TCP 连接建立的三次握手过程可以携带数据吗?,一致性hash算法
前几天实验室的群里扔出了这样一个问题:TCP连接建立的三次握手过程可以携带数据吗?突然发现自己还真不清楚这个问题,平日里用tcpdump或者Wireshark抓包时,从来没留意过第三次握手的ACK包有没有数据。于是赶紧用nc配合tcpdump抓了几次包想检验一下。但是经过了多次实验,确实都发现第三次握手的包没有其它数据(后文解释)。后来的探究中发现这个过程有问题,遂整理探究过程和结论汇成本文,以供后来者参考。
先来张三次握手的图(下面这张图来自网络,若侵犯了作者权利,请联系我删除):
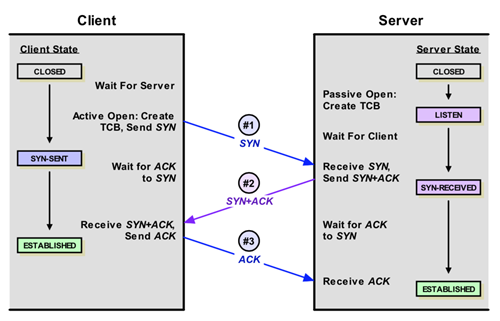
RFC793文档里带有SYN标志的过程包是不可以携带数据的,也就是说三次握手的前两次是不可以携带数据的(逻辑上看,连接还没建立,携带数据好像也有点说不过去)。重点就是第三次握手可不可以携带数据。
先说结论:TCP协议建立连接的三次握手过程中的第三次握手允许携带数据。
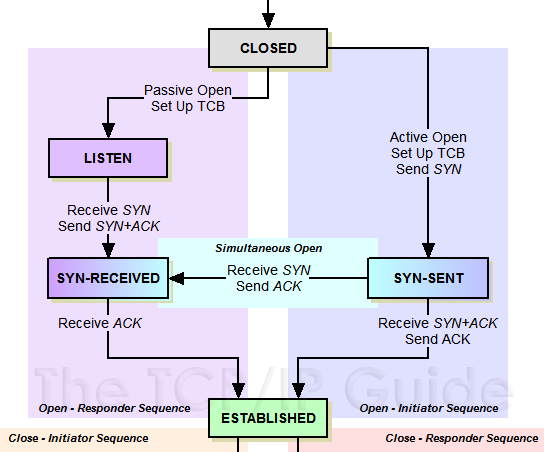
对照着上边的TCP状态变化图的连接建立部分,我们看下RFC793文档的说法。RFC793文档给出的说法如下(省略不重要的部分):
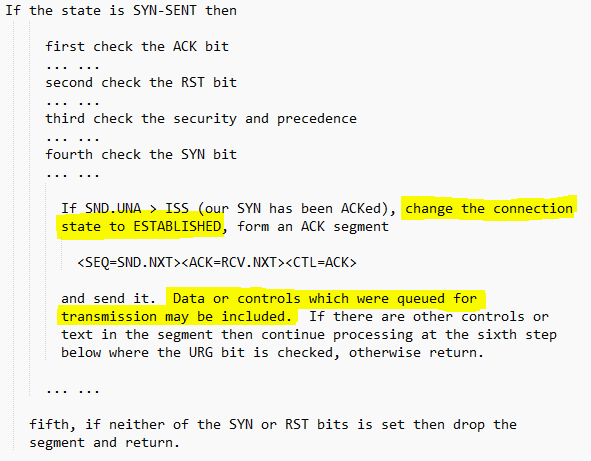
重点是这句 “Data or controls which were queued for transmission may be included”,也就是说标准表示,第三次握手的ACK包是可以携带数据。那么Linux的内核协议栈是怎么做的呢?侯捷先生说过,“源码面前,了无秘密”。最近恰逢Kernel 4.0正式版发布,那就追查下这个版本的内核协议栈的源码吧。
在探索源码前,我们假定读者对Linux的基本socket编程很熟悉,起码对连接的流程比较熟悉(可以参考这篇文章《浅谈服务端编程》最前边的socket连接过程图)。至于socket接口和协议栈的挂接,可以参阅《socket接口与内核协议栈的挂接》 。
首先, 第三次握手的包是由连接发起方(以下简称客户端)发给端口监听方(以下简称服务端)的,所以只需要找到内核协议栈在一个连接处于SYN-RECV(图中的SYN_RECEIVED)状态时收到包之后的处理过程即可。经过一番搜索后找到了,位于 net\ipv4目录下tcp_input.c文件中的tcp_rcv_state_process函数处理这个过程。如图:

这个函数实际上是个TCP状态机,用于处理TCP连接处于各个状态时收到数据包的处理工作。这里有几个并列的switch语句,因为函数很长,所以比较容易看错层次关系。下图是精简了无需关注的代码之后SYN-RECV状态的处理过程:
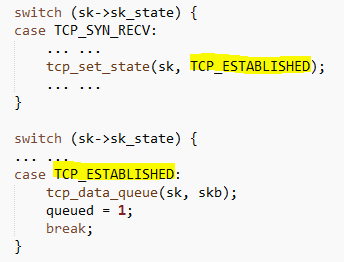
一定要注意这两个switch语句是并列的。所以当TCP_SYN_RECV状态收到合法规范的二次握手包之后,就会立即把socket状态设置为TCP_ESTABLISHED状态,执行到下面的TCP_ESTABLISHED状态的case时,会继续处理其包含的数据(如果有)。
