部署隐语SecretPad及其监控系统clustermon
部署隐语SecretPad及其监控系统clustermon
实验目的与环境
- 部署SecretPad平台并运行一个模型训练任务,SecretPad链接
- 在某个节点运行集群测量,通过promethus获取数据并通过grafana可视化,clustermon链接
- 操作系统:ubuntu 18.04
- 资源要求:8core / 16G Memory / 200G Hard disk
- kuscia运维操作文档:文档链接
部署SecretPad
S1 资源获取:通过SecretPad中的下载链接获得压缩包并解压缩,进入对应目录,目录下具有以下文件:

S2 安装:运行sudo ./install.sh命令,根据提示设置存储路径、账号密码之后,最后获得Successfully init tee app image输出即可,不一定需要获得web server started successfully输出。
Note:如果需要重新install,在运行sudo ./install.sh命令之前,建议先运行sudo ./uninstall.sh命令,并确保已经彻底清空环境,使得该命令的输出如下图所示。如果提示有相关容器没有被清空,需要通过sudo docker stop <容器名>和sudo docker rm <容器名>命令将容器删除之后,重新运行sudo ./uninstall.sh

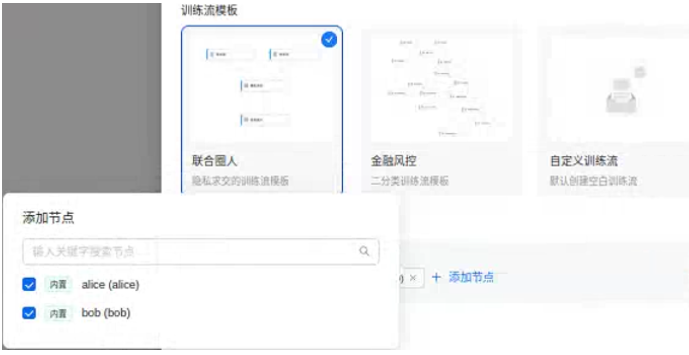
S3 访问界面并运行任务:用浏览器打开127.0.0.1:8088界面,在登录界面输入S2中所设置的账号密码,在新建项目中选择模板并添加节点(默认有两个节点alice和bob),配置数据集(有内置的两个csv数据集)和关键字后,点击“全部执行”即可开始执行任务。
部署运行监控系统clustermon
S1 将所需文件复制到某一方并运行:本实验以在alice节点(即xxx-kuscia-lite-alice)上进行测量为例。运行sudo docker ps命令即可查看各节点名称(本实验alice节点的容器名为root-kuscia-lite-alice)。通过sudo docker cp命令将clustermon文件复制到容器中,然后可以运行go run monitor.go,例如:
sudo docker cp clustermon/ root-kuscia-lite-alice:/home/
Note:建议先进入alice容器,通过pwd等命令确认目标路径后再复制。进入容器的命令如下:
sudo docker exec -it root-kuscia-lite-alice bash
S2 运行grafana并加入kuscia:运行grafana容器,并将其加入kuscia-exchange网络的命令如下:
sudo docker run -itd --name=grafana --restart=always -p 3000:3000 grafana/grafana
sudo docker network connect kuscia-exchange grafana
Note:查看kuscia-exchange网络的连接情况,通过下述命令可以查看加入到网络中的容器:
sudo docker network inspect kuscia-exchange
S3 配置prometheus.yml:在 /home/$USER/prometheus 路径下,放置prometheus.yml文件,内容如下:
global:
scrape_interval: 5s # 默认 5 秒采集一次指标
external_labels:
monitor: 'codelab-monitor'
# Prometheus指标的配置
scrape_configs:
- job_name: 'prometheus'
# 覆盖全局默认采集周期
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090'] # 配置 Prometheus 采集指标暴露的地址
- job_name: 'alice'
scrape_interval: 5s
static_configs:
- targets: ['172.18.0.3:9091'] # 配置机构 IP 地址采集指标暴露的地址
metrics_path: /metrics
scheme: http
S4 运行prometheus并加入kuscia:运行prometheus容器,并将其加入kuscia-exchange网络。注意要将$USER手动修改为具体的绝对路径,避免产生报错。
sudo docker run -d --name prometheus -p 9090:9090 -v /home/$USER/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus:latest --config.file=/etc/prometheus/prometheus.yml
sudo docker network connect kuscia-exchange prometheus
S5 查看对应页面并操作:如果上述操作成功,用浏览器访问prometheus页面(localhost:9090)和grafana页面(localhost:3030)都应该能显示对应界面。根据grafana的操作,添加prometheus数据源并填入对应的url之后,就可以得到可视化界面。
Appendix
关于隐私计算任务失败问题:使用内置的数据集执行任务时,出现隐私求交任务失败的情况。根据排查,本实验中的任务失败是由于内存不足导致,当系统中释放出足够多的内存,重新执行任务即可成功,可通过free -h命令查看空闲内存。
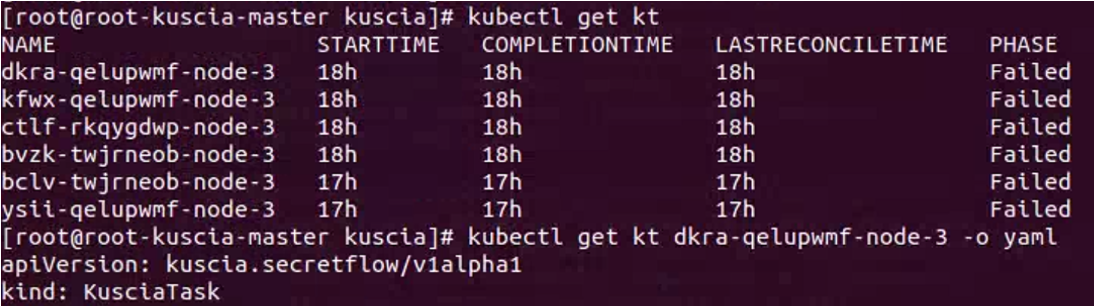
查看任务及其输出:进入master节点的bash之后,kubectl get kt可以查看任务,要查看特定任务的输出,使用kubectl get kt 任务名 -o yaml命令即可,如下所示,可以看到有若干失败的任务:
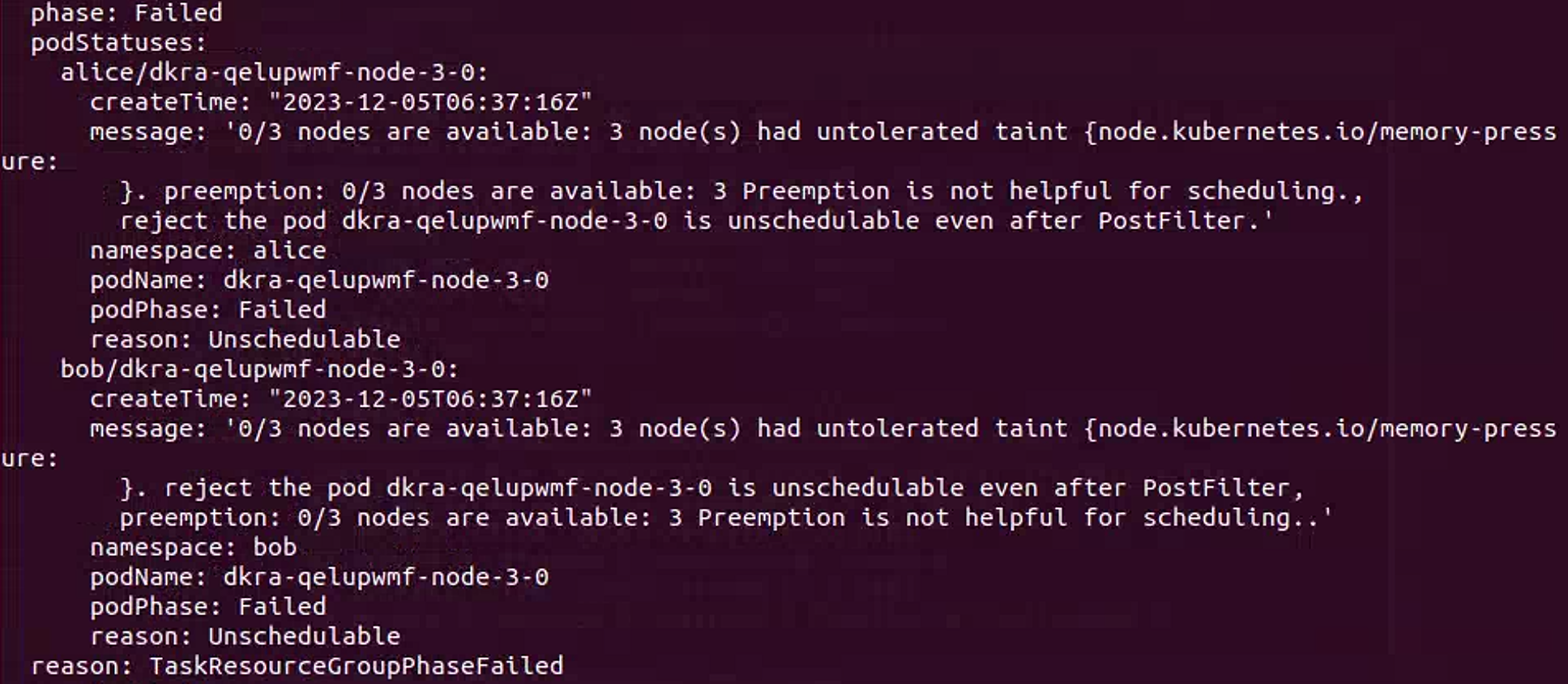
日志分析:在任务的输出中,可以看到had untolerated taint的提示,并且根据memory-pressure的提示,可以推测是因为存在内存压力,所以导致节点被k8s添加了污点,其他污点情况还有disk-pressure等
内存不足的原因:在本实验中,内存不足的原因是大页分配,我们发现剩余内存很少,但top命令又没有看到什么进程占据了很多内存。可以使用grep Huge /proc/meminfo命令查看大页内存分配情况,其中HugePages_Total表示分配的大页内存数量,如果是因为大页内存分配过多,可以通过echo 0 > /proc/sys/vm/nr_hugepages把大页数量强制设置为0,从而释放内存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号