LeetGPU入门教程 (CUDA guide最佳实践)
5.20更 终于搞定了Triton的tma kernel,当时还怀疑是卡坏了,自己没好好读文档的问题。建立了LeetGPU Github仓库,看代码更方便。
本博客原文地址:https://www.cnblogs.com/BobHuang/p/18755313,原文体验更佳
工作中写过一点点算子,现在来刷刷OJ https://leetgpu.com/challenges,其实就是leetcode for GPU。
目前平台有28道题,支持CUDA,Pytorch和Triton共3种写算子的框架。订阅是5美刀/月,不订阅看不到运行时间和百分比排位,目前还看不到Nsight Compute的性能分析,但是我已充值。评测卡有Hopper架构的H100,Ampere架构的A100和Turing架构的Tesla T4。
我这里较为深入得探讨4题,剩下的你可以尝试下,诚然Triton是最好写且性能过得去的。
一、Vector Addition
OJ入门均是a+b,GPU 中就是向量C=向量A + 向量B,以下是为我们提供的示例代码。
#include "solve.h"
#include <cuda_runtime.h>
__global__ void vector_add(const float* A, const float* B, float* C, int N) {
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
void solve(const float* A, const float* B, float* C, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vector_add<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
cudaDeviceSynchronize();
}
2025.3项目刚上线是有cudaMalloc、cudaMemcpy、cudaFree等API的,目前已简化成申请好的指针。示例代码里计算了threadsPerBlock表示每个block分配的线程数量,blocksPerGrid计算了需要多少个block,由于是除法进行了向上取整,有一些线程是空转的。当然还可以指定shared memory大小和stream,完整的<<< ... >>>即启动(launch)kernel 函数为<<<gridDim, blockDim, sharedMemBytes, stream>>>。CUDA guide 也对此进行了细致的讲解。
我们只需要补充cuda kernel函数,计算出全局索引,全局索引有block维度的编号,也有thread维度的编号,乘加得到当前线程的ID,不超过N的数组大小不越界后相加即可。
__global__ void vector_add(const float* A, const float* B, float* C, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N) {
C[i] = A[i] + B[i];
}
}
那我们能不能修改下threadsPerBlock的大小呢,比如1024呢,当然可以。当然也可以改为128、64、32等这样的数字,但是改为2048就会Failed,因为对blcok内线程的限制为1024。以下我搞的目前评测用的Tesla T4的./deviceQuery信息。
点击展开代码
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 12.8 / 12.4
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 14914 MBytes (15638134784 bytes)
(040) Multiprocessors, (064) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 5001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
关于performance的信息,使用信用卡 5美刀/月 订阅后就可以看到。,默认的Block内线程数256,可以获得71.2th percentile,也就是超过了71.2%的人水平,我们尝试用满即修改为1024达到了16.5th percentile,修改为512可以得到46.8th percentile,修改为128可以获得83.5th percentile,这个数据范围内128确实比较优,所以有些时候会对threadsPerBlock进行autotune自动调优。
Failed的时候可以看到输出的数据,所以我们可以把N给hack出来,是10000=625*16,设置625和16就可以省掉条件判断,但是我们会发现其并不会变快,因为我们不能精细得控制线程调度到指定物理线程,具体见CUDA 如何调度 kernel 到指定的 SM?。2025.4 更 数据加强了,现在会直接Failed。
Pytorch算子写起来就很简单了,就是a+b,题目描述中有dentical lengths,但是Pytorch帮我们处理好了一切,一行秒杀。
import torch
# A, B, C are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, C: torch.Tensor, N: int):
torch.add(A, B, out=C)
Triton的话和CUDA类似,不需要考虑block内,Triton按照block整块处理。参考代码给出了Grid信息,grid = (triton.cdiv(N, BLOCK_SIZE),) 是CUDA编程中blocksPerGrid,BLOCK_SIZE = 1024是CUDA编程中的threadsPerBlock。
# a_ptr, b_ptr, c_ptr are raw device pointers
def solve(a_ptr: int, b_ptr: int, c_ptr: int, N: int):
BLOCK_SIZE = 1024
grid = (triton.cdiv(N, BLOCK_SIZE),)
vector_add_kernel[grid](a_ptr, b_ptr, c_ptr, N, BLOCK_SIZE)
作者以前写过一篇浅析 Triton 执行流程,有兴趣可以看看。Triton kernel基本也呼之欲出了,按照整块处理并mask即可。
@triton.jit
def vector_add_kernel(a_ptr, b_ptr, c_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
# 有多个“程序”在处理不同的数据。我们在这里确定我们是哪个程序:
pid = tl.program_id(axis=0) # 我们以1D网格启动 所以 axis 是 0.
