OO 第三单元总结
OO 第三单元总结
摘要
本单元主要根据课程组提供的接口中的JML规格,实现自己的方法。 JML(JAVA Modeling Language)是一种形式化的、面向JAVA的行为接口规格语言,起初会比较陌生,但是仔细学习JML手册后可以发现其描述的逻辑和大一下学习的离散一中的逻辑基本一致,在熟悉后还是比较直白易懂的,而且作业中大部分方法的实现和JML描述的流程基本一样,只需按部就班地实现即可。当然,三次作业中有许多处的容器和数据结构是需要自己设计和优化的。这也是三次作业主要的工作量。不过总体而言,工作量相比前两单元还是少了很多。
Homework9、10、11:三次作业最终需要实现一个社交关系模拟系统。可以通过各类输入指令来进行数据的增删查改等交互。可以抽象为利用有关图论的数据结构和相关算法创建并维护一个以人为结点的有向图。
分析在本单元自测过程中如何利用JML规格来准备测试数据
本次的测试,最开始还是自己粗略检查是否完备地实现了JML所要求的各种琐碎的细节。但是,这个层次的检查也只是可以纠正一些简单的手误或者低级错误。
之后进一步的测试则是通过跑随机数据生成器生成的数据与同学对拍代码实现的。对拍的优点在于可以高效地验证代码的正确性,缺点在于对方法复杂度的查验不好。此外,由于作业中社交系统的功能十分复杂,且互相间的承接也比较重要,比如一定量的人和关系是其他一切功能的基础,所以纯随机出的测试样例,并没有办法直击要害,第二次作业也出现了多次对拍后仍然暴毙的惨状,在对拍中,参与的几个朋友都出现了不同程度的问题。。所以之后的数据增加了对边界情况的考虑和对性能的考察,也起到了不错的效果。
梳理本单元的架构设计,分析自己的图模型构建和维护策略
本单元的作业需要自己设计的地方不如前两个单元多,我的设计流程如下:
- 浏览各官方接口,理清各个方法目的。
- 将操作分类:查询类型和修改类型,查询类只需要完成所要求的功能,修改类可能还需要添加额外操作,比如并查集的维护。
- 优先实现较简单的方法和所有异常类
- 分析各类的属性,进行合适的容器选取。
- 分析方法的复杂度,对根据规格实现可能超时的方法设计合理的优化算法。
此设计流程贯穿三次作业,以下进行作业回顾:
第一次作业
容器选择
为了查找效率,MyPerson类的acquaintances,MyGroup类的人和MyNetwork类的人和group都选择了HashMap,此外,MyNetwork里还加了一个HashMap,进行并查集算法中祖先的存储。
复杂方法
本次涉及算法需要考虑性能的方法有isCircle、queryBlockSum
- isCircle选择了带路径压缩的并查集的算法。这里要注意发生栈溢出问题。解决栈溢出的办法是:在递归调用find方法时要先保存find出的祖先,再替换和返回,其次就是添加关系时合并两人的父节点,find方法如下:
private int find(int id) {
if (pa.get(id) == id) {
return id;
}
int ans = find(pa.get(id));
pa.replace(id, ans);
return ans;
}
queryBlockSum考虑到时间复杂对问题,没有采用每次查询朴素遍历的方式,而是在MyNetWork里定义了blockNum变量,在addPerson、addRelation方法里进行++和--的维护,之后在调用queryBlockSum方法时直接返回blockNum的值,达到O(1)的复杂度。值得一提的是,这种维护一个缓冲变量,调用相应的查询方法时直接返回其值的处理在之后的getAgeVar、getValueSum等方法里都有相同的应用
第二次作业
容器选择
本次作业新增了MyMessage类,MyPerson类里新增LinkedList存储他的所有messages,目的是为了方便message的头部插入。
复杂方法
本次需要考虑的问题是对group中人员的ValueSum、AgeMean、AgeVar的相关计算以及queryLeastConnection(int)方法要求最小生成树
ValueSum/AgeMean方法极易CTLE,解决方法是进行相关值的缓存,并实现相应的维护
两个方法即要算:
可以令
两个量在addPerson 和 delPerson时维护。有:
@Override
public void addPerson(Person person) {
MyPerson p = (MyPerson) person;
people.put(p.getId(), p);
ageSum += p.getAge();
ageSqrSum += (p.getAge() * p.getAge());
}
@Override
public void delPerson(Person person) {
MyPerson p = (MyPerson) person;
int id = p.getId();
ageSum -= p.getAge();
ageSqrSum -= p.getAge() * p.getAge();
people.remove(id);
for (Map.Entry<Integer, MyPerson> entry : people.entrySet()) {
if (entry.getValue().isLinked(person)) {
