



结对项目-实现一个自动生成小学四则运算题目的命令行程序
姓名:何睿欣 吴腾烨
学号:3223003267 3123007877
Github链接:https://github.com/ZnZn-cat/3223003267/tree/main/xiaoxue
一.PSP表格
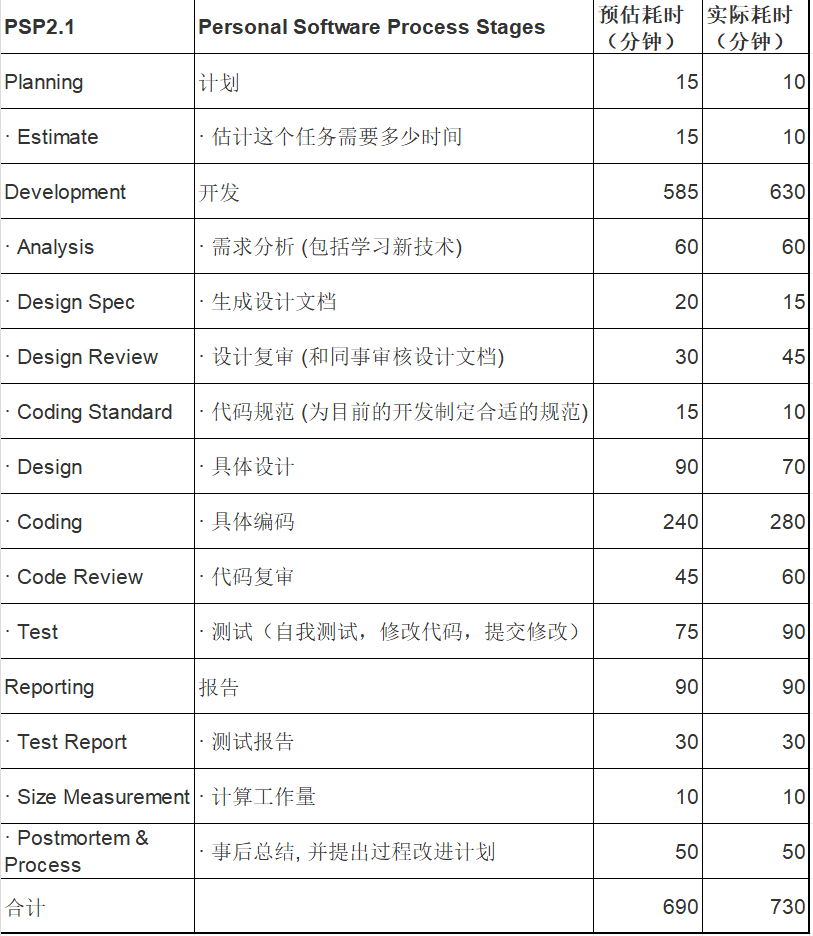
二.效能分析
1.时间花费: 我们大约花费了45分钟进行性能分析和优化。
2.改进思路:项目的核心需求之一是支持生成高达一万道不重复的题目。在初步实现后,我们预见到当生成大量题目时,性能瓶颈会出现在“检查题目是否重复”这一环节。如果每次生成新题目都与已有的数千个题目逐一比较,时间复杂度会非常高。我们的优化思路是:
(1)采用范式(Canonical Form): 为每一个表达式生成一个唯一的、与形式无关的字符串标识。例如,对于交换律a+b和b+a,我们规定其范式必须是操作数按字典序排序的形式。
(2)使用集合(Set)进行存储: 将所有已生成题目的范式字符串存储在一个Python的set数据结构中。set的查找操作平均时间复杂度为O(1),这使得检查重复的操作非常快,即使在已有一万个题目的情况下,也能瞬间完成判断。
三.设计实现过程
1.代码组织:我们的代码采用纯函数式的编程风格,将整个程序划分为多个职责明确的函数,没有定义任何类。这些函数可以分为五个逻辑模块:
(1)核心生成模块:
·generate_expression_tree: 递归生成表达式树的核心函数。
·create_operand: 创建一个操作数(自然数或真分数)。
(2)表达式计算模块:
·evaluate_expression: 递归计算表达式树的值。
(3)格式化与查重模块:
·format_fraction: 将 Fraction 对象格式化为指定的字符串。
·expression_to_string: 将表达式树转换为带括号的标准字符串。
·to_canonical_form: 将表达式树转换为唯一的范式字符串,用于查重。
(4)主业务逻辑模块:
·generate_problems: 负责生成指定数量的题目并写入文件。
·grade_files: 负责批改答案并生成统计报告。
(5)程序入口模块:
·main: 解析命令行参数,并根据参数调用不同的业务逻辑函数。
2.函数关系:函数之间的调用关系形成了一个清晰的层次结构。main 函数是顶层入口,它调用generate_problems或grade_files。generate_problems在循环中调用generate_expression_tree来获取表达式,并调用to_canonical_form来检查重复,最后用expression_to_string和evaluate_expression来生成题目和答案。
3.关键函数流程图:

四.代码说明
我们的代码实现中有几个关键部分,这里进行展示和说明。
1.表达式树的递归生成 (generate_expression_tree) 这是整个程序的核心,负责生成符合所有复杂约束的算术表达式。
def generate_expression_tree(max_ops: int, max_range: int):
# ... 省略基准情况 ...
ops = ['+', '-', '×', '÷']
op = random.choice(ops)
# ... 省略操作符分配 ...
while True:
left_child = generate_expression_tree(left_ops, max_range)
right_child = generate_expression_tree(right_ops, max_range)
left_val = evaluate_expression(left_child)
