

【硬核】集合论 - 序数 | 教你如何使用 LaTeX
这篇文章打算写 1~2 年(这是刚开始写文章时写的,事实证明大概应该只用三个月)。
如果你看不懂这篇文章,但是还想要让这篇文章对你产生一些知识上的提高,可以管我洛谷私信 uid=663638 要 LaTeX 源码以学习 LaTeX。
由于洛谷博客现在非作者不能使用中国 IP 查看,所以本文同步更新于博客园。
一切的一切开始之前,我们有必要介绍一下自然数(其实可以跳过的)。
自然数由 Peano 公理定义:
- \(0\) 是自然数;
- 每一个自然数 \(x\),都有一个自然数后继 \(x'\);
- \(0\) 不是任何自然数的后继;
- 每个数的后继互不相同;
- 归纳假设:设由一个集合 \(S\) 满足 \(0\in S\) 且 \(\forall x\in S,x'\in S\),则 \(S\) 就是整个自然数集。
有了这个定义,可以很容易的定义加法和乘法,在此不表,留给读者。
我们想知道的是,自然数数完了之后,是否还有数?
当然。
我们设 \(\omega\) 为 \(x\to1+x\) 这个映射的第一个不动点,也就是 \(\aleph_0\)(待查证)。
注意,在序数中,加法、乘法不满足交换律,你必须要记住这一点。
所以 \(x\to1+x\) 这个映射不能写成 \(x\to x+1\),也不能写成 \(x\to x'\)。
那么 \(\omega\) 是否就是最大的数了呢?
非也,\(\omega+1\) 不就比 \(\omega\) 大吗?
\(\omega\) 不是 \(x\to1+x\) 这个映射的不动点吗?\(\omega+1\) 为什么不等于 \(\omega\) 呢?
这是因为序数加法是没有交换律的。
\(\omega=\sup\{0,1,2,3,4,5,\dots\}\),则 \(1+\omega=\sup\{1,2,3,4,5,6,\dots\}\)。
容易看出这只少了一个 \(0\),所以 \(\omega=1+\omega\)。
但是 \(\omega+1\) 是 \(\omega\) 之后的第一个(整?)数,也就是 \(\omega'\)。
那么我们还有 \(\omega+1,\omega+2,\omega+3,\dots\),最后一直到 \(\omega+\omega\),我们将其记作 \(\omega2\)。
注意不能写成 \(2\omega\)。原因同 \(\omega+1\) 不能写成 \(1+\omega\)。
同样,我们有 \(\omega2+\omega=\omega3\),\(\omega n+\omega=\omega(n+1)\)。
最后的最后我们将会得到 \(\omega\omega\),也就是 \(\omega^2\)。
但是 \(\omega^2\) 不是我们旅途的终点,我们还有 \(\omega^2+1,\omega^2+2,\omega^22,\omega^23\dots\omega^2\omega\),最后我们可以得到 \(\omega^3\)。
再继续,我们还有 \(\omega^4,\omega^5,\omega^6,\dots,\omega^{\omega}\)。
继续下去 \(\omega^{\omega}+1,\omega^{\omega}+2,\dots,\omega^{\omega}2,\omega^{\omega}3,\dots,\omega^{\omega}\omega=\omega^{\omega+1},\omega^{\omega+2},\dots,\omega^{\omega2},\dots,\omega^{\omega^{\omega}}\)。
还没有结束,\(\omega^{\omega^{\omega^{\omega}}},\omega\uparrow\uparrow5,\dots,\omega\uparrow\uparrow\omega\)。这里默认读者知道 Knuth 箭头。
我们记 \(\varepsilon_0=\omega\uparrow\uparrow\omega\)。这是 Peano 公理计数的极限(待查证)。
用不动点来表示,就是 \(\varepsilon_0\) 是映射 \(x\to\omega^x\) 的第一个不动点,又称 \(SCO\)。
到目前位置一切都是脑子可以想到的。
接下来我们需要定义 \(\varepsilon_1\),他被定义为 \(x\to\omega^x\) 的第二个不动点,也就是 \(\omega^{\omega^{\dots^{\varepsilon_0+1}}}\)。
然后我们就可以继续往后定义了,\(\varepsilon_x=\omega^{\omega^{\dots^{\varepsilon_{x-1}+1}}}\)。
那么我们有了一系列的 \(\varepsilon\):\(\varepsilon_0,\varepsilon_1,\varepsilon_2,\dots,\varepsilon_{\omega}\)。
\(\varepsilon\) 的下角标可以嵌套,于是我们有了 \(\varepsilon_{\varepsilon_0},\varepsilon_{\varepsilon_{\varepsilon_0}},\varepsilon_{\varepsilon_{{\dots}}}\),于是我们定义 \(\zeta_0\) 为 \(x\to\varepsilon_x\) 的第一个不动点,又称 \(CO\)。
仿照 \(\varepsilon\) 对 \(\zeta\) 进行嵌套,定义 \(\eta_0\)(又称 \(LCO\)),然后是 \(\vartheta_0,\iota_0,\kappa_0,\dots\),但是对于这无穷的序数以有限的希腊字母写出显然不可行。
我们可以定义 \(\varphi\) 函数 ,即 \(\varphi(0,x)=\omega^x,\varphi(1,x)=\varepsilon_x,\varphi(2,x)=\zeta_x,\varphi(3,x)=\eta_x,\varphi(4,x)=\vartheta_x,\varphi(5,x)=\iota_x,\varphi(6,x)=\kappa_x,\dots\),最后我们来到了 \(\varphi(\omega,x),\varphi(\varepsilon_0,x),\varphi(\varphi(\omega,0),0),\varphi(\varphi(\varphi(1,0),0),0)\dots\),最后我们来到了二元 \(\varphi\) 函数能表示的极限,\(x\to\varphi(x,0)\) 的不动点,将其定义为 \(\Gamma_0\),又称 \(FSO\)。
最终还是讨论了我们的多元 \(\varphi\) 函数。\(FSO\) 就是三元 \(\varphi\) 函数的开始,我们也将其记为 \(\varphi(1,0,0)\)。
然后 \(\varphi(1,\Gamma_0+1),\varphi(2,\Gamma_0+1),\varphi(3,\Gamma_0+1),\dots,\varphi(\omega,\Gamma_0+1),\dots\)。
再继续,\(\varphi(\Gamma_0+1,0),\varphi(\varphi(\Gamma_0+1,0),0),\varphi(\varphi(\varphi(\Gamma_0+1,0),0),0),\dots\),这串数列的极限就是 \(\varphi(1,0,0,0)\),哦不对,\(\varphi(1,0,1)\),fk,怎么才刚进了一位!
然后 \(\varphi(1,0,1),\varphi(1,0,2),\dots,\varphi(1,0,\omega)\)。
接着 \(\varphi(1,0,\varphi(1,0)),\varphi(1,0,\varphi(1,0,0)),\varphi(1,0,\varphi(1,0,\varphi(1,0,0))),\varphi(1,0,\varphi(1,0,\varphi(1,0,\varphi(1,0,0)))),\dots\),这串数列的极限就是 \(\varphi(1,0,0,0)\),哦不对,\(\varphi(1,1,0)\),fk!
然后是 \(\varphi(1,2,0),\varphi(1,\omega,0),\varphi(1,\varphi(1,0,0),0),\varphi(1,\varphi(1,\varphi(1,0,0),0),0),\dots\),这串数列的极限就是 \(\varphi(1,0,0,0)\),哦不对,\(\varphi(2,0,0)\),fk!
最后是 \(\varphi(3,0,0),\varphi(4,0,0),\varphi(\omega,0,0),\varphi(\varphi(1,0,0),0,0),\varphi(\varphi(\varphi(1,0,0),0,0),0,0),\varphi(\varphi(\varphi(\varphi(1,0,0),0,0),0,0),0,0),\dots\),这串数列的极限就是 \(\varphi(1,0,0,0)\),这回是真的了,\(\varphi(1,0,0,0)\) 又称 \(AO\)。
我们设 \(\varphi(1,0)=\varphi(1@1),\varphi(1,0,0)=\varphi(1@2),\varphi(1,0,0,0)=\varphi(1@3)\)。
于是根据上述定义,我们有 \(\varphi(1@4),\varphi(1@5),\dots,\varphi(1@\omega)\),也叫 \(SVO\),是多元 Veblen(即 \(\varphi\) 函数)的极限。
然后我们有 \(\varphi(1@\varphi(1@\omega)),\varphi(1@\varphi(1@\varphi(1@\omega))),\dots\),这串数列的极限是 \(LVO\),这便是序元 Veblen 的极限。
这部分要讲的是超序元 Veblen。
我们可以对后面的维度进行进位。
即 \(\varphi(1@(0,0))\) 是 \(\varphi(1@\omega)\),\(\varphi(1@(1,0))\) 是 \(LVO\),可以将 \(\varphi(1@(\dots))\) 类比成 \(\varphi(\dots)\) 进位,这样的话,类比成 \(SVO\) 的就是 \(\varphi(1@(1@(1,0)))\),类比成 \(LVO\) 的就是 \(\varphi(1@(1@(1@(1@\dots))))\),这个序数被叫做 \(BHO\),这是超序元 Veblen 函数的极限,往后 Veblen 失去了他的意义。
现在我们开启了一个新的篇章,即 OCF。
我查到的 OCF 都是直接上定义,这对新手十分的不友好,所以我会把这个玩意讲清楚。
首先我们有三个数 \(0,1,\omega\),和三种序数运算加法、乘法和乘方。
通过这些能达到最大的数是 \(\omega\uparrow\uparrow\omega=\varepsilon_0\),那么我们令 \(\psi(0)=\varepsilon_0\)。
然后我们现在已经有了 \(0,1,\omega,\psi(0)=\varepsilon_0\),那么我们再做一遍,就可以得到 \(\varepsilon_0\uparrow\uparrow\omega=\varepsilon_1\)。
一直往后做,得到 \(\psi(x)=\varepsilon_x\),\(x\) 可以是任何序数小于 \(\zeta_0\) 的序数。
这里,我们对 \(\psi(x)\) 下一个具体的定义:
- \(C^0(x)=\{0,1,\omega\}\);
- \(C^{n+1}(x)=\{a+n,ab,a^b,\psi(c)|a,b,c\in C^n(x),c<x\}\);
- \(C(x)=\bigcup\limits_{0\le n<\omega}C^n(x)\);
- \(\psi(x)=\operatorname{mex}C(x)\)。
注意第三条规则中的 \(n\) 不能是 \(\omega\),这个不起眼的地方决定了现在的 OCF 在 \(x=\zeta_0\) 的时候早早取到极限。
由于 \(\varepsilon_{\zeta_0}=\zeta_0\),所以 \(\psi(\zeta_0)=\zeta_0\),而 \(\psi(\zeta_0+1)\) 并不是 \(\varepsilon_{\zeta_0+1}\),因为 \(\max C^n(x)\) 仅仅是 \(\varepsilon^{(n)}_x\),只有 \(\max C^{\omega}(x)\) 才能真正达到 \(\zeta_0\),所以很可惜,\(\psi(\zeta_0+1)=\zeta_0\)。
那么 \(\forall x\ge\zeta_0,\psi(x)=\zeta_0\),这不免让我们失望。
但是我们会有更加强大的方式的!
我们设 \(\Omega\) 为第一个非递归序数,也就是 \(\omega_1^{CK}\)(待查证),这里你不需要理解 \(\Omega\) 是什么,你只需要知道它很大,比我们知道的任何序数还要大且无法通过任何运算达到就行了。我们将 \(0,1,\omega\) 的初始值变成 \(0,1,\omega,\Omega\),每次选取的为不包含 \(\Omega\) 的最大的非递归序数。
显然对于所有的 \(\zeta_0\le x\le\Omega\),事情并不会发生任何变化。
当 \(x=\Omega+1\) 时,事情开始有了一丝转机,由于 \(\Omega<\Omega+1\),\(\psi(\Omega)=\zeta_0\) 就可以作为元素放进 \(C^1(x)\),于是 \(\psi(\Omega+1)=\varepsilon_{\zeta+1}\),更一般的,对于所有的 \(1\le x\le \zeta_0,\psi(\Omega+x)=\varepsilon_{\zeta_0+x}\)。
事实上这个上界不仅是 \(\zeta_0\) 了!
我们还有 \(\psi(\Omega+\psi(\Omega+\zeta_0))\),这些嵌套可以一直嵌套到映射 \(x\to\psi(\Omega+x)\) 的不动点,\(\zeta_1\)。
和刚才的情况类似,\(\forall \zeta_1\le x\le\Omega,\psi(\Omega+x)=\zeta_1\)。
然而考虑 \(\psi(\Omega2+1)\),和刚才 \(\psi(\Omega+1)\) 的分析类似,\(\psi(\Omega2+1)=\varepsilon_{\zeta_1+1}\)。
然后推下去有 \(\psi(\Omega x)=\zeta_{x-1}\)。
那么我们有 \(\psi(\Omega\omega)=\zeta_{\omega}\)。
接着,\(\psi(\Omega\psi(\Omega))=\zeta_{\zeta_0},\psi(\Omega\psi(\Omega\psi(\Omega)))=\zeta_{\zeta_{\zeta_0}}...\),最后达到了 \(x\to\psi(\Omega x)\) 的不动点,\(\eta_0\)。
然后对于 \(\psi(\Omega\eta_0)\) 到 \(\psi(\Omega^2)\) 的情况都是一样的,\(\eta_0\)。
直到 \(\psi(\Omega^2+\Omega)\) 获得进一步的增长。
一直下去,会有 \(\psi(\Omega^3)=\vartheta_0\),一直到 \(\psi(\Omega^x)=\varphi(x+1,0)\) 便是极限。
接着再玩一层不动点,\(x\to\psi(\Omega^x)\) 的不动点就是 \(\Gamma_0\),也就是 \(\varphi(1,0,0)\),直到 \(\psi(\Omega^{\Omega})\) 一直如此。
然后再将自变量进一步增大,\(\psi(\Omega^{\Omega}2)=\varphi(1,0,1),\psi(\Omega^{\Omega+1})=\varphi(1,1,0),\psi(\Omega^{\Omega^2})=\varphi(1@3),\psi(\Omega^{\Omega^x})=\varphi(1@(x+1))\),最终得到了序元 Veblen 的极限 \(\psi(\Omega^{\Omega^{\Omega}})=\varphi(1@(1,0))\)。
然后再往上叠 \(\Omega\) 的指数塔,最后叠到 \(\psi(\Omega\uparrow\uparrow\omega)=\psi(\varepsilon_{\Omega+1})\),也即超序元 Veblen 的极限 \(BHO\)。
直到这里 OCF 和 Veblen 能表示的东西还是一样的。
我们创造性的定义一个新的非递归序数 \(\Omega_2=\omega_2^{CK}\),再定义一个 OCF \(\psi_1(x)\),输出一个 \(\Omega\) 至 \(\Omega_2\) 间的序数。
我们再定义一个 \(C_1\),除了初始集合和 \(C\) 不一样意外其余都一样,初始集合 \(C_1^0(x)=\Omega\cup\{\Omega\}=\{x|x\le\Omega\}\)。
有了更为厉害的 \(\psi_1\) 后,我们要把 \(\psi\) 改造成和他原先定义彼此彼此的 \(C^0(x)=\{0,1,\omega,\Omega,\Omega_2\}\)。
这样看来,\(\psi(\psi_1(0))\) 就是 \(BHO\),然后接着迭代一系列的序数,最后得到了 \(\psi(\zeta_{\Omega+1})\),这个序数很大,大到现有的记号已经没有它的第二种表示形式了。
但是我们还可以做到更好:在第一内层中引入 \(\Omega_2\),然后类似没有 \(\Omega_2\) 时,最后会达到 \(\psi(\varepsilon_{\Omega_2+1})\)。
接着我们已经做了示范,可以照葫芦画瓢引出 \(\Omega_3,\dots,\Omega_{\omega}\)。然后我们得到了 \(\psi(\Omega_{\omega})=BO\)。
然后接着扩展,\(\psi(\Omega_{\omega+1})=TFBO,\psi(\Omega_{\Omega})=BIO\),然后最后得到 \(x\to\psi(\Omega_x)\) 的不动点 \(EBO\),可以用反射序数表示为 \(\psi(\psi_I(0))\)。
接下来,我们要对 OCF 打断一下,讲一下“反射序数”。他是用来创造更大的序数的。别着急,OCF 还会以一种更安全、更专业、更温暖的方式回来,也许可以算是本文的第 \(3\) 章。
首先需要介绍一下 \(\operatorname{pseudo.}x\),他表示的是在 OCF 下,\(x\) 折叠的序数 \(y\),例如 \(\operatorname{pseudo.}\Omega=\zeta_0\),缩写是 \(\operatorname{psd.}\Omega=\zeta_0\)。
我们先定义集合 \(\Pi_0=\{1,2,3,4,5,6,7,\dots,\omega+1,\omega+2,\dots\}\)。
然后我们将取 \(\Pi_0\) 中的所有极限点,就可以得到 \(\Pi_1=\{\omega,\omega2,\omega3,\dots\}\)。
我们将其缩写为 \(1\)。
接下来我们需要介绍一些符号:
\(\min 1\) 表示 \(1\) 中的最小值。
\(x\th 1\) 表示 \(1\) 中的第 \(x\) 小值。
\(1\operatorname{aft}x\) 表示 \(1\) 中大于 \(x\) 的最小值。
然后我们对 \(1\) 再求一次极限点,\(\Pi_1 \operatorname{onto} \Pi_1=\{\omega^2,\omega^22,\omega^23,\dots\}\),在这里,为了防止 ,我们将 \(\operatorname{onto}\) 简写为 \(-\),\(\Pi_1 \operatorname{onto} \Pi_1\) 可以简写为 \(1-1\)。\operatorname{onto} 占据大部分篇幅
然后重复作用 \(1-1\),可以得到 \(1-1-1\),\(1-1-1-1\) 等等。
我们记 \((x-)^ny=x-x-x-x-x-\dots-x-y\),其中共有 \(n\) 个 \(-\)。特别的,当 \(x=y\),我们可以将 \(y\) 省略。
另外,我们有时候会将 \(\min\) 省略,\(1-1=\min1-1=\omega^2\)。
这样一直到 \((1-)^{\omega}=\omega^{\omega}\),由于 \(\omega\) 就是 \(\min1\),我们将其记作 \((1-)^{((1))}\)。
然后再对指数进行迭代 \((1-)^{(1-)^{((1))}},(1-)^{(1-)^{(1-)^{((1))}}}\) 等等,最后达到了无穷层,我们按照 Veblen 不动点的形式来表示,最后达到了 \((1-)^{(1,0)}=\varepsilon_0\)。
然后再按 Veblen-way 继续迭代,这个过程已经在 Veblen 那里描述过了。事实上,\((1-)^{(x)}=\varphi(x)\)。
看到没有,反射序数略微出手就达到了 Veblen 的强度,前途无量啊!
可是仅凭 \(\Pi_1\) 最多最多只能达到 Veblen 的强度了。那么我们继续扩展,来看到我们的 \(\Pi_2\)。
\(\Pi_2\) 是所有非递归序数的集合,\(\{\Omega_1,\Omega_2,\dots,\Omega_{\omega+1},\dots\}\)。
这里需要注意,\(\Omega_\omega\) 不在 \(\Pi_2\) 中,因为他是通过 \(\Omega_x\) 递归得到的。
但是我们对 \(\Pi_2\) 取极限点,得到 \(\Pi_1\operatorname{onto}\Pi_2(1-2)\),他是 \(\{\Omega_\omega,\Omega_{\omega2},\dots\}\)。
然后可以再取一次 \(\Pi_1\),得到 \((1-)^22=\Omega_{\omega^2}\)(这里省略了 \(\min\)),然后 \((1-)^n2=\Omega_{\omega^n}\)。
然后到了 \((1-)^{((1))}2=\Omega_{\omega^\omega}\),\((1-)^{((2))}2=\Omega_{\Omega}\),\((1-)^{(1,0)}2=\Omega_{\Omega_{\Omega_{\dots}}}\),这是 \(x\to\Omega_x\) 的不动点。
然后还可以套娃到更牛的东西,不过我们不讨论。
以上所有序数都是通过递归方式得到的,不在 \(2\) 中。那么 \(2\) 和 \(1-2\) 有没有交呢?
