Http连接池,TCP:三次握手、四次握手、backlog及其他,Http持久连接与HttpClient连接池
起因
6.1大促值班发现的一个问题,一个rpc接口在0~2点用户下单高峰的时候表现rt高(超过1s,实际上针对性优化过的接口rt超过这个值也是有问题的,通常rpc接口里面即使逻辑复杂,300ms应该也搞定了),可以理解,但是在4~5点的时候接口的tps已经不高了,耗时依然在600ms~700ms之间就不能理解了。
查了一下,里面有段调用支付宝http接口的逻辑,但是每次都new一个HttpClient出来发起调用,调用时长大概在300ms+,所以导致即使在非高峰期接口耗时依然非常高。
问题不难,写篇文章系统性地对这块进行一下总结。
用不用线程池的差别
本文主要写的是“池”对于系统性能的影响,因此开始连接池之前,可以以线程池的例子作为一个引子开始本文,简单看下使不使用池的一个效果差别,代码如下:

/**
* 线程池测试
*
* @author 五月的仓颉https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class ThreadPoolTest {
private static final AtomicInteger FINISH_COUNT = new AtomicInteger(0);
private static final AtomicLong COST = new AtomicLong(0);
private static final Integer INCREASE_COUNT = 1000000;
private static final Integer TASK_COUNT = 1000;
@Test
public void testRunWithoutThreadPool() {
List<Thread> tList = new ArrayList<Thread>(TASK_COUNT);
for (int i = 0; i < TASK_COUNT; i++) {
tList.add(new Thread(new IncreaseThread()));
}
for (Thread t : tList) {
t.start();
}
for (;;);
}
@Test
public void testRunWithThreadPool() {
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 0, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>());
for (int i = 0; i < TASK_COUNT; i++) {
executor.submit(new IncreaseThread());
}
for (;;);
}
private class IncreaseThread implements Runnable {
@Override
public void run() {
long startTime = System.currentTimeMillis();
AtomicInteger counter = new AtomicInteger(0);
for (int i = 0; i < INCREASE_COUNT; i++) {
counter.incrementAndGet();
}
// 累加执行时间
COST.addAndGet(System.currentTimeMillis() - startTime);
if (FINISH_COUNT.incrementAndGet() == TASK_COUNT) {
System.out.println("cost: " + COST.get() + "ms");
}
}
}
}
逻辑比较简单:1000个任务,每个任务做的事情都是使用AtomicInteger从0累加到100W。
每个Test方法运行12次,排除一个最低的和一个最高的,对中间的10次取一个平均数,当不使用线程池的时候,任务总耗时为16693s;而当使用线程池的时候,任务平均执行时间为1073s,超过15倍,差别是非常明显的。
究其原因比较简单,相信大家都知道,主要是两点:
- 减少线程创建、销毁的开销
- 控制线程的数量,避免来一个任务创建一个线程,最终内存的暴增甚至耗尽
当然,前面也说了,这只是一个引子引出本文,当我们使用HTTP连接池的时候,任务处理效率提升的原因不止于此。
用哪个httpclient
容易搞错的一个点,大家特别注意一下。HttpClient可以搜到两个类似的工具包,一个是commons-httpclient:
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
一个是httpclient:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.8</version>
</dependency>
选第二个用,不要搞错了,他们的区别在stackoverflow上有解答:

即commons-httpclient是一个HttpClient老版本的项目,到3.1版本为止,此后项目被废弃不再更新(3.1版本,07年8.21发布),它已经被归入了一个更大的Apache HttpComponents项目中,这个项目版本号是HttpClient 4.x(4.5.8最新版本,19年5.30发布)。
随着不断更新,HttpClient底层针对代码细节、性能上都有持续的优化,因此切记选择org.apache.httpcomponents这个groupId。
不使用连接池的运行效果
有了工具类,就可以写代码来验证一下了。首先定义一个测试基类,等下使用连接池的代码演示的时候可以共用:
/**
* 连接池基类
*
* @author 五月的仓颉https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class BaseHttpClientTest {
protected static final int REQUEST_COUNT = 5;
protected static final String SEPERATOR = " ";
protected static final AtomicInteger NOW_COUNT = new AtomicInteger(0);
protected static final StringBuilder EVERY_REQ_COST = new StringBuilder(200);
/**
* 获取待运行的线程
*/
protected List<Thread> getRunThreads(Runnable runnable) {
List<Thread> tList = new ArrayList<Thread>(REQUEST_COUNT);
for (int i = 0; i < REQUEST_COUNT; i++) {
tList.add(new Thread(runnable));
}
return tList;
}
/**
* 启动所有线程
*/
protected void startUpAllThreads(List<Thread> tList) {
for (Thread t : tList) {
t.start();
// 这里需要加一点延迟,保证请求按顺序发出去
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
protected synchronized void addCost(long cost) {
EVERY_REQ_COST.append(cost);
EVERY_REQ_COST.append("ms");
EVERY_REQ_COST.append(SEPERATOR);
}
}
接着看一下测试代码:
/**
* 不使用连接池测试
*
* @author 五月的仓颉https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class HttpClientWithoutPoolTest extends BaseHttpClientTest {
@Test
public void test() throws Exception {
