AI-9 现代循环神经网络
例如,循环神经网络在实践中一个常见问题是数值不稳定性。 尽管我们已经应用了梯度裁剪等技巧来缓解这个问题, 但是仍需要通过设计更复杂的序列模型来进一步处理它。 具体来说,我们将引入两个广泛使用的网络, 即门控循环单元(gated recurrent units,GRU)和 长短期记忆网络(long short-term memory,LSTM)。 然后,我们将基于一个单向隐藏层来扩展循环神经网络架构。
9.1. 门控循环单元(GRU)
也许,早期观测值对预测所有未来观测值具有非常重要的意义。我们希望有某些机制能够在一个记忆元里存储重要的早期信息。 如果没有这样的机制,我们将不得不给这个观测值指定一个非常大的梯度, 因为它会影响所有后续的观测值。学术界为了解决此问题提出了很多种方法最早的方法是”长短期记忆”(long-short-term memory,LSTM),门控循环单元(gated recurrent unit,GRU) 是一个稍微简化的变体,通常能够提供同等的效果, 并且计算的速度明显更快。
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。 重置门有助于捕获序列中的短期依赖关系;更新门有助于捕获序列中的长期依赖关系。
练习:
1假设我们只想使用时间步t′的输入来预测时间步t>t′的输出。对于每个时间步,重置门和更新门的最佳值是什么?
答:需要令重置门的值趋向于0,减少过去状态的影响;同时需更新门的值也趋向于0,使得新的隐状态更接近于候选隐状态。
2调整和分析超参数对运行时间、困惑度和输出顺序的影响。
答:原始模型参数
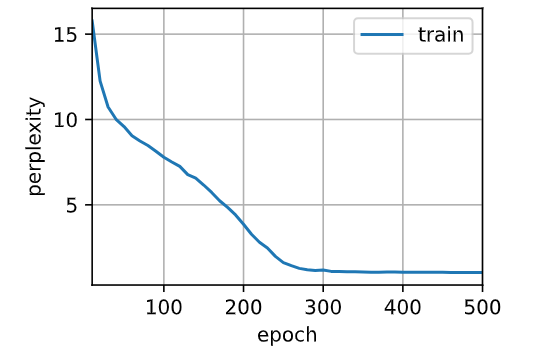
# [迭代周期,隐藏单元数,批量大小,小批量数据时间步数,学习率]
hyper_0 = [500, 512, 35, 32, 1]
hyper_1 = [250, 512, 35, 32, 1]
hyper_2 = [500, 256, 35, 32, 1]
hyper_3 = [500, 512, 10, 32, 1]
hyper_4 = [500, 512, 35, 10, 1]
