Triton 社区首贡献:Bug 修复实录
这个Bug为IR在transform(转换)过程中出现了tt.fp_to_fp,然后在lower(降级)时报错Unsupported conversion from f16 to f16,具体issue在Unsupported conversion from f16 to f16 #6698。这个Bug不难,在Github存在了1个多月让我捡漏了。我记录下我的修复过程,给自己留个纪念,这个Bug也对参与开源项目有一定科普性。

有类似想法给开源社区提PR(Pull request)的可以行动起来,这个难度没想象的那么高。
一、Bug描述
Unsupported conversion from f16 to f16 #6698,这个issue 提供了报错的IR和相关日志,并附上了自己的环境信息。这是一个非常标准的issue,类似问题往往在不主流的环境出现,环境信息也方便别人来复现并修复Bug。Triton截至2025.6已有15.8k star,主流环境没太大问题,Pytorch和vllm等均有Triton依赖。
下面回复说在Turing架构上3.3.0也有问题,但是3.2.0就没问题。然后是两个vllm的关联issue,我要来修复bug的话应该不会拒绝我。
我在一张Tesla T4上也是Turing架构卡上遇到了这个问题,具体为运行03-matrix-multiplication.py 时会报这个错,按照前面说的退回3.2.0又能跑。虽然精度有一点点对不上,这是Torch和Triton的算子实现问题。我租的Ampere架构的A10没有遇到这个问题,所以我大致判断和compute capability有关系,能复现这个Bug就好修。
二、Bug定位
既然我们看到了Bug的报错是Unsupported conversion from,那我们就全局搜索它,找到报错的具体位置。就能找到nvidia/lib/TritonNVIDIAGPUToLLVM/ElementwiseOpToLLVM.cpp:449的llvm::errs() << "Unsupported conversion from " << srcTy << " to ",所以我们从这里查起。另外报错log里还有以下这些信息,直接从ConvertTritonGPUToLLVM正向也能找到。
/home/ubuntu/triton/python/tutorials/03-matrix-multiplication.py:244:0: error: Failures have been detected while processing an MLIR pass pipeline
/home/ubuntu/triton/python/tutorials/03-matrix-multiplication.py:244:0: note: Pipeline failed while executing [`ConvertTritonGPUToLLVM` on 'builtin.module' operation]: reproducer generated at `std::errs, please share the reproducer above with Triton project.`
1、getConversionFunc函数
报错位置在nvidia/lib/TritonNVIDIAGPUToLLVM/ElementwiseOpToLLVM.cpp:449,此函数为getConversionFunc,报错原因是getConversionFunc里定义的srcMap是FP8和其他类型的相互转换,输入却是f16 to f16,Map里没这个key。当然Map里也不可能有这个key,我们继续向上找。
2、createDestOps函数
调用getConversionFunc的函数是createDestOps,调用位置在nvidia/lib/TritonNVIDIAGPUToLLVM/ElementwiseOpToLLVM.cpp:523。以下是调用的相关代码。
bool useFP16IntermediateSrc =
srcElementType.isF32() &&
(!(computeCapability >= 90 &&
(llvm::isa<Float8E4M3FNType, Float8E5M2Type>(srcElementType))) ||
roundingMode.value() == RoundingMode::RTZ);
bool isDstFP32 = dstElementType.isF32();
Type srcType = useFP16IntermediateSrc ? f16_ty : srcElementType;
Type dstType = isDstFP32 ? f16_ty : dstElementType;
auto [cvtFunc, numElements] =
getConversionFunc(srcType, dstType, roundingMode);
输入的类型分别是FP16和FP32,即srcElementType和dstElementType。nvidia/lib/TritonNVIDIAGPUToLLVM/ElementwiseOpToLLVM.cpp:517是4个月前更新的,也是我的怀疑对象。
先看下useFP16IntermediateSrc这个bool表达式,判断输入类型是F32,直接False了,还没判断FP8,所以怀疑失败。因此srcType还是FP16,dstType因为isDstFP32也变成了FP16。所以对getConversionFunc的输入成FP16和FP16,所以转换出错了。
那我们在这个前面就得做掉,即增加以下代码。你能跑过这段程序,看似解决了这个问题,也符合lower语义。
if (srcElementType.isF16() && dstElementType.isF32()) {
SmallVector<Value> outVals;
for (Value v : operands[0]) {
outVals.push_back(
convertFp16ToFp32(loc, rewriter, v));
