

K8s网络简介
网络设备简介
网络设备就像一个管道,从一端收到的数据从另一端发出去。
比如网卡,它的两端是内核协议栈和物理网络, 从物理网络收到的数据会转发给内核协议栈,而应用程序从协议栈发过来的数据将会通过物理网络发出去
cat /proc/net/dev //看所有网络设备
ls /sys/devices/virtual/net/ //看虚拟网络设备
对于Linux内核网络设备管理模块来说,虚拟设备与物理设备没什么区别,
都是网络设备,
都能配置IP,
数据都会转发给内核协议栈,
而从内核协议栈发来的数据,也会交由网络设备发送出去
所以说,虚拟网络设备的一端是协议栈,另一端是什么,取决于虚拟网络设备的驱动实现。
虚拟网络设备简介
Bridge:
bridge是linux上用来做TCP/IP二层协议交换的设备,与现实中的交换机功能相似。
和现实世界中的交换机处理过程类似:判断目的mac,单播or广播,单播的话,查找mac映射表,从目标端口转发出去或者丢弃,自动更新mac表
VLAN device
按照协议原理一般分为:
macVLAN、802.1qVLAN、802.1qbgVLAN、802.1qbhVLAN
linux里的802.1q VLAN设备是以母子关系成对出现的。 母设备连接上层设备相当于现实中的交换机TRUNK口。子设备连接下级网络。
数据在母子设备间传递时,内核会根据802.1q VLAN Tag进行对应操作。母子设备之间是一对多的关系。
当一个子设备有一包数据需要发送时,数据被加入vlan tag然后发到母设备, 母设备查看相应tag的子设备,如果有,移除tag转发数据,如果没有,丢弃数据。
母子设备具有相同的mac,子设备之间时隔离的
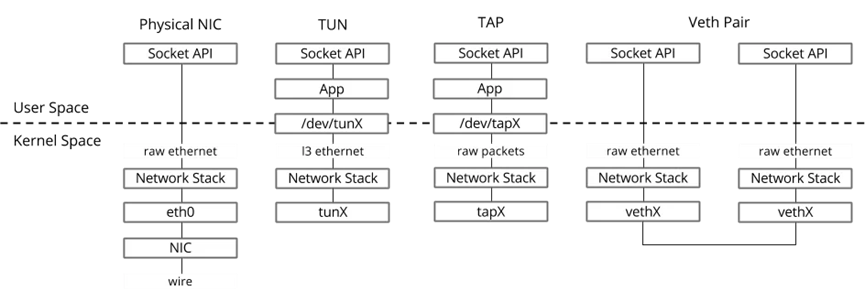
TAP设备与TUN设备
TUN/TAP设备是一种让用户态程序向内核协议栈注入数据的设备。
一个tap/tun设备被创建时,在linux设备文件目录下会生成一个对应的char设备,用户程序像打开普通文件一样对这个文件进行读写。
当执行write()时,代表数据进入TAP设备,当执行read()时,代表TAP设备发送数据
TUN/TAP驱动程序:
- 一个是字符设备驱动, -- 负责数据包在内核空间和用户空间的传送
- 一个是网卡驱动. -- 负责数据包在TCP/IP网络协议栈上的传输和处理

TUN是Linux内核的一种虚拟三层网络设备,在操作系统内核和用户空间程序传递IP包

TAP 设备与 TUN 设备工作方式完全相同,区别在于:
- TUN 设备是一个三层设备,它只模拟到了 IP 层,即网络层 我们可以通过 /dev/tunX 文件收发 IP 层数据包,它无法与物理网卡做 bridge,但是可以通过三层交换(如 ip_forward)与物理网卡连通。可以使用ifconfig之类的命令给该设备设定 IP 地址。
- TAP 设备是一个二层设备,它比 TUN 更加深入,通过 /dev/tapX 文件可以收发 MAC 层数据包,即数据链路层,拥有 MAC 层功能,可以与物理网卡做 bridge,支持 MAC 层广播。同样的,我们也可以通过ifconfig之类的命令给该设备设定 IP 地址,你如果愿意,我们可以给它设定 MAC 地址。
VETH-pair
VETH出现较早,它的作用是反转通讯数据的方向,需要发送的数据会被转化成需要收到的数据重新送入内核网络层进行处理,从而间接完成数据的注入
重点:跨namespace通信

