全国疫情和福建省疫情爬虫
一.主题式网络爬虫设计方案
1.主题式网络爬虫名称:全国疫情累计及福建省疫情爬虫
2.主题式网络爬虫爬取的内容与特征分析:
a.内容:全国疫情爬虫的内容为截至目前的各省的累计确诊,累计治愈,累计死亡数据,福建省疫情爬虫为1月22日至4月22日的每日新增确诊,每日新增疑似,每日新增境外输入确诊,每日境外输入疑似数据。
b.特征分析:全国疫情爬虫的数据特征分析,全国疫情数据的内容为json格式,可以通过字典的形式进行访问,福建省疫情数据为每日发布,通过html页面获得,多为数据格式不统一
3.主题式网络爬虫设计方案概述:
首先确定网址,以便于确定数据的来源,全国疫情数据选择网址为(https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=316578012887), 福建省疫情数据选择为(http://wjw.fujian.gov.cn/was5/web/search?)全国疫情网站不需要向服务器提交数据,福 建省疫情网站需要像网站提交数据。全国疫情数据返回的是一个json文件,将获得到的文件内容保存,之后通过字典的访问形式获得对应数据。福建省疫情数据返回的是包含了子网页的网址,将子网址的网址通过正则表达式匹配出来,之后进行访问,该网站采取 的是XHR加载网页,所以通过向服务器提交数据以便于获得数据。
二.主题页面的结构特征分析
A.全国疫情数据

B福建省疫情信息
三.网络爬虫设计
from bs4 import BeautifulSoup #导入beautifulsoup用来解析网页 import requests #导入requests用于网页访问 import matplotlib.pyplot as plt #对数据画图,散点图,柱状图等 import re #正则表达式用来匹配文章内容,过滤信息 import pandas as pd #修改格式,写入excel import json #json文件获取 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 def GetPage():# 获取网页源码 urllist = [] #保存匹配出来的网址 for i in range(1,7): URL = 'http://wjw.fujian.gov.cn/was5/web/search?' # 目标网页地址 formdata = { "sortfield": "-docreltime,-docorderpri,-docorder", "templet": "docs.jsp", "channelid": "285300", "classsql": "chnlid=38586", "prepage": "20", "page": i, "r": "0.2607847720437618" } #post数据 header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome / 53.0.2785.143Safari / 537.36', 'Connection': 'keep-alive', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cookie': '_gscu_1005022938=86859196iyievf18; _gscbrs_1005022938=1' } html = requests.post(URL, data=formdata,headers=header) # 获取网页源码 html.raise_for_status() p = re.compile(r'"url":"(http.*?)"') #正则匹配出跳转网址 temp = re.findall(p,html.content.decode('UTF-8')) #匹配 urllist+=temp #保存跳转网址 for i in urllist: #输出网址 print(i) return urllist#返回网址 def GetMsg(urllist): header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome / 53.0.2785.143Safari / 537.36', 'Connection': 'keep-alive', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cookie': '_gscu_1005022938=86859196iyievf18; _gscbrs_1005022938=1' } for url in urllist: html = requests.get(url,headers=header) #获取网页源码 soup = BeautifulSoup(html.content, 'html.parser') #使用html。parser解释器 f = open('word.txt', 'a', encoding='UTF-8') #写入文件 divs = soup.find_all('div',{'id':'detailContent'}) #匹配主要信息 for div in divs: #将匹配到的信息 afont = div.find_all('font') #找到所有文字 for font in afont: #对于每个匹配到的句子 str = font.text #得到文字 str = str.lstrip().rstrip() #去除左右空格 f.write(str)#写入文件 f.write('\n') f.close() def Get_time_outland():#匹配信息 f = open('word.txt', 'r',encoding='UTF-8') #读入文件 word = f.readlines()#读入内容 time_re = re.compile('([0-9]月[0-9]*日)')#用来匹配日期 concern_re_outland = re.compile('新增境外输入确诊病例[0-9]*例|新增境外输入新型冠状病毒肺炎确诊病例[0-9]*例')#匹配确诊 doubt_re_outland = re.compile('新增境外输入疑似病例[0-9]*例|新增境外输入新型冠状病毒肺炎疑似病例[0-9]*例')#匹配疑似 message_outland = {}#保存过滤出来的信息 for str in word:#对于每句文字 time_ = re.findall(time_re, str)#匹配日期 num_re = re.compile('[0-9]+')#匹配数字 concern_outland = re.findall(concern_re_outland, str)#匹配确诊 doubt_outland = re.findall(doubt_re_outland, str)#匹配疑似 try: if time_[0] not in message_outland:#如果当前日期第一次出现 message_outland[time_[0]] = [[], []] if len(concern_outland) <=0:#未匹配到内容 message_outland[time_[0]][0] += '0' else: message_outland[time_[0]][0] += concern_outland#将匹配到的内容保存 if len(doubt_outland) <= 0: message_outland[time_[0]][1] += '0' else: message_outland[time_[0]][1] += doubt_outland except: pass for time_time_, str_list in message_outland.items():#对于匹配到的信息 for iterator in str_list: max_num = -1 #只需要确诊或者疑似的最大数字,因为在文本中存在某市的数字 for i in iterator: max_num = max(max_num, int(re.findall(num_re, i)[0]))#获得最大数字 message_outland[time_time_][str_list.index(iterator)]=max_num#讲当日的确诊疑似固定为最大数字 return message_outland#返回数字 def Get_time_inland():#同国外 f = open('word.txt', 'r',encoding='UTF-8') word = f.readlines() time_re = re.compile('([0-9]月[0-9]*日)') concern_re_inland = re.compile('新增[^境外].?.?.?.?.?.?.?.?确诊病例[0-9]*例|新增.?.?.?新型冠状病毒.?.?.?肺炎确诊病例[0-9]*例') doubt_re_inland = re.compile('新增本地疑似病例[0-9]*例|新增.?.?.?新型冠状病毒.?.?.?肺炎疑似病例[0-9]*例') message_inland = {} for str in word: time_ = re.findall(time_re, str) num_re = re.compile('[0-9]+') concern_inland = re.findall(concern_re_inland, str) doubt_inland = re.findall(doubt_re_inland, str) try: if time_[0] not in message_inland: message_inland[time_[0]] = [[], []] if len(concern_inland) <=0: message_inland[time_[0]][0] += '0' else: message_inland[time_[0]][0] += concern_inland if len(doubt_inland) <= 0: message_inland[time_[0]][1] += '0' else: message_inland[time_[0]][1] += doubt_inland except: pass message_inland['1月22日'][0] += '1'#最初发布信息的时候没有准确数字,所以查看文字可知 确诊一人 ,疑似为0 message_inland['1月22日'][1] += '0' message_inland['1月23日'][0] += '3'#同1月22日 message_inland['1月23日'][1] += '0' for time_time_, str_list in message_inland.items(): for iterator in str_list: max_num = -1 for i in iterator: try: max_num = max(max_num, int(re.findall(num_re, i)[0])) except: pass message_inland[time_time_][str_list.index(iterator)] = max_num return message_inland def write_to_excel(message,mark = 1):#讲内容写进excel xticks = []#用来保存日期 y1ticks = []#用来保存确诊 y2ticks = []#用来保存疑似 for i,j in message.items():#内容格式为{日期:[确诊,疑似]} 类型为字典 xticks.append(i)#日期 y1ticks.append(j[0])# y2ticks.append(j[1]) dicts = { '时间':xticks, '新增确诊':y1ticks, '新增疑似':y2ticks } df = pd.DataFrame(dicts)#保存到excel中 if mark==1: df.to_excel('本地新增确诊疑似.xlsx', index=False) else: df.to_excel('境外输入新增确诊疑似.xlsx', index=False) def re_prope(message):#获得累计各个市内所有确诊人数 prope_re = re.compile('..