


第2章 入门必修:单、多层感知机
2-1 本章内容介绍

2-2 深度学习实施的一般过程
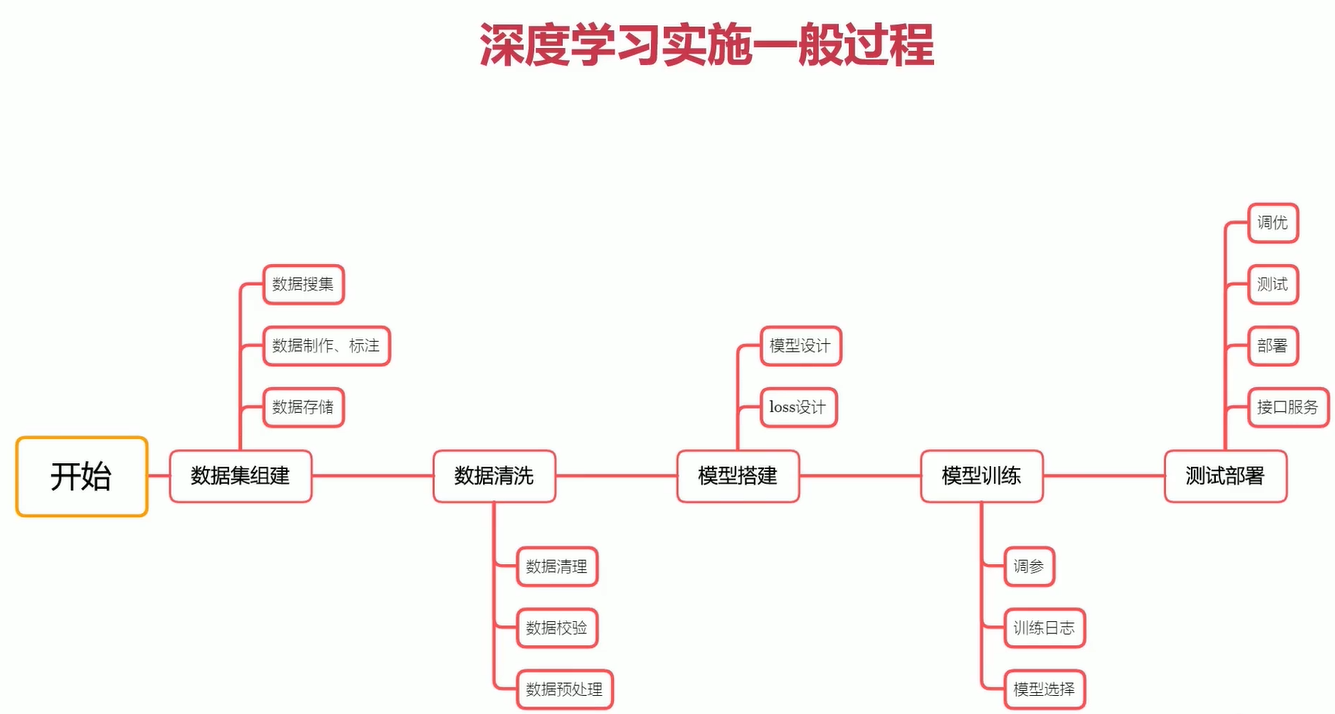
前两步可能占掉百分之七十的时间
2-3 逻辑回归

2-4 逻辑回归损失函数


这里的y(hat)是指概率,其取值从0到1,这个式子就是将每个样本预测的准确率相乘。
如果y(hat)是0.9,也就是预测1的概率是0.9,如果真实也是1,那么准确率就是0.9,
如果真实值是0,那么准确率就是1-0.9,也就是0.1。
所以这个L(w)的每一项,反映的是这个样本的准确率,每一项的准确率连成后就是L(w)本身,
即L(w)意思是:其值越大,那么整体预测的越准。
2-5 逻辑回归示例
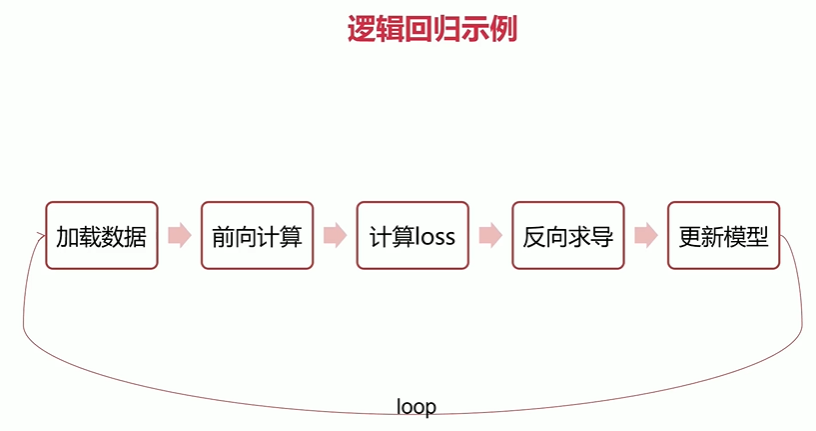
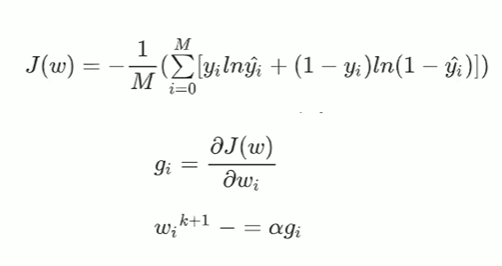
程序源码:
1 import torch 2 import torch.nn.functional as F 3 4 5 n_item = 1000 6 n_feature = 2 7 learning_rate = 0.001 8 epochs = 100 9 10 torch.manual_seed(123) 11 data_x = torch.randn(size=(n_item, n_feature)).float() 12 data_y = torch.where(torch.subtract(data_x[:, 0]*0.5, data_x[:, 1]*1.5) > 0, 1.0, 0).float() 13 14 15 class LogisticRegressionManually(object): 16 def __init__(self): 17 self.w = torch.randn(size=(n_feature, 1), requires_grad=True) 18 self.b = torch.zeros(size=(1, 1), requires_grad=True) 19 20 def forward(self, x): 21 y_hat = F.sigmoid(torch.matmul(self.w.transpose(0, 1), x)+self.b) 22 return y_hat 23 24 @staticmethod 25 def loss_func(y_hat, y): 26 return -(torch.log(y_hat)*y + (1-y)*torch.log(1-y_hat)) 27 28 def train(self): 29 for epoch in range(epochs): 30 for step in range(n_item): 31 y_hat = self.forward(data_x[step]) 32 y = data_y[step] 33 loss = self.loss_func(y_hat, y) 34 loss.backward() 35 with torch.no_grad(): 36 self.w.data -= learning_rate * self.w.grad.data 37 self.b.data -= learning_rate * self.b.grad.data 38 self.w.grad.data.zero_() 39 self.b.grad.data.zero_() 40 print('Epoch: %03d, loss%.3f' % (epoch, loss.item())) 41 42 43 if __name__ == '__main__': 44 lrm = LogisticRegressionManually() 45 lrm.train()
运行示例:
问题1:pytorch的配置
打开

运行下列代码
pip3 install torch -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
即可下载pytorch包
但这个包如何添加进pycharm环境是不清楚的,
尤其是对其中的Interpreter机制的运行。
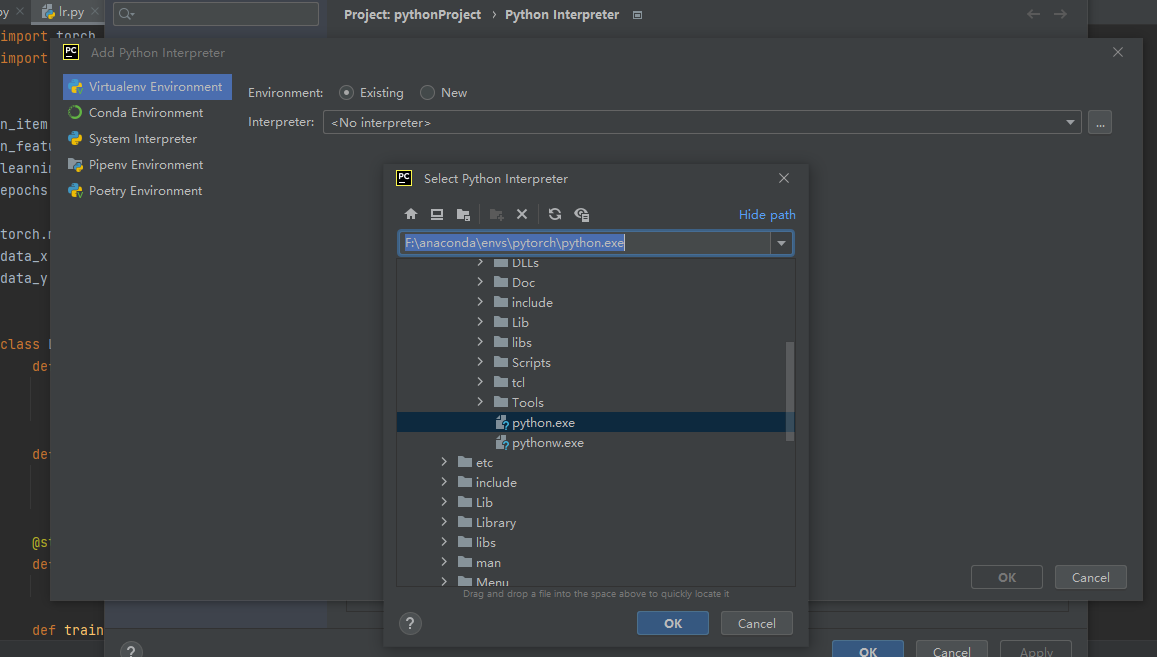
这个pytorch 其实是我将一个文件名为python的文件改名过来的,
当时我猜它下面其实是pytorch文件,
然后我把他移动到Anaconda的evs中,里面有python.exe文件
随后在Interpreter中选择这个路径就成功应用了包含pytorch的环境,
整个过程基本混乱,不清楚这个Interpreter是如何运转的。
移动并改名成pytorch的python文件如下:
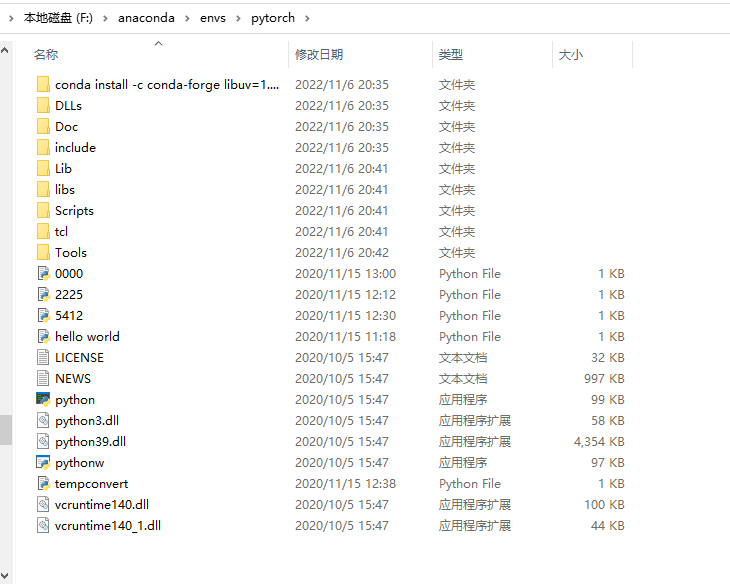
问题2:
虽然这个代码能跑但是这两行警告不清楚是什么情况。

2-6 单层、多层感知机
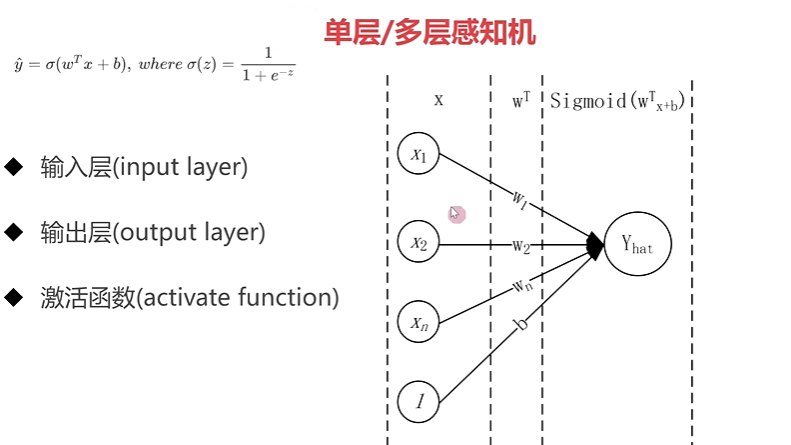
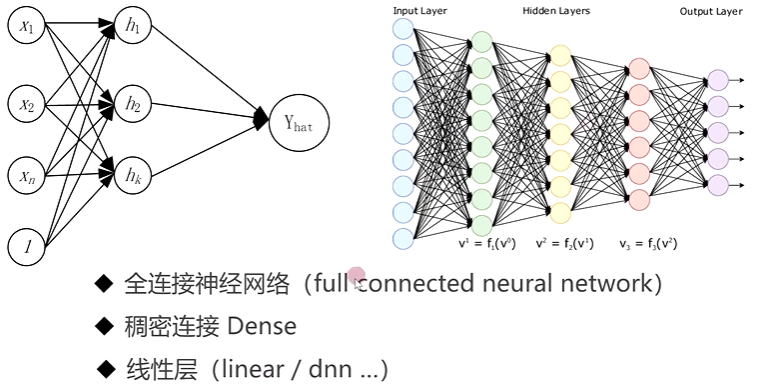
2-7 pytorch 构建单、多层感知机
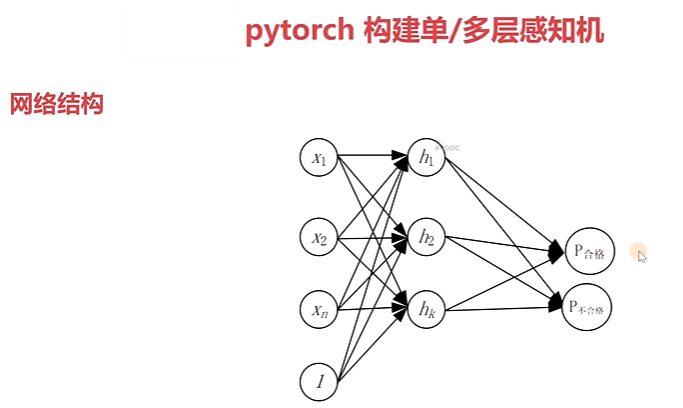
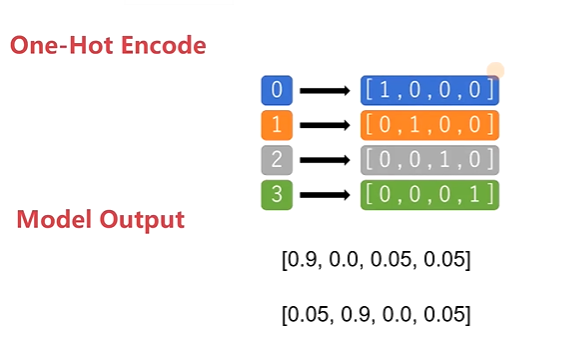
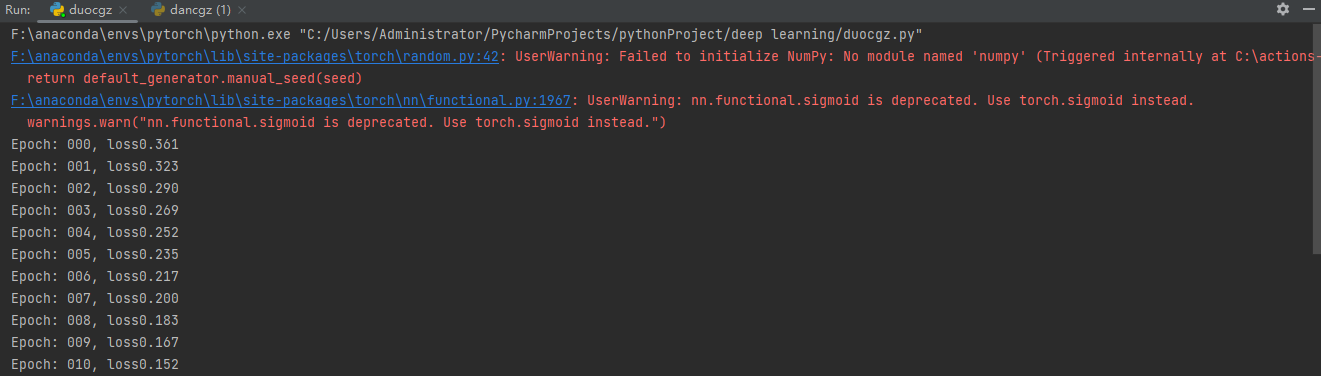
单层感知机代码示例:
1 import torch 2 from torch import nn 3 import torch.nn.functional as F 4 5 6 n_item = 1000 7 n_feature = 2 8 9 torch.manual_seed(123) 10 data_x = torch.randn(size=(n_item, n_feature)).float() 11 data_y = torch.where(torch.subtract(data_x[:, 0]*0.5, data_x[:, 1]*1.5) > 0, 1.0, 0).long() 12 13 data_y = F.one_hot(data_y) 14 15 16 class BinaryClassificationModel(nn.Module): 17 def __init__(self, in_feature): 18 super(BinaryClassificationModel, self).__init__() 19 self.layer_1 = nn.Linear(in_features=in_feature, out_features=2, bias=True) 20 21 def forward(self, x): 22 return F.sigmoid(self.layer_1(x)) 23 24 25 learning_rate = 0.01 26 epochs = 100 27 28 model = BinaryClassificationModel(n_feature) 29 30 opt = torch.optim.SGD(model.parameters(), lr=learning_rate) 31 32 criteria = nn.BCELoss() 33 34 for epoch in range(1000): 35 for step in range(n_item): 36 x = data_x[step] 37 y = data_y[step] 38 39 opt.zero_grad() 40 y_hat = model(x.unsqueeze(0)) 41 loss = criteria(y_hat, y.unsqueeze(0).float()) 42 loss.backward() 43 opt.step() 44 45 print('Epoch: %03d, loss%.3f' % (epoch, loss.item()))
输出示例:
太慢了就跑到这吧。。
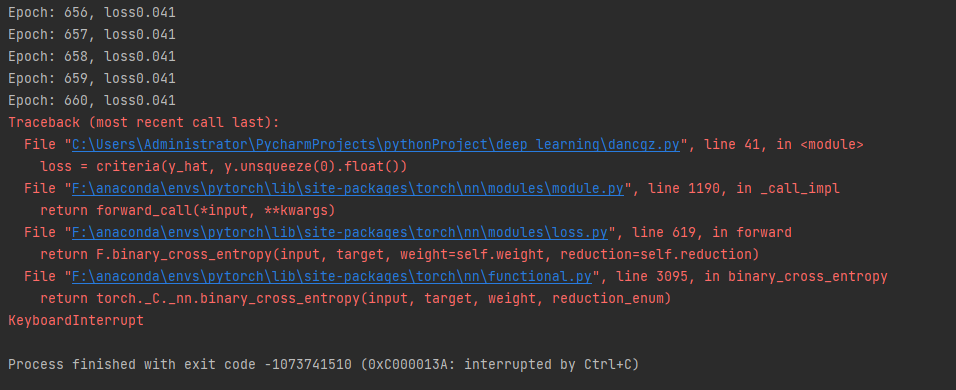
多层感知机代码示例
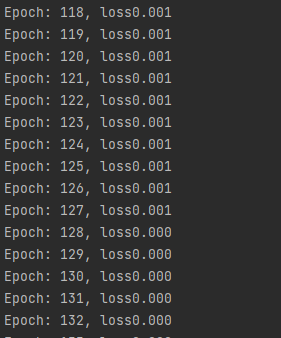
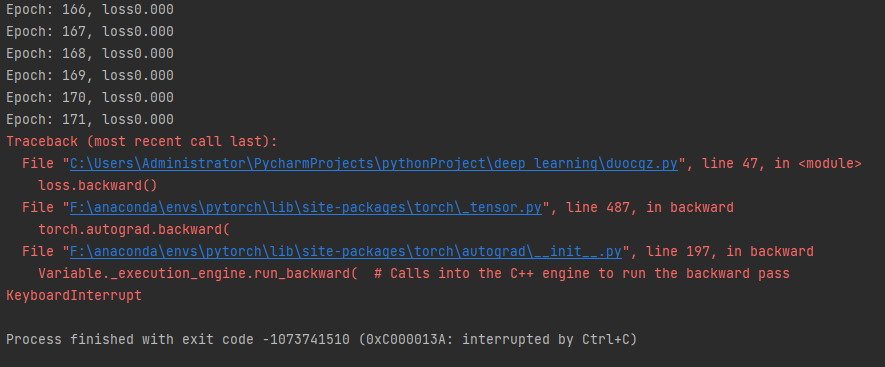
1 import torch 2 from torch import nn 3 import torch.nn.functional as F 4 5 6 n_item = 1000 7 n_feature = 2 8 9 torch.manual_seed(123) 10 data_x = torch.randn(size=(n_item, n_feature)).float() 11 data_y = torch.where(torch.subtract(data_x[:, 0]*0.5, data_x[:, 1]*1.5) > 0, 1.0, 0).long() 12 13 data_y = F.one_hot(data_y) 14 15 16 class BinaryClassificationModel(nn.Module): 17 def __init__(self, in_feature): 18 super(BinaryClassificationModel, self).__init__() 19 self.layer_1 = nn.Linear(in_features=in_feature, out_features=128, bias=True) 20 self.layer_2 = nn.Linear(in_features=128, out_features=512, bias=True) 21 self.layer_final = nn.Linear(in_features=512, out_features=2, bias=True) 22 23 def forward(self, x): 24 layer_1_output = F.sigmoid(self.layer_1(x)) 25 layer_2_output = F.sigmoid(self.layer_2(layer_1_output)) 26 output = F.sigmoid(self.layer_final(layer_2_output)) 27 return output 28 29 30 learning_rate = 0.01 31 epochs = 100 32 33 model = BinaryClassificationModel(n_feature) 34 35 opt = torch.optim.SGD(model.parameters(), lr=learning_rate) 36 37 criteria = nn.BCELoss() 38 39 for epoch in range(1000): 40 for step in range(n_item): 41 x = data_x[step] 42 y = data_y[step] 43 44 opt.zero_grad() 45 y_hat = model(x.unsqueeze(0)) 46 loss = criteria(y_hat, y.unsqueeze(0).float()) 47 loss.backward() 48 opt.step() 49 50 print('Epoch: %03d, loss%.3f' % (epoch, loss.item()))