幸运的是,有的。我们记 \(2\ 1-2\) 为 \(I\),其中空格表示 \(\cap\)。
我们在前面讨论了 \(\operatorname{psd.}\),那么我们注意到,我们可以说 \(\operatorname{psd.}I=(1-)^{(1,0)}2\),因为他们的 \(\psi\) 相同。然后我们又有 \(2\operatorname{aft}I=\Omega_{I+1}\)。
之后我们将会省略括号,所有表达式从右到左。
我们有了 \(\Omega_{I+1}\),未尝不能有 \(\Omega_{I+\Omega},\Omega_{I2},\Omega_{I+\Omega_{I+1}},\Omega_{I+\Omega_{I+\Omega_{I+1}}}\dots\),这一过程的极限是 \(\operatorname{psd.}I_2\)。
然后我们对 \(2\operatorname{aft}2\ 1-2\) 求容许点,得到 \(2-1\ 2\operatorname{aft}2\ 1-2=I_2\)。
对了,行文至此,文章破 10000 字大关,这是我两天写出来的东西!
接着我们还有 \(I_3,I_4,\dots,I_\omega,\dots,I_I\)。
然后我们有对 \(x\to I_x\) 取不动点,得到的是 \(\operatorname{psd.}I(1,0)\)。
然后用 \(2\ 1-\) 折叠 \((1-)^x\),即将不动点替换成容许点,就可以得到 \(2\ 1-2\ 1-2=I(1,0)\)。
现在我们得到了一个和 \(\varphi\) 性状相似的 \(I\),只不过,\(\varphi\) 是不动点进制,而 \(I\) 是容许点进制。
然后重走 Veblen 的老路,最后可以得到 \(I(1@(1@(1@(1@\dots))))\),这是 \(I\) 函数的极限。
在一切的一切之上,有 Mahlo 序数 \(M=2-2\)。
然后我们有 \(2\operatorname{aft}2-2=\Omega_{M+1},2\ 1-2\operatorname{aft}2-2=I_{M+1},(2\ 1-)^{(1,0)}2\operatorname{aft}2-2=I(1,0,M+1)\)。
然后用 \(2-2\) 折叠 \((2\ 1-)^x\),得到 \(2\operatorname{nd}2-2=M_2\)。
然后 \(1-2-2=M_\omega,1-1-2-2=M_{\Omega},(1-)^{(2\ 1-2)}2-2=M_I,(1-)^{(2-2)}2-2=M_M,(1-)^{(1,0)}2-2=M_{M_{M_{M_\dots}}}=M-\varphi(1,0),1-(1-)^{(1,0)}2-2=M-\varphi(1,\omega)\dots\),然后还有 \(2\ 1-2-2=M-I(1,0),1-2\ 1-2-2=M-I(1,\omega),1-1-2\ 1-2-2=M-I(1,\Omega),(2\ 1-)^{((2))}2-2=M-I(\Omega,0)\dots\),最后得到了 \(2-2\ 1-2-2=M(1,0)\)。
可以这么理解:\(M-I(1,0)=\operatorname{psd.}M(1,0),M-\varphi(1,0)=\operatorname{psd.}\operatorname{psd.}M(1,0)\)。
然后在 \(M\) 之上,脚步跨的大一点,有 \(2-2-2=N\),接着我们还会有 \(2-2-2-2,(2-)^4,(2-)^\omega\),直到 \(2-\) 的极限。
在所有这些序数之上,我们还有 \(\Pi_3\) 基数,以及对应的递归弱紧致基数 \(K\),\(3-\) 折叠了所有 \((2-)^x\)。
我们在这里将会给出反射序数的展开规则(原理未知):
- 删掉所有的空格和 \(-\),反转表达式,并在开头添加 \(1\);
- 找到最后一个数 \(a_k\),找到这之前第一个比它晓得数 \(a_i\);
- 如果不存在这样的 \(a_i\),在序列首添加一个 \(a_k-1\);
- 如果 \(a_i=a_k-1\),执行展开 \(\#_1,a_i,\#_2,a_k\to\#_1,a_i,\#_2,a_i,\#_2,a_i,\#_2,a_i,\#_2,a_i,\#_2,a_i\dots\);
- 否则,执行展开 \(\#_1,a_i,\#_2,a_k\to\#_1,a_i,\#_2,a_{k-1},a_i,\#_2,a_{k-1},a_i,\#_2,a_{k-1},a_i,\#_2,a_{k-1},a_i,\#_2,a_{k-1},a_i\dots\);
- 将表达式反转,删去最后的 \(1\),设相邻两项为 \(a,b\)。
- 若 \(a>b\),在中间添加空格,否则在中间添加 \(-\)。
然后就可以得到更大的反射序数,\(\Pi_4,\Pi_5,\dots,\operatorname{psd.}\Pi_\omega\)。
然后又有 \(\operatorname{psd.}\Pi_\omega-\operatorname{psd.}\Pi_\omega,\operatorname{psd.}\Pi_\omega-\operatorname{psd.}\Pi_\omega-\operatorname{psd.}\Pi_\omega,\operatorname{psd.}\Pi_\omega-\operatorname{psd.}\Pi_\omega-\operatorname{psd.}\Pi_\omega-\operatorname{psd.}\Pi_\omega,\dots,\Pi_\omega,\Pi_\Omega,\Pi_{\Pi_{\Pi_{\Pi_0}}},\Pi_{\Pi_{\Pi_{\Pi_\dots}}}\)。
事实上,角标还能扩展,这将使得 \(\Pi\) 和 \(\varphi\) 也有相似的行为,不过这不重要。我们将要回到我们熟悉的 OCF 了。
我们定义 \(\psi_I(0)\) 为 \(\Omega\) 的下标不动点。
定义多元 \(\Phi\) 函数,把 \(\varphi\) 的定义从 \(\omega\) 的指数不动点改成 \(\Omega\) 的下标不动点。
那么 \(\psi_I\) 和 \(\Phi\) 的类比就像是 \(\psi\) 和 \(\varphi\) 的类比,为了节省篇幅,我们就不加以解释了。
我们的内层也可以引入 \(I\),\(\psi_I(I)=\Phi(2,0)\) 等,这使得我们可以继续类比下去。
由于 \(\psi_I\) 所代表的序数是带 \(\Omega\) 的,所以我们再把它到 \(\psi\) 里头套。
容易看出 \(\psi(\psi_I(0))=EBO\)。
然后我们又有了一系列序数,即把刚才得到的序数放进 \(\psi\) 里。
最后有 \(\psi(\psi_I(0)^{\psi_I(0)^{\psi_I(0)^{\psi_I(0)^\dots}}})=\psi(\psi_{\Omega_{\psi_I(0)+1}}(0))\),然后继续指数塔,嵌套到极限了时候再嵌套一下 \(\Omega\) 下标,最后的最后,真的到极限了之后才能达到 \(\psi(\psi_I(1))\)。
继续走我们走过的路,直奔 \(\psi(\psi_I(\omega)),\psi(\psi_I(\Omega))\),最后得到的是 \(\psi(\psi_I(I))\)。我们定义 \(\psi(I)=\psi(\psi_I(I))\)。
然后我们就有 \(\psi(I^2),\psi(I^I),\psi(I\uparrow\uparrow\omega)=\psi(\psi_{\Omega_{\psi_I(0)+1}}(0))\),然后还可以增大到 \(\psi(\Omega_{I+1})\),又叫 \(JO\)。
然后还能增大到 \(\psi(\Omega_{\Omega_{\Omega_{\dots_{I+1}}}})\),这等于 \(\psi(\psi(I_2(0)))\)。
继续套娃,继续套娃,\(\psi(\psi_{I_2}(I))=\psi(\psi_{I_2}(\psi_I(\psi_{I_2}(\dots(0)))))\),\(\psi(I_2)=\psi(\psi_{I_2}(\psi_{I_2}(\psi_{I_2}(\dots(0)))))\)。
继续,\(\psi(I_3),\psi(I_{\omega}),\psi(I_\Omega),\psi(I_I),\psi(I_{I_I})\)。
然后 \(\psi(I(1,0)),\psi(I(1@\omega)),\psi(I(1@(1,0)))\),这是含 \(I\) OCF 的极限,当然还能类似 \(\varphi\) 的扩展,不过意义不大。
我们将 \(\psi_M(x)\) 上面的 \(\psi_I(x)\),并将 \(\Phi\) 类比成 \(I\) 继续套娃。初始值 \(\psi_M(0)=\varepsilon_0\)。
值得一提的是,中间有一个点 \(\psi(\varepsilon_{M+1})=SRO\)。
最后依照上述,我们将会达到 \(\psi(M(1@(1,0)))\)。
然后将 \(N,2-2-2-2,(2-)^4,(2-)^5,\dots,(2-)^\omega\) 折叠,然后再折叠 \((2-)^{(1,0)},(2-)^{(1,0,0)},\dots,(2-)^{(1@\omega)},\dots\) 最后达到了 \((2-)^x\) 的极限。
在这之上,我们的 \(K\) 就会派上用场,折叠,\(\psi(\varepsilon_{K+1})\) 被叫做 \(RO\),然后 \(\psi(\varepsilon_{\Pi_4+1})\) 被叫做 \(DO\),最后 \(\psi(\varepsilon_{\Pi_\omega+1})\) 被叫做 \(SSO\)。
我们可以套到 \(\Pi\) 的下标不动点,我们将 \(\psi(\Pi_{\Pi_{\Pi_{\Pi_\dots}}})\) 称作 \(LSO\),用稳定序数表示为 \(\psi(\lambda\alpha.(\alpha2)-\Pi_0)\)。
这可以看做本文的第 \(4\) 章:稳定序数。我们仍然是先暂停一会 OCF 的旅程,它会回来的。
看这一章的时候,你需要确保你完全了解了前一章。
并没有理解最优子结构,但是疑似在这块不太需要,所以就不讲了。
首先我们需要一个 \(\lambda\alpha.\alpha\),他的意思是将 \(\alpha\) 稳定到 \(\alpha\)。
人话:\(\lambda\alpha.\alpha-\Pi_x=\Pi_{1+x}\)。
请注意这里是 \(1+x\) 而非 \(x+1\)。
末尾的 \(\Pi\) 相当于一个计数器,逢 \(\omega\) 进 \(1\)。也就是 \(\lambda\alpha.(\alpha+1)-\Pi_0=\lambda\alpha.\alpha-\Pi_\omega=\Pi_\omega\)。
这样的话 \(\lambda\alpha.(\alpha+x)-\Pi_0\) 的 \(x\) 可以不断增大:\(\lambda\alpha.(\alpha+2)-\Pi_0=\Pi_{\omega2},\lambda\alpha.(\alpha+\omega)-\Pi_0=\Pi_{\omega^2},\lambda\alpha.(\alpha+\Omega)-\Pi_0=\Omega\dots\),内部还可以继续嵌套,\(\lambda\alpha.(\alpha+\lambda\alpha.(\alpha+1)-\Pi_0)-\Pi_0\dots\),最后得到的是 \(x\to\lambda\alpha.(\alpha+x)-\Pi_0\) 的不动点,它是 \(\lambda\alpha.\alpha2-\Pi_0\)。如果用类 \(\varphi\) 模式,\(\lambda\alpha.\alpha2-\Pi_0=\Pi(1,0)\)。
然后,\(\lambda\alpha.\alpha2-\Pi_1\) 折叠 \((\lambda\alpha.\alpha2-\Pi_0-)^n\),\(\lambda\alpha.\alpha2-\Pi_2\) 折叠 \((\lambda\alpha.\alpha2-\Pi_1-)^n\),\(\lambda\alpha.(\alpha2+1)-\Pi_0=\lambda\alpha.\alpha2-\Pi_\omega,\lambda\alpha.(\alpha2+\omega)-\Pi_0,\lambda\alpha.\alpha3-\Pi_0,\lambda\alpha.\alpha\omega-\Pi_0,\lambda\alpha.\alpha^2-\Pi_0,\lambda\alpha.\alpha^3-\Pi_0,\lambda\alpha.\alpha^\omega-\Pi_0,\lambda\alpha.\alpha^\alpha-\Pi_0,\lambda\alpha.\alpha^{\alpha^\alpha}-\Pi_0,\dots,\lambda\alpha.\varepsilon_{\alpha+1}-\Pi_0\)。
对了,本文在这里破了 1.5k 字大关,可喜可贺!
最后我们来到了这种迭代运算永远达不到的点,\(\lambda\alpha.\Omega_{\alpha+1}-\Pi_1\)。
请注意,这里结尾是 \(\Pi_1\) 而不是 \(\Pi_0\)。
更一般的,设这个稳定序数是 \(\lambda\alpha.f(\alpha)\),若 \(f(\alpha)\) 是 \(\Pi_n\) 集合中的,那么第一个尾数就是 \(\Pi_{n-1}\)。
然后 \(\lambda\alpha.(\Omega_{\alpha+1}+1)-\Pi_0\),这里由于 \(\Omega_{\alpha+1}+1\) 不再在 \(\Pi_2\) 中了,所以尾数可以是 \(\Pi_0\) 了。
继续变大,\(\lambda\alpha.(\Omega_{\alpha+1}+\omega)-\Pi_0,\lambda\alpha.(\Omega_{\alpha+1}+\alpha)-\Pi_0,\lambda\alpha.(\Omega_{\alpha+1}+\varepsilon_{\alpha+1})-\Pi_0,\lambda\alpha.\Omega_{\alpha+1}2-\Pi_0,\lambda\alpha.\Omega_{\alpha+1}^2-\Pi_0,\lambda\alpha.\Omega_{\alpha+1}^{\Omega_{\alpha+1}}-\Pi_0,\dots,\lambda\alpha.\Omega_{\alpha+2}-\Pi_1\)。
\(\lambda\alpha.\Omega_{\alpha+3}-\Pi_1,\lambda\alpha.\Omega_{\alpha+4}-\Pi_1,\dots,\lambda\alpha.\Omega_{\alpha+\omega}-\Pi_0\)。
注意 \(\Omega_{\alpha+\omega}\) 不在 \(\Pi_2\) 中。
然后 \(\lambda\alpha.I_{\alpha+1}-\Pi_1,\lambda\alpha.M_{\alpha+1}-\Pi_1,\lambda\alpha.N_{\alpha+1}-\Pi_1,\lambda\alpha.K_{\alpha+1}-\Pi_2,\lambda\alpha.\kappa_{\alpha+1}-\Pi_3,\dots,\lambda\alpha.\omega\operatorname{aft}\alpha-\Pi_\omega\)。
我们注意到一个很奇怪的现象,这里最小的尾数就是 \(\Pi_\omega\) 了,但是稳定序数的计数器逢 \(\omega\) 进 \(1\),也就是说,在这里稳定序数达到了极限,这已经大大扩张了反射序数。
既然 \(\alpha\) 能稳定到某个东西,那么我们可以让 \(\alpha\) 稳定到某个 \(\beta\),再让 \(\beta\) 稳定到 \(\beta+1\)。
两段稳定链的开端是 \(\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0)-\Pi_0\),它的值是一段稳定链的极限。
这里外层的尾部 \(\Pi\) 不小于内层的尾部 \(\Pi\)。
然后将外层的 \(\Pi\) 扩大到 \(\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0)-\Pi_\omega\),然后这样就将内层 \(+1\)。
然后是 \(\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0+1)-\Pi_0,\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0+\omega)-\Pi_0,\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_02)-\Pi_0,\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0^2)-\Pi_0,\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0)-\Pi_0^{\lambda\beta.(\beta+1)-\Pi_0}-\Pi_0,\dots\)。
然后是 \(\lambda\alpha.\Omega_{\lambda\beta.(\beta+1)-\Pi_0+1}-\Pi_0,\lambda\alpha.K_{\lambda\beta.(\beta+1)-\Pi_0+1}-\Pi_0,\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_0\operatorname{aft}\lambda\beta.(\beta+1)-\Pi_0)-\Pi_0=\lambda\alpha.(2\operatorname{nd}\lambda\beta.(\beta+1)-\Pi_0)\),然后就进行 \(1-,2\ 1-,\omega\ 1-,2-,\omega-\) 折叠,最后到了 \(\lambda\alpha.((\lambda\beta.(\beta+1)-)^{\beta})-\Pi_0\),折叠这一切的是 \(\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_1)-\Pi_1\)。
然后 \(\lambda\alpha.(\lambda\beta.(\beta+1)-\Pi_2)-\Pi_2,\dots,\lambda\alpha.(\lambda\beta.\omega\operatorname{aft}\beta-\Pi_\omega)-\Pi_\omega\)。
这步跳的有点大,大到和上一节整节一样大。
然后二段稳定就结束了。
接着,我们还会有三段稳定链、四段稳定链、……、\(n\) 段稳定链。
我们记 \(n-\pi-f-\Pi_x\) 表示所有稳定链的尾数都是 \(\Pi_x\),稳定链底端是 \(f(\theta)\)(这里 \(\theta\) 代指最后一个稳定序数)。
所以我们来到了 \(\omega-\pi-\Pi_0\)。\(f\) 不重要,到 \(\omega\) 这个等级的什么 \(f\) 都一样。
然后我们为了节省字数,多跳几步,直接跳到 \(x\to x-\pi-\Pi_0\) 的不动点,这是 \(\Sigma_1\) 稳定的弱极限。我们将其记为 \(\alpha(\alpha(0))\),也可以记作 \(\lambda\alpha.(\alpha-\pi-\Pi_0)-\Pi_0\)。
啥?OCF?
这玩意不是上面的东西套个 \(\psi\) 就行的?