上面表明了,当客户端发过来的第三次握手的ACK包含有数据时,服务端是可以正常处理的。那么客户端那边呢?那看看客户端处于SYN-SEND状态时,怎么发送第三次ACK包吧。如图:

tcp_rcv_synsent_state_process函数的实现比较长,这里直接贴出最后的关键点:

一目了然吧?if 条件不满足直接回复单独的ACK包,如果任意条件满足的话则使用inet_csk_reset_xmit_timer函数设置定时器等待短暂的时间。这段时间如果有数据,随着数据发送ACK,没有数据回复ACK。
之前的疑问算是解决了。
但是,那三个条件是什么?什么情况会导致第三次握手包可能携带数据呢?或者说,想抓到一个第三次握手带有数据的包,需要怎么做?别急,本博客向来喜欢刨根问底,且听下文一一道来。
条件1:sk->sk_write_pending != 0
这个值默认是0的,那什么情况会导致不为0呢?答案是协议栈发送数据的函数遇到socket状态不是ESTABLISHED的时候,会对这个变量做++操作,并等待一小会时间尝试发送数据。看图:
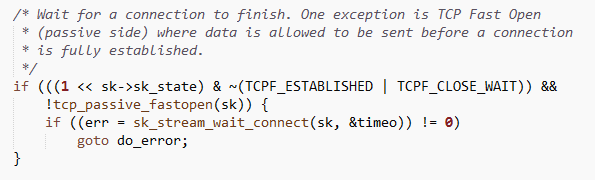
net/core/stream.c里的sk_stream_wait_connect函数做了如下操作:
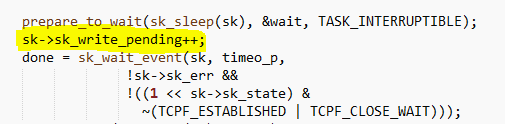
sk->sk_write_pending递增,并且等待socket连接到达ESTABLISHED状态后发出数据。这就解释清楚了。
Linux socket的默认工作方式是阻塞的,也就是说,客户端的connect调用在默认情况下会阻塞,等待三次握手过程结束之后或者遇到错误才会返回。那么nc这种完全用阻塞套接字实现的且没有对默认socket参数进行修改的命令行小程序会乖乖等待connect返回成功或者失败才会发送数据的,这就是我们抓不到第三次握手的包带有数据的原因。
那么设置非阻塞套接字,connect后立即send数据,连接过程不是瞬间连接成功的话,也许有机会看到第三次握手包带数据。不过开源的网络库即便是非阻塞socket,也是监听该套接字的可写事件,再次确认连接成功才会写数据。为了节省这点几乎可以忽略不计的性能,真的不如安全可靠的代码更有价值。
条件2:icsk->icsk_accept_queue.rskq_defer_accept != 0
这个条件好奇怪,defer_accept是个socket选项,用于推迟accept,实际上是当接收到第一个数据之后,才会创建连接。tcp_defer_accept这个选项一般是在服务端用的,会影响socket的SYN和ACCEPT队列。默认不设置的话,三次握手完成,socket就进入accept队列,应用层就感知到并ACCEPT相关的连接。当tcp_defer_accept设置后,三次握手完成了,socket也不进入ACCEPT队列,而是直接留在SYN队列(有长度限制,超过内核就拒绝新连接),直到数据真的发过来再放到ACCEPT队列。设置了这个参数的服务端可以accept之后直接read,必然有数据,也节省一次系统调用。
