ACAM,SA,SAM,PAM小结
\(\texttt{Part0 Update Log}\)
-
\(4.29\) 开始。
-
\(5.5\) \(10k\) 字。
-
\(8.1\) 在弃置了非常久之后重新开始写。
\(\texttt{Part1.ACAM}\)
\(\texttt{Part1.1}\) 作用
\(\texttt{KMP}\) 可以在 \(\mathrm O(n)\) 的时间内做单模式匹配。而 \(\texttt{ACAM}\) 则是将 \(\texttt{KMP}\) 和 \(\texttt{Trie}\) 树相结合,其可以做到在 \(\mathrm O(n)\) 的时间内完成多模式匹配。
\(\texttt{Part1.2}\) 流程
一般来说,建造一个 \(\texttt{ACAM}\) 需要以下几个步骤:
-
把所有的模式串插入到一个 \(\texttt{Trie}\) 中。
-
对 \(\texttt{Trie}\) 树上所有的结点构造失配指针(即 \(\texttt{fail}\) 指针)。
-
匹配。
此时我们定义状态 \(u\) 的 \(\texttt{fail}\) 指针指向其最长真后缀,接下来考虑如何求出一个点的 \(\texttt{fail}\)。考虑使用 \(\texttt{bfs}\) 求解,此时设当前节点为 \(u\),其父亲 \(f\) 通过 \(c\) 连向 \(u\)。
-
若 \(fail_f\) 通过 \(c\) 连接到的子节点 \(w\) 存在,则令 \(fail_u \leftarrow w\)。
-
否则继续寻找 \(fail_{fail_f}\),直到跳到根。
-
假如跳到了根都没有找到答案,则令 \(fail_u = rt\)。
我们发现第二个操作的复杂度为 \(\mathrm O(n)\),此时可以用路径压缩来优化,即若 \(u\) 没有出边 \(c\),则令 \(tr(u,c) \leftarrow tr(fail_u,c)\)。
接下来考虑如何做文本串匹配。其实就是考虑如何从 \(S[1,i - 1]\) 的状态转移到 \(S[1,i]\) 的状态。
不难发现我们只需要不断地跳 fail 指针即可,结束状态为 \(S[1,i]\),但是由于我们在求 \(\texttt{fail}\) 指针的时候已经路径压缩过了,所以直接跳 \(\texttt{ch}\) 即可。
跑到状态 \(u\) 时,\(u\) 在 \(\texttt{fail}\) 树上到根的链上所有的终止节点都是其后缀,都会产生匹配。问题转化为 \(\texttt{fail}\) 树上的链上求和,树上差分转化为单点加-子树求和。在多次询问的时候为了保证复杂度,需要受用树状数组维护。
\(\texttt{Part1.3}\) 例题
考虑对 \(S_{1 \sim n}\) 建立正串、反串各建个 \(\texttt{ACAM}\)。此时考虑枚举前缀 \(T[1,k]\),则只要将作为 \(T[1,k]\) 后缀的 \(S\) 的数量与作为 \(T[k + 1,|T|]\) 前缀的 \(S\) 的数量相乘即可。这两个信息可以表示为 \(\texttt{fail}\) 树上的链求和。
考虑对于 \(S\) 建出其 \(\texttt{ACAM}\),查询串 \(t\) 就是在这个 \(\texttt{ACAM}\) 跳。假设此时我们通过 \(t_i\) 跳到了状态 \(p\),那么 \(p\) 到 \(\texttt{trie}\) 树的根节点这条路径上的所有节点都会重现出现一次,于是现在就要维护的操作就是单点修改+链和然后再将其转换为子树修改+单点查询,此时就可以用 \(\texttt{dfs}\) 序 + \(\texttt{BIT}\) 维护这两个操作了。
先对模式串建出 \(\texttt{ACAM}\)。考虑定义 \(dp_i\) 表示 \(i\) 的前缀能否被拼出来,这个转移可以直接在 \(\texttt{fail}\) 树上跳。注意到 \(\max |S_i| \le 10\),考虑状压。定义 \(g_u\) 为状态 \(u\) 跳 \(\texttt{fail}\) 到根路径上的终止节点状态。然后就可以做到线性复杂度了。
对于所有的 \(s_i\) 建出 \(\texttt{ACAM}\),然后对于新加入的 \(t\) 求出他的贡献。和前几题是一样的,此时假设匹配经过的节点为 \(p_1,p_2,\cdots \cdots p_{|t|}\),但是这题不同的是对于同一个字符串只能计算 \(1\) 次贡献。所以我们可以按照这些点的 \(\texttt{dfs}\) 序排个序,然后在 \(p_i\) 上打个标记为 \(+1\),在 \(\text{lca}(p_i,p_{i-1})\) 上打个标签为 \(-1\),然后再用 \(\texttt{BIT}\) 维护以下即可。
\(\texttt{Part2.SA}\)
\(\texttt{Part2.1}\) 后缀数组是什么?