对比
Calico简介
Calico是一种容器之间互通的网络方案。在虚拟化平台中,比如OpenStack,Docker等都需要实现workloads之间互联,但同时也需要对容器做隔离控制,就像Internet中的服务仅开放80端口,公有云的多租户一样,提供隔离和管控机制。
Calico原理
设计思想
Calico不使用隧道或NAT来实现转发,而是巧妙的将所有的二三层流量转换成三层流量,并通过host上路由配置完成跨Host转发。
Calico核心组件:

Felix:Calico agent,是一个守护程序 跑在每台需要运行workload的节点上,负责网络接口管理和监听,路由及ACL管理同步,状态上报等;
监听ETCD,从它获取事件,比如用户在这台机器上加了一个IP,或者创建了一个容器等。用户创建pod后,Felix负责将其网卡,ip,MAC都设置好,然后在内核中添加一条路由条目,到这个ip需要到这个网卡
如:192.168.135.42 dev calibc5f0965128 scope link
如果制订了隔离策略,Felix会将该策略创建到ACL中,以实现隔离。

ETCD:分布式键值存储,负责网络元数据一致性,确保calico网络状态的准确性;
BGP Client(BIRD):Calico为每一台Host部署一个BGP Client,使用BIRD实现,BIRD是一个功能齐全的动态路由守护进程,实现了众多动态路由协议,如BGP,OSPF,RIP等。在Calico的角色是监听Host上由Felix注入的路由信息,然后通过BGP协议广播告诉其余Host节点,从而实现网络互通。
BGP Route Reflector(BIRD)
大规模集群需要使用到,作为BGP Client的中心连接点,避免每个节点互联
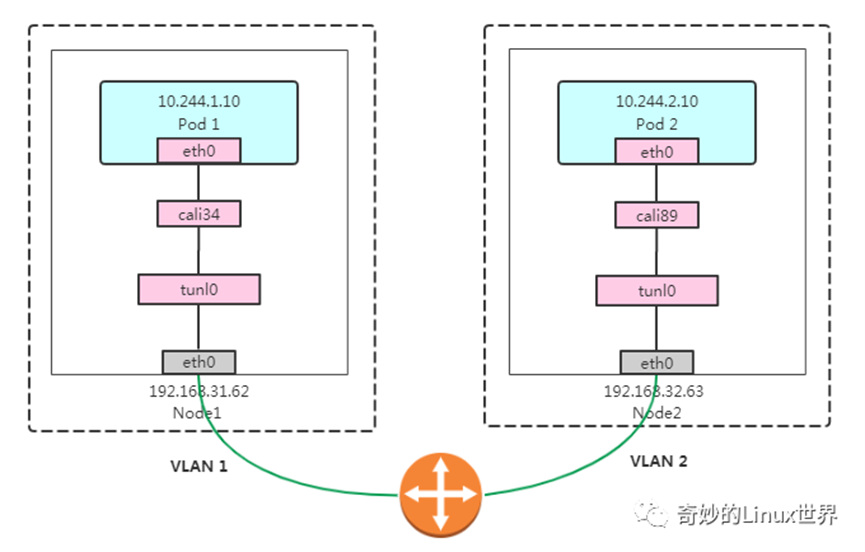
Calico网络Node之间两种网络
IPIP
Node间报文交互通过tunl0网卡,将ip层封装到ip层的一个tunnel。
BGP
去中心化的自治路由协议。通过维护路由表来实现AS间的可达性,AS间是矢量性协议

Pod间通信流程

容器内通过这个默认路由,将任何往外发的包认为是三层包, 因为网关是169.254.1.1,目的mac会封装成这个网关的mac,外界会认为这是个三层报文。【代理ARP原理】
同一个Host内,Pod间通信(抓包)
Node3上的两个pod间ping一下,192.168.135.15 ping 192.168.135.14
查看路由表有直达的路由条目:
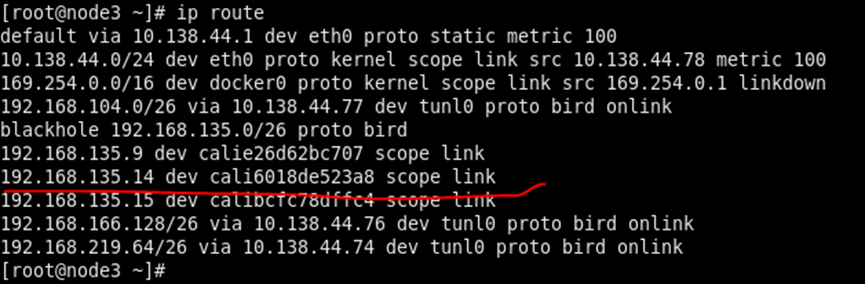
看下traceroute过程:

多了个44.78,这个是host的地址,因为calico网卡是在host上的所以多了这个条目
不同Host,pod间通信
从192.168.166.160 ping 192.168.135.14
Master上:

登录到容器里:

在容器里ping:

在node3 eth0上抓包
Tcpdump ip –I eth0 –P in –t –s 0 src host

在node3 tunl0上抓包:

查看路由表,找去往192.168.135.14的路由:

在calico网卡上抓包:

参考Veth图,流量进出网卡方向


从node1 calico网卡的出方向抓包,ping的数据包88,+8个icmp包头+20个ip头+14个mac头,共130字节
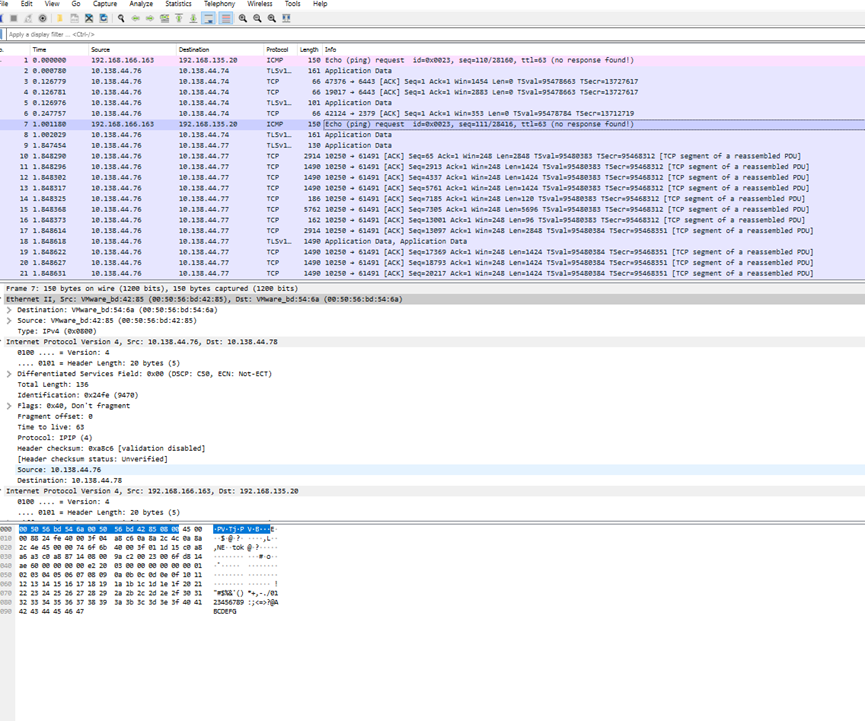
这个是从node3上的eth0收到的报文
88+8+20+20+14=150字节
Service简介
K8s的svc定义:一个pod的逻辑分组,一种可以访问他们的策略—通常称为微服务。
这一组pod能够被svc访问到,通常是通过Label Selector。Svc是用来暴露服务的
Svc四种类型:
Cluster IP:默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP。只能在集群内部访问
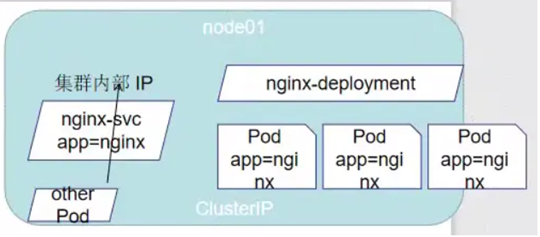
NodePort:在ClusterIP的基础上,为svc在每台机器上绑定一个端口,这样就可以通过NodeIP:NodePort来访问该服务
缺陷:容器端口冲突,不能统一入口,不能根据域名访问
通常会在node外加一个负载路由器统一访问svc

LoadBalancer:在NodePort基础上,引入cloud provider,创建一个外部负载均衡器,并将请求转发到NodeIP:NodePort上
与NodePort的区别在于,前端的负载路由器不用我们自己去配置,而使用云供应商的负载路由器,收费的

ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建。
Kube-proxy代理模式分类:
Userspace
V1.2后就被淘汰了,userspace的作用是在proxy的用户空间监听一个端口,所有的svc都转到这个端口,然后proxy的内部应用层对其转发。Proxy会为每个svc随机监听一个端口,并增加一个iptables规则,从客户端到ClusterIP:Port的报文都会被重定向到proxy port,然后通过Round Robin或者Session Affinity分发给对应的pod。

iptables
Linux iptables
iptables是基于内核的防火墙,前身是ip firewall(内核1.x时代)
iptables的功能由两部分组成: netfilter 和 iptables
netfilter在内核空间运行, 它是一组保存着一系列规则的表,内核利用这些规则进行网络分组过滤。
iptables在用户空间运行,它用来设置,维护和显示netfilter保存的规则
iptables有4个表,5条链:
表按照对数据包的操作区分
filter: 包过滤,如禁止访问,允许访问等,也是默认的处理表
nat: 用于nat,如端口映射,源/目的地址转换
mangle: 用于对特定数据包的修改,流量整形,如数据包打标记
raw: 优先级最高,设置raw一般是为了不再让iptables做数据包的连接跟踪和地址转换,提高性能
链按照不同的hook点来区分
PREROUTING: 数据包进入路由表之前
INPUT: 通过路由表后目的地为本机
FORWARD: 通过路由表后目的地不为本机
OUTPUT:由本机产生向外转发
POSTROUTING: 发送到网卡接口之前
表和链是netfilter的两个维度
表的处理优先级:
raw > managle > nat > filter
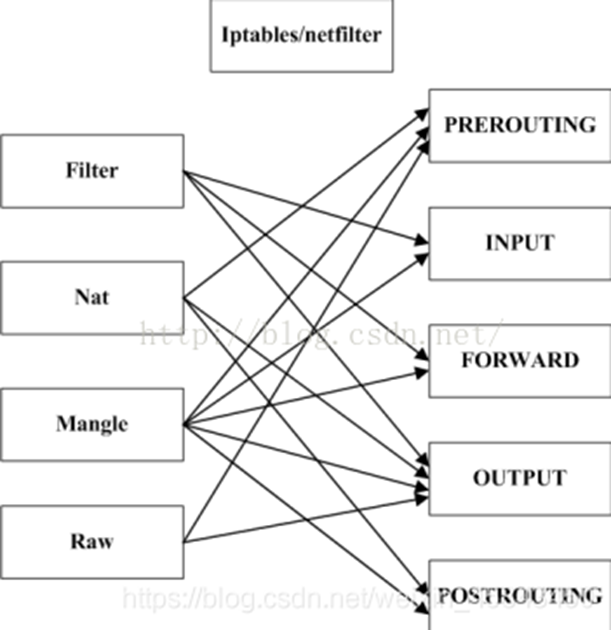
Linux数据转发流程:

iptables在k8s的应用
Kube-proxy通过apiserver的watch接口监控k8s对svc和endpoint对象的变更,创建或更新相应的iptables规则,流量通过iptables的NAT机制“直接路由”到目标endpoint
iptables模式中kube-proxy在NAT PREROUTING Hook中实现它的NAT和负载均衡功能
每增加一个svc就会增加一条iptables chain。