SYN队列保存SYN_RECV状态的socket,长度由net.ipv4.tcp_max_syn_backlog参数控制,accept队列在listen调用时,backlog参数设置,内核硬限制由 net.core.somaxconn 限制,即实际的值由min(backlog,somaxconn) 来决定。
有意思的是如果客户端先bind到一个端口和IP,然后setsockopt(TCP_DEFER_ACCEPT),然后connect服务器,这个时候就会出现rskq_defer_accept=1的情况,这时候内核会设置定时器等待数据一起在回复ACK包。我个人从未这么做过,难道只是为了减少一次ACK的空包发送来提高性能?哪位同学知道烦请告知,谢谢。
条件3:icsk->icsk_ack.pingpong != 0
pingpong这个属性实际上也是一个套接字选项,用来表明当前链接是否为交互数据流,如其值为1,则表明为交互数据流,会使用延迟确认机制。
好了,本文到此就应该结束了,上面各个函数出现的比较没有条理。具体的调用链可以参考这篇文章《TCP内核源码分析笔记》,不过因为内核版本的不同,可能会有些许差异。毕竟我没研究过协议栈,就不敢再说什么了。
浅谈服务端编程
从基本socket函数开始
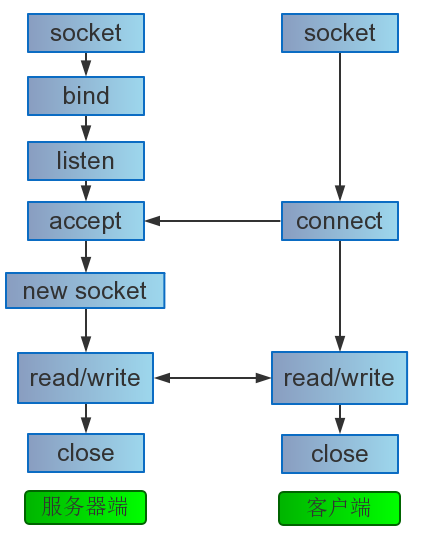
留意一些socket函数与众不同的参数细节
|
|
TCP三次握手在socket接口的位置
强调TIME_WAIT状态
MSL(最大分段生存期)指明TCP报文在Internet上最长生存时间,每个具体的TCP实现都必须选择一个确定的MSL值。RFC1122建议是2分钟。
TIME_WAIT 状态最大保持时间是2 * MSL,也就是1-4分钟。
|
|
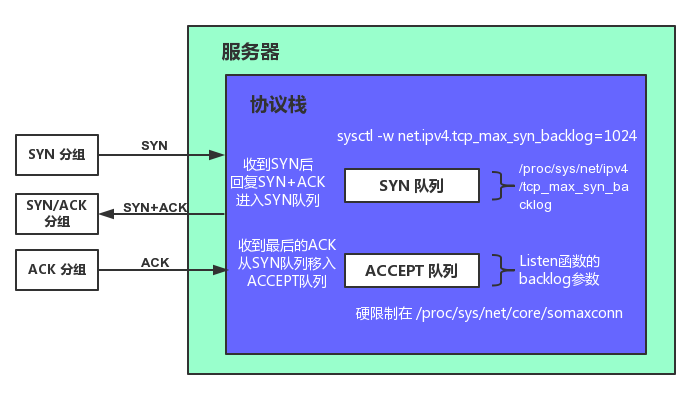
Linux内核协议栈
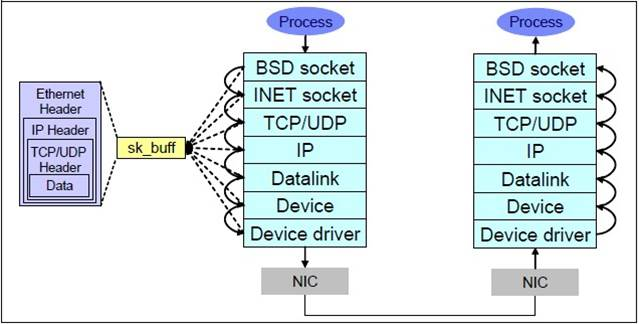
TCP 的发送
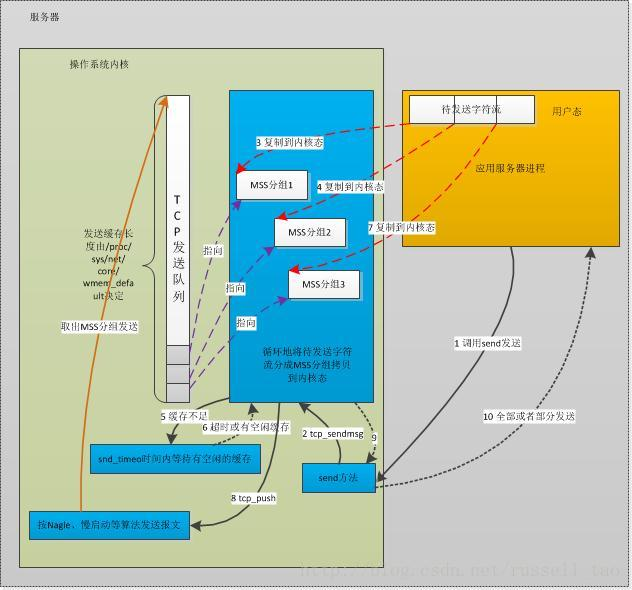
TCP的接收
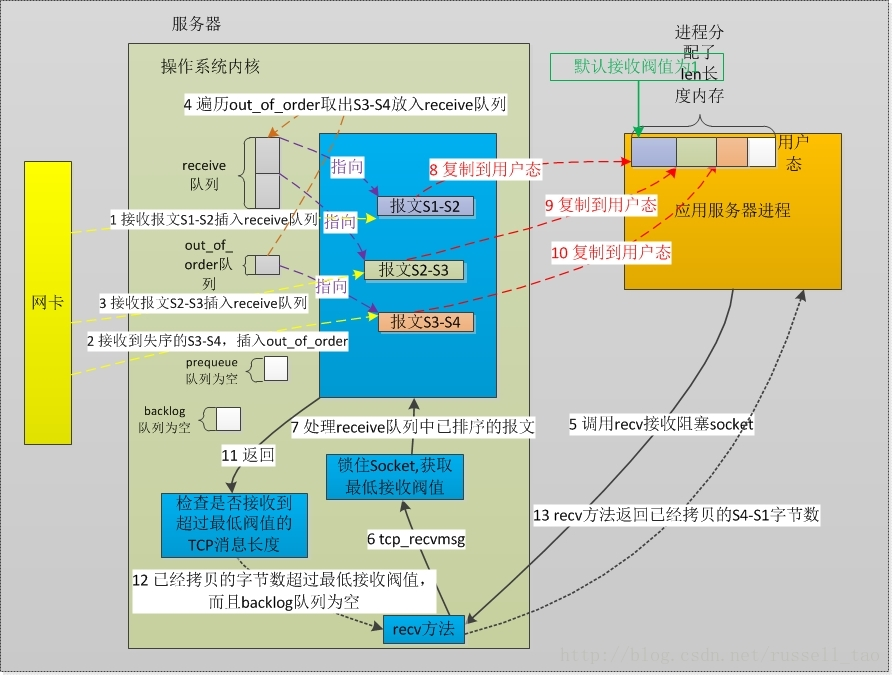
协议栈完整的收发流程
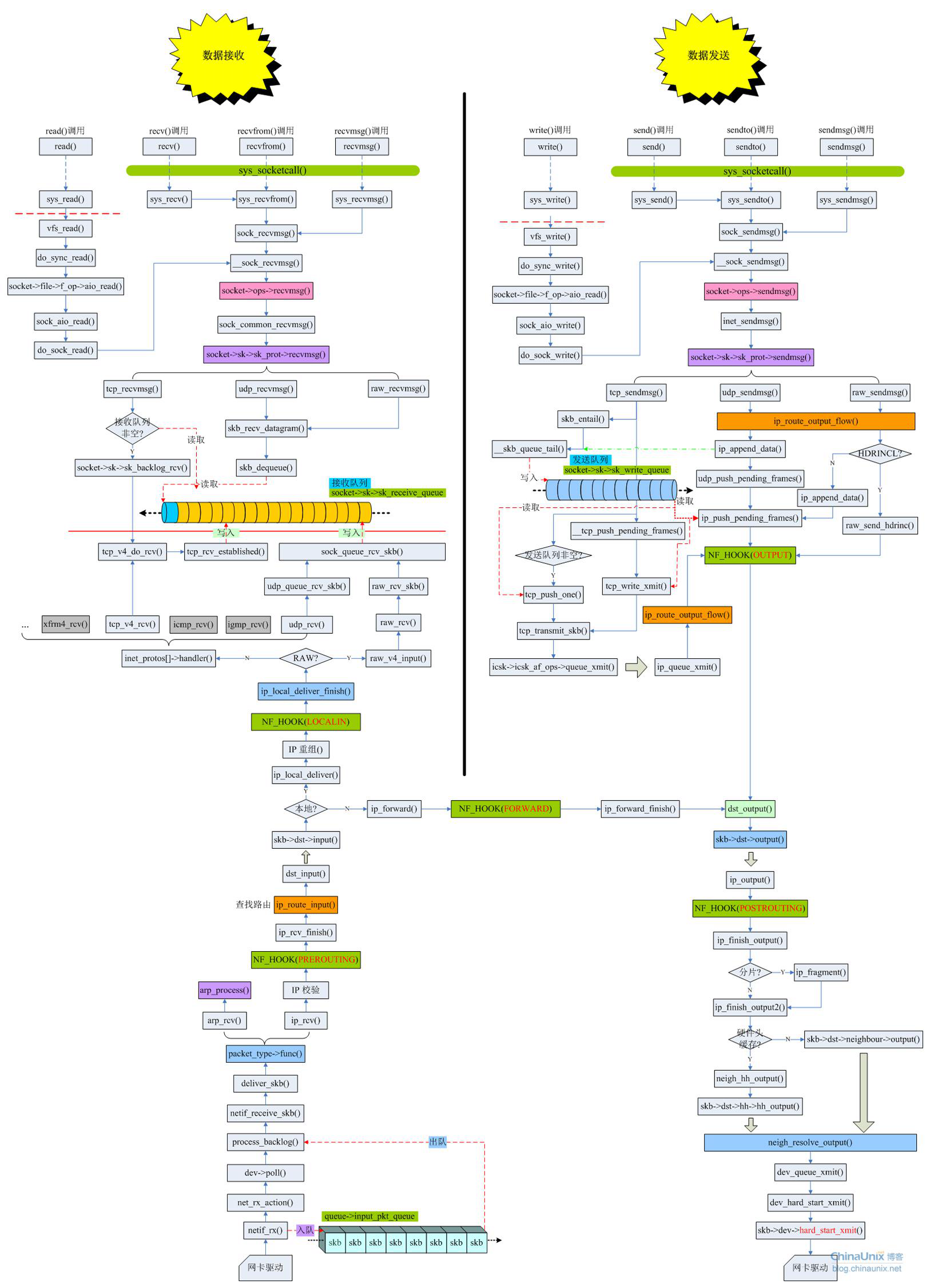
关于socket接口与内核协议栈的挂接
TCP相关参数的设置方法
套接字设置
|
|
SO_REUSEADDR
当有一个有相同本地地址和端口的socket1处于TIME_WAIT状态时,而你启动的程序的socket2要占用该地址和端口,你的程序就要用到该选项。这个选项允许同一port上启动同一服务器的多个实例(多个进程)。但每个实例绑定的IP地址是不能相同的。(多块网卡的应用场合)
SO_RECVBUF / SO_SNDBUF
发送和接收缓冲区大小,不详述。
TCP_NODELAY / TCP_CHORK
是否采用Nagle算法把较小的包组装为更大的帧。HTTP服务器经常使用TCP_NODELAY关闭该算法。相关的还有TCP_CORK。
TCP_DEFER_ACCEPT
推迟accept,实际上是当接收到第一个数据之后,才会创建连接。(对于像HTTP等非交互式的服务器,这个很有意义,可以用来防御空连接攻击。)