在此我们约定后缀 \(i\) 指 \(s[i:n+1]\)。
我们定义 \(sa_i\) 表示将所有后缀排序后第 \(i\) 小的后缀编号,\(rk[i]\) 表示后缀 \(i\) 在排完序后的排名。所以我们就会有一个重要的性质即 \(sa_{rk_i} = rk_{sa_i} = i\)。
\(\texttt{Part2.2}\) 如何求出后缀数组?
首先我们会有一个 \(\mathrm O(n^2 \log n)\) 的做法,即用 sort 去对于每个后缀进行排序。
此时我们考虑使用倍增求解。具体过程如下:
-
先对于字符串当中所有长度为 \(1\) 的字串进行排序,得到 \(sa_1\) 和 \(rk_1\)。这里可以使用基数排序
-
用两个长度为 \(1\) 的字符进行排序,即用 \(rk_1[i]\) 和 \(rk_1[i + 1]\) 进行排序,然后我们就可以得到 \(rk_2[i]\) 和 \(sa_2[i]\) 了。然后依次类推即可。
由于 \(rk_w[i]\) 是 \(s[i:i + w]\) 的排名,所以当 \(w \ge n\) 时,这个就是我们的后缀数组了。由于基数排序的复杂度是 \(\mathrm O(n)\) 的,所以我们的复杂度就是 \(\mathrm O(n \log n)\)。
\(\texttt{Part2.3 hight}\) 数组
我们定义 \(hight_i = |\text{lcp}(sa_i,sa_{i - 1})|\)。其中 \(\text{lcp}\) 为最长公共前缀。一般的我们定义 \(hight_i = 0\)。
\(hight\) 数组就有一个通俗的方法,即哈希+二分,但是这个做法不一定会对,应为哈希可能或被卡,并且他的复杂度是 \(\mathrm O(n \log n)\) 的,不够优秀。此时我们引出一个引理 \(hight_{rk_i} \ge hight_{rk_{i-1}} - 1\)。所以我们就可以 \(\mathrm O(n)\) 求出 \(hight\) 数组了。代码如下。
for(int i = 1,k = 0;i <= n;i++)
{
if(!rk[i])continue;k -= (bool)k;
while(s[i + k] == s[sa[rk[i] - 1] + k])k++;
hight[sa[i]] = k;
}
由于 \(k\) 最多只会减 \(n\) 次,所以最多加 \(2n\) 次,所以复杂度就是 \(\mathrm O(n)\)。
这里给出 SA 的完整代码:
void Sort()
{
for(int i = 0;i <= m;i++)cnt1[i] = 0;
for(int i = 1;i <= n;i++)cnt1[rk[i]]++;
for(int i = 1;i <= m;i++)cnt1[i] += cnt1[i - 1];
for(int i = n;i >= 1;i--)sa[cnt1[rk[ord[i]]]--] = ord[i];
}
void SA()
{
int ans = 0,sum = 0;
memset(rk,0,sizeof(rk));
memset(sa,0,sizeof(sa));
memset(hight,0,sizeof(hight));
memset(ord,0,sizeof(ord));
memset(cnt,0,sizeof(cnt));
memset(a,0,sizeof(a));
m = 2500;
for(int i = 1;i <= n;i++)rk[i] = s[i],ord[i] = i;
Sort();
for(int w = 1,p = 0;p < n;m = p,w <<= 1)
{
p = 0;
for(int i = 1;i <= w;i++)ord[++p] = n - w + i;
for(int i = 1;i <= n;i++)if(sa[i] > w)ord[++p] = sa[i] - w;
Sort();
for(int i = 1;i <= n;i++)swap(ord[i],rk[i]);