}
return outVals;
}
以我在llvm/Polygeist的PR 经历来看,想要合并成功需要考虑更上层的设计,需要完全搞清楚他的来龙去脉。所以我们还需要搞清楚这里lower的triton::FpToFpOp是怎么来的,然后说服reviewer。
3、溯源FpToFpOp的创建
存储在TRITON_CACHE_DIR文件夹的层级IR已经满足不了我们的需求,我们需要使用MLIR_ENABLE_DUMP=1环境变量把过程中的MLIR都输出出来。然后搜索tt.fp_to_fp,出现的位置module上面有dump信息// -----// IR Dump Before TritonGPURemoveLayoutConversions (tritongpu-remove-layout-conversions) ('builtin.module' operation) //----- //,代表是跑TritonGPURemoveLayoutConversions前出现的。我们需要找到上一个Pass,即// -----// IR Dump Before TritonGPUAccelerateMatmul (tritongpu-accelerate-matmul) ('builtin.module' operation) //----- //,说明是TritonGPUAccelerateMatmul这个Pass产生了triton::FpToFpOp。
我们需要分析其在怎么产生的,我们可以在lib/Dialect/TritonGPU/Transforms/AccelerateMatmul.cpp 里搜索FpToFpOp,发现仅有lib/Dialect/TritonGPU/Transforms/AccelerateMatmul.cpp:760,事情变得简单了起来,经过GDB调试或print输出可以确定其是在这里创建的。
4、溯源FpToFp为何创建
经过在ConvertTritonGPUToLLVM的查找过程,相信你也明白了,就是要找到函数调用栈。通常GDB能满足你的需求,不过有时候会有Pattern的封装等,你还需要多注意下。创建triton::FpToFpOp的倒序流程为promoteOperand -> decomposeMixedModeDotOp -> runOnOperation,调用路径很短,直接到Pass的入口了。
这里我们走的是FMA case。为何3.2.0就可以,这个版本就失败了呢,这部分代码都是1年前了,没有更新过。我们可以试试找一下是什么的变动导致问题的产生会更清楚些。所以可以切回3.2.0的代码跑下dump,你会发现他确实没创建triton::FpToFpOp。3.2.0执行完该Pass的triton::DotOp是%89 = tt.dot %87, %88, %86, inputPrecision = tf32 : tensor<128x64xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma, kWidth = 2}>> * tensor<64x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma, kWidth = 2}>> -> tensor<128x256xf32, #mma> loc(#loc44),我们的是%86 = tt.dot %84, %85, %arg10, inputPrecision = tf32 : tensor<128x64xf32, #ttg.dot_op<{opIdx = 0, parent = #blocked}>> * tensor<64x256xf32, #ttg.dot_op<{opIdx = 1, parent = #blocked}>> -> tensor<128x256xf32, #blocked> loc(#loc42),我们可以很明显观察到3.2.0上有#mma标记,decomposeMixedModeDotOp中的lib/Dialect/TritonGPU/Transforms/AccelerateMatmul.cpp:773的if (mmaLayout) {也对其做了判断。继续溯源可以发现是lib/Dialect/TritonGPU/Transforms/AccelerateMatmul.cpp:309的if (computeCapability < 80) {对computeCapability < 80弃用 MMA了,但是改完没有验证。
你运行这个Pass会在console得到以下输出
testcase.mlir:5:10: remark: Dot op using MMA for compute capability 75 has been deprecated. It falls back to the FMA path.
%0 = tt.dot %operand0, %operand1, %cst, inputPrecision = tf32 : tensor<128x64xf16, #ttg.dot_op<{opIdx = 0, parent = #blocked}>> * tensor<64x256xf16, #ttg.dot_op<{opIdx = 1, parent = #blocked}>> -> tensor<128x256xf32, #blocked>
4、溯源FpToFp为何错误
问题我们已经知道了,调用promoteOperand也是符合预期的。我们需要确定的是triton::FpToFpOp为何错误,我们先看下Op的定义,如下所示。
def TT_FpToFpOp : TT_Op<"fp_to_fp", [Elementwise,
SameOperandsAndResultShape,
SameOperandsAndResultEncoding,
Pure]> {
let summary = "Floating point casting for custom types";
let description = [{
Floating point casting for custom types (F8), and non-default rounding modes.