该讲的第 \(3\) 章最后一节都讲了,列举几个有名字的序数吧。
- \(LSO=\psi(\lambda\alpha.\alpha2-\Pi_0)\);
- \(BGO=\psi(1-\lambda\alpha.\Omega_{\alpha+2}-\Pi_1)\);
- \(SDO=\psi(\lambda\alpha.\Omega_{\alpha+\omega}-\Pi_0)\);
- \(LDO=\psi(\lambda\alpha.\psi_I(\alpha+1)-\Pi_0)\);
- \(LRO=\psi(\omega-\pi-\Pi_0)\):
- \(FSLSO=\psi(\alpha(\alpha(0)))\)。
第 \(5\) 章,强 \(\Sigma_1\) 极限。
我们对于一条反射链,比如 \(\alpha\to\beta\to\beta+1\),我们定义其 \(\alpha(0)=\alpha,\alpha(1)=\beta,\alpha(2)=\beta+1\)。
如果一个序数后面能接 \(n\) 条稳定链,我们称其为 \(n-\text{ply-stable}\)。
考察一条长度为 \(\omega\) 的稳定链,对于任何有限数 \(x\),\(\alpha(x)\) 是 \(\omega-\operatorname{ply-stable}\) 的。
那么 \(\alpha(0)\) 等于第一个 \(\omega-\operatorname{ply-stable}\),\(\omega-\pi-\Pi_0\)。
\(\alpha(\omega)\) 就等于 \(1-\omega-\operatorname{ply-stable}=1-\omega-\pi-\Pi_0\)。
继续增大,\(\omega-\pi-\Pi_0\ 1-\omega-\pi-\Pi_0,2-\omega-\pi-\Pi_0,\omega-\omega-\pi-\Pi_0,\omega-\pi-\Pi_0-\omega-\pi-\Pi_0,(\omega-\pi-\Pi_0-)^n\),折叠这一切的是 \(\lambda\alpha.(\omega-\pi-\Pi_0)-\Pi_1\)。
然后,\(\lambda\alpha.(\omega-\pi-\Pi_0)-\Pi_\omega=\lambda\alpha.(\omega-\pi-\Pi_0+1)-\Pi_1,\lambda\alpha.(\omega-\pi-\Pi_02)-\Pi_1,\lambda\alpha.(\omega-\pi-\Pi_0^2)-\Pi_1,\lambda\alpha.(\omega-\pi-\Pi_0^{\Pi_0})-\Pi_1,\dots,\lambda\alpha.(\omega-\pi-\Pi_0-\omega-\pi-\Pi_0),\dots,\lambda\alpha.((\omega-\pi-\Pi_0-)^n),\dots\),折叠这一切的是 \(\lambda\alpha.(\omega-\pi-\Pi_1)-\Pi_1=\omega-\pi-\Pi_1\)。
然后,\(\omega-\pi-\Pi_2,\omega-\pi-\Pi_\omega,\dots,(\omega+1)-\pi-(+1)-\Pi_0\)。
然后 \((\omega+2)-\pi-(+1)-\Pi_0,\omega2-\pi-\Pi_0,\omega^2-\pi-\Pi_0,\omega^\omega-\pi-\Pi_0,\dots,\varepsilon_0-\pi-\Pi_0\)。
接着 \(\zeta_0-\pi-\Pi_0,\Omega-\pi-\Pi_0,M-\pi-\Pi_0,K-\pi-\Pi_0,\dots,\alpha(\alpha(0))\)。
我们介绍了 \(\alpha\) 函数并达到了 \(\Sigma_1\) 的弱极限,这是好的。
接下来,我们记 \(\alpha(x)=\lambda\alpha.x-\Pi_0\),这也是 \(\Sigma_1\) 的弱极限被记作 \(\alpha(\alpha(0))\) 的原因。
坐稳,扶好,我们要冲刺了。
在 \(\alpha(\alpha(0))\) 之后,下一个应当是 \(\alpha(\alpha(0)+1)\)。
\(\lambda\alpha.(\alpha-\pi-\Pi_0)-\Pi_0,\lambda\alpha.(\alpha-\pi-\Pi_0 \operatorname{onto}\alpha-\pi-\Pi_0)-\Pi_0,\dots,\lambda\alpha.(\alpha-\pi-\Pi_1)-\Pi_1,\dots,\lambda\alpha.(\alpha+1-\pi-(+1)-\Pi_0)-\Pi_0=\alpha(\alpha(0)+1)\)。
\(\lambda\alpha.(\alpha+2-\pi-(+1)-\Pi_0)-\Pi_0,\lambda\alpha.(\alpha2-\pi-\Pi_0)-\Pi_0,\lambda\alpha.(\alpha^2-\pi-\Pi_0)-\Pi_0,\lambda\alpha.(\alpha^2-\pi-\Pi_0)-\Pi_0,\lambda\alpha.(\alpha^\alpha-\pi-\Pi_0)-\Pi_0,\lambda\alpha.(\Omega_{\alpha+1}-\pi-\Pi_0)-\Pi_0,\dots,\alpha(\alpha(1))\)。省略号所省略掉的东西是一直套 \(\alpha\) 条稳定链。
然后 \(\alpha(\alpha(2)),\dots,\alpha(\alpha(\omega))\)。这也可以记作 \(\lambda\alpha.(\omega-\pi_1-\Pi_0)-\Pi_0\)。
继续堆 \(\alpha\),\(\alpha(\alpha(\omega)+1),\alpha(\alpha(\omega+1)),\alpha(\alpha(\omega2)),\alpha(\alpha(\omega^2)),\alpha(\alpha(\omega^\omega)),\alpha(\alpha(\varepsilon_0)),\dots,\alpha(\alpha(\alpha(0)))\)。
然后是 \(\alpha^{(4)}(0),\alpha^{(5)}(0),\alpha^{(\omega)}(0),\alpha^{(\alpha(0))}(0),\dots\) 直到 \(x\to\alpha^{(x)}(0)\) 的不动点。这是 \(\operatorname{psd.}\alpha(1,0)\)。怎么把 \(\operatorname{psd.}\) 消掉已经演示过了,把不动点换成 \(\alpha\) 点就行。
然后我们把 \(\alpha\) 类比成 \(\varphi\),直到它自己的极限,我们称其为,\(\Pi_3[2]\)。
好像破 2w 字了。
第六章,中括号稳定。
我们考虑如下的集合:\(\{\beta\in\alpha\mid\beta\prec_1\alpha\}\),这是所有稳定到 \(\alpha\) 序数的序数的集合。
那么如果 \(\alpha\in\Pi_n[2]\),那么 \(\alpha\in n-\{\beta\in\alpha\mid\beta\prec_1\alpha\}\)。
在 \([]\) 反射中,\(\Pi_0,\Pi_1,\Pi_2\) 等价,所以为了使得序数看起来变得更大,我们将最小的中括号反射序数记作 \(\Pi_2[2]\),这也是最小的 \(\text{Nonprojectable}\) 序数(以下简称 \(\text{Np}\))。
\(\alpha(0)\) 是第一个 \(\Pi_2[2]\) 序数,之后每增加 \(\omega\) 就会有一个新的 \(\Pi_2[2]\),比如 \(\alpha(\omega3)\) 是 \(4\th \Pi_2[2]\)。
我们直接一步到位 \(\Pi_3[2]\)。
我们接下来会将 \(\Pi_a[b]\) 记作 \(a_b\)。\(\Pi_3[2]\) 就会被写作 \(3_2\)。
接着再爬稳定塔:
\(\lambda\alpha.3_2-\Pi_2,\lambda\alpha.(3_2+1)-\Pi_0,\lambda\alpha.(3_22)-\Pi_0,\lambda\alpha.(2\operatorname{nd}3_2)-\Pi_2,\lambda\alpha.(1-3_2)-\Pi_0,\lambda\alpha.(\omega-3_2)-\Pi_\omega,\dots\),这样的话,一段的 \(3_2\) 便极限了。
然后我们已经可以知道怎么搞——加入多段稳定链,直到稳定链也用完了,就可以得到 \(3_2\ 0-3_2\)。
然后 \(3_2\ 1-3_2,3_2\ 2-3_2,3_2\ 3-3_2,3_2\ 4-3_2\)。
这个 \(3_2\ 4-3_2\) 可以直接写成 \(3_2\ 4\),这里出现了“序数吸收”现象,比如说 \(\omega=1+\omega,\omega\omega^\omega=\omega^\omega,\omega^{\varepsilon_0}=\varepsilon_0\) 就是“序数吸收”。
这样可以到 \(3_2\ (1)\),即 \(3_2\ \omega\),接着 \(3_2\ (+1)- \Pi_0,3_2\ \omega-\pi-\Pi_0,3_2\ \lambda\alpha.3_2-\Pi_2,\dots\),然后就是又来多条稳定链,直到 \(\omega\) 条稳定链的 \((0-3)_2\)。
注意,\((0-3)_2\not=0-3_2\)。
然后就是,如果是第 \(\omega^k\) 条稳定链,那么序数就是 \(((0-)^k-3)_2\)。
然后仿照第 \(3\) 章中的 \(I\),我们设一个序数 \((3\ 0-3)_2\)。
因为这个序数太厉害了,所以我认为我们应该写出他的全名:\(\Pi_{\Pi_3\cap\Pi_0\operatorname{onto}\Pi_3}[2]\),注意这里的下标不是 \(\min\) 的缩写,而是实实在在的集合,这折叠了 \((0-)^{(\dots)}[2]\)。
并且我们有,\(\Pi_x-\operatorname{stable}\) 折叠 \((x-1-)^{(\dots)}[2]\)。
然后就可以继续扩展了,\((0-3\ 0-3)_2,(0-0-3\ 0-3)_2,(3\ 0-3\ 0-3)_2,(3-3)_2,(3-3-3)_2,\dots,4_2\)。
我们已经到达了 \(4_2\),自然就有 \(5_2\)、\(6_2\)、\(7_2\),直到 \(\operatorname{psd.}\omega_2\)。
我们想把 \(\operatorname{psd.}\) 摘掉该怎么做呢?
其实这是很一样的,再按着上述规则迭代一次,就是 \(\omega_2\)。
由于 \(\omega_2\) 会和之后的一些东西引起歧义,我们会写它的全称——\(\Pi_\omega[2]\),或许也会将其记作 \(\omega_{[2]}\)(其实之前也应该这么叫,不过由于懒癌等原因省略了 \([]\),结果发现到 \(\omega\) 这里就歧义了)。
\([2]\) 反射的使命完成了,接下来是 \([2]\) 稳定!
和 \([1]\) 稳定一样,我们用 \(\Pi_\omega\) 代指 \(\operatorname{psd.}\Pi_\omega\),而 \(\Pi_{\omega+1}\) 代指 \(\Pi_\omega\)。
和 \([1]\) 稳定一样,我们记 \(\lambda\alpha.(\alpha+1)-\Pi_0[2]=\Pi_\omega\),再强调一遍,这里是有 \(\operatorname{psd.}\) 的。
请注意区分 \([1]\) 上和 \([2]\) 上的 \(\operatorname{onto}\),\(0-\omega_{[2]}\not=(0-\omega)_{[2]}\)。
然后注意到除了最后加了个 \([2]\),和 \([1]\) 稳定是没有区别的,所以直接快进到 \((\lambda\alpha.(\omega-\pi-\Pi_0)-\Pi_0)[2]\)。
然后是 \((\lambda\alpha.(\alpha-\pi-\Pi_0)-\Pi_0)[2],(\lambda\alpha.\alpha(1,0)-\Pi_0)[2]\)。
然后内层开始出现 \([2]\) 反射序数,\((\lambda\alpha.\Pi_3[2]-\Pi_0)[2]\),然后多条稳定链套上 \((\lambda\alpha.((\lambda\beta.(\beta+1)-\Pi_0)[2]))[2]\),然后再上稳定链,就是二阶的 \(\omega-\pi_{[2]}-\Pi_0\)。
再爬塔到顶端,则是 \(\operatorname{psd.}\Pi_0[3]\),我们也到达了 \([3]\) 领域,当然,还需要摘掉 \(\operatorname{psd.}\)。
\(\omega-\pi_{[2]}-\Pi_0[2]=\lambda\alpha.(\omega-\pi_{[2]}-\Pi_0)-\Pi_0\),这是三个 \(\operatorname{psd.}\)。
然后先摘掉 \([1]\) 上的 \(\operatorname{psd.}\),爬一层塔,将其变成 \(\lambda\alpha.(\lambda\beta-(\omega-\pi_{[2]}-\Pi_0)-\Pi_1)-\Pi_1\)。
然后摘掉 \([2]\) 上的 \(\operatorname{psd.}\),进行稳定链的堆叠,变成 \((\lambda\alpha.(\omega-\pi_{[2]}-\Pi_0)-\Pi_1)[2]\)。
再摘掉 \([3]\) 上的 \(\operatorname{psd.}\),再次堆稳定链,直到 \(\omega-\pi_{[2]}-\Pi_1\),这是真正的 \(\Pi_0[3]\) 了。
接着就 \(\Pi_0[4],\Pi_0[5],\dots,\operatorname{psd.}\Pi_0[\omega]\)。
对他进行一阶稳定、……、\(\omega\) 阶稳定,这就是摘掉了一个 \(\operatorname{psd.}\)。
然后再将以上过程重复 \(\omega\) 次,就得到了真正的 \(\Pi_0[\omega]\)。
\(\Pi_0[\omega]\) 也是一条稳定链的底端,我们可以继续迭代往后增加。
\(0_\omega,0_\omega\ 1-0_\omega,0_\omega\ 3_2,\dots,\operatorname{psd.}(0-0)_\omega\),然后再用同样的方法摘掉 \(\operatorname{psd.}\)。
这看出 \([\omega]\) 也能同样方法套上去,于是来到了 \([\omega]\) 稳定,\(\lambda\alpha.\alpha+1-\Pi_1[\omega]\)。
稳定结束就是 \(\omega-\pi-\Pi_1[\omega]\),接着来到了 \(\Pi_0[\omega+1]\)。
接着,\(\Pi_0[\omega2],\Pi_0[\omega^2],\Pi_0[\omega^\omega],\Pi_0[\varepsilon_0],\Pi_0[\Omega]\)。
然后就是 \(\lambda\alpha.\Pi_0[\alpha]-\Pi_1\),然后再迭代 \(\alpha\),到二段稳定链,然后是三段,四段……
然后内层套 \(\alpha\operatorname{aft}\Pi\),然后再套 \(\alpha\) 函数,最后套到 \(\Pi\)。
最后的最后,\(\lambda\alpha.(\lambda\beta.\Pi_0[\beta]-\Pi_1)-\Pi_1\) 终结了中括号稳定。
第 \(7\) 章就是投影序数了。
我们熟悉的 OCF 又回到了我们的视线。
这部分记号太乱,不保证我的记法就是大众记法。
首先我们需要介绍一下 \((\min)\ 2-\operatorname{Projection}\)(后简称 \(2-\operatorname{pjt}\),在分析中一般记作 \(a\))。
他的规则为:
- \(\psi_a(0)=\Omega\);
- \(\psi_a(n+1)=\psi_a(n)\omega\);
- \(\psi_a(\#\sim a)\) 是 \(\alpha\to\psi_a(\#\sim\alpha)\) 的不动点;
- \(\psi_a(\#\sim X_{a+1})=\sup\{\psi_a(\#\sim x)|n\le X_{a+1}\}\)。
破 2.5w 字了。
然后就是若干扽西工作,这里列几个结点:
- \(\psi_a(n)=\Omega\omega^n\);
- \(\psi_a(a)=\varepsilon_{\Omega+1}\);
- \(\psi_a(\Omega_{a+1})=\Omega_2\);
- \(\psi_a(\Omega_{a+1}\omega)=\Omega_\omega\);
- \(\psi_a(\Omega_{a+1}^2)=I\);
- \(\psi_a(\Omega_{a+1}^{a+1})=I(1,0,0)\);
- \(\psi_a(\Omega_{a+1}^{\Omega_{a+1}})=M\);
- \(\psi_a(\varepsilon_{\Omega_{a+1}2})=\Pi_\omega\);
- \(\psi_a(\varphi(a,\Omega_{a+1}+1))=\lambda\alpha.\alpha2-\Pi_0\);
- \(\psi_a(\Omega_{a+2})=\lambda\alpha.\Omega_{\alpha+1}-\Pi_2\);
- \(\psi_a(\Omega_{a+\omega})=\lambda\alpha.\Omega_{\alpha+\omega}-\Pi_0\)。
以后的事,有 \(\psi_a(X(a))=\lambda\alpha.X(\alpha)-\Pi_0\)。
这个强度已经等同于一段稳定序数了。
然而 \(2-\operatorname{pjt}\) 不止一个,我们统一的定义:
- \(\psi_{a_{n+1}}(0)=a_n\);
- \(\psi_{a_n}(n+1)=\psi_{a_n}(n)\omega\);
- \(\psi_{a_n}(\#\sim a_n)\) 是 \(\alpha\to\psi_{a_n}(\#\sim\alpha)\) 的不动点;
- \(\psi_{a_n}(\#\sim X_{a_n+1})=\sup\{\psi_a(\#\sim x)|n\le X_{a_n+1}\}\)。
然后再列几个扽西的结点:
- \(\psi_a(\psi_{a_2}(a_2))=\psi_a(a_2)=\psi_a(\varepsilon_{a+1})\);
- \(\psi_a(a_n)=n-\pi-\Pi_0\);
- \(\psi_a(a_\omega)=\omega-\pi-\Pi_0\)。
这是 \(2-\operatorname{pjt}\) 的极限。
接着,\(3-\operatorname{pjt}\) 虽迟但到。由于我们刚才分析了很多,所以我们会直接分析 \(n-\operatorname{pjt}\)。
- \(\psi_{n-\operatorname{pjt}_m}(0)=(n-1)-\operatorname{pjt}_{n-\operatorname{pjt}_{m-1}}\);
- \(\psi_{n-\operatorname{pjt}_m}(t+1)=\psi_{n-\operatorname{pjt}_m}(t)\omega\);
- \(\psi_{n-\operatorname{pjt}_m}(\#\sim n-\operatorname{pjt}_m)\) 是 \(\alpha\to \psi_{n-\operatorname{pjt}_m}(\#\sim\alpha)\) 的不动点;
- \(\psi_{n-\operatorname{pjt}_m}(\#\sim X_{n-\operatorname{pjt}_m+1})=\sup\{\#\sim x|x<X_{n-\operatorname{pjt}_m+1},X\in\operatorname{pjt}_{\{1,2,\dots,n\}}\}\)。
他们刻画了很大的序数,我们接下来会用 BMS(见下一章)来分析几个关键点:
- \(\psi_a(\psi_b(a(b+1)^\omega))=(1,1,1)(2,2,2)(3,2,2)(4,2,2)(4,0,0)\);
- \(\psi_a(\psi_b(a(b+1)^a))=(1,1,1)(2,2,2)(3,2,2)(4,2,2)(4,1,0)(2,0,0)\);
- \(\psi_a(\psi_b(a(b+1)^b))=(1,1,1)(2,2,2)(3,2,2)(4,2,2)(4,2,0)(3,0,0)\);
- \(\psi_a(\psi_b(a(b+\omega)))=(1,1,1)(2,2,2)(3,3,2)(4,0,0)\);
- \(\psi_a(b_\omega)=(1,1,1)(2,2,2)(3,3,3)\);
- \(\psi_a(c_\omega)=(1,1,1)(2,2,2)(3,3,3)(4,4,4)\);
- \(\psi_a(n-\operatorname{pjt}_\omega)=(1,1,1)(2,2,2)(3,3,3)\dots(n,n,n)\);
- \(\psi_a(\omega-\operatorname{pjt})=(1,1,1,1)\);
- \(\psi(\omega-\operatorname{pjt})=(0,0,0,0)(1,1,1,1)=\text{TSSO}\)。
这是三行 BMS 的结束(尽管我们还没有讲 BMS),也是 OCF 真正的告一段落。理论上这才是第二章的结束。
接下来是第八章 BMS。
由于作者认为这个东西只需要讲定义,所以接下来的内容扽西为主讲解为辅(而不是像之前一样反过来)。
但是由于不可抗力因素,我们需要先讲 PrSS,不讲这个理解 BMS 是困难的。
PrSS 形如 \((a_1,a_2,\dots,a_n,\dots)\)。
一个序列作为一个合法的 PrSS,必要条件就是:
- \(a_1=1\);
- \(\forall k,a_{k+1}\le a_{k}+1\)。
注意这仅仅是必要条件,有很多满足这个条件的可能不是那么合法。
首先我们定义好部、坏部和坏根:
- 最后一个比最后一个数小的数称作坏根;
- 坏根之后(含)的数是坏部(不含最后一个数);
- 不是坏部且不是最后一个数的就是好部。
然后就是 PrSS 的展开规则:
- \(()=0\);
- 若 \(a_n=1\),则把 \(a_n\) 删去计算序数,再把计算完的结果 \(+1\);
- 如果 \(a_n\not=1\),则把好部保留,把最后一个数删去,把坏部无限重复,例如 \((1,2)\) 展开成 \((1,1,1,1,\dots)\),\((1,2,3)\) 展开成 \((1,2,2,2,2,\dots)\)。
那么,开始扽西!
最简单的就是 \((1,1,1,1,\dots)\),有几个 \(1\) 就是几。
然后 \((1,2)\) 是 \(\omega\) 个 \(1\),所以是 \(\omega\)。
\((1,2,1)=\omega+1,(1,2,1,1)=\omega+2,(1,2,1,2)=(1,2,1,1,1,1,\dots)=\omega2,(1,2,1,2,1,2)=\omega3,(1,2,2)=(1,2,1,2,1,2,1,2,\dots)=\omega^2\)。
\((1,2,2,1)=\omega^2+1,(1,2,2,1,2)=\omega^2+\omega,(1,2,2,1,2,2)=\omega^22,(1,2,2,2)=(1,2,2,1,2,2,1,2,2,1,2,2,\dots)=\omega^3,(1,2,2,2,2)=\omega^4,(1,2,3)=(1,2,2,2,2,\dots)=\omega^\omega\)。
\((1,2,3,1)=\omega^\omega+1,(1,2,3,1,2)=(1,2,3,1,1,1,1,\dots)=\omega^\omega+\omega,(1,2,3,1,2,3)=(1,2,3,1,2,2,2,2,\dots)=\omega^\omega2,(1,2,3,2)=(1,2,3,1,2,3,1,2,3,1,2,3,\dots)=\omega^{\omega+1}\)。
\((1,2,3,2,2)=\omega^{\omega+2},(1,2,3,3)=(1,2,3,2,3,2,3,2,3\dots)=\omega^{\omega^2},(1,2,3,4)=(1,2,3,3,3,3,\dots)=\omega^{\omega^\omega}\)。
\((1,2,3,4,5)=\omega\uparrow\uparrow5,\dots,(1,2,3,4,5,6,\dots)=\omega\uparrow\uparrow\omega=\varepsilon_0\)。
这是 PrSS 的极限。
PrSS 很弱,但是他是之后我要讲的所有记号(除 FFFZ)的基础。
把 \(a_{k+1}\le a_k+1\) 去掉,定义 \((1,3)=(1,2,3,4,5,6,\dots),(1,4)=(1,3,5,7,\dots)\) 可以得到 lPrSS。
引入阶差序列的概念可以得到 hPrSS。
多层求阶差序列可以得到 0-Y。
将序数改成多行,就是接下来要讲的 BMS。
(其实本来想讲一讲 Hydra,后来发现其实没啥必要。)
接下来要说一说 BMS 了。
BMS 是一个矩阵,但是它一般写作若干个数列的形式,一个列一个列的记(如 \((0,0)(1,1)\))。
一个合法的 BMS 要满足对于每一列,前面的行总是大于后面的行,且首列必须全为 \(0\)。
先说在 BMS 中的定义。
对于第一行,父项是和它在同一行的在它前面的比他小的最后一个数(这句话有点绕,本质上就是 PrSS 中的坏根)(由于 PrSS 父项和坏根定义相同,所以 PrSS 中只有坏根)。
祖先项指的是父项、父项的父项等的集合。
对于非第一行,在第一行父项的条件下,还要满足父项的上一行是现在元素的上一行的祖先项。
坏根指的是最后一行最后一个非 \(0\) 数的父项所在列。
好部指的是坏根(不含)前面的列。
坏部指的是坏根(含)后面的列(不含最后一行)。
阶差数列指的是最后一列按位减去坏根的值,注意如果最后一列有一项为 \(0\),那么阶差数列对应的上一项也要置为 \(0\)。
然后就可以说展开规则了。
- 如果最后一列全是 \(0\),把最后一列去掉并将算出的序数 \(+1\);
- 否则将好根保留,将坏根无限重复,第 \(i\) 次重复加上 \(i-1\) 倍阶差;
- 为了防止不会停机的问题,如果一个元素的祖先项不包含坏根元素,那么复制的时候这个元素保持不变。
另外,在没有歧义的情况下,我们可以把最末尾的 \(0\) 删去。
然后,开始扽西!