rk[sa[1]] = p = 1;
for(int i = 2;i <= n;i++)rk[sa[i]] = (ord[sa[i - 1]] == ord[sa[i]] && ord[sa[i - 1] + w] == ord[sa[i] + w]) ? p : ++p;
}
int k = 0;
for(int i = 1;i <= n;i++)
{
if(k)k--;
while(s[i + k] == s[sa[rk[i] - 1] + k])k++;
hight[rk[i]] = k;
}
}
\(\texttt{Part2.4}\) 例题
考虑化简原式。
所以我们就只需要维护后面的式子即可。此时我们给出一个结论:
\(rk_i < rk_j\) 则 \(|\text{lcp}(i,j)| = \min^{rk_j}_{k = rk_i + 1} hight_k\)
给出一个图像应该更好理解一点:(本图来自 Alex_Wei 老师的博客)
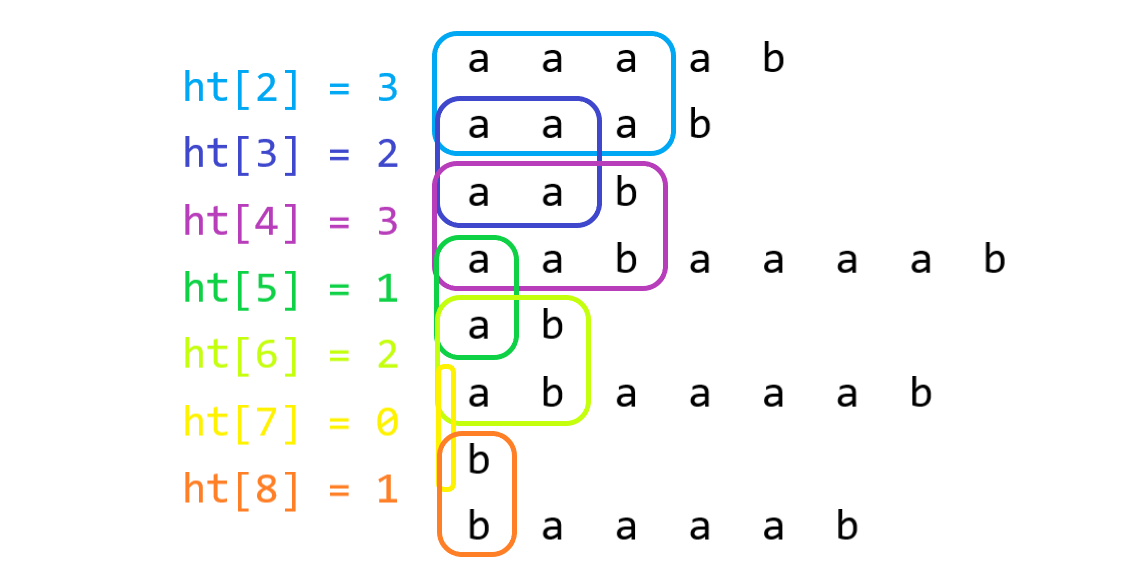
所以本题就变为了每个区间的区间最小值之和,可以使用单调栈进行维护。
我们发现一对 \(r\) 相似的酒一定是一对 \(r-1\) 相似的,\(r-2\) 相似的。于是我们可以倒叙枚举将其转化为 \([\text{lcp}(i,j) = r]\)。在根据上面那个题的结论,我就需要求出有多少对 \([l,r]\) 满足 \(\min^{rk_r}_{k = rk_l + 1} hight_k = r\)。
对于这个问题,我们可以先对 \(hight\) 进行排序,然后从大到小插入 \(hight\),再插入的时候并查集来维护,具体的对于,每一个连通块维护其的大小和最大值和最小值,然后每一次加入一个 \(r\) 可以将两边的并查集合并为一个并查集。然后就做完了。
答案很明显有单调性,所以考虑使用二分。假设答案为 \(len\),我们有:
-
我们可以找到一个子串 \(\texttt{ans}\) 完全位于 \([a,b]\) 之间,则 \(\texttt{ans}\) 的开头应该位于 \([a,b−len+1]\) 之间。
-
\(\texttt{lcp}(\texttt{ans},s[c:n+1]) \ge len\)。
假如第二个性质是成立的,则 \(\texttt{ans}\) 的前缀一定是开头包含 \(c\) 的连续区间,对于这个区间我们考虑二分。所以先在只需要考虑如何验证第一个限制了。
我们发现第一个操作就是这个区间里面是否有一个位置 \(i\),满足 \(sa_i \in [a,b - len + 1]\),这个东西我们可以用主席树来维护。最值时间复杂度为 \(\mathrm O(n \log^2 n)\)。
我们可以把条件变为 \(A_i - A_j = B_i - B_j\)。所以我们就可以考虑将其转化为差分序列。
那么现在就变为了要求出这个差分序列当中不相交并且不相临的的子串对数。这个很不好求,于是我们考虑使用容斥将其转化为所有的情况减去相交或相邻的相等子串情况。
套路的,我们将 \(hight\) 进行排序,从大到小去插入,同时加上两个连通块 \(x,y\) 的贡献,即 \(\sum_{i \in x} \sum_{j \in y} \max(0,w + 1 - |i - j|)\),其中的 \(w\) 为当前的 \(hight\) 值。
考虑对于更小的集合 \(y\) 进行枚举。我们发现当 \(i \in [j - w,j) \cup (j,j + w]\) 时,\(w + 1 - |i - j| > 0\)。所以就变为在线段树 \(T_x\) 上查询 \([j − w,j)\) 以及 \((j,j + w]\) 两个区间位置个数与下标之和,然后在将 \(T_x\) 和 \(T_y\) 和并即可。时间复杂度 \(\mathrm O(n \log^2 n)\)。
用容斥 + SA + 线段树合并。但是更好的做法是用 SAM。
\(\texttt{Part3.SAM}\)