输出示例:
2-8 基于多层DNN假钞识别

2-9 数据集及特征分析

2-10 项目构建和模型训练
preprocess.py
1 import numpy as np 2 from config import HP 3 import os 4 5 trainset_ratio = 0.7 6 devset_ratio = 0.2 7 testset_ratio = 0.1 8 9 np.random.seed(HP.seed) 10 dataset = np.loadtxt(HP.data_path, delimiter=',') 11 np.random.shuffle(dataset) 12 13 n_items = dataset.shape[0] 14 15 trainset_num = int(trainset_ratio * n_items) 16 devset_num = int(devset_ratio * n_items) 17 testset_num = n_items - trainset_num - devset_num 18 19 np.savetxt(os.path.join(HP.data_dir, 'train.txt'), dataset[:trainset_num], delimiter=',') 20 np.savetxt(os.path.join(HP.data_dir, 'dev.txt'), dataset[trainset_num:trainset_num + devset_num], delimiter=',') 21 np.savetxt(os.path.join(HP.data_dir, 'test.txt'), dataset[trainset_num+devset_num:], delimiter=',')
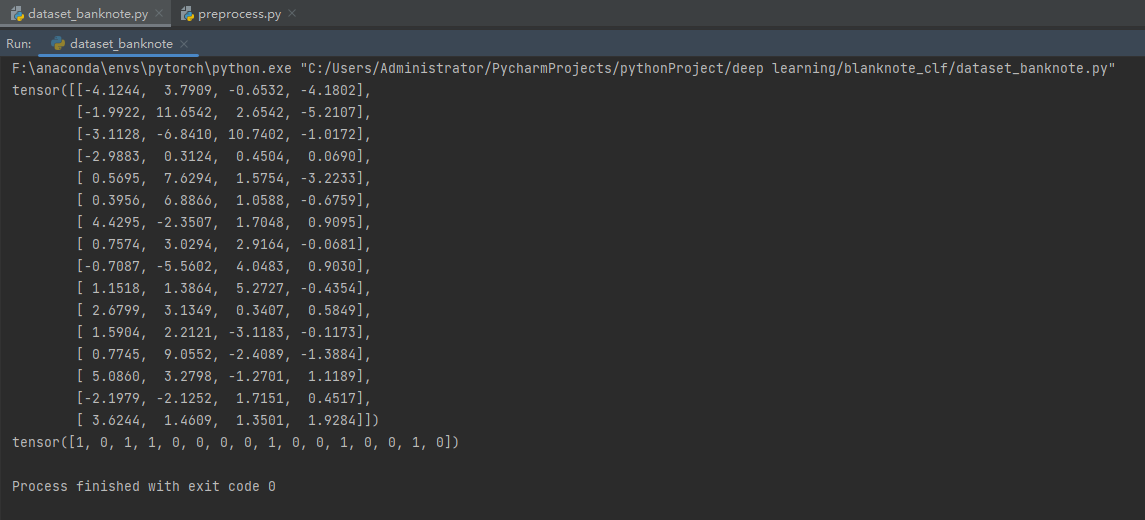
dataset_banknote.py
1 import torch 2 from torch.utils.data import DataLoader 3 from config import HP 4 import numpy as np 5 6 7 # class BanknoteDataset(torch.utils.data.Dataset): 8 # 9 # def __init__(self, data_path): 10 # """ banknote dataset 11 # :param data_path: dataset path: [trainset, devset, testset] 12 # """ 13 # self.dataset = np.loadtxt(data_path, delimiter=',') 14 # 15 # def __getitem__(self, idx): 16 # item = self.dataset[idx] 17 # x, y = item[:HP.in_features], item[HP.in_features:] 18 # return torch.Tensor(x).float().to(HP.device), torch.Tensor(y).squeeze().long().to(HP.device) 19 # 20 # def __len__(self): 21 # return self.dataset.shape[0] 22 23 24 # if __name__ == '__main__': 25 # bkdataset = BanknoteDataset(HP.trainset_path) 26 # bkdataloader = DataLoader(bkdataset, batch_size=13, shuffle=True, drop_last=True) 27 # for batch in bkdataloader: 28 # x, y = batch 29 # print(x) 30 # print(y.size()) 31 # break 32 33 34 class BanknoteDataset(torch.utils.data.Dataset): 35 def __init__(self, data_path): 36 self.dataset = np.loadtxt(data_path, delimiter=',') 37 38 def __getitem__(self, idx): 39 item = self.dataset[idx] 40 x, y = item[:HP.in_features], item[HP.in_features:] 41 return torch.Tensor(x).float().to(HP.device), torch.Tensor(y).squeeze().long().to(HP.device) 42 43 def __len__(self): 44 return self.dataset.shape[0] 45 46 # if __name__ == '__main__': 47 # bkdataset = BanknoteDataset(HP.testset_path) 48 # bkdataloader = DataLoader(bkdataset, batch_size=16, shuffle=True, drop_last=True) 49 # 50 # for batch in bkdataloader: 51 # x, y = batch 52 # print(x) 53 # print(y) 54 # break