hyper_5 = [500, 512, 35, 32, 0.01]
hyper_params = [hyper_0, hyper_1, hyper_2, hyper_3, hyper_4, hyper_5]
实验组1: 迭代周期减少,模型无法正常收敛
实验组2:减少了隐藏单元降低模型复杂度,训练速度提高
实验组3:减小了批量大小,这使得模型的训练时间开销显著增加;
实验组4:将小批量时间步的跨度缩小,虽然也造成了时间开销的增加,但少于批量减少带来的时间增长;
实验组5:减小了学习率,发现过低的学习率会使得模型收敛的非常慢,疑惑度较高
3比较rnn.RNN和rnn.GRU的不同实现对运行时间、困惑度和输出字符串的影响。
答:GRU在重置门、更新门以及候选码门中增加了大量计算,导致训练时间较长,但其结果的困惑度较低。
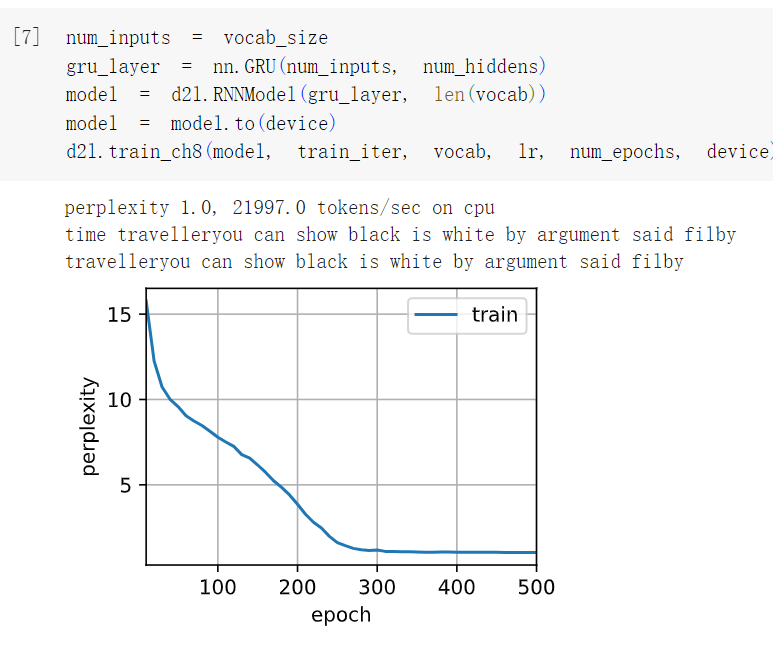
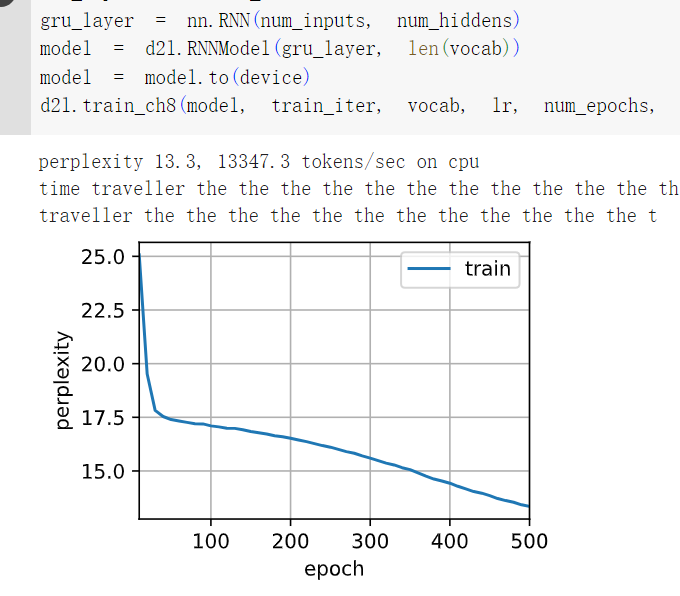
4如果仅仅实现门控循环单元的一部分,例如,只有一个重置门或一个更新门会怎样?
答:如果只实现了一个重置门,那么模型将只能重置隐藏状态,而无法更新其状态。这会导致模型无法学习长期依赖性并且可能无法产生准确的输出。而如果只实现了一个更新门,则模型可以更新其隐藏状态,但是无法选择要丢弃的信息,这也可能会导致模型无法正确地处理长期依赖性。
9.2. 长短期记忆网络(LSTM)
可以说,长短期记忆网络的设计灵感来自于计算机的逻辑门。 长短期记忆网络引入了记忆元(memory cell),或简称为单元(cell)。
为了控制记忆元,我们需要许多门。 其中一个门用来从单元中输出条目,我们将其称为输出门(output gate)。 另外一个门用来决定何时将数据读入单元,我们将其称为输入门(input gate)。 我们还需要一种机制来重置单元的内容,由遗忘门(forget gate)来管理。
在长短期记忆网络中,也有两个门用于这样的目的: 输入门控制采用多少来自当前的新数据, 而遗忘门控制保留多少过去的 记忆元的内容。
练习:
1调整和分析超参数对运行时间、困惑度和输出顺序的影响。
同上
2如何更改模型以生成适当的单词,而不是字符序列?