\(\texttt{SA}\) 无法表达出所有的后缀的信息,而此时我们就需要一个更加优秀的数据结构来表达后缀之间的联系。
\(\texttt{Part3.1}\) 后缀树
由于我们需要表达很多个后缀之间的联系,所以我们考虑将所有后缀都插入到一颗字典树上,此时我们就得到了一颗后缀字典树。而后缀字典树有一个很明显的劣势就是他的空间复杂度在最坏情况下是 \(\mathrm O(n^2)\) 的。
此时我们发现其实之后每一个后缀的最后一个节点是必须保留的,而中间的单链可以压缩起来,变为一个串字符。这个过程其实就是对于后缀字典树建虚树。此时我们的节点数就被降到了 \(\mathrm O(n)\) 级别的了。
而对于储存字符串的空间复杂度也是 \(\mathrm O(n^2)\) 的问题,我们发现由于从初始节点开始到当前这个节点一定是原串的子串,于是我们只需要纪录他在原串的开始位置 \(\text{startpos}_x\) 和长度 \(\text{len}_x\) 即可。这样的结构就是后缀树。
那么构建后缀树的方法也就很简单了,考虑建虚树的方法。我们发现 \(\texttt{dfs}\) 序实际上就是后缀数组的顺序,而求 \(\texttt{lca}\) 就相当于求 \(sa_i\) 和 \(sa_{i - 1}\) 的最长公共前缀,这个操作可以直接用 \(hight\) 数组 \(\mathrm O(1)\) 求出,所以建一个后缀树的时间就是 \(\mathrm O(n)\) 的。
\(\texttt{Part3.2 SAM}\) 的构建方法
我们考虑将 \(s\) 反转得到 \(s^R\),然后对其建出后缀树,而 \(\text{startpos}\) 也变为了 \(\text{endpos}\),我们称这颗后缀树为 \(\text{endpos}\) 树。
我们发现 \(\text{endpos}\) 树拥有以下几个性质:
-
串的最小长度为 \(len_{fa_x} + 1\)。
-
串的最长长度为 \(len_{x}\)。
-
在 \(\text{endpos}\) 树中我们称 \(x\) 的父亲为 \(parent_x\)。
-
任何 \(s\) 的子串都会被精准的分在 \(\text{endpos}\) 树的某一个节点上。
此时我们需要考虑如何构建一颗 \(\text{endpos}\) 树。假设我们已经获得了 \(s[:i]\) 的 \(\text{endpos}\) 树。此时我们想在这棵树上加上字符 \(s[i]\),即此时的 \(\text{endpos}\) 树考虑的是 \(s[:i+1]\) 的所有后缀。
我们对于 \(s[:i+1]\) 的后缀从长到短去考虑。\(s[:i+1]\) 本身出现的位置仅在 \(\{i\}\),所以他必定是一个新的叶子节点,我们将这个节点命名为 \(np\),而 \(len_{np} = i + 1\)。接下来考虑 \(s[:i+1]\) 的后缀逐渐变短的情况。
假如 \(s[j:i+1]\) 出现在新位置 \(k\) 上,则 \(s[j:i]\) 一定会出现在 \(k-1\) 的位置上。这边启发了我们去参考 \(s[:i]\) 后缀的结束位置情况来求出 \(s[:i+1]\) 后缀的结束情况。
我们考虑先找到对应于 \(s[:i]\) 的节点,记作 \(lst\),而 \(s\) 后缀的结束位置情况,我们就保存在 \(lst\) 和她用 \(parent\) 链接的祖先中。在所有的结束位置当中,我们感兴趣其实就是下一个字符是 \(s[i]\) 的那一部分。
此时我们对于任意节点 \(x\) 和字符 \(c\),\(trans_{x,c}\) 表示在字符串 \(x\) 后新加一个字符 \(c\) 后会在哪一个节点。假如这个字符串比不存在,则 \(trans_{x,c} = -1\)。
此时我们考虑如何找到在其他位置上的 \(s[:i+1]\) 后缀的长度。为了找到这个长度,我们参考 \(s[:i]\) 的后缀。所以我们令 \(p\) 从 \(lst\) 开始,不断查找 \(parent\),一次从长到短枚举 \(s[:i]\) 的后缀。