# 该程序将处理从初始数据偏移的输入。
# 例如,如果你有一个长度为4096且块大小为1024的向量,程序 将分别访问元素 [0:1024), [1024:2048), [2048:3072), [3072:4096)。
block_start = pid * BLOCK_SIZE
# 注意,offsets 是一个指针列表
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# 创建一个掩码以防止内存越界访问
mask = offsets < n_elements
# 从 DRAM 加载 a 和 b,mask用来解决输入不是块大小的倍数而多余的元素
a = tl.load(a_ptr + offsets, mask=mask)
b = tl.load(b_ptr + offsets, mask=mask)
c = a + b
# 将 a + b 写回 DRAM
tl.store(c_ptr + offsets, c, mask=mask)
Triton同样BLOCK_SIZE = 128最优,可以超过98.2%的人,CUDA不使用技巧的最快时间为1.14817 ms,Pytorch为2.0441 ms,Triton为1.19467 ms。人生苦短,我选Triton, all in Triton。
二、matrix-multiplication
这个是C=A*B,矩阵A是M*N,矩阵B是N*K, 得到的矩阵C是M*K,C[m][k]的值将由A的一行A[m][i]和对应的B的一列B[i][k]相乘得到,在KMN的循环顺序下我们串行的代码是这样的。
void matmul(const float* A, const float* B, float* C, int M, int N, int K) {
memset(C, 0, M * K * sizeof(float));
for (int col = 0; col < K; col++) {
for (int row = 0; row < M; row++) {
for (int i = 0; i < N; i++) {
C[row * K + col] += A[row * N + i] * B[i * K + col];
}
}
}
}
矩阵乘launch也麻烦点,是二维的。以下代码中dim3 threadsPerBlock (16, 16)声明每个线程块包含 16x16=256 个线程,这个二维block有利于全局内存合并访问,规整的线程组可以减少Warp Divergence。blocksPerGrid则分别进行了X方向和Y方向的网格维度,进行了向上取整。
// Calculate grid and block dimensions
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((K + threadsPerBlock.x - 1) / threadsPerBlock.x,
(M + threadsPerBlock.y - 1) / threadsPerBlock.y);
如果是(3,2)的Grid,(4,3)的Block可以用下图表示
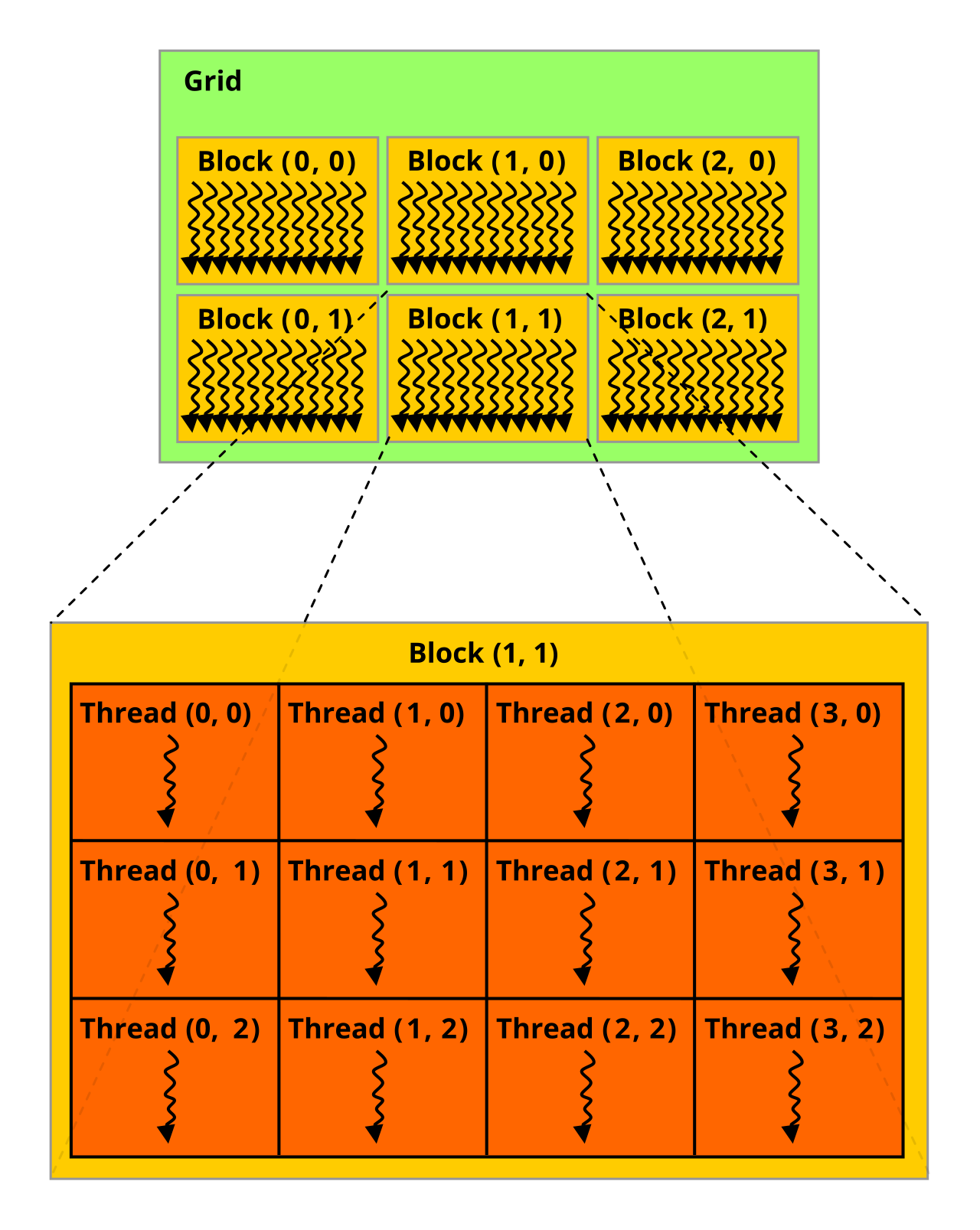
以上用的是K和M,也就是我们用X维度可以求出col,在Y维度可以求出row,是这样的代码
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
在数据范围内我们做累加就好了,我们可以用中间变量去保存这个结果,最终代码为
__global__ void matrix_multiplication_kernel(const float* A, const float* B, float* C, int M, int N, int K) {
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
if (row < M && col < K) {
float sum = 0.0f;
for (int i = 0; i < N; i++) {
sum += A[row * N + i] * B[i * K + col];
}
C[row * K + col] = sum;
}
}
row和col能不能反一下呢,逻辑上当然是可以的,代码如下所示
#include "solve.h"
#include <cuda_runtime.h>
__global__ void matrix_multiplication_kernel(const float* A, const float* B, float* C, int M, int N, int K) {
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
if (row < M && col < K) {
float sum = 0.0f;
for (int i = 0; i < N; i++) {
sum += A[row * N + i] * B[i * K + col];
}
C[row * K + col] = sum;
}
}
// A, B, C are device pointers (i.e. pointers to memory on the GPU)
void solve(const float* A, const float* B, float* C, int M, int N, int K) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((M + threadsPerBlock.x - 1) / threadsPerBlock.x,
(K + threadsPerBlock.y - 1) / threadsPerBlock.y);
matrix_multiplication_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);
cudaDeviceSynchronize();
}
以上代码提交我们将会获得Speed Test timed out after 25 seconds,矩阵 B 的访问 B[i * K + col] 中,col 由 blockIdx.y 控制,相邻线程(threadIdx.x 连续)访问 B 的不同行,导致非合并访问,因此速度恨慢,若想使用此种方法需要使用转置后的矩阵进行相乘。
Pytorch依旧是直接秒杀,图一乐。
import torch
# A, B, C are tensors on the GPU
def solve(A: torch.Tensor, B: torch.Tensor, C: torch.Tensor, M: int, N: int, K: int):
torch.matmul(A, B , out = C)
Triton我们可以按照CUDA逻辑先写下,2D的Grid启动,累加到N的循环,通过了。交换M、K还可以更快。限制少了很多,Triton 帮你做了。
# The use of PyTorch in Triton programs is not allowed for the purposes of fair benchmarking.
import triton
import triton.language as tl
@triton.jit
def matrix_multiplication_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_K: tl.constexpr
