多态
通过下面的程序可以看到,整个多态是怎么执行的。
我们可以看到,我们可以使用接口来多态,也可以使用 泛型的 interface{} 来多态,但是需要有一个类型转换。
反转控制
我们再来看一个示例,我们有一个存放整数的数据结构,如下所示:
其中实现了 Add() 、Delete() 和 Contains() 三个操作,前两个是写操作,后一个是读操作。
实现Undo功能
现在我们想实现一个 Undo 的功能。我们可以把把 IntSet 再包装一下变成 UndoableIntSet 代码如下所示:
在上面的代码中,我们可以看到
- 我们在
UndoableIntSet中嵌入了IntSet,然后Override了 它的Add()和Delete()方法。 Contains()方法没有Override,所以,会被带到UndoableInSet中来了。- 在Override的
Add()中,记录Delete操作 - 在Override的
Delete()中,记录Add操作 - 在新加入
Undo()中进行Undo操作。
通过这样的方式来为已有的代码扩展新的功能是一个很好的选择,这样,可以在重用原有代码功能和重新新的功能中达到一个平衡。但是,这种方式最大的问题是,Undo操作其实是一种控制逻辑,并不是业务逻辑,所以,在复用 Undo这个功能上是有问题。因为其中加入了大量跟 IntSet 相关的业务逻辑。
反转依赖
现在我们来看另一种方法:
我们先声明一种函数接口,表现我们的Undo控制可以接受的函数签名是什么样的:
有了上面这个协议后,我们的Undo控制逻辑就可以写成如下:
这里你不必觉得奇怪, Undo 本来就是一个类型,不必是一个结构体,是一个函数数组也没什么问题。
然后,我们在我们的IntSet里嵌入 Undo,然后,再在 Add() 和 Delete() 里使用上面的方法,就可以完成功能。
这个就是控制反转,不再由 控制逻辑 Undo 来依赖业务逻辑 IntSet,而是由业务逻辑 IntSet 来依赖 Undo 。其依赖的是其实是一个协议,这个协议是一个没有参数的函数数组。我们也可以看到,我们 Undo 的代码就可以复用了。
GO编程模式:MAP-REDUCE
在本篇文章中,我们学习一下函数式编程的中非常重要的Map、Reduce、Filter的三种操作,这三种操作可以让我们非常方便灵活地进行一些数据处理——我们的程序中大多数情况下都是在到倒腾数据,尤其对于一些需要统计的业务场景,Map/Reduce/Filter是非常通用的玩法。下面先来看几个例子:
基本示例
Map示例
下面的程序代码中,我们写了两个Map函数,这两个函数需要两个参数,
- 一个是字符串数组
[]string,说明需要处理的数据一个字符串 - 另一个是一个函数
func(s string) string或func(s string) int
整个Map函数运行逻辑都很相似,函数体都是在遍历第一个参数的数组,然后,调用第二个参数的函数,然后把其值组合成另一个数组返回。
于是我们就可以这样使用这两个函数:
我们可以看到,我们给第一个 MapStrToStr() 传了函数做的是 转大写,于是出来的数组就成了全大写的,给MapStrToInt() 传的是算其长度,所以出来的数组是每个字符串的长度。
我们再来看一下Reduce和Filter的函数是什么样的。
Reduce 示例
Filter示例
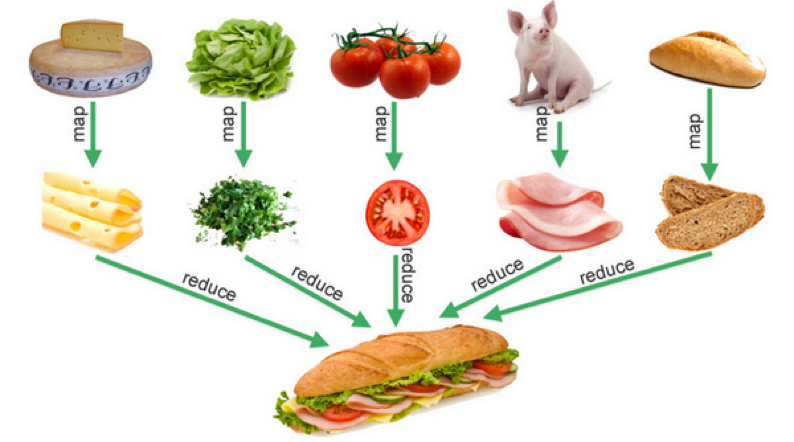
下图是一个比喻,其非常形象地说明了Map-Reduce是的业务语义,其在数据处理中非常有用。
业务示例
通过上面的一些示例,你可能有一些明白,Map/Reduce/Filter只是一种控制逻辑,真正的业务逻辑是在传给他们的数据和那个函数来定义的。是的,这是一个很经典的“业务逻辑”和“控制逻辑”分离解耦的编程模式。下面我们来看一个有业务意义的代码,来让大家强化理解一下什么叫“控制逻辑”与业务逻辑分离。
员工信息
首先,我们一个员工对象,以及一些数据
相关的Reduce/Fitler函数
然后,我们有如下的几个函数:
简单说明一下:
EmployeeConutIf和EmployeeSumIf分别用于统满足某个条件的个数或总数。它们都是Filter + Reduce的语义。EmployeeFilterIn就是按某种条件过虑。就是Fitler的语义。
各种自定义的统计示例
于是我们就可以有如下的代码。
1)统计有多少员工大于40岁
2)统计有多少员工薪水大于6000
3)列出有没有休假的员工
4)统计所有员工的薪资总和
5)统计30岁以下员工的薪资总和
泛型Map-Reduce
我们可以看到,上面的Map-Reduce都因为要处理数据的类型不同而需要写出不同版本的Map-Reduce,虽然他们的代码看上去是很类似的。所以,这里就要带出来泛型编程了,Go语言在本文写作的时候还不支持泛型(注:Go开发团队技术负责人Russ Cox在2012年11月21golang-dev上的mail确认了Go泛型(type parameter)将在Go 1.18版本落地,即2022.2月份)。
简单版 Generic Map