TCP_KEEPCNT / TCP_KEEPIDLE / TCP_KEEPINTVL
如果一方已经关闭或异常终止连接,而另一方却不知道,我们将这样的TCP连接称为半打开的。TCP通过保活定时器(KeepAlive)来检测半打开连接。设置SO_KEEPALIVE选项来开启KEEPALIVE,然后通过TCP_KEEPIDLE、TCP_KEEPINTVL和TCP_KEEPCNT设置keepalive的开始时间、间隔、次数等参数。
保活时间:keepalive_time = TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT
从TCP_KEEPIDLE 时间开始,向对端发送一个探测信息,然后每过TCP_KEEPINTVL 发送一次探测信息。如果在保活时间内,就算检测不到对端了,仍然保持连接。超过这个保活时间,如果检测不到对端,服务器就会断开连接,如果能够检测到对方,那么连接一直持续。
内核全局设置
内核的TCP/IP调优参数都位于/proc/sys/net/目录,可以直接写入数值或者采用sysctl命令或者系统调用。
|
|
详细请参考:提高 Linux 上 socket 性能
常见的协议格式设计
记住,TCP是一种流协议
语出《Effective TCP/IP Programming》。意思是,TCP的数据是以字节流的方式由发送者传递给接收者,没有固有的“报文”或者“报文边界”的概念。简单说,TCP不理解应用层通信的协议,不知道应用层协议格式和边界。所以,所谓的“粘包和断包”是个伪概念。TCP压根就没有包边界的概念,何谈粘与断。

OSI模型定义的7层结构网络中,TCP协议所在的传输层和应用层之间还有会话层和表示层,原本协议包分界和加密等等操作是在这两层完成的。TCP/IP协议在设计的时候,并没有会话层和表示层。那如果用户需要这两层提供的服务怎么办?比如包的分界?答案是,用户自行在应用层代码中实现吧。
示例:
发送者发送三次
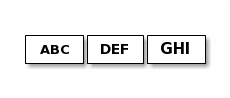
接收者可能收到这样:
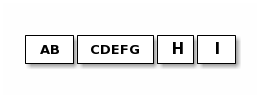
避免分片的效率损失
数据链路层Maximum Transmission Unit(MTU, 最大传输单元)。
以太网通常在1500字节上下。所以单次发送的协议包数据最好小于这个值,从而避免IP层分片带来的效率损失。
扩展阅读:Linux TCP/IP协议栈关于IP分片重组的实现
常见的协议格式
这个很简单,和文件一样,无非是纯文本格式或者二进制格式。
便于解包的协议设计方法
一般而言,应用层协议设计有四种常见方法:
- 每个发送的包长度固定
- 包每行均采取特殊结束标记用以区分(例如HTTP使用的\r\n)
- 包前添加长度信息(所谓的TLV模式,即type、length、value)
- 利用包本身的格式解析(如XML、JSON等)
以上1和3通常是二进制格式,2和4是文本格式。
有没有通用的二进制通信协议?推荐谷歌的ProtoBuf或者Apache Swift.
Need a demo?