startUpAllThreads(getRunThreads(new HttpThread()));
// 等待线程运行
for (;;);
}
private class HttpThread implements Runnable {
@Override
public void run() {
/**
* HttpClient是线程安全的,因此HttpClient正常使用应当做成全局变量,但是一旦全局共用一个,HttpClient内部构建的时候会new一个连接池
* 出来,这样就体现不出使用连接池的效果,因此这里每次new一个HttpClient,保证每次都不通过连接池请求对端
*/
CloseableHttpClient httpClient = HttpClients.custom().build();
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
long startTime = System.currentTimeMillis();
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response != null) {
response.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
addCost(System.currentTimeMillis() - startTime);
if (NOW_COUNT.incrementAndGet() == REQUEST_COUNT) {
System.out.println(EVERY_REQ_COST.toString());
}
}
}
}
}
注意这里如注释所说,HttpClient是线程安全的,但是一旦做成全局的就失去了测试效果,因为HttpClient在初始化的时候默认会new一个连接池出来。
看一下代码运行效果:
324ms 324ms 220ms 324ms 324ms
每个请求几乎都是独立的,所以执行时间都在200ms以上,接着我们看一下使用连接池的效果。
使用连接池的运行结果
BaseHttpClientTest这个类保持不变,写一个使用连接池的测试类:
/**
* 使用连接池测试
*
* @author 五月的仓颉https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class HttpclientWithPoolTest extends BaseHttpClientTest {
private CloseableHttpClient httpClient = null;
@Before
public void before() {
initHttpClient();
}
@Test
public void test() throws Exception {
startUpAllThreads(getRunThreads(new HttpThread()));
// 等待线程运行
for (;;);
}
private class HttpThread implements Runnable {
@Override
public void run() {
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
// 长连接标识,不加也没事,HTTP1.1默认都是Connection: keep-alive的
httpGet.addHeader("Connection", "keep-alive");
long startTime = System.currentTimeMillis();
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response != null) {
response.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
addCost(System.currentTimeMillis() - startTime);
if (NOW_COUNT.incrementAndGet() == REQUEST_COUNT) {
System.out.println(EVERY_REQ_COST.toString());
}
}
}
}
private void initHttpClient() {
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager();
// 总连接池数量
connectionManager.setMaxTotal(1);
// 可为每个域名设置单独的连接池数量
connectionManager.setMaxPerRoute(new HttpRoute(new HttpHost("www.baidu.com")), 1);
// setConnectTimeout表示设置建立连接的超时时间
// setConnectionRequestTimeout表示从连接池中拿连接的等待超时时间
// setSocketTimeout表示发出请求后等待对端应答的超时时间
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(1000).setConnectionRequestTimeout(2000)
.setSocketTimeout(3000).build();
// 重试处理器,StandardHttpRequestRetryHandler这个是官方提供的,看了下感觉比较挫,很多错误不能重试,可自己实现HttpRequestRetryHandler接口去做
HttpRequestRetryHandler retryHandler = new StandardHttpRequestRetryHandler();
httpClient = HttpClients.custom().setConnectionManager(connectionManager).setDefaultRequestConfig(requestConfig)
.setRetryHandler(retryHandler).build();
// 服务端假设关闭了连接,对客户端是不透明的,HttpClient为了缓解这一问题,在某个连接使用前会检测这个连接是否过时,如果过时则连接失效,但是这种做法会为每个请求
// 增加一定额外开销,因此有一个定时任务专门回收长时间不活动而被判定为失效的连接,可以某种程度上解决这个问题
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
try {
// 关闭失效连接并从连接池中移除
connectionManager.closeExpiredConnections();
// 关闭30秒钟内不活动的连接并从连接池中移除,空闲时间从交还给连接管理器时开始
connectionManager.closeIdleConnections(20, TimeUnit.SECONDS);
} catch (Throwable t) {
t.printStackTrace();
}
}
}, 0 , 1000 * 5);
}
}
这个类详细地演示了HttpClient的用法,相关注意点都写了注释,就不讲了。
和上面一样,看一下代码执行效果:
309ms 83ms 57ms 53ms 46ms
看到除开第一次调用的309ms以外,后续四次调用整体执行时间大大提升,这就是使用了连接池的好处,接着,就探究一下使用连接池提升整体性能的原因。
绕不开的长短连接
说起HTTP,必然绕不开的一个话题就是长短连接,这个话题之前的文章已经写了好多次了,这里再写一次。
我们知道,从客户端发起一个HTTP请求到服务端响应HTTP请求之间,大致有以下几个步骤:

HTTP1.0最早在网页中使用是1996年,那个时候只是使用一些较为简单的网页和网络的请求,每次请求都需要建立一个单独的连接,上一次和下一次请求完全分离。这种做法,即使每次的请求量都很小,但是客户端和服务端每次建立TCP连接和关闭TCP连接都是相对比较费时的过程,严重影响客户端和服务端的性能。