right_val = evaluate_expression(right_child)
# 应用题目约束: 减法结果不能是负数
if op == '-' and left_val < right_val:
# 如果不满足条件,则交换左右子节点
left_child, right_child = right_child, left_child
left_val, right_val = right_val, left_val
# 应用题目约束: 除法结果必须是真分数
if op == '÷':
if right_val == 0: continue
if left_val >= right_val: continue
# 如果所有约束都满足,返回生成的子树
return (left_child, op, right_child)
思路说明: 该函数通过递归构建表达式树。最精妙之处在于函数末尾的while True循环,它确保了任何不满足“减法不出负数”和“除法结果为真分数”的随机组合都会被抛弃并重新生成,直到一个完全合规的表达式树节点被创建出来为止。
2.表达式范式生成与查重 (to_canonical_form) 为了实现高效且准确的查重,我们设计了这个函数来为每个表达式生成一个唯一的身份证。
def to_canonical_form(expression) -> str:
"""
将表达式树转换为唯一的范式字符串以进行查重 。
对于+和×,子表达式的范式字符串按字典序排序。
"""
if isinstance(expression, Fraction):
return str(expression.numerator) + '/' + str(expression.denominator)
left, op, right = expression
left_canonical = to_canonical_form(left)
right_canonical = to_canonical_form(right)
# 核心查重逻辑:对于满足交换律的+和×运算符
if op in ['+', '×']:
# 将其左右子节点的范式字符串按字典序排序。
if left_canonical > right_canonical:
left_canonical, right_canonical = right_canonical, left_canonical
return f"({left_canonical}{op}{right_canonical})"
思路说明: 此函数同样采用递归。关键在于,当遇到+或×这种满足交换律的运算符时,它会强制将左右两边子表达式的范式字符串按字典顺序进行排序。这样一来,无论原始表达式是1 + 2还是2 + 1,它们生成的范式字符串都是完全相同(1/1+2/1),从而达到了查重的目的。
五.测试运行
我们设计了以下10个测试用例,覆盖了程序的各种功能和边界条件,以确保其正确性。
1.参数健壮性测试 (缺少 -r)
·命令: python test.py -n 10
·预期输出: 程序报错并打印帮助信息,提示-r参数是必须的 。
·目的: 验证程序能正确处理错误的参数输入。
2.基本功能测试
·命令: python test.py -n 5 -r 10
·预期输出: 成功生成Exercises.txt和Answers.txt文件,各包含5道题目和答案。
·目的: 验证程序最基本生成功能。
3.边界条件测试 (最小范围)
·命令: python test.py -n 3 -r 2
·预期输出: 成功生成3道题目,题目中的数值只包含0, 1和分母为2的真分数(1/2)。
·目的: 测试在最小数值范围下的生成逻辑。
4.减法约束测试
·命令: python test.py -n 20 -r 15
·预期输出: 手动检查Exercises.txt中所有减法运算,确保不存在a - b而a的值小于b的情况。
