AI-3线性回归
3.1笔记
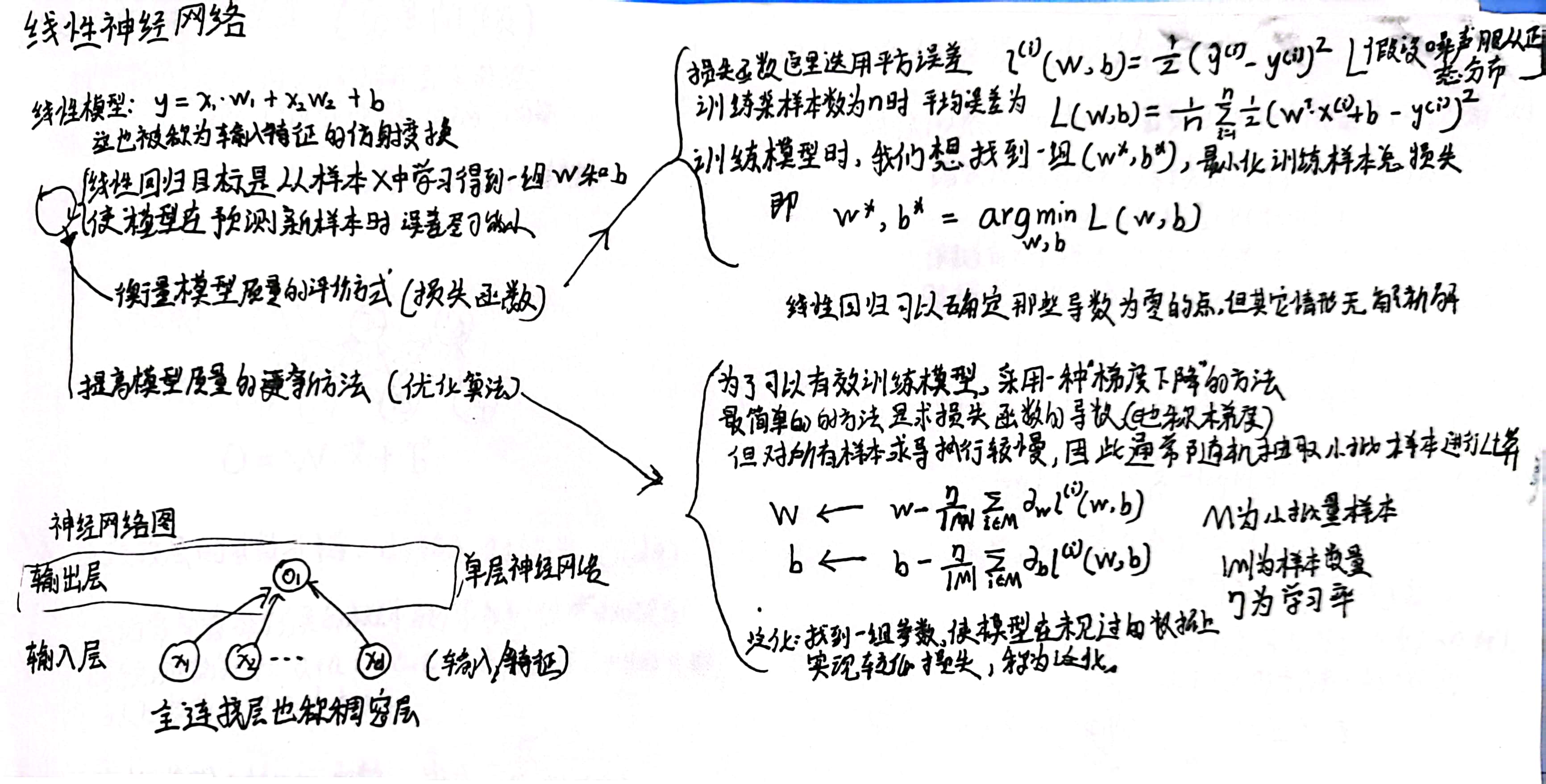
线性回归假设y与多个x之间的关系是线性的,且噪声符合正态分布。
线性模型则是对输入特征做仿射变换Y^ = W * X+b,其中Y^为预测值,我们希望预测值与真实值Y的误差最小。那如何衡量这个误差呢,使用损失函数来量化。
(在线性模型中,一般采用最小二乘的损失函数)
这样,将问题转化为关注最小化损失函数的优化问题。
优化得到数值解过程中用到梯度下降法。为了在精度和效率之间权衡,现学者多采用小批量随机梯度下降。
通过梯度下降可以多次迭代找到一组参数,使得损失函数接近最小值。即该参数使得模型在训练集上损失最小。
而更难做的是,如何找到一组参数使得其在模型未见过的数据集上实现较低的损失。
另外,在迭代过程中通过利用广播机制,矢量化的代码会带来数量级别的加速。
3.1练习
1假设我们有一些数据𝑥1,…,𝑥𝑛∈ℝ。我们的目标是找到一个常数𝑏,使得最小化∑𝑖(𝑥𝑖−𝑏)2。找到最优值𝑏的解析解。这个问题及其解与正态分布有什么关系?