):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
pid_k = tl.program_id(axis=0)
pid_m = tl.program_id(axis=1)
offs_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_k = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
# 初始化A和B的指针
a_ptrs = a_ptr + offs_m[:, None] * stride_am
b_ptrs = b_ptr + offs_k[None, :] * stride_bk
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_K), dtype=tl.float32)
# 沿N维度依次累加
for n in range(N):
# 加载A和B的当前块,并应用边界检查
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
accumulator += a * b
a_ptrs += stride_an
b_ptrs += stride_bn
# 将结果写回C
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_k[None, :] * stride_ck
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_ck = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
c_mask = (offs_cm[:, None] < M) & (offs_ck[None, :] < K)
tl.store(c_ptrs, accumulator, mask=c_mask)
# a_ptr, b_ptr, c_ptr are raw device pointers
def solve(a_ptr: int, b_ptr: int, c_ptr: int, M: int, N: int, K: int):
stride_am, stride_an = N, 1
stride_bn, stride_bk = K, 1
stride_cm, stride_ck = K, 1
grid = lambda META: (triton.cdiv(K, META['BLOCK_SIZE_K']), triton.cdiv(M, META['BLOCK_SIZE_M']), )
matrix_multiplication_kernel[grid](
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M=16,
BLOCK_SIZE_K=16,
)
tl.dot是向量乘,可以转换为mmaMatrix Multiply Accumulate指令来调用Tensor Core,Tesla T4由于架构太旧只能生成fma乘加指令。tl.dot做向量乘是有限制的,需要M >= 16, N >= 16 and K >= 16,也就是最小的块必须都大于16。所以我们把N也切掉,再加上BLOCK_SIZE_N,变成分块的矩阵乘法,代码如下所示。
# The use of PyTorch in Triton programs is not allowed for the purposes of fair benchmarking.
import triton
import triton.language as tl
@triton.jit
def matrix_multiplication_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, BLOCK_SIZE_N: tl.constexpr
):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
pid_m = tl.program_id(axis=0)
pid_k = tl.program_id(axis=1)
offs_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_k = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
offs_n = tl.arange(0, BLOCK_SIZE_N)
# 初始化A和B的指针
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_n[None, :] * stride_an
b_ptrs = b_ptr + offs_n[:, None] * stride_bn + offs_k[None, :] * stride_bk
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_K), dtype=tl.float32)
# 沿N维度依次累加
for n in range(0, tl.cdiv(N, BLOCK_SIZE_N)):
# 加载A和B的当前块,并应用边界检查
a = tl.load(a_ptrs, mask=offs_n[None, :] < N - n * BLOCK_SIZE_N, other=0.0)
b = tl.load(b_ptrs, mask=offs_n[:, None] < N - n * BLOCK_SIZE_N, other=0.0)
# 计算矩阵乘法并累加
accumulator = tl.dot(a, b, accumulator, input_precision="ieee")
a_ptrs += BLOCK_SIZE_N * stride_an
b_ptrs += BLOCK_SIZE_N * stride_bn
# 将结果写回C
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_k[None, :] * stride_ck
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_ck = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
c_mask = (offs_cm[:, None] < M) & (offs_ck[None, :] < K)
tl.store(c_ptrs, accumulator, mask=c_mask)
# a_ptr, b_ptr, c_ptr are raw device pointers
def solve(a_ptr: int, b_ptr: int, c_ptr: int, M: int, N: int, K: int):
stride_am, stride_an = N, 1
stride_bn, stride_bk = K, 1
stride_cm, stride_ck = K, 1
grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']), triton.cdiv(K, META['BLOCK_SIZE_K']))
matrix_multiplication_kernel[grid](
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M=16,
BLOCK_SIZE_K=16,
BLOCK_SIZE_N=16
)