包长度固定
很简单的思路,我们可以定义服务端和客户端均采用同一个结构体进行数据传输,这样的话很容易根据结构体大小来进行分隔收到的数据。这个不用写吧…
包每行均采取特殊结束标记用以区分
这个也很简单理解,采用纯ASCII发送信息的时候,完全可以采用这种方式。比如一个包中,每行采用\r\n进行分隔,包结束采用\r\n\r\n进行分隔等等。
如果在包的数据中出现了结束标记怎么办?转义呗~
包前添加长度信息(所谓的TLV模式,即type、length、value)
这个理解起来也不困难,以结构体为例,即便是服务端和客户端采用多种结构体进行通信,只需要加上一个类型字段和长度字段,这样不就解决了么。
不过这里的type、length以及value只是指导思想,大家完全可以自行去实现自己的格式。
不要觉得这个貌似很搓的样子,看看QQ早些时候的定义:
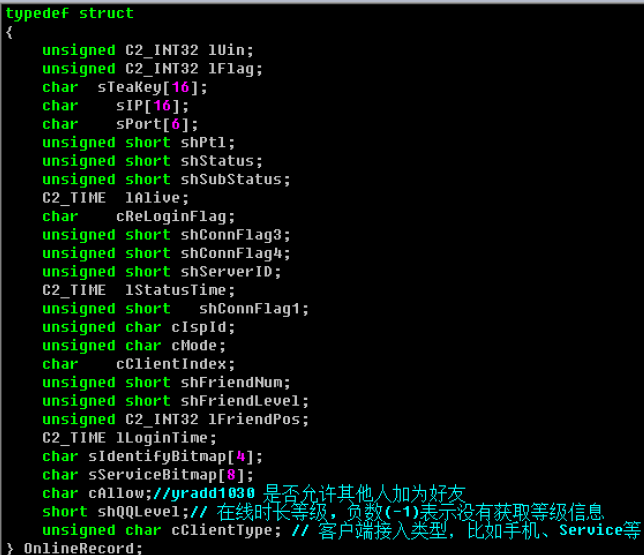
沈昭萌学长博客:TLV-简单的数据传输协议
|
|
rio_readn 函数的实现如下
|
|
analyse_protocol 是解析函数,简单的实现如下:
|
|
利用包本身的格式解析(如XML、JSON等)
这种方式也不难,我们可以通过Xml,Json本身的格式来匹配每一个具体的包。下面给出一个简单的XML接收和解析的简单例子和Qt下使用QtXml的解析方法。
上面是同步的,下面来个异步的:
|
|
常见的通信模型
研究server模型的目的
适应特定的硬件体系与OS特点
比如说相同的server模型在SMP体系下与NUMA下的表现就可能不尽相同,又如在linux下表现尚可的进程模型在windows下面就非常吃力。好的server 模型应该从硬件和OS的进步发展中,得到最大化的好处。
实现维护成本与性能的平衡
好的模型会在编程难度与性能之间做比较好的平衡,并且会很容易地在特定场景下做重心偏移。
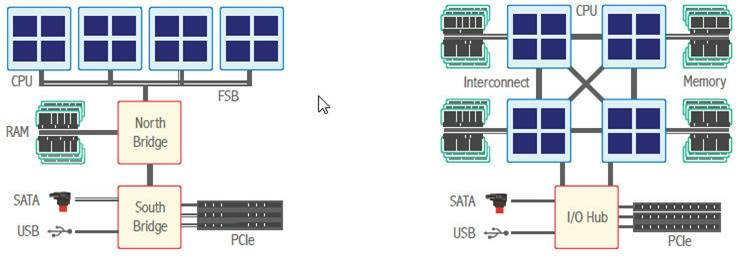
基本模型
多进程模型与原理
Unix/Linux特有模型,不必多说,可参考子进程自父进程继承什么或未继承什么。
最典型的应用当数传统CGI了。什么语言能写CGI?只要写出来的东东能运行,就能当CGI。c/c++、php、python、perl、甚至shell等等。
优化下就是prefork模型,传说中的进程池。
进程数的经验值可以这样估计: n=current * delay
Current 是并发量,delay 是平均任务时延。
当delay 为2,并发量current 为100 时,进程数至少要为200。
缺点:用进程数来抗并发用户数,因一台机器可启动的进程数是有限的,还没见到过进程能开到K级别,并且当进程太多时OS调度和切换开销往往也大于业务本身了。
多线程模型与原理
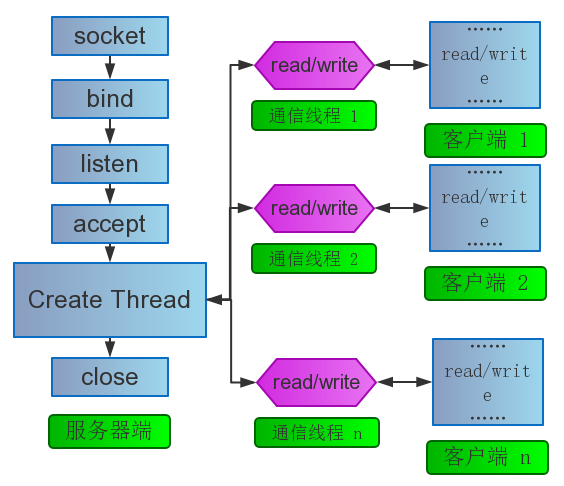
也不必多说了吧?对其进行简单的优化就是线程池模型了。
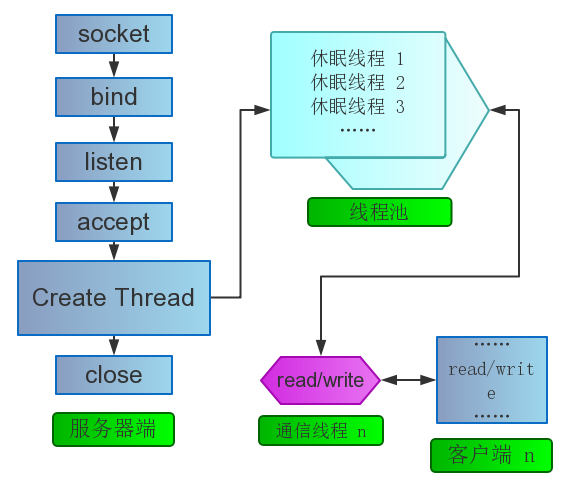
上面代码看看思想就好,99.99%的可能会有bug。