双行 BMS 的扽西点就很构式,大家忍着点。
显然一行 BMS 就是 PrSS 每个元素减 \(1\)。
\((0)(1,1)=(0)(1)(2)(3)\dots=\varepsilon_0,(0)(1,1)(0)=\varepsilon_0+1,(0)(1,1)(0)(1,1)=\varepsilon_02,(0)(1,1)(0)(1,1)(0)(1,1)=\varepsilon_03,(0)(1,1)(1)=(0)(1,1)(0)(1,1)(0)(1,1)(0)(1,1)=\varepsilon_0\omega,(0)(1,1)(1)(2,1)=\varepsilon_0^2,(0)(1,1)(1)(2,1)(2)(3,1)=\varepsilon_0^{\varepsilon_0},(0)(1,1)(1,1)=(0)(1,1)(1)(2,1)(2)(3,1)(3)(4,1)=\varepsilon_1\)。
破 3w 字了。
\((0)(1,1)(1,1)(1,1)=\varepsilon_2,(0)(1,1)(2)=\varepsilon_\omega,(0)(1,1)(2)(1,1)=\varepsilon_{\omega+1},(0)(1,1)(2)(1,1)(2)=\varepsilon_{\omega2},(0)(1,1)(2)(3)=\varepsilon_{\omega^\omega},(0)(1,1)(2)(3,1)=\varepsilon_{\varepsilon_0},(0)(1,1)(2,1)=\zeta_0\)。
\((0)(1,1)(2,1)(2,1)=\eta_0,(0)(1,1)(2,1)(2,1)(2,1)=\varphi(4,0),(0)(1,1)(2,1)(3)=\varphi(\omega,0),(0)(1,1)(2,1)(3)(2,1)=\varphi(\omega+1,0),(0)(1,1)(2,1)(3)(4,1)=\varphi(\varphi(1,0),0),(0)(1,1)(2,1)(3,1)=\varphi(1,0,0),(0)(1,1)(2,1)(3,1)(3,1)=\varphi(1,0,0,0),(0)(1,1)(2,1)(3,1)(4)=\varphi(1@\omega),(0)(1,1)(2,1)(3,1)(4)(5,1)=\varphi(1@\varepsilon_0),(0)(1,1)(2,1)(3,1)(4)(5,1)(6,1)(7,1)(8)=\varphi(1@\varphi(1@\omega)),(0)(1,1)(2,1)(3,1)(4,1)=LVO=\varphi(1@(1,0))=\psi(\Omega^{\Omega^\Omega})\)。
现在开始换 OCF 来分析。
\((0)(1,1)(2,2)=\psi(\varepsilon_{\Omega+1})=\psi(\psi_1(0)),(0)(1,1)(2,2)(2,2)=\psi(\psi_1(1)),(0)(1,1)(2,2)(3,1)=\psi(\psi_1(\Omega)),(0)(1,1)(2,2)(3,2)=\psi(\Omega_2),(0)(1,1)(2,2)(3,3)=\psi(\psi_2(0)),(0)(1,1)(2,2)(3,3)(4,4)=\psi(\psi_3(0)),(0)(1,1,1)=(0)(1,1)(2,2)(3,3)(4,4)\dots=\psi(\Omega_\omega)\),这是双行 BMS 的极限。
然后就是三行 BMS 了。
二行 BMS 还是“和蔼可亲”,三行就是和癌可氢了!
三行的极限比你想象的要大,三行 BMS 的极限是 \(\psi(\omega-\operatorname{Projection})\)。
说完这些文字就开始扽西了。
\((0)(1,1,1)(2,1)=\psi(\Omega_\omega\Omega),(0)(1,1,1)(2,1)(1,1,1)=\psi(\Omega_\omega^2),(0)(1,1,1)(2,1)(3,2)=\psi(\Omega_{\omega+1}),(0)(1,1,1)(2,1,1)=\psi(\Omega_{\omega^2}),(0)(1,1,1)(2,1,1)(3,1)=\psi(\Omega_\Omega)\)。
然后就是反射序数了。
\((0)(1,1,1)(2,1,1)(3,1)(2)=\psi(I),(0)(1,1,1)(2,1,1)(3,1,1)=\psi(I_\omega),(0)(1,1,1)(2,1,1)(3,1,1)(2,1,1)(3,1)(2)=\psi(\psi_{I(1,0)}(0)),(0)(1,1,1)(2,1,1)(3,1,1)(3)=\psi(I(\omega,0)),(0)(1,1,1)(2,1,1)(3,1,1)(3,1,1)=M_\omega,(0)(1,1,1)(2,1,1)(3,1,1)(4,1,1)=K_\omega,(0)(1,1,1)(2,2)=\psi(\Pi_\omega)\)。
然后开始稳定序数。
\((0)(1,1,1)(2,2)(3,1,1)(4,2)=\psi(\lambda\alpha.\alpha+2-\Pi_0),(0)(1,1,1)(2,2)(3,2)=\psi(\lambda\alpha.\alpha+\omega-\Pi_0),(0)(1,1,1)(2,2)(3,2)(4,1)(2)=\psi(\lambda\alpha.\alpha2-\Pi_0),(0)(1,1,1)(2,2)(3,2)(4,1)(3,2)(4,1)(2)=\psi(\lambda\alpha.\alpha^2-\Pi_0),(0)(1,1,1)(2,2,1)(3)=\psi(\lambda\alpha.\Omega_{\alpha+\omega}-\Pi_0),(0)(1,1,1)(2,2,2)=\psi(\omega-\pi-\Pi_0)\)。
然后是稳定。
这一部分在稳定分析过了,注意稳定里面需要左边来个 \(\psi()\),右边最前面来个 \((0)\)。
最后就做完了。
然后就到了 \(TSSO\)。
然后是四行极限 \(QSSO\)。
据称有一种可以将投影扩展到 \(QSSO\) 的方法,但我不会。
最后是有限行 BMS 的极限 \((0)(1,1,1,1,1,\dots)=SHO\)。
BMS 完。
我们回到了对 PrSS 的扩展。我们会讲的是 lPrSS。
说来 lPrSS 也简单,就是去除 PrSS 中 \(a_i+1\ge a_{i+1}\) 的性质,定义展开方式如下:
- \(()=0\);
- 若 \(a_n=1\),则把 \(a_n\) 删去计算序数,再把计算完的结果 \(+1\);
- 如果 \(a_n\not=1\),则把好部保留,把最后一个数删去,把坏部无限重复,并且每次重复都是上一次重复的值加上 \(a_n-a_k-1\),其中 \(a_k\) 是坏根,例如 \((1,2)\) 展开成 \((1,1,1,1,\dots)\),\((1,2,3)\) 展开成 \((1,2,2,2,2,\dots)\),\((1,3,3)\) 展开成 \((1,3,2,4,3,5,4,6,\dots)\)。
那么继续开始扽西。
\((1,3)\) 之前,lPrSS 就是 PrSS。
写了几个关键点,事实上分析起来还是很构式的。
\((1,3)=\varepsilon_0,(1,3,1,3)=\varepsilon_02,(1,3,2)=\varepsilon_0\omega,(1,3,2,2)=\varepsilon_0\omega^2,(1,3,2,3)=\varepsilon_0\omega^\omega,(1,3,2,3,4)=\varepsilon_0\omega^{\omega^\omega},(1,3,2,4)=\varepsilon_0^2,(1,3,2,4,2,4)=\varepsilon_0^3,(1,3,2,4,3)=\varepsilon_0^\omega,(1,3,2,4,3,3)=\varepsilon_0^{\omega^2},(1,3,2,4,3,4)=\varepsilon_0^{\omega^\omega},(1,3,2,4,3,4,5)=\varepsilon_0^{\omega^{\omega^\omega}},(1,3,2,4,3,5)=\varepsilon_0^{\varepsilon_0},(1,3,3)=\varepsilon_1,(1,3,3,3)=\varepsilon_2,(1,3,4)=\varepsilon_\omega,(1,3,4,4)=\varepsilon_{\omega^2},(1,3,4,5)=\varepsilon_{\omega^\omega},(1,3,5)=\varepsilon_{\varepsilon_0},(1,4)=\zeta_0\)。
从 \(1,4\) 到 \(1,5\) 是春春答辩,有兴趣的各位可以品尝一下,这里就不过多说明了。
\((1,4,2)=\zeta_0\omega,(1,4,2,4)=\zeta_0\varepsilon_0,(1,4,2,5)=\zeta_0^2,(1,4,2,5,3)=\zeta_0^\omega,(1,4,2,5,3,5)=\zeta_0^{\varepsilon_0},(1,4,2,5,3,6)=\zeta_0^{\zeta_0},(1,4,3)=\varepsilon_{\zeta_0+1},(1,4,4)=\zeta_1,(1,4,4,4)=\zeta_2,(1,4,5)=\zeta_\omega,(1,4,6)=\zeta_{\varepsilon_0},(1,4,7)=\zeta_{\zeta_0},(1,5)=\eta_0\)。
\((1,5,2)=\eta_0\omega,(1,5,3)=\varepsilon_{\eta_0+1},(1,5,4)=\zeta_{\eta_0+1},(1,5,5)=\eta_1,(1,5,6)=\eta_\omega,(1,5,7)=\eta_{\varepsilon_0},(1,5,8)=\eta_{\zeta_0},(1,5,9)=\eta_{\eta_0},(1,6)=\vartheta_0,(1,7)=\iota_0,\dots,(1,\omega)=\varphi(\omega,0)\)。
lPrSS 的规则是简单的,与之相对的是,它的极限也是弱的。
接下来到场的是 hPrSS。与 lPrSS 不同,hPrSS 充分运用了“阶差”的思想。
定义在序列中一个数的“子坏根” \(c_i\) 为 \(\max\{k<i|a_k<a_i\}\),“阶差” \(b_i\) 为 \(a_i-a_{c_i}\)。
展开时,如果最后一项阶差为 \(1\) 则按 PrSS 规则展开。
否则,画出山脉图。
山脉图绘画方式如下:
在 \(a_i\) 上方写上数字 \(b_i\),并连两条线,一条是从 \(a_i\) 连到 \(b_i\),一条是从 \(a_{c_i}\) 连到 \(b_i\)。
这时候,上方的一个数的父项为:向左下走一步再向上走一步,一直重复直到得到一个小于当前数的数为止。
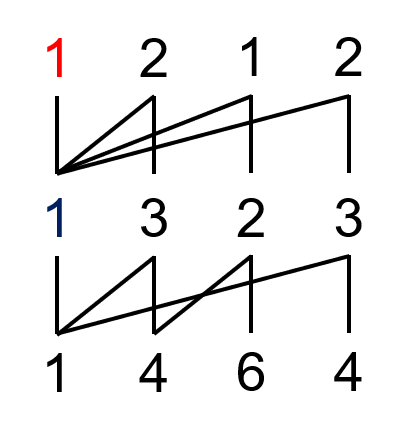
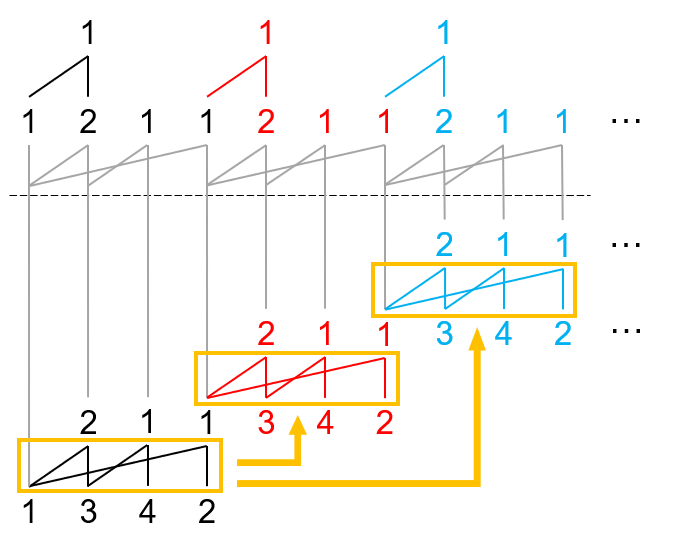
举个例子:\((1,4,6,4,1,4,6,3,6,8)^H\)。
画出山脉图是(感谢知乎用户 Suzuka梅天狸 提供的图片,以后类似风格的图都是从他那里贺的):
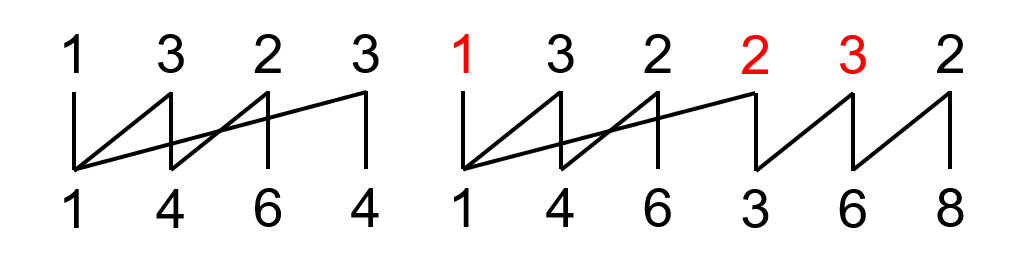
那么右上脚的 \(2\) 可以走到的地方就是红色的,那么右上角数的父项就是左中的 \(1\)。
右上角数字的父项称作坏根。
hPrSS 的展开方式是,忽略上面一行坏根及以前的数字及其所连的边和下面一整行数字,然后将右上脚数字减 \(1\),最后将还没有忽略的数字和边重复 \(\omega\) 次,然后把忽略的边和数字填上,最后再根据规则在下面一行填上合理的数字。
例如,上面举的例子的展开就是:
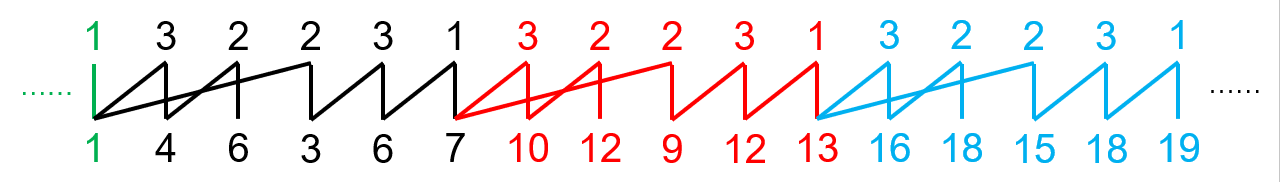
省略了前四项和后面若干项。
既然规则搞明白了就又可以开始扽西了。
以下表格将列出 OCF、hPrSS 表达式、Veblen、lPrSS 表达式。
| MOCF | hPrSS | Veblen | lPrSS |
|---|---|---|---|
| \(<\psi(\psi(0))\) | Same as lPrSS | \(<\varepsilon_{\varepsilon_0}\) | \(<(1,3,5)\) |
| \(\psi(\psi(0))\) | \((1,3,4,6)\) | \(\varepsilon_{\varepsilon_0}\) | \((1,3,5)\) |
| \(\psi(\psi(\psi(0)))\) | \((1,3,4,6,7,9)\) | \(\varepsilon_{\varepsilon_{\varepsilon_0}}\) | \((1,3,5,7)\) |
| \(\psi(\Omega)\) | \((1,3,5)\) | \(\zeta_0\) | \((1,4)\) |
| \(\psi(\Omega2)\) | \((1,3,5,3,5)\) | \(\zeta_1\) | \((1,4,4)\) |
| \(\psi(\Omega\omega)\) | \((1,3,5,4)\) | \(\zeta_\omega\) | \((1,4,5)\) |
| \(\psi(\Omega^2)\) | \((1,3,5,5)\) | \(\eta_0\) | \((1,5)\) |
| \(\psi(\Omega^3)\) | \((1,3,5,5,5)\) | \(\varphi(4,0)\) | \((1,6)\) |
| \(\psi(\Omega^\omega)\) | \((1,3,5,6)\) | \(\varphi(\omega,0)\) | \((1,(1,2))\) |
| \(\psi(\Omega^\Omega)\) | \((1,3,5,7)\) | \(\varphi(1,0,0)\) | \(limit=(1,(1,(1,\dots)))\) |
| \(\psi(\Omega^{\Omega\omega})\) | \((1,3,5,7,6)\) | \(\varphi(\omega,0,0)\) | |
| \(\psi(\Omega^{\Omega^2})\) | \((1,3,5,7,7)\) | \(\varphi(1@3)\) | |
| \(\psi(\Omega^{\Omega^\omega})\) | \((1,3,5,7,8)\) | \(\varphi(1@\omega)\) | |
| \(\psi(\Omega^{\Omega^\Omega})\) | \((1,3,5,7,9)\) | \(\varphi(1@(1,0))\) | |
| \(\psi(\Omega\uparrow\uparrow4)\) | \((1,3,5,7,9,11)\) | \(\varphi(1@(1@(1,0)))\) | |
| \(\psi(\psi_1(0))\) | \((1,4)\) | \(limit=\varphi(1@(1@(1@\dots)))\) | |
| \(\psi(\psi_1(1))\) | \((1,4,4)\) | ||
| \(\psi(\psi_1(\omega))\) | \((1,4,5)\) | ||
| \(\psi(\psi_1(\Omega))\) | \((1,4,6)\) | ||
| \(\psi(\Omega_2)\) | \((1,4,7)\) | ||
| \(\psi(\psi_2(0))\) | \((1,5)\) | ||
| \(\psi(\psi_3(0))\) | \((1,6)\) | ||
| \(\psi(\Omega_\omega)\) | \(limits=(1,\omega)\) |
也就是说 hPrSS 的极限就是 \(\psi(\Omega_\omega)\)。
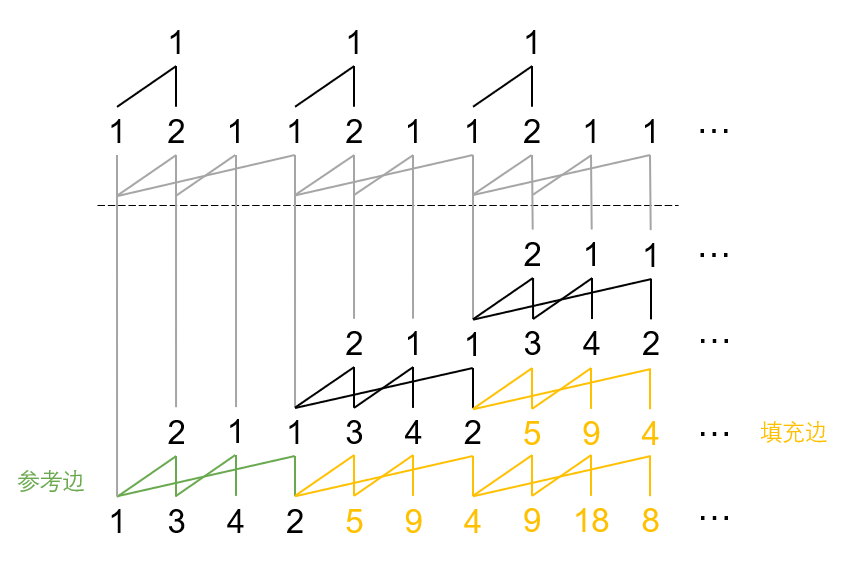
0-Y 对阶差序列的运用则更为充分,用到了多次求阶差的方式。
阶差序列意义同 hPrSS。
0-Y 山脉图的绘画方式如下:
不停的取阶差序列,直到父项等于末项减一。
展开方式如下:
将山脉图最上方按 hPrSS 最上方规则展开,然后和 hPrSS 一样复制、代回。
这里代回有一个特殊规则:如果坏部的某一项的父项位于坏根所在列之前,那么复制的时候只把靠右的边端点向右平移,靠左的边端点固定不变。
回忆一下 BMS 也有一个看上去莫名其妙的规则:如果一个元素的祖先项不包含坏根元素,那么复制的时候这个元素保持不变。
那么,这是否说明,BMS 和 0-Y 本质相同?