切的块变大的话提升很多,比如切分均为64,直接到了前33%。官方tutorials是利用L2 cache的,其实就是做了一下Group,性能又提升不少
# The use of PyTorch in Triton programs is not allowed for the purposes of fair benchmarking.
import triton
import triton.language as tl
@triton.jit
def matrix_multiplication_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, BLOCK_SIZE_N: tl.constexpr,
GROUP_SIZE_M: tl.constexpr
):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_k = tl.cdiv(K, BLOCK_SIZE_K)
num_pid_in_group = GROUP_SIZE_M * num_pid_k
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
pid_k = (pid % num_pid_in_group) // group_size_m
offs_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_k = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
offs_n = tl.arange(0, BLOCK_SIZE_N)
# 初始化A和B的指针
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_n[None, :] * stride_an
b_ptrs = b_ptr + offs_n[:, None] * stride_bn + offs_k[None, :] * stride_bk
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_K), dtype=tl.float32)
# 沿N维度依次累加
for n in range(0, tl.cdiv(N, BLOCK_SIZE_N)):
# 加载A和B的当前块,并应用边界检查
a = tl.load(a_ptrs, mask=offs_n[None, :] < N - n * BLOCK_SIZE_N, other=0.0)
b = tl.load(b_ptrs, mask=offs_n[:, None] < N - n * BLOCK_SIZE_N, other=0.0)
# 计算矩阵乘法并累加
accumulator = tl.dot(a, b, accumulator, input_precision="ieee")
a_ptrs += BLOCK_SIZE_N * stride_an
b_ptrs += BLOCK_SIZE_N * stride_bn
# 将结果写回C
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_k[None, :] * stride_ck
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_ck = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
c_mask = (offs_cm[:, None] < M) & (offs_ck[None, :] < K)
tl.store(c_ptrs, accumulator, mask=c_mask)
# a_ptr, b_ptr, c_ptr are raw device pointers
def solve(a_ptr: int, b_ptr: int, c_ptr: int, M: int, N: int, K: int):
stride_am, stride_an = N, 1
stride_bn, stride_bk = K, 1
stride_cm, stride_ck = K, 1
grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(K, META['BLOCK_SIZE_K']), )
matrix_multiplication_kernel[grid](
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M=64,
BLOCK_SIZE_K=64,
BLOCK_SIZE_N=64,
GROUP_SIZE_M=8
)
CUDA里使用Tensor core需要使用WMMA API,会比较繁琐,Triton里就会简单些。当然CUTLASS就要友好地多,大力支持CUTLASS,未来LeetGPU也将支持CUTLASS。目前Triton的版本是3.2.0,在release/3.2.x分支,当前commit id是9641643da6c52000c807b5eeed05edaec4402a67。以下代码是根据SM(stream multi-processor)数做的持久化线程块,SM是Tensor Core的最小单元。
import triton
import triton.language as tl
@triton.jit
def _compute_pid(tile_id, num_pid_in_group, num_pid_m, GROUP_SIZE_M):
group_id = tile_id // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (tile_id % group_size_m)
pid_k = (tile_id % num_pid_in_group) // group_size_m
return pid_m, pid_k
@triton.jit
def matmul_kernel_persistent(a_ptr, b_ptr, c_ptr, #
M, N, K, #
stride_am, stride_an, #
stride_bn, stride_bk, #
stride_cm, stride_ck, #
BLOCK_SIZE_M: tl.constexpr, #
BLOCK_SIZE_K: tl.constexpr, #
BLOCK_SIZE_N: tl.constexpr, #
GROUP_SIZE_M: tl.constexpr, #
NUM_SMS: tl.constexpr, #
):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
start_pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_k = tl.cdiv(K, BLOCK_SIZE_K)
n_tiles = tl.cdiv(N, BLOCK_SIZE_N)
num_tiles = num_pid_m * num_pid_k
# NOTE: There is currently a bug in blackwell pipelining that means it can't handle a value being
# used in both the prologue and epilogue, so we duplicate the counters as a work-around.
tile_id_c = start_pid - NUM_SMS
offs_n_for_mask = tl.arange(0, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_k
for tile_id in tl.range(start_pid, num_tiles, NUM_SMS):
pid_m, pid_k = _compute_pid(tile_id, num_pid_in_group, num_pid_m, GROUP_SIZE_M)
start_m = pid_m * BLOCK_SIZE_M
start_k = pid_k * BLOCK_SIZE_K
offs_am = start_m + tl.arange(0, BLOCK_SIZE_M)
offs_bk = start_k + tl.arange(0, BLOCK_SIZE_K)
offs_am = tl.where(offs_am < M, offs_am, 0)
offs_bk = tl.where(offs_bk < K, offs_bk, 0)
offs_am = tl.max_contiguous(tl.multiple_of(offs_am, BLOCK_SIZE_M), BLOCK_SIZE_M)
offs_bk = tl.max_contiguous(tl.multiple_of(offs_bk, BLOCK_SIZE_K), BLOCK_SIZE_K)
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_K), dtype=tl.float32)
for ni in range(n_tiles):
offs_k = ni * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_an)
b_ptrs = b_ptr + (offs_k[:, None] * stride_bn + offs_bk[None, :] * stride_bk)
a = tl.load(a_ptrs, mask=offs_n_for_mask[None, :] < N - ni * BLOCK_SIZE_N, other=0.0)
b = tl.load(b_ptrs, mask=offs_n_for_mask[:, None] < N - ni * BLOCK_SIZE_N, other=0.0)
accumulator = tl.dot(a, b, accumulator, input_precision="ieee")
tile_id_c += NUM_SMS
pid_m, pid_k = _compute_pid(tile_id_c, num_pid_in_group, num_pid_m, GROUP_SIZE_M)
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_ck = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_ck * offs_ck[None, :]
c_mask = (offs_cm[:, None] < M) & (offs_ck[None, :] < K)
c = accumulator.to(tl.float32)
tl.store(c_ptrs, c, mask=c_mask)
# a_ptr, b_ptr, c_ptr are raw device pointers
def solve(a_ptr: int, b_ptr: int, c_ptr: int, M: int, N: int, K: int):
