AI-15. 自然语言处理:应用
15.1. 情感分析及数据集
情感分析(sentiment analysis)研究人们在文本中 (如产品评论、博客评论和论坛讨论等)“隐藏”的情绪。由于情感可以被分类为离散的极性或尺度(例如,积极的和消极的),我们可以将情感分析看作一项文本分类任务,它将可变长度的文本序列转换为固定长度的文本类别。
15.2. 情感分析:使用循环神经网络
与词相似度和类比任务一样,我们也可以将预先训练的词向量应用于情感分析,我们将使用预训练的GloVe模型来表示每个词元,并将这些词元表示送入多层双向循环神经网络以获得文本序列表示,该文本序列表示将被转换为情感分析输出。
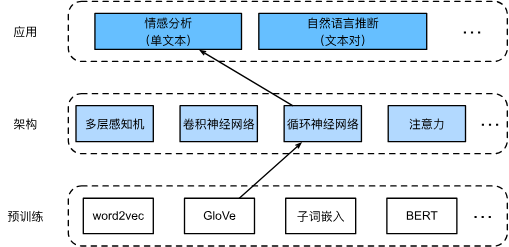
15.3. 情感分析:使用卷积神经网络
虽然卷积神经网络最初是为计算机视觉设计的,但它也被广泛用于自然语言处理。简单地说,只要将任何文本序列想象成一维图像即可。通过这种方式,一维卷积神经网络可以处理文本中的局部特征,例如n元语法。类似地,我们可以使用汇聚层从序列表示中提取最大值,作为跨时间步的最重要特征。textCNN中使用的最大时间汇聚层的工作原理类似于一维全局汇聚
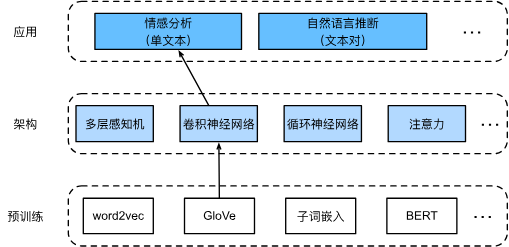
15.4. 自然语言推断与数据集
自然语言推断(natural language inference)主要研究 假设(hypothesis)是否可以从前提(premise)中推断出来, 其中两者都是文本序列。 换言之,自然语言推断决定了一对文本序列之间的逻辑关系。这类关系通常分为三种类型:
-
蕴涵(entailment):假设可以从前提中推断出来。
-
矛盾(contradiction):假设的否定可以从前提中推断出来。
-
中性(neutral):所有其他情况。
自然语言推断也被称为识别文本蕴涵任务,自然语言推断一直是理解自然语言的中心话题。它有着广泛的应用,从信息检索到开放领域的问答。
15.5. 自然语言推断:使用注意力
通过注意力机制来完成自然语言推断问题。
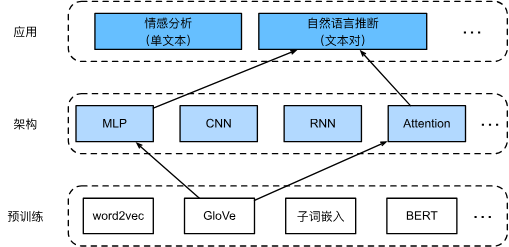
15.6. 针对序列级和词元级应用微调BERT
为每个自然语言处理任务精心设计一个特定的模型实际上是不可行的。名为BERT的预训练模型,该模型可以对广泛的自然语言处理任务进行最少的架构更改。然而,原始BERT模型的两个版本分别带有1.1亿和3.4亿个参数。因此,当有足够的计算资源时,我们可以考虑为下游自然语言处理应用微调BERT。
包括但不限于:
- 单文本分类将单个文本序列作为输入,并输出其分类结果。 除了情感分析之外,语言可接受性语料库(Corpus of Linguistic Acceptability,COLA)也是一个单文本分类的数据集,它的要求判断给定的句子在语法上是否可以接受。
- 以一对文本作为输入但输出连续值,语义文本相似度是一个流行的“文本对回归”任务。 这项任务评估句子的语义相似度
- 现在让我们考虑词元级任务,比如文本标注(text tagging),其中每个词元都被分配了一个标签。在文本标注任务中,词性标注为每个单词分配词性标记(例如,形容词和限定词)。 根据单词在句子中的作用。
- 作为另一个词元级应用,问答反映阅读理解能力。 例如,斯坦福问答数据集(Stanford Question Answering Dataset,SQuAD v1.1)由阅读段落和问题组成,其中每个问题的答案只是段落中的一段文本(文本片段)。
15.7. 自然语言推断:微调BERT
自然语言推断是一个序列级别的文本对分类问题,而微调BERT只需要一个额外的基于多层感知机的架构。如图所示,
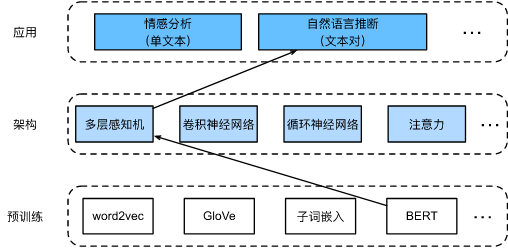
“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示。在微调过程中,BERT模型成为下游应用模型的一部分。仅与训练前损失相关的参数在微调期间不会更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号