当然!不过这是后话。
和 BMS 一样,这条规则也是为了使 0-Y 停机,从而不会 ill-defined。
举个例子,\(0-Y(1,5)\) 的展开。
先画出山脉图:
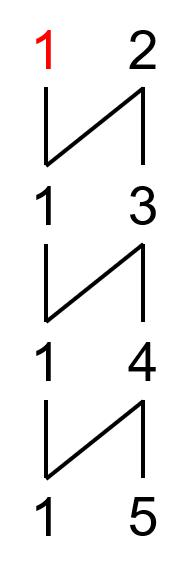
坏根已经标出。那么展开规则就是对右上元素的 \(2\) 进行减一操作,然后无限重复,最后就是:
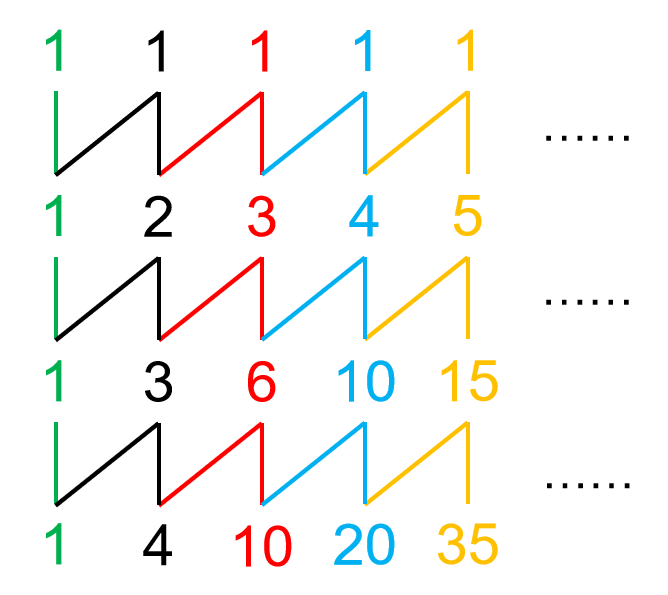
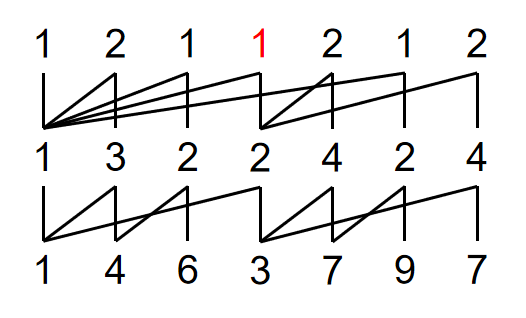
还有一个比较复杂的例子:\(0-Y(1,4,6,4)\)。
同样画出山脉图:
好部是 \(1\),坏部是 \(2,1,1\)。无限重复代回,得到:
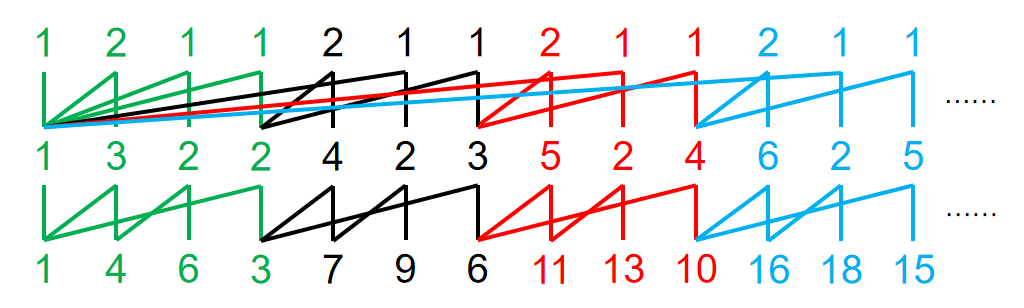
还有一个特殊规则的例子:\(0-Y(1,4,6,3,7,9,7)\)。
注意到中间一行第六项 \(2\) 的坏根是中左 \(1\),在第四列之前,所以对应的靠左边不变。那么,展开就是:
强度分析参考 BMS,接下来要讲的是 0-Y 和 BMS 的转换,然后就可以 BMS 方式扽了。
这一章山脉图的规则有点变化:再画一层,直到上层所有数全为 \(1\)。
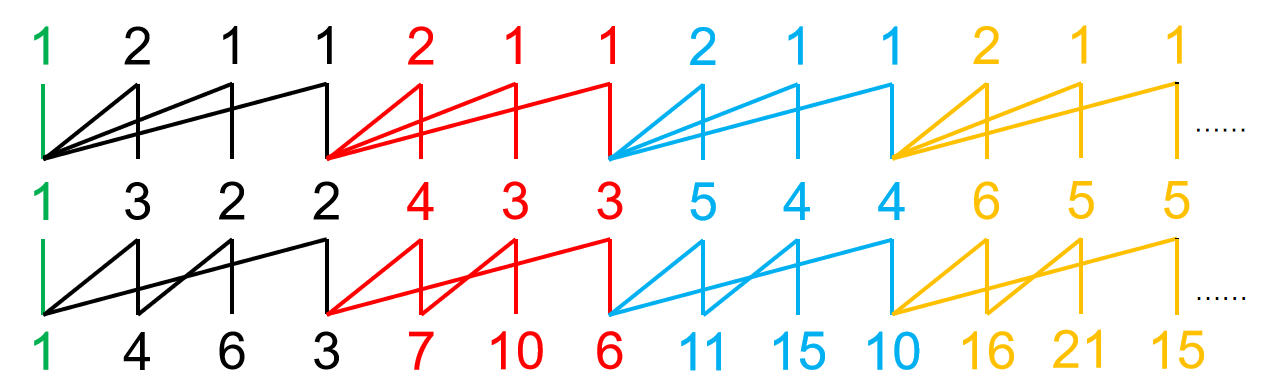
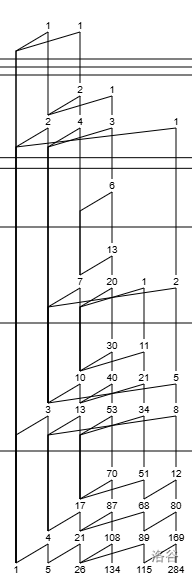
举个例子,\(0-Y(1,4,7,10,7,9,4,7,9,13,17,21,17,19,5)\)。
我为什么举这个例子?当然是因为 Suzuka 梅天狸 举得这个。
多一层的山脉图:
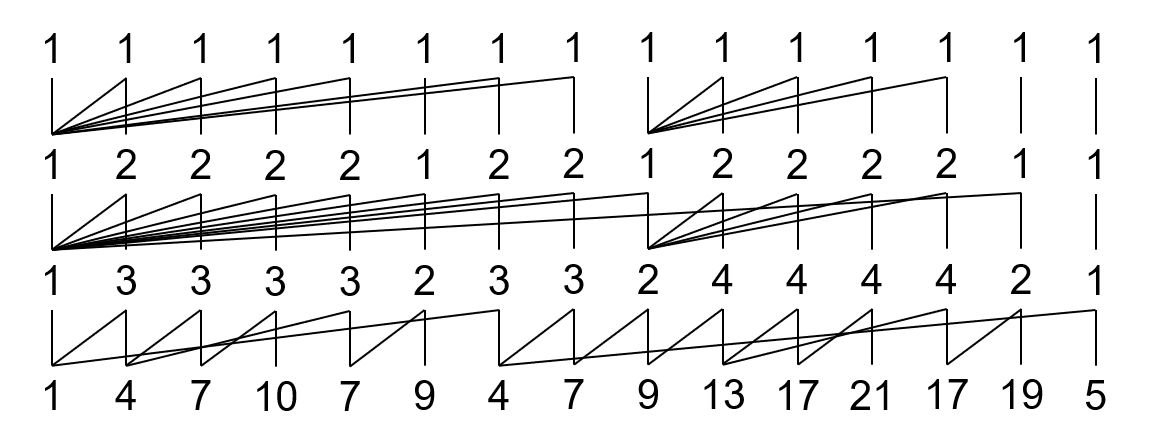
第一行的存在是帮助我们确定父项的,不用管他。
对于其他元素:
- 所有 \(1\) 的阶是 \(0\);
- 父项的阶为自己的阶减去 \(1\)。
比如说上面那个玩意就会转化为:
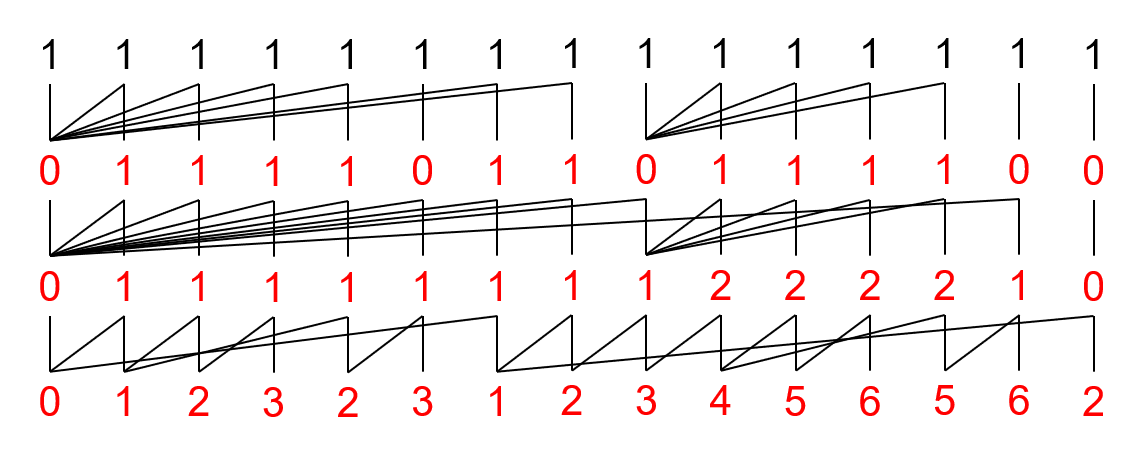
然后把每一行倒过来就是转化出来的 BMS:\((0)(1,1,1)(2,1,1)(3,1,1)(2,1,1)(3,1)(1,1,1)(2,1,1)(3,1)(4,2,1)(5,2,1)(6,2,1)(5,2,1)(6,1)(2)\)。
于是,第九章结束了。
文章还没有破 4w 字/1k 行,那么这一重任就交给了一个强有力的模式——急。
急。乐。绷。典。
对了,说到典:昂?
如果你还是没懂:安民!
其实这个名字起的很无厘头,从他的效果来看,应该是“尽可能地扩大坏部的范围,减缓展开的速度”,所以其实不用急模式的记号更急一点。我也不知道为什么减缓速度反而要叫急。
至此 1k 行。
这一章的标题中,有 HSS 和 SSS,这两个东西是 PrSS 运用急模式得到的结果。
其实如果我命名的话,PrSS 命名成 1SS,HSS 命名成 2SS,SSS 命名成ωSS,这是从急的范围来考虑的。
把这两个东西扩展到二维就是本文主角——BHM&BSM。
BHM 的规则如下:
- 行列指标从 \(1\) 开始,在 \(1\) 之前增加第 \(0\) 列;
- 第一行元素的父项为这个数前第一个小于这个数的数,特别地,如果这样的父项不存在,则将其父项取为该行第 \(0\) 列的元素;
- 一个元素的祖先项是父项的传递闭包;
- 其余行元素的父项为从该元素起,在该元素左边,小于该元素,且其正上方的项是该元素正上方的项的祖先项的第一个项,特别地,如果这样的父项不存在,则将其父项取为该行第 \(0\) 列的元素;
- 子项为父项的逆运算;
- 矩阵的待定坏根为最后一个非零项的父项的父项的子项,特别地,如果末列最后一个非零项不在第一行,则待定坏根正上方的元素应当是末列最后一个非零项正上方元素的祖先项;
- 待定坏根的预展开式为对于该待定坏根按 BMS 的规则展开一步,再在后面附加上(末列 + 阶差向量)这样一列所得到的序列;
- 在字典序下,预展开式小于基准式的坏根称为小根。特别地,如果这样的小根不存在,则将其父项取为该行第 \(0\) 列的小根,真正的坏根为在所有小根右侧的第一个待定坏根;
- 找到这些后,按 BMS 规则展开。
这便是 BHM 的规则,和 BMS 不同的地方已经加粗。
大数界还没有对 BHM 的极限的分析,但是有可能(但不大)和 BMS 极限相同。
单行 BHM HSS 的极限是 \(\varphi(1,0,0)\)。超过了 lPrSS。
BSM 和 BHM 的规则只有几项不同,但是强度却天壤之别(其实也不一定,现在有猜测说 BMS、BHM、BSM 极限其实一致,不过 SSS 的强度确实和 PrSS 和 HSS 天壤之别)。
改变:
第六条规则改为:待定坏根为末列最后一个非零项的除父项之外的祖先项的子项。特别地,如果末列最后一个非零项不在第一行,则待定坏根正上方的元素应当是末列最后一个非零项正上方元素的祖先项。
阶差向量规则的改变:对于某待定坏根来说,它所对应的阶差向量为末列和坏根的差值。特别地,对于末列最后一个非零项的元素所在列来说,该列的阶差向量取值要额外减去一;而对于在该列之下的所有列来说,其阶差向量总取为零。
单行 BSM SSS 的极限是 \(\psi(\psi_I(0))\),超过了 hPrSS。
显然 BHM 和 BSM 超过了 0-Y。
BHM 和 BSM 的分析极为困难,接下来会给出几个已经有的分析。
BMS-BHM 分离点是 \(\omega2\)。
这是 PrSS 的极限和 BHM-BSM 分离点。
4w 字。
HSS 极限。
双行 BMS 极限:\(BMS(0)(1,1,1)=BHM(0)(1,1)(1)(2)=SSS(1,2,3,3,4)=\psi(\Omega_\omega)\)。
SSS 极限:\(BMS(0)(1,1,1)(2,1,1)(3,1)(2)=BHM(0)(1,1)(1)(2)(1,1)=BSM(0,0)(1,1)=\psi(\psi_I(0))\)。
往后的分析寸步难行,目前的成果是 \(BSM(0)(1,1)(1)(1)(2)(3,1)(3)(3)=\psi(\psi_I(\omega))\)。
还有 \(BHM(0)(1,1)(2,1)(2)(2,1)(1,1)(2,1)(1)(2)(2)\le BMS(0)(1,1,1)(2,2,1)(3)\)。
那么 BSM 还是结束了吧。
上面的 BMS 扩展虽然规则看起来强大,但是实际强度却不尽如人意甚至有可能强度和 BMS 一样。
另外还有一个东西叫做 TBMS,他把 BMS 扩展到了 \(\Omega\) 维、甚至 \(\omega_1\)(第一个不可数序数) 维的结构。Bubby3 把它扩展到更加高的结构。
但是,接下来介绍的 1-Y 甚至只用了 \(\omega+1\) 维就薄纱各种 TBMS。
除了 Bubby3's TBMS Extended,没有任何 TBMS 能过 \(Y(1,3,4,3)\) 这个提升(注意,由于 1-Y 比 0-Y 出现要早,所以一般的 Y 都是指的 1-Y 而不是 0-Y)。
有以下分析:
\(Y(1,3)=\text{SHO},Y(1,3,4,2,5,8)=(0,1^{\omega^2}),Y(1,3,4,2,5,8,8)=(0,1^{\omega^3}),Y(1,3,4,2,5,8,9)=(0,1^{\omega^\omega}),Y(1,3,4,2,5,8,10)=(0,1^\Omega)=\Omega\text{SSO}\)。
神奇,上一秒还是不是很大的 \(\omega^\omega\),下一秒直接到递归序数极限了。
将最后一个数改成 \(11\) 更是直接薄纱所有 TBMS(除了 Bubby3 的,那个挺牛),作为对比,\(Y(1,3,4,2,5,8,10,4,9,14,17,10)=(0,1^{\omega_1})=\aleph\text{SSO}\)。
然后,用 Bubby3's TBMS 可以得到 \(Y(1,3,4,3)=(0)(1^{2,1^3})\)。
Bubby3's TBMS 的极限是 \(Y(1,3,7,14)\),仍然没有达到 \(Y\) 极限的一点点影子。
说了这么多……
你 TM 赶紧说 Y 序列是啥啊!
先讲一讲 Y 的山脉图怎么画吧。
先按 0-Y 规则做出山脉图,不过这里有一点不一样——如果一个元素是 \(1\),那么山脉图在它顶上的元素不是 \(1\) 而是“空”,然后如果按着 0-Y 规则找不到父项了就是没有父项,不用管它。
比如说 \(Y(1,2,4,5,7)\) 的山脉图就是:
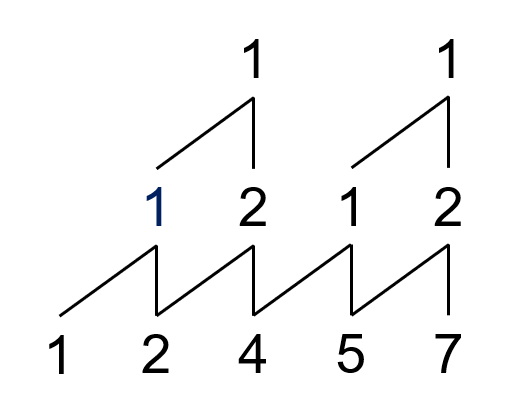
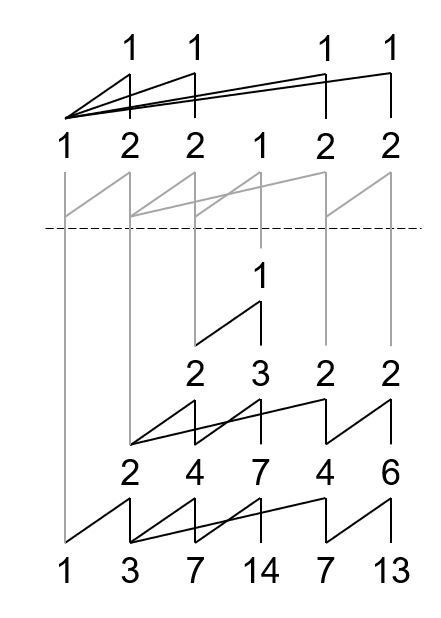
但是如果画完山脉图之后,存在一列顶点元素不是 \(1\) 该怎么办?
比如说,\(Y(1,3)\)?