F8 <-> FP16, BF16, FP32, FP64
}];
let arguments = (
ins TT_FloatLike:$src,
OptionalAttr<TT_RoundingModeAttr>:$rounding
);
let results = (outs TT_FloatLike:$result);
let assemblyFormat = "$src attr-dict (`,` `rounding` `=` $rounding^)? `:` type($src) `->` type($result)";
let hasVerifier = 1;
let hasFolder = 1;
}
我们可以看到其是对FP8和其他类型的转换,还好没在ConvertTritonGPUToLLVM里改。我们可以顺手再看看triton::FpToFpOp还在什么时候创建,如下所示
# Casting with customized floating types involved: fp8 <=> bf16, fp16, fp32, fp64
# and non-default rounding modes for downcasting
if (src_sca_ty.is_fp8() and dst_sca_ty.is_floating()) or \
(src_sca_ty.is_floating() and dst_sca_ty.is_fp8()) or \
use_custom_rounding:
return self.tensor(
self.builder.create_fp_to_fp(input.handle, dst_ty.to_ir(self.builder), fp_downcast_rounding), dst_ty)
和td描述中的description相同,所以清楚triton::FpToFpOp的定义可能在开始就把这个问题秒杀了。当然怎么产生的这个Bug还是要解释清楚。
三、修复Bug
MMA的时候需要使用triton::FpToFpOp来做转换,FMA需要FP16到FP32的转换。Triton的运算是使用Arith dialect的,arith::ExtFOp就是对较低精度的浮点数执行扩展,会得到更高精度的结果。当然你可以写以下例子然后看IR确认,你会看到%10 = arith.extf %9 : tensor<256xf16, #blocked> to tensor<256xf32, #blocked> loc(#loc9)。
@triton.jit
def fp16_to_fp32_kernel(
input_ptr, output_ptr,
n_elements,
BLOCK_SIZE: tl.constexpr
):
pid = tl.program_id(0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
fp16_vals = tl.load(input_ptr + offsets, mask=mask)
fp32_vals = fp16_vals.cast(tl.float32)
tl.store(output_ptr + offsets, fp32_vals, mask=mask)
所以修复方案为判断operand的类型,于是我得到以下的修改。
Type operandElType =
cast<RankedTensorType>(operand.getType()).getElementType();
if (llvm::isa<Float8E5M2Type, Float8E4M3FNType>(operandElType)) {
return builder.create<FpToFpOp>(loc, tensorPromotedType, operand);Add commentMore actions
}
return builder.create<arith::ExtFOp>(loc, tensorPromotedType, operand);
四、提交 PR
我将分支命名为fix-tl.dot-before-ampere,并写下以下commit注释,然后push到自己仓库
[BACKEND] Fix promoteOperand behavior in AccelerateMatmul for SM < 80
Dot op using MMA for compute capability < 80 has been deprecated.
It falls back to the FMA path. In this path, `promoteOperand` used
`triton::FpToFpOp` unconditionally, which supports `F8 <-> FP16, BF16,
