微软开源的Trill是什么?
以下是一篇15年的文章的译文:https://dwainegilmer.wordpress.com/2015/01/28/microsoft-trill-for-streaming-analytics-from-microsoft-research/
当今许多大数据应用程序套件的重点是数据存储。它们是围绕狭窄范围的数据集设想和设计的,通常是为了组织内的特定业务功能使用。
对新数据源的不断增加的需求使得许多BI应用程序在短短几年内就过时了。令人遗憾的是,对于许多公司而言,他们的大数据战略是存储数据,直到其实际业务价值可以在未来某个时间解锁。
在这些快节奏的时代,大多数企业迫切需要是实时的处理数据,而不是仅仅存储数据并应用一组工具进行滞后的离线分析。Trill则可以从数据中实时提取可用的知识和分析结果。基于实时的当前信息对决策提供可靠的支持和制定。这最终将改善整个决策过程。
流分析应用程序在数据到达时就可以开始搜索分析数据。而不是通过查询数据库以拉取数据信息流来进行分析,将常设查询应用于在捕获数据时产生事件(推送)的数据流。
与传统关系型数据库比较。SQL Server旨在存储和管理静态数据,Trill则旨在分析动态数据。基于Trill构建的应用程序将流传递给一组查询,这些查询分析数据并在找到匹配项时触发事件完成实时结果推送。
在大数据的新时代,公司正在竞相推出大数据系统。这些系统本质上是用于检查,转换,存储和建模业务数据的第一代紧耦合平台。Microsoft Trill(每天万亿事件)是Data Analytics层的一部分。
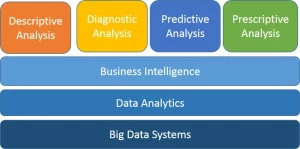
可以在Microsoft.com上可以找到介绍Trill的Microsoft Research(MSR)研究论文 。 Microsoft Trill是用于分析的流分析引擎或查询处理器。Trill被设计为大数据的查询处理器,有三个要求:
1) 查询模型:使用早期结果实时处理流式和关系查询,并提供离线查询;
2) 结构和语言集成:提供从高级语言库轻松访问,以便与现有分发结构和应用程序集成;
3) 性能:低延迟和高吞吐量。
与Apache Storm,Microsoft SQL StreamInsight,Vertica Shark和Naiad Spark流相比,Trill具有许多优势。Trill也将取代微软的StreamInsight。下面是Microsoft的图表,说明了差异并比较了功能集。
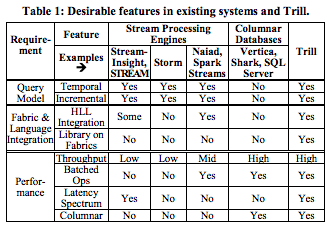
Trill具有时间语义化查询的能力,允许用户“通过实时或离线数据集的方式进行复杂查询”,并且由于分析引擎“在预期的使用场景中具有高性能”,因此可以比以前更快地获得结果。
Trill使用批量处理事件的新技术和算法。并且,这些批次中的数据以一种促使查询更有效地方式执行与组织。
结论
事实上,我们目前的总存储容量能提供的能力远远落后于存储新的和变化的数据流不断增长的需求。此种情况下很快就会引发以处理数据和流分析为处理方式的转变。
额外的阅读资料:
您可以从以下出版物中了解有关Trill的更多信息,或者从我们的幻灯片中了解更多信息pdf | pptx。
Trill现在是开源的,可以在GitHub上找到!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号