运行测试代码示例:
config.py
1 # banknote classification config 2 3 # 超参配置 4 # yaml 5 class Hyperparameter: 6 # ################################################################ 7 # Data 8 # ################################################################ 9 device = 'cpu' # cuda 10 data_dir = './data/' 11 data_path = './data/data_banknote_authentication.txt' 12 trainset_path = './data/train.txt' 13 devset_path = './data/dev.txt' 14 testset_path = './data/test.txt' 15 16 in_features = 4 # input feature dim 17 out_dim = 2 # output feature dim (classes number) 18 seed = 1234 # random seed 19 20 # ################################################################ 21 # Model Structure 22 # ################################################################ 23 layer_list = [in_features, 64, 128, 64, out_dim] 24 # ################################################################ 25 # Experiment 26 # ################################################################ 27 batch_size = 64 28 init_lr = 1e-3 29 epochs = 100 30 verbose_step = 10 31 save_step = 200 32 33 34 HP = Hyperparameter()
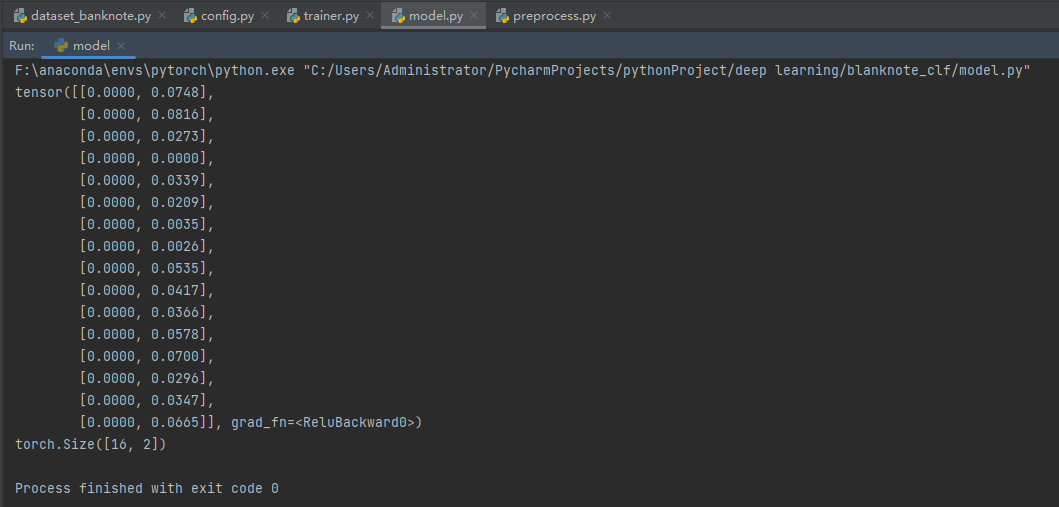
model.py
1 import torch 2 from torch import nn 3 from torch.nn import functional as F 4 from config import HP 5 6 7 # class BanknoteClassificationModel(nn.Module): 8 # def __init__(self,): 9 # super(BanknoteClassificationModel, self).__init__() 10 # # """ 代码过于冗余 11 # self.linear_layers = [] 12 # for idx, dim in enumerate(HP.layer_list[:-1]): 13 # self.linear_layers.append(nn.Linear(dim, HP.layer_list[idx+1])) 14 # # """ 15 # self.linear_layers = nn.ModuleList([ 16 # nn.Linear(in_dim, out_dim) for in_dim, out_dim in zip(HP.layer_list[:-1], HP.layer_list[1:]) 17 # ]) 18 # pass 19 # 20 # def forward(self, input_x): 21 # for layer in self.linear_layers: 22 # input_x = layer(input_x) 23 # input_x = F.relu(input_x) 24 # return input_x 25 # 26 # 27 # # if __name__ == '__main__': 28 # # model = BanknoteClassificationModel() 29 # # x = torch.randn(size=(8, HP.in_features)).to(HP.device) 30 # # print(model(x).size()) 31 32 33 class BanknoteClassificationModel(nn.Module): 34 def __init__(self, ): 35 super(BanknoteClassificationModel, self).