stride_am, stride_an = N, 1
stride_bn, stride_bk = K, 1
stride_cm, stride_ck = K, 1
# 查询资料可得,torch API 不让用,正常使用torch.cuda.get_device_properties("cuda").multi_processor_count
NUM_SMS = 40
# 1D launch kernel where each block gets its own program.
grid = lambda META: (min(NUM_SMS, triton.cdiv(M, META["BLOCK_SIZE_M"]) * triton.cdiv(K, META["BLOCK_SIZE_K"])), )
kernel = matmul_kernel_persistent[grid](
a_ptr, b_ptr, c_ptr, #
M, N, K, #
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M=64,
BLOCK_SIZE_K=64,
BLOCK_SIZE_N=64,
GROUP_SIZE_M=8,
NUM_SMS=NUM_SMS, #
)
Hopper 架构已经引入TMA Tensor,你还可以试试H100的Kernel编写,这个我在学习。目前平台Triton的版本是3.2.0,3.3.0变化还是挺大的,感恩,已经更新。
5.20更 5.8尝试了一早上,都没看文档的Leading dimensions must be multiples of 16-byte strides,python/triton/language/core.py:2042拷打下自己。我们的数据类型是float32,所以在M,N,K均是4的倍数就可以使用tma,仅提供个参考
# The use of PyTorch in Triton programs is not allowed for the purposes of fair benchmarking.
import triton
import triton.language as tl
@triton.jit
def matrix_multiplication_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_an,
stride_bn, stride_bk,
stride_cm, stride_ck,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, BLOCK_SIZE_N: tl.constexpr,
GROUP_SIZE_M: tl.constexpr
):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_k = tl.cdiv(K, BLOCK_SIZE_K)
num_pid_in_group = GROUP_SIZE_M * num_pid_k
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
pid_k = (pid % num_pid_in_group) // group_size_m
offs_m = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_k = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
offs_n = tl.arange(0, BLOCK_SIZE_N)
# 初始化A和B的指针
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_n[None, :] * stride_an
b_ptrs = b_ptr + offs_n[:, None] * stride_bn + offs_k[None, :] * stride_bk
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_K), dtype=tl.float32)
# 沿N维度依次累加
for n in range(0, tl.cdiv(N, BLOCK_SIZE_N)):
# 加载A和B的当前块,并应用边界检查
a = tl.load(a_ptrs, mask=offs_n[None, :] < N - n * BLOCK_SIZE_N, other=0.0)
b = tl.load(b_ptrs, mask=offs_n[:, None] < N - n * BLOCK_SIZE_N, other=0.0)
# 计算矩阵乘法并累加
accumulator = tl.dot(a, b, accumulator, input_precision="ieee")
a_ptrs += BLOCK_SIZE_N * stride_an
b_ptrs += BLOCK_SIZE_N * stride_bn
# 将结果写回C
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_k[None, :] * stride_ck
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_ck = pid_k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
c_mask = (offs_cm[:, None] < M) & (offs_ck[None, :] < K)
tl.store(c_ptrs, accumulator, mask=c_mask)
@triton.jit
def matmul_kernel_make_tensor_desciptor(a_ptr, b_ptr, c_ptr, #
M, N, K, #
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr, #
):
a_ptr = a_ptr.to(tl.pointer_type(tl.float32))
b_ptr = b_ptr.to(tl.pointer_type(tl.float32))
c_ptr = c_ptr.to(tl.pointer_type(tl.float32))
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
pid_m = pid % num_pid_m
pid_n = pid // num_pid_m
offs_am = pid_m * BLOCK_SIZE_M
offs_bn = pid_n * BLOCK_SIZE_N
offs_k = 0
a_desc = tl._experimental_make_tensor_descriptor(
a_ptr,
shape=[M, K],
strides=[K, 1],
block_shape=[BLOCK_SIZE_M, BLOCK_SIZE_K],
)
b_desc = tl._experimental_make_tensor_descriptor(
b_ptr,
shape=[K, N],
strides=[N, 1],
block_shape=[BLOCK_SIZE_K, BLOCK_SIZE_N],
)
c_desc = tl._experimental_make_tensor_descriptor(
c_ptr,
shape=[M, N],
strides=[N, 1],
block_shape=[BLOCK_SIZE_M, BLOCK_SIZE_N],
)
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
a = a_desc.load([offs_am, offs_k])
