分布式锁,base柔性事务,类加载,Tomcat类加载机制和JAVA类加载机制的比较,JVM内存区域划分(JDK6/7/8中的变化)
再有人问你分布式锁,这篇文章扔给他 - 掘金 (juejin.cn)
1.背景
对于锁大家肯定不会陌生,在Java中synchronized关键字和ReentrantLock可重入锁在我们的代码中是经常见的,一般我们用其在多线程环境中控制对资源的并发访问,但是随着分布式的快速发展,本地的加锁往往不能满足我们的需要,在我们的分布式环境中上面加锁的方法就会失去作用。于是人们为了在分布式环境中也能实现本地锁的效果,也是纷纷各出其招,今天让我们来聊一聊一般分布式锁实现的套路。
2.分布式锁
2.1为何需要分布式锁
Martin Kleppmann是英国剑桥大学的分布式系统的研究员,之前和Redis之父Antirez进行过关于RedLock(红锁,后续有讲到)是否安全的激烈讨论。Martin认为一般我们使用分布式锁有两个场景:
- 效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
2.2分布式锁的一些特点
当我们确定了在不同节点上需要分布式锁,那么我们需要了解分布式锁到底应该有哪些特点:
- 互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
- 锁超时:和本地锁一样支持锁超时,防止死锁。
- 高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞:和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
2.3常见的分布式锁
我们了解了一些特点之后,我们一般实现分布式锁有以下几个方式:
- MySql
- Zk
- Redis
- 自研分布式锁:如谷歌的Chubby。
下面分开介绍一下这些分布式锁的实现原理。
3Mysql分布式锁
首先来说一下Mysql分布式锁的实现原理,相对来说这个比较容易理解,毕竟数据库和我们开发人员在平时的开发中息息相关。对于分布式锁我们可以创建一个锁表:
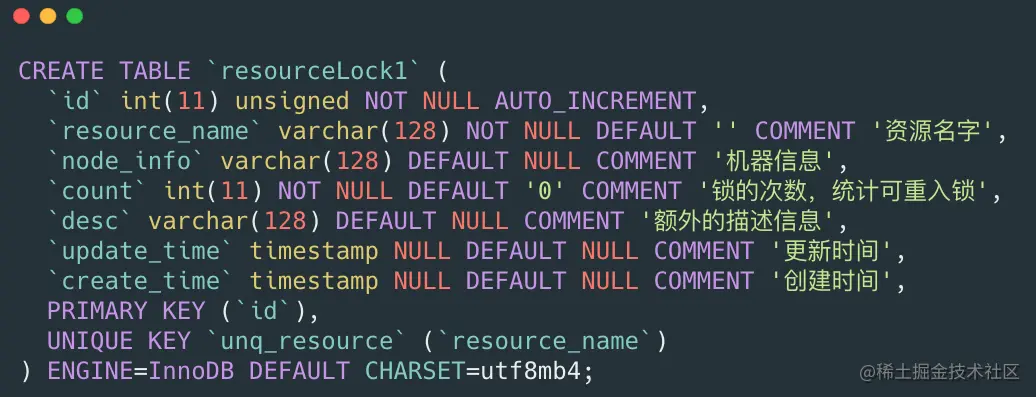
前面我们所说的lock(),trylock(long timeout),trylock()这几个方法可以用下面的伪代码实现。
3.1 lock()
lock一般是阻塞式的获取锁,意思就是不获取到锁誓不罢休,那么我们可以写一个死循环来执行其操作:

mysqlLock.lcok内部是一个sql,为了达到可重入锁的效果那么我们应该先进行查询,如果有值,那么需要比较node_info是否一致,这里的node_info可以用机器IP和线程名字来表示,如果一致那么就加可重入锁count的值,如果不一致那么就返回false。如果没有值那么直接插入一条数据。伪代码如下:
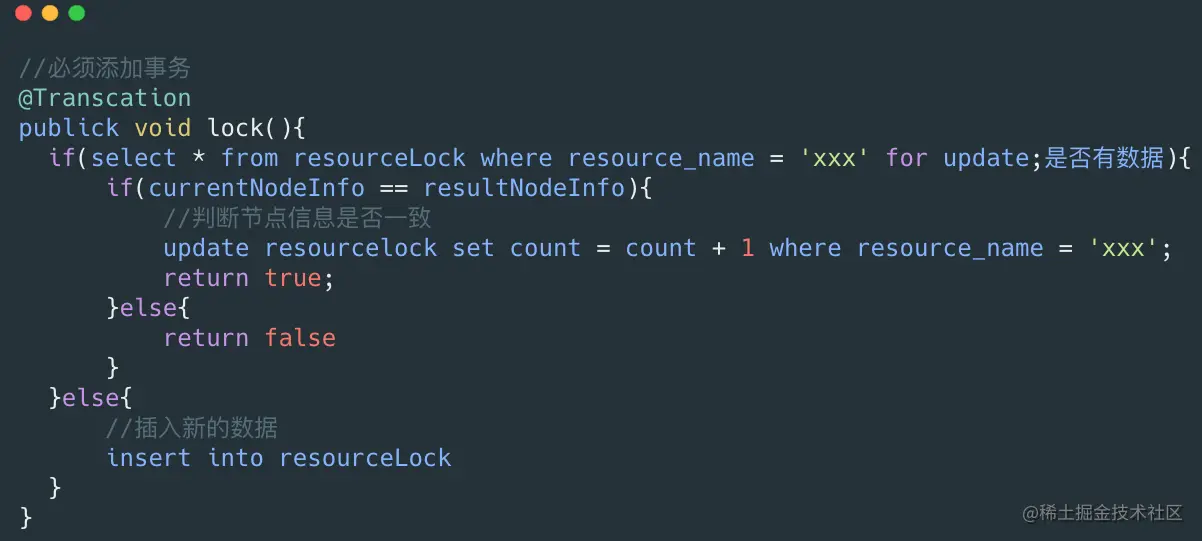
需要注意的是这一段代码需要加事务,必须要保证这一系列操作的原子性。
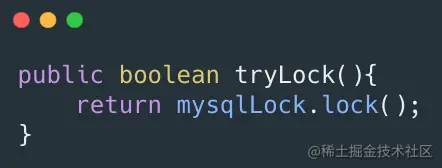
3.2tryLock()和tryLock(long timeout)
tryLock()是非阻塞获取锁,如果获取不到那么就会马上返回,代码可以如下:
tryLock(long timeout)实现如下:
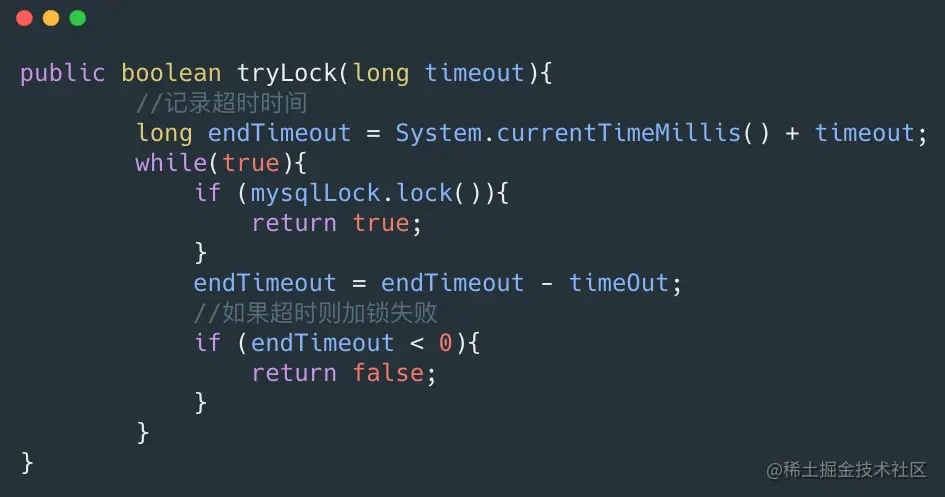
mysqlLock.lock和上面一样,但是要注意的是select ... for update这个是阻塞的获取行锁,如果同一个资源并发量较大还是有可能会退化成阻塞的获取锁。
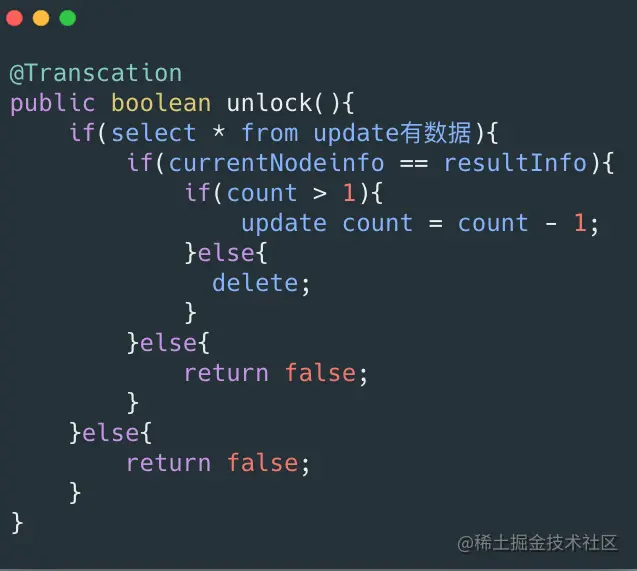
3.3 unlock()
unlock的话如果这里的count为1那么可以删除,如果大于1那么需要减去1。
3.4 锁超时
我们有可能会遇到我们的机器节点挂了,那么这个锁就不会得到释放,我们可以启动一个定时任务,通过计算一般我们处理任务的一般的时间,比如是5ms,那么我们可以稍微扩大一点,当这个锁超过20ms没有被释放我们就可以认定是节点挂了然后将其直接释放。