所以,目前的Go语言的泛型只能用 interface{} + reflect来完成,interface{} 可以理解为C中的 void*,Java中的 Object ,reflect是Go的反射机制包,用于在运行时检查类型。
下面我们来看一下一个非常简单不作任何类型检查的泛型的Map函数怎么写。
上面的代码中,
- 通过
reflect.ValueOf()来获得interface{}的值,其中一个是数据vdata,另一个是函数vfn, - 然后通过
vfn.Call()方法来调用函数,通过[]refelct.Value{vdata.Index(i)}来获得数据。
Go语言中的反射的语法还是有点令人费解的,但是简单看一下手册还是能够读懂的。我这篇文章不讲反射,所以相关的基础知识还请大家自行Google相关的教程。
于是,我们就可以有下面的代码——不同类型的数据可以使用相同逻辑的Map()代码。
但是因为反射是运行时的事,所以,如果类型什么出问题的话,就会有运行时的错误。比如:
上面的代码可以很轻松的编译通过,但是在运行时就出问题了,还是panic错误……
健壮版的Generic Map
所以,如果要写一个健壮的程序,对于这种用interface{} 的“过度泛型”,就需要我们自己来做类型检查。下面是一个有类型检查的Map代码:
上面的代码一下子就复杂起来了,可见,复杂的代码都是在处理异常的地方。我不打算Walk through 所有的代码,别看代码多,但是还是可以读懂的,下面列几个代码中的要点:
- 代码中没有使用Map函数,因为和数据结构和关键有含义冲突的问题,所以使用
Transform,这个来源于 C++ STL库中的命名。 - 有两个版本的函数,一个是返回一个全新的数组 –
Transform(),一个是“就地完成” –TransformInPlace() - 在主函数中,用
Kind()方法检查了数据类型是不是 Slice,函数类型是不是Func - 检查函数的参数和返回类型是通过
verifyFuncSignature()来完成的,其中:NumIn()– 用来检查函数的“入参”-
NumOut()用来检查函数的“返回值”
- 如果需要新生成一个Slice,会使用
reflect.MakeSlice()来完成。
好了,有了上面的这段代码,我们的代码就很可以很开心的使用了:
可以用于字符串数组
可以用于整形数组
可以用于结构体
健壮版的 Generic Reduce
同样,泛型版的 Reduce 代码如下:
健壮版的 Generic Filter
同样,泛型版的 Filter 代码如下(同样分是否“就地计算”的两个版本):
后记
还有几个未尽事宜:
1)使用反射来做这些东西,会有一个问题,那就是代码的性能会很差。所以,上面的代码不能用于你需要高性能的地方。怎么解决这个问题,我们会在本系列文章的下一篇文章中讨论。
2)上面的代码大量的参考了 Rob Pike的版本,他的代码在 https://github.com/robpike/filter
3)其实,在全世界范围内,有大量的程序员都在问Go语言官方什么时候在标准库中支持 Map/Reduce,Rob Pike说,这种东西难写吗?还要我们官方来帮你们写么?这种代码我多少年前就写过了,但是,我从来一次都没有用过,我还是喜欢用“For循环”,我觉得你最好也跟我一起用 “For循环”。
我个人觉得,Map/Reduce在数据处理的时候还是很有用的,Rob Pike可能平时也不怎么写“业务逻辑”的代码,所以,对他来说可能也不太了解业务的变化有多么的频繁……
当然,好还是不好,由你来判断,但多学一些编程模式是对自己的帮助也是很有帮助的。
GO 编程模式:GO GENERATION
在本篇文章中,我们将要学习一下Go语言的代码生成的玩法。Go语言代码生成主要还是用来解决编程泛型的问题,泛型编程主要解决的问题是因为静态类型语言有类型,所以,相关的算法或是对数据处理的程序会因为类型不同而需要复制一份,这样导致数据类型和算法功能耦合的问题。泛型编程可以解决这样的问题,就是说,在写代码的时候,不用关心处理数据的类型,只需要关心相当处理逻辑。泛型编程是静态语言中非常非常重要的特征,如果没有泛型,我们很难做到多态,也很难完成抽象,会导致我们的代码冗余量很大。
现实中的类比
举个现实当中的例子,用螺丝刀来做具比方,螺丝刀本来就是一个拧螺丝的动作,但是因为螺丝的类型太多,有平口的,有十字口的,有六角的……螺丝还有大小尺寸,导致我们的螺丝刀为了要适配各种千奇百怪的螺丝类型(样式和尺寸),导致要做出各种各样的螺丝刀。
 |
 |
而真正的抽象是螺丝刀不应该关心螺丝的类型,只要关注好自己的功能是否完备,并让自己可以适配于不同类型的螺丝,如下所示,这就是所谓的泛型编程要解决的实际问题。
 |
Go语方的类型检查
因为Go语言目前并不支持真正的泛型,所以,只能用 interface{} 这样的类似于 void* 这种过度泛型来玩这就导致了我们在实际过程中就需要进行类型检查。Go语言的类型检查有两种技术,一种是 Type Assert,一种是Reflection。
Type Assert
这种技术,一般是对某个变量进行 .(type)的转型操作,其会返回两个值, variable, error,第一个返回值是被转换好的类型,第二个是如果不能转换类型,则会报错。
