人工智能06 能计划的agent
能计划的agent
存储与计算
响应agent的动作功能几乎没有做任何计算。从本质上讲,这些agent执行的动作或者由他们的设计者、或者通过学习、或者通过演化过程、或者由以上几方面的组合来选择给他们的。
一个能在复杂环境下执行复杂任务的反应型agent需要大量的存储。而且,这样一个反应型机器的设计者需要有超人类的预见能力,要为该机器能遇到的所有可能情况预期一个合适的反应。首先,考虑反应型机器人的设计者必须做一些计算的动作函数。这些计算肯定需要时间,但是他们将减少agent的存储要求和设计者的负担。即时间换空间。
状态空间图
作为一个例子,让我们考虑一个有A、B、C三个玩具积木的网络空间,开始时,三个积木都在地板上。假设机器人的最终目标是将A放在B上面,B放在C上面,C放在地板上。
假定agent能通过一对环境模型——一个代表动作执行前的环境状态,另一个代表动作执行后的环境状态。用列表结构图标模型,可表示所有积木都在地面时能采取的所有动作模型。
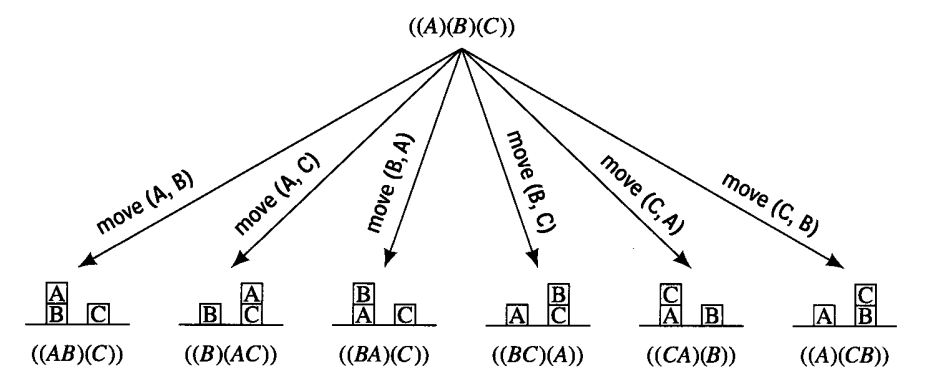
在这些情况中,((A,B),(C))和((A),(B,C))在某些方面似乎比其他更接近我们的目标(A,B,C),因此仅考虑单个动作的预期结果,agent可能宁愿执行动作move(A,B)或move(B,C)。在一个模拟环境中,只向前看一步常常就能产生有用的预期效果,但是多看几步,也许直到任务完成后的所有步骤都看到后就会发现一些捷径,从而避免走弯路。
如果大量可区分的环境状态足够小,那么一个代表所有可能动作和状态的图就能被显示的表达出来。如下图所示的状态空间图。每一个动作都是可逆的。从图中可以清楚地看到,如果初始状态是((A),(B),(C)),机器人任务是((ABC))的状态,那么他应该执行{move(B,C),move(A,B)}的动作序列。

从上图可以通过视觉容易地找到路径,然而为了发现路径,计算型agent要用各种图搜索过程。
-
顺着路径达到目标的所有弧的算子可以组合称为一个序列的计划。
-
搜索这个序列的过程称为规划。
-
这种从一系列动作结果得到的世界状态的预测过程称为规划方案。
显示状态空间搜索

从((BAC))转移到((ABC))的标记传播过程如下图所示,这种方法和所谓的广度优先算法相一致。


基于特征的状态空间
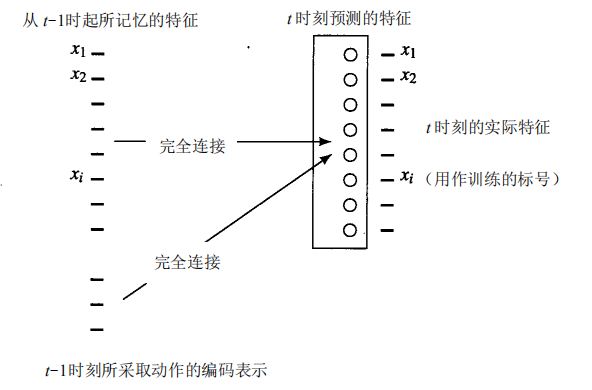
用图标模型标识节点来解释状态空间是相当直接的——可以很容易地使状态上的动作结果形象化。可以定义一个有特征标识的节点图,但此时,我们需要一种方法来描述一个动作是如何响应特征的。
例如,我们也可以训练一个网络,从它在t-1时刻的值和该时刻采取的动作来学习预测一个特征向量在时刻t时的值。如下图所示,虽然只显示了一层网络,但也可以使用具有隐藏单元的中间层。在训练后,预测网络能被用来计算来源于各种动作的特征向量。这些向量反过来又能作为网络的新输入来预测两步以后的特征向量,等等。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号