3.5 Mysql小结
- 适用场景: Mysql分布式锁一般适用于资源不存在数据库,如果数据库存在比如订单,那么可以直接对这条数据加行锁,不需要我们上面多的繁琐的步骤,比如一个订单,那么我们可以用select * from order_table where id = 'xxx' for update进行加行锁,那么其他的事务就不能对其进行修改。
- 优点:理解起来简单,不需要维护额外的第三方中间件(比如Redis,Zk)。
- 缺点:虽然容易理解但是实现起来较为繁琐,需要自己考虑锁超时,加事务等等。性能局限于数据库,一般对比缓存来说性能较低。对于高并发的场景并不是很适合。
3.6 乐观锁
前面我们介绍的都是悲观锁,这里想额外提一下乐观锁,在我们实际项目中也是经常实现乐观锁,因为我们加行锁的性能消耗比较大,通常我们会对于一些竞争不是那么激烈,但是其又需要保证我们并发的顺序执行使用乐观锁进行处理,我们可以对我们的表加一个版本号字段,那么我们查询出来一个版本号之后,update或者delete的时候需要依赖我们查询出来的版本号,判断当前数据库和查询出来的版本号是否相等,如果相等那么就可以执行,如果不等那么就不能执行。这样的一个策略很像我们的CAS(Compare And Swap),比较并交换是一个原子操作。这样我们就能避免加select * for update行锁的开销。
4. ZooKeeper
ZooKeeper也是我们常见的实现分布式锁方法,相比于数据库如果没了解过ZooKeeper可能上手比较难一些。ZooKeeper是以Paxos算法为基础分布式应用程序协调服务。Zk的数据节点和文件目录类似,所以我们可以用此特性实现分布式锁。我们以某个资源为目录,然后这个目录下面的节点就是我们需要获取锁的客户端,未获取到锁的客户端注册需要注册Watcher到上一个客户端,可以用下图表示。
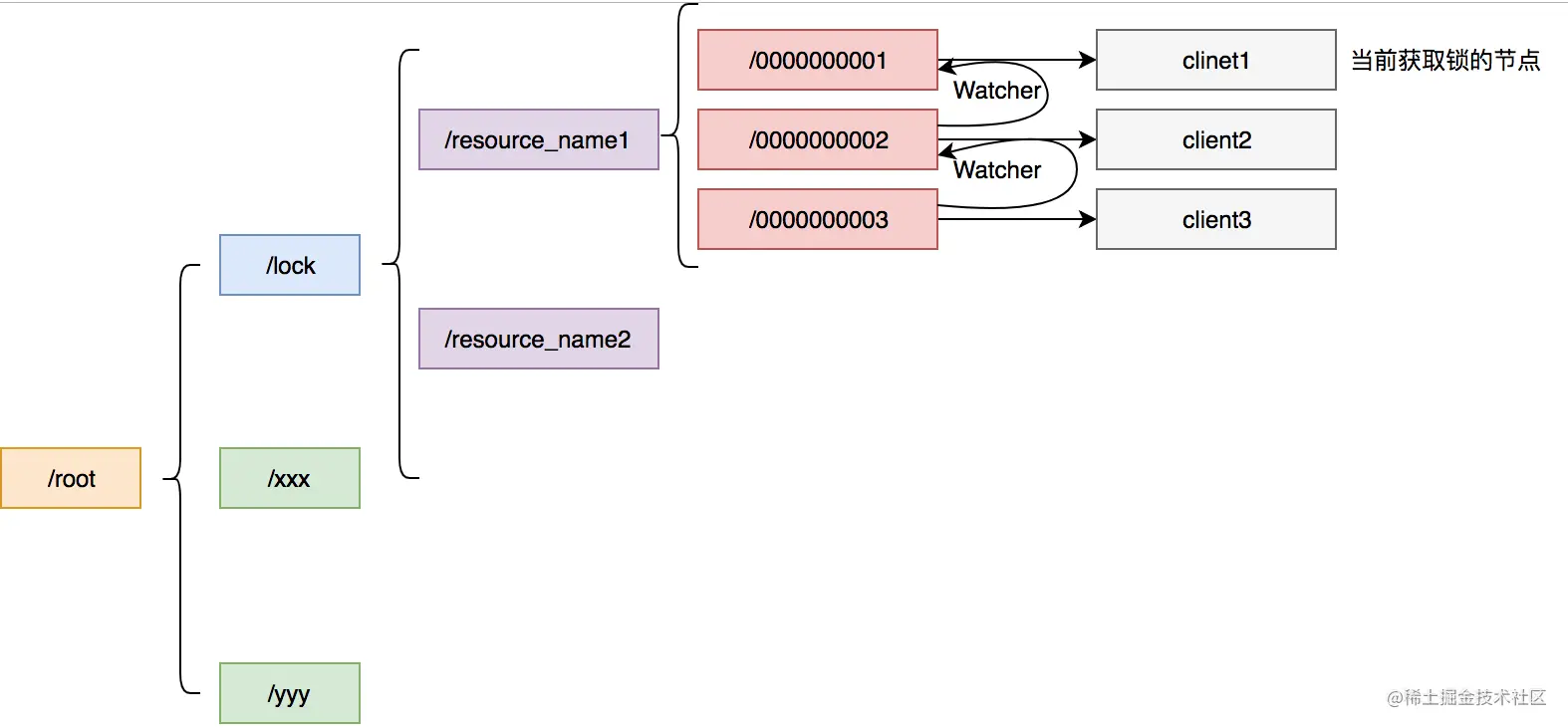
/lock是我们用于加锁的目录,/resource_name是我们锁定的资源,其下面的节点按照我们加锁的顺序排列。
4.1Curator
Curator封装了Zookeeper底层的Api,使我们更加容易方便的对Zookeeper进行操作,并且它封装了分布式锁的功能,这样我们就不需要再自己实现了。
Curator实现了可重入锁(InterProcessMutex),也实现了不可重入锁(InterProcessSemaphoreMutex)。在可重入锁中还实现了读写锁。
4.2InterProcessMutex
InterProcessMutex是Curator实现的可重入锁,我们可以通过下面的一段代码实现我们的可重入锁:

我们利用acuire进行加锁,release进行解锁。
加锁的流程具体如下:
- 首先进行可重入的判定:这里的可重入锁记录在ConcurrentMap<Thread, LockData> threadData这个Map里面,如果threadData.get(currentThread)是有值的那么就证明是可重入锁,然后记录就会加1。我们之前的Mysql其实也可以通过这种方法去优化,可以不需要count字段的值,将这个维护在本地可以提高性能。
- 然后在我们的资源目录下创建一个节点:比如这里创建一个/0000000002这个节点,这个节点需要设置为EPHEMERAL_SEQUENTIAL也就是临时节点并且有序。
- 获取当前目录下所有子节点,判断自己的节点是否位于子节点第一个。
- 如果是第一个,则获取到锁,那么可以返回。
- 如果不是第一个,则证明前面已经有人获取到锁了,那么需要获取自己节点的前一个节点。/0000000002的前一个节点是/0000000001,我们获取到这个节点之后,再上面注册Watcher(这里的watcher其实调用的是object.notifyAll(),用来解除阻塞)。
- object.wait(timeout)或object.wait():进行阻塞等待这里和我们第5步的watcher相对应。
解锁的具体流程:
- 首先进行可重入锁的判定:如果有可重入锁只需要次数减1即可,减1之后加锁次数为0的话继续下面步骤,不为0直接返回。
- 删除当前节点。
