C#网络爬虫抓取小说
心血来潮,想研究下爬虫,爬点小说。
通过百度选择了个小说网站,随便找了一本小书http://www.23us.so/files/article/html/13/13655/index.html
一、分析html规则
思路是获取小说章节目录,循环目录,抓取所有章节中的内容,拼到txt文本中。最后形成完本小说。
1、获取小说章节目录
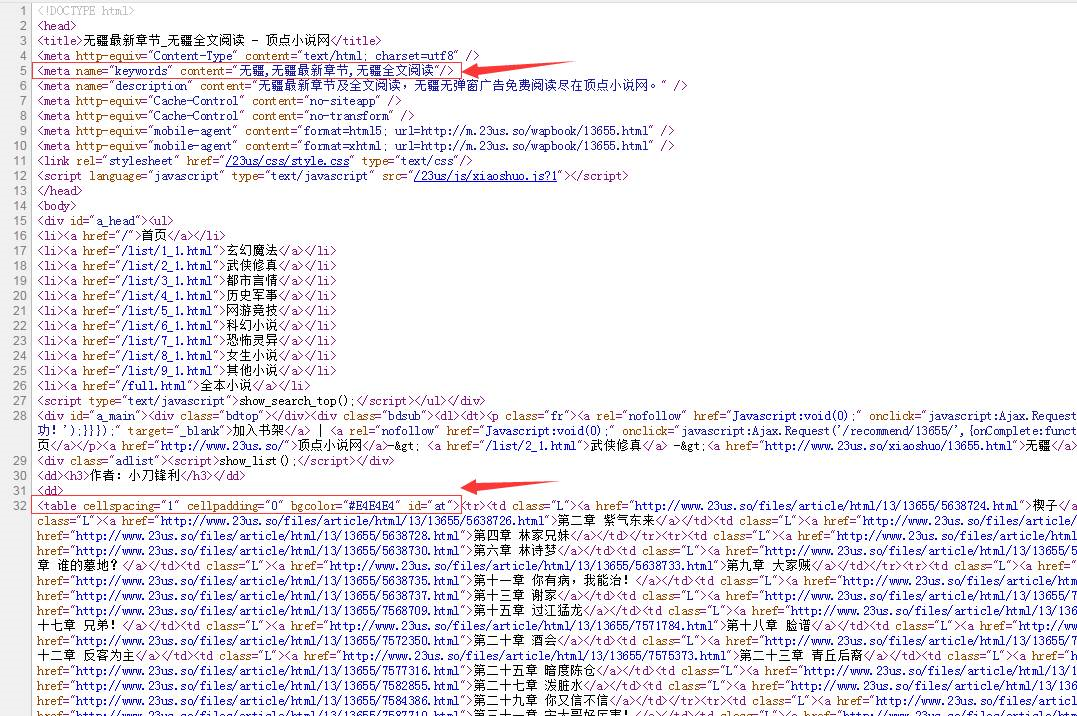
通过分析,我在标注的地方获取小说名字及章节目录。
<meta name="keywords" content="无疆,无疆最新章节,无疆全文阅读"/>// 获取小说名字 <table cellspacing="1" cellpadding="0" bgcolor="#E4E4E4" id="at">// 所有的章节都在这个table中。
下面是利用正则,获取名字与目录。
// 获取小说名字 Match ma_name = Regex.Match(html, @"<meta name=""keywords"".+content=""(.+)""/>"); string name = ma_name.Groups[1].Value.ToString().Split(',')[0]; // 获取章节目录 Regex reg_mulu = new Regex(@"<table cellspacing=""1"" cellpadding=""0"" bgcolor=""#E4E4E4"" id=""at"">(.|\n)*?</table>"); var mat_mulu = reg_mulu.Match(html); string mulu = mat_mulu.Groups[0].ToString();
2、获取小说正文内容
通过章节a标签中的url地址,查看章节内容。

通过分析,正文内容在<dd id="contents">中。
// 获取正文 Regex reg = new Regex(@"<dd id=""contents"">(.|\n)*?</dd>"); MatchCollection mc = reg.Matches(html_z); var mat = reg.Match(html_z); string content = mat.Groups[0].ToString().Replace("<dd id=\"contents\">", "").Replace("</dd>", "").Replace(" ", "").Replace("<br />", "\r\n");
二、C#完整代码


1 using System; 2 using System.Collections; 3 using System.Collections.Generic; 4 using System.IO; 5 using System.Linq; 6 using System.Net; 7 using System.Text; 8 using System.Text.RegularExpressions; 9 using System.Web; 10 using System.Web.Mvc; 11 12 namespace TestInsect.Controllers 13 { 14 public class CrawlerController : Controller 15 { 16 // GET: Crawler 17 public ActionResult Index() 18 { 19 Index1(); 20 return View(); 21 } 22 // GET: Crawler 23 public void Index1() 24 { 25 //抓取整本小说 26 CrawlerController cra = new CrawlerController();// 顶点抓取小说网站小说 27 string html = cra.HttpGet("http://www.23us.so/files/article/html/13/13655/index.html", ""); 28 29 // 获取小说名字 30 Match ma_name = Regex.Match(html, @"<meta name=""keywords"".+content=""(.+)""/>"); 31 string name = ma_name.Groups[1].Value.ToString().Split(',')[0]; 32 33 // 获取章节目录 34 Regex reg_mulu = new Regex(@"<table cellspacing=""1"" cellpadding=""0"" bgcolor=""#E4E4E4"" id=""at"">(.|\n)*?