基于以上的问题,HTTP1.1在1999年广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议(2015年诞生了HTTP2,但是还未大规模应用),这里不详细对比HTTP1.1针对HTTP1.0改进了什么,只是在连接这块,HTTP1.1支持在一个TCP连接上传送多个HTTP请求和响应,减少了建立和关闭连接的消耗延迟,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点,这就是长连接,HTTP1.1默认使用长连接。
那么,长连接是如何工作的呢?首先,我们要明确一下,长短连接是通信层(TCP)的概念,HTTP是应用层协议,它只能说告诉通信层我打算一段时间内复用TCP通道而没有自己去建立、释放TCP通道的能力。那么HTTP是如何告诉通信层复用TCP通道的呢?看下图:

分为以下几个步骤:
- 客户端发送一个Connection: keep-alive的header,表示需要保持连接
- 客户端可以顺带Keep-Alive: timeout=5,max=100这个header给服务端,表示tcp连接最多保持5秒,长连接接受100次请求就断开,不过浏览器看了一些请求貌似没看到带这个参数的
- 服务端必须能识别Connection: keep-alive这个header,并且通过Response Header带同样的Connection: keep-alive,告诉客户端我可以保持连接
- 客户端和服务端之间通过保持的通道收发数据
- 最后一次请求数据,客户端带Connection:close这个header,表示连接关闭
至此在一个通道上交换数据的过程结束,在默认的情况下:
- 长连接的请求数量限定是最多连续发送100个请求,超过限制即关闭这条连接
- 长连接连续两个请求之间的超时时间是15秒(存在1~2秒误差),超时后会关闭TCP连接,因此使用长连接应当尽量保持在13秒之内发送一个请求
这些的限制都是在重用长连接与长连接过多之间做的一个折衷,因为长连接虽好,但是长时间的TCP连接容易导致系统资源无效占用,浪费系统资源。
最后这个地方多说一句http的keep-alive和tcp的keep-alive的区别,一个经常讲的问题,顺便记录一下:
- http的keep-alive是为了复用已有连接
- tcp的keep-alive是为了保活,即保证对端还存活,不然对端已经不在了我这边还占着和对端的这个连接,浪费服务器资源,做法是隔一段时间发送一个心跳包到对端服务器,一旦长时间没有接收到应答,就主动关闭连接
性能提升的原因
通过前面的分析,很显而易见的,使用HTTP连接池提升性能最重要的原因就是省去了大量连接建立与释放的时间,除此之外还想说一点。
TCP建立连接的时候有如下流程:

如图所示,这里面有两个队列,分别为syns queue(半连接队列)与accept queue(全连接队列),这里面的流程就不细讲了,之前我有文章https://www.cnblogs.com/xrq730/p/6910719.html专门写过这个话题。
一旦不使用长连接而每次连接都重新握手的话,队列一满服务端将会发送一个ECONNREFUSED错误信息给到客户端,相当于这次请求就失效了,即使不失效,后来的请求需要等待前面的请求处理,排队也会增加响应的时间。
By the way,基于上面的分析,不仅仅是HTTP,所有应用层协议,例如数据库有数据库连接池、hsf提供了hsf接口连接池,使用连接池的方式对于接口性能都是有非常大的提升的,都是同一个道理。
TLS层的优化
上面讲的都是针对应用层协议使用连接池提升性能的原因,但是对于HTTP请求,我们知道目前大多数网站都运行在HTTPS协议之上,即在通信层和应用层之间多了一层TLS:

通过TLS层对报文进行了加密,保证数据安全,其实在HTTPS这个层面上,使用连接池对性能有提升,TLS层的优化也是一个非常重要的原因。
HTTPS原理不细讲了,反正大致上就是一个证书交换-->服务端加密-->客户端解密的过程,整个过程中反复地客户端+服务端交换数据是一个耗时的过程,且数据的加解密是一个计算密集型的操作消耗CPU资源,因此如果相同的请求能省去加解密这一套就能在HTTPS协议下对整个性能有很大提升了,实际上这种优化是有的,这里用到了一种会话复用的技术。
TLS的握手由客户端发送Client Hello消息开始,服务端返回Server Hello结束,整个流程中提供了2种不同的会话复用机制,这个地方就简单看一下,知道有这么一回事:
- session id会话复用----对于已建立的TLS会话,使用session id为key(来自第一次请求的Server Hello中的session id),主密钥为value组成一对键值对保存在服务端和客户端的本地。当第二次握手时,客户端如果想复用会话,则发起的Client Hello中带上session id,服务端收到这个session id检查本地是否存在,有则允许会话复用,进行后续操作
- session ticket会话复用----一个session ticket是一个加密的数据blob,其中包含需要重用的TLS连接信息如session key等,它一般使用ticket key加密,因为ticket key服务端也知道,在初始化握手中服务端发送一个session ticket到客户端并存储到客户端本地,当会话重用时,客户端发送session ticket到服务端,服务端解密成功即可复用会话
session id的方式缺点是比较明显的,主要原因是负载均衡中,多机之间不同步session,如果两次请求不落在同一台机器上就无法找到匹配信息,另外服务端存储大量的session id又需要消耗很多资源,而session ticket是比较好解决这个问题的,但是最终使用的是哪种方式还是有浏览器决定。关于session ticket,在网上找了一张图,展示的是客户端第二次发起请求,携带session ticket的过程:

一个session ticket超时时间默认为300s,TLS层的证书交换+非对称加密作为性能消耗大户,通过会话复用技术可以大大提升性能。
使用连接池的注意点
使用连接池,切记每个任务的执行时间不要太长。
因为HTTP请求也好、数据库请求也好、hsf请求也好都是有超时时间的,比如连接池中有10个线程,并发来了100个请求,一旦任务执行时间非常长,连接都被先来的10个任务占着,后面90个请求迟迟得不到连接去处理,就会导致这次的请求响应慢甚至超时。
当然每个任务的业务不一样,但是按照我的经验,尽量把任务的执行时间控制在50ms最多100ms之内,如果超出的,可以考虑以下三种方案:
- 优化任务执行逻辑,比如引入缓存
- 适当增大连接池中的连接数量
- 任务拆分,将任务拆分为若干小任务
连接池中的连接数量如何设置
有些朋友可能会问,我知道需要使用连接池,那么一般连接池数量设置为多少比较合适?有没有经验值呢?首先我们需要明确一个点,连接池中的连接数量太多不好、太少也不好:
- 比如qps=100,因为上游请求速率不可能是恒定不变的100个请求/秒,可能前1秒900个请求,后9秒100个请求,平均下来qps=100,当连接数太多的时候,可能出现的场景是高流量下建立连接--->低流量下释放部分连接--->高流量下重新建立连接的情况,相当于虽然使用了连接池,但是因为流量不均匀反复建立连接、释放链接
- 线程数太少当然也是不好的,任务多而连接少,导致很多任务一直在排队等待前面的执行完才可以拿到连接去处理,降低了处理速度
那针对连接池中的连接数量如何设置的这个问题,答案是没有固定的,但是可以通过估算得到一个预估值。
首先开发同学对于一个任务每天的调用量心中需要有数,假设一天1000W次好了,线上有10台服务器,那么平均到每台服务器每天的调用量在100W,100W平均到1天的86400秒,每秒的调用量1000000 / 86400 ≈ 11.574次,根据接口的一个平均响应时长适当加一点余量,差不多设置在15~30比较合适,根据线上运行的实际情况再做调整。
TCP:三次握手、四次握手、backlog及其他
TCP是什么
首先看一下OSI七层模型:
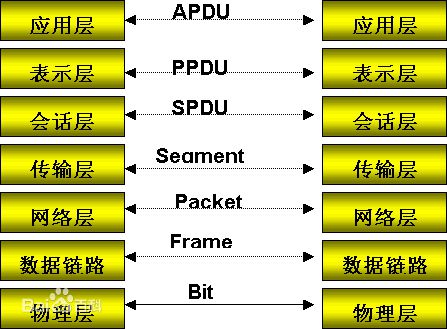
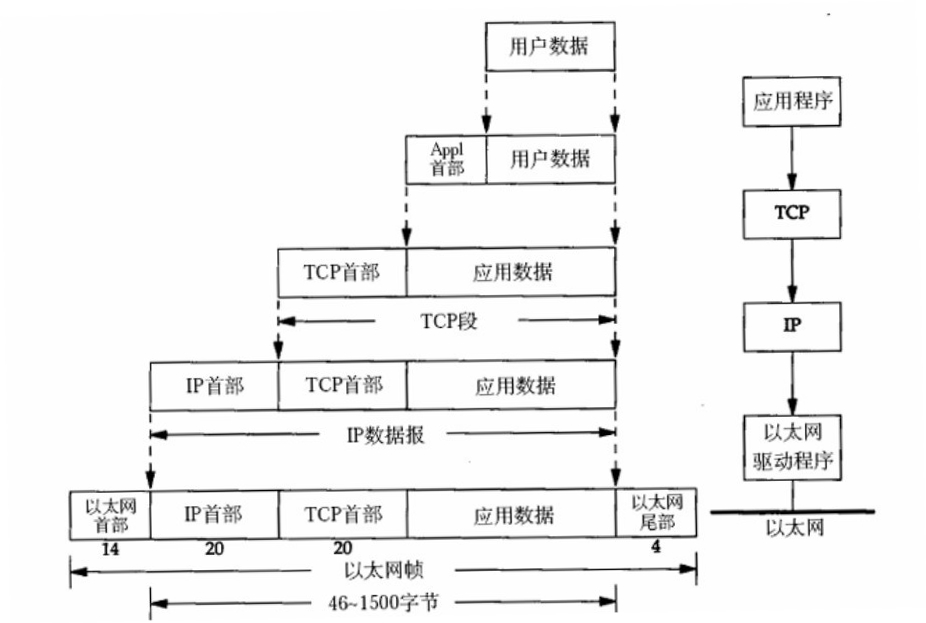
然后数据从应用层发下来,会在每一层都加上头部信息进行封装,然后再发送到数据接收端,这个基本的流程中每个数据都会经过数据的封装和解封的过程,流程如下图所示:
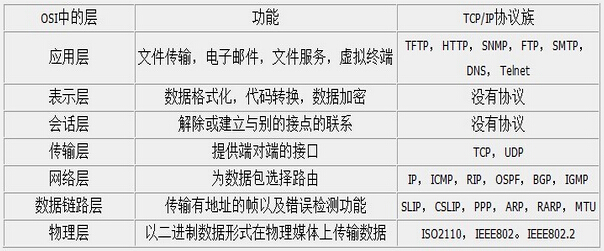
在OSI七层模型中,每一层的作用和对应的协议如下图所示:
说回TCP,简单说TCP(Transmission Control Protocol)即传输控制协议,是一种面向连接的、可靠的、基于ip的传输层协议。
TCP协议头部格式
要学习TCP协议,首先得知道TCP协议头部的格式,我在网上找了一张觉得画得比较好的TCP协议头部格式的图片:
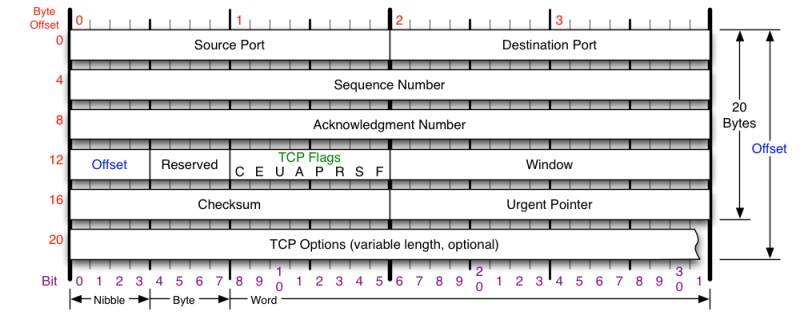
这张图把TCP协议头部格式的每部分都描述得比较清楚:
- Source Port与Destination Port表示源端口与目标端口,各占据2个字节
- Sequence Number表示顺序号,占4个字节,每一个字节都有一个序号,连接建立时发送方将初始序号填写到第一个发送的TCP段序号中
- Acknowledgment Number表示应答号,占4个字节,是期望收到对方下次发送的数据的第一个字节的序号,也就是期望收到的下一个报文段的首部中的序号
- Offset表示数据偏移量,占4位,表示数据开始的地方离TCP段的起始处有多远,实际上就是TCP段首部的长度
- Reserved表示保留位,占4位,全为0,为了将来定义新的用途保留
- C表示CWR,占1位,拥塞窗口减少标识,发送方设置,用于表明它收到了ECE标识的TCP包,发送端通过降低发送窗口的大小来降低速率
- E表示ECN,占1位,用于TCP3次握手时表示一个TCP端是具备ECN功能的
- U表示URG,占1位,该标志位表示紧急标识有效
- A表示ACK,占1位,表示Acknowledgment Number字段有效,这是一个确认的TCP包,0表示不是确认包
- P表示PSH,占1位,该标志位设置时一般表示发送端缓存中已经没有待发送的数据,接收端不将该数据进行队列处理
- R表示RST,占1位,用于复位相应的TCP链接
- S表示SYN,占1位,该标志仅在三次握手建立TCP连接时有效
- F表示FIN,占1位,带有该标志位的数据包用来结束一个TCP会话,但对应端口仍处于开放状态,准备接收后续数据
- Window表示窗口,占2个字节,表示报文段发送方期望收到的字节数,换句话说用于表示接收端还有多少空间剩余,用于控制TCP流量
- Checksum表示校验和,占2个字节,发送端基于数据内容计算一个数值,接收端要与发送端数值结果完全一样,才能证明数据的有效性,接收端校验失败会直接丢掉这个数据包
- Urgent Pointer表示紧急指针,占2个字节,指向后面优先数据的字节,只有在URG标识设置了才有效
- TCP Options表示TCP选项,长度不定,但必须是32bits的整数倍,常见的选项包括MSS、SACK、Timestamp等
从图上我们可以看到,TCP头部的固定大小为20个字节,不过由于有可选字段,实际上TCP头部的大小有可能超过20字节。
TCP三次握手
TCP三次握手是TCP一个比较重点的内容,来学习一下。
TCP三次握手其实就是TCP连接建立的过程,三次握手的目的是同步连接双方的序列号和确认号并交换TCP窗口大小信息。下面是TCP三次握手的流程图:
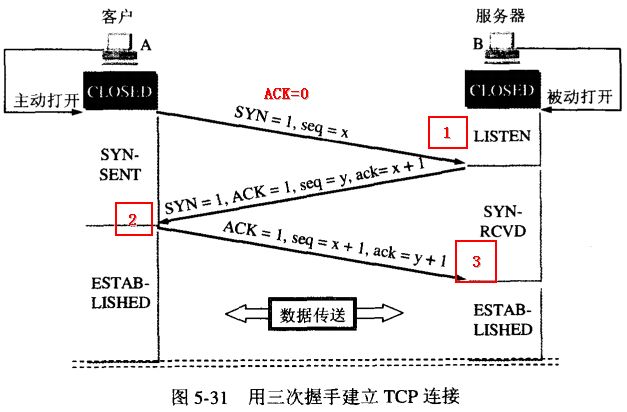
画得很清晰,可惜不是我画的。整个流程为:
- 客户端主动打开,发送连接请求报文段,将SYN标识位置为1,Sequence Number置为x(TCP规定SYN=1时不能携带数据,x为随机产生的一个值),然后进入SYN_SEND状态
- 服务器收到SYN报文段进行确认,将SYN标识位置为1,ACK置为1,Sequence Number置为y,Acknowledgment Number置为x+1,然后进入SYN_RECV状态,这个状态被称为半连接状态
- 客户端再进行一次确认,将ACK置为1(此时不用SYN),Sequence Number置为x+1,Acknowledgment Number置为y+1发向服务器,最后客户端与服务器都进入ESTABLISHED状态
为什么在第3步中客户端还要再进行一次确认呢?这主要是为了防止已经失效的连接请求报文段突然又传回到服务端而产生错误的场景:
所谓"已失效的连接请求报文段"是这样产生的。正常来说,客户端发出连接请求,但因为连接请求报文丢失而未收到确认。于是客户端再次发出一次连接请求,后来收到了确认,建立了连接。数据传输完毕后,释放了连接,客户端一共发送了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,没有"已失效的连接请求报文段"。
现在假定一种异常情况,即客户端发出的第一个连接请求报文段并没有丢失,只是在某些网络节点长时间滞留了,以至于延误到连接释放以后的某个时间点才到达服务端。本来这个连接请求已经失效了,但是服务端收到此失效的连接请求报文段后,就误认为这是客户端又发出了一次新的连接请求。于是服务端又向客户端发出请求报文段,同意建立连接。假定不采用三次握手,那么只要服务端发出确认,连接就建立了。
由于现在客户端并没有发出连接建立的请求,因此不会理会服务端的确认,也不会向服务端发送数据,但是服务端却以为新的传输连接已经建立了,并一直等待客户端发来数据,这样服务端的许多资源就这样白白浪费了。
采用三次握手的办法可以防止上述现象的发生。比如在上述的场景下,客户端不向服务端的发出确认请求,服务端由于收不到确认,就知道客户端并没有要求建立连接。
TCP四次握手
TCP三次握手是TCP连接建立的过程,TCP四次握手则是TCP连接释放的过程。下面是TCP四次握手的流程图:
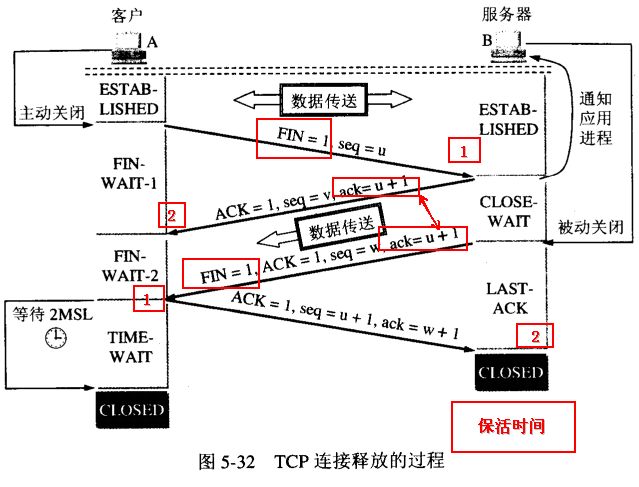
当客户端没有数据再需要发送给服务端时,就需要释放客户端的连接,这整个过程为:
- 客户端发送一个报文给服务端(没有数据),其中FIN设置为1,Sequence Number置为u,客户端进入FIN_WAIT_1状态
- 服务端收到来自客户端的请求,发送一个ACK给客户端,Acknowledge置为u+1,同时发送Sequence Number为v,服务端年进入CLOSE_WAIT状态
- 服务端发送一个FIN给客户端,ACK置为1,Sequence置为w,Acknowledge置为u+1,用来关闭服务端到客户端的数据传送,服务端进入LAST_ACK状态
- 客户端收到FIN后,进入TIME_WAIT状态,接着发送一个ACK给服务端,Acknowledge置为w+1,Sequence Number置为u+1,最后客户端和服务端都进入CLOSED状态
这里的一个问题是,为什么TCP连接的建立只需要三次握手而TCP连接的释放需要四次握手呢:
因为服务端在LISTEN状态下,收到建立请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而连接关闭时,当收到对方的FIN报文时,仅仅表示对方没有需要发送的数据了,但是还能接收数据,己方未必数据已经全部发送给对方了,所以己方可以立即关闭,也可以将应该发送的数据全部发送完毕后再发送FIN报文给客户端来表示同意现在关闭连接。
从这个角度而言,服务端的ACK和FIN一般都会分开发送。
使用Wireshark抓包验证TCP三次握手过程
为了加深对TCP三次握手的理解,抓包看一下TCP三次握手的过程。我这里访问的是我们公司自己的网站,不打广告,访问的具体什么页面、哪个ip就不透露了。
抓包下来的内容为:

这里多说一句,由于wireshark抓包针对的是网卡,因此只要某张网卡上有网络访问,就会有数据包,这会导致Wireshark的抓包结果里面会有大量数据包,而大多数都不是想要的,这种情况可以使用Wireshark的过滤规则。我这里由于知道目标ip,因此使用的是"ip.src == xxx.xxx.xxx.xxx or ip.dst == xxx.xxx.xxx.xxx"这条规则只过滤特定的ip。
从抓包结果看来,整个过程符合TCP三次握手的预期:
- 客户端发送SYN给服务端
- 服务端返回SYN+ACK给客户端
- 客户端确认,返回ACK给服务端
至于Sequence Number和Acknowledge Number就不看了,但是注意,前面说了Sequence Number是随机产生的一个值,但是这里确是0,不光这里是0,抓其他的任何包这个值都是0。但其实这里并不是真的0,而是Wireshark为了显示更好阅读,使用了relative sequence number相对序号,Sequence Number具体值我们也是可以看到的:
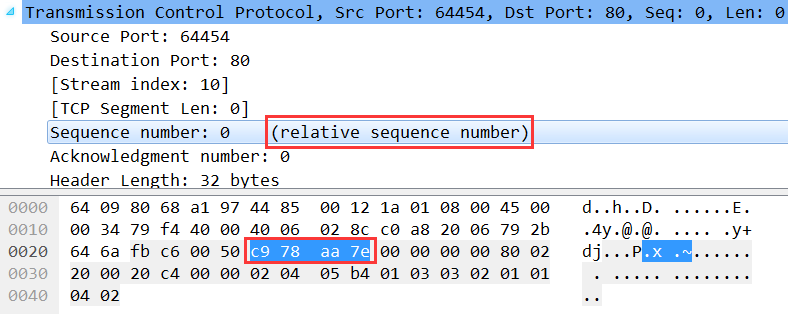
第一个红框就是上面说的relative sequence number,第二个红框就是Sequence Number的真实值0xc978aa7e,转换为十进制为3380128382,就是随机产生的Sequence Number。
顺便能看到,下一个数据包就是HTTP的数据包,因为TCP三次握手已完成,连接建立,正式传输应用层数据,传输的HTTP内容大小为704字节。
TCP的backlog
在学习TCP的时候发现的一个比较重要的知识点。
在TCP连接建立的过程中有如下的流程和队列:
如图所示,这里面有两个队列,分别为syns queue(半连接队列)与accept queue(全连接队列)。整个流程总结用文字如下:
- 服务端绑定某个端口并监听
- 客户端发送SYN给服务端发起第一次握手,此时服务端将此请求信息放在半连接队列中并回复SYN + ACK给客户端
- 客户端收到SYN+ACK,发起应答,回复一个ACK给服务端,假设此时全连接队列未满,那么从半连接队列中拿出此请求信息放入全连接队列中。如果全连接队列满了,那么客户端继续向服务端发送ACK,服务端的处理方式和系统参数tcp_abort_on_overflow有关,Linux环境下可以通过执行"cat /proc/sys/net/ipv4/tcp_abort_on_overflow"来查看此参数:
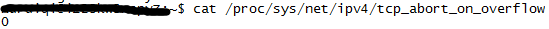
- 0表示字节丢弃该ACK
- 1表示发送一个RST给客户端,直接废掉这个握手过程与连接
- 服务端accept处理此请求,从全连接队列中将此请求信息拿出
backlog的定义是已连接但未进行accept处理的socket队列大小,如果这个队列满了,将会发送一个ECONNREFUSED错误信息给到客户端,即 linux 头文件 /usr/include/asm-generic/errno.h中定义的“Connection refused”。
Java支持原生的Socket,我们可以写一段代码来验证一下。首先是一个普通的客户端Socket,模拟向本地的8888端口发起连接:
1 public class ClientSocketClass {
2
3 private static Socket[] clients = new Socket[30];
4
5 public static void main(String[] args) throws Exception {
6 for (int i = 0; i < 10; i++) {
7 clients[i] = new Socket("127.0.0.1", 8888);
8 System.out.println("Client:" + i);
9 }
10 }
11
12 }
接着是服务端Socket,监听8888端口,ServerSocket构造函数的第二个参数就是backlog的大小,如果backlog小于1或者不传会给一个默认值50,代码很简单:
1 public class ServerSocketClass {
2
3 public static void main(String[] args) throws Exception {
4 ServerSocket server = new ServerSocket(8888, 5);
5
6 while (true) {
7 // server.accept();
8 }
9 }
10
11 }
先把注释关闭,运行ServerSocketClass,先发起监听,再运行ClientSocketClass,运行结果为:
1 Client:0
2 Client:1
3 Client:2
4 Client:3
5 Client:4
6 Exception in thread "main" java.net.ConnectException: Connection refused: connect
7 at java.net.DualStackPlainSocketImpl.connect0(Native Method)
8 at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:79)
9 at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
10 at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
11 at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
12 at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
13 at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
14 at java.net.Socket.connect(Socket.java:579)
15 at java.net.Socket.connect(Socket.java:528)
16 at java.net.Socket.<init>(Socket.java:425)
17 at java.net.Socket.<init>(Socket.java:208)
18 at org.xrq.test.socket.ClientSocketClass.main(ClientSocketClass.java:11)
看到Client只发起了五个请求,第六个请求发起被拒绝了,因为三次握手建立后,前五个请求占据了全连接队列并没有被处理,于是第六个请求进来,全连接队列中没有它的位置了,因此请求被拒绝。
如果注释打开,又是不一样的效果:
1 Client:0
2 Client:1
3 Client:2
4 Client:3
5 Client:4
6 Client:5
7 Client:6
8 Client:7
9 Client:8
10 Client:9
这里所有的十个客户端请求全部被接受,因为accept()方法从全连接队列中取出了连接请求进行处理。看得出来,backlog提供了容量限制功能,避免过多的客户端Socket占据大量的服务端资源。
全连接队列大小的问题
接着说说全连接队列大小的问题。首先上面提到了backlog,不同的应用对backlog的默认值定义不同,比如:
- Java的Socket默认backlog为50
- Tomcat默认的backlog为100
- 阿里改造的Ali-Tomcat默认的backlog为200
- Nginx默认的backlog为511
Tomcat可以通过server.xml配置文件中<Connector />节点中的acceptCount来修改backlog。如果请求量不是很大,使用Tomcat默认的100也可以,但如果访问量比较大,建议这个值设置得大一些,比如1024或者更大。如果Tomcat前一层对SYC FLOOD攻击的防御没有把握的话,最好将SYN COOKIE防御也开启。
但是,全连接队列的大小未必是backlog的值,它是backlog与somaxconn(一个os级别的系统参数)的较小值。Linux环境下可以通过执行"cat /proc/sys/net/core/somaxconn"来查看:

这个值系统默认的是128,假如传入的backlog是10,取128和10的较小值,那么最终的全连接队列大小就是10。同样,如果要修改Linux系统默认的全连接队列大小的话,可以通过修改/proc/sys/net/core路径下的somaxconn。
半连接队列大小的问题
说完了全连接队列大小的问题,接着说一下半连接队列大小的问题,它是64与tcp_max_syn_backlog的较大值。
可以通过"cat /proc/sys/net/ipv4/tcp_max_syn_backlog"命令或者"cat /etc/sysctl.conf"命令来查看半连接队列的大小。以后者为例,其实就是打开了/ect/sysctl.conf这个文件:
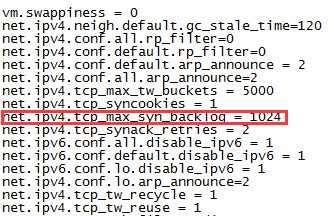
标红的即tcp_max_syn_backlog默认值,默认值为1024,可以通过修改这个值来修改系统默认的半连接队列大小。
通过ss查看Socket统计状态
前面说了这么多全连接队列,那么如何查看全连接队列大小?
