
第一次个人编程作业
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | · 估计这个任务需要多少时间 | 710 | 930 |
| Development | 开发 | 610 | 840 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 200 |
| · Design Spec | · 生成设计文档 | 10 | 15 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 20 | 25 |
| · Coding | · 具体编码 | 300 | 400 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | 70 | 50 |
| · Test Repor | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 710 | 930 |
1.Github链接:https://github.com/yntrash/3123004263/tree/main
2.计算模块接口的设计
算法核心设计
1.余弦相似度
原理:将 “文本” 转化为 “词语 - 词频向量”,通过向量夹角判断文本的相似程度:
向量夹角越小 → 余弦值越接近 1 → 文本越相似;
向量夹角越大 → 余弦值越接近 0 → 文本越不相似。
2.匹配率
原理:匹配率是 “抄袭文中出现在原文的词语数量” 与 “抄袭文总词语数量” 的比值,直接反映两篇文本的词语重叠程度,优点是计算极快、直观,可弥补余弦相似度对 “低频词重叠” 不敏感的问题。
融合公式:final_similarity = (cosine * 0.7) + (match_ratio * 0.3)
流程图:
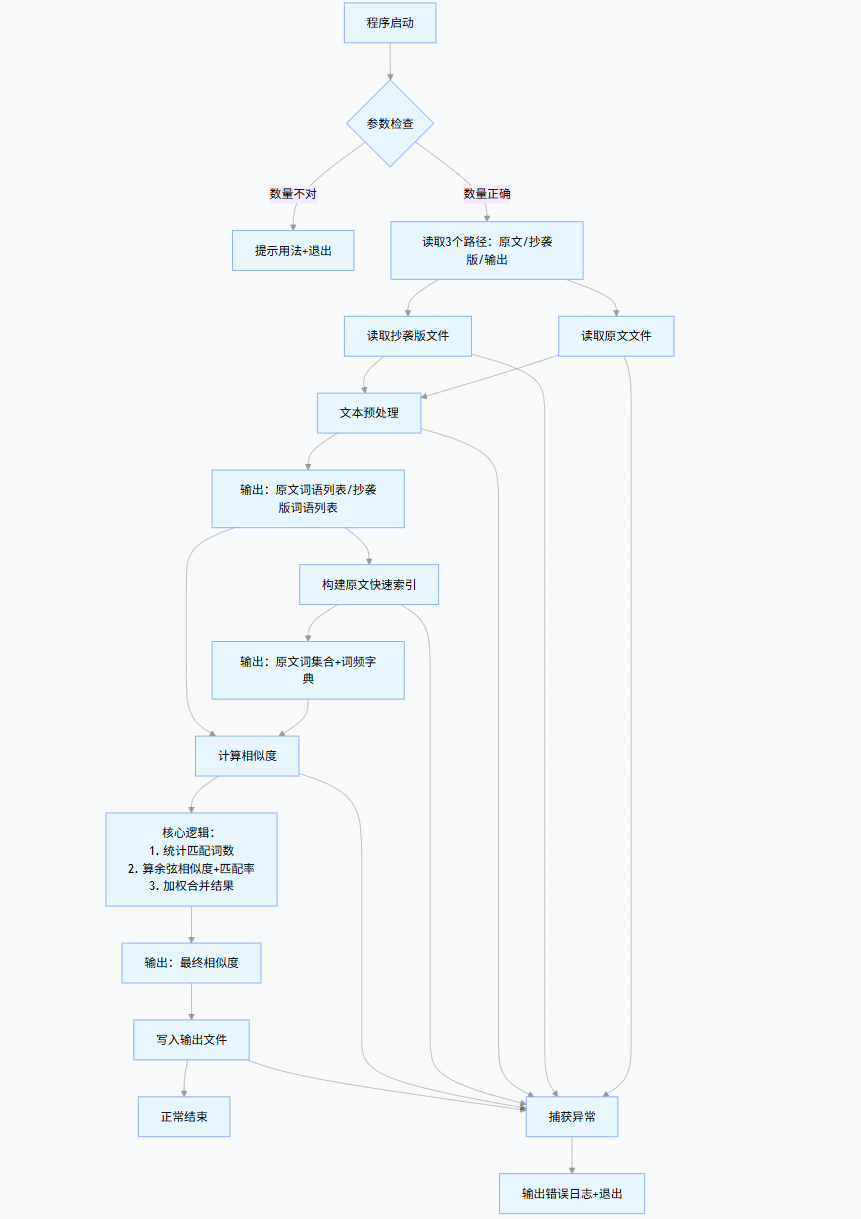
3.计算模块接口的优化
一.分析图
优化前:
优化后:
二.优化改进思路
1.数据结构优化:
- 将倒排索引从存储位置列表简化为只存储词语集合和词频,减少内存占用和计算量
- 使用集合(set)而非列表存储停用词和原文词语,将查找时间复杂度从 O (n) 降至 O (1)
2.算法简化:
- 减少相似度计算指标,保留最有效的余弦相似度和匹配率
- 合并循环操作,将多次遍历改为单次遍历完成多项计算
- 只对抄袭文中存在的词语进行计算,减少不必要的运算
3.文本处理优化:
- 使用 jieba 的lcut_for_search模式,分词速度更快
- 合并正则表达式操作,减少字符串处理次数
- 简化编码处理逻辑,只尝试最常用的 utf-8 和 gbk 编码
4.I/O 操作优化:
- 减少日志输出,只记录错误信息
- 简化文件读取的异常处理,减少不必要的检查
- 禁用 jieba 库的日志输出
5.内存使用优化:
- 避免创建不必要的中间变量
- 减少数据复制和转换操作
- 使用更紧凑的数据结构存储中间结果
4.计算模块部分单元测试展示
import unittest
import os
import tempfile
import sys
import subprocess
#将当前目录添加到Python路径,确保能导入主程序
current_dir = os.path.dirname(os.path.abspath(__file__))
sys.path.append(current_dir)
#导入主程序函数
from main import (
preprocess_text,
build_fast_index,
calculate_fast_similarity
)
class TestPlagiarismChecker(unittest.TestCase):
# 测试用例数据
TEST_ORIGINAL = "今天是星期天,天气晴,今天晚上我要去看电影。"
TEST_PLAGIARIZED = "今天是周天,天气晴朗,我晚上要去看电影。"
TEST_EMPTY = ""
TEST_SPECIAL_CHARS = "论文标题:基于Python的查重算法研究\n关键词:查重;Python;算法\n摘要:本文介绍了1种基于倒排索引的查重方法。"
def test_preprocess_text_basic(self):
result = preprocess_text(self.TEST_ORIGINAL)
self.assertTrue(len(result) > 0)
self.assertIn("今天", result)
self.assertIn("天气", result)
self.assertIn("电影", result)
self.assertNotIn("是", result) # 停用词应被过滤