__init__() 36 37 self.linear_layer = nn.ModuleList([ 38 nn.Linear(in_features=in_dim, out_features=out_dim) 39 for in_dim, out_dim in zip(HP.layer_list[:-1], HP.layer_list[1:]) 40 ]) 41 42 def forward(self, input_x): 43 for layer in self.linear_layer: 44 input_x = layer(input_x) 45 input_x = F.relu(input_x) 46 return input_x 47 48 # if __name__ == '__main__': 49 # model = BanknoteClassificationModel() 50 # x = torch.randn(size=(16, HP.in_features)).to(HP.device) 51 # y_pred = model(x) 52 # print(y_pred) 53 # print(y_pred.size())
运行测试代码示例
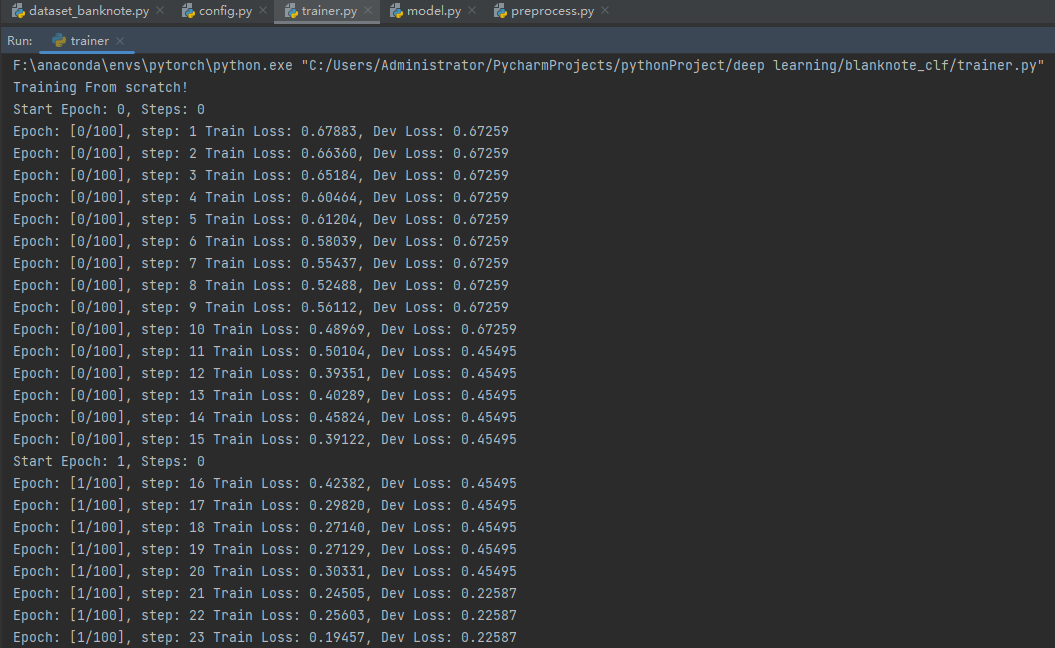
trainer.py
1 import os 2 from argparse import ArgumentParser 3 import torch.optim as optim 4 import torch 5 import random 6 import numpy as np 7 import torch.nn as nn 8 from torch.utils.data import DataLoader 9 from tensorboardX import SummaryWriter 10 11 from model import BanknoteClassificationModel 12 from config import HP 13 from dataset_banknote import BanknoteDataset 14 15 # # training logger 16 # logger = SummaryWriter('./log') 17 # 18 # # seed init: Ensure Reproducible Result 19 # torch.manual_seed(HP.seed) 20 # random.seed(HP.seed) 21 # np.random.seed(HP.seed) 22 # torch.cuda.manual_seed(HP.seed) 23 # 24 # 25 # # evaluate function 26 # def evaluate(model_, devloader, crit): 27 # model_.eval() 28 # sum_loss = 0. 29 # with torch.no_grad(): 30 # for batch in devloader: 31 # x, y = batch 32 # pred = model_(x) 33 # loss = crit(pred, y) 34 # sum_loss += loss.item() 35 # model_.train() 36 # return sum_loss/len(devloader) 37 # 38 # 39 # def save_checkpoint(model_, epoch_, optm, checkpoint_path): 40 # save_dict = { 41 # 'epoch': epoch_, 42 # 'model_state_dict': model_.state_dict(), 43 # 'optimizer_state_dict': optm.state_dict(), 44 # } 45 # torch.save(save_dict, checkpoint_path) 46 # 47 # 48 # def train(): 49 # parser = ArgumentParser(description='Model Train') 50 # parser.add_argument( 51 # '--c', 52 # default=None, 53 # # default='./model_save/model_66_4000.pth' 54 # type=str, 55 # help='train from scratch if it is none, or resume training from checkpoint' 56 # ) 57 # args = parser.parse_args() 58 # 59 # # new model instance 60 # model = BanknoteClassificationModel() 61 # model = model.to(HP.device) 62 # 63 # # new criterion loss function or customize define in "loss.py" 64 # criterion = nn.CrossEntropyLoss() 65 # 66 # opt = optim.Adam(model.parameters(), lr=HP.init_lr) 67 # 68 # # load train set 69 # trainset = BanknoteDataset(HP.trainset_path) 70 # train_loader = DataLoader(trainset, batch_size=HP.batch_size, shuffle=True, drop_last=True) 71 # 72 # # load dev set 73 # devset = BanknoteDataset(HP.devset_path) 74 # dev_loader = DataLoader(devset, batch_size=HP.batch_size, shuffle=True, drop_last=True) 75 # 76 # start_epoch = 0 77 # step = 0 78 # if args.c: # training resume 79 # checkpoint = torch.load(args.c) 80 # model.load_state_dict(checkpoint['model_state_dict']) 81 # opt.load_state_dict(checkpoint['optimizer_state_dict']) 82 # start_epoch = checkpoint['epoch'] 83 # print('Resume Training From %s' % args.c) 84 # else: 85 # print('Train From Scratch.') 86 # step = len(train_loader)*start_epoch 87 # 88 # model.train() # set training flag 89 # 90 # # training loop 91 # for epoch in range(start_epoch, HP.epochs): 92 # print("="*33, 'Start Epoch: %d, %d iters' % (epoch, len(trainset)/HP.batch_size), "="*33) 93 # 94 # sum_loss = 0. # loss 95 # for batch in train_loader: 96 # 97 # x, y = batch # load data 98 # opt.zero_grad() # gradient clean 99 # pred = model(x) # froward process 100 # loss = criterion(pred, y) # loss calc 101 # sum_loss += loss.item() 102 # loss.backward() # backward process 103 # opt.step() # model weights update 104 # 105 # logger.add_scalar('Loss/Train', loss, step) # add train loss to logger 106 # if not step % HP.verbose_step: 107 # eval_loss = evaluate(model, dev_loader, criterion) 108 # logger.add_scalar('Loss/eval', eval_loss, step) 109 # print('Train loss: %.4f, Eval loss %.4f' % (loss.item(), eval_loss)) 110 # 111 # if not step % HP.save_step: 112 # model_path = 'model_%d_%d.pth' % (epoch, step) 113 # save_checkpoint(model, epoch, opt, os.path.join('model_save', model_path)) 114 # step += 1 115 # logger.flush() 116 # print("Epoch: [%d/%d], step: %d Train loss: %.4f, Dev loss: %.4f" % (epoch, HP.epochs, step, loss.item(), eval_loss)) 117 # logger.close() 118 # 119 # 120 # if __name__ == '__main__': 121 # train() 122 123 logger = SummaryWriter('./log') 124 125 # seed init: Ensure Reproducible Result 126 torch.manual_seed(HP.seed) 127 torch.cuda.manual_seed(HP.seed) 128 random.seed(HP.seed) 129 np.random.seed(HP.seed) 130 131 132 def evaluate(model_, devloader, crit): 133 model_.eval() # set evaluation flag 134 sum_loss = 0. 