答:词元化处理时采用单词级别的词元化处理,而非字符级别。
3在给定隐藏层维度的情况下,比较门控循环单元、长短期记忆网络和常规循环神经网络的计算成本。要特别注意训练和推断成本。
答: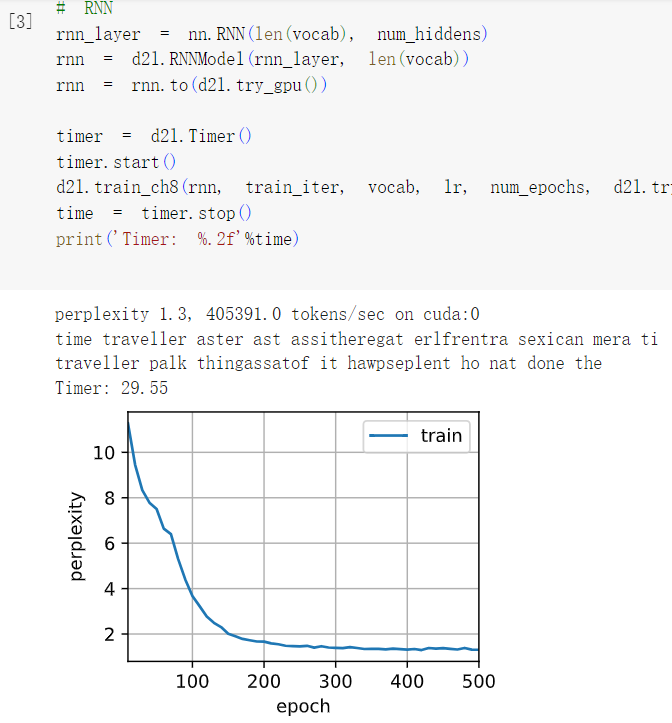
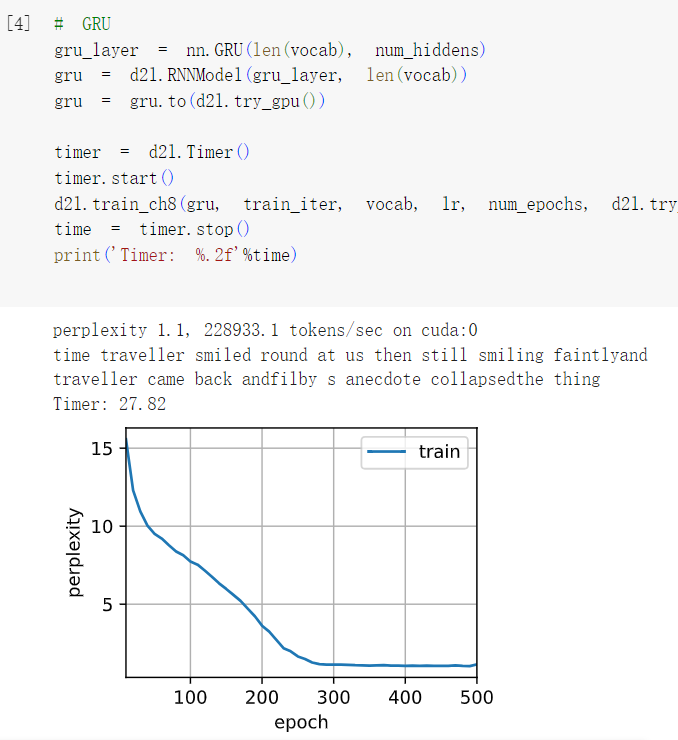
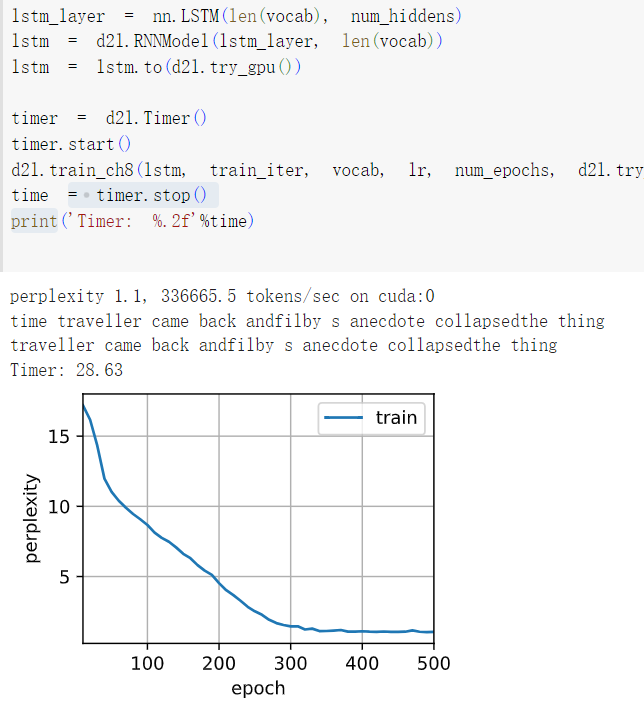
所花费的计算量/时间 ,越来越多
4既然候选记忆元通过使用tanh函数来确保值范围在(−1,1)之间,那么为什么隐状态需要再次使用tanh函数来确保输出值范围在(−1,1)之间呢?