在Linux环境下可以通过ss命令查看,ss命令全称为Socket Statistics,顾名思义它用于统计Socket。netstat命令其实也可以显示类似内容,但是ss命令相比netstat命令能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
ss命令的参数就不列举了,可以自己上网查看,这里使用ss -lnt,即查看处于LISTEN状态的TCP套接字,且不解析服务名称:

Send-Q表示当前端口的全连接队列大小,Recv-Q表示全连接队列当前使用了多少。
从Send-Q可以看到,它的值只有三种:128、50、1。这也印证了我们的结论,全连接队列的大小为传入的backlog与somaxconn的较小值。
Http持久连接与HttpClient连接池
一、背景
HTTP协议是无状态的协议,即每一次请求都是互相独立的。因此它的最初实现是,每一个http请求都会打开一个tcp socket连接,当交互完毕后会关闭这个连接。
HTTP协议是全双工的协议,所以建立连接与断开连接是要经过三次握手与四次挥手的。显然在这种设计中,每次发送Http请求都会消耗很多的额外资源,即连接的建立与销毁。
于是,HTTP协议的也进行了发展,通过持久连接的方法来进行socket连接复用。
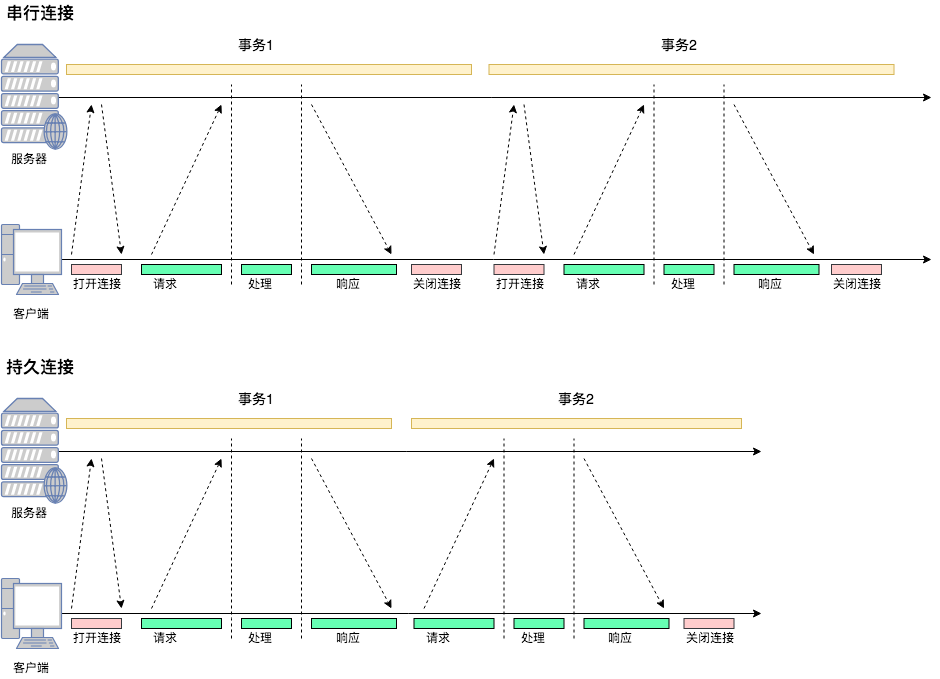
从图中可以看到:
- 在串行连接中,每次交互都要打开关闭连接
- 在持久连接中,第一次交互会打开连接,交互结束后连接并不关闭,下次交互就省去了建立连接的过程。
持久连接的实现有两种:HTTP/1.0+的keep-alive与HTTP/1.1的持久连接。
二、HTTP/1.0+的Keep-Alive
从1996年开始,很多HTTP/1.0浏览器与服务器都对协议进行了扩展,那就是“keep-alive”扩展协议。
注意,这个扩展协议是作为1.0的补充的“实验型持久连接”出现的。keep-alive已经不再使用了,最新的HTTP/1.1规范中也没有对它进行说明,只是很多应用延续了下来。
使用HTTP/1.0的客户端在首部中加上"Connection:Keep-Alive",请求服务端将一条连接保持在打开状态。服务端如果愿意将这条连接保持在打开状态,就会在响应中包含同样的首部。如果响应中没有包含"Connection:Keep-Alive"首部,则客户端会认为服务端不支持keep-alive,会在发送完响应报文之后关闭掉当前连接。
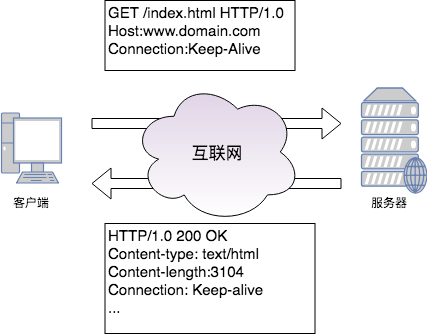
通过keep-alive补充协议,客户端与服务器之间完成了持久连接,然而仍然存在着一些问题:
- 在HTTP/1.0中keep-alive不是标准协议,客户端必须发送Connection:Keep-Alive来激活keep-alive连接。
- 代理服务器可能无法支持keep-alive,因为一些代理是"盲中继",无法理解首部的含义,只是将首部逐跳转发。所以可能造成客户端与服务端都保持了连接,但是代理不接受该连接上的数据。
三、HTTP/1.1的持久连接
HTTP/1.1采取持久连接的方式替代了Keep-Alive。
HTTP/1.1的连接默认情况下都是持久连接。如果要显式关闭,需要在报文中加上Connection:Close首部。即在HTTP/1.1中,所有的连接都进行了复用。
然而如同Keep-Alive一样,空闲的持久连接也可以随时被客户端与服务端关闭。不发送Connection:Close不意味着服务器承诺连接永远保持打开。
四、HttpClient如何生成持久连接
HttpClien中使用了连接池来管理持有连接,同一条TCP链路上,连接是可以复用的。HttpClient通过连接池的方式进行连接持久化。
其实“池”技术是一种通用的设计,其设计思想并不复杂:
- 当有连接第一次使用的时候建立连接
- 结束时对应连接不关闭,归还到池中
- 下次同个目的的连接可从池中获取一个可用连接
- 定期清理过期连接
所有的连接池都是这个思路,不过我们看HttpClient源码主要关注两点:
- 连接池的具体设计方案,以供以后自定义连接池参考
- 如何与HTTP协议对应上,即理论抽象转为代码的实现
4.1 HttpClient连接池的实现
HttpClient关于持久连接的处理在下面的代码中可以集中体现,下面从MainClientExec摘取了和连接池相关的部分,去掉了其他部分:
public class MainClientExec implements ClientExecChain {
@Override
public CloseableHttpResponse execute(
final HttpRoute route,
final HttpRequestWrapper request,
final HttpClientContext context,
final HttpExecutionAware execAware) throws IOException, HttpException {
//从连接管理器HttpClientConnectionManager中获取一个连接请求ConnectionRequest
final ConnectionRequest connRequest = connManager.requestConnection(route, userToken);final HttpClientConnection managedConn;
final int timeout = config.getConnectionRequestTimeout();
//从连接请求ConnectionRequest中获取一个被管理的连接HttpClientConnection
managedConn = connRequest.get(timeout > 0 ? timeout : 0, TimeUnit.MILLISECONDS);
//将连接管理器HttpClientConnectionManager与被管理的连接HttpClientConnection交给一个ConnectionHolder持有
final ConnectionHolder connHolder = new ConnectionHolder(this.log, this.connManager, managedConn);
try {
HttpResponse response;
if (!managedConn.isOpen()) {
//如果当前被管理的连接不是出于打开状态,需要重新建立连接
establishRoute(proxyAuthState, managedConn, route, request, context);
}
//通过连接HttpClientConnection发送请求
response = requestExecutor.execute(request, managedConn, context);
//通过连接重用策略判断是否连接可重用
if (reuseStrategy.keepAlive(response, context)) {
//获得连接有效期
final long duration = keepAliveStrategy.getKeepAliveDuration(response, context);
//设置连接有效期
connHolder.setValidFor(duration, TimeUnit.MILLISECONDS);
//将当前连接标记为可重用状态
connHolder.markReusable();
} else {
connHolder.markNonReusable();
}
}
final HttpEntity entity = response.getEntity();
if (entity == null || !entity.isStreaming()) {
//将当前连接释放到池中,供下次调用
connHolder.releaseConnection();
return new HttpResponseProxy(response, null);
} else {
return new HttpResponseProxy(response, connHolder);
}
}
这里看到了在Http请求过程中对连接的处理是和协议规范是一致的,这里要展开讲一下具体实现。
PoolingHttpClientConnectionManager是HttpClient默认的连接管理器,首先通过requestConnection()获得一个连接的请求,注意这里不是连接。
public ConnectionRequest requestConnection(
final HttpRoute route,
final Object state) {final Future<CPoolEntry> future = this.pool.lease(route, state, null);
return new ConnectionRequest() {
@Override
public boolean cancel() {
return future.cancel(true);
}
@Override
public HttpClientConnection get(
final long timeout,
final TimeUnit tunit) throws InterruptedException, ExecutionException, ConnectionPoolTimeoutException {
final HttpClientConnection conn = leaseConnection(future, timeout, tunit);
if (conn.isOpen()) {
final HttpHost host;
if (route.getProxyHost() != null) {
host = route.getProxyHost();
} else {
host = route.getTargetHost();
}
final SocketConfig socketConfig = resolveSocketConfig(host);
conn.setSocketTimeout(socketConfig.getSoTimeout());
}
return conn;
}
};
}
可以看到返回的ConnectionRequest对象实际上是一个持有了Future<CPoolEntry>,CPoolEntry是被连接池管理的真正连接实例。