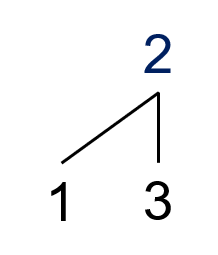
我们可以把所有顶点元素组成一个新序列,此时找父项要到提取前的序列去找。
比如说,\(Y(1,3,7,14,7,13)\)。
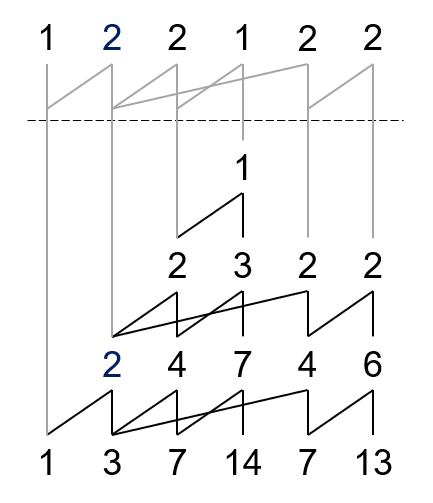
然后再根据规则做一下山脉图就好了。
当然,也有可能提取两次,比如说 \(Y(1,4,11,21)\)。
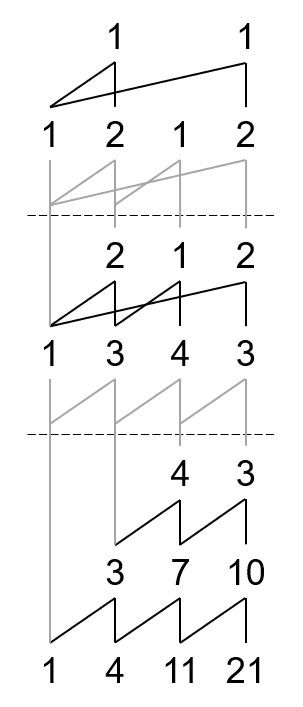
这便是 1-Y 山脉图的画法了。
然后就是 1-Y 的展开。
父项定义和 0-Y 有些许不同,是元素向下沿着左边走,然后再往正上方走,不能跨线,如果后一步无法实现就不实现,其他定义一样。
在 0-Y 中没有加粗部分,因为后一步总能实现。
最上层 0-Y 规则。
从次上层开始,事情变得不太一样。
我们还是先定义几个概念。
顶点元素:从根元素起,重复“先向右上走一步再向正下走 0~1 步”所能达到每一列的最高点。
轮廓边:从任意顶点元素起,重复“先向右上走一步再向正下走一步”直到走不了可能经过的所有边。
平移边:根列右侧不是轮廓边就是平移边。
参考边:从根元素起,重复“先向右上走一步再向正下走一步”直到走不了可能经过的所有边。
次上层,包括除最上层外的所有层的展开规则其实就三句话:提升轮廓边,平移平移边,填充参考边。
- 提升轮廓边:两条横线间的山脉图高度的定义为最右列顶点元素和根元素的高度之差。每次将轮廓边除了平移宽度以外还要提升高度,每次提升的高度就是山脉图的高度;
- 平移平移边:对于所有平移边,直接平移。
- 填充参考边:注意到轮廓边和平移边之间会产生一些空隙,这些空隙用参考边进行所需填充。
其实还是可以理解。
举个经典例子:
\(Y\) 的巨大提升:\(Y(1,3,4,3)\)。
先画出山脉图,然后展开上层,标注下层:
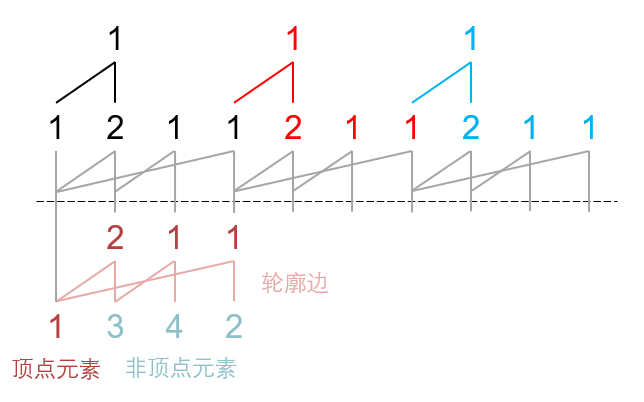
提升轮廓边,平移平移边(这里没有平移边):
右下出现了一定的空隙,用参考边(这个例子中和轮廓边一样)填充:
大功告成,\(Y(1,3,4,3)=Y(1,3,4,2,5,9,4,9,18,8,\dots)\)。
更多的例子没有必要,我不在狸那里贺更多的图了,相信大家都已经理解了。
Y 的扽西是困难的,因为它和 BMS 差了很多。
接下来我们将会使用序数行 BMS 来扽西,目标是 \(Y(1,3,4,2,5,8,10)\)。
单行 BMS(PrSS)就是 Y,跳过。重要节点标绿,极其重要节点标红。
至此达到了普通 BMS 的极限,往后我就仅仅给几个节点,不作详尽的分析了(4.5k 字)。
至此,BMS 的分析达到了极限,往后已经几乎没有记号可以分析它了。
我们令 \(SYO=Y(1,\omega)\),但是我们不知道它有什么性质。
哦对了值得一提的是:
接下来要说的 ω-Y 极限是 MHO,但是还没有 LHO 和 MYO。所以如果你的符号定义强度极高并且是 worm 型,那么大数界一般说这个符号拥有“LHO 定义权”或“MYO 定义权”。
1-Y 完。
接下来,是 ω-Y 的主场!
我们考虑把提取规则去掉,来获取更为厉害的表现。
和 1-Y 一样,先来说几个 ω-Y 的式子来表示它的强大:
这还仅仅是体现 \(\omega-Y\) 强大的一小部分规则,一般的我们有 \(\omega-Y(1,n+3)=C\ n-Y(1,\omega)\)。
至于 \(C\ Y\) 和 \(D\ Y\) 的区别,暂且不表。只需要知道,我们上一篇讲的 \(Y\) 既是 \(C\ 1-Y\) 也是 \(D\ 1-Y\)(然而从结构上来看是 \(C\ 1-Y\)),\(D\) 比 \(C\) 发明要晚,结构几乎一致,并且强度还要弱。
那要它有什么用?
当然有用。适当的弱化是为了向无限推广,\(C\) 模式是不能走向无限的,也就是说,\(\omega-Y\) 只有 \(D\ \omega-Y\) 一种。
\(\omega-Y\) 内层还细分为四种模式:weak magma、actual magma、medium magma、strong magma。
actual magma 是 \(\omega-Y\) 刚被发明出来的时候的规则,难于理解。
事实上这些的区别在于 magma 边。定义 magma 边的时候有 weak magma 和 strong magma。展开 magma 边的时候有 weak recursion 和 strong recursion。
weak magma 是 weak magma+weak recursion。
actual magma 是 weak magma+(有时候 weak recursion 有时候 strong recursion),这也是 actual 最难于理解的原因。
medium magma 是 weak magma+strong recursion。
strong magma 是 stong magma+strong recursion。
靠后的比靠前的强大,但是极限都是一样的,清一色 MHO。所以基本上大家所说的 \(\omega-Y\) 都是理解最容易的 weak magma,本文接下来所讲的就是这些。
说了这么多……
你 TM 赶紧说 ω-Y 序列是啥啊!
先来说一下 ω-Y 山脉图画法吧。
大部分定义与 1-Y 相同。
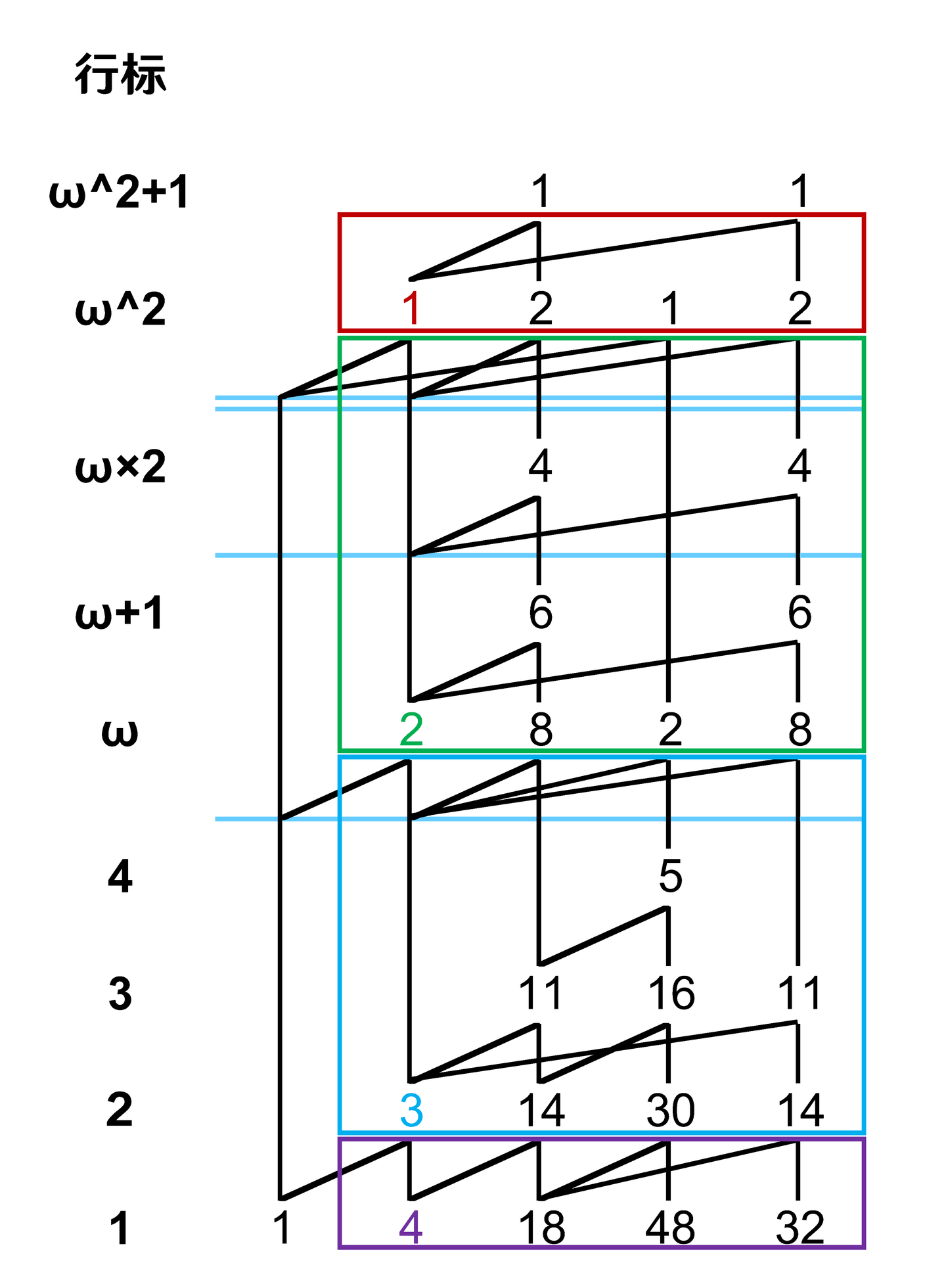
在 ω-Y 中,有一个叫做行标的东西。
其实 1-Y 也有这个东西,不过不很重要。
简单来说,行标 \(\alpha\) 和 \(\alpha+\omega^k\) 用 \(k\) 条横线隔开。
也就是说,一条横线分割 \(\omega\) 系数不同的区域,两条横线分割 \(\omega^2\) 系数不同的区域……
省流:\(\sum\limits_{i=0}^{+\infty}\alpha_i\omega^i\) 的行标下边有 \(\alpha_i\) 条 \(i\) 重线(你猜为什么是 \(+\infty\) 不是 \(\omega\))。
如果一个元素的行标是 \(\alpha\),父项行标是 \(\beta\),且 \(\beta+\omega^k\le\alpha<\alpha+\omega^{k+1}\),那么阶差的行标就是 \(\beta+\omega^{k+1}\)。
然后开始画就行了。
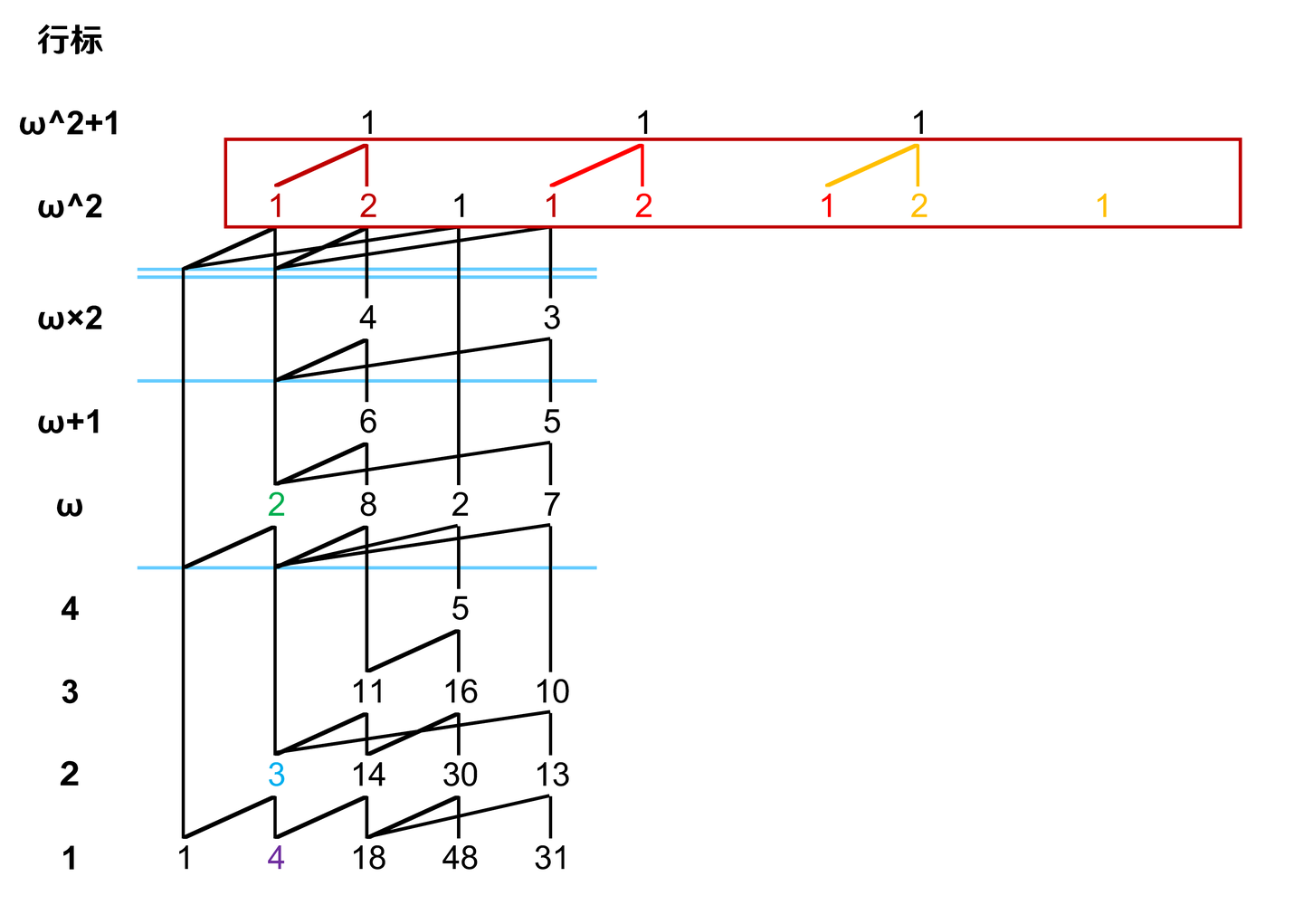
举个例子:\(\omega-Y(1,5,26,134,115,284)\)。
在看下面之前,大家可以先自己画一画。
完整山脉图是这样的。
Suzuka梅天狸说一列一列的画比一行一行的画更方便,我试了,深以为不然,因为经常会把本应在线下面的元素画到线的上面。
接下来该讲展开了。
我们定义:
- 根元素、根列同 1-Y;
- 根列元素:位于根列且行标小于等于根元素的元素;
- 作用区域:一个根列元素的作用区域为行标范围为它自己(含)到下一个根列元素(不含)的所有元素;
- eruption 边(轮廓边):从一个根列元素开始,不超过作用范围的向右上走一步,不超过作用范围的向左下走若干步,可能经过的所有边就是 eruption 边;
- wildfire 边(非轮廓边):作用区域内不是 eruption 边就是 wildfire 边;
- magma 边(填充边):从一个根列元素开始,不超过作用范围的向右上走一步,不超过作用范围的向左下走一步,可能经过的所有边就是 magma 边。
注意这里的非轮廓边和 1-Y 中的平移边并不一致。
规则:
- 从上到下以作用区域为单位执行以下操作。
- 把末列减一。
- 提升 eruption 边:把 eruption 边向右平移的同时向上提升,提升的高度是根元素与末列最上方元素的行标之差。即:设 \(\alpha\) 为根元素行标,\(\beta\) 为末列上方元素行标,\(\gamma\) 为满足 \(\alpha+\gamma=\beta\) 的序数,那么原先行标为 \(\delta\) 的将会平移到 \(\gamma+\delta\)。注意不是 \(\delta+\gamma\)。