因为隐状态的结果是输入与前一个记忆元以及当前状态的和,可能会超过1.
5实现一个能够基于时间序列进行预测而不是基于字符序列进行预测的长短期记忆网络模型。
9.3. 深度循环神经网络
为了提取更多的信息,增加网络的隐藏层数,我们可以将深度架构中的函数依赖关系形式化。
练习:
1基于我们在 8.5节中讨论的单层实现, 尝试从零开始实现两层循环神经网络。
查看代码
# 定义训练数据
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 初始化模型参数
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 第一层RNN参数
W_xh1 = normal((num_inputs, num_hiddens))
W_hh1 = normal((num_hiddens, num_hiddens))
b_h1 = torch.zeros(num_hiddens, device=device)
# 第二层RNN参数
W_hh2 = normal((num_hiddens, num_hiddens))
b_h2 = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh1, W_hh1, b_h1, W_hh2, b_h2, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_rnn_state(batch_size, num_hiddens, device):
# 返回初始化的双层RNN状态
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
W_xh1, W_hh1, b_h1, W_hh2, b_h2, W_hq, b_q = params
H1, H2 = state
outputs = []
# X的形状:(批量大小,词表大小)
for X in inputs:
H1 = torch.relu(torch.mm(X, W_xh1) + torch.mm(H1, W_hh1) + b_h1)
H2 = torch.relu(torch.mm(H1, W_hh2) + b_h2)
Y = torch.mm(H2, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H1, H2)
num_hiddens = 512
net = d2l.RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())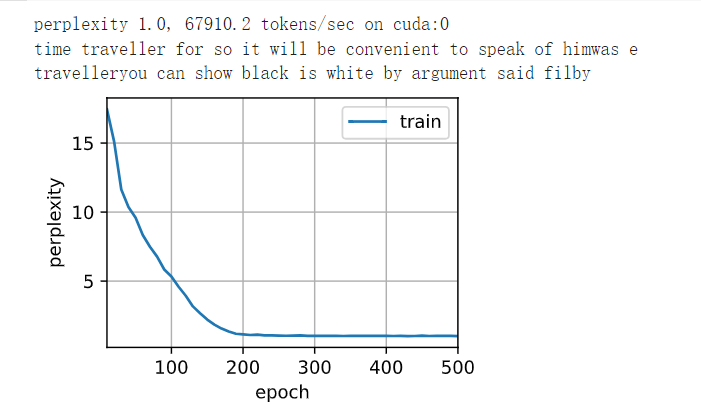
2在本节训练模型中,比较使用门控循环单元替换长短期记忆网络后模型的精确度和训练速度。
LSTM GRU
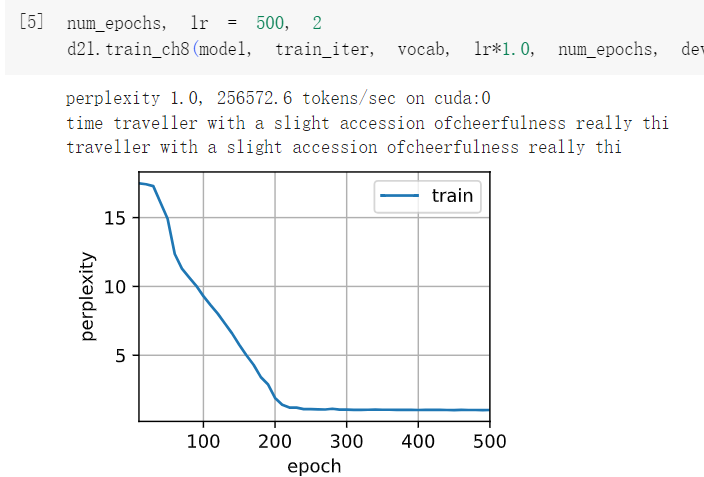

对比双层GRU与双层LSTM的结果可以发现,将LSTM替换为GRU后模型的训练速度有所提高,因为相较于LSTM,GRU只有两个门,具有更少的参数量,因此训练速度更快。精确度方面,由于文本量限制,二者都在该文本上达到了1.0的困惑度,并未出现明显差别。
3如果增加训练数据,能够将困惑度降到多低?