市[0-9]*例')#匹配某某市 total_re = re.compile('累计报告本地确诊病例[0-9]*例')#匹配累计确诊数量 num_re = re.compile('[0-9]*')#匹配数字 pro_re = re.compile('..市')#匹配市 f = open('word.txt', 'r',encoding='UTF-8')#打开文件 word = f.readlines()#读取文件 for str in word: result = re.findall(prope_re, str)#匹配出市 result2 = re.findall(total_re, str)#匹配累计确诊 break message = {}#保存清洗过后的信息 for i in result: pro = re.findall(pro_re, i)#匹配市 num = re.findall(num_re, i)#匹配数字 if pro[0] not in message:#市第一次出现 message[pro[0]] = 0# 先将人数置为0 for j in num: if len(j)>=1: j = int(j) message[pro[0]] = j #保存有效数字 else: pass temp = re.findall(num_re,result2[0])#匹配数字 for i in temp: if len(i)>=1: total = int(i) else: pass return message,total def draw_fig(message):#绘制折线图 fig = plt.figure()#建立一个空图 xticks = []#x轴标签 y1ticks = []#y轴标签 确诊人数 y2ticks = []#y轴标签 疑似人数 for i,j in message.items():#分割内容 xticks.append(i) y1ticks.append(j[0]) y2ticks.append(j[1]) xticks.reverse()#反转内容,因为爬取来的信息是最近日期,所以反过来 y1ticks.reverse() y2ticks.reverse() #折线图 ax1 = fig.add_subplot(211)#图分为两部分 plt.xlabel('时间') plt.ylabel('人数') plt.plot(xticks,y1ticks,label = '新增确诊') plt.legend() plt.xticks(rotation=270) ax2 = fig.add_subplot(212) plt.xlabel('时间') plt.ylabel('人数') plt.plot(xticks, y2ticks, color='green',label = '新增疑似') plt.legend() plt.xticks(rotation=270) plt.savefig('福建确诊疑似病例折线图.jpg') def draw_bar(message):#绘制柱形图 xvalue = []#x轴标签 yvalue = []#y内容 for i,j in message.items(): xvalue.append(i) yvalue.append(j) plt.title('各市累计确诊柱形图') plt.bar(xvalue, yvalue) plt.savefig('福建各市累计确诊柱形图.jpg') def draw_pie(message,total_):#绘制饼图 total = total_#总人数 xvalue = [] yvalue = [] for i, j in message.items(): xvalue.append(i) yvalue.append(j) labels = xvalue #饼标签 share = []#每部分的比例 for i in yvalue: share.append(i/total) plt.title('各市累计确诊比例') plt.pie(share, labels=labels,autopct = '%3.1f%%',) plt.savefig('福建各市累计确诊比例饼图.jpg') def nationwide(): url="https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=316578012887" headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36' } try: r = requests.get(url, headers=headers) #获取网址源码 r.raise_for_status() r.encoding = r.apparent_encoding#转码 r = r.json()#转换成json b = json.dumps(r,ensure_ascii=False) f2 = open('new_json.json','w',encoding='utf-8') f2.write(b)#保存数据 f2.close() except Exception as e: print('error: ',e) def parser_page(filename): f= open(filename, encoding='utf-8')#加载文件 data = json.load(f)#读取内容 casedata = data['data']['areaTree'][2]['children']#获得到国内的内容 result = {}#保存结果 for i in casedata: if i['name'] not in result:#省名字 result[i['name']] = [] result[i['name']].append(i['total']['confirm']) #累计确诊 