- 填充 magma 边:将上一步产生的空隙用 magma 边填补。当然如果没有空隙就不填补。
- 平移 wildfire 边:左边的边不动,右边的边向右上平移。如果右边的边正下元素没有被 eruption 边指到,那么只向右平移,否则行为和 eruption 边一致。
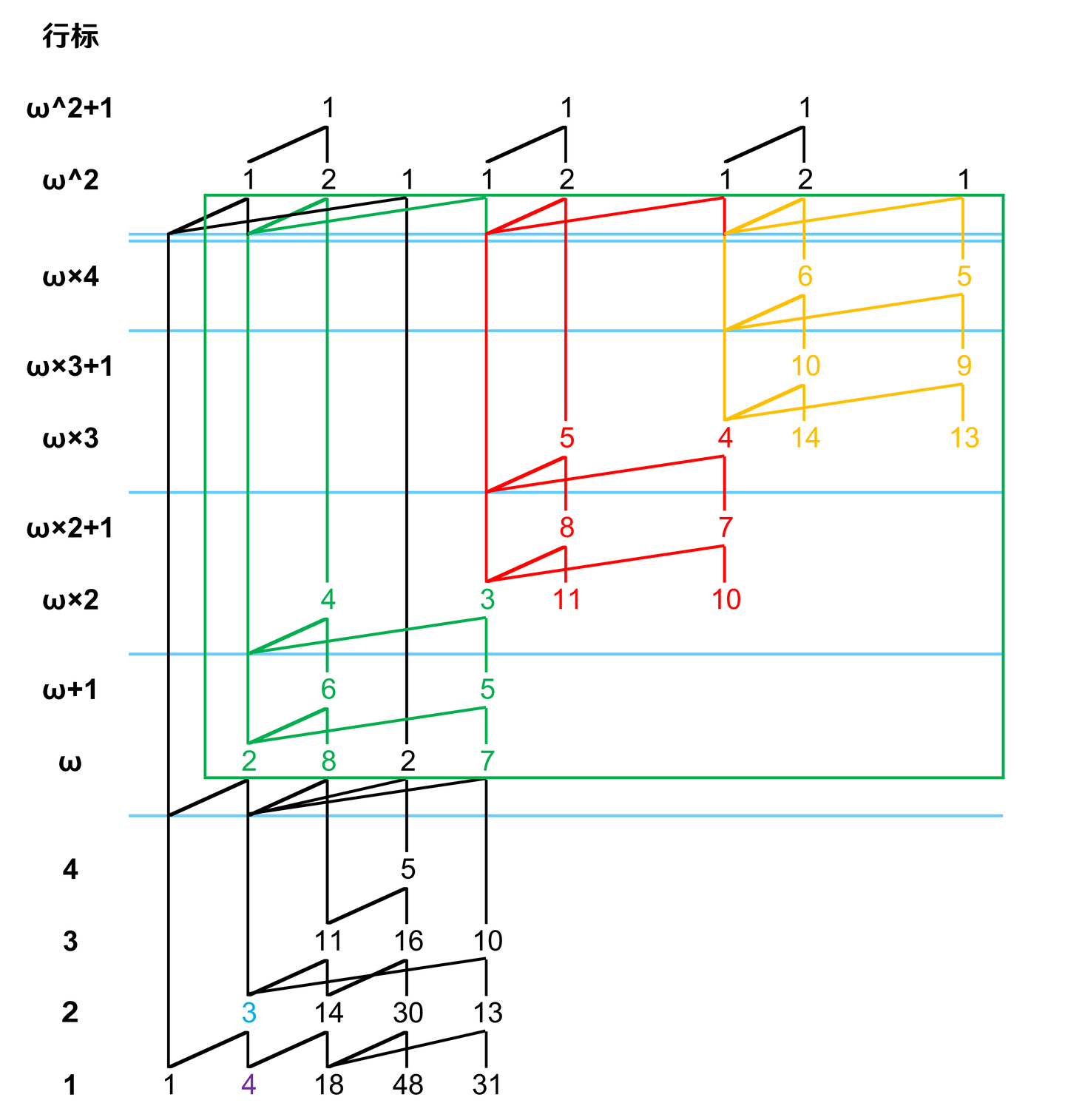
比如说 \(\omega-Y(1,4,8,18,48,32)\)。
第一步,标出根元素和作用区域:
第二步,展开上层,因为只有一行,所以只用向右平移:
第三步,标记第二层 eruption 边并复制:
第四步,标记第二层 magma 边并填充:
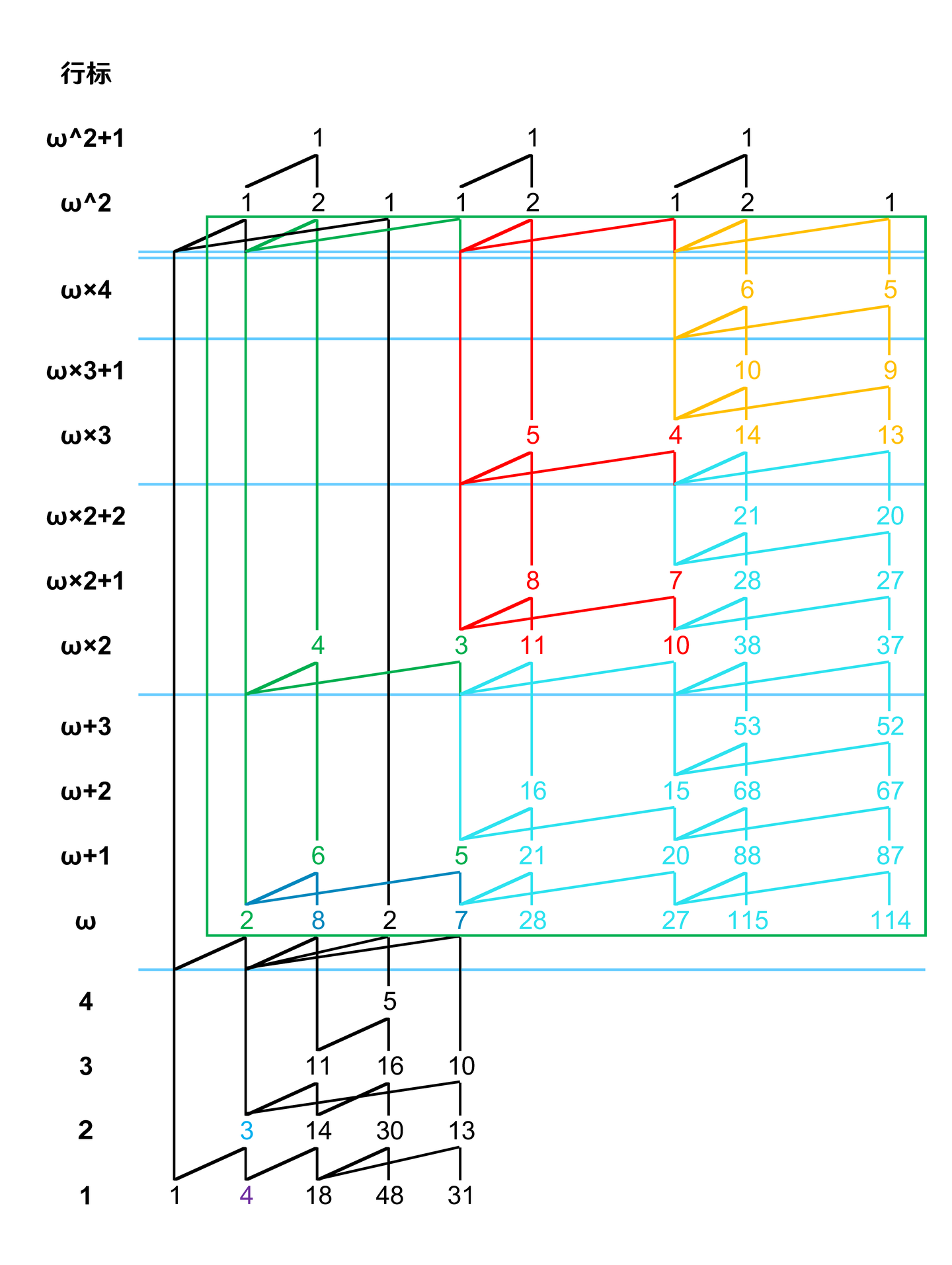
第五步,平移 wildfire 边:
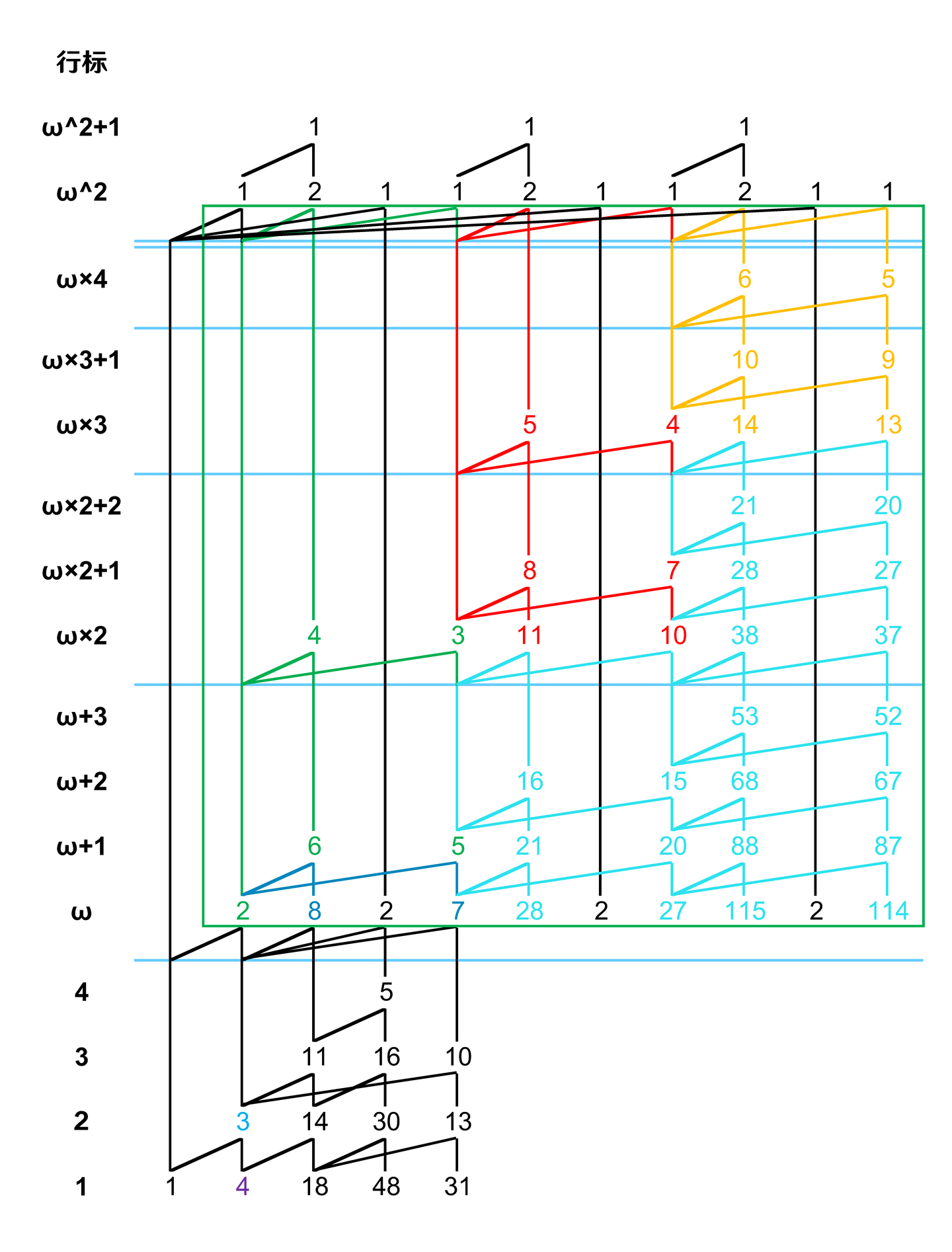
第六步,按着同样的操作复制最后两层:
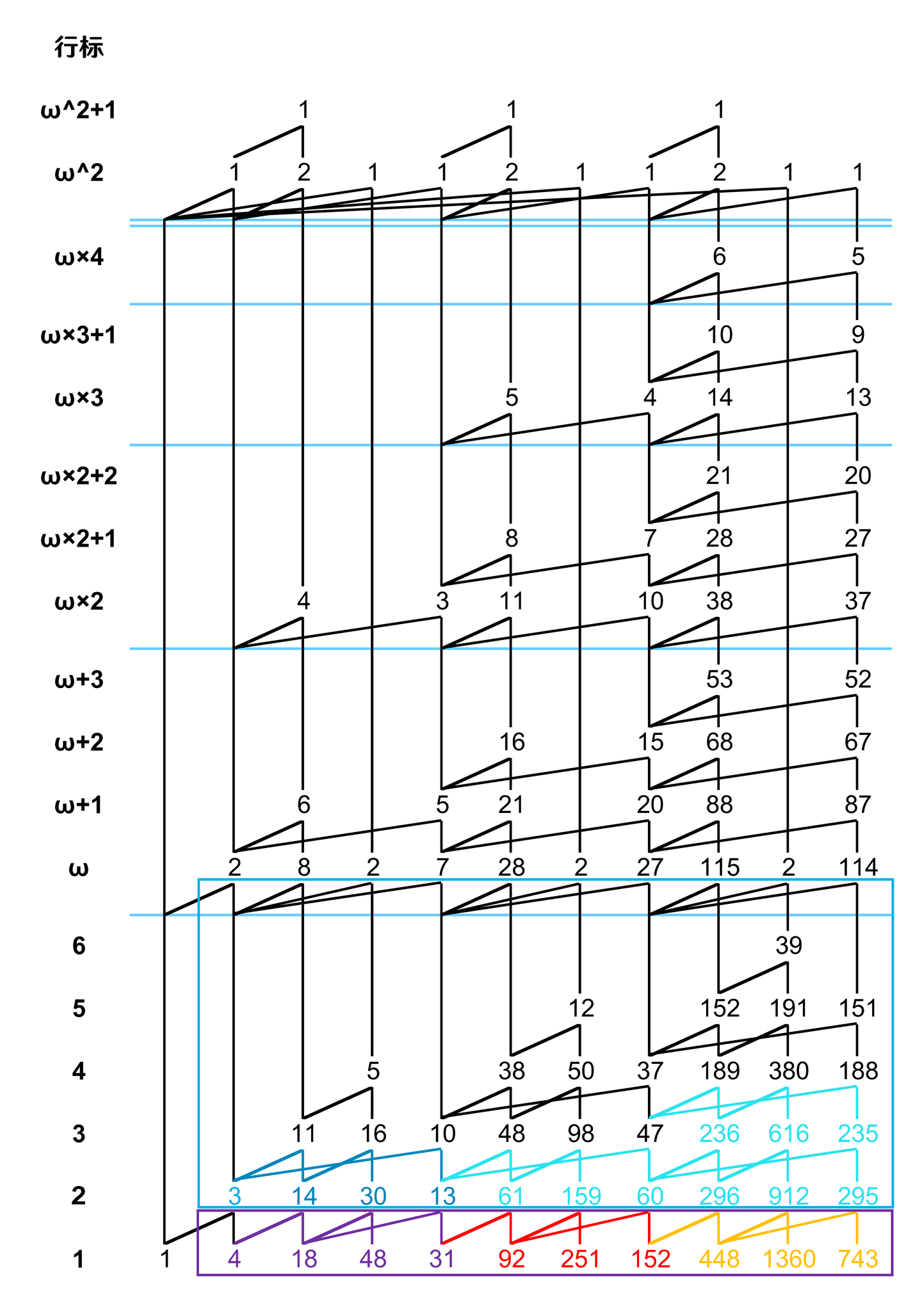
大功告成
作业:展开 \(\omega-Y(1,5,26,134,115,284)\)。
答案山脉图:

答案:\(\omega-Y(1,5,26,134,115,283,572,1163,2974,10830,49037,233124,1085084,4874560,\dots)\)。
对于 ω-Y,我们仍然没有很多的手段进行分析,作为对比,没有什么可以对比的了。
以后要讲的记号大多都是和 ω-Y 进行对比分析,比如 MMS、ωMN、fffz、X-Y。也就是说,ω-Y 是过不去的一关。但是由于上述记号和 ω-Y 均有错层效应导致分析
但是之前讲的记号远远不够描述 ω-Y 有多强,也许有一天会有一个强度在 1-Y 和 ω-Y 之间的简单记号来辅助了解。目前我找到的符合这样一个条件的记号是 DBMS,但是由于资源限制,我找不到其规则。
还是写几条吧?
\(\omega-Y(1,n+3)\) 的展开式前 \(k\) 位是 \(C\ n-Y(1,k+1)\)。
然后放几个我个人的想法。
注意到所有 worm 型记号大小都是字典序,只不过有一些不合法而已,也就是说,如果所有都合法呢?
很神奇的现象出现了!这样能表示的序数数量最多 \(\omega^\omega\)!
究其根本,还是因为本质上 \(\omega\) 和任何可数序数都是可以一一对应的,包括 \(\varepsilon_0,\Gamma_0,\varphi(1@(1,0)),\psi(\Omega_\omega),TSSO,QSSO,SHO,\Omega SSO,SYO,MHO\),甚至 \(\Omega,\omega_1^{CK}\) 等等,第一个无法和 \(\omega\) 一一对应的序数是 \(\omega_1\),这也是第一个不可数序数。
所以,事实上上面说的是,worm 极限(也许是 LHO)和 \(\omega^\omega\) 一一对应,明显说了等于没说。并且,这个记号是明显不良记号,也就是说如果有一天真的存在了这样的记号,必须要良序。由良序定理这可以一试,但是我怀疑如果真的存在这样的记号,极限也不过是 \(\omega^\omega\)。
但是为什么即使是最基本的 worm 型序列——PrSS(其实最基本的是 -4-Y,不过没意义),也超过了 \(\omega^\omega\) 呢?
好问题,我不知道。
你问我为什么说这么多,当然是不想把 5w 字重任给我还没有完全搞懂的 ωMN。所以现在就堂堂 5w 字了。
从这里开始,我们正式进入的大数前沿。
Mountain Notation 是由 Hypcos 在 2024 年发明的序数记号,它的名字的命名格式为 {限定词}[分隔符种类数(可能且大概率为序数)]Mountain Notation{版本号},其中[]内为必填项,{}内为可选项。
1.5k 行了。
这里讲的是最初版本的 ωMN(即 ω Montain Notation)的简写。
这是把 ω-Y 的山脉图显式的表示出来并做一些简化的一个记号的一个记号,极限也和 ω-Y 相同——MHO。
我个人认为,ω-Y 之于 ωMN,就像 0-Y 之于 BMS。
ωMN 也是一个矩阵形式的表达式,他的形式一般是 \((列_1)(列_2)\dots(列_n)\),列的形式一般是 \(元素_1,元素_2,\dots,元素_m\),元素的形式一般是 \(分隔符\ 数值\)。每列还额外存在位于行标 \(0\) 处。
请注意即使是一列中第一个元素,也有分隔符。
数值表示它向下伸出的左腿要到第几列,分隔符表示它和下一格的行标差(一定是 \(\omega^x\) 形式),在 ωMN 中,分隔符是 \(x\) 重逗号。
行标为一个 \(\omega\) 进制数列,记作 \((a_k,a_{k-1},\dots,a_0)\),行标加运算为行标和分隔符间的运算,\((a_k,a_{k-1},\dots,a_0)+p\ 重逗号=(a_k,a_{k-1},\dots,a_{p+1},a_p+1,0,0,\dots,0)\)。
父元被定义为一个元素先沿右腿向上一格,再沿左腿向左下一步,就到达这个元素的父元。
祖先是父元、父元的父元等的集合,不含自身。
后代定义为祖先的逆运算。
右上角为最右列最上端的元素。
从右上角沿左腿走一步达到根元素。
根元素所在列为根列。
根列元素为在根元素及其下方的所有在根列上的元素。
一个根列元素的顶元素为比它靠上的第一个根列元素,如果这个根列元素是根元素,那么它所对应的顶元素是右上角元素。
一个根列元素的参考元素为在最右列的行标大于等于这个根列元素且小于这个根列元素对应的顶元素的元素。
一个根列元素的 magma 元素为它的同行后代。
复制区域为列标严格大于根列且小于等于最右列的元素。
复制宽度为最右列的列标减去根列列标。
这些都是可以轻松理解的,接下来的减一操作是第一个比较复杂的定义。
减一操作在 ω-Y 中就是单纯把末列减一,但是在 ωMN 中由于 ω-Y 的元素值并未保留,所以稍显麻烦。
流程如下:
- 设右上角的分隔符是 \(k\) 重逗号。右上角沿左腿向左下走一步,到达行标 \(x\);右上角沿右腿向下一格,到达行标 \(y\)。
- 如果 \(k=1\),则删掉右上角,然后跳过下一步。
- 如果 \(x+(k-1)\ 重逗号<y\),则删掉右上角,否则把右上角的分隔符从 \(k\) 重逗号改为 \(k-1\) 重逗号。
- 把根元素上方的元素(不含根元素)都复制到最右列上方。
然后介绍展开规则:
- 零规则:空矩阵为 \(0\),若可以通过这种形式得到答案则结束展开。
- 后继规则:如果最后一列为空,那么序数为去掉最后一列得到的序数加一,若可以通过这种形式得到答案则结束展开。
- 进行减一操作并枚举每个复制区域元素。
- 若待展开元素是 magma 元素跳第 \(8\) 步。(这步将会执行 \(\omega\) 次。)
- 从待展开元素沿右腿向上一格,到达的元素是待复制的源元素。它只能复制成一个目标元素,目标元素的分隔符与源元素相同,若源元素的值大于等于根列的列标,跳过下一步。
- 目标元素的值与源元素相等,跳过下一步。
- 若这是第 \(m\) 次执行第 \(4\) 步,则目标元素的值比源元素大 \(wm\),其中 \(w\) 为复制宽度,跳到第 \(11\) 步。
- 从待展开元素沿右腿向上一格,到达的元素是待复制的源元素。它可能复制成一个或更多个目标元素。找到待展开元素所在行的根列元素,然后找到这个根列元素对应的参考元素。每个参考元素将得出一个目标元素。若这是第 \(m\) 次执行第 \(4\) 步,则目标元素的值比源元素大 \(wm\),其中 \(w\) 为复制宽度。枚举每一个参考元素若其为最上端的参考元素,跳过下一步。
- 沿右腿向上一格,到达一个元素,目标元素分隔符和这个元素一致。跳过下一步。
- 目标元素的分隔符与源元素相同。
- 回到第 \(4\) 步。
虽然规则看似很抽象,但是如果你去看它研究它的话你会发现基本上和 ω-Y 一致(除了减一操作)。
哎哎哎这一章怎么才两千字,这么水的吗?