- 删除threadDataMap里面的可重入锁的数据。
4.3读写锁
Curator提供了读写锁,其实现类是InterProcessReadWriteLock,这里的每个节点都会加上前缀:
private static final String READ_LOCK_NAME = "__READ__";
private static final String WRITE_LOCK_NAME = "__WRIT__";
复制代码根据不同的前缀区分是读锁还是写锁,对于读锁,如果发现前面有写锁,那么需要将watcher注册到和自己最近的写锁。写锁的逻辑和我们之前4.2分析的依然保持不变。
4.4锁超时
Zookeeper不需要配置锁超时,由于我们设置节点是临时节点,我们的每个机器维护着一个ZK的session,通过这个session,ZK可以判断机器是否宕机。如果我们的机器挂掉的话,那么这个临时节点对应的就会被删除,所以我们不需要关心锁超时。
4.5 ZK小结
- 优点:ZK可以不需要关心锁超时时间,实现起来有现成的第三方包,比较方便,并且支持读写锁,ZK获取锁会按照加锁的顺序,所以其是公平锁。对于高可用利用ZK集群进行保证。
- 缺点:ZK需要额外维护,增加维护成本,性能和Mysql相差不大,依然比较差。并且需要开发人员了解ZK是什么。
5.Redis
大家在网上搜索分布式锁,恐怕最多的实现就是Redis了,Redis因为其性能好,实现起来简单所以让很多人都对其十分青睐。
5.1Redis分布式锁简单实现
熟悉Redis的同学那么肯定对setNx(set if not exist)方法不陌生,如果不存在则更新,其可以很好的用来实现我们的分布式锁。对于某个资源加锁我们只需要
setNx resourceName value
复制代码这里有个问题,加锁了之后如果机器宕机那么这个锁就不会得到释放所以会加入过期时间,加入过期时间需要和setNx同一个原子操作,在Redis2.8之前我们需要使用Lua脚本达到我们的目的,但是redis2.8之后redis支持nx和ex操作是同一原子操作。
set resourceName value ex 5 nx
复制代码5.2Redission
Javaer都知道Jedis,Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持。Redission也是Redis的客户端,相比于Jedis功能简单。Jedis简单使用阻塞的I/O和redis交互,Redission通过Netty支持非阻塞I/O。Jedis最新版本2.9.0是2016年的快3年了没有更新,而Redission最新版本是2018.10月更新。
Redission封装了锁的实现,其继承了java.util.concurrent.locks.Lock的接口,让我们像操作我们的本地Lock一样去操作Redission的Lock,下面介绍一下其如何实现分布式锁。

Redission不仅提供了Java自带的一些方法(lock,tryLock),还提供了异步加锁,对于异步编程更加方便。 由于内部源码较多,就不贴源码了,这里用文字叙述来分析他是如何加锁的,这里分析一下tryLock方法:
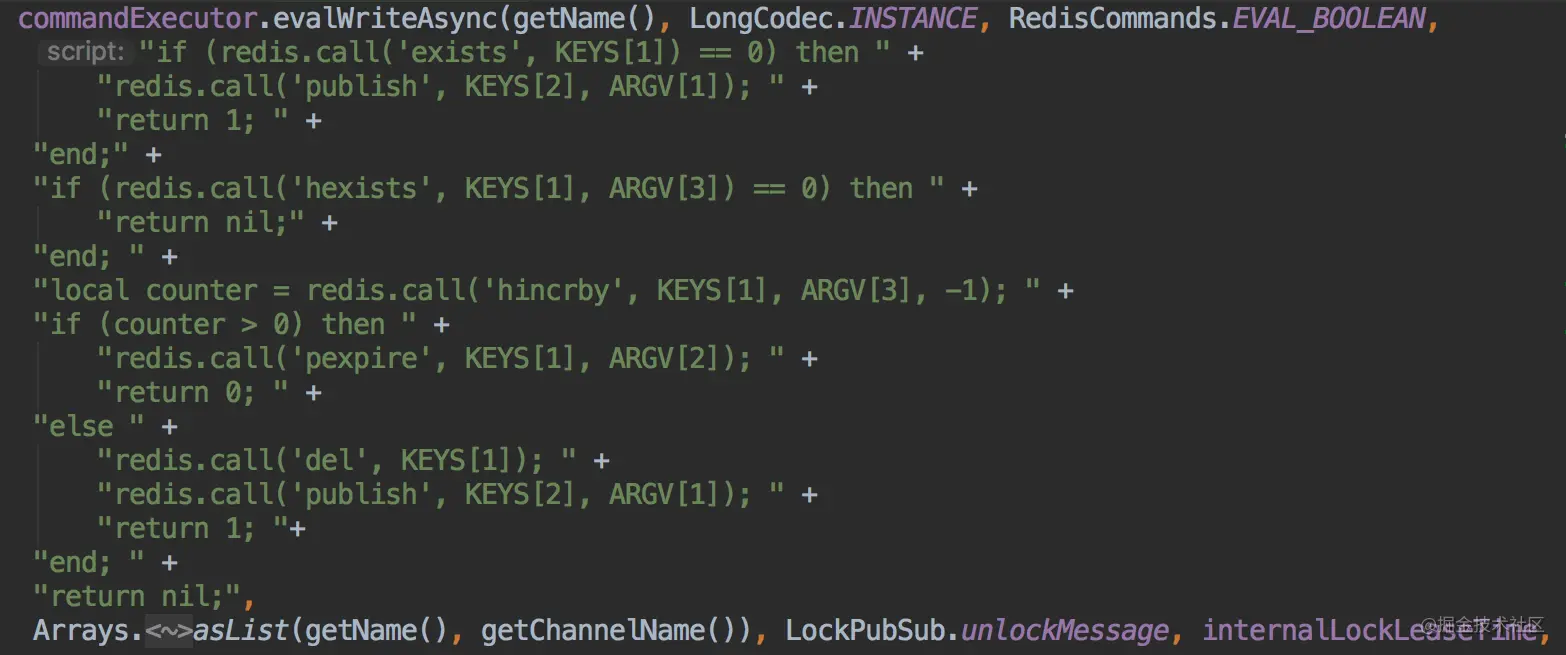
- 尝试加锁:首先会尝试进行加锁,由于保证操作是原子性,那么就只能使用lua脚本,相关的lua脚本如下:
 可以看见他并没有使用我们的sexNx来进行操作,而是使用的hash结构,我们的每一个需要锁定的资源都可以看做是一个HashMap,锁定资源的节点信息是Key,锁定次数是value。通过这种方式可以很好的实现可重入的效果,只需要对value进行加1操作,就能进行可重入锁。当然这里也可以用之前我们说的本地计数进行优化。
可以看见他并没有使用我们的sexNx来进行操作,而是使用的hash结构,我们的每一个需要锁定的资源都可以看做是一个HashMap,锁定资源的节点信息是Key,锁定次数是value。通过这种方式可以很好的实现可重入的效果,只需要对value进行加1操作,就能进行可重入锁。当然这里也可以用之前我们说的本地计数进行优化。 - 如果尝试加锁失败,判断是否超时,如果超时则返回false。
