【CS231N】7、卷积神经网络
一、疑问
1. assignments2
- 在代码文件FullyConnectedNets.ipynd 中,有代码如下:
# Test the affine_forward function
num_inputs = 2
input_shape = (4, 5, 6)
output_dim = 3
input_size = num_inputs * np.prod(input_shape)
weight_size = output_dim * np.prod(input_shape)
x = np.linspace(-0.1, 0.5, num=input_size).reshape(num_inputs, *input_shape)
w = np.linspace(-0.2, 0.3, num=weight_size).reshape(np.prod(input_shape), output_dim)
b = np.linspace(-0.3, 0.1, num=output_dim)
out, _ = affine_forward(x, w, b)
correct_out = np.array([[ 1.49834967, 1.70660132, 1.91485297],
[ 3.25553199, 3.5141327, 3.77273342]])
# Compare your output with ours. The error should be around 1e-9.
print 'Testing affine_forward function:'
print 'difference: ', rel_error(out, correct_out)
此处用np.prod和 np.linspace等一系列函数初始化权重w和x,与之前直接用np.random等函数想比略显复杂,如此初始化的好处是什么?
**A: **在这个代码模块里,最主要是为了测试前向传播函数是否实现正确,所以需要固定的权重和数据来得出结果,以和函数的输出进行对比。而之前随机生成的数据输出结果也是随机的,无法用于判定实现的前向传播函数是否正确。
- 当用多层FC网络过拟合50个样本时,如果网络层数越深,随机初始化权重时,所用的weight_scale应当越大点。
二、知识点
1. im2col操作
用矩阵乘法实现:卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。卷积层的常用实现方式就是利用这一点,将卷积层的前向传播变成一个巨大的矩阵乘法:
- 输入图像的局部区域被im2col操作拉伸为列。比如,如果输入是[227x227x3],要与尺寸为11x11x3的滤波器以步长为4进行卷积,就取输入中的[11x11x3]数据块,然后将其拉伸为长度为11x11x3=363的列向量。重复进行这一过程,因为步长为4,所以输出的宽高为(227-11)/4+1=55,所以得到im2col操作的输出矩阵X_col的尺寸是[363x3025],其中每列是拉伸的感受野,共有55x55=3,025个。注意因为感受野之间有重叠,所以输入数据体中的数字在不同的列中可能有重复。
- 卷积层的权重也同样被拉伸成行。举例,如果有96个尺寸为[11x11x3]的滤波器,就生成一个矩阵W_row,尺寸为[96x363]。
- 现在卷积的结果和进行一个大矩阵乘np.dot(W_row, X_col)是等价的了,能得到每个滤波器和每个感受野间的点积。在我们的例子中,这个操作的输出是[96x3025],给出了每个滤波器在每个位置的点积输出。
- 结果最后必须被重新变为合理的输出尺寸[55x55x96]。
这个方法的缺点就是占用内存太多,因为在输入数据体中的某些值在X_col中被复制了多次。但是,其优点是矩阵乘法有非常多的高效实现方式,我们都可以使用(比如常用的BLAS API)。还有,同样的im2col思路可以用在汇聚操作中。
三、归一化层(Batch normalization)
**Q: **在神经网络训练开始前,都要对输入数据做一个归一化处理,那为什么需要归一化呢?
**A: **神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
1. 定义
批量归一化。让激活数据在训练开始前通过一个网络,网络处理数据使其服从标准高斯分布。使用了批量归一化的网络对于不好的初始值有更强的鲁棒性。
2. 优点
- BN解决了反向传播过程中的梯度问题(梯度消失和爆炸),同时使得不同scale的
整体更新步调更一致。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
- 减少坏初始化的影响;
- 加快模型的收敛速度;
- 可以用大些的学习率
- 能有效地防止过拟合。
3. 前向传播过程公式
4. 反向传播求导公式
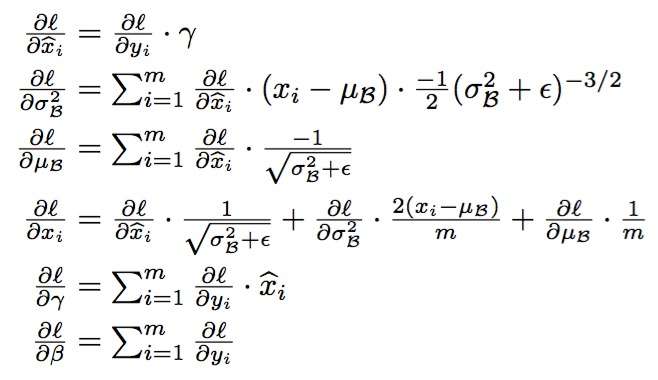
5. 代码
sample_mean = K.mean(X, axis=-1, keepdims=True)#计算均值
sample_var = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - sample_mean) / (sample_var + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
out = self.gamma * X_normed + self.beta 这个操作为“scale and shift”操作。为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入(即当
),从而保证整个network的capacity。(实际上BN可以看作是在原模型上加入的“新操作”,这个新操作很大可能会改变某层原来的输入。当然也可能不改变,不改变的时候就是“还原原来输入”。如此一来,既可以改变同时也可以保持原输入,那么模型的容纳能力(capacity)就提升了。)
当引入BN层,原始的数据分布可能会因此遭到破坏,从而导致网络的loss变大,则在反向传播中,可以使用梯度更新规则对参数gamma和beta进行更新,从而接用“scale and shift”操作,以求可能保持原输入的部分特征。
我们训练时使用一个minibatch的数据,因此可以计算均值和方差,但是预测时一次只有一个数据,所以均值方差都是0,那么BN层什么也不干,原封不动的输出。这肯定会用问题,因为模型训练时是进过处理的,但是测试时又没有,那么结果肯定不对。
解决的方法是使用训练的所有数据,也就是所谓的population上的统计。不过这需要训练完成之后在多出一个步骤。一种常见的办法就是基于momentum的指数衰减,这和低通滤波器类似。每次更新时把之前的值衰减一点点(乘以一个momentum,一般很大,如0.9,0.99),然后把当前的值加一点点进去(1-momentum)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号