再讲讲 ωMN 的弱扩展 TωMN 吧。
BMS 的时候没怎么讲 TBMS,这里大家可以详细看看 Transfinite 到底是个啥。
关于 TBMS 有几个规则需要修改。
分隔符是非空矩阵,分隔符中的分隔符也是非空矩阵……
元素的大小比较:两元素相比,先比其值,如果值不等,则得出结果;如果值相等,再比分隔符,分隔符的比较结果就是元素的比较结果。
列的大小比较:以元素为单位,按字典序比较。
矩阵的大小比较(也就是分隔符的大小比较):以列为单位,按字典序比较。
减一操作流程如下:
- 设右上角的分隔符是 \(M_1M_2\dots M_m()\)。右上角沿左腿向左下走一步,到达行标 \(x\);右上角沿右腿向下一格,到达行标 \(y\)。
- 如果 \(m=0\),则删掉右上角,然后跳过下一步。
- 如果 \(x+M_1M_2\dots M_m<y\),则删掉右上角,否则把右上角的分隔符从 \(M_1M_2\dots M_m()\) 改为 \(M_1M_2\dots M_m\)。
- 把根元素上方的元素(不含根元素)都复制到最右列上方。
其他操作不变。
关于 ωMN 的强度,我们已经有了 \(\omega MN()((k重逗号)1)=\omega-Y(1,k+1)\),具体分析留给读者作为练习,我们接下来将会从 \(\omega-Y(1,3)=\omega MN()(,,1)\) 开始,扽到 \(\omega-Y(1,4)=\omega MN()(,,,1)\)。
以下左为 \(\omega-Y\) 右为 \(\omega MN\)。
ωMN 的极限表达式是 \(()(,,,,,\dots1)\) 即 \(MHO\),TωMN 的极限表达式是 \(()(()(()((\dots)1)1)1)\),即 \(EMHO\)。
ωMN 完。
X-Y 是 Gomen 在 2023 年发表的一个记号,作者宣称这个东西其实是 ε₀-Y,并认为以前提出的这个记号的弱化版本为 ω²-Y(后来又宣称是 ω^ω-Y)。即使这个记号的强度确实比 CatIsFluffy's Ω-Y 以及 Yto's Y-Y(只是一个很大的弱化,不是真正的 Ω-Y 和 Y-Y)要强很多,但是大部分人还是认为这个记号的强度不能到真正的 ε₀-Y,所以这个记号一般被叫做 X-Y。现在由于传递的研究,ε₀-Y 应该有任意的 \(\omega\uparrow\uparrow n\) 行传递,所以这个记号事实上确实略微欠了一点。
X-Y 的展开极为复杂,分析极为困难,这或许预示着 Y 这条路已经走到了尽头。
现在没有任何一篇详尽的 X-Y 分析,Gomen 本人也没有提供目前最新版 X-Y 和 ω-Y 的对比,所以这个部分没有扽西。
需要声明的是,该文主要引用于 Gomen 本人的博客。
X-Y 的山脉图画法和 ω-Y 一样,不过行标形式有所不同。不过也没什么不一样,就是原先直接用序数,现在改成了 \(\omega\) 进制。例如 \(\omega^5+\omega^4+4\omega^3+5\omega^2+\omega+4\) 就会改造成 \([1,1,4,5,1,4]\)。
其中右腿被命名成头元素,新元素被命名成足元素,左腿称号不变。
行标维度的定义是行标 \(\omega\) 的最高次项的次数。
行标等级的定义是行标 \(\omega\) 的最高次项的系数。
行标等级差是同一维度的行标等级之差。
行偏差为行标去掉首项。
芽元素为山脉图最右列行标第 2 大的元素。
若元素与其父元素在同一行,则父元素是该元素的参照元素,否则如果该元素不在首行,则该元素的左腿是该元素的参照元素,首行值为 1 的元素没有参照元素。
从某元素开始,顺着它的参照元素、参照元素的参照元素、参照元素的参照元素的参照元素……溯源而上,直到某个没有参照元素的元素为止,这条链路叫做该元素的参照链。
芽元素的参照链叫做根链。
非首行值为 1 的元素,它的参照链中离它最近的值为 1 的元素,是该元素的准父元素。
提取根链中各元素的维度值组成一个数列,并将该数列末项(芽元素维度值)的值 +1,该数列即原数列的主维度数列。
如果芽元素与其父元素在同一维度,则芽元素的父元素是根元素;否则主维度数列的根列对应的根链元素是根元素;根元素所在的列叫做根列,位于根列的元素叫作根列元素。
这里主维度的展开方式决定了 X-Y 数列的细分。
如果用 PrSS 规则就是 Gomen's ω^ω-Y。
如果用 x varience Y 规则就是 Gomen's ω^x-Y。
如果用 0-Y 规则就叫 0-X。
1-Y 规则就叫 1-X。
ω-Y 规则就叫 ω-X。
0-X 规则就叫 0-X-X。
1-X 规则就叫 1-X-X。
0-X-X 规则就叫 0-X-X-X。
递归下去,X-Y 规则就叫 X-Y。
真正的 X-Y 的终止看上去不那么显然,但至少我们还没有发现它不终止。
然后可以发现 X-Y 规则计算特别复杂,我目前没有想到低复杂度做法,所以展开器特别慢,1 5 展开三组都会爆炸。
说一下这个展开器的用法:
上面的框是你要展开的序列。
第二行左边是你要展开的组数,右边代表展开规则。
如果是一个自然数 \(n\) 的话就是 n-Y。
如果两个数的话第一个数一定是 \(0\),若第二个数是 \(n\) 的话就是 Gomen's ω^n-Y,\(0,0\) 代表 ω^ω-Y。
如果是三个数的话前两个数一定是 \(1,0\),\(1,0,1\) 是 X-Y,\(1,0,2\) 是 1-X。
不符合以上规则视作啥我也不知道。
好了回到 X-Y 规则。
山脉图根列右边(不含根列)的区域叫做坏区。
根列之前的元素编号均为 0,根列元素从上到下(上表示行标更小,下表示行标更大,下同)依次编号为 1、2、3、4 等。坏区元素编号等于其参考元素编号。
好了定义说完了,接下来是展开流程。
去掉山脉图最右列行标最大的元素,最右列其它元素值减 1,如果根元素值大于 1(此时山脉图最右列最大行元素是减 1 后的芽元素,其值等于根元素),芽元素要以根元素的父元素为父元素继续作差,直到山脉图最右列最大行元素值为 1 时为止。
芽元素与根元素的列标之差就是坏区长度,用 L 表示。
元素每一轮复制要从左到右依次复制坏区的每一列,复制某一列元素时要从上往下依次复制该列的每一个元素,当该列元素都复制到目标位置之后,从下往上(最下方元素的值为 1)计算复制列中每一个元素的值。
复制元素的编号等于被复制元素的编号,第 n 轮复制,复制元素的列标等于被复制元素列标加上 L*n(下文出现的 n 同样表示第 n 轮复制)。
如果被复制元素的父元素(若被复制元素不在首行且值为 1,则认为该元素的准父元素为父元素)在根列之前,复制元素以被复制元素的父元素为父元素;如果被复制元素的父元素在根列或根列之后,复制元素与父元素的列差,应等于被复制元素与父元素的列差,复制元素的父元素所在列中行标小于等于复制元素的、行标最大的元素就是复制元素的父元素。
编号大于 0 的元素在第 n 轮复制时,根列复制出来的列中编号与被复制元素相同的行标最大的元素是该元素的最大复制行参照元素。
元素在某一轮复制中可以复制到的最大行叫作该元素的最大复制行。它的规则如下:
- 如果被复制元素的编号为 0,则该元素的最大复制行与被复制元素的行相同;
- 如果被复制元素编号大于 0 且不等于根元素编号,或被复制元素编号等于根元素编号且被复制元素与根元素的维度及维度等级相同,则被复制元素的最大复制行与最大复制行参照元素的行差,应等于被复制元素与根列同编号元素的行差;
- 如果被复制元素编号等于根元素编号,且被复制元素维度等于根元素维度但被复制元素维度等级大于根元素维度等级,则被复制元素的最大复制行与最大复制行参照元素的维度等级差应等于被复制元素与根元素的维度等级差,且被复制元素的最大复制行的行偏差与被复制元素的行偏差相等;
- 如果被复制元素编号等于根元素编号,且被复制元素维度大于根元素维度,则被复制元素的最大复制行的维度等于被复制元素的维度数列展开式中对应项的值,且被复制元素的最大复制行的维度等级和行偏差都与被复制元素相等。
编号等于根元素编号且维度大于根元素维度的元素都对应一个它自己的特征维度数列,一般简称为元素的维度数列;将元素参照链中维度大于根元素维度的项的维度提取出来,插入到主维度数列中根元素之后(插入项不影响原主维度数列各项的父子关系),新插入的项的父元素仍是前方最近的值比它小的元素,该数列就是该元素的特征维度数列,该元素对应特征维度数列中它的维度值那一项。
这里特征维度展开的方式和上方主维度序列的展开方式一样。
第 0 行元素的最小复制行是第 0 行,非 0 行元素的最小复制行由它的头元素在同一轮复制中的最大复制行与其父元素所在行作差生成(即如果元素 A 是元素 B 的足元素,则元素 A 的最小复制行元素是元素 B 的最大复制行元素的足元素)。
对元素的复制是从复制到最小复制行开始,即某轮对元素进行第 1 次复制时,必定将该元素复制到该轮最小复制行。当被复制元素复制出一个新元素之后,执行下述流程:
- 判断新元素的足元素所在行与被复制元素最大复制行的大小;
- 如果新元素的足元素所在行小于等于被复制元素的大复制行,将被复制元素复制到足元素所在行,回到步骤 1,否则复制结束。
前面提到 X-Y 没有相关分析,其实我可以找到几个,但是这是老版 X-Y,但是和新版 X-Y 在这个时候应该没有分叉,姑且一写(这里带上我们之前提到过的 Gomen's ω^ω-Y)。
X-Y 和 ω-Y 的分界点在 \(\omega-Y(1,4)=X-Y(1,3,11)\) 处。
其强度可见一般。
此外 Gomen 还设计了强度较弱的 Gomen's ω+n-Y,可以说,Gomen 是对 Y 序列系统在 ω-Y 之后最大贡献的人之一。
Mutant Matrix System 是一种 Aarex 在 2023 年提出(MM1),Gomen(MM2)、Hypcos(MM3)、ProjectCF(MM4)试图改善的一个序数记号,现在普遍使用的是由 Hypcos 在 2024 年提出的 MM3(MM1 和 MM2 被发现不良了,MM4 强度弱于 MM3),接下来,我将介绍一下它的规则。
感谢 QQ 用户 SuzukaFox(也即先前提到的知乎用户 Suzuka梅天狸)对本篇的帮助。
请注意:在 MMS 中,没有 MMS 的 PSSO(BO)/TSSO 这一说,因为两项序列可能展开后就变成了三项、四项、五项,但是确实有 MPSO/MTSO/MQSO,分别代表 \(MM()(1,1,1)/MM()(1,1,1,1)/MM()(1,1,1,1,1)\)。
以下表述中,左方元素比右方元素列标小,上方元素比下方元素行标小。
表观行标就是它是一列中第几个元素。
内在行标定义如下:
若表观行标为 \(1\) 则内在行标为 \(1\);
否则找到它上方最近不等于这个元素的元素,设它们的的表观行标差是 \(d\),则内在行标差就是 \(\omega^{d-1}\)。
定义待定父元如下:
若内在行标为 \(1\),则待定父元就是它向左一格;
否则找到它上方元素的父元所在列,待定父元是这列中内在行标小于此元素且值大于等于此元素值减一的最靠下的元素。
父元是待定父元、待定父元的待定父元……中第一个等于此元素值减一的元素。
祖先元是自身、父元、父元的父元……的集合。
后代元素是祖先元素的逆运算。
右下角元素为最右列最靠下的非零元素。
右下值为右下角元素的值。
待定根元素定义如下:
从右下角元素开始进行如下操作直到元素行标为 0:
- 找到最近的值等于右下值减一的目前元素祖先项,并令其为待定根元素。
- 将目前元素向上移动一格。
请注意由于祖先元素包含自身,所以很有可能一列有多个待定根元素,这点很重要。
定义提取序列为如下序列:将每一列的待定根元素数目列出来变成一个序列,将此序列所有 0 去掉,再在最左边加一个 1,就是提取序列。
根元素为提取序列按照 PrSS 规则的根元素向右一格所对应的列中最靠上的待定根元素。如果提取序列最后一位是 1,那么根元素就是最靠右的那个待定根元素。
减一操作是把根元素及其下方的所有元素复制到最右列,列标与内在行标平移,使得根元素恰好复制到右下角元素的位置,这是展开的第一步。
根列元素定义为根元素上方(含)的所有元素。
一个根列元素的 magma 元素定义为从这个根列元素出发,所有内在行标与其相等的后代元素。
magma 元素定义为所有根列元素的 magma 元素的集合。
一个根列元素的参考元素是最右列中所有内在行标大于等于这个根列元素并小于下一格根列元素的元素。
延伸操作是将减一之前的表达式中,根列右方(不含)的元素一列一列地复制出来。每一列从上到下复制。一个源元素复制时可能有值的提升、行标的提升。所有提升由本列最近一次经过的 magma 元素,以及它对应的根列元素对应的最下参考元素,二者决定。magma 元素复制时可能产生多个复制品。它对应的根列元素对应的参考元素可能有多个,每个产生一个复制品。
这就是 MM3 完整的规则。关于 MM3 有以下的分析(左为 MM3,右为 ω-Y):
其实在这中间出现了一点规则漏洞导致狸只扽到了这中间的某个值,不过我们考虑直接跳过之。
MM3 有一个叫做 \(3322\) 提升的东西,它指的是 MM3 在 \(MM()(1,1)(2,2,1,1)(3,3,2,2)\) 处的提升,这个提升也是我的现 QQ 名,在这里 MMS 的强度大幅增强,大概率使得 MPSO>MHO,但是现在这方面的分析不足。
ω2MN 是 ωMN 的一个扩展,也由 Hypcos 提出。目前有两种口味,一种是 Defective ω*2 Mountain Notation,还有一种是 Astral ω*2 Mountain Notation。
至于哪个强,我倾向于后者,但是:
MM()(1,1)(2,2,1,1)(3,3,2,2) 是我。
这篇文章主要讲的是前者。
TBMS 和 ω+1 row Y 都是 BMS 的扩展,前者有 \(\Omega\) 行结构但比不过后者的 \(\omega+1\) 行结构(事实上远不如,前者是 \(Y(1,3,4,2,5,8,10)\) 而后者是 \(Y(1,3,9)\)),这说明 Y 有一些 BMS 没有的提升。
事实上,在 TBMS 中,极限序数行只意味着最右列会变为极限序数下的大行标,而非最右列没有行标的增长。而在 Y 中,最右列出现极限序数行时,不论是最右列还是非最右列,都存在行标的增加。Y 的这种现象称作 eruption。
事实上,TωMN 之于 ωMN 正像是 TBMS 之于 BMS,是一种很弱的扩展。我们可以引入一些更强的扩展,这就是我们的 ω2MN。
6w 字纪念。
在 Dω2MN 中,最右列出现极限序数行时,不论是最右列还是非最右列,都存在分隔符的增加。分隔符的增加意味着同列相邻元素的距离变远了,“拉伸”因而得名。
Dω2MN 中,分隔符以 0~1 个分号(“;”)和若干个逗号(“,”)构成,分隔符的值是指 \(\omega a+b\),其中 \(a\) 是分号个数而 \(b\) 是逗号个数。
父元、祖先、右上角、后代、根元素、根列元素、参考元素、复制部分、复制宽度、magma 元素的定义和 ωMN 相同。
每一个根列元素的拉伸阈定义如下:
如果其下一个根列元素的分隔符不是 ;,那么没有拉伸阈。
如果这个根列元素的分隔符中有 ;(即为 ;、;,、;,, 等),那么拉伸阈就是 ,。
否则拉伸阈是这个根列元素分隔符末尾加上一个逗号后的分隔符。
每一个根列元素的拉伸量定义如下:
如果没有拉伸阈、参考元素只有一个、最上方参考元素的分隔符中含有 ; 或拉伸阈比最上方参考元素的分隔符还要大,拉伸量为 \(0\)。
否则拉伸量是最上方参考元素的分隔符和拉伸阈的值差加一。
然后那就可以定义减一操作了。
- 设右上角的分隔符值是 \(M\)。右上角沿左腿向左下走一步,到达的元素具有分隔符 \(A\)、行标 \(\alpha\);右上角沿右腿向下一格,到达的元素具有分隔符 \(B\)、行标 \(\beta\)。若 \(M=\omega\) 则跳至第 4 步。
- 若 \(M=1\) 则直接删掉右上角然后跳到第 6 步。
- 如果 \(\alpha+M-1\le\beta\) 则删掉右上角,否则将右上角分隔符值减一,即删掉最后一个逗号,跳到第六步。
- 如果 \(A\) 中含有
;则令重数值为 \(1\),否则重数值为 \(A\) 的值加一。 - 如果 \(\alpha<\beta\) 且 \(B\) 的值大于等于重数值那么删去右上角,否则把右上角的分隔符值改为重数值。
- 把根元素上方的元素(不含根元素)都复制到最右列上方。
可以看到,如果不是极限分隔符那么规则和 ωMN 是一样的。
减一操作结束之后,我们开始展开。
对于一个矩阵进行 \(\omega\) 次延伸,每次流程如下:
首先确定右上角、根列元素、复制部分、复制宽度、magma元素。
然后做减一操作。
然后确定参考元素、拉伸阈、拉伸量。
注意减一操作在确定参考元素、拉伸阈、拉伸量之前。
然后,从左到右逐列地把复制部分的元素(称为源元素)复制到右边的新增列中(目标元素)。
对于每一个“源元素列”的复制,从下到上操作列中元素。第 \(0\) 行的元素需要操作,但它不会作为源元素。最上端的元素不需操作,但它会作为源元素。
对于一个被操作的元素 \(a\),沿右腿向上一格,到达的元素 \(x\) 是待复制的源元素。
如果 \(a\) 不是 magma 元素,那么 \(x\) 只能复制成一个目标元素。
如果 \(x\) 的值小于根列的列标,那么目标元素的值与 \(x\) 相同。
如果 \(x\) 的值大于等于根列的列标,那么目标元素的值等于 \(x\) 的值加上复制宽度。
如果 \(x\) 的分隔符大于等于其对应行标下一个根元素的分隔符或小于拉伸阈或没有拉伸阈,则目标元素的分隔符与 \(x\) 相同。
否则,目标元素的分隔符是“\(x\) 的分隔符后面添加拉伸量重逗号”。
可以看到前两条规则和 ωMN 相同,对于后两条规则,出现了每个复制元素都有的分隔符增长,这就是我们开头提到的和简单的 TωMN 不同的地方,这也是一种 eruption。
如果 \(a\) 是 magma 元素,那么 \(x\) 可以复制成多个目标元素。具体的,找到 \(a\) 所对应的根列元素,其对应的每个参考元素都会产生一个目标元素。
任何情况下,目标元素的值等于 \(x\) 的值加上复制宽度。
对于不是最上端的参考元素,目标元素的分隔符为参考元素沿右腿向上一格后所得到的元素的分隔符。
对于最上端的参考元素,分隔符确定方式如下:
如果 \(x\) 的分隔符大于等于其对应行标下一个根元素分隔符或小于拉伸阈,或者没有拉伸阈,则目标元素的分隔符与x相同。
否则,目标元素的分隔符是“\(x\) 的分隔符后面添加拉伸量重逗号”。
这里最上端的参考元素的分隔符确定方式和非 magma 元素一样,其它规则同样和 ωMN 一样。
以下例子中,标红为根元素。
以 \(()(;1)(,2;1)(,3,3)(\color{red},1\color{a})(,5;5)(,6,,6;5)(,7,,7,7;5)\) 为例,第一次进行减一操作后,最后一个分隔符是 ;,需要实行极限分隔符规则,得到 \(()(;1)(,2;1)(,3,3)(\color{red},1\color{black})(,5;5)(,6,,6;5)(,7,,7,7,,5)\)
此时拉伸阈为 \(,,\),拉伸量为 \(1\)。
可以得到 \(()(;1)(,2;1)(,3,3)(,1)(,5;5)(,6,,6;5)(,7,,7,7\color{red},,5\color{black})(,8,,8,8,,8;8)(,9,,9,9,,9,,,9;8)(,10,,10,10,,10,,,10,10;8)\)。
再次减一得到 \(()(;1)(,2;1)(,3,3)(,1)(,5;5)(,6,,6;5)(,7,,7,7\color{red},,5\color{black})(,8,,8,8,,8;8)(,9,,9,9,,9,,,9;8)(,10,,10,10,,10,,,10,10,,,8)\)。
此时拉伸阈和拉伸量都没有。
可以得到 \(()(;1)(,2;1)(,3,3)(,1)(,5;5)(,6,,6;5)(,7,,7,7\color{red},,5\color{black})(,8,,8,8,,8;8)(,9,,9,9,,9,,,9;8)(,10,,10,10,,10,,,10,10,,,8)(,11,,11,11,,11,,,11,11,,,11;11)(,12,,12,12,,12,,,12,12,,,12,,,,12;11)(,13,,13,13,,13,,,13,13,,,13,,,,13,13,,,,11)\)。
现在右上角元素分隔符不是逗号了,可以按 ωMN 方式展开了。
本篇内容结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号