- 如果加锁失败之后,没有超时,那么需要在名字为redisson_lock__channel+lockName的channel上进行订阅,用于订阅解锁消息,然后一直阻塞直到超时,或者有解锁消息。
- 重试步骤1,2,3,直到最后获取到锁,或者某一步获取锁超时。
对于我们的unlock方法比较简单也是通过lua脚本进行解锁,如果是可重入锁,只是减1。如果是非加锁线程解锁,那么解锁失败。
Redission还有公平锁的实现,对于公平锁其利用了list结构和hashset结构分别用来保存我们排队的节点,和我们节点的过期时间,用这两个数据结构帮助我们实现公平锁,这里就不展开介绍了,有兴趣可以参考源码。
5.3RedLock
我们想象一个这样的场景当机器A申请到一把锁之后,如果Redis主宕机了,这个时候从机并没有同步到这一把锁,那么机器B再次申请的时候就会再次申请到这把锁,为了解决这个问题Redis作者提出了RedLock红锁的算法,在Redission中也对RedLock进行了实现。
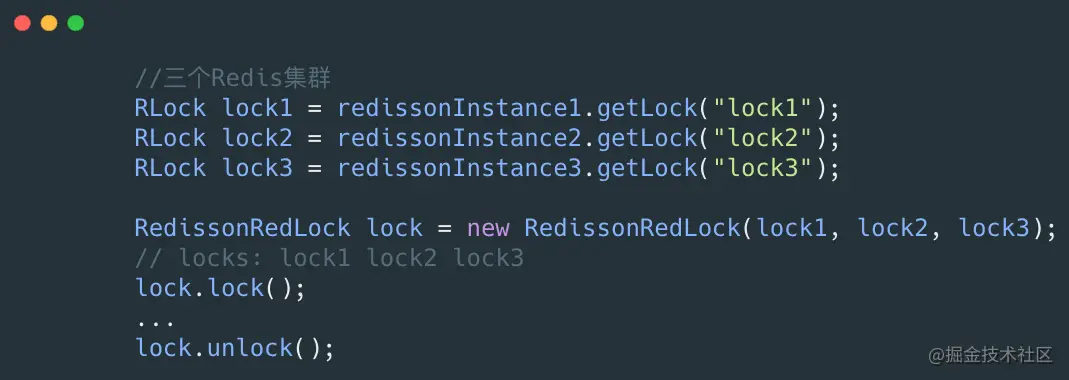
通过上面的代码,我们需要实现多个Redis集群,然后进行红锁的加锁,解锁。具体的步骤如下:
- 首先生成多个Redis集群的Rlock,并将其构造成RedLock。
- 依次循环对三个集群进行加锁,加锁的过程和5.2里面一致。
- 如果循环加锁的过程中加锁失败,那么需要判断加锁失败的次数是否超出了最大值,这里的最大值是根据集群的个数,比如三个那么只允许失败一个,五个的话只允许失败两个,要保证多数成功。
- 加锁的过程中需要判断是否加锁超时,有可能我们设置加锁只能用3ms,第一个集群加锁已经消耗了3ms了。那么也算加锁失败。
- 3,4步里面加锁失败的话,那么就会进行解锁操作,解锁会对所有的集群在请求一次解锁。
可以看见RedLock基本原理是利用多个Redis集群,用多数的集群加锁成功,减少Redis某个集群出故障,造成分布式锁出现问题的概率。
5.4 Redis小结
- 优点:对于Redis实现简单,性能对比ZK和Mysql较好。如果不需要特别复杂的要求,那么自己就可以利用setNx进行实现,如果自己需要复杂的需求的话那么可以利用或者借鉴Redission。对于一些要求比较严格的场景来说的话可以使用RedLock。
- 缺点:需要维护Redis集群,如果要实现RedLock那么需要维护更多的集群。
6.分布式锁的安全问题
上面我们介绍过红锁,但是Martin Kleppmann认为其依然不安全。有关于Martin反驳的几点,我认为其实不仅仅局限于RedLock,前面说的算法基本都有这个问题,下面我们来讨论一下这些问题:
- 长时间的GC pause:熟悉Java的同学肯定对GC不陌生,在GC的时候会发生STW(stop-the-world),例如CMS垃圾回收器,他会有两个阶段进行STW防止引用继续进行变化。那么有可能会出现下面图(引用至Martin反驳Redlock的文章)中这个情况:
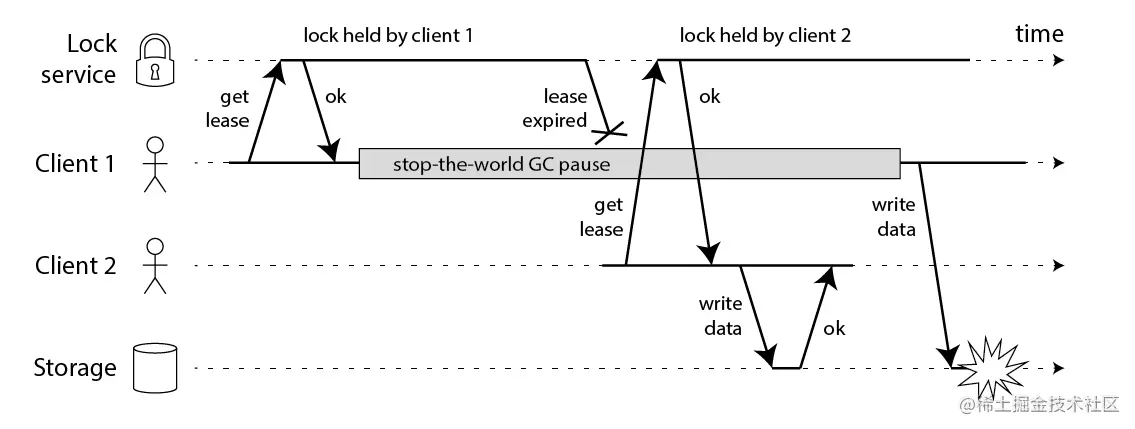 client1获取了锁并且设置了锁的超时时间,但是client1之后出现了STW,这个STW时间比较长,导致分布式锁进行了释放,client2获取到了锁,这个时候client1恢复了锁,那么就会出现client1,2同时获取到锁,这个时候分布式锁不安全问题就出现了。这个其实不仅仅局限于RedLock,对于我们的ZK,Mysql一样的有同样的问题。
client1获取了锁并且设置了锁的超时时间,但是client1之后出现了STW,这个STW时间比较长,导致分布式锁进行了释放,client2获取到了锁,这个时候client1恢复了锁,那么就会出现client1,2同时获取到锁,这个时候分布式锁不安全问题就出现了。这个其实不仅仅局限于RedLock,对于我们的ZK,Mysql一样的有同样的问题。 - 时钟发生跳跃:对于Redis服务器如果其时间发生了向跳跃,那么肯定会影响我们锁的过期时间,那么我们的锁过期时间就不是我们预期的了,也会出现client1和client2获取到同一把锁,那么也会出现不安全,这个对于Mysql也会出现。但是ZK由于没有设置过期时间,那么发生跳跃也不会受影响。