比如下面的示例,我们有一个通用类型的容器,可以进行 Put(val)和 Get(),注意,其使用了 interface{}作泛型
在使用中,我们可以这样使用
但是,在把数据取出来时,因为类型是 interface{} ,所以,你还要做一个转型,如果转型成功能才能进行后续操作(因为 interface{}太泛了,泛到什么类型都可以放)下在是一个Type Assert的示例:
Reflection
对于反射,我们需要把上面的代码修改如下:
上面的代码并不难读,这是完全使用 reflection的玩法,其中
- 在
NewContainer()会根据参数的类型初始化一个Slice - 在
Put()时候,会检查val是否和Slice的类型一致。 - 在
Get()时,我们需要用一个入参的方式,因为我们没有办法返回reflect.Value或是interface{},不然还要做Type Assert - 但是有类型检查,所以,必然会有检查不对的道理 ,因此,需要返回
error
于是在使用上面这段代码的时候,会是下面这个样子:
我们可以看到,Type Assert是不用了,但是用反射写出来的代码还是有点复杂的。那么有没有什么好的方法?
它山之石
对于泛型编程最牛的语言 C++ 来说,这类的问题都是使用 Template来解决的。
|
//用<class T>来描述泛型
template <class T>
T GetMax (T a, T b) {
T result;
result = (a>b)? a : b;
return (result);
}
|
int i=5, j=6, k;
//生成int类型的函数
k=GetMax<int>(i,j);
long l=10, m=5, n;
//生成long类型的函数
n=GetMax<long>(l,m);
|
C++的编译器会在编译时分析代码,根据不同的变量类型来自动化的生成相关类型的函数或类。C++叫模板的具体化。
这个技术是编译时的问题,所以,不需要我们在运行时进行任何的运行的类型识别,我们的程序也会变得比较的干净。
那么,我们是否可以在Go中使用C++的这种技术呢?答案是肯定的,只是Go的编译器不帮你干,你需要自己动手。
Go Generator
要玩 Go的代码生成,你需要三件事:
- 一个函数模板,其中设置好相应的占位符。
- 一个脚本,用于按规则来替换文本并生成新的代码。
- 一行注释代码。
函数模板
我们把我们之前的示例改成模板。取名为 container.tmp.go 放在 ./template/下
我们可以看到函数模板中我们有如下的占位符:
PACKAGE_NAME– 包名GENERIC_NAME– 名字GENERIC_TYPE– 实际的类型
其它的代码都是一样的。
函数生成脚本
然后,我们有一个叫gen.sh的生成脚本,如下所示:
其需要4个参数:
- 模板源文件
- 包名
- 实际需要具体化的类型
- 用于构造目标文件名的后缀
然后其会用 sed 命令去替换我们的上面的函数模板,并生成到目标文件中。(关于sed命令请参看本站的《sed 简明教程》)
生成代码
接下来,我们只需要在代码中打一个特殊的注释:
其中,
- 第一个注释是生成包名为
gen类型为uint32目标文件名以container为后缀 - 第二个注释是生成包名为
gen类型为string目标文件名以container为后缀
然后,在工程目录中直接执行 go generate 命令,就会生成如下两份代码,
一份文件名为uint32_container.go
另一份的文件名为 string_container.go
这两份代码可以让我们的代码完全编译通过,所付出的代价就是需要多执行一步 go generate 命令。
新版Filter
现在我们再回头看看我们之前《Go编程模式:Map-Reduce》中的那些个用反射整出来的例子,有了这样的技术,我就不必在代码里用那些晦涩难懂的反射来做运行时的类型检查了。我们可以写下很干净的代码,让编译器在编译时检查类型对不对。下面是一个Fitler的模板文件 filter.tmp.go:
于是我们可在需要使用这个的地方,加上相关的 go generate 的注释
第三方工具
我们并不需要自己手写 gen.sh 这样的工具类,已经有很多第三方的已经写好的可以使用。下面是一个列表:
- Genny – https://github.com/cheekybits/genny
- Generic – https://github.com/taylorchu/generic
- GenGen – https://github.com/joeshaw/gengen
- Gen – https://github.com/clipperhouse/gen
Python修饰器的函数式编程 | 酷 壳 - CoolShell
GO编程模式:PIPELINE
HTTP 处理
这种Pipeline的模式,我们在《Go编程模式:修饰器》中有过一个示例,我们在这里再重温一下。在那篇文章中,我们有一堆如 WithServerHead() 、WithBasicAuth() 、WithDebugLog()这样的小功能代码,在我们需要实现某个HTTP API 的时候,我们就可以很容易的组织起来。
原来的代码是下面这个样子:
通过一个代理函数:
我们就可以移除不断的嵌套像下面这样使用了:
Channel 管理
当然,如果你要写出一个泛型的pipeline框架并不容易,而使用Go Generation,但是,我们别忘了Go语言最具特色的 Go Routine 和 Channel 这两个神器完全也可以被我们用来构造这种编程。
Rob Pike在 Go Concurrency Patterns: Pipelines and cancellation 这篇blog中介绍了如下的一种编程模式。
Channel转发函数
首先,我们需一个 echo()函数,其会把一个整型数组放到一个Channel中,并返回这个Channel
然后,我们依照这个模式,我们可以写下这个函数。
平方函数
过滤奇数函数
求和函数
然后,我们的用户端的代码如下所示:(注:你可能会觉得,sum(),odd() 和 sq()太过于相似。你其实可以通过我们之前的Map/Reduce编程模式或是Go Generation的方式来合并一下)
上面的代码类似于我们执行了Unix/Linux命令: echo $nums | sq | sum
同样,如果你不想有那么多的函数嵌套,你可以使用一个代理函数来完成。
然后,就可以这样做了:
Fan in/Out
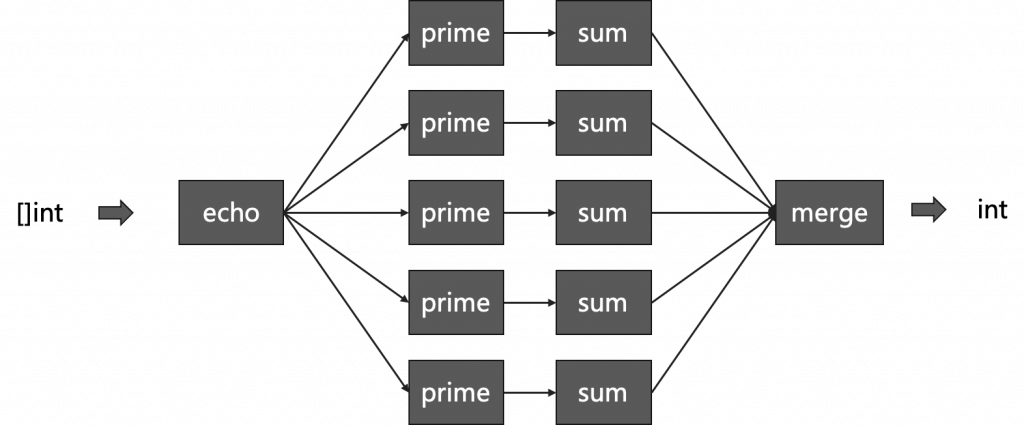
动用Go语言的 Go Routine和 Channel还有一个好处,就是可以写出1对多,或多对1的pipeline,也就是Fan In/ Fan Out。下面,我们来看一个Fan in的示例:
我们想通过并发的方式来对一个很长的数组中的质数进行求和运算,我们想先把数组分段求和,然后再把其集中起来。
下面是我们的主函数:
再看我们的 prime() 函数的实现 :
我们可以看到,
- 我们先制造了从1到10000的一个数组,
- 然后,把这堆数组全部
echo到一个channel里 –in - 此时,生成 5 个 Channel,然后都调用
sum(prime(in)),于是每个Sum的Go Routine都会开始计算和 - 最后再把所有的结果再求和拼起来,得到最终的结果。
其中的merge代码如下:
用图片表示一下,整个程序的结构如下所示:
GO 编程模式:K8S VISITOR 模式
一个简单示例
我们还是先来看一个简单设计模式的Visitor的示例。
- 我们的代码中有一个
Visitor的函数定义,还有一个Shape接口,其需要使用Visitor函数做为参数。 - 我们的实例的对象
Circle和Rectangle实现了Shape的接口的accept()方法,这个方法就是等外面给我传递一个Visitor。
然后,我们实现两个Visitor,一个是用来做JSON序列化的,另一个是用来做XML序列化的
下面是我们的使用Visitor这个模式的代码
其实,这段代码的目的就是想解耦 数据结构和 算法,使用 Strategy 模式也是可以完成的,而且会比较干净。但是在有些情况下,多个Visitor是来访问一个数据结构的不同部分,这种情况下,数据结构有点像一个数据库,而各个Visitor会成为一个个小应用。 kubectl就是这种情况。
k8s相关背景
接下来,我们再来了解一下相关的知识背景:
- 对于Kubernetes,其抽象了很多种的Resource,比如:Pod, ReplicaSet, ConfigMap, Volumes, Namespace, Roles …. 种类非常繁多,这些东西构成为了Kubernetes的数据模型(点击 Kubernetes Resources 地图 查看其有多复杂)
kubectl是Kubernetes中的一个客户端命令,操作人员用这个命令来操作Kubernetes。kubectl会联系到 Kubernetes 的API Server,API Server会联系每个节点上的kubelet,从而达到控制每个结点。kubectl主要的工作是处理用户提交的东西(包括,命令行参数,yaml文件等),然后其会把用户提交的这些东西组织成一个数据结构体,然后把其发送给 API Server。- 相关的源代码在
src/k8s.io/cli-runtime/pkg/resource/visitor.go中(源码链接)
kubectl 的代码比较复杂,不过,其本原理简单来说,它从命令行和yaml文件中获取信息,通过Builder模式并把其转成一系列的资源,最后用 Visitor 模式模式来迭代处理这些Reources。
下面我们来看看 kubectl 的实现,为了简化,我用一个小的示例来表明 ,而不是直接分析复杂的源码。
kubectl的实现方法
Visitor模式定义
首先,kubectl 主要是用来处理 Info结构体,下面是相关的定义:
我们可以看到,
- 有一个
VisitorFunc的函数类型的定义 - 一个
Visitor的接口,其中需要Visit(VisitorFunc) error的方法(这就像是我们上面那个例子的Shape) - 最后,为
Info实现Visitor接口中的Visit()方法,实现就是直接调用传进来的方法(与前面的例子相仿)
我们再来定义几种不同类型的 Visitor。
Name Visitor
这个Visitor 主要是用来访问 Info 结构中的 Name 和 NameSpace 成员