如果 \(trans_{p,s[i]} = -1\),说明 \(p\) 的结束集合没有以 \(s[i]\) 为下一个字符的。因此,新添加字符 \(s[i]\) 以后,\(s[:i+1]\) 会成为 \(p\) 后面加 \(s[i]\) 的唯一选择。于是我们令 \(trans_{p,s[i]} = np\)。但是如果一直枚举到了根并且 \(trans_{p,s[i]}\) 始终为 \(-1\),说明字符 \(s[i]\) 为首次出现,所以我们直接令 \(parent_{np} = root\) 即可。
否则我们找到第一个 \(trans_{p,s[i]}\) 不等于 \(-1\) 的点 \(p\),令 \(q = trans_{p,s[i]}\)。这意味着 \(s[:i]\) 的后缀长度减小到 \(len_p\) 的时候,他终于在下一个字符是 \(s[i]\) 的结束位置出现,这也意味着 \(s[:i+1]\) 的后缀长度减小到 \(len_p + 1\) 时,他就会在其他的位置上出现。但是未必一定有 \(len_q = len_p + 1\)。所以我们需要对其进行分类。
我们考虑先处理最简单的情况,即 \(len_q = len_p + 1\)。在这种情况下,\(q\) 不需要进行改动,此时我们有 \(parent_{np} = q\)。
接下来,我们处理更复杂的 \(len_q > len_p + 1\) 的情况。和前面一样,这表示加入 \(s[i]\) 以前,这些节点 \(q\) 所代表的子串的出现结束位置在长度为 \(len_p+1\) 时相同,在长度达到 \(len_q\) 时,也是相同的。
而加入 \(s[i]\) 之后,这一点被破坏了。在长度不超过 \(len_p+1\) 时,这些子串会额外出现在结束位置 \(i\) 上,但是长度在 \(len_p+2\) 和 \(len_q\) 之间时则不会出现在结束位置 i 上。
我们现在考虑将 \(q\) 分为小于等于 \(len_q + 1\) 和 \(>len_p+1\) 两段考虑,前一段的出现结束集合加入 \(i\),后一段则不变。为此,我们新建一个节点 \(nq\),用来表示前一段的状态,而 \(q\) 则改为表示后一段的状态。
首先,我们假设 \(len_{nq} = len_q + 1,parent_{nq} = parent_q\)。按照之前的定义 \(parent_q = parent_{np} = nq\)。接下来考虑如何更新 \(trans\)。对于任意 \(nq\),以及其祖先节点 \(q_2\)。尽管 \(\text{endpos}\) 集合多增加了一个 \(i\),但是由于 \(i\) 在其末尾,后面无法增加任何字符串 \(c\),所以这个 \(i\) 并不会对其 \(trans\) 产生任何影响。
不过,\(p\) 和他的祖先的转移函数 \(trans\) 可能改变。从 \(p\) 开始,不断查找 \(parent\) 来枚举 \(p\) 的后缀。
-
若 \(trans_{p,s[i]} = q\),需在 \(trans_{p,s[i]}\) 中引入新结束位置 \(i\),即将其修改为 \(nq\),然后继续查找。
-
若 \(trans_{p,s[i]}\) 是 \(q\) 的祖先(同时也是 \(nq\) 的祖先),因其 \(\text{endpos}\) 集合已新增 \(i\),后续无需修改。
而此时的 \(\text{endpos}\) 树也更新完了。而为了求解 \(\text{endpos}\) 树而引入的 \(trans\) 和 \(parent\) 可以在一起组成一个自动机,这就是 \(\texttt{SAM}\)。
使用这个算法来构建的 \(\text{endpos}\) 树的复杂度为 \(\mathrm O(|s||\sum|)\),其中 \(s\) 为字符集的总长度。假如使用哈希来转移 \(trans\),复杂度即为 \(\mathrm O(|s|)\),如果使用平衡树来维护 \(trans\) 数组,则复杂度为 \(\mathrm O(|s| \log |\sum|)\)。