- 长时间的网络I/O:这个问题和我们的GC的STW很像,也就是我们这个获取了锁之后我们进行网络调用,其调用时间由可能比我们锁的过期时间都还长,那么也会出现不安全的问题,这个Mysql也会有,ZK也不会出现这个问题。
对于这三个问题,在网上包括Redis作者在内发起了很多讨论。
6.1 GC的STW
对于这个问题可以看见基本所有的都会出现问题,Martin给出了一个解法,对于ZK这种他会生成一个自增的序列,那么我们真正进行对资源操作的时候,需要判断当前序列是否是最新,有点类似于我们乐观锁。当然这个解法Redis作者进行了反驳,你既然都能生成一个自增的序列了那么你完全不需要加锁了,也就是可以按照类似于Mysql乐观锁的解法去做。
我自己认为这种解法增加了复杂性,当我们对资源操作的时候需要增加判断序列号是否是最新,无论用什么判断方法都会增加复杂度,后面会介绍谷歌的Chubby提出了一个更好的方案。
6.2 时钟发生跳跃
Martin觉得RedLock不安全很大的原因也是因为时钟的跳跃,因为锁过期强依赖于时间,但是ZK不需要依赖时间,依赖每个节点的Session。Redis作者也给出了解答:对于时间跳跃分为人为调整和NTP自动调整。
- 人为调整:人为调整影响的那么完全可以人为不调整,这个是处于可控的。
- NTP自动调整:这个可以通过一定的优化,把跳跃时间控制的可控范围内,虽然会跳跃,但是是完全可以接受的。
6.3长时间的网络I/O
这一块不是他们讨论的重点,我自己觉得,对于这个问题的优化可以控制网络调用的超时时间,把所有网络调用的超时时间相加,那么我们锁过期时间其实应该大于这个时间,当然也可以通过优化网络调用比如串行改成并行,异步化等。可以参考我的两个文章: 并行化-你的高并发大杀器,异步化-你的高并发大杀器
7.Chubby的一些优化
大家搜索ZK的时候,会发现他们都写了ZK是Chubby的开源实现,Chubby内部工作原理和ZK类似。但是Chubby的定位是分布式锁和ZK有点不同。Chubby也是使用上面自增序列的方案用来解决分布式不安全的问题,但是他提供了多种校验方法:
- CheckSequencer():调用Chubby的API检查此时这个序列号是否有效。
- 访问资源服务器检查,判断当前资源服务器最新的序列号和我们的序列号的大小。
- lock-delay:为了防止我们校验的逻辑入侵我们的资源服务器,其提供了一种方法当客户端失联的时候,并不会立即释放锁,而是在一定的时间内(默认1min)阻止其他客户端拿去这个锁,那么也就是给予了一定的buffer等待STW恢复,而我们的GC的STW时间如果比1min还长那么你应该检查你的程序,而不是怀疑你的分布式锁了。
8.小结
本文主要讲了多种分布式锁的实现方法,以及他们的一些优缺点。最后也说了一下有关于分布式锁的安全的问题,对于不同的业务需要的安全程度完全不同,我们需要根据自己的业务场景,通过不同的维度分析,选取最适合自己的方案。
最后这篇文章被我收录于JGrowing,一个全面,优秀,由社区一起共建的Java学习路线,如果您想参与开源项目的维护,可以一起共建,github地址为:github.com/javagrowing… 麻烦给个小星星哟。
如何保证事务一致性的问题,目前并没有完美的解决方案:
- 传统数据库的事务非常好的保证了业务的一致性,无论是单数据库的事务机制,还是分布式事务的两阶段提交机制,都在互联网场景下就暴露出数据库性能和处理能力上的瓶颈,效率不够搞。
- 采用CAP、BASE理论的柔性事务,在保证可用性、一致性的前提下,达成“最终一致性”。
- 一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- 一致性:所有节点在同一时间的数据完全一致。
- 可用性:用户在访问数据时可以得到及时的响应。
- 分区容错性:指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
- 强一致性的锁机制带来了数据层的性能瓶颈,可用性会严重影响用户体验,分区容错性影响系统的横向扩展能力。
- 实际上分区容错性是分布式系统的固有属性,所以基本上我们在设计分布式系统的时候只能二选一:要数据一致性(C)还是系统可用性(A)?