从上面的代码我们应该关注的是:
- Future<CPoolEntry> future = this.pool.lease(route, state, null)
- 如何从连接池CPool中获得一个异步的连接,Future<CPoolEntry>
- HttpClientConnection conn = leaseConnection(future, timeout, tunit)
- 如何通过异步连接Future<CPoolEntry>获得一个真正的连接HttpClientConnection
4.2 Future<CPoolEntry>
看一下CPool是如何释放一个Future<CPoolEntry>的,AbstractConnPool核心代码如下:
private E getPoolEntryBlocking(
final T route, final Object state,
final long timeout, final TimeUnit tunit,
final Future<E> future) throws IOException, InterruptedException, TimeoutException {
//首先对当前连接池加锁,当前锁是可重入锁ReentrantLockthis.lock.lock();
try {
//获得一个当前HttpRoute对应的连接池,对于HttpClient的连接池而言,总池有个大小,每个route对应的连接也是个池,所以是“池中池”
final RouteSpecificPool<T, C, E> pool = getPool(route);
E entry;
for (;;) {
Asserts.check(!this.isShutDown, "Connection pool shut down");
//死循环获得连接
for (;;) {
//从route对应的池中拿连接,可能是null,也可能是有效连接
entry = pool.getFree(state);
//如果拿到null,就退出循环
if (entry == null) {
break;
}
//如果拿到过期连接或者已关闭连接,就释放资源,继续循环获取
if (entry.isExpired(System.currentTimeMillis())) {
entry.close();
}
if (entry.isClosed()) {
this.available.remove(entry);
pool.free(entry, false);
} else {
//如果拿到有效连接就退出循环
break;
}
}
//拿到有效连接就退出
if (entry != null) {
this.available.remove(entry);
this.leased.add(entry);
onReuse(entry);
return entry;
}
//到这里证明没有拿到有效连接,需要自己生成一个
final int maxPerRoute = getMax(route);
//每个route对应的连接最大数量是可配置的,如果超过了,就需要通过LRU清理掉一些连接
final int excess = Math.max(0, pool.getAllocatedCount() + 1 - maxPerRoute);
if (excess > 0) {
for (int i = 0; i < excess; i++) {
final E lastUsed = pool.getLastUsed();
if (lastUsed == null) {
break;
}
lastUsed.close();
this.available.remove(lastUsed);
pool.remove(lastUsed);
}
}
//当前route池中的连接数,没有达到上线
if (pool.getAllocatedCount() < maxPerRoute) {
final int totalUsed = this.leased.size();
final int freeCapacity = Math.max(this.maxTotal - totalUsed, 0);
//判断连接池是否超过上线,如果超过了,需要通过LRU清理掉一些连接
if (freeCapacity > 0) {
final int totalAvailable = this.available.size();
//如果空闲连接数已经大于剩余可用空间,则需要清理下空闲连接
if (totalAvailable > freeCapacity - 1) {
if (!this.available.isEmpty()) {
final E lastUsed = this.available.removeLast();
lastUsed.close();
final RouteSpecificPool<T, C, E> otherpool = getPool(lastUsed.getRoute());
otherpool.remove(lastUsed);
}
}
//根据route建立一个连接
final C conn = this.connFactory.create(route);
//将这个连接放入route对应的“小池”中
entry = pool.add(conn);
//将这个连接放入“大池”中
this.leased.add(entry);
return entry;
}
}
//到这里证明没有从获得route池中获得有效连接,并且想要自己建立连接时当前route连接池已经到达最大值,即已经有连接在使用,但是对当前线程不可用
boolean success = false;
try {
if (future.isCancelled()) {
throw new InterruptedException("Operation interrupted");
}
//将future放入route池中等待
pool.queue(future);
//将future放入大连接池中等待
this.pending.add(future);
//如果等待到了信号量的通知,success为true
if (deadline != null) {
success = this.condition.awaitUntil(deadline);
} else {
this.condition.await();
success = true;
}
if (future.isCancelled()) {
throw new InterruptedException("Operation interrupted");
}
} finally {
//从等待队列中移除
pool.unqueue(future);
this.pending.remove(future);
}
//如果没有等到信号量通知并且当前时间已经超时,则退出循环
if (!success && (deadline != null && deadline.getTime() <= System.currentTimeMillis())) {
break;
}
}
//最终也没有等到信号量通知,没有拿到可用连接,则抛异常
throw new TimeoutException("Timeout waiting for connection");
} finally {
//释放对大连接池的锁
this.lock.unlock();
}
}
上面的代码逻辑有几个重要点:
- 连接池有个最大连接数,每个route对应一个小连接池,也有个最大连接数
- 不论是大连接池还是小连接池,当超过数量的时候,都要通过LRU释放一些连接
- 如果拿到了可用连接,则返回给上层使用
- 如果没有拿到可用连接,HttpClient会判断当前route连接池是否已经超过了最大数量,没有到上限就会新建一个连接,并放入池中
- 如果到达了上限,就排队等待,等到了信号量,就重新获得一次,等待不到就抛超时异常
- 通过线程池获取连接要通过ReetrantLock加锁,保证线程安全
到这里为止,程序已经拿到了一个可用的CPoolEntry实例,或者抛异常终止了程序。
4.3 HttpClientConnection
protected HttpClientConnection leaseConnection(
final Future<CPoolEntry> future,
final long timeout,
final TimeUnit tunit) throws InterruptedException, ExecutionException, ConnectionPoolTimeoutException {
final CPoolEntry entry;
try {
//从异步操作Future<CPoolEntry>中获得CPoolEntry
entry = future.get(timeout, tunit);
if (entry == null || future.isCancelled()) {
throw new InterruptedException();
}
Asserts.check(entry.getConnection() != null, "Pool entry with no connection");
if (this.log.isDebugEnabled()) {
this.log.debug("Connection leased: " + format(entry) + formatStats(entry.getRoute()));
}
//获得一个CPoolEntry的代理对象,对其操作都是使用同一个底层的HttpClientConnection
return CPoolProxy.newProxy(entry);
} catch (final TimeoutException ex) {
throw new ConnectionPoolTimeoutException("Timeout waiting for connection from pool");
}
}
五、HttpClient如何复用持久连接?
在上一章中,我们看到了HttpClient通过连接池来获得连接,当需要使用连接的时候从池中获得。
对应着第三章的问题:
- 当有连接第一次使用的时候建立连接
- 结束时对应连接不关闭,归还到池中
- 下次同个目的的连接可从池中获取一个可用连接
- 定期清理过期连接
我们在第四章中看到了HttpClient是如何处理1、3的问题的,那么第2个问题是怎么处理的呢?