我们可以看到,上面的代码:
- 声明了一个
NameVisitor的结构体,这个结构体里有一个Visitor接口成员,这里意味着多态。 - 在实现
Visit()方法时,其调用了自己结构体内的那个Visitor的Visitor()方法,这其实是一种修饰器的模式,用另一个Visitor修饰了自己(关于修饰器模式,参看《Go编程模式:修饰器》)
Other Visitor
这个Visitor主要用来访问 Info 结构中的 OtherThings 成员
实现逻辑同上,我就不再重新讲了
Log Visitor
使用方代码
现在我们看看如果使用上面的代码:
上面的代码,我们可以看到
- Visitor们一层套一层
- 我用
loadFile假装从文件中读如数据 - 最后一条
v.Visit(loadfile)我们上面的代码就全部开始激活工作了。
上面的代码输出如下的信息,你可以看到代码的执行顺序是怎么执行起来了
我们可以看到,上面的代码有以下几种功效:
- 解耦了数据和程序。
- 使用了修饰器模式
- 还做出来pipeline的模式
所以,其实,我们是可以把上面的代码重构一下的。
Visitor修饰器
下面,我们用修饰器模式来重构一下上面的代码。
上面的代码并不复杂,
- 用一个
DecoratedVisitor的结构来存放所有的VistorFunc函数 NewDecoratedVisitor可以把所有的VisitorFunc转给它,构造DecoratedVisitor对象。DecoratedVisitor实现了Visit()方法,里面就是来做一个for-loop,顺着调用所有的VisitorFunc
于是,我们的代码就可以这样运作了:
是不是比之前的那个简单?注意,这个DecoratedVisitor 同样可以成为一个Visitor来使用。
好,上面的这些代码全部存在于 kubectl 的代码中,你看懂了这里面的代码逻辑,相信你也能够看懂 kubectl 的代码了。
TDD并不是看上去的那么美 | 酷 壳 - CoolShell
Bob大叔和Jim Coplien对TDD的论战 | 酷 壳 - CoolShell
Go语言、Docker 和新技术 | 酷 壳 - CoolShell
GO语言、DOCKER 和新技术
上个月,作为 Go 语言的三位创始人之一,Unix 老牌黑客罗勃·派克(Rob Pike)在新文章“Go: Ten years and climbing”中,回顾了一下 Go 语言的发展过程。其中提到,Go 语言这十年的迅猛发展大到连他们自己都没有想到,并且还成为了云计算领域中新一代的开发语言。还提到了,中国程序员对 Go 语言的热爱完全超出了他们的想象,甚至他们都不敢相信是真的。
这让我想起,我在 2015 年 5 月份拜访 Docker 公司在湾区的总部时,Docker 负责人也和我表达了相似的感叹:他们完全没有想到居然中国有那么多人喜欢 Docker,而且还有这么多人在为 Docker 做贡献,这让他们感到非常意外。此外,还跟我说,中国是除了美国本土之外的另一个如此喜欢 Docker 技术的国家,在其它国家都没有看到。
的确如他们所说,Go 语言和 Docker 这两种技术已经成为新一代的云计算技术,而且可以看到其发展态势非常迅猛。而中国也成为了像美国一样在强力推动这两种技术的国家。这的确是一件让人感到非常高兴的事,因为中国在跟随时代潮流这件事上已经做得非常不错了。
然而,从 2014-2015 年我在阿里推动 Docker 和 Go 语言的痛苦和失败过程中,以及这许多年来,有很多很多人问我是否要学 Go 语言,是否要学 Docker,Go 和 Docker 是否能用在生产线上,这些问题看来,对于 Go 语言和 Docker 这两种技术,在国内的技术圈中有相当大的一部分人和群体还在执观望或是不信任的态度。
所以,我想写这篇文章,从两个方面来论述一下我的观点和看法。
- 一个方面,为什么 Go 语言和 Docker 会是新一代的云计算技术。
- 另一个方面,作为技术人员,我们如何识别什么样的新技术会是未来的趋势。
这两个问题是相辅相成的,所以我会把这两个问题揉在一起谈。
虽然 Go 语言是在 2009 年底开源的,但我是从 2012 年才开始接触和学习 Go 语言的。我只花了一个周末两天的时间就学完了,而且在这两天,我还很快地写出了一个能工作很好的网页爬虫程序,以及一个简单的高并发文件处理服务,用于提取前面抓取的网页的关键内容。这两个程序都很简单,总共才写了不到 500 行代码。
我当时对 Go 语言有几点体会。
第一,语言简单,上手快。Go 语言的语法特性简直是太简单了,简单到你几乎玩不出什么花招,直来直去的,学习曲线很低,上手非常快。
第二,并行和异步编程几乎无痛点。Go 语言的 Goroutine 和 Channel 这两个神器简直就是并发和异步编程的巨大福音。像 C、C++、Java、Python 和 JavaScript 这些语言的并发和异步方式太控制就比较复杂了,而且容易出错,而 Go 解决这个问题非常地优雅和流畅。这对于编程多年受尽并发和异步折磨的我来说,完全就是让我眼前一亮的感觉。
(图片来自 Medium:Why should you learn Go?)