·目的: 验证“计算过程不能产生负数”规则的正确性。
5.除法约束测试
·命令: python test.py -n 20 -r 10
·预期输出: 手动检查Exercises.txt中所有除法运算,确保结果都是真分数。
·目的: 验证“除法结果应是真分数”规则的正确性。
6.括号生成测试
·命令: python test.py -n 10 -r 20
·预期输出: 生成的题目中应包含括号,例如(1 + 2) × 3,且括号的使用符合运算优先级规则。
·目的: 验证expression_to_string函数处理运算优先级的逻辑。
7.查重功能测试
·命令: 连续两次运行 python test.py -n 2 -r 3
·预期输出: 由于范围极小,第二次运行时可能会花费更长时间或生成与第一次完全不同的题目,证明查重机制在起作用。
·目的: 间接验证查重逻辑的有效性。
8.压力测试
·命令: python test.py -n 10000 -r 20
·预期输出: 程序能够在合理时间内(如一分钟内)成功生成10000道题目。
·目的: 验证程序能支持一万道题目的生成需求。
9.批改功能测试 (全对)
·前置: 运行 -n 10 -r 10 生成文件,然后复制 Answers.txt 为 MyAnswers.txt。
·命令: python test.py -e Exercises.txt -a MyAnswers.txt
·预期输出: 生成 Grade.txt,内容为 Correct: 10 (...) 和 Wrong: 0 ()。
·目的: 验证批改功能的正确性。
10.批改功能测试 (部分对错)
·前置: 基于上一条,手动修改 MyAnswers.txt 中的3个答案为错误答案。
·命令: python test.py -e Exercises.txt -a MyAnswers.txt
·预期输出: 生成 Grade.txt,内容为 Correct: 7 (...) 和 Wrong: 3 (...) 。
·目的: 验证批改功能对错误答案的统计能力。
六.实验小结
·总结成败得失:
本次结对项目总体上是成功的。我们顺利地实现了作业要求的所有核心功能和附加功能,特别是在表达式查重这一难点上,通过设计“范式字符串”的方案,给出了一个高效且优雅的解决方案。最大的挑战来自于需求的细节。例如,“3+(2+1)和1+2+3这两个题目是重复的”这一描述,背后关联到加法的交换律和结合律,如何用程序去定义和识别这种“等价性”是我们在设计阶段讨论最久的问题。我们最终通过对交换律进行排序处理,简化并解决了一部分问题。
·经验教训:
1.在动手编码前,我们花费了大量时间修改表达式树的数据结构和查重算法,这使得后续的编码过程非常顺畅。
2.Git很重要: 清晰的Git提交记录(commit message)和分支管理让我们在协作中没有出现任何代码冲突或覆盖的问题,是团队协作的基石。
3.结对优势: 结对编程模式效果显著。一个人在编码时,另一个人可以实时复审,或者思考即将到来的测试用例。很多逻辑漏洞和笔误在刚刚出现时就被发现和纠正了,大大减少了后期调试的时间。
·结对的感受与分享:
何睿欣的分享:这次合作非常愉快。吴腾烨同学写代码非常严谨,尤其是在测试环节,他考虑到了很多我忽略的边界情况,确保了我们程序的健壮性。从他身上我学到了,一个好的程序不仅要实现功能,更要能稳定地应对各种异常输入。他的闪光点就是这种对质量的极致追求。
吴腾烨的分享:我非常佩服何睿欣同学的算法设计能力。当我还在纠结如何处理查重时,她很快就提出了“范式”这个核心思路,并设计出了递归生成范式字符串的算法,一下子就解决了项目的最大难点。她的闪光点是能迅速抓住问题的本质并设计出创造性的解决方案。这次合作让我认识到,清晰的算法思路是高效开发的灵魂。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号