valueSum -= (person.queryValue(entry.getValue()) * 2);
}
}
}
queryLeastConnection方法采用Kruskal算法,新建一个Edge类代表图中的边,在MyNetwork里用TreeSet存储所有Edge,TreeSet自动根据Edge的权重进行从小到大的排序 ,在addRelation时对TreeSet进行添加新的边的操作,之后对排好序的边集进行Kruskal算法即可
public int queryLeastConnection(int id) throws PersonIdNotFoundException {
if (!contains(id)) {
throw new MyPersonIdNotFoundException(id);
} else {
HashMap<Integer,MyPerson> personInBlock = new HashMap<>();
ArrayList<Edge> edgesInBlock = new ArrayList<>(); // 此数组中的边权重已经按照从大到小的顺序排序
HashMap<Integer,Integer> dsu = new HashMap<>();
dsu.put(id,id);
for (Map.Entry<Integer, MyPerson> per : people.entrySet()) {
if (isCircle(id, per.getKey())) {
personInBlock.put(per.getKey(),per.getValue());
dsu.put(per.getKey(),per.getKey()); // 并查集的初始化
}
}
for (Edge edge : edges) {
MyPerson person1 = edge.getP1();
MyPerson person2 = edge.getP2();
if (personInBlock.containsKey(person1.getId())
&& personInBlock.containsKey(person2.getId())) {
edgesInBlock.add(edge);
}
} // Kruskal is followed :
int res = 0;
for (Edge edge : edgesInBlock) {
int a = find(dsu,edge.getP1().getId());
int b = find(dsu,edge.getP2().getId());
if (a != b) {
res += edge.getVal();
dsu.replace(a, b); //并查集将两个集合合并
}
}
return res;
}
}
第三次作业
容器选择
本次作业新增了EmojiMessage、NoticeMessage、RedEnvelopMessage类,其中NoticeMessage和RedEnvelopMessage类的需求实现比较简单,我只在MyNetwork中添加了新的HashMap来存储每条EmojiMessage的热度。
复杂方法
sendIndirectMessage
跑堆优化的dijkstra算法即可
public int dijkstra(Person person1, Person person2) {
HashMap<Integer, Integer> vis = new HashMap<>();
HashMap<Integer, Integer> dis = new HashMap<>();
Queue<Edge> que = new PriorityQueue<>();
MyPerson p1 = (MyPerson) person1;
que.add(new Edge(p1,p1, 0));
dis.put(p1.getId(), 0);
while (!que.isEmpty()) {
Edge now = que.poll();
MyPerson u2 = now.getP2();
if (dis.get(u2.getId()) < now.getVal()) {
continue;
}
if (vis.containsKey(u2.getId())) {
continue;
}
vis.put(u2.getId(), 1);
for (Integer key:u2.getAcquaintances().keySet()) {
int next = key;
int weight = u2.queryValue(getPerson(key));
if (!vis.containsKey(next)) {
if (!dis.containsKey(next)) {
dis.put(next, dis.get(u2.getId()) + weight);
que.add(new Edge(p1,people.get(next), dis.get(next)));
} else if (dis.get(next) > dis.get(u2.getId()) + weight) {
dis.replace(next, dis.get(u2.getId()) + weight);
que.add(new Edge(p1,people.get(next), dis.get(next)));
}
}