第三,Go 语言的 lib 库麻雀虽小五脏俱全。Go 语言的 lib 库中基本上有绝大多数常用的库,虽然有些库还不是很好,但我觉得不是问题,因为我相信在未来的发展中会把这些问题解决掉。
第四,C 语言的理念和 Python 的姿态。C 语言的理念是信任程序员,保持语言的小巧,不屏蔽底层且底层友好,关注语言的执行效率和性能。而 Python 的姿态是用尽量少的代码完成尽量多的事。于是我能够感觉到,Go 语言想要把 C 和 Python 统一起来,这是多棒的一件事啊。
(图片来自 Medium:Why should you learn Go?)
所以,即便 Go 语言存在诸多的问题,比如垃圾回收、异常处理、泛型编程等,但相较于上面这几个优势,我认为这些问题都是些小问题。于是就毫不犹豫地入坑了。
当然,一个技术能不能发展起来,关键还要看三点。
- 有没有一个比较好的社区。像 C、C++、Java、Python 和 JavaScript 的生态圈都是非常丰富和火爆的。尤其是有很多商业机构参与的社区那就更为人气爆棚了,比如 Linux 的社区。
- 有没有一个工业化的标准。像 C、C++、Java 都是有标准化组织的。尤其是 Java,其在架构上还搞出了像 J2EE 这样的企业级标准。
- 有没有一个或多个杀手级应用。C、C++ 和 Java 的杀手级应用不用多说了,就算是对于 PHP 这样还不能算是一个好的编程语言来说,因为是 Linux 时代的第一个杀手级解决方案 LAMP 中的关键技术,所以,也发展起来了。
上述的这三点是非常关键的,新的技术只需要占到其中一到两点就已经很不错了,何况有的技术,比如 Java,是三点全占到了,所以,Java 的发展是如此好。当然,除了上面这三点重要的,还有一些其它的影响因素,比如:
- 学习曲线是否低,上手是否快。这点非常重要,C++ 在这点上越做越不好了。
- 有没有一个不错的提高开发效率的开发框架。如:Java 的 Spring 框架,C++ 的 STL 等。
- 是否有一个或多个巨型的技术公司作为后盾。如:Java 和 Linux 后面的 IBM、Sun……
- 有没有解决软件开发中的痛点。如:Java 解决了 C 和 C++ 的内存管理问题。
用这些标尺来量一下 Go 语言,我们可以清楚地看到:
- Go 语言容易上手;
- Go 语言解决了并发编程和写底层应用开发效率的痛点;
- Go 语言有 Google 这个世界一流的技术公司在后面;
- Go 语言的杀手级应用是 Docker,而 Docker 的生态圈在这几年完全爆棚了。
所以,Go 语言的未来是不可限量的。当然,我个人觉得,Go 可能会吞食很多 C、C++、Java 的项目。不过,Go 语言所吞食主要的项目应该是中间层的项目,既不是非常底层也不会是业务层。
也就是说,Go 语言不会吞食底层到 C 和 C++ 那个级别的,也不会吞食到高层如 Java 业务层的项目。Go 语言能吞食的一定是 PaaS 上的项目,比如一些消息缓存中间件、服务发现、服务代理、控制系统、Agent、日志收集等等,没有复杂的业务场景,也到不了特别底层(如操作系统)的中间平台层的软件项目或工具。而 C 和 C++ 会被打到更底层,Java 会被打到更上层的业务层。这是我的一个判断。
好了,我们再用上面的标尺来量一下 Go 语言的杀手级应用 Docker,你会发现基本是一样的。
- Docker 上手很容易。
- Docker 解决了运维中的环境问题以及服务调度的痛点。
- Docker 的生态圈中有大公司在后面助力。比如 Google。
- Docker 产出了工业界标准 OCI。
- Docker 的社区和生态圈已经出现像 Java 和 Linux 那样的态势。
- ……
所以,早在 3、4 年前我就觉得 Docker 一定会是未来的技术。虽然当时的坑儿还很多,但是,相对于这些大的因素来说,那些小坑儿都不是问题。只是需要一些时间,这些小坑儿在未来 5-10 年就可以完全被填平了。
同样,我们可以看到 Kubernetes 作为服务和容器调度的关键技术一定会是最后的赢家。这点我在去年初就能够很明显地感觉到了。
关于 Docker 我还想多说几句,这是云计算中 PaaS 的关键技术,虽然,这世上在出现 Docker 之前,几乎所有的要玩公有 PaaS 的公司和产品都玩不起来,比如:Google 的 GAE,国内的各种 XAE,如淘宝的 TAE,新浪的 SAE 等。但我还是想说,PaaS 是一个被世界或是被产业界严重低估的平台。
PaaS 层是承上启下的关键技术,任何一个不重视 PaaS 的公司,其技术架构都不可能让这家公司成长为一个大型的公司。因为 PaaS 层的技术主要能解决下面这些问题。