135 with torch.no_grad(): 136 for batch in devloader: 137 x, y = batch 138 pred = model_(x) 139 loss = crit(pred, y) 140 sum_loss += loss.item() 141 142 model_.train() # back to training mode 143 return sum_loss / len(devloader) 144 145 146 def save_checkpoint(model_, epoch_, optm, checkpoint_path): 147 save_dict = { 148 'epoch': epoch_, 149 'model_state_dict': model_.state_dict(), 150 'optimizer_state_dict': optm.state_dict() 151 } 152 torch.save(save_dict, checkpoint_path) 153 154 155 def train(): 156 parser = ArgumentParser(description="Model Training") 157 parser.add_argument( 158 '--c', 159 default=None, 160 type=str, 161 help='train from scratch or resume training' 162 ) 163 args = parser.parse_args() 164 165 # new model instance 166 model = BanknoteClassificationModel() 167 model = model.to(HP.device) 168 169 # loss function (loss.py) 170 criterion = nn.CrossEntropyLoss() 171 172 # optimizer 173 opt = optim.Adam(model.parameters(), lr=HP.init_lr) 174 # opt = optim.SGD(model.parameters(), lr=HP.init_lr) 175 176 # train dataloader 177 trainset = BanknoteDataset(HP.trainset_path) 178 train_loader = DataLoader(trainset, batch_size=HP.batch_size, shuffle=True, drop_last=True) 179 180 # dev datalader(evaluation) 181 devset = BanknoteDataset(HP.devset_path) 182 dev_loader = DataLoader(devset, batch_size=HP.batch_size, shuffle=True, drop_last=False) 183 184 start_epoch, step = 0, 0 185 186 if args.c: 187 checkpoint = torch.load(args.c) 188 model.load_state_dict(checkpoint['model_state_dict']) 189 opt.load_state_dict(checkpoint['optimizer_state_dict']) 190 start_epoch = checkpoint['epoch'] 191 print('Resume From %s.' % args.c) 192 else: 193 print('Training From scratch!') 194 195 model.train() # set training flag 196 197 # main loop 198 for epoch in range(start_epoch, HP.epochs): 199 print('Start Epoch: %d, Steps: %d' % (epoch, len(train_loader) / HP.batch_size)) 200 for batch in train_loader: 201 x, y = batch # load data 202 opt.zero_grad() # gradient clean 203 pred = model(x) # forward process 204 loss = criterion(pred, y) # loss calc 205 206 loss.backward() # backward process 207 opt.step() 208 209 logger.add_scalar('Loss/Train', loss, step) 210 211 if not step % HP.verbose_step: # evaluate log print 212 eval_loss = evaluate(model, dev_loader, criterion) 213 logger.add_scalar('Loss/Dev', eval_loss, step) 214 215 if