你会发现,C写的线程池把互斥锁、条件变量、队列和代码逻辑混合在一起很难理解。我们引入C++和RAII技术:RAII就是资源获取即初始化。简单说就是由相关的类来拥有和处理资源,在构造函数里进行资源的获取,在析构函数里对资源进行释放。由语言天生的作用域来控制资源,极大的解放了生产力和程序员思想包袱。
pthread_mutex的 例子
怎么用?戳这里的 无界阻塞队列
封装之后的代码:线程池
从同步到异步
阻塞、非阻塞、同步、异步
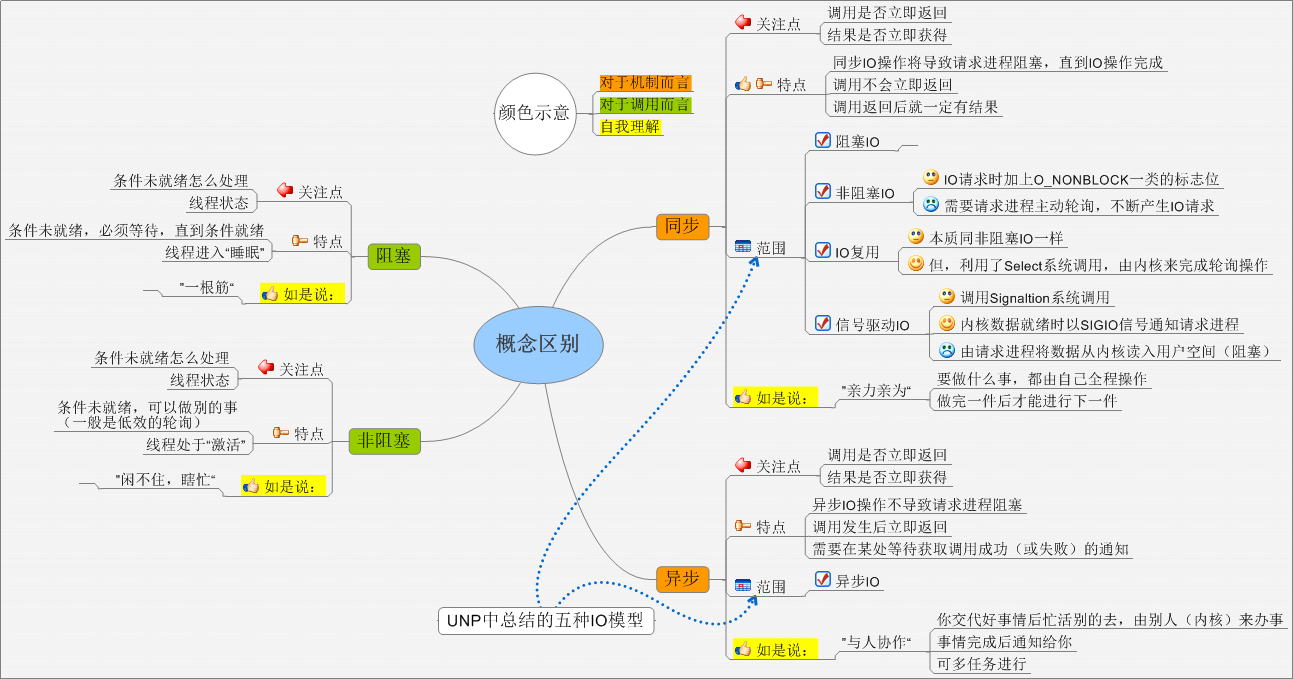
非阻塞+IO复用
推荐方式,非阻塞必然和IO复用联合起来~(不然你要一直在用户态做轮询吗?)
这是异步IO?
啥是异步IO?看POSIX.1对同步I/O和异步I/O的定义:
- 同步I/O操作导致发出请求的进程被阻塞直到I/O操作完成。
- 异步I/O操作在I/O操作期间不导致发出请求的进程被阻塞。
根据这个定义,阻塞,非阻塞,多路复用,信号驱动均属于同步I/O(尽管信号驱动由于习惯原因,在以前被成为异步I/O)
Linux目前实现的两套异步IO方法
Pthread实现的AIO和Linxu内核实现的Native AIO。
缺点?Pthread的是在用线程模拟!完全不可用!内核的倒是异步,但是目前的实现没法利用IO缓存!不过在一些场合还是不错的。
可以参考:Linux AIO(异步IO)那点事儿
好吧,不明觉厉的同学暂时还是老老实实的用EventLoop+IO线程池吧~
吐槽下,windows很早以前的的IOCP就是纯异步了…迅雷很早以前都在用…
Reactor模型与Proactor模型
重头戏,先看看 【翻译】两种高性能I/O设计模式(Reactor/Proactor)的比较,到时候我们现场重点聊聊Reactor这个。这里就不描述了,细节太多,问题太多。我希望这里作为大家讨论的重点,而不是现在用文字完全描述。
其次,单个EventLoop循环如果跑在了单个进程/线程中,对于多核服务器来说,是个浪费。多线程和多进程需要注意的一些点还有false sharing等现象和cache的利用以及上下的切换。前者看SMP架构多线程程序的一种性能衰退现象—False Sharing,后者看cpu绑定和cpu亲和性。最后不要忘记了函数重入性与线程安全。
什么,你要代码示例?看这里.
内核级别的优化,来自最近火起来的新浪的FastOS计划内的FastSocket.
Linux服务器程序规范
- 一般以后台守进程形式运行,没有控制终端不接受用户输入。
- 通常有一套日志系统,至少能输出到文件。
- 一般以非root的特殊用户身份运行。
- 通常是可配置的,文件放在/etc下。
- 通常需要在启动的时候生成一个PID文件并存入/var/run目录中,记录该后台进程的PID 。
标准库与第三方库
C/C++相关
太多了,数不胜数,典型的有libev、libevent、libuv、boost asio、cpp-netlib、POCO
太多了,还有各种特殊用途的,比如SSL,DNS异步解析,HTTP相关操作的curl等,不详细说了。
Java相关
标准库就是socket和nio了。
第三方库很多,比如mina、netty等,推荐后者,应用的比较多且比前者效率好些。
Python相关
大名鼎鼎的 Twisted.