self.assertNotIn(",", result) # 标点应被过滤
def test_preprocess_text_empty(self):
#测试空文本和特殊字符处理
self.assertEqual(preprocess_text(self.TEST_EMPTY), [])
self.assertEqual(preprocess_text(" "), [])
self.assertEqual(preprocess_text("!@#¥%……&*"), [])
def test_preprocess_text_special_chars(self):
#测试含特殊字符的文本预处理
result = preprocess_text(self.TEST_SPECIAL_CHARS)
expected_words = [
"论文", "标题", "基于", "Python", "算法", "研究",
"关键词", "Python", "算法", "摘要", "本文", "介绍",
"基于", "倒排", "索引", "方法"
]
for word in expected_words:
self.assertIn(word, result)
def test_build_fast_index(self):
#测试索引构建功能
words = ["今天", "天气", "今天", "晚上", "电影"]
word_set, word_freq, total = build_fast_index(words)
self.assertEqual(word_set, {"今天", "天气", "晚上", "电影"})
self.assertEqual(word_freq["今天"], 2)
self.assertEqual(word_freq["天气"], 1)
self.assertEqual(total, 5)
def test_build_fast_index_empty(self):
#测试空列表的索引构建
word_set, word_freq, total = build_fast_index([])
self.assertEqual(word_set, set())
self.assertEqual(word_freq, {})
self.assertEqual(total, 0)
def test_calculate_similarity_identical(self):
#测试完全相同文本的相似度
original_words = ["今天", "天气", "晚上", "电影"]
plagiarized_words = ["今天", "天气", "晚上", "电影"]
orig_set, orig_freq, _ = build_fast_index(original_words)
similarity = calculate_fast_similarity(orig_set, orig_freq, plagiarized_words)
self.assertAlmostEqual(similarity, 1.0, places=1)
def test_calculate_similarity_none(self):
#测试完全不同文本的相似度
original_words = ["苹果", "香蕉", "橙子"]
plagiarized_words = ["汽车", "火车", "飞机"]
orig_set, orig_freq, _ = build_fast_index(original_words)
similarity = calculate_fast_similarity(orig_set, orig_freq, plagiarized_words)
self.assertEqual(similarity, 0.0)
def test_calculate_similarity_partial(self):
#测试部分相似文本的相似度
original_words = ["今天", "星期天", "天气", "晚上", "看", "电影"]
plagiarized_words = ["今天", "周天", "天气", "晚上", "看", "电影"]
orig_set, orig_freq, _ = build_fast_index(original_words)
similarity = calculate_fast_similarity(orig_set, orig_freq, plagiarized_words)
self.assertGreater(similarity, 0.8)
self.assertLess(similarity, 1.0)
def test_calculate_similarity_subset(self):
#测试抄袭文本是原文子集的情况
original_words = ["第一章", "介绍", "研究", "背景", "目的", "意义"]