- 当集群中的节点数量持续增加时,一致性的成本非常高,所以很多时候只能选择可用性而放弃强一致性(当然提高可用性也意味着商业上少损失money)。Zookeeper、Hadoop之所以选择强一致性,是因为这些系统的节点相对来说还是少量。
BASE理论
- eBay架构师Dan Pritchett对于大规模分布式系统的实践总结:B(Basically Available)、S(Soft state)、E(Eventual Consistency)。
- 基本可用:指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。
- 柔性状态:指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。比如,允许不同节点间副本同步的延时就是柔性状态的体现。
- 最终一致性:指系统中的所有副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
- 互联网应用的最核心需求是高可用性,高可用性=分布式系统=高性能。
传统分布式事务机制:
- 两阶段提交:第一阶段是准备阶段,第二阶段是提交阶段,如果有任意一个参与者在第一阶段响应“未准备好”,则整个事务回滚;如果所有参与者在第一阶段都回答“就绪”,那这些资源就在第二阶段提交。
- X/Open组织为基于两阶段协议的分布式事务处理系统提出了标准的系统参考模型(X/Open事务模型)以及不同组件间与事务协调相关的接口,使不同厂商的产品能够互操作。
柔性事务如何解决分布式事务问题:
- 引入日志和补偿机制:通过日志来保证柔性事务的原子性,事务日志记录事务的开始、结束状态,可能还包括事务参与者信息,参与者节点也需要根据重做或回滚需求记录REDO/UNDO日志,当事务重试、回滚时,可以根据这些日志最终将数据恢复到一致状态。在互联网业界采用日志方式实现柔性事务的比例非常大,但因为这部分技术的实现并没有如XA这样的技术标准和规范,很多应用对这部分的实现非常的粗糙。
- 可靠消息传递:由于“网络通信危险期”的存在,消息投递只有两种模式:1)消息仅投递一次,但是可能会没有收到;2)消息至少收到一次,但可能会投递多次。在业务一致性的要求下,只能选择第二种投递方式,由于可能重复投递这就要求消息处理程序必须实现幂等(即同一操作反复执行多次结果不变),这一要求跟传统应用开发相比是非常具有互联网特征的一种模式。幂等的实现方法--也是eBay给的一个简单思路,根据msg_id在目标端是否存在来判断是已经处理过。
- 实现无锁:1)避免事务进入回滚,由于事务不会回滚也不会导致脏读;2)辅助业务变化明细表,比如对资金或库存进行增减处理时,可采用记录这些变化的明细表的方式,避免所有事务均对同一数据表进行更新操作,造成数据访问热点,同时使得不同事务中处理的数据互不干扰,实现对资金或库存信息处理的隔离;3)乐观锁,比如通过在资金表中增加版本号,在事务开始前获取版本号,在事务开始后对资金进行数据更新时可通过在执行最后的修改update语句时进行之前获取版本号的比对,如果版本号一致则更新否则放弃当前事务。
面试常备题---JVM加载class文件的原理机制 - 文酱 - 博客园 (cnblogs.com)
在面试java工程师的时候,这道题经常被问到,故需特别注意。
Java中的所有类,都需要由类加载器装载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中。在写程序的时候,我们几乎不需要关心类的加载,因为这些都是隐式装载的,除非我们有特殊的用法,像是反射,就需要显式的加载所需要的类。
Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(像是基类)完全加载到jvm中,至于其他类,则在需要的时候才加载。这当然就是为了节省内存开销。
Java的类加载器有三个,对应Java的三种类:
Bootstrap Loader // 负责加载系统类 (指的是内置类,像是String,对应于C#中的System类和C/C++标准库中的类)
|
- - ExtClassLoader // 负责加载扩展类(就是继承类和实现类)
|
- - AppClassLoader // 负责加载应用类(程序员自定义的类)
三个加载器各自完成自己的工作,但它们是如何协调工作呢?哪一个类该由哪个类加载器完成呢?为了解决这个问题,Java采用了委托模型机制。
委托模型机制的工作原理很简单:当类加载器需要加载类的时候,先请示其Parent(即上一层加载器)在其搜索路径载入,如果找不到,才在自己的搜索路径搜索该类。这样的顺序其实就是加载器层次上自顶而下的搜索,因为加载器必须保证基础类的加载。之所以是这种机制,还有一个安全上的考虑:如果某人将一个恶意的基础类加载到jvm,委托模型机制会搜索其父类加载器,显然是不可能找到的,自然就不会将该类加载进来。
我们可以通过这样的代码来获取类加载器:
ClassLoader loader = ClassName.class.getClassLoader();
ClassLoader ParentLoader = loader.getParent();
注意一个很重要的问题,就是Java在逻辑上并不存在BootstrapKLoader的实体!因为它是用C++编写的,所以打印其内容将会得到null。
前面是对类加载器的简单介绍,它的原理机制非常简单,就是下面几个步骤:
1.装载:查找和导入class文件;
2.连接:
(1)检查:检查载入的class文件数据的正确性;
(2)准备:为类的静态变量分配存储空间;
(3)解析:将符号引用转换成直接引用(这一步是可选的)
3.初始化:初始化静态变量,静态代码块。
这样的过程在程序调用类的静态成员的时候开始执行,所以静态方法main()才会成为一般程序的入口方法。类的构造器也会引发该动作。
Tomcat类加载机制和JAVA类加载机制的比较_风剑无影的博客-CSDN博客
图解Tomcat类加载机制
说到本篇的tomcat类加载机制,不得不说翻译学习tomcat的初衷。
之前实习的时候学习javaMelody的源码,但是它是一个Maven的项目,与我们自己的web项目整合后无法直接断点调试。后来同事指导,说是直接把java类复制到src下就可以了。很纳闷....为什么会优先加载src下的java文件(编译出的class),而不是jar包中的class呢?