如果时间允许,我们还要:
剖析一个流行的开源服务器模型,比如nginx的框架和实现,顺道看看阿里核心系统团队怎么对nginx的数据结构和算法进行的优化~
下一站,分布式系统设计与实现
啥是分布式?别被名字吓到了,分布式的定义如下:
组件分布在联网的计算机上,组件之间通过传递消息进行通信和动作协调的系统。
特性:组件的并发性、缺乏全局时钟、组件故障的独立性
动机:资源共享
挑战:组件异构性、开放性、安全性、可伸缩性、故障处理、并发性、透明性、服务质量。
怎么学?哈哈,我还不会,跟着大牛们摸索,不过分布式两大基础协议之一的一致性哈希算法我介绍过的,这个必须会。
服务器端程序设计就这么一点内容吗?
No, we are too young, too simple.
路很长,现在还远远不是终点,我们欠缺的还有很多!共勉!
一致性hash算法
分布式系统中有两个非常重要的算法,一个是上一篇讲的Paxos算法,一个就是本篇介绍的一致性 hash 算法。前者的比较著名的应用有 Google 的 Chubby 和 ZooKeeper ,后者在NoSQL技术中可以看到。
本篇转载一篇介绍一致性 hash 算法的比较好的文章。
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛。
1 基本场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache :
hash(object) % N一切都运行正常,再考虑如下的两种情况:
- 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object) % (N-1) ;
- 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object) % (N+1) 。
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing...
2 hash 算法和单调性
Hash 算法的一个衡量指标是单调性(Monotonicity),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object) % N 难以满足单调性要求。
3 consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除/添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
3.1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0 ~ 2^32-1 次方的数值空间;我们可以将这个空间想象成一个首(0)尾(2^32-1)相接的圆环,如下面图 1 所示的那样。
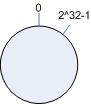
图 1 环形 hash 空间
3.2 把对象映射到hash 空间
接下来考虑 4 个对象 object1 ~ object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
...
hash(object4) = key4;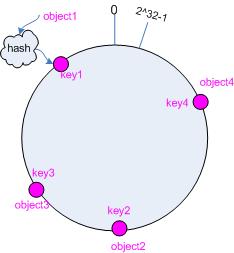
图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash 值排列。
hash(cache A) = key A;
...
hash(cache C) = key C;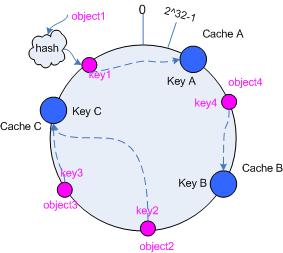
图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为 hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法:
object1 -> cache A
object2 -> cache C
object3 -> cache C
object4 -> cache B3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时, cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4。
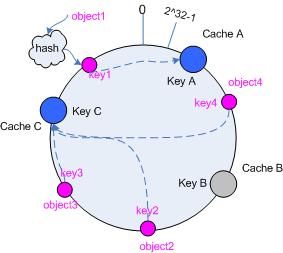
图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和 object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。
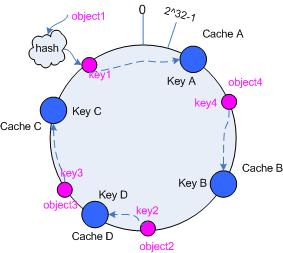
图 5 添加 cache D 后的映射关系
4 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中,cache A 仅存储了 object1,而 cache C 则存储了 object2、object3 和 object4;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”(virtual node)是实际节点在 hash 空间的复制品(replica),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A;cache C1, cache C2 代表了 cache C;假设一种比较理想的情况,参见图 6 。
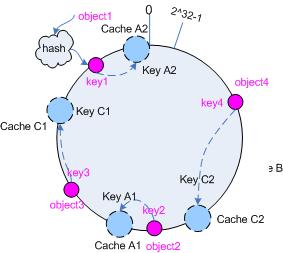
图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
object1 -> cache A2
object2 -> cache A1
object3 -> cache C1
object4 -> cache C2因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache 时的映射关系如图 7 所示。
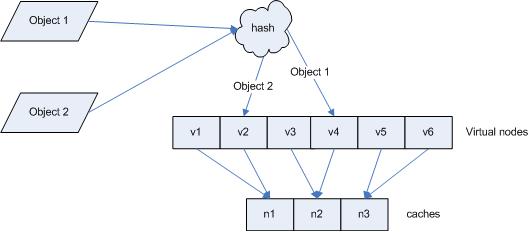
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为 202.168.14.241。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash("202.168.14.241");引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash("202.168.14.241#1"); // cache A1