plagiarized_words = ["介绍", "研究", "目的"]
orig_set, orig_freq, _ = build_fast_index(original_words)
similarity = calculate_fast_similarity(orig_set, orig_freq, plagiarized_words)
self.assertGreater(similarity, 0.8)
def test_full_file_processing(self):
# 创建临时文件
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as orig_file:
orig_file.write(self.TEST_ORIGINAL)
orig_path = orig_file.name
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as plag_file:
plag_file.write(self.TEST_PLAGIARIZED)
plag_path = plag_file.name
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as output_file:
output_path = output_file.name
try:
# 运行主程序
result = subprocess.run(
[sys.executable, "main.py", orig_path, plag_path, output_path],
capture_output=True,
text=True,
timeout=10
)
# 验证程序正常运行
self.assertEqual(result.returncode, 0, f"主程序运行错误: {result.stderr}")
# 验证输出结果
with open(output_path, 'r', encoding='utf-8') as f:
content = f.read().strip()
self.assertRegex(content, r'^\d+\.\d{2}$')
similarity = float(content)
self.assertGreater(similarity, 0.6)
self.assertLess(similarity, 1.0)
finally:
# 清理临时文件
for path in [orig_path, plag_path, output_path]:
if os.path.exists(path):
os.unlink(path)
if __name__ == '__main__':
unittest.main(verbosity=2)
2.测试结构设计
1.文本预处理测试:
- 测试基本文本处理功能
- 测试空文本和特殊字符的处理
- 验证停用词和标点符号是否被正确过滤
2.索引构建测试:
- 验证索引构建的正确性(词集合、词频和总数)
- 测试空列表的边界情况
3.相似度计算测试:
- 完全相同文本的相似度(应接近 1.0)
- 完全不同文本的相似度(应等于 0.0)
- 部分相似文本的相似度(应在合理范围)
- 抄袭文本是原文子集的情况
4.完整流程测试:
- 使用临时文件模拟实际使用场景
- 测试命令行调用和文件 I/O
- 验证输出格式和结果合理性
覆盖率
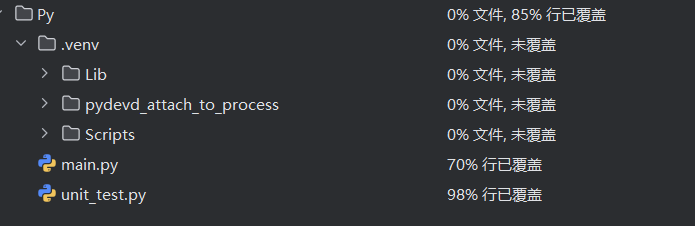
5.计算模块部分异常处理说明
1.空列表处理
#测试空列表的索引构建
word_set, word_freq, total = build_fast_index([])
self.assertEqual(word_set, set())
self.assertEqual(word_freq, {})
self.assertEqual(total, 0)
2.完全相同文本处理
#测试完全相同文本的相似度
original_words = ["今天", "天气", "晚上", "电影"]
plagiarized_words = ["今天", "天气", "晚上", "电影"]
orig_set, orig_freq, _ = build_fast_index(original_words)
similarity = calculate_fast_similarity(orig_set, orig_freq, plagiarized_words)
self.assertAlmostEqual(similarity, 1.0, places=1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号