最优值b的解析解为1/n *∑𝑥𝑖 . 若样本x1,x2,x3...服从正态分布,则b为样本均值mu。
2推导出使用平方误差的线性回归优化问题的解析解。为了简化问题,可以忽略偏置𝑏
(我们可以通过向𝐗添加所有值为1的一列来做到这一点)。
用矩阵和向量表示法写出优化问题(将所有数据视为单个矩阵,将所有目标值视为单个向量)。
计算损失对𝑤的梯度。
通过将梯度设为0、求解矩阵方程来找到解析解。
什么时候可能比使用随机梯度下降更好?这种方法何时会失效?
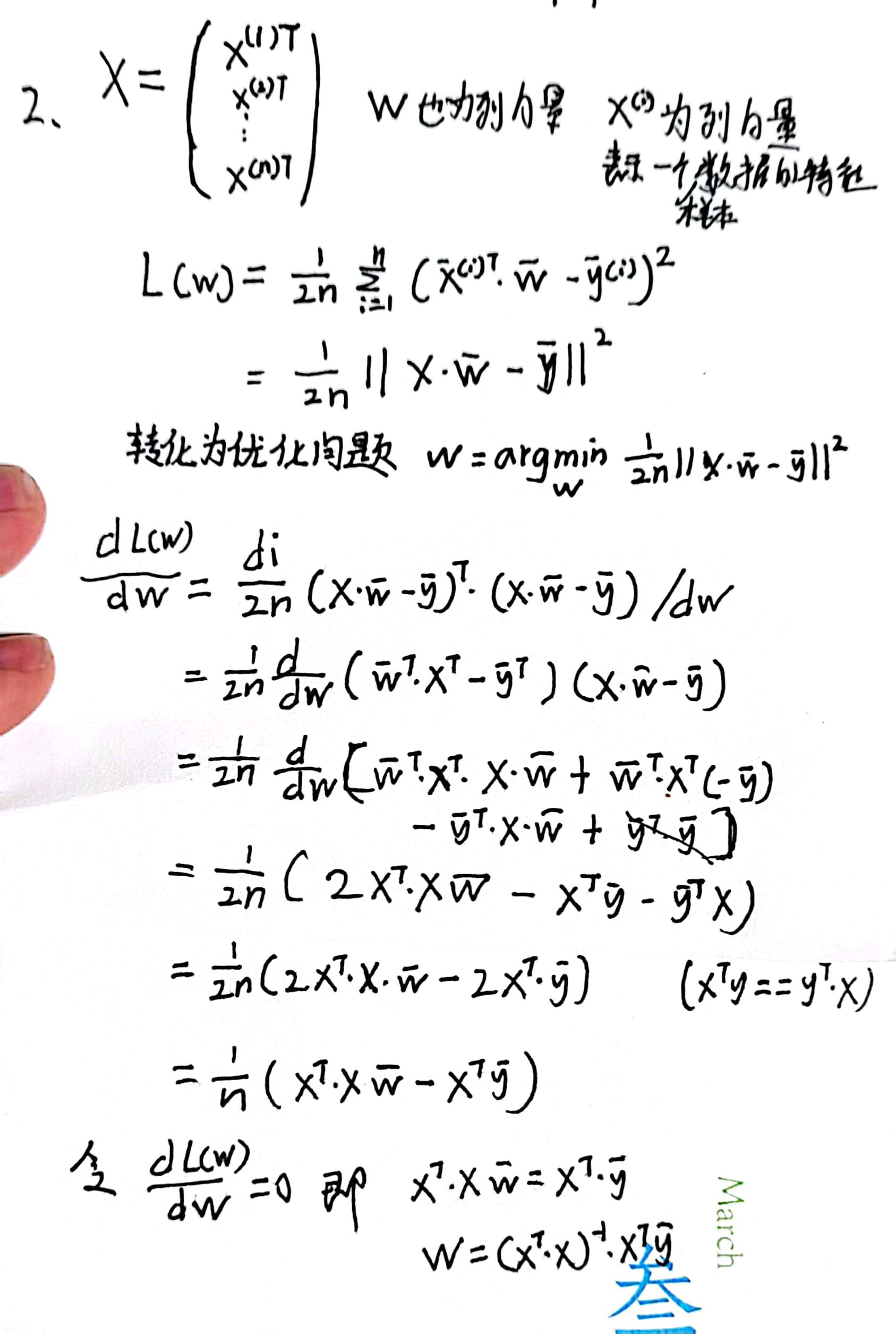
3假定控制附加噪声𝜖的噪声模型是指数分布。也就是说,𝑝(𝜖)=12exp(−|𝜖|)
写出模型−log𝑃(𝐲∣𝐗)下数据的负对数似然。
请试着写出解析解。
提出一种随机梯度下降算法来解决这个问题。哪里可能出错?(提示:当我们不断更新参数时,在驻点附近会发生什么情况)请尝试解决这个问题。

3.2线性回归的从零开始实现
通过 自定义模型,自定义层,自定义损失函数,具体了解机器进行线性回归的过程。
在读取数据集时,每次抽取小批量样本对模型进行更新。所以有必要定义一个函数(data_iter函数), 该函数能打乱数据集中的样本并以小批量方式获取数据。
data_iter函数, 该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
使用小批量的原因是,GPU可以并行运算可以同时处理多个数据
模型参数的初始化,我们通过从均值为0、标准差为0.01的正态分布初始化权重(但似乎别人的代码中中不是这样的,有时间验证一下)。
然后定义损失函数进行优化。
3.2练习
1如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