# tl.device_print("a: ", a)
b = b_desc.load([offs_k, offs_bn])
accumulator = tl.dot(a, b, acc=accumulator, input_precision="ieee")
offs_k += BLOCK_SIZE_K
accumulator = accumulator.to(a_desc.dtype)
c_desc.store([offs_am, offs_bn], accumulator)
# a_ptr, b_ptr, c_ptr are raw device pointers
def solve(a_ptr: int, b_ptr: int, c_ptr: int, M: int, N: int, K: int):
grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(K, META['BLOCK_SIZE_K']), )
# Leading dimensions must be multiples of 16-byte strides
if M % 4 == 0 and N % 4 == 0 and K % 4 == 0:
import ctypes
cudart = ctypes.CDLL("libcudart.so")
cudart.cudaMalloc.argtypes = [ctypes.POINTER(ctypes.c_void_p), ctypes.c_size_t]
cudart.cudaMalloc.restype = ctypes.c_int
from typing import Optional
# TMA descriptors require a global memory allocation
def alloc_fn(size: int, alignment: int, stream: Optional[int]):
ptr = ctypes.c_void_p()
err = cudart.cudaMalloc(ctypes.byref(ptr), size)
if err != 0:
raise RuntimeError(f"cudaMalloc failed, code {err}")
return ptr.value
triton.set_allocator(alloc_fn)
matmul_kernel_make_tensor_desciptor[grid](
a_ptr, b_ptr, c_ptr,
M, K, N,
BLOCK_SIZE_M=32,
BLOCK_SIZE_K=32,
BLOCK_SIZE_N=32,
)
else:
matrix_multiplication_kernel[grid](
a_ptr, b_ptr, c_ptr,
M, N, K,
N, 1,
K, 1,
K, 1,
BLOCK_SIZE_M=64,
BLOCK_SIZE_K=64,
BLOCK_SIZE_N=64,
GROUP_SIZE_M=8
)
三、Matrix Transpose
矩阵转置和矩阵乘法这个很像,naive的方法就是转换索引
#include <cuda_runtime.h>
__global__ void matrix_transpose_kernel(const float* input, float* output, int rows, int cols) {
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
if (col < cols && row < rows) {
output[col * rows + row] = input[row * cols + col];
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
extern "C" void solve(const float* input, float* output, int rows, int cols) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((cols + threadsPerBlock.x - 1) / threadsPerBlock.x,
(rows + threadsPerBlock.y - 1) / threadsPerBlock.y);
matrix_transpose_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, rows, cols);
cudaDeviceSynchronize();
}
我们可以利用共享内存,padding 解决 bank conflict等等优化得到个性能好的,具体可以参考 PeakCrosser [CUDA 学习笔记] 矩阵转置算子优化
#include "solve.h"
#include <cuda_runtime.h>
template <int BLOCK_SZ, int NUM_PER_THREAD>
__global__ void mat_transpose_kernel_v3(const float* idata, float* odata, int M, int N) {
const int bx = blockIdx.x, by = blockIdx.y;
const int tx = threadIdx.x, ty = threadIdx.y;
__shared__ float sdata[BLOCK_SZ][BLOCK_SZ+1];
int x = bx * BLOCK_SZ + tx;
int y = by * BLOCK_SZ + ty;
constexpr int ROW_STRIDE = BLOCK_SZ / NUM_PER_THREAD;
if (x < N) {
#pragma unroll
for (int y_off = 0; y_off < BLOCK_SZ; y_off += ROW_STRIDE) {
if (y + y_off < M) {
sdata[ty + y_off][tx] = idata[(y + y_off) * N + x];
}
}
}
__syncthreads();
x = by * BLOCK_SZ + tx;
y = bx * BLOCK_SZ + ty;
if (x < M) {
for (int y_off = 0; y_off < BLOCK_SZ; y_off += ROW_STRIDE) {
if (y + y_off < N) {
odata[(y + y_off) * M + x] = sdata[tx][ty + y_off];
}
}
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
void solve(const float* input, float* output, int rows, int cols) {
constexpr int BLOCK_SZ = 32;
constexpr int NUM_PER_THREAD = 4;
dim3 block(BLOCK_SZ, BLOCK_SZ/NUM_PER_THREAD);
dim3 grid((cols+ BLOCK_SZ-1)/BLOCK_SZ, (rows+BLOCK_SZ-1)/BLOCK_SZ);
mat_transpose_kernel_v3<BLOCK_SZ, NUM_PER_THREAD><<<grid, block>>>(input, output, rows, cols);
cudaDeviceSynchronize();
}
Pytorch 要做的就是一行秒杀
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, rows: int, cols: int):
output.copy_(torch.transpose(input, 0, 1))