}
}
MyPerson p2 = (MyPerson) person2;
return dis.get(p2.getId());
}
架构设计
本次作业的架构设计均已由官方给出,只需正确实现其中的每一个方法即可,我只有为了辅助Kruskal算法和dijkstra算法的实现新建了Edge类。三次作业结束后具体UML类图如下:
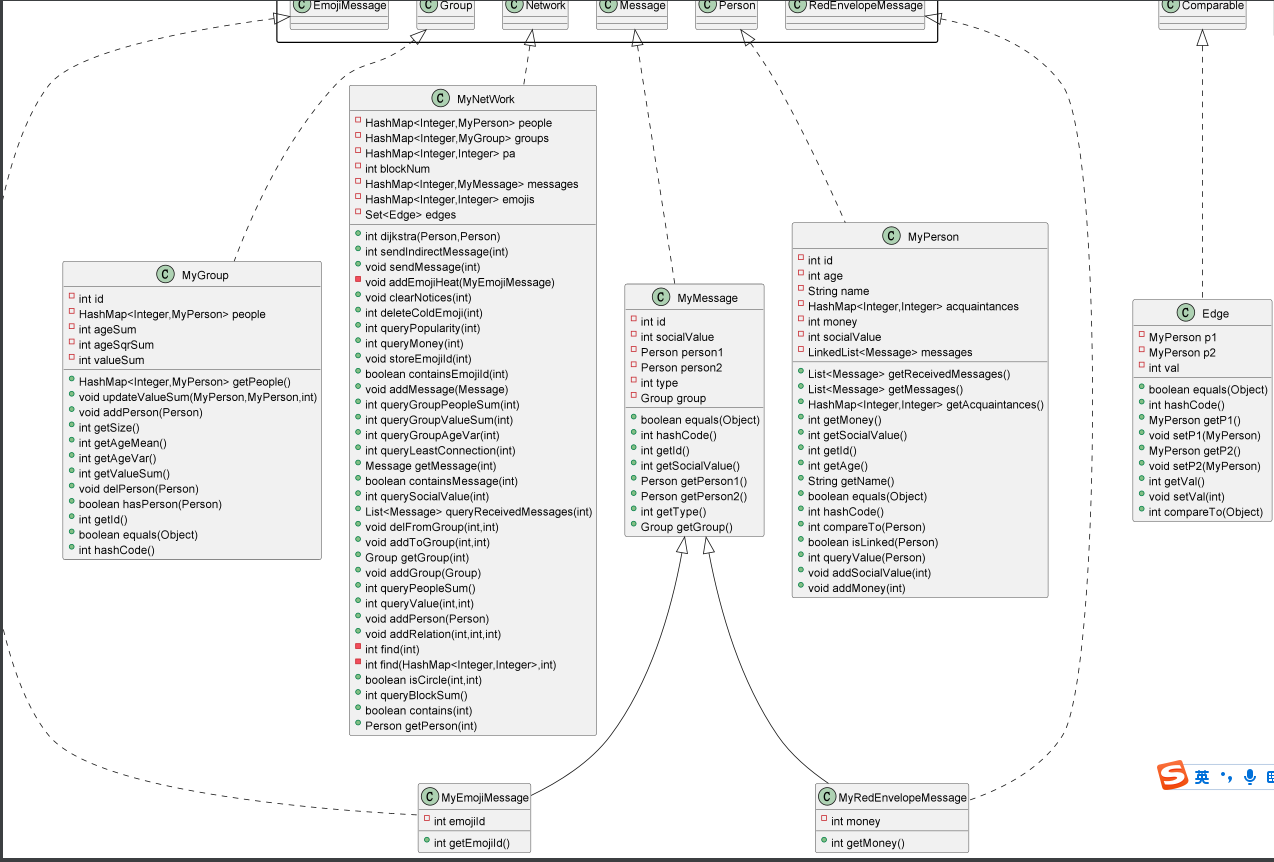
按照作业分析代码实现出现的性能问题和修复情况
第一、三次作业在强测和互测中均未出现任何Bug。在自己测试阶段也仅发现几个因JML阅读理解有误造成的小错误。(对拍大法好)互测同房的同学貌似也没有出现什么大问题,
第二次作业强测寄了4个点原因均是getAgeVar方法竟然忘记写除数为零而返回0的情况,导致只要输入中有除数为0的数据代码都会崩(悲)
public int getAgeVar() {
if (getSize() == 0) { //这个判断是强测寄了之后deBug加上的,鬼知道我为啥在JML中都有提示的情况下写漏了它
return 0;
}
int ave = getAgeMean();
int size = getSize();
int s = ageSqrSum - 2 * ave * ageSum + size * ave * ave;
return s / size;
}
此外互测中因为getValueSum偷懒没有用维护缓冲值的方法,而是每次都朴素都遍历被人Hack出了TLE的问题。修复Bug的方法则是在MyGroup类中添加变量ValueSum记录要查询的值,之后在addToGroup、delFromGroup、addRelation方法中对它进行相应维护,之后查询时直接返回ValueSum。
第二次作业中的这几个Bug确实将对拍的所有缺点都体现出来了,一是对一些特殊的边界输入没有进行特殊考虑,当时随机生成的数据甚至没有除数为0的数据;二是对时间复杂度的检测效率并不高。
请针对下页ppt内容对Network进行扩展,并给出相应的JML规格
- Advertiser:持续向外发送产品广告
- Producer:产品生产商,通过Advertiser来销售产品
- Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
- Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等 请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)
设计如下
将Advertiser、Producer、Customer类继承MyPerson类,之后在其中添加其特有的方法;
新建Product类,其中记录有产品的id和value;
新建PurchaseMessage,ProduceMessage,AdvertiseMessage类继承Message类
3个核心业务功能的JML规格撰写如下:
发送广告
/*@ public normal_behavior
@ requires containsMessage(id) && (containsAdvertisement(id));
@ assignable messages;
@ assignable people[*].messages;
@ ensures !containsMessage(id) && messages.length == \old(messages.length) - 1 &&
@ (\forall int i; 0 <= i && i < \old(messages.length) && \old(messages[i].getId()) != id;
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i]))));
@ ensures (\forall int i; 0 <= i && i < people.length && !getMessage(id).getPerson1().isLinked(people[i]);
@ people[i].getMessages().equals(\old(people[i].getMessages()));
@ ensures (\forall int i; 0 <= i && i < people.length && getMessage(id).getPerson1().isLinked(people[i]);
@ (\forall int j; 0 <= j && j < \old(people[i].getMessages().size());
@ people[i].getMessages().get(j+1) == \old(people[i].getMessages().get(j))) &&
@ people[i].getMessages().get(0).equals(\old(getMessage(id))) &&
@ people[i].getMessages().size() == \old(people[i].getMessages().size()) + 1);
@ also
@ public exceptional_behavior
@ signals (MessageIdNotFoundException e) !containsMessage(id);