not step % HP.save_step: # model save 216 model_path = 'model_%d_%d.pth' % (epoch, step) 217 save_checkpoint(model, epoch, opt, os.path.join('model_save', model_path)) 218 219 step += 1 220 logger.flush() 221 print('Epoch: [%d/%d], step: %d Train Loss: %.5f, Dev Loss: %.5f' 222 % (epoch, HP.epochs, step, loss.item(), eval_loss)) 223 logger.close() 224 225 226 if __name__ == '__main__': 227 train()
运行测试代码示例
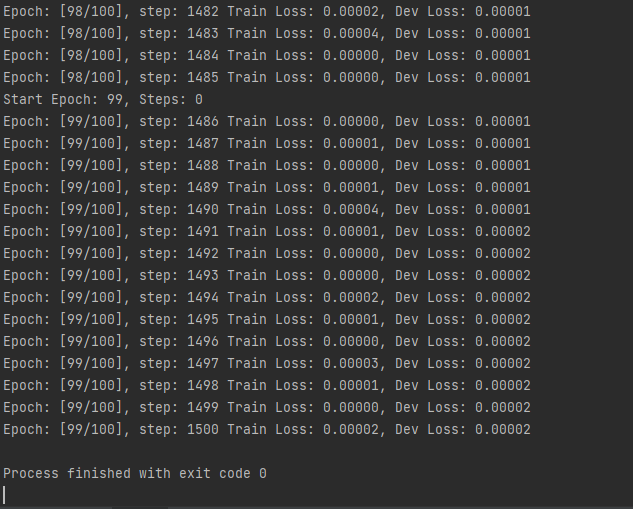
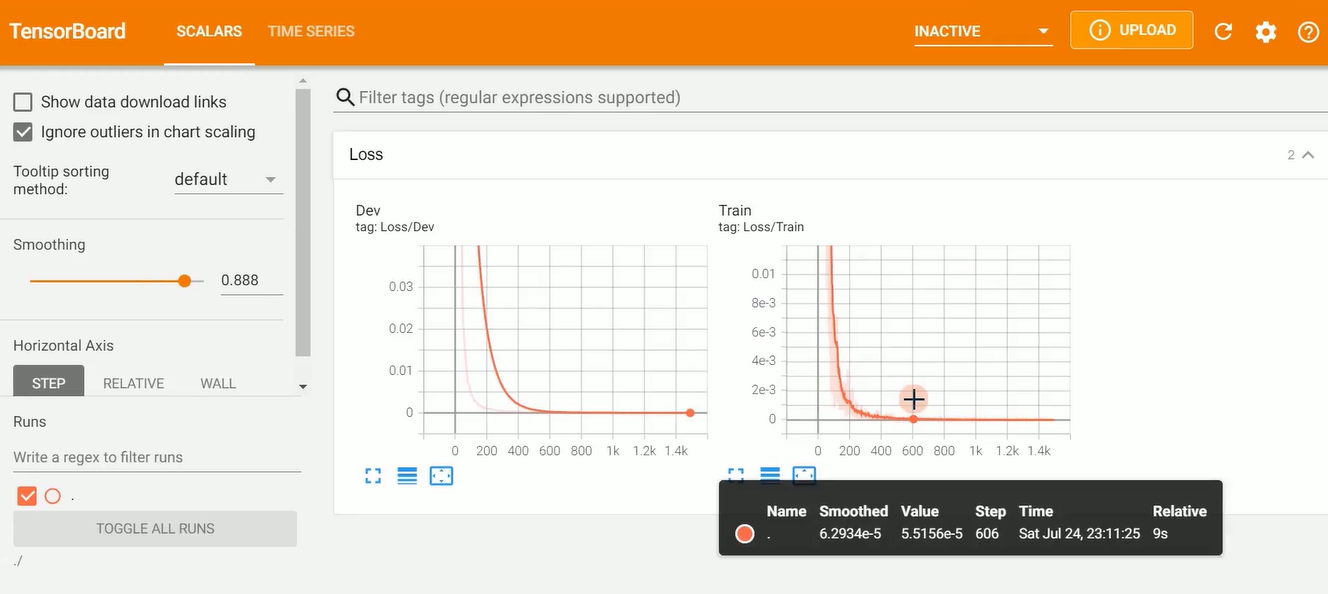
2-14 模型评估和选择

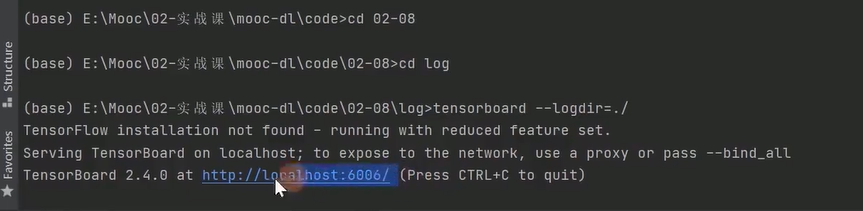
好家伙!这个链接半天搞不出来,暂时放弃。
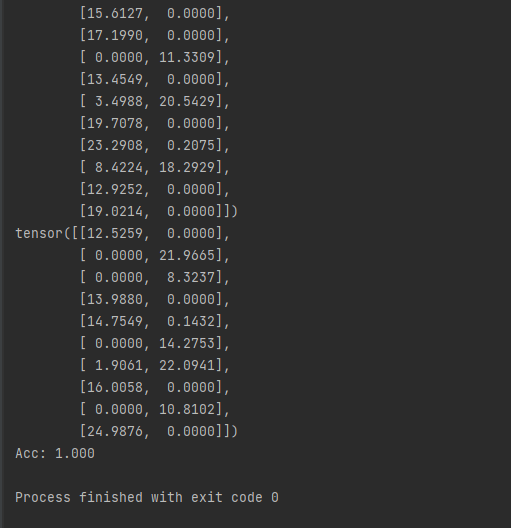
inference.py
1 import torch 2 from torch.utils.data import DataLoader 3 from dataset_banknote import BanknoteDataset 4 from model import BanknoteClassificationModel 5 from config import HP 6 7 # # load model from save dir 8 # model = BanknoteClassificationModel() 9 # checkpoint = torch.load('./model_save/model_83_5000.pth') 10 # model.load_state_dict(checkpoint['model_state_dict']) 11 # 12 # # load test set 13 # testset = BanknoteDataset(HP.testset_path) 14 # test_loader = DataLoader(testset, batch_size=HP.batch_size, shuffle=True, drop_last=False) 15 # 16 # model.eval() 17 # 18 # total_cnt = 0 19 # correct_cnt = 0 20 # with torch.no_grad(): 21 # for batch in test_loader: 22 # x, y = batch 23 # pred = model(x) 24 # total_cnt += pred.size(0) 25 # correct_cnt += (torch.argmax(pred, -1) == y).sum() 26 # 27 # print("Accuracy : %.3f" % (correct_cnt/total_cnt)) 28 29 # new model instance 30 model = BanknoteClassificationModel() 31 checkpoint = torch.load('./model_save/model_40_600.pth') 32 model.load_state_dict(checkpoint['model_state_dict']) 33 34 # test set 35 # dev datalader(evaluation) 36 testset = BanknoteDataset(HP.testset_path) 37 test_loader = DataLoader(testset, batch_size=HP.batch_size, shuffle=True, drop_last=False) 38 39 model.eval() 40 41 total_cnt = 0 42 correct_cnt = 0 43 44 with torch.no_grad(): 45 for batch in test_loader: 46 x, y = batch 47 pred = model(x) 48 # print(pred) 49 total_cnt += pred.size(0) 50 correct_cnt += (torch.argmax(pred, 1) == y).sum() 51 52 print('Acc: %.3f' % (correct_cnt / total_cnt))
运行测试代码示例:
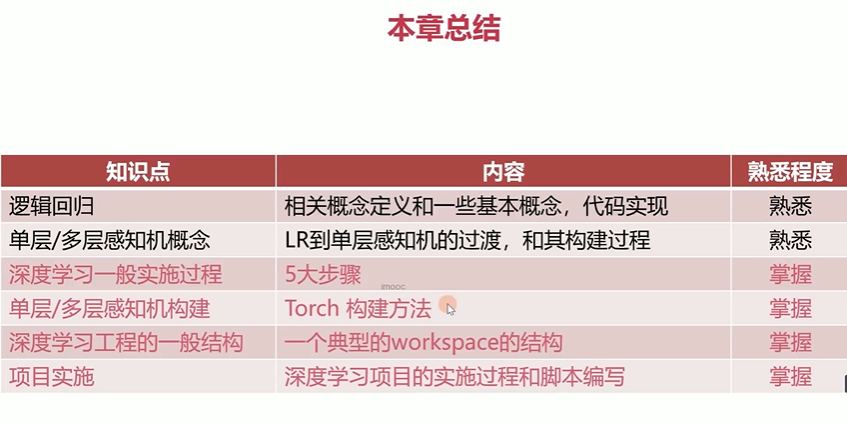
2-15 本章总结
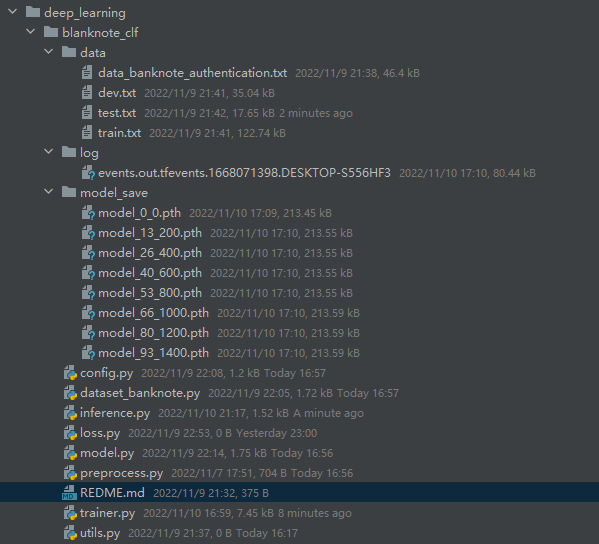
项目目录:
一脸懵逼的来,一脸懵逼的走。太多东西不清楚了,但也不能拘泥于此,先建立整体印象,很多细节下章会分解。虽说如此,一些基础的重要的内容还是需要额外花上许多时间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号