</table>"); 35 var mat_mulu = reg_mulu.Match(html); 36 string mulu = mat_mulu.Groups[0].ToString(); 37 38 // 匹配a标签里面的url 39 Regex tmpreg = new Regex("<a[^>]+?href=\"([^\"]+)\"[^>]*>([^<]+)</a>", RegexOptions.Compiled); 40 MatchCollection sMC = tmpreg.Matches(mulu); 41 if (sMC.Count != 0) 42 { 43 //循环目录url,获取正文内容 44 for (int i = 0; i < sMC.Count; i++) 45 { 46 //sMC[i].Groups[1].Value 47 //0是<a href="http://www.23us.so/files/article/html/13/13655/5638725.html">第一章 泰山之巅</a> 48 //1是http://www.23us.so/files/article/html/13/13655/5638725.html 49 //2是第一章 泰山之巅 50 51 // 获取章节标题 52 string title = sMC[i].Groups[2].Value; 53 54 // 获取文章内容 55 string html_z = cra.HttpGet(sMC[i].Groups[1].Value, ""); 56 57 // 获取小说名字,章节中也可以查找名字 58 //Match ma_name = Regex.Match(html, @"<meta name=""keywords"".+content=""(.+)"" />"); 59 //string name = ma_name.Groups[1].Value.ToString().Split(',')[0]; 60 61 // 获取标题,通过分析h1标签也可以得到章节标题 62 //string title = html_z.Replace("<h1>", "*").Replace("</h1>", "*").Split('*')[1]; 63 64 // 获取正文 65 Regex reg = new Regex(@"<dd id=""contents"">(.|\n)*?</dd>"); 66 MatchCollection mc = reg.Matches(html_z); 67 var mat = reg.Match(html_z); 68 string content = mat.Groups[0].ToString().Replace("<dd id=\"contents\">", "").Replace("</dd>", "").Replace(" ", "").Replace("<br />", "\r\n"); 69 70 // txt文本输出 71 string path = AppDomain.CurrentDomain.BaseDirectory.Replace("\\", "/") + "Txt/"; 72 Novel(title + "\r\n" + content, name, path); 73 } 74 } 75 } 76 77 /// <summary> 78 /// 创建文本 79 /// </summary> 80 /// <param name="content">内容</param> 81 /// <param name="name">名字</param> 82 /// <param name="path">路径</param> 83 public void Novel(string content, string name, string path) 84 { 85 string Log = content + "\r\n"; 86 // 创建文件夹,如果不存在就创建file文件夹 87 if (Directory.Exists(path) == false) 88 { 89 Directory.CreateDirectory(path); 90 } 91 92 // 判断文件是否存在,不存在则创建 93 if (!System.IO.File.Exists(path + name + ".txt")) 94 { 95 FileStream fs1 = new FileStream(path + name + ".txt", FileMode.Create, FileAccess.Write);// 创建写入文件 96 StreamWriter sw = new StreamWriter(fs1); 97 sw.WriteLine(Log);// 开始写入值 98 sw.Close(); 99 fs1.Close(); 100 } 101 else 102 { 103 FileStream fs = new FileStream(path + name + ".txt" + "", FileMode.Append, FileAccess.Write); 104 StreamWriter sr = new StreamWriter(fs); 105 sr.WriteLine(Log);// 开始写入值 106 sr.Close(); 107 fs.Close(); 108 } 109 } 110 111 public string HttpPost(string Url, string postDataStr) 112 { 113 CookieContainer cookie = new CookieContainer(); 114 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url); 115 request.Method = "POST"; 116 request.ContentType = "application/x-www-form-urlencoded"; 117 request.ContentLength = Encoding.UTF8.GetByteCount(postDataStr); 118 request.CookieContainer = cookie; 119 Stream myRequestStream = request.GetRequestStream(); 120 StreamWriter myStreamWriter = new StreamWriter(myRequestStream, Encoding.GetEncoding("gb2312")); 121 myStreamWriter.Write(postDataStr); 122 myStreamWriter.Close(); 123 124 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); 125 126 response.Cookies = cookie.GetCookies(response.ResponseUri); 127 Stream myResponseStream = response.GetResponseStream(); 128 StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8")); 129 string retString = myStreamReader.ReadToEnd(); 130 myStreamReader.Close(); 131 myResponseStream.Close(); 132 133 return retString; 134 } 135 136 public string HttpGet(string Url, string postDataStr) 137 { 138 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url + (postDataStr == "" ? "" : "?") + postDataStr); 139 request.Method = "GET"; 140 HttpWebResponse response; 141 request.ContentType = "text/html;charset=UTF-8"; 142 try 143 { 144 response = (HttpWebResponse)request.GetResponse(); 145 } 146 catch (WebException ex) 147 { 148 response = (HttpWebResponse)request.GetResponse(); 149 } 150 151 Stream myResponseStream = response.GetResponseStream(); 152 StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8")); 153 string retString = myStreamReader.ReadToEnd(); 154 myStreamReader.Close(); 155 myResponseStream.Close(); 156 157 return retString; 158 } 159 } 160 }
补充:
有人说NSoup解析html更方便,可能不太会用。DLL下载地址http://nsoup.codeplex.com/
1 NSoup.Nodes.Document doc = NSoup.NSoupClient.Parse(html); 2 //获取小说名字 3 //<meta name="keywords" content="无疆,无疆最新章节,无疆全文阅读"/> 4 //获取meta 5 NSoup.Select.Elements ele = doc.GetElementsByTag("meta"); 6 string name = ""; 7 foreach (var i in ele) 8 { 9 if (i.Attr("name") == "keywords") 10 { 11 name = i.Attr("content").ToString(); 12 } 13 } 14 //获取章节 15 NSoup.Select.Elements eleChapter = doc.GetElementsByTag("table");//查找table,获取table里的html 16 NSoup.Nodes.Document docChild = NSoup.NSoupClient.Parse(eleChapter.ToString()); 17 NSoup.Select.Elements eleChild = docChild.GetElementsByTag("a");//查找a标签 18 //循环目录,获取正文内容 19 foreach (var j in eleChild) 20 { 21 string title = j.Text();//获取章节标题 22 23 string htmlChild = cra.HttpGet(j.Attr("href").ToString(), "");//获取文章内容 24 }
原文:http://www.cnblogs.com/cang12138/p/7464226.html
那是一座岛,岛上有青草,鲜花,美丽的走兽与飞鸟!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号