@ signals (AdvertisementIdExistException e) containsAdvertisement(id);
@*/
public void sendAdvertisement(int id) throws
MessageIdNotFoundException, AdvertisementIdExistException;
查询某个Producer生产的产品的总额
/*@ public normal_behavior
@ requires containsProducer(producerId)
@ ensure \result = (\sum (int i ; 0 <= i && i <= getProducer(producerId).products.length ; getProducer(producerId).products[i]))
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !containsProducer(producerId);
@*/
public int queryCommoditisValue(int producerId)
生产产品
/*@ public normal_behavior
@ requires containsProducer(producerId) && !containsProduct(productId));
@ assignable getProducer(producerId).productCount,productSum;
@ ensures getProducer(producerId).getProductCount(productId) ==
@ \old(getProducer(producerId).getProductCount(productId)) + 1;
@ ensures productSum == \old(productSum) + 1;
@ assignable getProducer(producerId).products,products;
@ ensure (\forall int i; 0 <= i && i < \old(getProducer(producerId).products.length)
@ && \old(getProducer(producerId).products.getId()) != productId;
@ (\exists int j; 0 <= j && j < getProducer(producerId).products.length;
@ getProducer(producerId).products[j].equals(\old(getProducer(producerId).products[i]))));
@ ensure (\forall int i; 0 <= i && i < \old(products.length)
@ && \old(products.getId()) != productId;
@ (\exists int j; 0 <= j && j < products.length;
@ products[j].equals(\old(products[i]))));
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !containsProducer(producerId);
@ signals (ProductIdExistException e) containsProduct(productId));
@*/
public void produceProduct(int producerId, int productId) throws
PersonIdNotFoundException,ProductIdExistException;
本单元学习体会
关于JML
JML是函数功能的外化,能高效、清晰地对需求和函数执行结果进行规划。但本单元过后自己动手写JML的能力还较差,只是培养了个根据JML实现功能的能力。
同时,在实现JML时也不能因为它限制了自己的思考,一些JML的实现也不必按照它描述的流程来一步步实现。JML规格描述仅限于描述当前的方法,而其实许多方法之间都有着相互协作的关系,本单元根据JML实现各个方法时,很容易产生疏离感,让你感觉自己只在写手头上这个方法,而忘却了这个社交系统的整体性和各部分间的联系。所以写时要牢记自己在写的是社交系统,牢记初心。
关于算法基础
目前还没有系统学习过算法,对于数据结构的知识也几乎忘光,每个单元用的算法都是自己现学的。因此,要从现在开始脚踏实地慢慢积累算法知识,总结经验。
关于测评
本单元的测试较前两单元我测得更多,因为本单元采用了数据生成来对拍。这样是比较高效的,对拍过程中每个人都找到了自己的一些奇怪的Bug,同时根据数据的异常输出定位Bug的能力也有了提升。
唯一遗憾的就是第二次作业中的TLE问题和没有考虑除数为0的问题,确实有回到高中考试时第一题最简单的选择题就做错痛失5分的感觉。可见还是太浮躁了,之后还要注意细心的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号