- 软件生产线的问题。持续集成和持续发布,以及 DevOps 中的技术必需通过 PaaS。
- 分布式服务化的问题。分布式服务化的服务高可用、服务编排、服务调度、服务发现、服务路由,以及分布式服务化的支撑技术完全是 PaaS 的菜。
- 提高服务的可用性 SLA。提高服务可用性 SLA 所需要的分布式、高可用的技术架构和运维工具,也是 PaaS 层提供的。
- 软件能力的复用。软件工程中的核心就是软件能力的复用,这一点也完美地体现在 PaaS 平台的技术上。
老实说,这些问题的关键程度已经到了能判断一家依托技术的公司的研发能力是否靠谱的程度。没有这些技术,依托技术拓展业务的公司几乎没有可能发展得规模很大。
在后面,我会在“极客时间”我的付费专栏里另外写几篇文章详细地讲一下分布式服务化和 PaaS 平台的重要程度。
最后,我还要说一下,为什么要早一点地进入这些新技术,而不是等待这些技术成熟了后再进入。原因有这么几个。
技术的发展过程非常重要。我进入 Go 和 Docker 的技术不能算早,但也不算晚,从 2012 年学习 Go,到 2013 年学习 Docker 到今天,我清楚地看到了这两种技术的生态圈发展过程。让我收获最大的并不是这些技术本身,而是一个技术的变迁和行业的发展。
从中,我看到了非常具体的各种思潮和思路,这些东西比起 Go 和 Docker 来说更有价值。因为,这不但让我重新思考我已掌握的技术以及如何更好地解决已有的问题,而且还让我看到了未来。我不但有了技术优势,而且这些知识还让我的技术生涯多了很多的可能性。
这些关键新技术,可以让你拿到技术的先机。这些对一个需要技术领导力的个人或公司来说都是非常重要的。
一个公司或是个人能够占有技术先机,就会比其它公司或个人有更大的影响力。一旦未来行业需求引爆,那么这个公司或是个人的影响力就会形成一个比较大的护城河,并可以快速地产生经济利益。
近期,在与中国移动、中国电信以及一些股份制银行进行交流的过程中,我已看到通讯行业、金融行业对于 PaaS 平台的理解已经超过了互联网公司,而我近 3 年来在这些技术上的研究让我也从中受益非浅。
所以,Go 语和 Docker 作为 PaaS 平台的关键技术前途是无限的,我很庆幸赶上了这个浪潮,也很庆幸在 3 年前我就看到了这个趋势,现在我也在用这些技术开发相关的技术产品,助力于为高速成长的公司提供这些关键技术。
今天早上看到一篇文章《百度不要用户》这篇文章里的大意是:百度错过了移动互联网,等反应过来的时候,在2013年猛收购了一些公司来追赶对手或是时代,但都不成功,然后又开始后过来走到技术,大力发展AI,可惜,AI又是一个不是很成熟的事,需要没有上限的投入,而且在短期内看不到盈利的事,然而整个KPI又设计在了盈利上,最后导致内部内耗严重,人才和管理层流失,最终离用户越来越远。
文章中有一个段落的标题是【做决策的是技术】,其中有话是这样的——
在“重技术、轻运营”的百度,产品的主导权和优先权在技术手里,产品和运营的立项话语权相对轻很多。如果是在 PC 时代,这无可厚非,但在移动互联网时代,这就有很大的问题。
这就是中国这个社会的价值观了,整个社会价值观从本质上来说是不待见技术的——平时都说技术不重要,但是当有问题出现的的时候,他们都会把问题都推到技术上。
虽然我同意这篇文章中大多数观点,但是我对“做决策的是技术造成了问题”有很大的不同意,并不是我是技术人员,我只会站在我的角度上思考问题,而且,这个结论就是错的。
要证明这个事,我们就需要找一个反例,这个反例就是Google。其实,文章中所有的因为移动互联网出现而对传统互联网造成挑战的问题,Google其实都遇到了,然而,Google却走了一条完全与百度不一样的路。
当时,Facebook如日中天的时候,Google也有很多人才流失到了Facebook,而Google的所有产品线都受到了来自移动互联网的挑战,人们不再打开电脑了,而且把时间全部放在了手机上,于是,Google的搜索也变得麻烦了,就算Google也做了一个搜索的App,也没人用过。Google还做了Google Plus的社交产品,最终也是以失败告终。除此之外,还有众多的Google产品都在移动互联网下玩完,比如:Google Talk/Hangouts, Google Wave,Google Buzz,Google Reader……还有电商网站Google Checkout, Google Offers……如果你要看Google死掉的产品你可以看一下这个网页 – Killed By Google ,一共200多个产品,有好多你都没有听说过。