\(\texttt{Part3.3}\) 广义后缀自动机
我们知道 \(\texttt{SAM}\) 是对于一个字符的,而在这里我们需要对于 \(k\) 的字符串建 \(\texttt{SAM}\)。
接下来考虑如何构造广义 \(\texttt{SAM}\)。我们可以参考 \(\texttt{ACAM}\) 的结构,先建立 \(t_1,t_2,t_3 \cdots t_m\) 的字典树。然后我们用 \(\texttt{BFS}\) 来求出 \(trans\),具体的每当从队列当中取出 \(x\) 时,我们就以 \(x\) 的父亲的对应节点为 \(lst\),然后执行 \(x\) 的构建操作。此时如果使用哈希表来储存 \(trans\),则这个构建这个广义 \(\texttt{SAM}\) 的复杂度就是 \(\mathrm O(\sum |t|)\)。
但是广义 \(\texttt{SAM}\) 无法使用 \(\texttt{DFS}\) 来构建,所以广义 \(\texttt{SAM}\) 不支持动态添加字符串。
这里给出模板:P3346。
\(\texttt{Part3.4}\) 例题
对于所有的 \(t_i\) 建出一颗广义 \(\texttt{SAM}\)。
对于第 \(i\) 次询问 \(s[p_l,\cdots,p_r]\),我们考虑使用倍增确定其所在节点 \(u\),于是问题就被转化为求 \(u\) 子树内出现次数最多的标记的节点。考虑对于每一个节点开一颗动态开点线段树,给 \(t_i\) 所在的节点把 \(i\) 这个位置 \(+1\)。离线下来后用线段树合并,然后区间查询最大值即可。
考虑对于字符串建出 \(\texttt{SAM}\)。此时考虑在 \(\texttt{parent}\) 树上从根开始向下进行 \(\text{dp}\)。设 \(dp_i\) 表示到达节点 \(i\) 时的最大值。
如果一个父节点的子串在子节点的子串中出现了至少两次,则 \(dp\) 就 \(+1\)。那么此时的问题就是考虑如何判断是否出现了至少两次。
假设当前的节点为 \(x\),其父亲为 \(parent_x\)。找到 \(x\) 对应的 \(\text{endpos}\) 中的任意一个位置 \(pos\),\(pos\) 处 \(parent_x\) 的子串一定出现了一次。那么另一次只需要在 \([pos - len_x + len_{parent_x},pos - 1]\) 中出现过即可。
\(\texttt{Part4.PAM}\)
\(\texttt{Part4.1 PAM}\) 的引入
我们知道 \(\texttt{manachar}\) 可以在 \(\mathrm O(n)\) 的时间求解出一个字符串的所有回文串。但是 \(\texttt{manachar}\) 无法给我们带来更多的信息,例如回文子串之间的前/后缀关系。
由于回文串的性质,我们容易知道如果一个回文串 \(t\) 为另一个回文串 \(s\) 的前缀,则 \(t\) 必为 \(s\) 的后缀,即 \(s\) 的回文 \(\texttt{border}\)。此时我们想搞出一种数据结构能够维护这种回文 \(\texttt{border}\) 关系。
\(\texttt{Part4.2}\) 回文树
考虑对于一个回文 \(\texttt{border}\),我们关心最长的那个非平凡回文 \(\texttt{border}\),即为 \(\texttt{plink}_s\)。那么 \(s\) 的所有回文 \(\texttt{border}\) 均可以通过不断跳 \(\texttt{plink}_s\) 得到。考虑将 \(\texttt{plink}_s\) 视为 \(s\) 的父亲,那么我们就可以对于 \(s\) 的所有的回文子串建立出一颗树,这棵树就是回文树。
那么此时有一个定理就是对于一个字符串 \(s\) 的本质不同的回文子串数量是 \(\mathrm O(|s|)\) 级别的。