Triton 考虑的就不多了,tl.trans会帮我们做掉
# The use of PyTorch in Triton programs is not allowed for the purposes of fair benchmarking.
import triton
import triton.language as tl
@triton.jit
def matrix_transpose_kernel(
input_ptr, output_ptr,
M, N,
stride_ir, stride_ic,
stride_or, stride_oc,
BLOCK_SIZE : tl.constexpr
):
input_ptr = input_ptr.to(tl.pointer_type(tl.float32))
output_ptr = output_ptr.to(tl.pointer_type(tl.float32))
# -----------------------------------------------------------
# 1. 确定当前线程块负责的输入分块坐标
# -----------------------------------------------------------
pid_m = tl.program_id(0) # 分块在 M 方向的索引
pid_n = tl.program_id(1) # 分块在 N 方向的索引
# -----------------------------------------------------------
# 2. 计算分块内每个元素的位置偏移
# -----------------------------------------------------------
offs_m = pid_m * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
offs_n = pid_n * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
# -----------------------------------------------------------
# 3. 定义输入分块的全局内存指针(行优先)
# -----------------------------------------------------------
input_ptrs = input_ptr + offs_m[:, None] * stride_ir + offs_n[None, :] * stride_ic
# -----------------------------------------------------------
# 4. 从全局内存加载输入分块(带边界检查)
# -----------------------------------------------------------
mask = (offs_m[:, None] < M) & (offs_n[None, :] < N)
block = tl.load(input_ptrs, mask=mask, other=0)
# -----------------------------------------------------------
# 5. 转置分块(交换行列)
# -----------------------------------------------------------
transposed_block = tl.trans(block) # Triton 内置转置函数
# -----------------------------------------------------------
# 6. 计算输出分块的全局内存指针(列优先)
# -----------------------------------------------------------
output_ptrs = output_ptr + offs_n[:, None] * M + offs_m[None, :] # 注意 M 是转置后的行步长
# -----------------------------------------------------------
# 7. 将转置后的分块写入全局内存
# -----------------------------------------------------------
tl.store(output_ptrs, transposed_block, mask=mask.T) # mask 也需要转置
# input_ptr, output_ptr are raw device pointers
def solve(input_ptr: int, output_ptr: int, rows: int, cols: int):
stride_ir, stride_ic = cols, 1
stride_or, stride_oc = rows, 1
grid = lambda META: (triton.cdiv(rows, META['BLOCK_SIZE']), triton.cdiv(cols, META['BLOCK_SIZE']))
matrix_transpose_kernel[grid](
input_ptr, output_ptr,
rows, cols,
stride_ir, stride_ic,
stride_or, stride_oc,
BLOCK_SIZE=32
)
四、softmax
softmax就比较麻烦了,所用公式为\(\sigma(\mathbf{z})_i \;=\; \frac{\exp\bigl(z_i - \max_k z_k\bigr)} {\displaystyle\sum_{j=1}^{K} \exp\bigl(z_j - \max_k z_k\bigr)}\),想要性能过得去得用原子指令求最大值,写个块内reduce 规约操作。
__global__ void softmax_kernel(const float* input, float* output, int N) {
extern __shared__ float shared_mem[]; // 动态共享内存用于归约
float* max_shared = shared_mem;
float* sum_shared = &shared_mem[blockDim.x];
int tid = threadIdx.x;
// 阶段1: 计算最大值
float local_max = -FLT_MAX;
for (int i = tid; i < N; i += blockDim.x) {
local_max = fmaxf(local_max, input[i]);
}
max_shared[tid] = local_max;
__syncthreads();
// 块内归约求最大值
for (int s = blockDim.x/2; s > 0; s >>= 1) {
if (tid < s) {
max_shared[tid] = fmaxf(max_shared[tid], max_shared[tid + s]);
}
__syncthreads();
}
float max_val = max_shared[0];
__syncthreads();
// 阶段2: 计算指数和
float local_sum = 0.0f;
for (int i = tid; i < N; i += blockDim.x) {
local_sum += expf(input[i] - max_val);
}
sum_shared[tid] = local_sum;
__syncthreads();
// 块内归约求和
for (int s = blockDim.x/2; s > 0; s >>= 1) {
if (tid < s) {
sum_shared[tid] += sum_shared[tid + s];
}
__syncthreads();
}
float sum_exp = sum_shared[0];
__syncthreads();
// 阶段3: 计算最终结果
for (int i = tid; i < N; i += blockDim.x) {
output[i] = expf(input[i] - max_val) / sum_exp;
}
}
// input, output are device pointers (i.e. pointers to memory on the GPU)
void solve(const float* input, float* output, int N) {
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
size_t sharedSize = 2 * threadsPerBlock * sizeof(float);
softmax_kernel<<<blocksPerGrid, threadsPerBlock, sharedSize>>>(input, output, N);
cudaDeviceSynchronize();
}
Pytorch 要做的就是一行秒杀
import torch
# input, output are tensors on the GPU
def solve(input: torch.Tensor, output: torch.Tensor, N: int):
torch.softmax(input, 0, out=output)
这是一个比较重要的算子,Triton tutorials也有示例,这个块内规约起来就简单了,但是跨线程块(grid-wide)的规约怎么办。Triton关注块内,让我们看看tutorials/02-fused-softmax.py 是怎么做的,首先他是一个在线的方式,先编译了kernel拿到了kernel.metadata.shared, 那这个shared memory会不会不够用呢。计算出了一个更小的tl.num_programs(0) 作为 循环的 step。BLOCK_SIZE是大于等于n_cols的最小2的幂,那我们N这么大。
可以写3个kernel,先做max的局部规约和全局归约,再做sum的局部规约和全局规约,最后再归一化 softmax 输出。但是不能通过题目,因为用torch申请新的空间了,triton mode下禁止使用torch。
5.7更 使用ctypes.CDLL("libcudart.so")来cudaMalloc,无敌了
import triton