现在了解tomcat的类加载机制,原来一切是这么的简单。
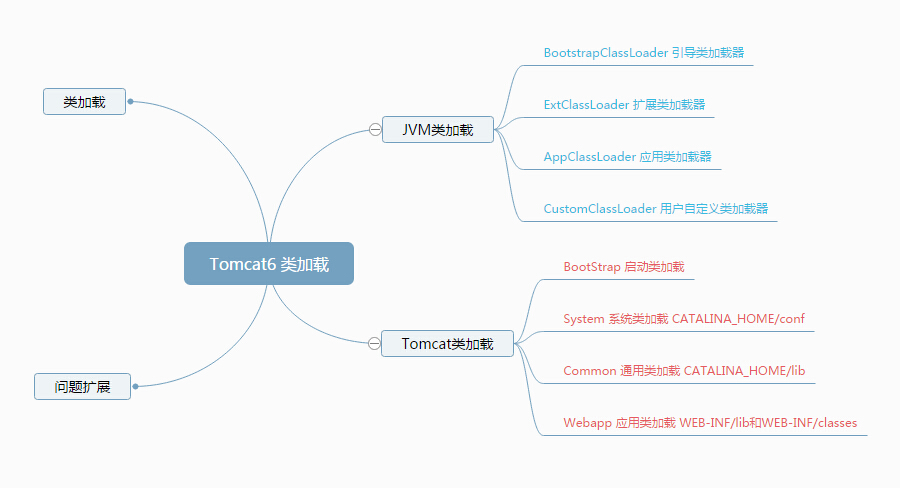
类加载
在JVM中并不是一次性把所有的文件都加载到,而是一步一步的,按照需要来加载。
比如JVM启动时,会通过不同的类加载器加载不同的类。当用户在自己的代码中,需要某些额外的类时,再通过加载机制加载到JVM中,并且存放一段时间,便于频繁使用。
因此使用哪种类加载器、在什么位置加载类都是JVM中重要的知识。
JVM类加载
JVM类加载采用 父类委托机制,如下图所示:
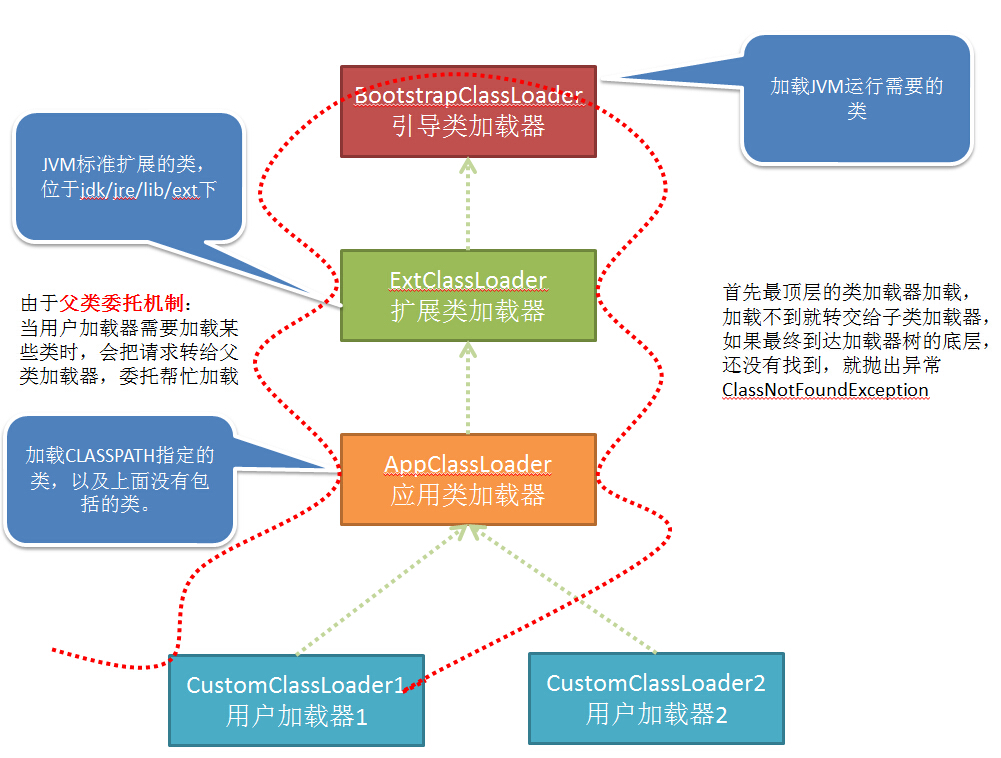
JVM中包括集中类加载器:
1 BootStrapClassLoader 引导类加载器
2 ExtClassLoader 扩展类加载器
3 AppClassLoader 应用类加载器
4 CustomClassLoader 用户自定义类加载器
他们的区别上面也都有说明。需要注意的是,不同的类加载器加载的类是不同的,因此如果用户加载器1加载的某个类,其他用户并不能够使用。
当JVM运行过程中,用户需要加载某些类时,会按照下面的步骤(父类委托机制):
1 用户自己的类加载器,把加载请求传给父加载器,父加载器再传给其父加载器,一直到加载器树的顶层。
2 最顶层的类加载器首先针对其特定的位置加载,如果加载不到就转交给子类。
3 如果一直到底层的类加载都没有加载到,那么就会抛出异常ClassNotFoundException。
因此,按照这个过程可以想到,如果同样在CLASSPATH指定的目录中和自己工作目录中存放相同的class,会优先加载CLASSPATH目录中的文件。
Tomcat类加载
在tomcat中类的加载稍有不同,如下图:

当tomcat启动时,会创建几种类加载器:
1 Bootstrap 引导类加载器
加载JVM启动所需的类,以及标准扩展类(位于jre/lib/ext下)
2 System 系统类加载器
加载tomcat启动的类,比如bootstrap.jar,通常在catalina.bat或者catalina.sh中指定。位于CATALINA_HOME/bin下。
3 Common 通用类加载器
加载tomcat使用以及应用通用的一些类,位于CATALINA_HOME/lib下,比如servlet-api.jar
4 webapp 应用类加载器
每个应用在部署后,都会创建一个唯一的类加载器。该类加载器会加载位于 WEB-INF/lib下的jar文件中的class 和 WEB-INF/classes下的class文件。
当应用需要到某个类时,则会按照下面的顺序进行类加载:
1 使用bootstrap引导类加载器加载
2 使用system系统类加载器加载
3 使用应用类加载器在WEB-INF/classes中加载
4 使用应用类加载器在WEB-INF/lib中加载
5 使用common类加载器在CATALINA_HOME/lib中加载
问题扩展
通过对上面tomcat类加载机制的理解,就不难明白 为什么java文件放在Eclipse中的src文件夹下会优先jar包中的class?