有了这个性质之后考虑如何快速构建一颗回文树。
假设我们已经获得了 \(s[:i]\) 的回文树,那么此时想要添加上 \(s[i]\) 获得 \(s[:i+1]\) 的回文树。我们注意到我们要额外考虑的就是 \(s[:i+1]\) 的所有回文后缀。那么此时假设 \(s[j:i+1]\) 为 \(s[:i+1]\) 的最长回文后缀。那么 \(s[j+1:i]\) 也为 \(s[:i]\) 的最长回文后缀。所以我们可以从 \(s[:i]\) 的最长回文后缀不断开始查找 \(\texttt{plink}\),从长到短开始枚举 \(s[:i]\) 的回文后缀 \(p\),知道找到满足 \(s[i - |p| - 1] = s[i]\) 的 \(p\),那么我们就找到了 \(s[:i+1]\) 的最长回文后缀 \(s[i] + p + s[i]\)。但是如果当 \(p\) 为空串 \(\zeta\) 的时候依然匹配不上,那么我们考虑令 \(\texttt{plink}_{\zeta}\) 为一个特殊的字符即可。同时认为 \(s[i] + \zeta + s[i] = s[i]\)。这个 \(\zeta\) 也就解决了如果回文串长度为奇的问题。
然后我们就得到了 \(s[:i+1]\) 的最长回文后缀 \(np = s[i] + p + s[i]\)。那么假如 \(np\) 不在这颗回文树上,此时考虑如何去插入他。
考虑对于任意的回文串 \(p\) 和字符 \(c\),定义 \(\texttt{trans}_{p,c}\),表示回文树上对应 \(c+p+c\) 的串,如果 \(\texttt{trans}_{p,c}\) 为空,那么表示 \(c+p+c\) 在回文树上不存在。
如果 \(np\) 在插入之前 \(\texttt{trans}_{p,s[i]}\) 已经非空,那么就不同做任何改动。否则我们需要在回文树中插入节点 \(np\),并令 \(\texttt{trans}_{p,s[i]} = np\),并求出 \(\texttt{plink}_{np}\)。由于 \(\texttt{plink}_{np}\) 为 \(np\) 的前缀,所以不用担心 \(np\) 不在回文树上。
我们可以从 \(\texttt{plink}_p\) 不断开始查找 \(\texttt{plink}\),从长到短开始枚举 \(s[:i]\) 的回文后缀 \(p^{\prime}\),知道找到满足 \(s[i - |p^{\prime}| - 1] = s[i]\) 的 \(p^{\prime}\),那么我们就找到了 \(np\) 的最长回文后缀 \(\texttt{border} \ \ q = s[i] + p^{\prime} + s[i] = \texttt{trans}_{p^{\prime},s[i]}\)。
这样我们就是 \(\mathrm O(|s||\sum|)\) 的时间内完成了回文树的构建。瓶颈在于处理 \(\texttt{trans}\)。
在这里给出构建回文树的代码:
void add(int c,int pos)
{
int p = getfail(lst,pos);
if(!ch[p][c])
{
int q = ++tot,tmp;len[q] = len[p] + 2;
tmp = getfail(plink[p],pos);
plink[q] = ch[tmp][c];ch[p][c] = q;
if(len[q] <= 2)trans[q] = plink[q];
else
{
tmp = trans[p];
while(s[pos - len[tmp] - 1] != s[pos] || ((len[tmp] + 2) << 1) > len[q])tmp = plink[tmp];
trans[q] = ch[tmp][c];
}
}
lst = ch[p][c];
}
\(\texttt{Part4.3}\) 回文自动机
考虑一个问题:我们在构建回文树时引入的 \(\texttt{trans}\) 能否和自动机的概念产生联系?