import triton.language as tl
@triton.jit
def partial_max_value_kernel(X, partial_max, N, BLOCK_SIZE: tl.constexpr):
X = X.to(tl.pointer_type(tl.float32))
partial_max = partial_max.to(tl.pointer_type(tl.float32))
pid = tl.program_id(0)
offset = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offset < N
x = tl.load(X + offset, mask=mask, other=-float("inf"))
local_max = tl.max(x, axis=0)
tl.store(partial_max + pid, local_max)
@triton.jit
def partial_exp_sum_value_kernel(X, partial_sum, global_max, N, BLOCK_SIZE: tl.constexpr):
X = X.to(tl.pointer_type(tl.float32))
partial_sum = partial_sum.to(tl.pointer_type(tl.float32))
global_max = global_max.to(tl.pointer_type(tl.float32))
pid = tl.program_id(0)
offset = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offset < N
x = tl.load(X + offset, mask=mask, other=-float("inf"))
gmax = tl.load(global_max)
local_sum = tl.sum(tl.exp(x - gmax), axis=0)
tl.store(partial_sum + pid, local_sum)
@triton.jit
def normalize_kernel(X, Y, N, global_max, global_sum, BLOCK_SIZE: tl.constexpr):
X = X.to(tl.pointer_type(tl.float32))
Y = Y.to(tl.pointer_type(tl.float32))
global_max = global_max.to(tl.pointer_type(tl.float32))
global_sum = global_sum.to(tl.pointer_type(tl.float32))
pid = tl.program_id(0)
offset = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offset < N
x = tl.load(X + offset, mask=mask)
gmax = tl.load(global_max)
gsum = tl.load(global_sum)
y = tl.exp(x - gmax) / gsum
tl.store(Y + offset, y, mask=mask)
@triton.jit
def get_max_value(partial_max, global_max, BLOCK_SIZE: tl.constexpr):
partial_max = partial_max.to(tl.pointer_type(tl.float32))
global_max = global_max.to(tl.pointer_type(tl.float32))
offset = tl.arange(0, BLOCK_SIZE)
x = tl.load(partial_max + offset)
local_max = tl.max(x, axis=0)
tl.store(global_max, local_max)
@triton.jit
def get_sum_value(partial_sum, global_sum, BLOCK_SIZE: tl.constexpr):
partial_sum = partial_sum.to(tl.pointer_type(tl.float32))
global_sum = global_sum.to(tl.pointer_type(tl.float32))
offset = tl.arange(0, BLOCK_SIZE)
x = tl.load(partial_sum + offset)
local_sum = tl.sum(x, axis=0)
tl.store(global_sum, local_sum)
def cudaEmpty(num_elements:int):
import ctypes
cudart = ctypes.CDLL("libcudart.so")
cudart.cudaMalloc.argtypes = [ctypes.POINTER(ctypes.c_void_p), ctypes.c_size_t]
cudart.cudaMalloc.restype = ctypes.c_int
ptr = ctypes.c_void_p()
err = cudart.cudaMalloc(ctypes.byref(ptr), num_elements*4)
if err != 0:
raise RuntimeError(f"cudaMalloc failed, code {err}")
return ptr.value
# input_ptr, output_ptr are raw device pointers
def solve(input_ptr: int, output_ptr: int, N: int):
BLOCK_SIZE = 32768
num_blocks = triton.cdiv(N, BLOCK_SIZE)
grid = (num_blocks,)
partial_max = cudaEmpty(BLOCK_SIZE)
partial_max_value_kernel[grid](
input_ptr, partial_max, N,
BLOCK_SIZE=BLOCK_SIZE
)
global_max = cudaEmpty(1)
get_max_value[1,](partial_max, global_max, BLOCK_SIZE=num_blocks)
partial_sum = cudaEmpty(num_blocks)
partial_exp_sum_value_kernel[grid](
input_ptr, partial_sum, global_max, N,
BLOCK_SIZE=BLOCK_SIZE
)
global_sum = cudaEmpty(1)
get_sum_value[1,](partial_sum, global_sum, BLOCK_SIZE=num_blocks)
normalize_kernel[grid](
input_ptr, output_ptr, N,
global_max, global_sum,
BLOCK_SIZE=BLOCK_SIZE
)
暂时领先cuda 心满意足.jpg 但感觉不太合理,怀疑评测程序有点问题。

4.30更那其实把这些规约的东西放到shared memory就好了,一个block干完所有任务算了。具体见以下代码
# The use of PyTorch in Triton programs is not allowed for the purposes of fair benchmarking.
import triton
import triton.language as tl
@triton.jit
def softmax_kernel(
input_ptr, output_ptr,
N,
BLOCK_SIZE: tl.constexpr
):
input_ptr = input_ptr.to(tl.pointer_type(tl.float32))
output_ptr = output_ptr.to(tl.pointer_type(tl.float32))
_max = tl.zeros([BLOCK_SIZE], dtype=tl.float32) - float("inf")
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(input_ptr + cols, mask=cols < N, other=-float("inf"))
_max = tl.maximum(a, _max)
max = tl.max(_max, axis=0)
_sum = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(input_ptr + cols, mask=cols < N, other=-float("inf"))
_sum += tl.exp(a - max)
sum = tl.sum(_sum, axis=0)
pid = tl.program_id(0)
offset = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offset < N
x = tl.load(input_ptr + offset, mask=mask)
y = tl.exp(x - max) / sum
tl.store(output_ptr + offset, y, mask=mask)
# input_ptr, output_ptr are raw device pointers
def solve(input_ptr: int, output_ptr: int, N: int):
BLOCK_SIZE = 32768
grid = (triton.cdiv(N, BLOCK_SIZE),)
softmax_kernel[grid](
input_ptr, output_ptr, N,
BLOCK_SIZE=BLOCK_SIZE
)
成功拿到number 1,值得纪念

五、提交新题
对比在传统OJ出题少了制造数据,我之前写过TZOJ出题帮助,这个数据看起来是平台这边帮忙给造的,提供cpu标程就可以了。

六、参考
2.LeetCUDA
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/18755313

 浙公网安备 33010602011771号
浙公网安备 33010602011771号