若偏置也为0,由于参数的对称性,会使得多个神经元的作用如同一个神经元。
若偏置随机初始化, 模型权重初始化为0,则在反向传播时由于部分梯度为0,在初始阶段参数更新慢。
2假设试图为电压和电流的关系建立一个模型。自动微分可以用来学习模型的参数吗?
可以,假设U=I w+b,可以建立一个输入一个隐藏层一个输出的简单模型,并根据U和i的数据进行回归。自动微分可以学习。
3能基于普朗克定律使用光谱能量密度来确定物体的温度吗?
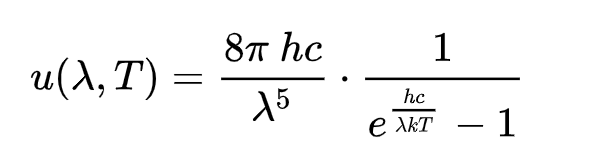
4计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
5为什么在squared_loss函数中需要使用reshape函数?
保证两个向量的形状相同。
6尝试使用不同的学习率,观察损失函数值下降的快慢。
学习率过大前期下降很快,但是后面不容易收敛,可能会在最值附件震荡;学习率过小损失函数梯度下降会很慢。
7如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
只读取部分数据。最多只读取到num_examples
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
3.3线性回归的简洁实现
通过使用深度学习框架简洁完成线性回归,学会调用API。
对于每一个小批量,我们会进行以下步骤: 通过调用net(X)生成预测并计算损失l(前向传播)。通过进行反向传播来计算梯度。通过调用优化器来更新模型参数。
3.3练习
1如果将小批量的总损失替换为小批量损失的平均值,需要如何更改学习率? 除以batchsize
2查看深度学习框架文档,它们提供了哪些损失函数和初始化方法?