我们发现我们不断跳 \(\texttt{plink}\) 的过程非常像 \(\texttt{ACAM}\) 跳 \(\texttt{fail}\)。我们发现我们在构建或者跑串的时候和 \(\texttt{ACAM}\) 相比都多了一个检查,但是正是因为这个检查导致我们无法像 \(\texttt{ACAM}\) 的 \(\texttt{ch}\) 一样提前预处理,而是在跑串的时候额外处理一些信息,但是我们依然认为这是一个自动机。
当然 PAM 这类需要额外记录信息的自动机也就不叫有限状态自动机了,而是下推自动机,当然这不重要。
\(\texttt{Part4.4}\) 例题
考虑直接对于两个串建出 PAM。然后考虑在这两个 PAM 上 dfs,因为起始状态相同,那么如果遇到相同的转移就说明有相同的状态,把 \(siz_x \times siz_y\) 作为贡献加到答案里面即可求出答案。
好题。
因为和回文串有关,所以我们考虑把他扔到 PAM 里面。考虑在回文自动机的节点间建单向边,然后跑单源最短路。
-
光归:连边 \((i,fail_i,A)\),其中 \(\texttt{plink}_i\) 可以为 \(0\)。
-
光辉:连边 \((fail_i,i,B)\),其中 \(\texttt{plink}_i\) 可以为 \(0\)。
-
光隐:处理出来 \(i\) 的 \(fa_i\),然后连 \(k\) 条 \((i,fa_i,C)\) 的边。
-
光腾:
这个操作就不能直接连边了,因为我们发现这个操作其实是这个操作,本质上是从 \(i\) 以 \(D\) 的代价转移到 \(i\) 子树中的任意一个结点。这样不行,数量是 \(\mathrm O(|S|^2)\) 级别的。
考虑优化建图的思想,对每个点建立一个对应的虚点,而虚点只能往儿子的方向转移(花费为 \(0\))。那么我们只需要对于 \(i\) 连一条向 \(i\) 的虚点边权为 \(D\) 的边,然后 \(i\) 的虚点向 \(i\) 连一条边权为 \(0\) 的边即可。
- 光弋:这个操作做完了之后就不能做前面的 \(4\) 个操作了。所以这个操作我们考虑放到询问的时候再来做。
建完图之后我们跑一边 Dijkstra,然后定义 \(dis_i\) 表示到第 \(i\) 个点的最短路。
考虑询问。由于光戈操作只能由回文串在前面添加字符而来,故开始光戈前一定是询问串的一个回文后缀。
首先暴力跳 \(fail\) 是简单的,此时考虑如何优化。
我们发现跳 \(fail\) 时长度是在不断减小的,也就是查询的实际上是从根出发的一条链的最小值。
然后此时我们可以用倍增求出来第一个 \(len_p \le r - l + 1\)。然后我们就知道答案就是 \((r - l + 1) \times E + dis_p - len_p \times E\)。那么我们查询的复杂度就是 \(O(q \log n)\)。
那么时间复杂度就是 \(\mathrm O(k \times |S| + (k \times |S| + q) \log n)\)。
考虑将 \(s\) 的后半段翻转然后将其插入前面一半的空隙当中,即变为 \(s_1 s_n s_2 s_{n-1} \cdots \cdots\)。这样原串中本应满足回文关系的字符(串)在新串中就处于同一串中,由于题目要求对原串进行偶数长度划分,故我们只对新串进行偶数长度的回文划分。
那么我们现在的任务就是在 \(\mathrm O(n \log n)\) 的时间内解决将一个字符串划分为若干子串,使得每一段都是回文串,求方案数。
定义 \(dp_i\) 表示前 \(i\) 个位置的划分方案数,则有转移:
那么此时引入一个结论:
PAM的 \(\texttt{plink}\) 链上的 \(\texttt{len}\) 值的差一定构成若干个等差数列,并且数量在 \(\mathrm O(\log n)\) 级别。
但是我不会证明,所以跳过证明。此时考虑如何用这个性质去优化 dp。
设 \(dif_x = \texttt{len}_x - \texttt{len}_{\texttt{plink}_x}\),\(\texttt{slink}_x\) 为 \(\texttt{plink}\) 树上距离 \(x\) 最近的满足 \(dif_x \neq dif_y\) 的节点编号。
此时再定义 \(g_x = \sum_y dp_{i - \texttt{len}_y}\),其中的 \(y\) 为 \(x\) 在 \(\texttt{fail}\) 树上的祖先并且和 \(x\) 在同一个等差数列当中。
如果 \(x\) 和 \(\texttt{plink}_x\) 在同一等差数列里,则 \(g_x\) 和 \(g_{\texttt{plink}_x}\) 只相差一个 \(f_{i - len_z}\) ,其中 \(z\) 为 \(x\) 所在等差数列里最短的回文串,由定义易知 \(len_x = len_{\texttt{slink}_x} + dif_x\)。
然后我们维护这样的一个 \(g\),那么我们就很容易转移到 \(g_{\texttt{plink}_x}\),然后对于 \(f\) 直接变为暴力跳 \(\texttt{slink}\) 链计算贡献。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号