即HttpClient如何判断一个连接在使用完毕后是要关闭,还是要放入池中供他人复用?再看一下MainClientExec的代码
//发送Http连接
response = requestExecutor.execute(request, managedConn, context); //根据重用策略判断当前连接是否要复用 if (reuseStrategy.keepAlive(response, context)) { //需要复用的连接,获取连接超时时间,以response中的timeout为准 final long duration = keepAliveStrategy.getKeepAliveDuration(response, context); if (this.log.isDebugEnabled()) { final String s;
//timeout的是毫秒数,如果没有设置则为-1,即没有超时时间 if (duration > 0) { s = "for " + duration + " " + TimeUnit.MILLISECONDS; } else { s = "indefinitely"; } this.log.debug("Connection can be kept alive " + s); }
//设置超时时间,当请求结束时连接管理器会根据超时时间决定是关闭还是放回到池中 connHolder.setValidFor(duration, TimeUnit.MILLISECONDS); //将连接标记为可重用
connHolder.markReusable(); } else {
//将连接标记为不可重用 connHolder.markNonReusable(); }
可以看到,当使用连接发生过请求之后,有连接重试策略来决定该连接是否要重用,如果要重用就会在结束后交给HttpClientConnectionManager放入池中。
那么连接复用策略的逻辑是怎么样的呢?
public class DefaultClientConnectionReuseStrategy extends DefaultConnectionReuseStrategy {
public static final DefaultClientConnectionReuseStrategy INSTANCE = new DefaultClientConnectionReuseStrategy();
@Override
public boolean keepAlive(final HttpResponse response, final HttpContext context) {
//从上下文中拿到request
final HttpRequest request = (HttpRequest) context.getAttribute(HttpCoreContext.HTTP_REQUEST);
if (request != null) {
//获得Connection的Header
final Header[] connHeaders = request.getHeaders(HttpHeaders.CONNECTION);
if (connHeaders.length != 0) {
final TokenIterator ti = new BasicTokenIterator(new BasicHeaderIterator(connHeaders, null));
while (ti.hasNext()) {
final String token = ti.nextToken();
//如果包含Connection:Close首部,则代表请求不打算保持连接,会忽略response的意愿,该头部这是HTTP/1.1的规范
if (HTTP.CONN_CLOSE.equalsIgnoreCase(token)) {
return false;
}
}
}
}
//使用父类的的复用策略
return super.keepAlive(response, context);
}
}
看一下父类的复用策略
if (canResponseHaveBody(request, response)) {
final Header[] clhs = response.getHeaders(HTTP.CONTENT_LEN);
//如果reponse的Content-Length没有正确设置,则不复用连接
//因为对于持久化连接,两次传输之间不需要重新建立连接,则需要根据Content-Length确认内容属于哪次请求,以正确处理“粘包”现象
//所以,没有正确设置Content-Length的response连接不能复用
if (clhs.length == 1) {
final Header clh = clhs[0];
try {
final int contentLen = Integer.parseInt(clh.getValue());
if (contentLen < 0) {
return false;
}
} catch (final NumberFormatException ex) {
return false;
}
} else {
return false;
}
}
if (headerIterator.hasNext()) {
try {
final TokenIterator ti = new BasicTokenIterator(headerIterator);
boolean keepalive = false;
while (ti.hasNext()) {
final String token = ti.nextToken();
//如果response有Connection:Close首部,则明确表示要关闭,则不复用
if (HTTP.CONN_CLOSE.equalsIgnoreCase(token)) {
return false;
//如果response有Connection:Keep-Alive首部,则明确表示要持久化,则复用
} else if (HTTP.CONN_KEEP_ALIVE.equalsIgnoreCase(token)) {
keepalive = true;
}
}
if (keepalive) {
return true;
}
} catch (final ParseException px) {
return false;
}
}
//如果response中没有相关的Connection首部说明,则高于HTTP/1.0版本的都复用连接
return !ver.lessEquals(HttpVersion.HTTP_1_0);
总结一下:
- 如果request首部中包含Connection:Close,不复用
- 如果response中Content-Length长度设置不正确,不复用
- 如果response首部包含Connection:Close,不复用
- 如果reponse首部包含Connection:Keep-Alive,复用
- 都没命中的情况下,如果HTTP版本高于1.0则复用
从代码中可以看到,其实现策略与我们第二、三章协议层的约束是一致的。
六、HttpClient如何清理过期连接
在HttpClient4.4版本之前,在从连接池中获取重用连接的时候会检查下是否过期,过期则清理。
之后的版本则不同,会有一个单独的线程来扫描连接池中的连接,发现有离最近一次使用超过设置的时间后,就会清理。默认的超时时间是2秒钟。
public CloseableHttpClient build() {
//如果指定了要清理过期连接与空闲连接,才会启动清理线程,默认是不启动的
if (evictExpiredConnections || evictIdleConnections) {
//创造一个连接池的清理线程
final IdleConnectionEvictor connectionEvictor = new IdleConnectionEvictor(cm,
maxIdleTime > 0 ? maxIdleTime : 10, maxIdleTimeUnit != null ? maxIdleTimeUnit : TimeUnit.SECONDS,
maxIdleTime, maxIdleTimeUnit);
closeablesCopy.add(new Closeable() {
@Override
public void close() throws IOException {
connectionEvictor.shutdown();
try {
connectionEvictor.awaitTermination(1L, TimeUnit.SECONDS);
} catch (final InterruptedException interrupted) {
Thread.currentThread().interrupt();
}
}
});
//执行该清理线程
connectionEvictor.start();
}
可以看到在HttpClientBuilder进行build的时候,如果指定了开启清理功能,会创建一个连接池清理线程并运行它。
public IdleConnectionEvictor(
final HttpClientConnectionManager connectionManager,
final ThreadFactory threadFactory,
final long sleepTime, final TimeUnit sleepTimeUnit,
final long maxIdleTime, final TimeUnit maxIdleTimeUnit) {
this.connectionManager = Args.notNull(connectionManager, "Connection manager");
this.threadFactory = threadFactory != null ? threadFactory : new DefaultThreadFactory();
this.sleepTimeMs = sleepTimeUnit != null ? sleepTimeUnit.toMillis(sleepTime) : sleepTime;
this.maxIdleTimeMs = maxIdleTimeUnit != null ? maxIdleTimeUnit.toMillis(maxIdleTime) : maxIdleTime;
this.thread = this.threadFactory.newThread(new Runnable() {
@Override
public void run() {
try {
//死循环,线程一直执行
while (!Thread.currentThread().isInterrupted()) {
//休息若干秒后执行,默认10秒
Thread.sleep(sleepTimeMs);
//清理过期连接
connectionManager.closeExpiredConnections();
//如果指定了最大空闲时间,则清理空闲连接
if (maxIdleTimeMs > 0) {
connectionManager.closeIdleConnections(maxIdleTimeMs, TimeUnit.MILLISECONDS);
}
}
} catch (final Exception ex) {
exception = ex;
}
}
});
}
总结一下:
- 只有在HttpClientBuilder手动设置后,才会开启清理过期与空闲连接
- 手动设置后,会启动一个线程死循环执行,每次执行sleep一定时间,调用HttpClientConnectionManager的清理方法清理过期与空闲连接。
七、本文总结
- HTTP协议通过持久连接的方式,减轻了早期设计中的过多连接问题
- 持久连接有两种方式:HTTP/1.0+的Keep-Avlive与HTTP/1.1的默认持久连接
- HttpClient通过连接池来管理持久连接,连接池分为两个,一个是总连接池,一个是每个route对应的连接池
- HttpClient通过异步的Future<CPoolEntry>来获取一个池化的连接
- 默认连接重用策略与HTTP协议约束一致,根据response先判断Connection:Close则关闭,在判断Connection:Keep-Alive则开启,最后版本大于1.0则开启
- 只有在HttpClientBuilder中手动开启了清理过期与空闲连接的开关后,才会清理连接池中的连接
- HttpClient4.4之后的版本通过一个死循环线程清理过期与空闲连接,该线程每次执行都sleep一会,以达到定期执行的效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号