IPVS
在ipvs模式下,使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。Iptables规则链是一个线性数据结构,ipset则引入了带索引的数据结构。复杂度O(n)与O(1)的区别
IPVS是LVS项目的重要组成部分,ipvs工作在内核中netfilter的INPUT的钩子函数上
目前包含于官方Linux kernel,ipvs依赖于netfilter框架,位于内核源码的net/netfilter/ipvs目录下,ipvs是一款运行在kernel中的4层负载均衡器。性能异常优秀。
IPVS负载均衡模式
NAT
FULLNAT
DR(Direct Routing)
iptables与ipvs区别
性能:iptables是线性增加规则,而ipvs是基于ipset集合实现恒定
健康检查:iptables本身无法做到健康检查,ipvs可以
调度算法:iptables基于随机算法,ipvs支持静态和动态算法
调度算法
轮询调度(Round Robin,简称RR):
依次循环将请求调度到不同的服务器上
加权轮询调度(Weight Round Robin,简称WRR):
对轮询的补充,LVS会考虑每台服务器性能,给每台服务器一个权值,性能越好,权值越高,处理的请求越多。
最小连接调度(Least Connections,简称LC):
把新的连接请求分配到当前连接数最少的服务器上
加权最小连接调度(Weight Least Connections,简称 WLC):
权值表示处理性能,亦表示期望,可以动态设置,WLC 在调度新连接时,尽可能的使服务器的已建立连接数与其权值成正比例。调度器可以自动问询服务器真实负载情况,并动态调整其权值
基于局部的最少连接(Locality-Based Least Connections,LBLC):
针对请求报文的目的ip地址来负载均衡调度。
目前主要用于cache集群系统。因为在cache集群客户请求报文的目标ip地址是变化的。
目标:在服务器负载进本均衡情况下,将相同目的IP的报文调度到同一台server,提高服务器的访问局部性和cache命中率
带复制的基于局部性的最少连接:
目前主要用于cache集群系统。它与LBLC不同之处在于,它要维护从一个目标ip地址到一组服务器的映射,而LBLC只维护从一个目标ip地址到一台服务器的映射
目标地址散列调度(Destination Hashing,DH)
根据请求的目标IP地址,作为散列键,从静态分配的散列表中找出对应服务器,若未超载,将请求发给该服务器,超载返回空
源地址散列调度
最短的期望的延迟(Shortest Expected Delay,SED)
基于WLC,举例说明,如果A,B,C三台服务器权重分别1,2,3,使用SED算法后会进行运算A:(1+1)/1=2;B:(1+2)/2=1.5;C: (1+3)/3=4/3,会把请求交给结果最小的服务器
最少队列调度(Never Queue,NQ)
无需队列,如果有连接数等于0的就直接分配过去,无需SED运算

Kube-proxy包转发过程:

步骤:
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存,此时才有了大家熟悉的 skb(包的内核结构体表示,分析报文的字段并赋值给不同成员变量),然后 送到内核协议栈。
- 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在 PREROUTING hook 点处理 raw table 里的 iptables 规则。
- 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在 PREROUTING hook 点处理 mangle table 的 iptables 规则。
- Netfilter:在 PREROUTING hook 点处理 nat table 的 iptables 规则。
- 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在 FORWARD hook 点处理 mangle table 里的iptables 规则。
- Netfilter:在 FORWARD hook 点处理 filter table 里的iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 mangle table 里的iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 nat table 里的iptables 规则。
- 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:发送到一个本机 veth 设备,或者一个本机 service endpoint, 或者,如果目的 IP 是主机外,就通过网卡发出去。
Iptables模式下kube-proxy转发分析:
- 起一个svc

- 看PREROUTING链:

- 转到KUBE-SERVICES

3.1 源地址不是集群内部pod地址

将该条数据打标记,继续下一条匹配
3.2 所有到10.108.53.44的都重定向到KUBE-SEP链

- 看下每条KUBE-SEP链,三条规则对应三个endpoint,匹配到的概率见上图
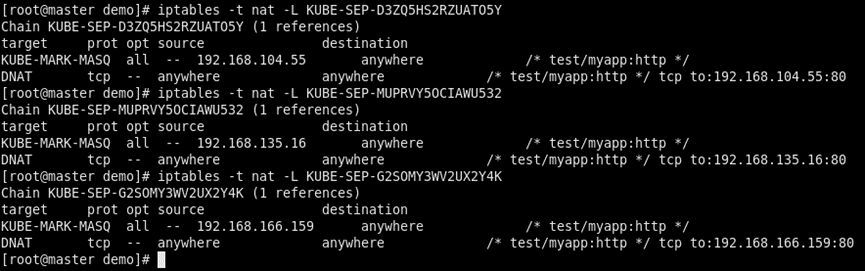
KUBE-MARK-MASQ表示打标签,DNAT表示做目的ip:端口转换到对应的endpoint
然后看INPUT链


附录
DMA
DMA(Direct Memeory Access):直接存储器访问,是现代电脑的重要角色,它允许不同速度的硬件装置来沟通,而不需要依赖于CPU的大量中断负载。
DMA传输 是将数据从一个地址空间复制到另一个地址空间。
一个完整的DMA传输过程:
DMA请求:
CPU对DMA控制器初始化,并向I/O接口发出操作命令,I/O接口提出DMA请求
DMA响应:
DMA控制器对DMA请求判断优先级及屏蔽,并向总线裁决逻辑提出总线请求。当CPU完成当前总线周期即可释放总线控制权。此时,总线裁决控制逻辑输出总线应答,表示DMA已经响应,通过DMA控制器通知I/O接口开始DMA传输。
DMA传输:
DMA控制器获得总线控制权后,CPU即刻挂起或只执行内部操作。DMA控制器输出读写命令,直接控制RAM与I/O进行DMA传输
在DMA控制器的控制下,在存储器和外部设备之间直接进行数据传送。不需CPU参与
DMA结束:
传输完成后,DMA控制器释放总线控制权,并向I/O接口发出结束信号。