0-1loss,交叉熵损失等等
用Huber损失代替原损失
Loss = torch.nn.SmoothL1Loss()3如何访问线性回归的梯度?
net[0].weight.grad
net[0].bias.grad3.4softmax回归
在分类问题当中,我们需要得到每个类别的概率(因此有多个输出)。
为了使输出的概率更合法,我们使用softmax函数对其进行归一化处理。使得所有输出在0-1直接,且和为1.
其损失函数的梯度为梯度是观测值和估计值之间的差异。

3.4练习
-
我们可以更深入地探讨指数族与softmax之间的联系。
-
计算softmax交叉熵损失l(y,y^)的二阶导数。
-
计算softmax(y)给出的分布方差,并与上面计算的二阶导数匹配。
-
-
假设我们有三个类发生的概率相等,即概率向量是(1/3,1/3,1/3)。
-
如果我们尝试为它设计二进制代码,有什么问题?
-
请设计一个更好的代码。提示:如果我们尝试编码两个独立的观察结果会发生什么?如果我们联合编码n个观测值怎么办?
-
-
softmax是对上面介绍的映射的误称(虽然深度学习领域中很多人都使用这个名字)。真正的softmax被定义为RealSoftMax(a,b)=log(exp(a)+exp(�b))。
-
证明RealSoftMax(a,b)>max(a,b)。
-
证明k−1RealSoftMax(ka,kb)>max(a,b)成立,前提是k>0。
-
证明对于k→∞,有�k−1RealSoftMax(ka,kb)→max(a,b)。
-
soft-min会是什么样子?
-
将其扩展到两个以上的数字。
-

3.5. 图像分类数据集
3.5练习
1减少batch_size(如减少到1)是否会影响读取性能?
读取数据的时间变动非常长,如图


2数据迭代器的性能非常重要。当前的实现足够快吗?探索各种选择来改进它。
迭代器(iterable)是一个超级接口!是可以遍历集合的对象,为各种容器提供了公共的操作接口。 似乎并不快,改进未解决。
似乎并不快,改进未解决。3查阅框架的在线API文档。还有哪些其他数据集可用?
用于image classification:
手写字符识别:EMNIST、MNIST、QMNIST、USPS、SVHN、KMNIST、Omniglot
实物分类:Fashion MNIST、CIFAR、LSUN、SLT-10、ImageNet
人脸识别:CelebA
场景分类:LSUN、Places365
3.6 softmax回归的从零开始实现
3.6练习
1本节直接实现了基于数学定义softmax运算的softmax函数。这可能会导致什么问题?提示:尝试计算exp(50)的大小。
直接计算指数函数有时结果会非常大,导致数据溢出。
2本节中的函数cross_entropy是根据交叉熵损失函数的定义实现的。它可能有什么问题?提示:考虑对数的定义域。
不理解
3请想一个解决方案来解决上述两个问题。
3返回概率最大的分类标签总是最优解吗?例如,医疗诊断场景下可以这样做吗?
最大概率是可能的选项,但医疗场景中需要全面的数据分析。
4假设我们使用softmax回归来预测下一个单词,可选取的单词数目过多可能会带来哪些问题?
词汇量大意味着类别多。一方面会加大计算量,另一方面会导致每个分类概率都很小,分类辨识度低。
3.7softmax回归的简洁实现
3.7练习
1尝试调整超参数,例如批量大小、迭代周期数和学习率,并查看结果。
batch_size = 256,trainer = torch.optim.SGD(net.parameters(), lr=0.1), num_epochs = 10
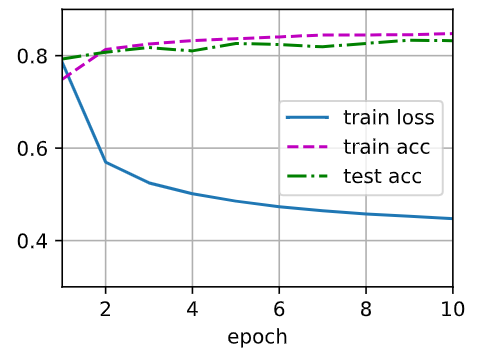
batch_size = 256,trainer = torch.optim.SGD(net.parameters(), lr=0.1), num_epochs = 70

2增加迭代周期的数量。为什么测试精度会在一段时间后降低?我们怎么解决这个问题?
这可能是过拟合现象,可以通过L2正则化、dropout等方法解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号