result[i['name']].append(i['total']['suspect']) #现存疑似 result[i['name']].append(i['total']['heal']) #累计治愈 result[i['name']].append(i['total']['dead']) #累计死亡 result[i['name']].append(i['lastUpdateTime'])#最近更新日期 print(result) return result def draw_nation_bar(data):#画柱状图 xvalue = []#x轴标签 y1value = []#确诊人数 y2value = []#治愈人数 y3value = []#死亡人数 for i,j in data.items(): #数据内容为{日期:[累计确诊,现存疑似,累计治愈,累计死亡,更新日期] xvalue.append(i) y1value.append(j[0]) y2value.append(j[2]) y3value.append(j[3]) fig = plt.figure() #空图 ax1 = fig.add_subplot(311)#分成三份 plt.bar(xvalue[1:], y1value[1:]) plt.title("各省累计确诊(除湖北)") ax2 = fig.add_subplot(312) plt.bar(xvalue[1:], y2value[1:]) plt.title("各省累计治愈(除湖北)") ax3 = fig.add_subplot(313) plt.bar(xvalue[1:], y3value[1:]) plt.title("各省累计死亡(除湖北)") plt.savefig('各省比例.jpg') def count_nation_pie(data): #绘制饼图 xvalue = []#标签 y1value = []#累计确诊 y2value = []#累计治愈 y3value = []#累计死亡 total1 = 0 #确诊总数 total2 = 0#治愈总数 total3 = 0#死亡总数 for i,j in data.items(): xvalue.append(i) y1value.append(j[0]) y2value.append(j[2]) y3value.append(j[3]) total1 += j[0] total2 += j[2] total3 += j[3] xvalue.remove(xvalue[0])#去除湖北, 因为湖北数据比例过大,影响直观表现,所以去除湖北 total1 -= y1value[0] total2 -= y2value[0] total3 -= y3value[0] share1 = [] #个省份的比例 share2 = [] share3 = [] for i in y1value[1:]: share1.append(i/total1) for i in y2value[1:]: share2.append(i / total2) for i in y3value[1:]: share3.append(i / total3) print(xvalue, share1, share2, share3) return xvalue,share1,share2,share3 def draw_natiom_bar(share, labels,mark): fig = plt.figure() plt.pie(share, labels=labels, autopct='%3.1f%%') title = ['累计确诊比例(除湖北)','累计治愈比例(除湖北)','累计死亡比例(除湖北)'] plt.title(title[mark-1]) plt.savefig('{}.jpg'.format(title[mark-1])) if __name__ == '__main__': urllist = GetPage() GetMsg(urllist) message_inland = Get_time_inland() message_outland = Get_time_outland() draw_fig(message_inland) draw_fig(message_outland) write_to_excel(message_inland, mark=1) #写入本地确诊疑似excel write_to_excel(message_outland, mark=2) #写入境外确诊疑似excel message,total = re_prope(message_inland) # draw_bar(message) draw_pie(message,total) nationwide() data = parser_page('new_json.json') draw_nation_bar(data) x,y1,y2,y3 = count_nation_pie(data) draw_natiom_bar(y1, x,1) draw_natiom_bar(y2, x,2) draw_natiom_bar(y3, x,3)

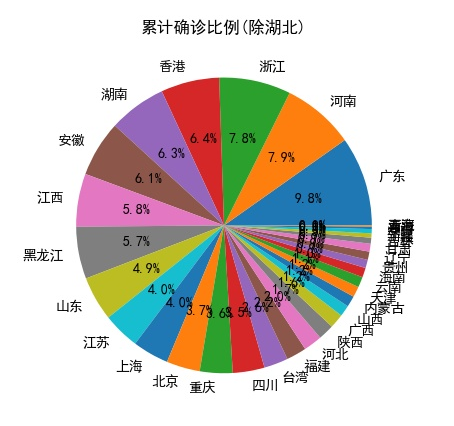
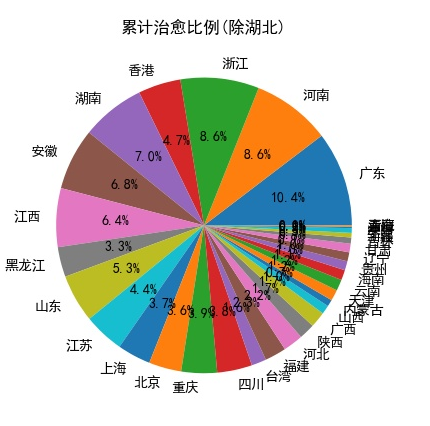

程序小结:
本程序通过post数据以获得数据,同时也解决了爬取网址不会变化的问题,同时也实现了数据永久化的保存包括爬取下来的所有信息,通过txt文件,json文件,jpg图像等将数据通过饼图折线图如柱状图,将数据更好的呈现出来,以便于用户更好的获得信息,通过获得的这些信息,我也意识到了中国人民在面对疫情情况下的团结一心,一线工作人员的尽心竭力,这些数据的背后都是大家的努力,同时也希望大家勤洗手,多通风,不聚集,戴口罩,让治愈数字越来越多,让死亡和确诊数字越来越少,加油福建,加油中国

 浙公网安备 33010602011771号
浙公网安备 33010602011771号