由此可见,DMA传输方式无需CPU直接控制传输,通过硬件为RAM与I/O设备开辟一条直接传送数据的通路,使CPU效率大大提高。
DMA控制器与CPU分时使用内存三种方式



Ring-buffer
缓冲区
https://www.cnblogs.com/luego/p/12048857.html
缓冲区(Buffer)是在内存中预留指定大小的存储空间 用来对输入/输出(I/O)的数据做临时存储,这部分预留空间就叫缓冲区
使用缓冲区有这么两个好处:
1、减少实际的物理读写次数
2、缓冲区在创建时就被分配内存,这块内存区域一直被重用,可以减少动态分配和回收内存的次数
举个简单的例子,比如A地有1w块砖要搬到B地
由于没有工具(缓冲区),我们一次只能搬一本,那么就要搬1w次(实际读写次数)
如果A,B两地距离很远的话(IO性能消耗),那么性能消耗将会很大
但是要是此时我们有辆大卡车(缓冲区),一次可运5000本,那么2次就够了
相比之前,性能肯定是大大提高了。
Fields
属性 描述
|
Capacity |
容量,即可以容纳的最大数据量;在缓冲区创建时被设定并且不能改变 |
|
Limit |
表示缓冲区的当前终点,不能对缓冲区超过极限的位置进行读写操作。且极限是可以修改的 |
|
Position |
位置,下一个要被读或写的元素的索引,每次读写缓冲区数据时都会改变改值,为下次读写作准备 |
|
Mark |
标记,调用mark()来设置mark=position,再调用reset()可以让position恢复到标记的位置 |
From <https://blog.csdn.net/qq_28657577/article/details/80990777>
环形缓冲区(ring-buffer)
通信程序中,经常使用环形缓冲区来存放数据。它是一个先进先出的循环缓冲区,可以向通信程序提供对缓冲区的互斥访问。
原理:
环形缓冲区有一个读指针和一个写指针。读指针指向环形缓冲区中可读数据,写指针指向可写的缓冲区。通过移动读指针和写指针可以实现数据的读取和写入
读用户仅影响读指针,写用户仅影响写指针;若仅有一个读用户和一个写用户,天然互斥;若有多个读写用户,需添加互斥锁

只有当存储空间的分配/释放非常频繁并且确实产生了明显的影响,才考虑环形缓冲区
XDP
XDP全称为eXpress Data Path,是Linux内核网络栈的最底层。它只存在于RX路径上,允许在网络设备驱动内部网络堆栈中数据来源最早的地方进行数据包处理,在特定模式下可以在操作系统分配内存(skb)之前就已经完成处理。
XDP系统4个组件:
XDP driver hook:XDP程序的接入点,当数据包从硬件中接收到时会被执行
eBPF virtual machine:执行XDP程序的字节码,并且JIT编译到机器码
BPF maps:key/value store,用来在整个XDP系统中做数据交互
eBPF verifier:在程序加载到内核之前静态分析代码,确保代码不会crash或者损坏运行的内核
XDP程序本身是无状态的,每当网卡收到一个packet会触发执行XDP一次
XDP的位置