增加训练数据其困惑度仍为1
4在为文本建模时,是否可以将不同作者的源数据合并?有何优劣呢?
合并不同作者的数据会增加数据量,但不同作者之间的写作习惯不同,也许会影响训练效果。
9.4. 双向循环神经网络
在序列学习中,我们以往假设的目标是: 在给定观测的情况下 (例如,在时间序列的上下文中或在语言模型的上下文中), 对下一个输出进行建模。但也许这不是唯一的情景,也许我们需要根据下一个文本对当前输出进行建模。
如果我们希望在循环神经网络中拥有一种机制, 使之能够提供与隐马尔可夫模型类似的前瞻能力, 只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络, 而不是只有一个在前向模式下“从第一个词元开始运行”的循环神经网络。 双向循环神经网络(bidirectional RNNs) 添加了反向传递信息的隐藏层,以便更灵活地处理此类信息。
双向循环网络的代价非常高。
练习:
1如果不同方向使用不同数量的隐藏单位,Ht的形状会发生怎样的变化?
答:Ht是由前向循环网络和后向循环网络的隐藏层连接而来。
2设计一个具有多个隐藏层的双向循环神经网络。
3在自然语言中一词多义很常见。例如,“bank”一词在不同的上下文“i went to the bank to deposit cash”和“i went to the bank to sit down”中有不同的含义。如何设计一个神经网络模型,使其在给定上下文序列和单词的情况下,返回该单词在此上下文中的向量表示?哪种类型的神经网络架构更适合处理一词多义?
例如在神经网络中,可以采用双向循环神经网络模型或者Transformer,将上下文中的单词序列映射到单词的向量表示。
9.5. 机器翻译与数据集
语言模型是自然语言处理的关键, 而机器翻译是语言模型最成功的基准测试。 因为机器翻译正是将输入序列转换成输出序列的 序列转换模型(sequence transduction)的核心问题。本书的关注点是神经网络机器翻译方法,强调的是端到端的学习。
练习:
1在load_data_nmt函数中尝试不同的num_examples参数值。这对源语言和目标语言的词表大小有何影响?
num_examples=600

num_examples=1200 词表增大

2某些语言(例如中文和日语)的文本没有单词边界指示符(例如空格)。对于这种情况,单词级词元化仍然是个好主意吗?为什么?
可以,例如中文可以使用基于词典或者基于统计的分词方法,进行词元化处理。
9.6. 编码器-解码器架构
机器翻译是序列转换模型的一个核心问题, 其输入和输出都是长度可变的序列。 为了处理这种类型的输入和输出, 我们可以设计一个包含两个主要组件的架构:
第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。
第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。
练习:
1假设我们使用神经网络来实现“编码器-解码器”架构,那么编码器和解码器必须是同一类型的神经网络吗?
·不一定,具体选择需要取决于具体的任务需求和设计思路。
2除了机器翻译,还有其它可以适用于”编码器-解码器“架构的应用吗?
语音任务,文本编辑等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号