FP32, FP64` conversions.
This change introduces an `ElementType` check in `promoteOperand`: if
the operand’s element type is **not** FP8, it uses `arith::ExtFOp`
instead of `triton::FpToFpOp`.
push到fork项目后,console里会有 https://github.com/sBobHuang/triton/pull/new/fix-tl.dot-before-ampere,项目里会也有一个Compare & pull request的绿色按钮,然后确认contributor declaration等信息无误就可以点击Create pull request的绿色按钮了。等审核就可以了。
ThomasRaoux 光速回复了我,希望我添加一个a lit test,我接触过但是不熟悉。我在示例里学着自己造了一个,不懂的直接问AI就好了,所以还添加了test/TritonGPU/accelerate-matmul.mlir的case
// -----
#blocked = #ttg.blocked<{sizePerThread = [4, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 2], order = [1, 0]}>
module attributes {"ttg.num-ctas" = 1 : i32, "ttg.num-warps" = 8 : i32, ttg.target = "cuda:75", "ttg.threads-per-warp" = 32 : i32} {
// CHECK-LABEL: dot_fall_back_fma_before_ampere
tt.func public @dot_fall_back_fma_before_ampere(%arg0: tensor<128x64xf16, #ttg.dot_op<{opIdx = 0, parent = #blocked}>>, %arg1: tensor<64x256xf16, #ttg.dot_op<{opIdx = 1, parent = #blocked}>>, %arg2: tensor<128x256x!tt.ptr<f32>, #blocked>) {Add commentMore actions
%cst = arith.constant dense<0.000000e+00> : tensor<128x256xf32, #blocked>
// CHECK: %[[EXT0:.*]] = arith.extf %arg0
// CHECK: %[[EXT1:.*]] = arith.extf %arg1
// CHECK: %[[DOT:.*]] = tt.dot %[[EXT0]], %[[EXT1]]
%0 = tt.dot %arg0, %arg1, %cst, inputPrecision = tf32 : tensor<128x64xf16, #ttg.dot_op<{opIdx = 0, parent = #blocked}>> * tensor<64x256xf16, #ttg.dot_op<{opIdx = 1, parent = #blocked}>> -> tensor<128x256xf32, #blocked>
// CHECK: tt.store %arg2, %[[DOT]]
tt.store %arg2, %0 : tensor<128x256x!tt.ptr<f32>, #blocked>
tt.return
}
}
之后peterbell10在review时建议使用isFloat8来判断FP8,这个全局搜索下就知道在#include "triton/Conversion/MLIRTypes.h",所以我合入的最终修改为commit 9ca271d
五、代码合入
ThomasRaoux以LGTM结束approved了我的修改,随后peterbell10哥merge了到了main分支。

然后commit c80eef1就在triton-lang:main了,我的代码进入了主线,你clone Triton项目就会看到我的代码。
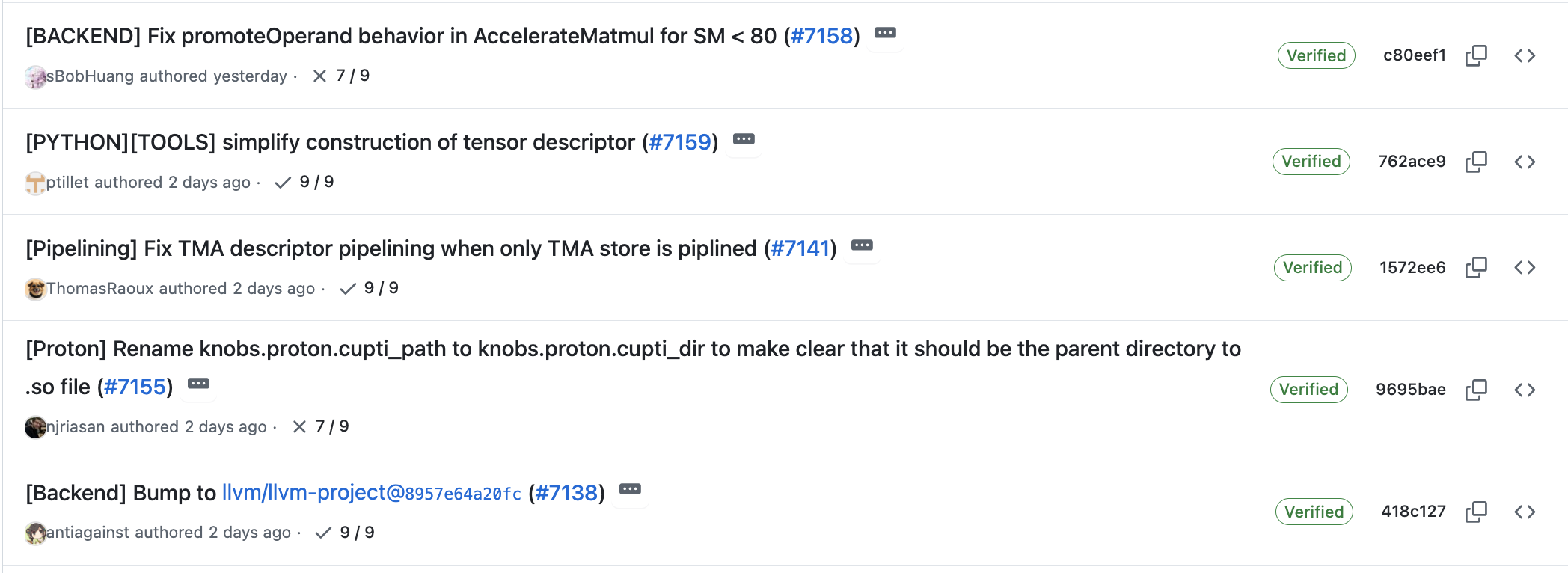
这是个Bug,但是影响的人不多,会在下一个版本3.4.0修复。所以Unsupported conversion from f16 to f16 #6698还没close。
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/18926405

 浙公网安备 33010602011771号
浙公网安备 33010602011771号