最显而易见的是,竟然可以在如此低的层面上把数据包丢弃或者回弹回去,如果面临DDoS攻击,采用这种方式的话,数据包就没有必要上升到Netfilter层面再被丢弃了。说白了,XDP允许数据包在进入Linux协议栈之前就能受到判决。这相当于在网卡驱动层面运行了一个eBPF程序,该程序决定数据包何去何从。
GRO
用来做报文分片后的组合
GRO是针对报文接收方向的,是指设备链路层在接收报文处理的时候,将多个小包合并成一个大包一起上送协议栈,减少数据包在协议栈间交互的机制。
打开/关闭GRO:
ethtool -K eth0 gro on/off
GRO需要网卡有NAPI的能力
驱动通过NAPI 收上包来后,判断如果有启用GRO功能,则将包按流的方式先存在 napi --> gro_list 链表里,等NAPI 收完包或GRO链表里的skb超时,或者GRO合并过程中断需要上报协议栈处理时,将对应的gro链表的skb上送协议栈。
CONTRACK
链接跟踪是保存链接状态的一种机制
Linux 为每个通过网络堆栈的数据包,生成一个新的链接记录项。此后,属于此链接的数据包都唯一地被分配给这个链接,并标识链接状态
链接跟踪是防火墙模块的状态监测的基础,同时也是地址转换的前提。
链接跟踪是Netfilter提供的一项基本功能,用户可以为不同状态的链接制定不同的策略
链接跟踪在报文进入Netfilter入口将信息记录在报文上,在出口进行confirm,确认后的链接信息能够影响以后的报文
为什么要保存链接状态?
只应该让主动发起的链接产生的双向报文通过
链接跟踪提供一种缓存方案,当一条链接的第一个数据包经过时查询nat表,链接跟踪把转换方法保存下来,后续报文直接使用这个转换方法就可以
链接跟踪发生在哪里?
OUTPUT and PREROUTING
Connection tracking hooks into high-priority NF_IP_LOCAL_OUT and NF_IP_PRE_ROUTING hooks, in order to see packets before they enter the system
From <http://www.javashuo.com/article/p-wfxxzrhe-en.html>
链接跟踪,在入口记录,在出口确认
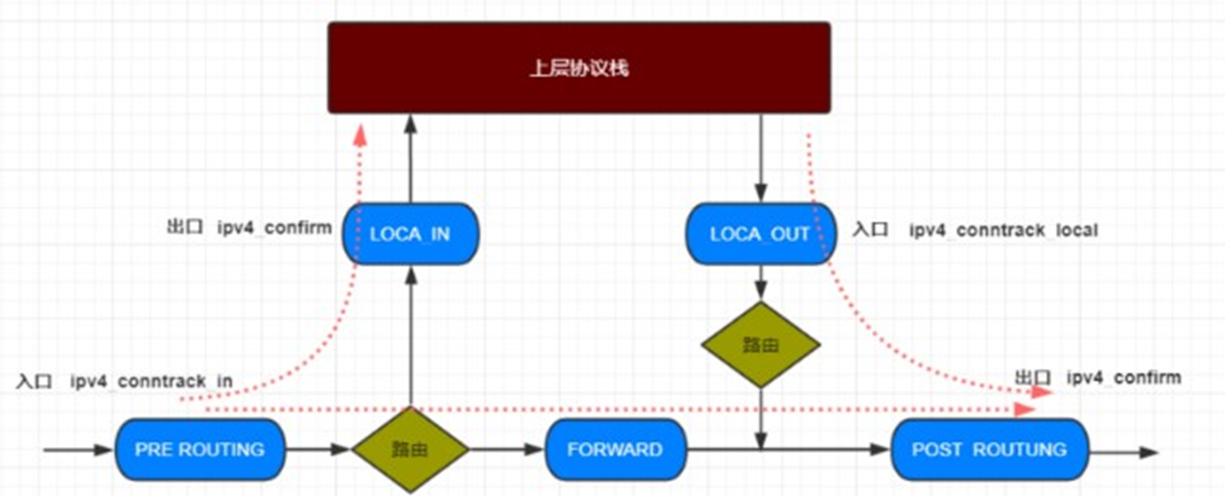
链接跟踪信息是什么?
链接跟踪信息会在入口进行计算,保存在skb上,信息具体包括tuple信息(地址,端口,协议号等),扩展信息及协议的私有信息
Tuple 信息包括收发两个方向,对TCP和UDP来说,是IP加Port;对ICMP来说,是IP加Type和Code,等等
扩展信息比较复杂,略
协议私有信息,如TCP是序号,重传次数,缩放因子等
报文的链接跟踪状态:
IP_CT_ESTABLISHED: 已经创建链接的报文
IP_CT_RELATED: 这个状态的报文所处的链接与 IP_CT_ESTABLISHED状态的链接是有联系的。好比ftp,ftp_data的链接就是ftp-control派生出来的
IP_CT_NEW: 链接的第一个包,通常是TCP的SYN包
IP_CT_ESTABLISHED + IP_CT_IS_REPLY: 回复方向的ESTABLISHED
IP_CT_RELATED + IP_CT_IS_REPLY:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号