Hash("202.168.14.241#2"); // cache A25 小结
Consistent hashing 的基本原理就是这些,具体的分布性等理论分析应该是很复杂的,不过一般也用不到。
http://weblogs.java.net/blog/2007/11/27/consistent-hashing 上面有一个 java 版本的例子,可以参考。
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx 转载了一个 PHP 版的实现代码。
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C语言版本
跟着动画来学习TCP三次握手和四次挥手
TCP三次握手和四次挥手的问题在面试中是最为常见的考点之一。很多读者都知道三次和四次,但是如果问深入一点,他们往往都无法作出准确回答。
本篇尝试使用动画来对这个知识点进行讲解,期望读者们可以更加简单地地理解TCP交互的本质。
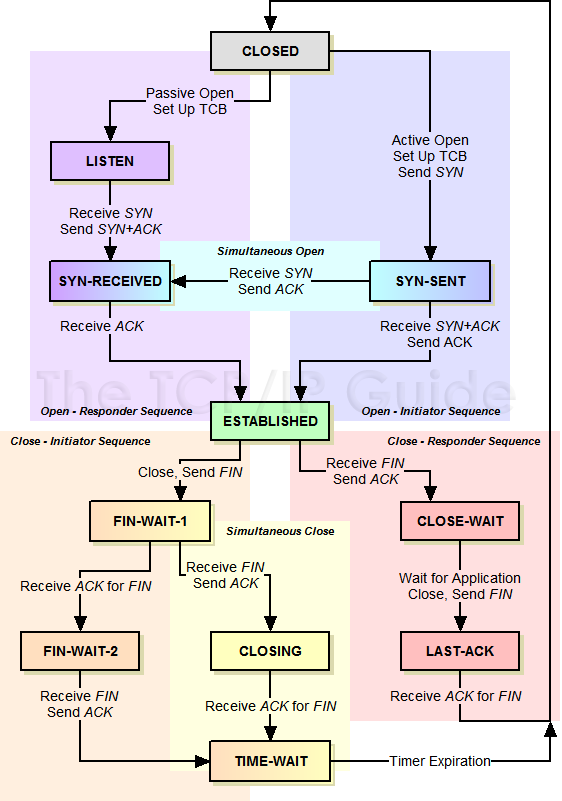
TCP 三次握手
TCP 三次握手就好比两个人在街上隔着50米看见了对方,但是因为雾霾等原因不能100%确认,所以要通过招手的方式相互确定对方是否认识自己。
张三首先向李四招手(syn),李四看到张三向自己招手后,向对方点了点头挤出了一个微笑(ack)。张三看到李四微笑后确认了李四成功辨认出了自己(进入estalished状态)。
但是李四还有点狐疑,向四周看了一看,有没有可能张三是在看别人呢,他也需要确认一下。所以李四也向张三招了招手(syn),张三看到李四向自己招手后知道对方是在寻求自己的确认,于是也点了点头挤出了微笑(ack),李四看到对方的微笑后确认了张三就是在向自己打招呼(进入established状态)。
于是两人加快步伐,走到了一起,相互拥抱。
我们看到这个过程中一共是四个动作,张三招手--李四点头微笑--李四招手--张三点头微笑。其中李四连续进行了2个动作,先是点头微笑(回复对方),然后再次招手(寻求确认),实际上可以将这两个动作合一,招手的同时点头和微笑(syn+ack)。于是四个动作就简化成了三个动作,张三招手--李四点头微笑并招手--张三点头微笑。这就是三次握手的本质,中间的一次动作是两个动作的合并。
我们看到有两个中间状态,syn_sent和syn_rcvd,这两个状态叫着「半打开」状态,就是向对方招手了,但是还没来得及看到对方的点头微笑。syn_sent是主动打开方的「半打开」状态,syn_rcvd是被动打开方的「半打开」状态。客户端是主动打开方,服务器是被动打开方。
- syn_sent: syn package has been sent
- syn_rcvd: syn package has been received
TCP 数据传输
TCP 数据传输就是两个人隔空对话,差了一点距离,所以需要对方反复确认听见了自己的话。
张三喊了一句话(data),李四听见了之后要向张三回复自己听见了(ack)。
如果张三喊了一句,半天没听到李四回复,张三就认为自己的话被大风吹走了,李四没听见,所以需要重新喊话,这就是tcp重传。
也有可能是李四听到了张三的话,但是李四向张三的回复被大风吹走了,以至于张三没听见李四的回复。张三并不能判断究竟是自己的话被大风吹走了还是李四的回复被大风吹走了,张三也不用管,重传一下就是。
既然会重传,李四就有可能同一句话听见了两次,这就是「去重」。「重传」和「去重」工作操作系统的网络内核模块都已经帮我们处理好了,用户层是不用关心的。
张三可以向李四喊话,同样李四也可以向张三喊话,因为tcp链接是「双工的」,双方都可以主动发起数据传输。不过无论是哪方喊话,都需要收到对方的确认才能认为对方收到了自己的喊话。
张三可能是个高射炮,一说连说了八句话,这时候李四可以不用一句一句回复,而是连续听了这八句话之后,一起向对方回复说前面你说的八句话我都听见了,这就是批量ack。但是张三也不能一次性说了太多话,李四的脑子短时间可能无法消化太多,两人之间需要有协商好的合适的发送和接受速率,这个就是「TCP窗口大小」。
网络环境的数据交互同人类之间的对话还要复杂一些,它存在数据包乱序的现象。同一个来源发出来的不同数据包在「网际路由」上可能会走过不同的路径,最终达到同一个地方时,顺序就不一样了。操作系统的网络内核模块会负责对数据包进行排序,到用户层时顺序就已经完全一致了。
TCP 四次挥手
TCP断开链接的过程和建立链接的过程比较类似,只不过中间的两部并不总是会合成一步走,所以它分成了4个动作,张三挥手(fin)——李四伤感地微笑(ack)——李四挥手(fin)——张三伤感地微笑(ack)。
之所以中间的两个动作没有合并,是因为tcp存在「半关闭」状态,也就是单向关闭。张三已经挥了手,可是人还没有走,只是不再说话,但是耳朵还是可以继续听,李四呢继续喊话。等待李四累了,也不再说话了,朝张三挥了挥手,张三伤感地微笑了一下,才彻底结束了。
上面有一个非常特殊的状态time_wait,它是主动关闭的一方在回复完对方的挥手后进入的一个长期状态,这个状态标准的持续时间是4分钟,4分钟后才会进入到closed状态,释放套接字资源。不过在具体实现上这个时间是可以调整的。
它就好比主动分手方要承担的责任,是你提出的要分手,你得付出代价。这个后果就是持续4分钟的time_wait状态,不能释放套接字资源(端口),就好比守寡期,这段时间内套接字资源(端口)不得回收利用。
它的作用是重传最后一个ack报文,确保对方可以收到。因为如果对方没有收到ack的话,会重传fin报文,处于time_wait状态的套接字会立即向对方重发ack报文。
同时在这段时间内,该链接在对话期间于网际路由上产生的残留报文(因为路径过于崎岖,数据报文走的时间太长,重传的报文都收到了,原始报文还在路上)传过来时,都会被立即丢弃掉。4分钟的时间足以使得这些残留报文彻底消逝。不然当新的端口被重复利用时,这些残留报文可能会干扰新的链接。
4分钟就是2个MSL,每个MSL是2分钟。MSL就是maximium segment lifetime——最长报文寿命。这个时间是由官方RFC协议规定的。至于为什么是2个MSL而不是1个MSL,我还没有看到一个非常满意的解释。
四次挥手也并不总是四次挥手,中间的两个动作有时候是可以合并一起进行的,这个时候就成了三次挥手,主动关闭方就会从fin_wait_1状态直接进入到time_wait状态,跳过了fin_wait_2状态。
总结
TCP状态转换是一个非常复杂的过程,本文仅对一些简单的基础知识点进行了类比讲解。关于TCP的更多知识还需要读者去搜寻相关技术文章进入深入学习。如果读者对TCP的基础知识掌握得比较牢固,高级的知识理解起来就不会太过于吃力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号