另外一方面,Google和百度一样,在云计算方面都没有跟上时代。百度的李彦宏,2010年03月28日,在中国IT领袖峰会上说,“云计算不客气一点讲是新瓶装旧酒,没有新东西”,可见出了战略上的错误。而Google则是云计算的倡导者,Google在云计算上的技术造诣绝对不会比任何一家公司差,但是Google走了一条很曲高和寡的路——Google App Engine,直接跨过IaaS上到PaaS,最终错失市场,现在整合进Google Cloud Platform,提供一整套的多种形式的云服务,尤其是其AI、大数据和数据中心的运营能力,才挽回一点面子,但还是被AWS和Azure抛在后面。而百度那边呢,百度的“百度云”做成了“百度网盘”……
可以看见,在过去10年,Google还是比较危险的,同样和是搜索引擎起家的百度所面临的风险和危机是一样的——流量入口开始发生转移,导致技术架构和方案也跟着一起转变。但是,今天的Google依然很成功,也是一个破万亿市值的公司,为什么呢?是不是因为Google那边是运营和产品说了算呢?显然不是,如果是那样,Google今天的结局可能和百度也会很类似。
Google 牛逼的原因有很多,我想在这里重点说几个跟开源有关的产品,让大家感受一下Google是怎么在落后的地方力挽狂澜的,这实在让人细思极恐:
- Chrome浏览器。Google面对的竞争对手是微软的IE,这个用户入口如果失去了,Google的收入至少少一半(注:今天的天天在做慈善的Bill Gates,当年在浏览器市场上用操作系统垄断的方式把网景和Java都干得痛不欲生,最终引发反垄断诉讼才变得开放一点)。所以,为了要从当时占市场份额98%以上的IE抢市场,开源是一个非常好的策略(当时,还有用户体验,安全性和性能等其它因素)。
- Android 操作系统。Android 操作系统本质上是为了对抗 Apple和Microsoft,这两个公司在操作系统上耕耘多年,而未来的手机入口成为必争之地,如果Google错失了这个阵地,那么,Google的业务量会受到巨大的影响。所以,Google必需争夺,而且还必需用开源来搞。试想,如果Google的Android不开源的话,今天的智能手机市场很有可能是Apple和Micorsoft/Nokia唱主角了。正因为开源了Android,所以可以让更多的人和企业以Android的方式参与进来,从而对Apple和Microsoft形成真正的对抗。
- Kubernetes & CNCF。很明显,Kubernetes和后来的CNCF把云计算提升到了另一个层次——不再以资源虚拟化的云设施,而是以应用/服务/API调度为主的云计算。这个真的很猛,其目的主要也是要用一个新的云计算的形式来遏制AWS和Azure的发展,想通过Cloud Native的方式把云计算的游戏规则改变,从而让GCP更好用,另外,其也是开源的,并成立了了开源基金会,似乎是在告诉大众,无产阶级联合起来,对抗巨头。如果Kubernetes像Google的的论文不开源的话,估计也会错失当时竞争异常激烈的容器调度市场。
开源并不是Google的核心文化,Google有太多的好的东西,他都不开源,Google做死的产品几百个,但宁可放到垃圾桶里,他们也不会开源出来。所以,Google的开源,其本质上来说,还是为其商业逻辑服务的——为了抢夺别人的市场,为了后来者居上。
当然,Google比百度成功的原因还不仅上面这些,上面这些只是想让大家看到Google的思路。这些思路,很明显都是技术的思路,不是运营的思路。Google虽然有技术,但也不是在所有的技术上都有优势,看看人家是怎么在自己并没有优势的地方抢市场的玩法,可能会对理解百度为什么掉队了会有更准确的帮助。
最后,Wikipedia上有几个和Google有关清单,可以看看。
- Google 并购公司的清单 – Google 的并了购了240多家公司。
- Google 的产品清单 – Google 的产品簇简直就是一个大杂烩 。
- Google 的APP清单 – 看看Google的APP全家桶,数百个应用。
看完这些清单,你可能会感觉到,Google 这厮也是什么都在干,所以,死的也很多。但这种大规模试错的产能,并不是任何一个公司都有的。百度和Google的员工数量我在网上找了一下,只能看到2018年的数据,2018年百度有45000人,Google有98000人。人数少了一半,但是产能少了可不只一半。
另外,你再仔细看一下上面的清单,你会看得出来,Google做的这些产品和方向都有一种浓浓的技术味……而且,你会觉得,在技术上折腾,就算是失败了,也能让人感觉得到这家公司和团队不会差……
与《百度不要用户》这篇文章中所说的,百度的问题是“技术人员话语太强”,我觉得百度的问题是,不再做技术了……而公司出现了混乱的思维方式,无论是不是技术人员,谁都不会思考和做决定了……


 浙公网安备 33010602011771号
浙公网安备 33010602011771号