这是因为Eclipse中的src文件夹中的文件java以及webContent中的JSP都会在tomcat启动时,被编译成class文件放在 WEB-INF/class 中。
而Eclipse外部引用的jar包,则相当于放在 WEB-INF/lib 中。
因此肯定是 java文件或者JSP文件编译出的class优先加载。
通过这样,我们就可以简单的把java文件放置在src文件夹中,通过对该java文件的修改以及调试,便于学习拥有源码java文件、却没有打包成xxx-source的jar包。
另外呢,开发者也会因为粗心而犯下面的错误。
在 CATALINA_HOME/lib 以及 WEB-INF/lib 中放置了 不同版本的jar包,此时就会导致某些情况下报加载不到类的错误。
还有如果多个应用使用同一jar包文件,当放置了多份,就可能导致 多个应用间 出现类加载不到的错误。
参考
【1】Tomcat Class Loader:http://tomcat.apache.org/tomcat-6.0-doc/class-loader-howto.html
【2】Tomcat 类加载机制:http://blog.csdn.net/dc_726/article/details/11873343
JVM内存区域划分(JDK6/7/8中的变化)_Rainnnbow-CSDN博客
前言
Java程序的运行是通过Java虚拟机来实现的。通过类加载器将class字节码文件加载进JVM,然后根据预定的规则执行。Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些内存区域被统一叫做运行时数据区。Java运行时数据区大致可以划分为5个部分。如下图所示。在这里要特别指出,我们现在说的JVM内存划分是概念模型。具体到每个JVM的具体实现可能会有所不同。具体JVM的实现我只会提到HotSpot虚拟机的实现细节。
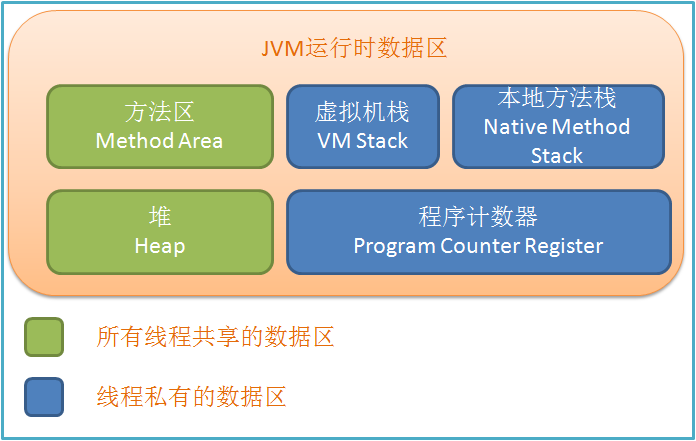
程序计数器
程序计数器是一块较小的内存空间,它可以看成是当前线程所执行的字节码的行号指示器。程序计数器记录线程当前要执行的下一条字节码指令的地址。由于Java是多线程的,所以为了多线程之间的切换与恢复,每一个线程都需要单独的程序计数器,各线程之间互不影响。这类内存区域被称为“线程私有”的内存区域。
由于程序计数器只存储一个字节码指令地址,故此内存区域没有规定任何OutOfMemoryError情况。
虚拟机栈
Java虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
一个栈帧就代表了一个方法执行的内存模型,虚拟机栈中存储的就是当前执行的所有方法的栈帧(包括正在执行的和等待执行的)。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机中入栈到出栈的过程。我们平时所说的“局部变量存储在栈中”就是指方法中的局部变量存储在代表该方法的栈帧的局部变量表中。而方法的执行正是从局部变量表中获取数据,放至操作数栈上,然后在操作数栈上进行运算,再将运算结果放入局部变量表中,最后将操作数栈顶的数据返回给方法的调用者的过程。(关于栈帧和基于栈的方法执行,我会在之后写两篇文章专门介绍。敬请期待☺)
虚拟机栈可能出现两种异常:由线程请求的栈深度过大超出虚拟机所允许的深度而引起的StackOverflowError异常;以及由虚拟机栈无法提供足够的内存而引起的OutOfMemoryError异常。
本地方法栈
本地方法栈与虚拟机栈类似,他们的区别在于:本地方法栈用于执行本地方法(Native方法);虚拟机栈用于执行普通的Java方法。在HotSpot虚拟机中,就将本地方法栈与虚拟机栈做在了一起。
本地方法栈可能抛出的异常同虚拟机栈一样。
堆
Java堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例:所有的对象实例以及数组都要在堆上分配(The heap is the runtime data area from which memory for all class instances and arrays is allocated)。但Class对象比较特殊,它虽然是对象,但是存放在方法区里。在下面的方法区一节会介绍。Java堆是垃圾收集器(GC)管理的主要区域。现在的收集器基本都采用分代收集算法:新生代和老年代。而对于不同的”代“采用的垃圾回收算法也不一样。一般新生代使用复制算法;老年代使用标记整理算法。对于不同的”代“,一般使用不同的垃圾收集器,新生代垃圾收集器和老年代垃圾收集器配合工作。(关于垃圾收集算法、垃圾收集器以及堆中具体的分代等知识,我之后会专门写几篇博客来介绍。再次敬请期待☺)
Java堆可以是物理上不连续的内存空间,只要逻辑上连续即可。Java堆可能抛出OutOfMemoryError异常。
方法区
方法区与Java堆一样,是各个线程共享的内存区域。它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
所有的字节码被加载之后,字节码中的信息:类信息、类中的方法信息、常量信息、类中的静态变量等都会存放在方法区。正如其名字一样:方法区中存放的就是类和方法的所有信息。此外,如果一个类被加载了,就会在方法区生成一个代表该类的Class对象(唯一一种不在堆上生成的对象实例)该对象将作为程序访问方法区中该类的信息的外部接口。有了该对象的存在,才有了反射的实现。
在Java7之前,HotSpot虚拟机中将GC分代收集扩展到了方法区,使用永久代来实现了方法区。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载。但是在之后的HotSpot虚拟机实现中,逐渐开始将方法区从永久代移除。Java7中已经将运行时常量池从永久代移除,在Java 堆(Heap)中开辟了一块区域存放运行时常量池。而在Java8中,已经彻底没有了永久代,将方法区直接放在一个与堆不相连的本地内存区域,这个区域被叫做元空间。
关于元空间的更多信息,请参考:Java永久代去哪儿了
运行时常量池
运行时常量池是方法区的一部分,关于运行时常量池的介绍,请参考我的另一篇博文:String放入运行时常量池的时机与String.intern()方法解惑。我还是花了些时间在理解运行时常量池上的。
直接内存
JDK1.4中引用了NIO,并引用了Channel与Buffer,可以使用Native函数库直接分配堆外内存,并通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。
如上文介绍的:Java8以及之后的版本中方法区已经从原来的JVM运行时数据区中被开辟到了一个称作元空间的直接内存区域。
参考:
《深入理解Java虚拟机-JVM高级特性与最佳实践》第二版 周志明著

 浙公网安备 33010602011771号
浙公网安备 33010602011771号